Озера даних набувають популярності для зберігання величезних обсягів даних із різноманітних джерел у масштабований та економічно ефективний спосіб. Оскільки кількість споживачів даних зростає, адміністраторам озер даних часто доводиться впроваджувати детальний контроль доступу для різних профілів користувачів. Їм може знадобитися обмежити доступ до певних таблиць або стовпців залежно від типу користувача, який робить запит. Крім того, компанії іноді хочуть зробити дані доступними для зовнішніх програм, але не знають, як це зробити безпечно. Щоб вирішити ці проблеми, організації можуть звернутися до GraphQL і Формування озера AWS.
GraphQL забезпечує потужний, безпечний і гнучкий спосіб запиту та отримання даних. AWS AppSync це служба для створення GraphQL API, яка може надсилати запити до кількох баз даних, мікросервісів і API з однієї уніфікованої кінцевої точки GraphQL.
Адміністратори озер даних можуть використовувати Lake Formation для керування доступом до озер даних. Lake Formation пропонує точне керування доступом для керування дозволами користувачів і груп на рівні таблиці, стовпця та клітинки. Таким чином, він може забезпечити безпеку даних і відповідність. Крім того, ця Lake Formation інтегрується з іншими службами AWS, такими як Амазонка Афіна, що робить його ідеальним для запитів до озер даних через API.
У цьому дописі ми демонструємо, як створити програму, яка може отримувати дані з озера даних за допомогою API GraphQL і надавати результати різним типам користувачів на основі їхніх конкретних привілеїв доступу до даних. Приклад програми, описаний у цій публікації, створено партнером AWS Технології НЕТСОЛ.
Огляд рішення
Наше рішення використовує Служба простого зберігання Amazon (Amazon S3) зберігати дані, Клей AWS Data Catalog для розміщення схеми даних і Lake Formation для забезпечення керування об’єктами AWS Glue Data Catalog шляхом впровадження рольового доступу. Ми також використовуємо Amazon EventBridge щоб фіксувати події в нашому озері даних і запускати подальші процеси. Архітектура рішення показана на наступній діаграмі.
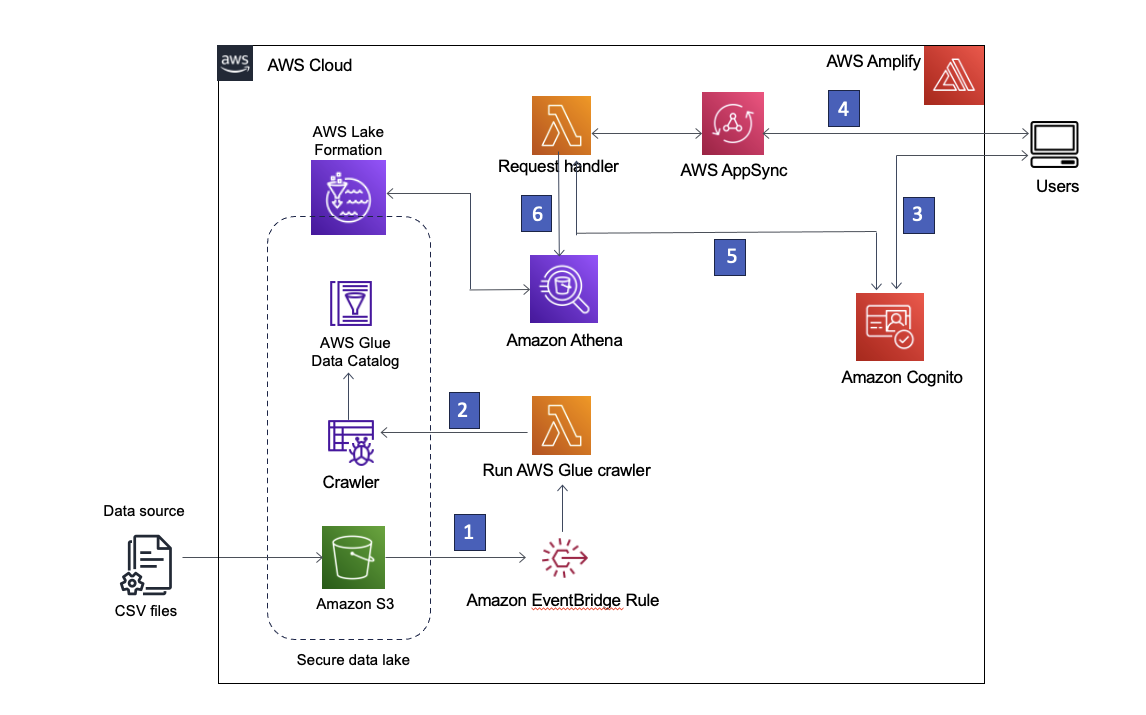
Рисунок 1 – Архітектура рішення
Нижче наведено покроковий опис рішення:
- Озеро даних створюється у сегменті S3, зареєстрованому в Lake Formation. Щоразу, коли надходять нові дані, викликається правило EventBridge.
- Правило EventBridge запускає AWS Lambda для запуску сканера AWS Glue для виявлення нових даних і оновлення будь-яких змін у схемі, щоб можна було запитувати останні дані.
Примітка: сканери AWS Glue також можна запускати безпосередньо з подій Amazon S3, як описано в цьому блог. - AWS Amplify дозволяє користувачам входити за допомогою Амазонка Когніто як постачальник ідентифікаційних даних. Cognito автентифікує облікові дані користувача та повертає маркери доступу.
- Автентифіковані користувачі викликають AWS AppSync GraphQL API через Amplify, отримуючи дані з озера даних. Для обробки запиту запускається функція Lambda.
- Функція Lambda отримує відомості про користувача з Cognito та припускає, що AWS Identity and Access Management (IAM) роль, пов’язану з групою користувачів Cognito запитувача.
- Потім функція Lambda запускає запит Athena до таблиць озера даних і повертає результати в AWS AppSync, який потім повертає результати користувачеві.
Передумови
Щоб розгорнути це рішення, ви повинні спочатку зробити наступне:
Підготувати дозволи на формування озера
Увійдіть у Консоль LakeFormation і додайте себе як адміністратора. Якщо ви входите в Lake Formation вперше, ви можете зробити це, вибравши «Додати себе» на екрані «Ласкаво просимо до Lake Formation» і вибравши «Розпочати», як показано на малюнку 2.

Рисунок 2. Додайте себе як адміністратора Lake Formation
В іншому випадку ви можете вибрати «Адміністративні ролі та завдання» на лівій навігаційній панелі та вибрати «Керування адміністраторами», щоб додати себе. Після завершення ви маєте побачити своє ім’я користувача IAM у розділі Адміністратори озера даних із повним доступом.
Виберіть параметри каталогу даних на лівій навігаційній панелі та переконайтеся, що два поля керування доступом IAM не вибрано, як показано на малюнку 3. Ви хочете, щоб Lake Formation, а не IAM, керував доступом до нових баз даних.
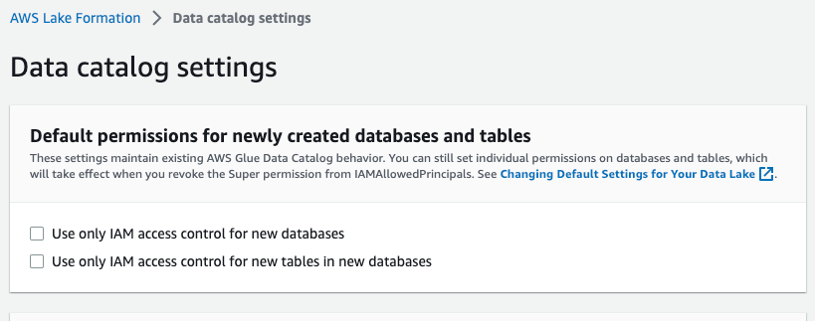
Рисунок 3 – Параметри каталогу даних Lake Formation
Розгорніть рішення
Щоб створити рішення у своєму середовищі AWS, запустіть такий стек AWS CloudFormation: ![]()
Наступні ресурси будуть запущені через шаблон CloudFormation:
- Amazon VPC і мережеві компоненти (підмережі, групи безпеки та шлюз NAT)
- Ролі IAM
- Lake Formation інкапсулююче відро S3, сканер AWS Glue і база даних AWS Glue
- Лямбда -функції
- Пул користувачів Cognito
- AWS AppSync GraphQL API
- Правила EventBridge
Після розгортання необхідних ресурсів зі стеку CloudFormation ви повинні створити дві функції Lambda та завантажити набір даних в Amazon S3. Lake Formation керуватиме озером даних, що зберігається у сегменті S3.
Створення лямбда-функцій
Кожного разу, коли новий файл поміщається в призначене відро S3, викликається правило EventBridge, яке запускає функцію Lambda для запуску сканера AWS Glue. Веб-сканер оновлює каталог даних AWS Glue, щоб відобразити будь-які зміни в схемі.
Коли програма надсилає запит на дані через GraphQL API, для обробки запиту та повернення результатів викликається лямбда-функція обробника запитів.
Щоб створити ці дві лямбда-функції, виконайте наступне.
- Увійдіть у консоль Lambda.
- Виберіть лямбда-функцію обробника запитів під назвою
dl-dev-crawlerLambdaFunction. - Знайдіть файл функції сканера Lambda у своєму
lambdas/crawler-lambdaу сховищі git, яке ви клонували на вашій локальній машині. - Скопіюйте та вставте код із цього файлу в розділ «Код».
dl-dev-crawlerLambdaFunctionу вашій консолі Lambda. Потім виберіть «Розгорнути», щоб розгорнути функцію.
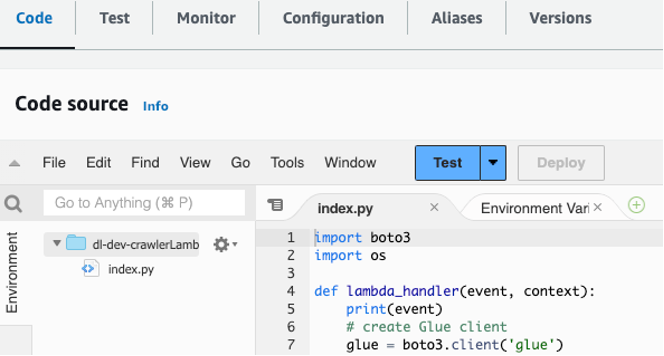
Рисунок 4 – Скопіюйте та вставте код у функцію Lambda
- Повторіть кроки 2–4 для вказаної функції обробника запитів
dl-dev-requestHandlerLambdaFunctionвикористовуючи код вlambdas/request-handler-lambda.
Створіть шар для обробника запитів Lambda
Тепер ви повинні завантажити додатковий код бібліотеки, необхідний для функції Lambda обробника запитів.
- Select Шари в меню ліворуч і виберіть Створити шар.
- Введіть назву, наприклад
appsync-lambda-layer. - завантажити цей ZIP-файл рівня пакета на вашу локальну машину.
- Завантажте ZIP-файл за допомогою Завантажувати кнопка на Створити шар стр.
- Вибирати Python 3.7 як час виконання для шару.
- Вибирати Створювати.
- Select Функції у меню ліворуч і виберіть
dl-dev-requestHandlerЛямбда-функція. - Прокрутіть вниз до Шари розділ і виберіть Додайте шар.
- Виберіть Користувацькі шари а потім виберіть шар, який ви створили вище.
- Натисніть додавати.
Завантажте дані в Amazon S3
Перейдіть до кореневого каталогу клонованого сховища git і виконайте наведені нижче команди, щоб завантажити зразок набору даних. Замініть bucket_name заповнювач із сегментом S3, наданим за допомогою шаблону CloudFormation. Ви можете отримати назву сегмента з консолі CloudFormation, перейшовши до Виходи вкладка з ключем datalakes3bucketName як показано на зображенні нижче.
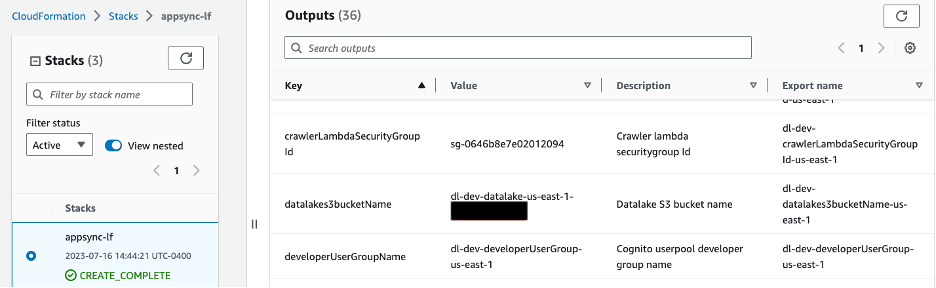
Малюнок 5 – Назва сегмента S3, показана на вкладці CloudFormation Outputs
Введіть наведені нижче команди в папку проекту на локальній машині, щоб завантажити набір даних у сегмент S3.
Тепер давайте подивимося на розгорнуті артефакти.
Озеро даних
Відро S3 містить зразки даних для двох організацій: компаній та їхніх відповідних власників. Відро зареєстровано в Lake Formation, як показано на малюнку 6. Це дає змогу Lake Formation створювати каталоги даних і керувати ними, а також керувати дозволами на дані.

Рисунок 6 – Консоль Lake Formation, на якій показано розташування озера даних
Базу даних створюється для зберігання схеми даних, присутніх в Amazon S3. Робота AWS Glue використовується для оновлення будь-яких змін у схемі в сегменті S3. Цьому сканеру надано дозвіл СТВОРЮВАТИ, ЗМІНЮВАТИ та ВИДАЛЯТИ таблиці в базі даних за допомогою Lake Formation.
Застосуйте елементи керування доступом до озера даних
Створено дві ролі IAM, dl-us-east-1-developer та dl-us-east-1-business-analyst, кожен з яких призначено окремій групі користувачів Cognito. Через Формування озера кожній ролі призначаються різні повноваження. Роль розробника отримує доступ до кожного стовпця в озері даних, тоді як роль бізнес-аналітика має доступ лише до стовпців інформації, що не дозволяє ідентифікувати особу.

Рисунок 7 – Дозволи озера даних консолі Lake Formation, призначені ролям групи
Схема GraphQL
API GraphQL доступний для перегляду з консолі AWS AppSync. The Companies тип містить кілька атрибутів, що описують власників компаній.
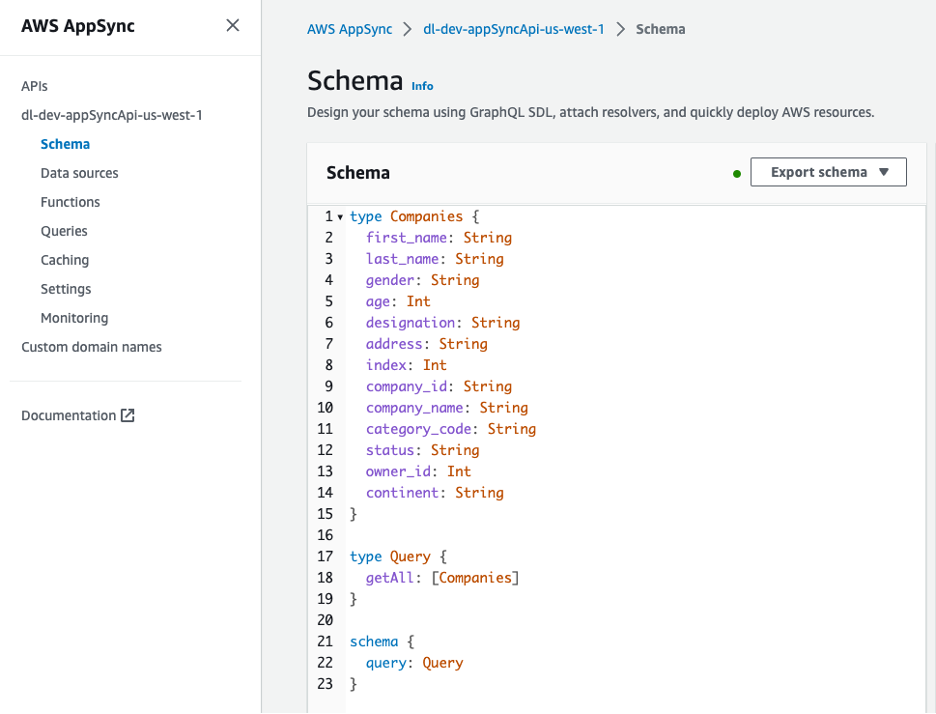
Рисунок 8 – Схема для GraphQL API
Джерелом даних для API GraphQL є функція Lambda, яка обробляє запити.
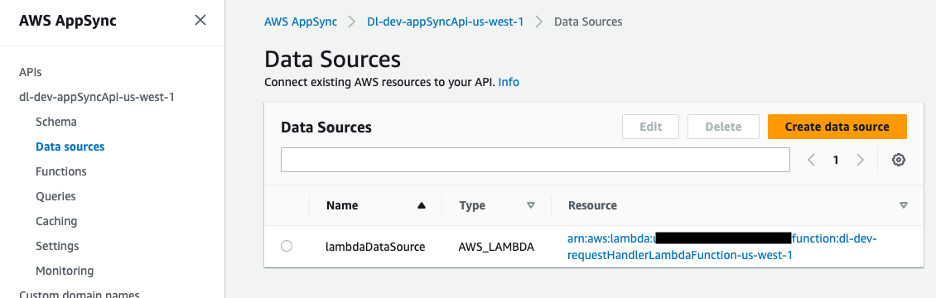
Рисунок 9 – Джерело даних AWS AppSync, зіставлене з функцією Lambda
Обробка запитів GraphQL API
Функція лямбда-обробника запитів GraphQL API отримує ідентифікатор пулу користувачів Cognito зі змінних середовища. Використовуючи бібліотеку boto3, ви створюєте клієнт Cognito та використовуєте get_group метод отримання ролі IAM, пов’язаної з групою користувачів Cognito.
Щоб отримати роль, ви використовуєте допоміжну функцію у функції Lambda.
Використання Служба маркерів безпеки AWS (AWS STS) через клієнт boto3 ви можете взяти на себе роль IAM і отримати тимчасові облікові дані, необхідні для виконання запиту Athena.
Ми передаємо тимчасові облікові дані як параметри під час створення нашого клієнта Boto3 Amazon Athena.
athena_client = boto3.client('athena', aws_access_key_id=access_key, aws_secret_access_key=secret_key, aws_session_token=session_token)Клієнт і запит передаються в нашу допоміжну функцію запитів Athena, яка виконує запит і повертає ідентифікатор запиту. За допомогою ідентифікатора запиту ми можемо читати результати з S3 і об’єднувати їх як словник Python, який повертається у відповідь.
Увімкнення клієнтського доступу до озера даних
На стороні клієнта AWS Amplify налаштовано з пулом користувачів Amazon Cognito для автентифікації. Ми перейдемо до консолі Amazon Cognito, щоб переглянути пул користувачів і створені групи.
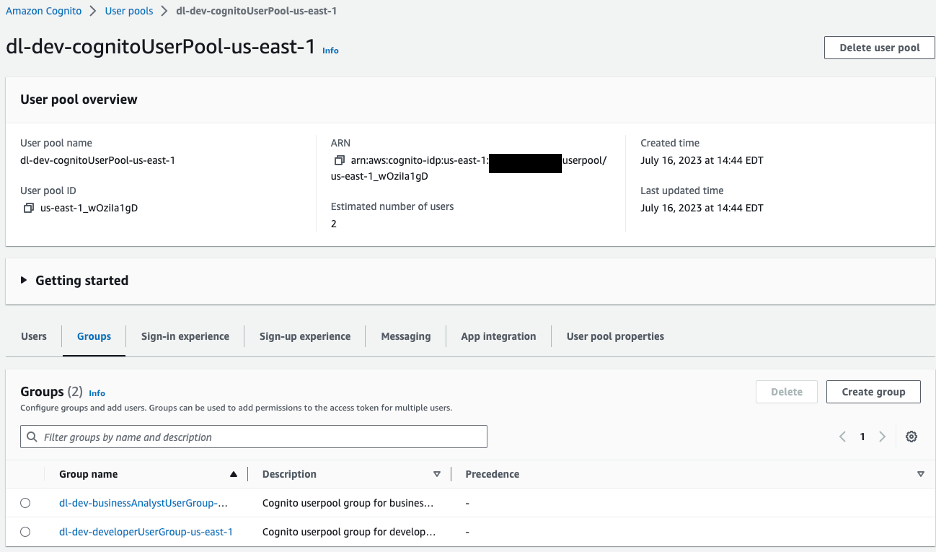
Рисунок 10 – Пули користувачів Amazon Cognito
Для нашого прикладу програми ми маємо дві групи в нашому пулі користувачів:
dl-dev-businessAnalystUserGroup– Бізнес-аналітики з обмеженими правами.dl-dev-developerUserGroup– Розробники з повними дозволами.
Якщо ви дослідите ці групи, ви побачите роль IAM, пов’язану з кожною. Це роль IAM, яка призначається користувачеві під час автентифікації. Athena бере на себе цю роль під час запиту до озера даних.
Якщо ви переглянете дозволи для цієї ролі IAM, ви помітите, що вона не містить елементів керування доступом нижче рівня таблиці. Вам потрібен додатковий рівень керування, наданий Lake Formation, щоб додати детальний контроль доступу.
Після того, як Cognito перевірить і автентифікує користувача, Amplify використовує маркери доступу, щоб викликати API AWS AppSync GraphQL і отримати дані. На основі групи користувача функція Lambda приймає на себе відповідну роль групи користувачів Cognito. Використовуючи прийняту роль, виконується запит Athena, і результат повертається користувачеві.
Створення тестових користувачів
Створіть двох користувачів, одного для розробника та одного для бізнес-аналітика, і додайте їх до груп користувачів.
- Перейдіть до Cognito та виберіть пул користувачів,
dl-dev-cognitoUserPool, це створено. - Вибирати Створити користувача і надайте деталі для створення нового користувача бізнес-аналітика. Ім'я користувача може бути бізнес-аналітик. Залиште адресу електронної пошти пустою та введіть пароль.
- Виберіть користувачів і виберіть щойно створеного користувача.
- Додайте цього користувача до групи бізнес-аналітиків, вибравши Додати користувача до групи кнопки.
- Виконайте ті самі кроки, щоб створити іншого користувача з цим іменем розробник і додайте користувача до групи розробників.
Перевірте розчин
Щоб протестувати своє рішення, запустіть програму React на локальній машині.
- У каталозі клонованого проекту перейдіть до
react-appкаталог. - Встановіть залежності проекту.
- Встановіть Amplify CLI:
- Створіть новий файл під назвою
.envза допомогою наступних команд. Потім за допомогою текстового редактора оновіть значення змінних середовища у файлі.
Використовувати Виходи вкладку стека консолі CloudFormation, щоб отримати необхідні значення з ключів, як показано нижче:
REACT_APP_APPSYNC_URL |
appsyncApiEndpoint |
REACT_APP_CLIENT_ID |
cognitoUserPoolClientId |
REACT_APP_USER_POOL_ID |
cognitoUserPoolId |
- Додайте попередні змінні до свого середовища.
- Згенеруйте код, необхідний для взаємодії з API за допомогою Розширити CodeGen. На вкладці «Виходи» консолі Cloudformation знайдіть свій ідентифікатор API AWS Appsync поруч із
appsyncApiIdключ
Прийміть усі параметри за замовчуванням для наведеної вище команди, натиснувши Що натомість? Створіть віртуальну версію себе у на кожну підказку.
- Запустіть додаток.
Ви можете підтвердити, що програма запущена, відвідавши http://localhost:3000 і ввійдіть як користувач-розробник, якого ви створили раніше.
Тепер, коли програма запущена, давайте подивимося, як кожна роль обслуговується з companies кінцева точка.
По-перше, підпишіться як роль розробника, яка має доступ до всіх полів, і зробіть запит API до кінцевої точки компанії. Зверніть увагу, до яких полів ви маєте доступ.
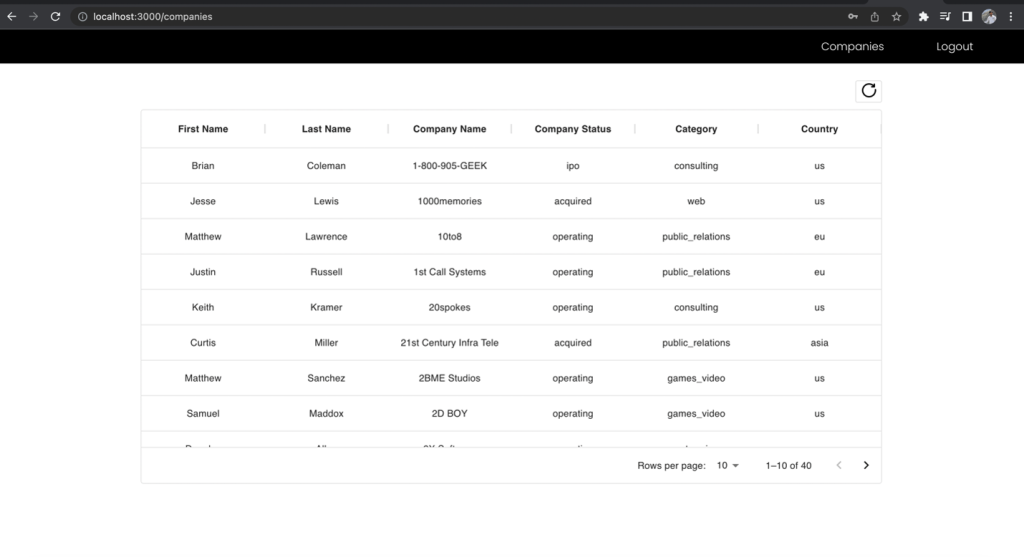
Рисунок 11 – Результати для ролі розробника
Тепер увійдіть як користувач Business Analyst і зробіть запит до тієї самої кінцевої точки та порівняйте включені поля.
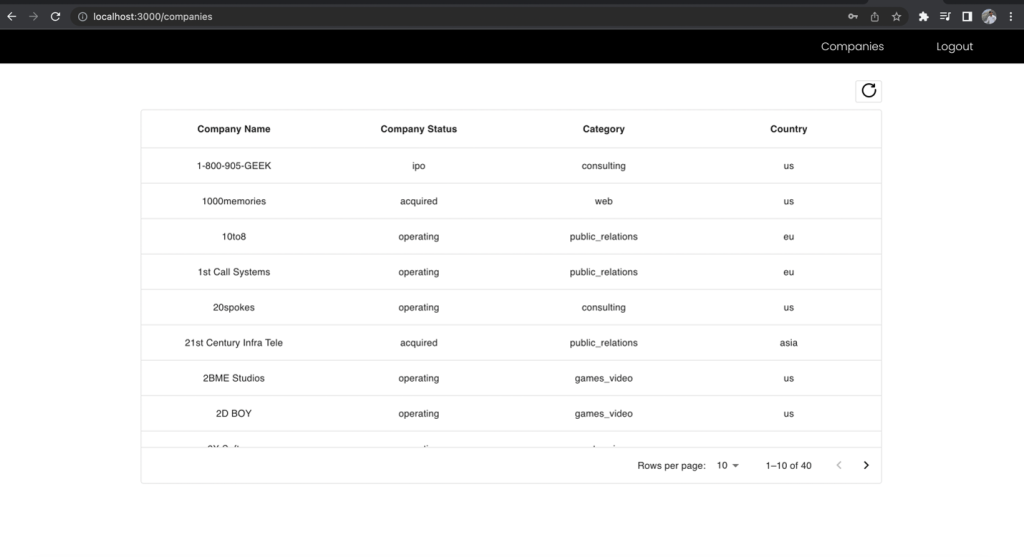
Рисунок 12 – Результати для ролі бізнес-аналітика
Стовпці «Ім’я» та «Прізвище» списку компаній виключаються в поданні бізнес-аналітики, навіть якщо ви зробили запит до тієї самої кінцевої точки. Це демонструє потужність використання однієї уніфікованої кінцевої точки GraphQL разом із кількома ролями IAM групи користувачів Cognito, зіставленими з дозволами Lake Formation, для керування доступом на основі ролей до ваших даних.
Очищення
Після завершення тестування рішення очистіть наведені нижче ресурси, щоб уникнути стягнення плати в майбутньому:
- Очистіть відра S3, створені шаблоном CloudFormation.
- Видаліть стек CloudFormation, щоб видалити сегменти S3 та інші ресурси.
Висновок
У цій публікації ми показали вам, як безпечно надавати дані в озері даних автентифікованим користувачам програми React на основі їхніх прав доступу на основі ролей. Щоб досягти цього, ви використали GraphQL API в AWS AppSync, детальні елементи керування доступом із Lake Formation і Cognito для автентифікації користувачів за групами та зіставлення їх із ролями IAM. Ви також використовували Athena для запиту даних.
Додаткову інформацію на цю тему див Візуалізація великих даних за допомогою AWS AppSync, Amazon Athena та AWS Amplify та Створіть архітектуру сітки даних за допомогою AWS Lake Formation і AWS Glue.
Чи застосуєте ви цей підхід для обслуговування даних із вашого озера даних? Дайте нам знати в коментарях!
Про авторів
 Рана Датт є головним архітектором рішень в Amazon Web Services. Він має досвід розробки масштабованих програмних платформ для фінансових послуг, охорони здоров’я та телекомунікаційних компаній, і він захоплено допомагає клієнтам будувати AWS.
Рана Датт є головним архітектором рішень в Amazon Web Services. Він має досвід розробки масштабованих програмних платформ для фінансових послуг, охорони здоров’я та телекомунікаційних компаній, і він захоплено допомагає клієнтам будувати AWS.
 Ранджит Раяпролу є старшим архітектором рішень в AWS, який працює з клієнтами на північному заході Тихого океану. Він допомагає клієнтам розробляти та використовувати добре архітектурні рішення в AWS, які вирішують їхні бізнес-проблеми та прискорюють впровадження послуг AWS. Він зосереджується на безпеці та мережевих технологіях AWS для розробки рішень у хмарі в різних галузевих вертикалях. Ранджит живе в районі Сіетла і любить активний відпочинок.
Ранджит Раяпролу є старшим архітектором рішень в AWS, який працює з клієнтами на північному заході Тихого океану. Він допомагає клієнтам розробляти та використовувати добре архітектурні рішення в AWS, які вирішують їхні бізнес-проблеми та прискорюють впровадження послуг AWS. Він зосереджується на безпеці та мережевих технологіях AWS для розробки рішень у хмарі в різних галузевих вертикалях. Ранджит живе в районі Сіетла і любить активний відпочинок.
 Джастін Лето є старшим архітектором рішень в Amazon Web Services, спеціалізується на базах даних, аналітиці великих даних і машинному навчанні. Його пристрасть полягає в тому, щоб допомогти клієнтам краще адаптувати хмару. У вільний час він захоплюється морським плаванням і грою на джазовому фортепіано. Він живе в Нью-Йорку з дружиною та маленькою донькою.
Джастін Лето є старшим архітектором рішень в Amazon Web Services, спеціалізується на базах даних, аналітиці великих даних і машинному навчанні. Його пристрасть полягає в тому, щоб допомогти клієнтам краще адаптувати хмару. У вільний час він захоплюється морським плаванням і грою на джазовому фортепіано. Він живе в Нью-Йорку з дружиною та маленькою донькою.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/using-aws-appsync-and-aws-lake-formation-to-access-a-secure-data-lake-through-a-graphql-api/
- : має
- :є
- : ні
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 14
- 200
- 27
- 32
- 7
- 8
- 9
- a
- Здатний
- МЕНЮ
- вище
- прискорювати
- доступ
- управління доступом
- Доступ до даних
- виконувати
- Achieve
- через
- діяльності
- додавати
- Додатковий
- Додатково
- адреса
- адміністративний
- Адміністратори
- Прийняття
- проти
- ВСІ
- дозволяє
- Також
- Amazon
- Амазонка Афіна
- Амазонка Когніто
- Amazon Web Services
- суми
- посилюватися
- an
- аналітик
- аналітики
- аналітика
- та
- Інший
- будь-який
- API
- Інтерфейси
- додаток
- додаток
- застосування
- підхід
- архітектура
- ЕСТЬ
- ПЛОЩА
- Прибуває
- AS
- призначений
- асоційований
- припустити
- передбачається
- передбачає
- At
- Атрибути
- перевіряти справжність
- автентифіковано
- засвідчує автентифікацію
- Authentication
- доступний
- уникнути
- AWS
- AWS CloudFormation
- Клей AWS
- Формування озера AWS
- дитина
- фон
- бар
- заснований
- BE
- було
- нижче
- Краще
- Великий
- Великий даних
- Black
- тіло
- коробки
- будувати
- побудований
- Пакет
- бізнес
- підприємства
- але
- button
- by
- званий
- CAN
- Може отримати
- захоплення
- каталог
- каталоги
- CD
- осередок
- певний
- проблеми
- зміна
- Зміни
- вантажі
- Вибирати
- Вибираючи
- Місто
- клієнт
- хмара
- прийняття хмари
- код
- Колонка
- Колони
- COM
- Компанії
- порівняти
- дотримання
- Компоненти
- налаштувати
- підтвердити
- Консоль
- Споживачі
- контроль
- управління
- Відповідний
- рентабельним
- гусеничний
- створювати
- створений
- створення
- Повноваження
- Клієнти
- дані
- доступ до даних
- Analytics даних
- Озеро даних
- безпеку даних
- Database
- базами даних
- дефолт
- доставляти
- демонструвати
- демонструє
- залежно
- Залежно
- розгортання
- розгорнути
- описаний
- description
- дизайн
- призначені
- деталі
- DEV
- розвивати
- Розробник
- розробників
- різний
- безпосередньо
- відкрити
- Різне
- do
- Ні
- зроблений
- вниз
- Падіння
- кожен
- Раніше
- нудьгувати
- редактор
- ще
- дозволяє
- Кінцева точка
- забезпечувати
- Що натомість? Створіть віртуальну версію себе у
- юридичні особи
- Навколишнє середовище
- Ефір (ETH)
- Навіть
- Події
- Кожен
- приклад
- виключений
- Виконує
- дослідити
- експорт
- зовнішній
- витяг
- Поля
- Рисунок
- філе
- фінансовий
- фінансові послуги
- знайти
- Перший
- перший раз
- гнучкий
- фокусується
- після
- слідує
- для
- освіта
- від
- Повний
- функція
- Функції
- майбутнє
- набирає
- прибуток
- шлюз
- отримати
- Git
- буде
- управління
- надається
- GraphQL
- Group
- Групи
- Зростає
- обробляти
- Ручки
- Мати
- he
- охорона здоров'я
- допомогу
- допомагає
- його
- тримати
- тримає
- будинок
- Як
- How To
- HTML
- HTTP
- HTTPS
- IAM
- ID
- ідеальний
- Особистість
- управління ідентифікацією та доступом
- if
- зображення
- здійснювати
- реалізації
- in
- включати
- включені
- includes
- промисловість
- інформація
- ініціювати
- встановлювати
- Інтеграція
- взаємодіяти
- в
- викликали
- IT
- JPG
- просто
- ключ
- ключі
- Знати
- озеро
- озера
- останній
- останній
- запуск
- запущений
- запуски
- шар
- вивчення
- Залишати
- залишити
- дозволяти
- рівень
- бібліотека
- обмеженою
- список
- Місце проживання
- місцевий
- розташування
- подивитися
- любить
- машина
- навчання за допомогою машини
- made
- зробити
- РОБОТИ
- Робить
- управляти
- управління
- управління
- відображення
- Меню
- сітці
- метод
- мікросервіс
- може бути
- множинний
- повинен
- себе
- ім'я
- Названий
- Переміщення
- навігація
- Необхідність
- необхідний
- мережа
- Нові
- Нью-Йорк
- Нью-Йорк
- наступний
- увагу
- Зверніть увагу..
- зараз
- номер
- об'єкти
- отримувати
- of
- Пропозиції
- часто
- on
- ONE
- тільки
- працювати
- варіант
- Опції
- or
- організації
- Інше
- наші
- Outdoor
- виходи
- над
- Власники
- Тихий океан
- сторінка
- панди
- параметри
- партнер
- проходити
- Пройшов
- пристрасть
- пристрасний
- Пароль
- дозвіл
- Дозволи
- пій
- розміщений
- заповнювач
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- ігри
- басейн
- Басейни
- популярність
- пошта
- влада
- потужний
- представити
- пресування
- Головний
- привілеї
- проблеми
- продовжити
- процес
- процеси
- Профілі
- проект
- забезпечувати
- за умови
- Постачальник
- забезпечує
- Python
- Реагувати
- Читати
- читання
- облік
- відображати
- зареєстрований
- пов'язаний
- видаляти
- замінювати
- Сховище
- запросити
- запитів
- вимагається
- ресурси
- ті
- відповідь
- обмежити
- результат
- результати
- повертати
- Умови повернення
- Роль
- ролі
- корінь
- Правило
- прогін
- біг
- пробіжки
- вітрильний спорт
- то ж
- Зразок набору даних
- масштабовані
- Екран
- Сіетл
- розділ
- безпечний
- безпечно
- безпеку
- токен безпеки
- побачити
- обраний
- вибирає
- старший
- служити
- служив
- обслуговування
- Послуги
- виступаючої
- налаштування
- кілька
- Повинен
- показав
- показ
- показаний
- сторона
- підпис
- підписання
- простий
- So
- Софтвер
- solid
- рішення
- Рішення
- деякі
- іноді
- Source
- Джерела
- конкретний
- стек
- старт
- почалася
- Статус
- Крок
- заходи
- зберігання
- зберігати
- Зберігайте дані
- зберігати
- підмережі
- успішний
- такі
- Переконайтеся
- таблиця
- Приймати
- завдання
- Технології
- телеком
- шаблон
- тимчасовий
- тест
- Тестування
- текст
- Що
- Команда
- їх
- Їх
- потім
- отже
- Ці
- вони
- це
- хоча?
- через
- час
- до
- разом
- знак
- Жетони
- тема
- ПЕРЕГЛЯД
- два
- тип
- Типи
- при
- єдиний
- Оновити
- Updates
- URL
- us
- використання
- використовуваний
- користувач
- ім'я користувача
- користувачі
- використовує
- використання
- Цінності
- змінна
- змінні
- величезний
- перевірено
- вертикалі
- вид
- хотіти
- було
- шлях..
- we
- Web
- веб-сервіси
- ласкаво просимо
- були
- коли
- коли б ні
- який
- в той час як
- дружина
- волі
- з
- робочий
- йорк
- ви
- вашу
- себе
- зефірнет
- Zip