تنظیموں نے سب سے اوپر ڈیٹا لیکس بنانے کا انتخاب کیا ہے۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) کئی سالوں سے۔ ایک ڈیٹا لیک تنظیموں کے لیے مختلف ٹیموں کے ذریعے تیار کردہ تمام تنظیمی ڈیٹا، کاروباری ڈومینز، تمام مختلف فارمیٹس سے، اور یہاں تک کہ تاریخ میں ذخیرہ کرنے کا سب سے مقبول انتخاب ہے۔ کے مطابق پڑھائی، اوسط کمپنی اپنے ڈیٹا کے حجم کو اس شرح سے بڑھتے ہوئے دیکھ رہی ہے جو سالانہ 50% سے زیادہ ہے، عام طور پر تجزیہ کے لیے اوسطاً 33 منفرد ڈیٹا ذرائع کا انتظام کرتی ہے۔
ٹیمیں اکثر متعلقہ ڈیٹا بیس سے ہزاروں ملازمتوں کو ایک ہی ایکسٹریکٹ، ٹرانسفارم اور لوڈ (ETL) پیٹرن کے ساتھ نقل کرنے کی کوشش کرتی ہیں۔ ملازمت کی حالتوں کو برقرار رکھنے اور ان انفرادی ملازمتوں کو شیڈول کرنے میں بہت زیادہ کوششیں کرنا پڑتی ہیں۔ یہ نقطہ نظر ٹیموں کو کچھ تبدیلیوں کے ساتھ میزیں شامل کرنے میں مدد کرتا ہے اور کم سے کم کوشش کے ساتھ ملازمت کی حیثیت کو برقرار رکھتا ہے۔ اس سے ترقیاتی ٹائم لائن میں بہت زیادہ بہتری آسکتی ہے اور آسانی کے ساتھ ملازمتوں کا سراغ لگایا جاسکتا ہے۔
اس پوسٹ میں، ہم آپ کو دکھاتے ہیں کہ اپاچی آئس برگ کا استعمال کرتے ہوئے ایک ہی ETL جاب کے ساتھ اپنے تمام متعلقہ ڈیٹا اسٹورز کو آسانی سے ایک خودکار انداز میں ٹرانزیکشنل ڈیٹا لیک میں نقل کرنا ہے۔ AWS گلو.
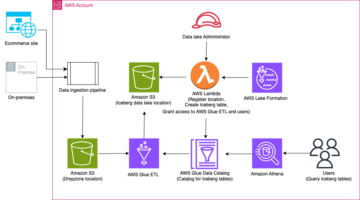
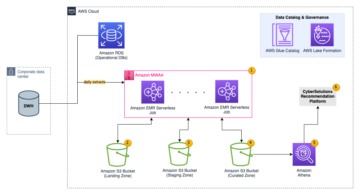
حل فن تعمیر
ڈیٹا لیکس ہیں۔ عام طور پر منظم ڈیٹا کی تین پرتوں کے لیے علیحدہ S3 بالٹیاں استعمال کرنا: خام پرت جس میں ڈیٹا اپنی اصل شکل میں ہوتا ہے، اسٹیج پرت جس میں انٹرمیڈیٹ پروسیسڈ ڈیٹا ہوتا ہے جو استعمال کے لیے موزوں ہوتا ہے، اور مخصوص استعمال کے معاملات کے لیے مجموعی ڈیٹا پر مشتمل تجزیاتی پرت۔ خام پرت میں، میزیں عام طور پر ان کے ڈیٹا کے ذرائع کی بنیاد پر ترتیب دی جاتی ہیں، جب کہ اسٹیج پرت میں موجود میزیں ان کاروباری ڈومینز کی بنیاد پر ترتیب دی جاتی ہیں جن سے وہ تعلق رکھتے ہیں۔
یہ پوسٹ ایک فراہم کرتا ہے AWS کلاؤڈ فارمیشن ٹیمپلیٹ جو AWS Glue جاب کو متعین کرتا ہے جو ڈیٹا لیک کی خام پرت کے ایک ڈیٹا سورس کے لیے Amazon S3 پاتھ کو پڑھتا ہے، اور ڈیٹا کو اسٹیج لیئر پر اپاچی آئس برگ ٹیبلز میں داخل کرتا ہے۔ ڈیٹا لیک فریم ورک کے لیے AWS گلو سپورٹ. کام توقع کرتا ہے کہ خام پرت میں میزیں اس طرح سے ترتیب دی جائیں گی۔ AWS ڈیٹا بیس مائیگریشن سروس (AWS DMS) انہیں داخل کرتا ہے: اسکیما، پھر ٹیبل، پھر ڈیٹا فائلز۔
یہ حل استعمال کرتا ہے۔ AWS سسٹمز مینیجر پیرامیٹر اسٹور ٹیبل کی ترتیب کے لیے۔ آپ کو اس پیرامیٹر میں ترمیم کرنی چاہیے جس میں آپ ان میزوں کی وضاحت کرنا چاہتے ہیں جن پر آپ کارروائی کرنا چاہتے ہیں اور کیسے، بشمول بنیادی کلید، پارٹیشنز، اور متعلقہ کاروباری ڈومین جیسی معلومات۔ جاب اس معلومات کا استعمال ہر کاروباری ڈومین کے لیے خود بخود ایک ڈیٹا بیس (اگر یہ پہلے سے موجود نہیں ہے) بنانے، آئس برگ ٹیبلز بنانے، اور ڈیٹا لوڈ کرنے کے لیے کرتی ہے۔
آخر میں، ہم استعمال کر سکتے ہیں ایمیزون ایتینا آئس برگ ٹیبلز میں ڈیٹا سے استفسار کرنے کے لیے۔
مندرجہ ذیل خاکہ اس فن تعمیر کو واضح کرتا ہے۔

اس نفاذ میں درج ذیل تحفظات ہیں:
- اس حل کا استعمال کرتے ہوئے نقل کرنے کے لیے ڈیٹا سورس سے تمام ٹیبلز میں ایک بنیادی کلید ہونی چاہیے۔ بنیادی کلید ایک کالم یا ایک سے زیادہ کالم کے ساتھ ایک جامع کلید ہو سکتی ہے۔
- اگر ڈیٹا لیک میں ایسی میزیں ہیں جن کو اپسرٹس کی ضرورت نہیں ہے یا ان کے پاس بنیادی کلید نہیں ہے، تو آپ انہیں پیرامیٹر کنفیگریشن سے خارج کر سکتے ہیں اور ڈیٹا لیک میں داخل کرنے کے لیے روایتی ETL عمل کو لاگو کر سکتے ہیں۔ یہ اس پوسٹ کے دائرہ کار سے باہر ہے۔
- اگر ڈیٹا کے اضافی ذرائع ہیں جن کو ہضم کرنے کی ضرورت ہے، تو آپ ایک سے زیادہ CloudFormation اسٹیک تعینات کر سکتے ہیں، ہر ایک ڈیٹا سورس کو سنبھالنے کے لیے۔
- AWS Glue جاب کو ڈیٹا کو دو مراحل میں پروسیس کرنے کے لیے ڈیزائن کیا گیا ہے: ابتدائی بوجھ جو AWS DMS کے مکمل لوڈ ٹاسک کو مکمل کرنے کے بعد چلتا ہے، اور اضافی بوجھ جو کہ AWS DMS کے ذریعے کیپچر کی گئی ڈیٹا کیپچر (CDC) فائلوں کو تبدیل کرنے والے شیڈول پر چلتا ہے۔ انکریمنٹل پروسیسنگ کا استعمال کرتے ہوئے کیا جاتا ہے۔ AWS گلو جاب بک مارک.
اس ٹیوٹوریل کو مکمل کرنے کے لیے نو مراحل ہیں:
- AWS DMS کے لیے ایک سورس اینڈ پوائنٹ سیٹ اپ کریں۔
- AWS CloudFormation کا استعمال کرتے ہوئے حل کو تعینات کریں۔
- AWS DMS نقل کے کام کا جائزہ لیں۔
- اختیاری طور پر، انکرپشن اور ڈکرپشن کے لیے اجازتیں شامل کریں یا AWS جھیل کی تشکیل.
- پیرامیٹر اسٹور پر ٹیبل کنفیگریشن کا جائزہ لیں۔
- ابتدائی ڈیٹا لوڈنگ انجام دیں۔
- اضافی ڈیٹا لوڈنگ انجام دیں۔
- ٹیبل کے ادخال کی نگرانی کریں۔
- انکریمنٹل بیچ ڈیٹا لوڈنگ کا شیڈول بنائیں۔
شرائط
اس ٹیوٹوریل کو شروع کرنے سے پہلے، آپ کو پہلے سے ہی آئس برگ سے واقف ہونا چاہیے۔ اگر آپ نہیں ہیں، تو آپ میں دی گئی ہدایات پر عمل کرتے ہوئے ایک ہی ٹیبل کی نقل بنا کر شروع کر سکتے ہیں۔ Apache Iceberg اور AWS Glue کا استعمال کرتے ہوئے ڈیٹا لیک میں CDC پر مبنی UPSERT لاگو کریں۔. مزید برآں، درج ذیل کو ترتیب دیں:
AWS DMS کے لیے ایک سورس اینڈ پوائنٹ سیٹ اپ کریں۔
اس سے پہلے کہ ہم اپنا AWS DMS ٹاسک بنائیں، ہمیں سورس ڈیٹا بیس سے منسلک ہونے کے لیے ایک سورس اینڈ پوائنٹ قائم کرنا ہوگا:
- AWS DMS کنسول پر، منتخب کریں۔ اختتامی نکات نیوی گیشن پین میں.
- میں سے انتخاب کریں اختتامی نقطہ بنائیں.
- اگر آپ کا ڈیٹا بیس ایمیزون آر ڈی ایس پر چل رہا ہے تو منتخب کریں۔ RDS DB مثال منتخب کریں۔، پھر فہرست سے مثال منتخب کریں۔ بصورت دیگر، سورس انجن کا انتخاب کریں اور کنکشن کی معلومات فراہم کریں۔ AWS سیکرٹس مینیجر یا دستی طور پر.
- کے لئے اختتامی نقطہ شناخت کنندہاختتامی نقطہ کے لیے ایک نام درج کریں؛ مثال کے طور پر، source-postgresql.
- میں سے انتخاب کریں اختتامی نقطہ بنائیں.
AWS CloudFormation کا استعمال کرتے ہوئے حل کو تعینات کریں۔
فراہم کردہ ٹیمپلیٹ کا استعمال کرتے ہوئے CloudFormation اسٹیک بنائیں۔ درج ذیل مراحل کو مکمل کریں:
- میں سے انتخاب کریں لانچ اسٹیک:

- میں سے انتخاب کریں اگلے.
- اسٹیک کا نام فراہم کریں، جیسے
transactionaldl-postgresql. - مطلوبہ پیرامیٹرز درج کریں:
- DMSS3EndpointIAMRoleARN - ایمیزون S3 میں ڈیٹا لکھنے کے لیے AWS DMS کے لیے IAM رول ARN۔
- ReplicationInstanceArn - AWS DMS نقل کی مثال ARN۔
- S3BucketStage - موجودہ بالٹی کا نام جو ڈیٹا لیک کی اسٹیج پرت کے لیے استعمال ہوتا ہے۔
- S3BucketGlue - AWS Glue اسکرپٹس کو ذخیرہ کرنے کے لیے موجودہ S3 بالٹی کا نام۔
- S3BucketRaw - موجودہ بالٹی کا نام جو ڈیٹا لیک کی خام تہہ کے لیے استعمال ہوتا ہے۔
- SourceEndpointArn - AWS DMS اینڈ پوائنٹ ARN جو آپ نے پہلے بنایا تھا۔
- ماخذ کا نام - نقل کرنے کے لیے ڈیٹا سورس کا صوابدیدی شناخت کنندہ (مثال کے طور پر،
postgres)۔ اس کا استعمال ڈیٹا لیک (خام پرت) کے S3 راستے کی وضاحت کے لیے کیا جاتا ہے جہاں ڈیٹا کو محفوظ کیا جائے گا۔
- درج ذیل پیرامیٹرز میں ترمیم نہ کریں:
- SourceS3BucketBlog - بالٹی کا نام جہاں فراہم کردہ AWS Glue اسکرپٹ کو محفوظ کیا جاتا ہے۔
- SourceS3BucketPrefix - بالٹی کا سابقہ نام جہاں فراہم کردہ AWS Glue اسکرپٹ کو محفوظ کیا جاتا ہے۔
- میں سے انتخاب کریں اگلے دو بار
- منتخب کریں میں تسلیم کرتا ہوں کہ AWS CloudFormation حسب ضرورت ناموں کے ساتھ IAM وسائل تخلیق کر سکتا ہے۔
- میں سے انتخاب کریں اسٹیک بنائیں.
تقریباً 5 منٹ کے بعد، CloudFormation اسٹیک تعینات ہو جاتا ہے۔
AWS DMS نقل کے کام کا جائزہ لیں۔
AWS CloudFormation کی تعیناتی نے آپ کے لیے AWS DMS ٹارگٹ اینڈ پوائنٹ بنایا ہے۔ اختتامی نقطہ کی دو مخصوص ترتیبات کی وجہ سے، ڈیٹا کو ہضم کیا جائے گا جیسا کہ ہمیں Amazon S3 پر اس کی ضرورت ہے۔
- AWS DMS کنسول پر، منتخب کریں۔ اختتامی نکات نیوی گیشن پین میں.
- اس کے ساتھ شروع ہونے والے اختتامی نقطہ کو تلاش کریں اور منتخب کریں۔
dmsIcebergs3endpoint. - اختتامی نقطہ کی ترتیبات کا جائزہ لیں:
DataFormatکے طور پر بیان کیا گیا ہے۔parquet.TimestampColumnNameکالم شامل کریں گے۔last_update_timeایمیزون S3 پر ریکارڈز کی تخلیق کی تاریخ کے ساتھ۔

تعیناتی ایک AWS DMS نقل کا کام بھی بناتی ہے جس سے شروع ہوتا ہے۔ dmsicebergtask.
- میں سے انتخاب کریں نقل کے کام نیویگیشن پین میں اور کام تلاش کریں۔
آپ دیکھیں گے کہ ٹاسک کی قسم کے طور پر نشان لگا دیا گیا ہے مکمل بوجھ، جاری نقل. AWS DMS موجودہ ڈیٹا کا ابتدائی مکمل بوجھ انجام دے گا، اور پھر ماخذ ڈیٹا بیس میں کی جانے والی تبدیلیوں کے ساتھ اضافی فائلیں بنائے گا۔
پر نقشہ سازی کے قواعد ٹیب، قوانین کی دو قسمیں ہیں:
- سورس اسکیما اور ٹیبلز کے نام کے ساتھ سلیکشن کا اصول جو سورس ڈیٹا بیس سے ہضم کیا جائے گا۔ پہلے سے طے شدہ طور پر، یہ شرائط میں فراہم کردہ نمونہ ڈیٹا بیس کا استعمال کرتا ہے،
dms_sample, اور کلیدی لفظ % کے ساتھ تمام جدولیں۔ - تبدیلی کے دو اصول جن میں ایمیزون S3 پر ٹارگٹ فائلز میں اسکیما کا نام اور ٹیبل کا نام بطور کالم شامل ہے۔ یہ ہمارے AWS Glue جاب کے ذریعے یہ جاننے کے لیے استعمال کیا جاتا ہے کہ ڈیٹا لیک میں موجود فائلیں کن ٹیبلز سے مطابقت رکھتی ہیں۔
اپنے ڈیٹا کے ذرائع کے لیے اسے کس طرح اپنی مرضی کے مطابق بنانا ہے اس بارے میں مزید جاننے کے لیے، ملاحظہ کریں۔ انتخاب کے قوانین اور اعمال.

آئیے اپنے کام کی تیاری مکمل کرنے کے لیے کچھ کنفیگریشنز کو تبدیل کرتے ہیں۔
- پر عوامل مینو، منتخب کریں میں ترمیم کریں.
- میں ٹاسک کی ترتیبات سیکشن کے تحت مکمل لوڈ مکمل ہونے کے بعد کام کو روک دیں۔منتخب کریں کیش شدہ تبدیلیاں لاگو کرنے کے بعد رک جائیں۔.
اس طرح، ہم دو مختلف مراحل کے طور پر ابتدائی بوجھ اور انکریمنٹل فائل جنریشن کو کنٹرول کر سکتے ہیں۔ ہم ہر قدم پر ایک بار AWS Glue جاب کو چلانے کے لیے یہ دو قدمی طریقہ استعمال کرتے ہیں۔
- کے تحت ٹاسک لاگزمنتخب کریں CloudWatch لاگز کو آن کریں۔.
- میں سے انتخاب کریں محفوظ کریں.
- ڈیٹا بیس کی منتقلی کے کام کی حیثیت کے بطور ظاہر ہونے کے لیے تقریباً 1 منٹ انتظار کریں۔ کے لئے تیار ہیں.
انکرپشن اور ڈکرپشن یا لیک فارمیشن کے لیے اجازتیں شامل کریں۔
اختیاری طور پر، آپ انکرپشن اور ڈکرپشن یا لیک فارمیشن کے لیے اجازتیں شامل کر سکتے ہیں۔
انکرپشن اور ڈکرپشن کی اجازتیں شامل کریں۔
اگر آپ کی خام اور اسٹیج پرتوں کے لیے استعمال ہونے والی S3 بالٹیاں استعمال کرتے ہوئے انکرپٹڈ ہیں۔ AWS کلیدی انتظام کی خدمت (AWS KMS) کسٹمر کے زیر انتظام کیز، آپ کو AWS Glue جاب کو ڈیٹا تک رسائی کی اجازت دینے کے لیے اجازتیں شامل کرنے کی ضرورت ہے:
جھیل کی تشکیل کی اجازتیں شامل کریں۔
اگر آپ لیک فارمیشن کا استعمال کرتے ہوئے اجازتوں کا انتظام کر رہے ہیں، تو آپ کو اپنے AWS Glue جاب کو IAM رول کے ذریعے اپنے ڈومین کے ڈیٹا بیس اور ٹیبلز بنانے کی اجازت دینی ہوگی۔ GlueJobRole.
- ڈیٹا بیس بنانے کی اجازت دیں (ہدایات کے لیے، رجوع کریں۔ ڈیٹا بیس بنانا).
- کو سپر اجازتیں دیں۔
defaultڈیٹا بیس - ڈیٹا لوکیشن کی اجازت دیں۔.
- اگر آپ دستی طور پر ڈیٹا بیس بناتے ہیں، تو میزیں بنانے کے لیے تمام ڈیٹا بیس پر اجازت دیں۔ کا حوالہ دیتے ہیں لیک فارمیشن کنسول اور نامزد وسائل کا طریقہ استعمال کرتے ہوئے ٹیبل کی اجازت دینا or LF-TBAC طریقہ استعمال کرتے ہوئے ڈیٹا کیٹلاگ کی اجازت دینا آپ کے استعمال کے معاملے کے مطابق۔
ابتدائی ڈیٹا لوڈ کرنے کے بعد کے مرحلے کو مکمل کرنے کے بعد، صارفین کو ٹیبلز سے استفسار کرنے کے لیے اجازتیں بھی شامل کرنا یقینی بنائیں۔ ملازمت کا کردار تخلیق کردہ تمام ٹیبلز کا مالک بن جائے گا، اور ڈیٹا لیک ایڈمن اس کے بعد اضافی صارفین کو گرانٹ دے سکتا ہے۔
پیرامیٹر اسٹور میں ٹیبل کنفیگریشن کا جائزہ لیں۔
AWS Glue جاب جو آئس برگ ٹیبلز میں ڈیٹا کے اندراج کو انجام دیتا ہے وہ پیرامیٹر اسٹور میں فراہم کردہ ٹیبل کی تفصیلات کا استعمال کرتا ہے۔ پیرامیٹر اسٹور کا جائزہ لینے کے لیے درج ذیل مراحل کو مکمل کریں جو آپ کے لیے خودکار طور پر ترتیب دیا گیا تھا۔ اگر ضرورت ہو تو اپنی ضرورت کے مطابق ترمیم کریں۔
- پیرامیٹر اسٹور کنسول پر، منتخب کریں۔ میرے پیرامیٹرز نیوی گیشن پین میں.
CloudFormation اسٹیک نے دو پیرامیٹرز بنائے:
iceberg-configکام کی ترتیب کے لئےiceberg-tablesٹیبل کی ترتیب کے لیے
- پیرامیٹر کا انتخاب کریں۔ آئس برگ کی میزیں.
JSON ڈھانچہ وہ معلومات پر مشتمل ہے جسے AWS Glue ڈیٹا کو پڑھنے اور ٹارگٹ ڈومین پر آئس برگ ٹیبل لکھنے کے لیے استعمال کرتا ہے:
- فی ٹیبل ایک چیز - آبجیکٹ کا نام اسکیما کے نام، مدت اور ٹیبل کے نام کا استعمال کرتے ہوئے بنایا گیا ہے۔ مثال کے طور پر،
schema.table. - بنیادی چابی - یہ ہر سورس ٹیبل کے لیے بیان کیا جانا چاہیے۔ آپ ایک کالم یا کالموں کی کوما سے الگ کردہ فہرست فراہم کر سکتے ہیں (اسپیس کے بغیر)۔
- پارٹیشن کولز - یہ اختیاری طور پر ٹارگٹ ٹیبلز کے لیے کالموں کو تقسیم کرتا ہے۔ اگر آپ تقسیم شدہ میزیں نہیں بنانا چاہتے ہیں، تو ایک خالی تار فراہم کریں۔ بصورت دیگر، استعمال کیے جانے والے کالموں کی ایک واحد کالم یا کوما سے الگ کردہ فہرست فراہم کریں (اسپیس کے بغیر)۔
- اگر آپ اپنا ڈیٹا ماخذ استعمال کرنا چاہتے ہیں تو درج ذیل JSON کوڈ کا استعمال کریں اور فراہم کردہ ٹیمپلیٹ سے CAPS میں متن کو تبدیل کریں۔ اگر آپ فراہم کردہ نمونہ ڈیٹا ماخذ استعمال کر رہے ہیں، تو پہلے سے طے شدہ ترتیبات کو برقرار رکھیں:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- میں سے انتخاب کریں تبدیلیاں محفوظ کرو.
ابتدائی ڈیٹا لوڈنگ انجام دیں۔
اب جب کہ مطلوبہ کنفیگریشن مکمل ہو گئی ہے، ہم ابتدائی ڈیٹا کو ہضم کر لیتے ہیں۔ اس مرحلے میں تین حصے شامل ہیں: ماخذ سے متعلق ڈیٹا بیس سے ڈیٹا کو ڈیٹا لیک کی خام پرت میں داخل کرنا، ڈیٹا لیک کی اسٹیج پرت پر آئس برگ ٹیبل بنانا، اور ایتھینا کا استعمال کرتے ہوئے نتائج کی تصدیق کرنا۔
ڈیٹا لیک کی خام پرت میں ڈیٹا داخل کریں۔
آئس برگ کا استعمال کرتے ہوئے متعلقہ ڈیٹا ماخذ (PostgreSQL اگر آپ فراہم کردہ نمونہ استعمال کر رہے ہیں) سے ڈیٹا کو ہماری ٹرانزیکشنل ڈیٹا لیک میں داخل کرنے کے لیے، درج ذیل مراحل کو مکمل کریں:
- AWS DMS کنسول پر، منتخب کریں۔ ڈیٹا بیس کی منتقلی کے کام نیوی گیشن پین میں.
- آپ نے جو نقل تیار کیا ہے اسے منتخب کریں اور پر عوامل مینو، منتخب کریں دوبارہ شروع/دوبارہ شروع کریں۔.
- نقل کا کام مکمل ہونے کے لیے تقریباً 5 منٹ انتظار کریں۔ آپ ٹیبلز کی نگرانی کر سکتے ہیں۔ اعداد و شمار نقل کے کام کا ٹیب۔

کچھ منٹوں کے بعد، کام پیغام کے ساتھ ختم ہو جاتا ہے۔ مکمل لوڈ مکمل.
- Amazon S3 کنسول پر، وہ بالٹی منتخب کریں جسے آپ نے خام پرت کے طور پر بیان کیا ہے۔
AWS DMS پر بیان کردہ S3 سابقہ کے تحت (مثال کے طور پر، postgres)، آپ کو درج ذیل ڈھانچے کے ساتھ فولڈرز کا درجہ بندی دیکھنا چاہئے:
- سکیم
- ٹیبل کا نام
LOAD00000001.parquetLOAD0000000N.parquet
- ٹیبل کا نام

اگر آپ کی S3 بالٹی خالی ہے تو جائزہ لیں۔ AWS ڈیٹا بیس مائیگریشن سروس میں منتقلی کے کاموں کا ازالہ کرنا AWS گلو کام چلانے سے پہلے۔
آئس برگ ٹیبلز میں ڈیٹا بنائیں اور داخل کریں۔
کام کو چلانے سے پہلے، آئیے اس کے رویے کو سمجھنے کے لیے CloudFormation اسٹیک کے حصے کے طور پر فراہم کردہ AWS Glue جاب کے اسکرپٹ کو دیکھیں۔
- AWS Glue Studio کنسول پر، منتخب کریں۔ نوکریاں نیوی گیشن پین میں.
- اس کام کی تلاش کریں جس سے شروع ہوتا ہے۔
IcebergJob-اور آپ کے CloudFormation اسٹیک نام کا لاحقہ (مثال کے طور پر،IcebergJob-transactionaldl-postgresql). - کام کا انتخاب کریں۔

جاب اسکرپٹ کو پیرامیٹر اسٹور سے مطلوبہ کنفیگریشن مل جاتی ہے۔ فنکشن getConfigFromSSM() جاب سے متعلق کنفیگریشنز کو واپس کرتا ہے جیسے سورس اور ٹارگٹ بکٹس جہاں سے ڈیٹا کو پڑھنے اور لکھنے کی ضرورت ہوتی ہے۔ متغیر ssmparam_table_values اس میں ٹیبل سے متعلق معلومات جیسے ڈیٹا ڈومین، ٹیبل کا نام، پارٹیشن کالم، اور ان ٹیبلز کی بنیادی کلید شامل ہوتی ہے جسے ہضم کرنے کی ضرورت ہوتی ہے۔ مندرجہ ذیل Python کوڈ دیکھیں:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']اسکرپٹ میں آئس برگ کے لیے ایک صوابدیدی کیٹلاگ کا نام استعمال کیا گیا ہے جسے my_catalog کے طور پر بیان کیا گیا ہے۔ یہ اسپارک کنفیگریشنز کا استعمال کرتے ہوئے AWS Glue Data Catalog پر لاگو کیا جاتا ہے، لہذا ڈیٹا کیٹلاگ پر my_catalog کی طرف اشارہ کرنے والا SQL آپریشن لاگو کیا جائے گا۔ درج ذیل کوڈ دیکھیں:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
اسکرپٹ پیرامیٹر اسٹور میں بیان کردہ جدولوں پر اعادہ کرتا ہے اور اس بات کا پتہ لگانے کے لیے منطق انجام دیتا ہے کہ آیا ٹیبل موجود ہے اور آیا آنے والا ڈیٹا ابتدائی بوجھ ہے یا اضافہ:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')۔ initialLoadRecordsSparkSQL() فنکشن ابتدائی ڈیٹا لوڈ کرتا ہے جب S3 فائلوں میں کوئی آپریشن کالم موجود نہیں ہوتا ہے۔ AWS DMS اس کالم کو صرف مسلسل نقل (CDC) کے ذریعے تیار کردہ Parquet ڈیٹا فائلوں میں شامل کرتا ہے۔ ڈیٹا کی لوڈنگ SparkSQL کے ساتھ INSERT INTO کمانڈ کا استعمال کرتے ہوئے کی جاتی ہے۔ درج ذیل کوڈ دیکھیں:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
اب ہم ابتدائی ڈیٹا کو آئس برگ ٹیبلز میں داخل کرنے کے لیے AWS Glue جاب چلاتے ہیں۔ CloudFormation اسٹیک شامل کرتا ہے۔ --datalake-formats پیرامیٹر، کام میں مطلوبہ آئس برگ لائبریریوں کو شامل کرنا۔
- میں سے انتخاب کریں نوکری چلائیں۔.
- میں سے انتخاب کریں کام چلتا ہے۔ حیثیت کی نگرانی کے لئے. اسٹیٹس ہونے تک انتظار کریں۔ رن کامیاب.
لوڈ کردہ ڈیٹا کی تصدیق کریں۔
اس بات کی تصدیق کرنے کے لیے کہ ملازمت نے توقع کے مطابق ڈیٹا پر کارروائی کی، درج ذیل مراحل کو مکمل کریں:
- ایتھینا کنسول پر، منتخب کریں۔ سوال ایڈیٹر نیوی گیشن پین میں.
- اس کی تصدیق کرلیں
AwsDataCatalogڈیٹا ماخذ کے طور پر منتخب کیا جاتا ہے۔ - کے تحت ڈیٹا بیس، اس ڈیٹا ڈومین کا انتخاب کریں جسے آپ پیرامیٹر اسٹور میں بیان کردہ کنفیگریشن کی بنیاد پر دریافت کرنا چاہتے ہیں۔ اگر فراہم کردہ نمونہ ڈیٹا بیس کا استعمال کرتے ہوئے، استعمال کریں
sports.
کے تحت میزیں اور نظارے۔، ہم ان میزوں کی فہرست دیکھ سکتے ہیں جو AWS Glue جاب کے ذریعہ بنائی گئی تھیں۔
- پہلے ٹیبل کے نام کے آگے اختیارات کے مینو (تین نقطوں) کو منتخب کریں، پھر منتخب کریں۔ ڈیٹا کا پیش نظارہ کریں۔.
آپ آئس برگ ٹیبلز میں بھری ہوئی ڈیٹا کو دیکھ سکتے ہیں۔ 
اضافی ڈیٹا لوڈنگ انجام دیں۔
اب ہم اپنے متعلقہ ڈیٹا بیس سے تبدیلیاں حاصل کرنا شروع کر دیتے ہیں اور انہیں ٹرانزیکشنل ڈیٹا لیک پر لاگو کرتے ہیں۔ اس مرحلے کو بھی تین حصوں میں تقسیم کیا گیا ہے: تبدیلیوں کو پکڑنا، انہیں آئس برگ ٹیبلز پر لاگو کرنا، اور نتائج کی تصدیق کرنا۔
متعلقہ ڈیٹا بیس سے تبدیلیاں کیپچر کریں۔
ہمارے بیان کردہ کنفیگریشن کی وجہ سے، مکمل بوجھ کے مرحلے کو چلانے کے بعد نقل کا کام رک گیا۔ اب ہم ڈیٹا لیک کی خام پرت میں تبدیلیوں کے ساتھ اضافی فائلوں کو شامل کرنے کا کام دوبارہ شروع کرتے ہیں۔
- AWS DMS کنسول پر، وہ ٹاسک منتخب کریں جسے ہم نے بنایا اور پہلے چلایا۔
- پر عوامل مینو، منتخب کریں پھر جاری.
- میں سے انتخاب کریں کام شروع کریں۔ تبدیلیوں کو پکڑنا شروع کرنے کے لیے۔
- ڈیٹا لیک پر نئی فائل تخلیق کو متحرک کرنے کے لیے، اپنے پسندیدہ ڈیٹا بیس ایڈمنسٹریشن ٹول کا استعمال کرتے ہوئے اپنے سورس ڈیٹا بیس کے ٹیبلز پر انسرٹس، اپ ڈیٹس یا ڈیلیٹ کریں۔ اگر فراہم کردہ نمونہ ڈیٹا بیس کا استعمال کرتے ہوئے، آپ درج ذیل SQL کمانڈز چلا سکتے ہیں:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- AWS DMS کام کی تفصیلات کے صفحہ پر، منتخب کریں۔ جدول کے اعدادوشمار کیپچر کی گئی تبدیلیوں کو دیکھنے کے لیے ٹیب۔

- ڈیٹا لیک کی کچی پرت کو کھولیں تاکہ ہر ٹیبل کے سابقہ کے اندر بڑھتی ہوئی تبدیلیوں کو رکھنے والی نئی فائل تلاش کریں، مثال کے طور پر
sporting_eventسابقہ
کے لئے تبدیلیوں کے ساتھ ریکارڈ sporting_event ٹیبل مندرجہ ذیل اسکرین شاٹ کی طرح لگتا ہے۔

نوٹس Op شروع میں کالم کی شناخت ایک اپ ڈیٹ کے ساتھ (U)۔ اس کے علاوہ، دوسری تاریخ/وقت کی قیمت AWS DMS کے ذریعے شامل کردہ کنٹرول کالم ہے جس وقت تبدیلی کی گئی تھی۔

AWS Glue کا استعمال کرتے ہوئے آئس برگ ٹیبلز پر تبدیلیاں لاگو کریں۔
اب ہم AWS Glue جاب کو دوبارہ چلاتے ہیں، اور یہ خود بخود صرف نئی انکریمنٹل فائلوں پر کارروائی کرے گا کیونکہ جاب بک مارک فعال ہے۔ آئیے جائزہ لیں کہ یہ کیسے کام کرتا ہے۔
۔ dedupCDCRecords() فنکشن ڈیٹا کی ڈپلیکیشن انجام دیتا ہے کیونکہ ایک ہی ریکارڈ ID میں متعدد تبدیلیاں ایمیزون S3 پر ایک ہی ڈیٹا فائل میں کیپچر کی جا سکتی ہیں۔ ڈپلیکیشن کی بنیاد پر انجام دیا جاتا ہے۔ last_update_time کالم AWS DMS کے ذریعہ شامل کیا گیا ہے جو اس ٹائم اسٹیمپ کی نشاندہی کرتا ہے جب تبدیلی کی گئی تھی۔ مندرجہ ذیل Python کوڈ دیکھیں:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFلائن 99 پر، upsertRecordsSparkSQL() فنکشن ابتدائی بوجھ کی طرح اپسرٹ کو انجام دیتا ہے، لیکن اس بار SQL MERGE کمانڈ کے ساتھ۔
لاگو تبدیلیوں کا جائزہ لیں۔
ایتھینا کنسول کھولیں اور ایک استفسار چلائیں جو سورس ڈیٹا بیس پر تبدیل شدہ ریکارڈز کو منتخب کرتا ہے۔ اگر فراہم کردہ نمونہ ڈیٹا بیس کا استعمال کر رہے ہیں، تو درج ذیل SQL سوالات میں سے ایک استعمال کریں:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

ٹیبل کے ادخال کی نگرانی کریں۔
AWS Glue جاب اسکرپٹ کو سادہ کے ساتھ کوڈ کیا گیا ہے۔ ازگر کی استثنا ہینڈلنگ ایک مخصوص ٹیبل پر کارروائی کے دوران غلطیوں کو پکڑنے کے لیے۔ ہر ٹیبل کی کامیابی کے ساتھ پروسیسنگ مکمل ہونے کے بعد جاب بُک مارک کو محفوظ کیا جاتا ہے، تاکہ ٹیبلز کو دوبارہ پروسیس کرنے سے بچنے کے لیے اگر جاب رن کی غلطیوں والی ٹیبلز کے لیے دوبارہ کوشش کی جاتی ہے۔
۔ AWS کمانڈ لائن انٹرفیس (AWS CLI) فراہم کرتا ہے a get-job-bookmark AWS Glue کے لیے کمانڈ جو پروسیس شدہ ہر ٹیبل کے لیے بک مارک کی حیثیت کی بصیرت فراہم کرتی ہے۔
- AWS Glue Studio کنسول پر، ETL جاب کا انتخاب کریں۔
- منتخب کیجئیے کام چلتا ہے۔ ٹیب کریں اور جاب رن آئی ڈی کاپی کریں۔
- AWS CLI کے لیے توثیق شدہ ٹرمینل پر درج ذیل کمانڈ کو چلائیں، تبدیل کریں۔
<GLUE_JOB_RUN_ID>لائن 1 پر اس قدر کے ساتھ جو آپ نے کاپی کی ہے۔ اگر آپ کے CloudFormation اسٹیک کا نام نہیں ہے۔transactionaldl-postgresql، اسکرپٹ کی لائن 2 پر اپنی ملازمت کا نام فراہم کریں:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunاس حل میں، جب ٹیبل پروسیسنگ ایک استثناء کا سبب بنتی ہے، تو AWS Glue جاب اس منطق کے مطابق ناکام نہیں ہوگا۔ اس کے بجائے، ٹیبل کو ایک صف میں شامل کیا جائے گا جو کام مکمل ہونے کے بعد پرنٹ کیا جاتا ہے۔ اس طرح کے منظر نامے میں، جاب کو ناکام کے بطور نشان زد کیا جائے گا جب یہ خام ڈیٹا سورس پر پائے جانے والے باقی ٹیبلز پر کارروائی کرنے کی کوشش کرے گا۔ اس طرح، غلطیوں کے بغیر ٹیبلز کو اس وقت تک انتظار نہیں کرنا پڑتا جب تک کہ صارف متضاد ٹیبلز پر مسئلہ کی شناخت اور حل نہ کر دے۔ صارف تیزی سے جاب رن کا پتہ لگا سکتا ہے جس میں AWS Glue جاب رن سٹیٹس کو استعمال کرتے ہوئے مسائل تھے، اور شناخت کر سکتے ہیں کہ کون سی مخصوص ٹیبلز جاب رن کے لیے CloudWatch لاگز کا استعمال کرتے ہوئے مسئلہ پیدا کر رہی ہیں۔
- جاب اسکرپٹ اس خصوصیت کو درج ذیل Python کوڈ کے ساتھ لاگو کرتا ہے:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')مندرجہ ذیل اسکرین شاٹ سے پتہ چلتا ہے کہ CloudWatch لاگ ان ٹیبلز کو کس طرح دیکھتے ہیں جو پروسیسنگ میں خرابیوں کا سبب بنتے ہیں۔

کے ساتھ منسلک AWS اچھی طرح سے تعمیر شدہ فریم ورک ڈیٹا اینالیٹک لینس طریقوں سے، آپ ڈیٹا پائپ لائنز پر غلطیاں ظاہر ہونے پر اسٹیک ہولڈرز کی شناخت اور مطلع کرنے کے لیے مزید جدید ترین کنٹرول میکانزم کو اپنا سکتے ہیں۔ مثال کے طور پر، آپ ایک استعمال کر سکتے ہیں ایمیزون ڈائنومو ڈی بی تمام میزیں ذخیرہ کرنے کے لئے کنٹرول ٹیبل اور کام غلطیوں کے ساتھ چلتا ہے، یا استعمال کرتے ہوئے ایمیزون سادہ نوٹیفکیشن سروس (ایمیزون ایس این ایس) سے آپریٹرز کو الرٹ بھیجیں۔ جب کچھ معیارات پورے ہوتے ہیں۔
انکریمنٹل بیچ ڈیٹا لوڈنگ کا شیڈول بنائیں
CloudFormation اسٹیک ایک تعینات کرتا ہے۔ ایمیزون ایونٹ برج اصول (بطور ڈیفالٹ غیر فعال) جو AWS Glue جاب کو شیڈول پر چلنے کے لیے متحرک کر سکتا ہے۔ اپنا شیڈول فراہم کرنے اور اصول کو فعال کرنے کے لیے، درج ذیل مراحل کو مکمل کریں:
- ایونٹ برج کنسول پر، منتخب کریں۔ قواعد نیوی گیشن پین میں.
- اپنے CloudFormation اسٹیک کے نام کے ساتھ پہلے سے لگا ہوا اصول تلاش کریں۔
JobTrigger(مثال کے طور پر،transactionaldl-postgresql-JobTrigger-randomvalue). - اصول کا انتخاب کریں۔
- کے تحت ایونٹ کے شیڈولمنتخب کریں ترمیم کریں.
ڈیفالٹ شیڈول ہر گھنٹے کو متحرک کرنے کے لیے ترتیب دیا گیا ہے۔
- وہ شیڈول فراہم کریں جسے آپ کام چلانا چاہتے ہیں۔
- اس کے علاوہ، آپ ایک استعمال کر سکتے ہیں ایونٹ برج کرون اظہار منتخب کرکے۔ ایک عمدہ شیڈول.

- جب آپ کرون ایکسپریشن سیٹ اپ مکمل کرلیں تو منتخب کریں۔ اگلے تین بار، اور آخر میں منتخب کریں اپڈیٹ رول تبدیلیوں کو بچانے کے لئے.
قاعدہ ڈیفالٹ کے ذریعے غیر فعال بنایا گیا ہے تاکہ آپ کو پہلے ڈیٹا لوڈ کرنے کی اجازت دی جا سکے۔
- منتخب کرکے اصول کو چالو کریں۔ فعال کریں.
آپ استعمال کر سکتے ہیں باخبر رہنا اصول کی درخواستیں دیکھنے کے لیے ٹیب، یا براہ راست AWS Glue پر جاب رن تفصیلات
نتیجہ
اس حل کو متعین کرنے کے بعد، آپ نے اپنے جدولوں کے ادخال کو ایک ہی متعلقہ ڈیٹا سورس پر خودکار کر دیا ہے۔ ڈیٹا لیک کو اپنے مرکزی ڈیٹا پلیٹ فارم کے طور پر استعمال کرنے والی تنظیموں کو عام طور پر ایک سے زیادہ، بعض اوقات دسیوں ڈیٹا ذرائع کو ہینڈل کرنے کی ضرورت ہوتی ہے۔ نیز، زیادہ سے زیادہ استعمال کے معاملات میں تنظیموں کو ڈیٹا لیک میں لین دین کی صلاحیتوں کو نافذ کرنے کی ضرورت ہوتی ہے۔ آپ اس حل کا استعمال اپنے تمام متعلقہ ڈیٹا ذرائع میں اس طرح کی صلاحیتوں کو اپنانے کو تیز کرنے کے لیے استعمال کر سکتے ہیں تاکہ آپ کے ڈیٹا سے مزید قدر حاصل کرنے کے لیے عمل درآمد کے عمل کو خودکار بنا کر کاروباری استعمال کے نئے معاملات کو قابل بنایا جا سکے۔
مصنفین کے بارے میں
 لوئس جیرارڈو بیزا ایمیزون ویب سروسز (AWS) ڈیٹا لیب میں ایک بڑا ڈیٹا آرکیٹیکٹ ہے۔ اس کے پاس صحت کی دیکھ بھال، مالیاتی اور تعلیم کے شعبوں میں اداروں کو انٹرپرائز آرکیٹیکچر پروگرام، کلاؤڈ کمپیوٹنگ، اور ڈیٹا اینالیٹکس کی صلاحیتوں کو اپنانے میں مدد کرنے کا 12 سال کا تجربہ ہے۔ Luis فی الحال لاطینی امریکہ میں تنظیموں کو اسٹریٹجک ڈیٹا کے اقدامات کو تیز کرنے میں مدد کرتا ہے۔
لوئس جیرارڈو بیزا ایمیزون ویب سروسز (AWS) ڈیٹا لیب میں ایک بڑا ڈیٹا آرکیٹیکٹ ہے۔ اس کے پاس صحت کی دیکھ بھال، مالیاتی اور تعلیم کے شعبوں میں اداروں کو انٹرپرائز آرکیٹیکچر پروگرام، کلاؤڈ کمپیوٹنگ، اور ڈیٹا اینالیٹکس کی صلاحیتوں کو اپنانے میں مدد کرنے کا 12 سال کا تجربہ ہے۔ Luis فی الحال لاطینی امریکہ میں تنظیموں کو اسٹریٹجک ڈیٹا کے اقدامات کو تیز کرنے میں مدد کرتا ہے۔
 سائی کرن ریڈی اینوگو ایمیزون ویب سروسز (AWS) ڈیٹا لیب میں ڈیٹا آرکیٹیکٹ ہے۔ اس کے پاس ڈیٹا لوڈنگ، ٹرانسفارمیشن، اور ویژولائزیشن کے عمل کو نافذ کرنے کا 10 سال کا تجربہ ہے۔ سائی کرن فی الحال شمالی امریکہ میں تنظیموں کو ڈیٹا لیکس اور ڈیٹا میش جیسے جدید ڈیٹا فن تعمیر کو اپنانے میں مدد کرتا ہے۔ ان کے پاس ریٹیل، ایئر لائن اور فنانس کے شعبوں میں تجربہ ہے۔
سائی کرن ریڈی اینوگو ایمیزون ویب سروسز (AWS) ڈیٹا لیب میں ڈیٹا آرکیٹیکٹ ہے۔ اس کے پاس ڈیٹا لوڈنگ، ٹرانسفارمیشن، اور ویژولائزیشن کے عمل کو نافذ کرنے کا 10 سال کا تجربہ ہے۔ سائی کرن فی الحال شمالی امریکہ میں تنظیموں کو ڈیٹا لیکس اور ڈیٹا میش جیسے جدید ڈیٹا فن تعمیر کو اپنانے میں مدد کرتا ہے۔ ان کے پاس ریٹیل، ایئر لائن اور فنانس کے شعبوں میں تجربہ ہے۔
 نریندر مرلا ایمیزون ویب سروسز (AWS) ڈیٹا لیب میں ڈیٹا آرکیٹیکٹ ہے۔ اس کے پاس ریئل ٹائم اور بیچ پر مبنی ڈیٹا پائپ لائنوں کو ڈیزائن اور پروڈکشنلائز کرنے اور کلاؤڈ اور آن پریمیسس دونوں ماحول پر ڈیٹا لیکس بنانے کا 12 سال کا تجربہ ہے۔ نریندر فی الحال شمالی امریکہ میں تنظیموں کو مضبوط ڈیٹا آرکیٹیکچر بنانے اور ڈیزائن کرنے میں مدد کرتا ہے، اور ٹیلی کام اور فنانس کے شعبوں میں تجربہ رکھتا ہے۔
نریندر مرلا ایمیزون ویب سروسز (AWS) ڈیٹا لیب میں ڈیٹا آرکیٹیکٹ ہے۔ اس کے پاس ریئل ٹائم اور بیچ پر مبنی ڈیٹا پائپ لائنوں کو ڈیزائن اور پروڈکشنلائز کرنے اور کلاؤڈ اور آن پریمیسس دونوں ماحول پر ڈیٹا لیکس بنانے کا 12 سال کا تجربہ ہے۔ نریندر فی الحال شمالی امریکہ میں تنظیموں کو مضبوط ڈیٹا آرکیٹیکچر بنانے اور ڈیزائن کرنے میں مدد کرتا ہے، اور ٹیلی کام اور فنانس کے شعبوں میں تجربہ رکھتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- ہمارے بارے میں
- رفتار کو تیز تر
- تک رسائی حاصل
- کے مطابق
- تسلیم کرتے ہیں
- کے پار
- اپنانے
- شامل کیا
- ایڈیشنل
- اس کے علاوہ
- جوڑتا ہے
- منتظم
- انتظامیہ
- اپنانے
- منہ بولابیٹا بنانے
- کے بعد
- ایئر لائن
- تمام
- پہلے ہی
- ایمیزون
- ایمیزون ایتینا
- ایمیزون آر ڈی ایس
- ایمیزون ویب سروسز
- ایمیزون ویب سروسز (AWS)
- امریکہ
- تجزیہ
- تجزیاتی
- اور
- اینجلس
- اپاچی
- ظاہر
- درخواست
- اطلاقی
- درخواست دینا
- نقطہ نظر
- تقریبا
- فن تعمیر
- لڑی
- منسلک
- تصدیق شدہ
- خود کار طریقے سے
- آٹومیٹڈ
- خود کار طریقے سے
- خودکار
- اوسط
- سے اجتناب
- AWS
- AWS کلاؤڈ فارمیشن
- AWS گلو
- کی بنیاد پر
- بٹس
- کیونکہ
- بن
- اس سے پہلے
- شروع
- بگ
- بگ ڈیٹا
- تعمیر
- بلڈر
- عمارت
- کاروبار
- حاصل کر سکتے ہیں
- صلاحیتوں
- کیپ
- قبضہ
- گرفتاری
- کیس
- مقدمات
- کیٹلوگ
- پکڑو
- کیونکہ
- وجوہات
- باعث
- سی ڈی سی
- مرکزی
- کچھ
- تبدیل
- تبدیلیاں
- انتخاب
- میں سے انتخاب کریں
- منتخب کریں
- منتخب کیا
- بادل
- کلاؤڈ کمپیوٹنگ
- کوڈ
- کالم
- کالم
- کمپنی کے
- مکمل
- کمپیوٹنگ
- ترتیب
- ترتیب
- کی توثیق
- متضاد
- رابطہ قائم کریں
- کنکشن
- خیالات
- کنسول
- صارفین
- کھپت
- پر مشتمل ہے
- جاری
- مسلسل
- کنٹرول
- سکتا ہے
- تخلیق
- بنائی
- پیدا
- تخلیق
- مخلوق
- معیار
- اس وقت
- اپنی مرضی کے
- گاہک
- اپنی مرضی کے مطابق
- اعداد و شمار
- ڈیٹا تجزیات
- ڈیٹا لیک
- ڈیٹا پلیٹ فارم
- ڈیٹا بیس
- ڈیٹا بیس
- تاریخ
- پہلے سے طے شدہ
- کی وضاحت
- تعیناتی
- تعینات
- تعینات
- تعیناتی
- تعینات کرتا ہے
- ڈیزائن
- ڈیزائن
- ڈیزائننگ
- تفصیلات
- پتہ چلا
- ترقی
- مختلف
- براہ راست
- غیر فعال کر دیا
- تقسیم
- نہیں کرتا
- ڈومین
- ڈومینز
- نہیں
- کے دوران
- ہر ایک
- اس سے قبل
- آسانی سے
- تعلیم
- کوشش
- یا تو
- کو چالو کرنے کے
- چالو حالت میں
- خفیہ کردہ
- خفیہ کاری
- اختتام پوائنٹ
- انجن
- درج
- انٹرپرائز
- ماحول
- نقائص
- Ether (ETH)
- بھی
- ہر کوئی
- مثال کے طور پر
- سے تجاوز
- اس کے علاوہ
- رعایت
- موجودہ
- موجود ہے
- توقع
- امید ہے
- تجربہ
- تلاش
- ملانے
- نکالنے
- ناکام
- واقف
- فیشن
- نمایاں کریں
- چند
- فائل
- فائلوں
- آخر
- کی مالی اعانت
- مالی
- مل
- ختم
- پہلا
- پیچھے پیچھے
- کے بعد
- صارفین کے لئے
- فارم
- قیام
- فریم ورک
- سے
- مکمل
- تقریب
- پیدا
- نسل
- حاصل
- عطا
- گرانٹ
- بڑھتے ہوئے
- ہینڈل
- صحت کی دیکھ بھال
- مدد
- مدد کرتا ہے
- درجہ بندی
- تاریخ
- انعقاد
- کس طرح
- کیسے
- HTML
- HTTPS
- بھاری
- IAM
- کی نشاندہی
- شناخت
- شناخت
- شناخت
- پر عملدرآمد
- نفاذ
- عملدرآمد
- پر عمل درآمد
- عمل
- بہتری
- in
- شامل
- شامل ہیں
- سمیت
- موصولہ
- اشارہ کرتا ہے
- انفرادی
- معلومات
- ابتدائی
- اقدامات
- داخل کرتا ہے
- بصیرت
- مثال کے طور پر
- کے بجائے
- ہدایات
- انٹرمیڈیٹ
- مسئلہ
- مسائل
- IT
- تکرار
- ایوب
- نوکریاں
- JSON
- رکھیں
- کلیدی
- چابیاں
- جان
- لیب
- جھیل
- لاطینی
- لاطینی امریکہ
- پرت
- تہوں
- قیادت
- جانیں
- لائبریریوں
- LIMIT
- لائن
- لسٹ
- لوڈ
- لوڈ کر رہا ہے
- بوجھ
- محل وقوع
- دیکھو
- دیکھنا
- ان
- لاس اینجلس
- بہت
- مین
- برقرار رکھتا ہے
- بنا
- میں کامیاب
- انتظام
- مینیجر
- مینیجنگ
- دستی طور پر
- بہت سے
- تعریفیں
- نشان لگا دیا گیا
- مینو
- ضم کریں
- پیغام
- شاید
- منتقلی
- کم سے کم
- منٹ
- منٹ
- جدید
- نظر ثانی کرنے
- کی نگرانی
- نگرانی
- زیادہ
- سب سے زیادہ
- سب سے زیادہ مقبول
- ایک سے زیادہ
- نام
- نامزد
- نام
- تشریف لے جائیں
- سمت شناسی
- ضرورت ہے
- ضرورت
- ضروریات
- نئی
- اگلے
- شمالی
- شمالی امریکہ
- نوٹیفیکیشن
- تعداد
- اعتراض
- اشیاء
- ایک
- جاری
- OP
- آپریشن
- اصلاح
- آپشنز کے بھی
- تنظیمی
- تنظیمیں
- منظم
- اصل
- دوسری صورت میں
- باہر
- خود
- مالک
- پین
- پیرامیٹر
- پیرامیٹرز
- حصہ
- حصے
- راستہ
- پاٹرن
- انجام دینے کے
- کارکردگی کا مظاہرہ
- کارکردگی کا مظاہرہ
- مدت
- اجازتیں
- مرحلہ
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- مقبول
- پوسٹ
- پوسٹگریسقیل
- طریقوں
- کو ترجیح دی
- ضروریات
- حال (-)
- پرائمری
- مسئلہ
- عمل
- عمل
- پروسیسنگ
- تیار
- پروگرام
- فراہم
- فراہم
- فراہم کرتا ہے
- ازگر
- جلدی سے
- بلند
- شرح
- خام
- خام ڈیٹا
- پڑھیں
- اصل وقت
- ریکارڈ
- ریکارڈ
- کی جگہ
- نقل تیار
- نقل
- کی ضرورت
- ضرورت
- وسائل
- وسائل
- باقی
- نتائج کی نمائش
- خوردہ
- واپسی
- واپسی
- کا جائزہ لینے کے
- مضبوط
- کردار
- حکمرانی
- قوانین
- رن
- چل رہا ہے
- اسی
- محفوظ کریں
- منظر نامے
- شیڈول
- گنجائش
- سکرپٹ
- تلاش کریں
- دوسری
- سیکٹر
- دیکھ کر
- منتخب
- منتخب
- انتخاب
- علیحدہ
- سروسز
- مقرر
- قائم کرنے
- ترتیبات
- ہونا چاہئے
- دکھائیں
- شوز
- اسی طرح
- سادہ
- بعد
- ایک
- So
- حل
- حل کرتا ہے
- کچھ
- بہتر
- ماخذ
- ذرائع
- خالی جگہیں
- چنگاری
- مخصوص
- تصریح
- مخصوص
- اسپورٹس
- SQL
- ڈھیر لگانا
- Stacks
- اسٹیج
- اسٹیک ہولڈرز
- شروع کریں
- شروع
- شروع
- شروع ہوتا ہے
- امریکہ
- کے اعداد و شمار
- درجہ
- مرحلہ
- مراحل
- بند کر دیا
- ذخیرہ
- ذخیرہ
- ذخیرہ
- پردہ
- حکمت عملی
- ساخت
- منظم
- سٹوڈیو
- کامیابی کے ساتھ
- اس طرح
- سپر
- حمایت
- سسٹمز
- ٹیبل
- ہدف
- ٹاسک
- کاموں
- ٹیم
- ٹیموں
- ٹیلی کام
- سانچے
- ٹرمنل
- ۔
- ماخذ
- ان
- ہزاروں
- تین
- کے ذریعے
- وقت
- ٹائم لائن
- اوقات
- ٹائمسٹیمپ
- کرنے کے لئے
- کے آلے
- سب سے اوپر
- کل
- ٹریکنگ
- روایتی
- لین دین
- تبدیل
- تبدیلی
- ٹرگر
- سبق
- اقسام
- کے تحت
- سمجھ
- منفرد
- اپ ڈیٹ کریں
- تازہ ترین معلومات
- استعمال کی شرائط
- استعمال کیس
- رکن کا
- صارفین
- عام طور پر
- قیمت
- تصدیق کرنا
- لنک
- تصور
- حجم
- انتظار
- گودام
- ویب
- ویب خدمات
- جس
- گے
- کے اندر
- بغیر
- کام کرتا ہے
- لکھنا
- لکھا
- یامل
- سال
- سال
- اور
- زیفیرنیٹ