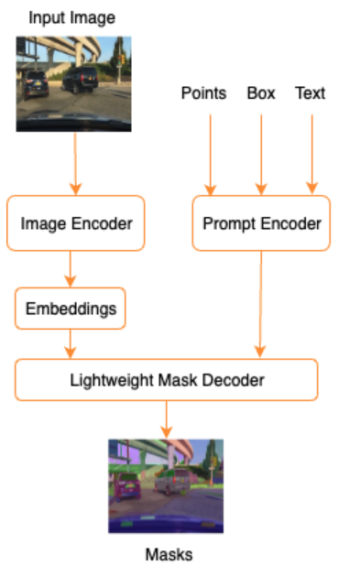
ایمیزون سیج میکر ایک مکمل طور پر منظم مشین لرننگ (ML) سروس ہے۔ SageMaker کے ساتھ، ڈیٹا سائنسدان اور ڈویلپرز ایم ایل ماڈلز کو تیزی سے اور آسانی سے تیار اور تربیت دے سکتے ہیں، اور پھر انہیں براہ راست پیداوار کے لیے تیار میزبان ماحول میں تعینات کر سکتے ہیں۔ یہ تلاش اور تجزیہ کے لیے آپ کے ڈیٹا کے ذرائع تک آسان رسائی کے لیے ایک مربوط Jupyter تصنیف کردہ نوٹ بک مثال فراہم کرتا ہے، لہذا آپ کو سرورز کا انتظام کرنے کی ضرورت نہیں ہے۔ یہ عام بھی فراہم کرتا ہے۔ ایم ایل الگورتھم جو تقسیم شدہ ماحول میں انتہائی بڑے ڈیٹا کے خلاف موثر انداز میں چلانے کے لیے موزوں ہیں۔
سیج میکر ریئل ٹائم انفرنس کام کے بوجھ کے لیے مثالی ہے جن میں ریئل ٹائم، انٹرایکٹو، کم تاخیر کی ضرورت ہوتی ہے۔ SageMaker ریئل ٹائم انفرنس کے ساتھ، آپ REST اینڈ پوائنٹس کو تعینات کر سکتے ہیں جن کی حمایت ایک مخصوص مثال کی قسم کے ساتھ کمپیوٹ اور میموری کی ایک خاص مقدار کے ساتھ ہوتی ہے۔ سیج میکر ریئل ٹائم اینڈ پوائنٹ کو تعینات کرنا بہت سے صارفین کے لیے پروڈکشن کی راہ میں صرف پہلا قدم ہے۔ ہم تاخیر کے تقاضوں پر عمل کرتے ہوئے فی سیکنڈ ٹارگٹ ٹرانزیکشنز (TPS) حاصل کرنے کے لیے اینڈ پوائنٹ کی کارکردگی کو زیادہ سے زیادہ کرنے کے قابل ہونا چاہتے ہیں۔ تخمینہ کے لیے کارکردگی کی اصلاح کا ایک بڑا حصہ اس بات کو یقینی بنا رہا ہے کہ آپ مناسب مثال کی قسم کا انتخاب کریں اور اختتامی نقطہ کو واپس کرنے کے لیے شمار کریں۔
یہ پوسٹ سیج میکر اینڈ پوائنٹ کو لوڈ کرنے کے بہترین طریقوں کی وضاحت کرتی ہے تاکہ مثالوں کی تعداد اور سائز کے لیے صحیح ترتیب تلاش کی جا سکے۔ یہ ہماری تاخیر اور TPS کی ضروریات کو پورا کرنے کے لیے کم سے کم فراہم کردہ مثال کے تقاضوں کو سمجھنے میں ہماری مدد کر سکتا ہے۔ وہاں سے، ہم اس بات پر غور کرتے ہیں کہ آپ SageMaker اینڈ پوائنٹ کے استعمال کے میٹرکس اور کارکردگی کو کیسے ٹریک اور سمجھ سکتے ہیں۔ ایمیزون کلاؤڈ واچ میٹرکس۔
ہم سب سے پہلے اپنے ماڈل کی کارکردگی کو کسی ایک مثال پر بینچ مارک کرتے ہیں تاکہ اس TPS کی شناخت کی جا سکے جو یہ ہماری قابل قبول تاخیر کی ضروریات کے مطابق سنبھال سکتا ہے۔ اس کے بعد ہم اپنے پروڈکشن ٹریفک کو سنبھالنے کے لیے مطلوبہ مثالوں کی تعداد پر فیصلہ کرنے کے لیے نتائج کو نکالتے ہیں۔ آخر میں، ہم پروڈکشن لیول ٹریفک کی نقل کرتے ہیں اور ریئل ٹائم سیج میکر اینڈ پوائنٹ کے لیے لوڈ ٹیسٹ ترتیب دیتے ہیں تاکہ اس بات کی تصدیق کی جا سکے کہ ہمارا اینڈ پوائنٹ پروڈکشن لیول کے بوجھ کو سنبھال سکتا ہے۔ مثال کے لیے کوڈ کا پورا سیٹ درج ذیل میں دستیاب ہے۔ GitHub ذخیرہ.
حل کا جائزہ
اس پوسٹ کے لیے، ہم پہلے سے تربیت یافتہ کو تعینات کرتے ہیں۔ گلے لگانا چہرہ DistilBERT ماڈل سے گلے لگانا چہرہ حب. یہ ماڈل متعدد کام انجام دے سکتا ہے، لیکن ہم خاص طور پر جذبات کے تجزیہ اور متن کی درجہ بندی کے لیے ایک پے لوڈ بھیجتے ہیں۔ اس نمونہ پے لوڈ کے ساتھ، ہم 1000 TPS حاصل کرنے کی کوشش کرتے ہیں۔
ایک ریئل ٹائم اینڈ پوائنٹ تعینات کریں۔
یہ پوسٹ فرض کرتی ہے کہ آپ ماڈل کو تعینات کرنے کے طریقہ سے واقف ہیں۔ کا حوالہ دیتے ہیں اپنا اختتامی نقطہ بنائیں اور اپنا ماڈل متعین کریں۔ اختتامی نقطہ کی میزبانی کے پیچھے اندرونی چیزوں کو سمجھنے کے لئے۔ ابھی کے لیے، ہم فوری طور پر Hugging Face Hub میں اس ماڈل کی طرف اشارہ کر سکتے ہیں اور درج ذیل کوڈ کے ٹکڑوں کے ساتھ ایک حقیقی وقت کا اختتامی نقطہ تعینات کر سکتے ہیں:
آئیے اپنے اختتامی نقطہ کو نمونے کے پے لوڈ کے ساتھ جانچتے ہیں جسے ہم لوڈ ٹیسٹنگ کے لیے استعمال کرنا چاہتے ہیں:

نوٹ کریں کہ ہم ایک واحد کا استعمال کرتے ہوئے اختتامی نقطہ کی حمایت کر رہے ہیں۔ ایمیزون لچکدار کمپیوٹ کلاؤڈ (Amazon EC2) ml.m5.12xlarge قسم کی مثال، جس میں 48 vCPU اور 192 GiB میموری ہے۔ vCPUs کی تعداد ہم آہنگی کا ایک اچھا اشارہ ہے جو مثال کو سنبھال سکتی ہے۔ عام طور پر، اس بات کو یقینی بنانے کے لیے مختلف مثالوں کی اقسام کو جانچنے کی سفارش کی جاتی ہے کہ ہمارے پاس کوئی ایسی مثال موجود ہے جس کا صحیح استعمال کیا گیا ہو۔ سیج میکر مثالوں کی مکمل فہرست اور ان کے متعلقہ کمپیوٹ پاور کو ریئل ٹائم انفرنس کے لیے دیکھیں۔ ایمیزون سیج میکر قیمتوں کا تعین.
ٹریک کرنے کے لیے میٹرکس
اس سے پہلے کہ ہم لوڈ ٹیسٹنگ میں شامل ہو جائیں، یہ سمجھنا ضروری ہے کہ آپ کے SageMaker اینڈ پوائنٹ کی کارکردگی کی خرابی کو سمجھنے کے لیے کن میٹرکس کو ٹریک کرنا ہے۔ CloudWatch ایک بنیادی لاگنگ ٹول ہے جسے SageMaker استعمال کرتا ہے تاکہ آپ کو مختلف میٹرکس کو سمجھنے میں مدد ملے جو آپ کے اختتامی نقطہ کی کارکردگی کو بیان کرتے ہیں۔ آپ اپنے اختتامی نقطہ کی درخواستوں کو ڈیبگ کرنے کے لیے CloudWatch لاگز کا استعمال کر سکتے ہیں۔ تمام لاگنگ اور پرنٹ اسٹیٹمنٹس جو آپ کے انفرنس کوڈ میں موجود ہیں وہ یہاں کیپچر کیے گئے ہیں۔ مزید معلومات کے لیے رجوع کریں۔ ایمیزون کلاؤڈ واچ کیسے کام کرتا ہے۔.
سیج میکر کے لیے دو مختلف قسم کے میٹرکس کلاؤڈ واچ کا احاطہ کرتا ہے: مثال کی سطح اور انووکیشن میٹرکس۔
مثال کی سطح کے میٹرکس
پیرامیٹرز کا پہلا سیٹ جس پر غور کرنا ہے وہ ہے مثال کی سطح کے میٹرکس: CPUUtilization اور MemoryUtilization (GPU پر مبنی مثالوں کے لیے، GPUUtilization). کے لئے CPUUtilization، آپ CloudWatch میں پہلے 100% سے زیادہ فیصد دیکھ سکتے ہیں۔ اس کا احساس کرنا ضروری ہے۔ CPUUtilization، تمام CPU کور کا مجموعہ دکھایا جا رہا ہے۔ مثال کے طور پر، اگر آپ کے اختتامی نقطہ کے پیچھے کی مثال 4 vCPUs پر مشتمل ہے، تو اس کا مطلب ہے کہ استعمال کی حد 400% تک ہے۔ MemoryUtilizationدوسری طرف، 0-100% کی حد میں ہے۔
خاص طور پر، آپ استعمال کر سکتے ہیں CPUUtilization اس بات کی گہرائی سے سمجھ حاصل کرنے کے لیے کہ آیا آپ کے پاس ہارڈ ویئر کی کافی یا اس سے زیادہ مقدار ہے۔ اگر آپ کے پاس کم استعمال شدہ مثال ہے (30% سے کم)، تو آپ ممکنہ طور پر اپنی مثال کی قسم کو کم کر سکتے ہیں۔ اس کے برعکس، اگر آپ کا استعمال تقریباً 80-90% ہے، تو زیادہ کمپیوٹ/میموری کے ساتھ مثال لینے کا فائدہ ہوگا۔ ہمارے ٹیسٹوں سے، ہم آپ کے ہارڈ ویئر کے تقریباً 60-70% استعمال کی تجویز کرتے ہیں۔
انووکیشن میٹرکس
جیسا کہ نام سے تجویز کیا گیا ہے، انووکیشن میٹرکس وہ ہے جہاں ہم آپ کے اختتامی نقطہ پر کسی بھی درخواست کے اختتام سے آخر میں تاخیر کو ٹریک کرسکتے ہیں۔ آپ غلطی کی گنتی اور کس قسم کی خرابیاں (5xx، 4xx، اور اسی طرح) کیپچر کرنے کے لیے درخواست کے میٹرکس کا استعمال کر سکتے ہیں جن کا آپ کے اختتامی نقطہ کو سامنا ہو سکتا ہے۔ زیادہ اہم بات یہ ہے کہ، آپ اپنی اینڈ پوائنٹ کالز کے لیٹنسی بریک ڈاؤن کو سمجھ سکتے ہیں۔ اس سے بہت کچھ پکڑا جا سکتا ہے۔ ModelLatency اور OverheadLatency میٹرکس، جیسا کہ مندرجہ ذیل خاکہ میں دکھایا گیا ہے۔

۔ ModelLatency میٹرک سیج میکر اینڈ پوائنٹ کے پیچھے ماڈل کنٹینر میں لگنے والے وقت کو پکڑتا ہے۔ نوٹ کریں کہ ماڈل کنٹینر میں کوئی بھی حسب ضرورت قیاس کوڈ یا اسکرپٹس بھی شامل ہیں جو آپ نے تخمینہ کے لیے پاس کیے ہیں۔ اس یونٹ کو مائیکرو سیکنڈز میں انووکیشن میٹرک کے طور پر کیپچر کیا جاتا ہے، اور عام طور پر آپ کلاؤڈ واچ (p99، p90، اور اسی طرح) پر پرسنٹائل گراف کر سکتے ہیں تاکہ یہ معلوم ہو سکے کہ آیا آپ اپنے ہدف میں تاخیر کو پورا کر رہے ہیں۔ نوٹ کریں کہ کئی عوامل ماڈل اور کنٹینر کی تاخیر کو متاثر کر سکتے ہیں، جیسے کہ درج ذیل:
- حسب ضرورت انفرنس اسکرپٹ - چاہے آپ نے اپنا اپنا کنٹینر لاگو کیا ہو یا حسب ضرورت انفرنس ہینڈلرز کے ساتھ SageMaker پر مبنی کنٹینر استعمال کیا ہو، یہ بہترین عمل ہے کہ آپ اپنی اسکرپٹ کو کسی ایسے آپریشن کو پکڑنے کے لیے پروفائل کریں جو خاص طور پر آپ کی تاخیر میں بہت زیادہ وقت ڈال رہے ہوں۔
- مواصلات کا پروٹوکول - ماڈل کنٹینر کے اندر ماڈل سرور سے REST بمقابلہ gRPC کنکشن پر غور کریں۔
- ماڈل فریم ورک کی اصلاح - یہ مخصوص فریم ورک ہے، مثال کے طور پر کے ساتھ TensorFlow، بہت سے ماحولیاتی متغیرات ہیں جو آپ ٹیون کر سکتے ہیں جو TF سرونگ مخصوص ہیں۔ اس بات کو یقینی بنائیں کہ آپ کون سا کنٹینر استعمال کر رہے ہیں اور اگر کوئی فریم ورک کے لیے مخصوص آپٹمائزیشنز ہیں تو آپ اسکرپٹ کے اندر یا کنٹینر میں انجیکشن لگانے کے لیے ماحولیاتی متغیرات کے طور پر شامل کر سکتے ہیں۔
OverheadLatency SageMaker کو درخواست موصول ہونے کے وقت سے ماپا جاتا ہے جب تک کہ وہ کلائنٹ کو جواب نہیں دیتا، مائنس ماڈل لیٹنسی۔ یہ حصہ بڑی حد تک آپ کے کنٹرول سے باہر ہے اور SageMaker اوور ہیڈز کی طرف سے لگنے والے وقت کے تحت آتا ہے۔
آخر سے آخر تک تاخیر کا انحصار مجموعی طور پر مختلف عوامل پر ہوتا ہے اور ضروری نہیں کہ اس کا مجموعہ ہو ModelLatency علاوہ OverheadLatency. مثال کے طور پر، اگر آپ کا کلائنٹ بنا رہا ہے۔ InvokeEndpoint انٹرنیٹ پر API کال، کلائنٹ کے نقطہ نظر سے، آخر سے آخر میں تاخیر انٹرنیٹ ہوگی + ModelLatency + OverheadLatency. اس طرح، جب آپ اینڈ پوائنٹ کو درست طریقے سے بینچ مارک کرنے کے لیے اپنے اینڈ پوائنٹ کی جانچ کرتے ہیں، تو یہ تجویز کیا جاتا ہے کہ اختتامی نقطہ میٹرکس (ModelLatency, OverheadLatency، اور InvocationsPerInstanceSageMaker اینڈ پوائنٹ کو درست طریقے سے بینچ مارک کرنے کے لیے۔ آخر سے آخر تک تاخیر سے متعلق کوئی بھی مسئلہ پھر الگ الگ کیا جا سکتا ہے۔
آخر سے آخر تک تاخیر کے لیے غور کرنے کے لیے چند سوالات:
- وہ کلائنٹ کہاں ہے جو آپ کے اختتامی نقطہ کی درخواست کر رہا ہے؟
- کیا آپ کے کلائنٹ اور SageMaker رن ٹائم کے درمیان کوئی درمیانی پرتیں ہیں؟
آٹو اسکیلنگ
ہم خاص طور پر اس پوسٹ میں آٹو اسکیلنگ کا احاطہ نہیں کرتے ہیں، لیکن کام کے بوجھ کی بنیاد پر مثالوں کی صحیح تعداد فراہم کرنے کے لیے یہ ایک اہم غور طلب ہے۔ آپ کے ٹریفک کے نمونوں پر منحصر ہے، آپ ایک منسلک کر سکتے ہیں۔ آٹو اسکیلنگ کی پالیسی آپ کے سیج میکر کے اختتامی نقطہ پر۔ اسکیلنگ کے مختلف اختیارات ہیں، جیسے TargetTrackingScaling, SimpleScaling، اور StepScaling. یہ آپ کے اختتامی نقطہ کو آپ کے ٹریفک پیٹرن کی بنیاد پر خود بخود اندر اور باہر کرنے کی اجازت دیتا ہے۔
ایک عام آپشن ٹارگٹ ٹریکنگ ہے، جہاں آپ CloudWatch میٹرک یا کسٹم میٹرک کی وضاحت کر سکتے ہیں جس کی آپ نے وضاحت کی ہے اور اس کی بنیاد پر اسکیل آؤٹ کر سکتے ہیں۔ آٹو اسکیلنگ کا بار بار استعمال ٹریکنگ کر رہا ہے۔ InvocationsPerInstance میٹرک کسی مخصوص TPS میں رکاوٹ کی نشاندہی کرنے کے بعد، آپ اکثر اس کو میٹرک کے طور پر استعمال کر سکتے ہیں تاکہ زیادہ سے زیادہ تعداد میں ٹریفک کے بوجھ کو سنبھالنے کے قابل ہو سکے۔ آٹو اسکیلنگ SageMaker اینڈ پوائنٹس کی گہرائی میں خرابی حاصل کرنے کے لیے، رجوع کریں۔ ایمیزون سیج میکر میں آٹو اسکیلنگ انفرنس اینڈ پوائنٹس کو ترتیب دینا.
لوڈ ٹیسٹنگ
اگرچہ ہم Locust کو یہ ظاہر کرنے کے لیے استعمال کرتے ہیں کہ ہم کس طرح پیمانے پر ٹیسٹ لوڈ کر سکتے ہیں، اگر آپ اپنے اختتامی نقطہ کے پیچھے مثال کو درست کرنے کی کوشش کر رہے ہیں، سیج میکر انفرنس تجویز کنندہ ایک زیادہ موثر آپشن ہے. تھرڈ پارٹی لوڈ ٹیسٹنگ ٹولز کے ساتھ، آپ کو دستی طور پر مختلف مثالوں میں اینڈ پوائنٹس کو تعینات کرنا ہوگا۔ Inference Recommender کے ساتھ، آپ آسانی سے ان مثالوں کی ایک صف کو پاس کر سکتے ہیں جن کے خلاف آپ ٹیسٹ لوڈ کرنا چاہتے ہیں، اور SageMaker آگے بڑھ جائے گا۔ روزگار کے مواقع ان مثالوں میں سے ہر ایک کے لئے.
ٹڈڈی
اس مثال کے لیے ہم استعمال کرتے ہیں۔ ٹڈڈی، ایک اوپن سورس لوڈ ٹیسٹنگ ٹول جسے آپ Python استعمال کر کے لاگو کر سکتے ہیں۔ ٹڈی بہت سے دوسرے اوپن سورس لوڈ ٹیسٹنگ ٹولز کی طرح ہے، لیکن اس کے کچھ مخصوص فوائد ہیں:
- سیٹ اپ کرنے کے لئے آسان - جیسا کہ ہم اس پوسٹ میں ظاہر کر رہے ہیں، ہم ایک سادہ Python اسکرپٹ پاس کریں گے جسے آپ کے مخصوص اینڈ پوائنٹ اور پے لوڈ کے لیے آسانی سے ری فیکٹر کیا جا سکتا ہے۔
- تقسیم شدہ اور توسیع پذیر - ٹڈی واقعہ پر مبنی ہے اور استعمال کرتی ہے۔ gevent ٹوپی کے نیچے. یہ انتہائی ہم آہنگی کے کام کے بوجھ کو جانچنے اور ہزاروں ہم آہنگ صارفین کی نقل کرنے کے لیے بہت مفید ہے۔ آپ ٹڈی چلانے والے واحد عمل کے ساتھ اعلی TPS حاصل کر سکتے ہیں، لیکن اس میں ایک بھی ہے۔ تقسیم شدہ لوڈ جنریشن وہ خصوصیت جو آپ کو ایک سے زیادہ پروسیسز اور کلائنٹ مشینوں تک اسکیل آؤٹ کرنے کے قابل بناتی ہے، جیسا کہ ہم اس پوسٹ میں دریافت کریں گے۔
- ٹڈی میٹرکس اور UI - ٹڈی ایک میٹرک کے طور پر آخر سے آخر تک تاخیر کو بھی پکڑ لیتی ہے۔ یہ آپ کے CloudWatch میٹرکس کو آپ کے ٹیسٹوں کی مکمل تصویر پینٹ کرنے میں مدد کر سکتا ہے۔ یہ سب Locust UI میں کیپچر کیا گیا ہے، جہاں آپ ساتھی صارفین، کارکنوں اور مزید کو ٹریک کر سکتے ہیں۔
ٹڈی کو مزید سمجھنے کے لیے، ان کو دیکھیں دستاویزات.
ایمیزون EC2 سیٹ اپ
آپ جو بھی ماحول آپ کے لیے موافق ہے اس میں آپ ٹڈی کو ترتیب دے سکتے ہیں۔ اس پوسٹ کے لیے، ہم نے ایک EC2 مثال قائم کی اور اپنے ٹیسٹ کرنے کے لیے وہاں Locust انسٹال کیا۔ ہم c5.18xlarge EC2 مثال استعمال کرتے ہیں۔ کلائنٹ سائیڈ کمپیوٹ پاور بھی غور کرنے کی چیز ہے۔ بعض اوقات جب آپ کلائنٹ کی طرف سے کمپیوٹ کی طاقت ختم کر دیتے ہیں، تو یہ اکثر پکڑا نہیں جاتا، اور اسے سیج میکر اینڈ پوائنٹ کی غلطی سمجھ کر غلطی کی جاتی ہے۔ یہ ضروری ہے کہ آپ اپنے کلائنٹ کو کافی کمپیوٹ پاور والے مقام پر رکھیں جو اس بوجھ کو سنبھال سکے جس کی آپ جانچ کر رہے ہیں۔ ہمارے EC2 مثال کے لیے، ہم Ubuntu Deep Learning AMI استعمال کرتے ہیں، لیکن آپ کسی بھی AMI کو استعمال کر سکتے ہیں جب تک کہ آپ مشین پر Locust کو صحیح طریقے سے سیٹ کر سکیں۔ اپنے EC2 مثال کو لانچ کرنے اور اس سے جڑنے کا طریقہ سمجھنے کے لیے، ٹیوٹوریل کو دیکھیں Amazon EC2 Linux مثالوں کے ساتھ شروع کریں۔.
Locust UI پورٹ 8089 کے ذریعے قابل رسائی ہے۔ ہم EC2 مثال کے لیے اپنے ان باؤنڈ سیکیورٹی گروپ کے قوانین کو ایڈجسٹ کرکے اسے کھول سکتے ہیں۔ ہم پورٹ 22 کو بھی کھولتے ہیں تاکہ ہم EC2 مثال میں SSH کر سکیں۔ ماخذ کو اس مخصوص آئی پی ایڈریس تک اسکوپ کرنے پر غور کریں جس سے آپ EC2 مثال تک رسائی حاصل کر رہے ہیں۔

آپ کے EC2 مثال سے منسلک ہونے کے بعد، ہم ایک Python ورچوئل ماحول قائم کرتے ہیں اور CLI کے ذریعے اوپن سورس Locust API انسٹال کرتے ہیں:
اب ہم Locust کے ساتھ اپنے اختتامی نقطہ کی جانچ کرنے کے لیے کام کرنے کے لیے تیار ہیں۔
ٹڈی دل کی جانچ
ٹڈی کے بوجھ کے تمام ٹیسٹ a کی بنیاد پر کیے جاتے ہیں۔ ٹڈی کی فائل جو آپ فراہم کرتے ہیں۔ یہ Locust فائل لوڈ ٹیسٹ کے لیے ایک کام کی وضاحت کرتی ہے۔ یہ وہ جگہ ہے جہاں ہم اپنے Boto3 کی وضاحت کرتے ہیں۔ invoke_endpoint API کال. درج ذیل کوڈ دیکھیں:
پچھلے کوڈ میں، اپنے مخصوص ماڈل کی درخواست کے مطابق اپنے انووک اینڈ پوائنٹ کال پیرامیٹرز کو ایڈجسٹ کریں۔ ہم استعمال کرتے ہیں InvokeEndpoint Locust فائل میں درج ذیل کوڈ کا استعمال کرتے ہوئے API؛ یہ ہمارا لوڈ ٹیسٹ رن پوائنٹ ہے۔ Locust فائل جو ہم استعمال کر رہے ہیں۔ locust_script.py.
اب جب کہ ہمارے پاس اپنا Locust اسکرپٹ تیار ہے، ہم ڈسٹری بیوٹڈ Locust ٹیسٹ چلانا چاہتے ہیں تاکہ یہ معلوم کیا جا سکے کہ ہماری مثال کتنی ٹریفک کو سنبھال سکتی ہے۔
لوکسٹ ڈسٹری بیوٹڈ موڈ سنگل پروسیس لوکسٹ ٹیسٹ کے مقابلے میں تھوڑا زیادہ اہم ہے۔ تقسیم شدہ موڈ میں، ہمارے پاس ایک بنیادی اور متعدد کارکن ہیں۔ بنیادی کارکن کارکنوں کو ہدایت کرتا ہے کہ درخواست بھیجنے والے ہم وقت صارفین کو کیسے پیدا کیا جائے اور ان کو کنٹرول کیا جائے۔ ہمارے میں distributed.sh اسکرپٹ، ہم بطور ڈیفالٹ دیکھتے ہیں کہ 240 صارفین کو 60 کارکنوں میں تقسیم کیا جائے گا۔ نوٹ کریں کہ --headless Locust CLI میں جھنڈا Locust کی UI خصوصیت کو ہٹاتا ہے۔
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
ہم سب سے پہلے اختتامی نقطہ کی حمایت کرتے ہوئے ایک واحد مثال پر تقسیم شدہ ٹیسٹ چلاتے ہیں۔ یہاں خیال یہ ہے کہ ہم اپنی تاخیر کی ضروریات کے اندر رہتے ہوئے اپنے ہدف TPS کو حاصل کرنے کے لیے مطلوبہ مثالوں کی گنتی کو سمجھنے کے لیے ایک مثال کو پوری طرح سے زیادہ سے زیادہ کرنا چاہتے ہیں۔ نوٹ کریں کہ اگر آپ UI تک رسائی حاصل کرنا چاہتے ہیں تو اسے تبدیل کریں۔ Locust_UI Environment variable کو True کریں اور اپنے EC2 مثال کے عوامی IP کو لے جائیں اور پورٹ 8089 کا نقشہ URL پر لے جائیں۔
درج ذیل اسکرین شاٹ ہمارے CloudWatch میٹرکس کو دکھاتا ہے۔

آخر کار، ہم نے دیکھا کہ اگرچہ ہم ابتدائی طور پر 200 کا TPS حاصل کرتے ہیں، لیکن ہم اپنے EC5 کلائنٹ سائڈ لاگز میں 2xx غلطیوں کو دیکھنا شروع کر دیتے ہیں، جیسا کہ درج ذیل اسکرین شاٹ میں دکھایا گیا ہے۔
ہم خاص طور پر اپنی مثال کی سطح کے میٹرکس کو دیکھ کر بھی اس کی تصدیق کر سکتے ہیں۔ CPUUtilization.
 یہاں ہم نوٹس کرتے ہیں۔
یہاں ہم نوٹس کرتے ہیں۔ CPUUtilization تقریباً 4,800 فیصد۔ ہمارے ml.m5.12x.large مثال میں 48 vCPUs (48 * 100 = 4800~) ہیں۔ یہ پوری مثال کو سیر کر رہا ہے، جو ہماری 5xx غلطیوں کی وضاحت کرنے میں بھی مدد کرتا ہے۔ میں بھی اضافہ دیکھتے ہیں۔ ModelLatency.
ایسا لگتا ہے جیسے ہماری واحد مثال گر رہی ہے اور اس کے پاس 200 TPS سے زیادہ بوجھ کو برقرار رکھنے کا حساب نہیں ہے جس کا ہم مشاہدہ کر رہے ہیں۔ ہمارا ہدف TPS 1000 ہے، تو آئیے اپنی مثالوں کی تعداد کو 5 تک بڑھانے کی کوشش کریں۔ پروڈکشن سیٹنگ میں یہ اور بھی زیادہ ہونا پڑ سکتا ہے، کیونکہ ہم ایک خاص نقطہ کے بعد 200 TPS پر غلطیوں کا مشاہدہ کر رہے تھے۔

ہم Locust UI اور CloudWatch دونوں لاگز میں دیکھتے ہیں کہ ہمارے پاس تقریباً 1000 کا TPS ہے جس میں پانچ مثالیں اختتامی نقطہ کی پشت پناہی کرتی ہیں۔

 اگر آپ اس ہارڈویئر سیٹ اپ کے ساتھ بھی غلطیوں کا سامنا کرنا شروع کر دیتے ہیں، تو نگرانی کرنا یقینی بنائیں
اگر آپ اس ہارڈویئر سیٹ اپ کے ساتھ بھی غلطیوں کا سامنا کرنا شروع کر دیتے ہیں، تو نگرانی کرنا یقینی بنائیں CPUUtilization اپنے اینڈ پوائنٹ ہوسٹنگ کے پیچھے پوری تصویر کو سمجھنے کے لیے۔ یہ دیکھنے کے لیے اپنے ہارڈ ویئر کے استعمال کو سمجھنا ضروری ہے کہ آیا آپ کو پیمانہ بڑھانے یا نیچے کرنے کی ضرورت ہے۔ بعض اوقات کنٹینر کی سطح کے مسائل 5xx کی خرابیوں کا باعث بنتے ہیں، لیکن اگر CPUUtilization کم ہے، یہ اس بات کی نشاندہی کرتا ہے کہ یہ آپ کا ہارڈ ویئر نہیں ہے بلکہ کنٹینر یا ماڈل کی سطح پر کوئی چیز ہے جو ان مسائل کی طرف لے جا سکتی ہے (مثال کے طور پر سیٹ نہ کیے گئے کارکنوں کی تعداد کے لیے مناسب ماحول کا متغیر)۔ دوسری طرف، اگر آپ دیکھتے ہیں کہ آپ کی مثال پوری طرح سیر ہو رہی ہے، تو یہ اس بات کی علامت ہے کہ آپ کو موجودہ مثال کے بیڑے میں اضافہ کرنے کی ضرورت ہے یا چھوٹے بیڑے کے ساتھ بڑی مثال کو آزمانا ہوگا۔
اگرچہ ہم نے 5 TPS کو ہینڈل کرنے کے لیے مثال کی تعداد 100 تک بڑھا دی، ہم دیکھ سکتے ہیں کہ ModelLatency میٹرک اب بھی زیادہ ہے. یہ سیر ہونے والے واقعات کی وجہ سے ہے۔ عام طور پر، ہم تجویز کرتے ہیں کہ مثال کے وسائل کو 60-70% کے درمیان استعمال کریں۔
صاف کرو
لوڈ ٹیسٹنگ کے بعد، کسی بھی وسائل کو صاف کرنا یقینی بنائیں جو آپ SageMaker کنسول کے ذریعے یا اس کے ذریعے استعمال نہیں کریں گے۔ ڈیلیٹ_اینڈ پوائنٹ Boto3 API کال۔ اس کے علاوہ، اس بات کو یقینی بنائیں کہ آپ اپنے EC2 مثال کو روکیں یا جو بھی کلائنٹ سیٹ اپ ہے آپ کو وہاں بھی مزید چارجز نہیں اٹھانا پڑیں۔
خلاصہ
اس پوسٹ میں، ہم نے بیان کیا کہ آپ اپنے SageMaker کے ریئل ٹائم اینڈ پوائنٹ کو کیسے لوڈ کر سکتے ہیں۔ ہم نے اس بات پر بھی تبادلہ خیال کیا کہ آپ کی کارکردگی کی خرابی کو سمجھنے کے لیے آپ کے اینڈ پوائنٹ کی جانچ کرتے وقت آپ کو کن میٹرکس کا جائزہ لینا چاہیے۔ چیک آؤٹ کرنا یقینی بنائیں سیج میکر انفرنس تجویز کنندہ مثال کے طور پر رائٹ سائزنگ اور کارکردگی کو بہتر بنانے کی مزید تکنیکوں کو مزید سمجھنے کے لیے۔
مصنفین کے بارے میں
 مارک کارپ سیج میکر سروس ٹیم کے ساتھ ایم ایل آرکیٹیکٹ ہے۔ وہ گاہک کو ML کام کے بوجھ کو پیمانے پر ڈیزائن، تعینات اور ان کا انتظام کرنے میں مدد کرنے پر توجہ مرکوز کرتا ہے۔ اپنے فارغ وقت میں، وہ سفر کرنے اور نئی جگہوں کی تلاش کا لطف اٹھاتا ہے۔
مارک کارپ سیج میکر سروس ٹیم کے ساتھ ایم ایل آرکیٹیکٹ ہے۔ وہ گاہک کو ML کام کے بوجھ کو پیمانے پر ڈیزائن، تعینات اور ان کا انتظام کرنے میں مدد کرنے پر توجہ مرکوز کرتا ہے۔ اپنے فارغ وقت میں، وہ سفر کرنے اور نئی جگہوں کی تلاش کا لطف اٹھاتا ہے۔
 رام ویگیراجو سیج میکر سروس ٹیم کے ساتھ ایم ایل آرکیٹیکٹ ہے۔ وہ ایمیزون سیج میکر پر صارفین کو ان کے AI/ML حل بنانے اور بہتر بنانے میں مدد کرنے پر توجہ مرکوز کرتا ہے۔ اپنے فارغ وقت میں، وہ سفر اور لکھنے سے محبت کرتا ہے.
رام ویگیراجو سیج میکر سروس ٹیم کے ساتھ ایم ایل آرکیٹیکٹ ہے۔ وہ ایمیزون سیج میکر پر صارفین کو ان کے AI/ML حل بنانے اور بہتر بنانے میں مدد کرنے پر توجہ مرکوز کرتا ہے۔ اپنے فارغ وقت میں، وہ سفر اور لکھنے سے محبت کرتا ہے.
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- قابلیت
- اوپر
- قابل قبول
- تک رسائی حاصل
- قابل رسائی
- تک رسائی حاصل
- درست طریقے سے
- حاصل
- کے پار
- اس کے علاوہ
- پتہ
- کے بعد
- کے خلاف
- AI / ML
- مقصد
- تمام
- کی اجازت دیتا ہے
- اگرچہ
- ایمیزون
- ایمیزون EC2
- ایمیزون سیج میکر
- رقم
- تجزیہ
- اور
- اے پی آئی
- ارد گرد
- لڑی
- منسلک کریں
- تصنیف
- آٹو
- خود کار طریقے سے
- دستیاب
- AWS
- واپس
- حمایت کی
- حمایت
- کی بنیاد پر
- کیونکہ
- پیچھے
- کیا جا رہا ہے
- معیار
- فائدہ
- فوائد
- BEST
- بہترین طریقوں
- کے درمیان
- جسم
- خرابی
- تعمیر
- C ++
- فون
- کالز
- حاصل کر سکتے ہیں
- قبضہ
- قبضہ
- پکڑو
- کچھ
- تبدیل
- بوجھ
- چیک کریں
- طبقے
- درجہ بندی
- کلائنٹ
- کوڈ
- کامن
- ہم آہنگ
- کمپیوٹنگ
- سمورتی
- سلوک
- ترتیب
- کی توثیق
- رابطہ قائم کریں
- منسلک
- کنکشن
- غور کریں
- غور
- کنسول
- کنٹینر
- پر مشتمل ہے
- سیاق و سباق
- کنٹرول
- اسی کے مطابق
- سکتا ہے
- احاطہ
- پر محیط ہے
- CPU
- تخلیق
- اہم
- موجودہ
- اپنی مرضی کے
- گاہکوں
- اعداد و شمار
- گہری
- گہری سیکھنے
- گہرے
- پہلے سے طے شدہ
- وضاحت کرتا ہے
- مظاہرہ
- منحصر ہے
- انحصار کرتا ہے
- تعیناتی
- تعینات
- بیان
- بیان کیا
- ڈیزائن
- ڈویلپرز
- مختلف
- براہ راست
- بات چیت
- دکھائیں
- تقسیم کئے
- نہیں کرتا
- نہیں
- نیچے
- ہر ایک
- آسانی سے
- ہنر
- مؤثر طریقے سے
- یا تو
- کے قابل بناتا ہے
- آخر سے آخر تک
- اختتام پوائنٹ
- پوری
- ماحولیات
- خرابی
- نقائص
- ضروری
- Ether (ETH)
- بھی
- مثال کے طور پر
- رعایت
- عملدرآمد
- تجربہ کرنا
- وضاحت
- کی تلاش
- تلاش
- ایکسپلور
- برآمد
- انتہائی
- چہرہ
- عوامل
- آبشار
- واقف
- نمایاں کریں
- چند
- فائل
- آخر
- مل
- پہلا
- فلیٹ
- توجہ مرکوز
- توجہ مرکوز
- کے بعد
- فارمیٹ
- فریم ورک
- بار بار اس
- سے
- مکمل
- مکمل طور پر
- مزید
- جنرل
- عام طور پر
- حاصل
- حاصل کرنے
- اچھا
- گراف
- زیادہ سے زیادہ
- گروپ
- گروپ کا
- ہینڈل
- خوش
- ہارڈ ویئر
- مدد
- مدد
- مدد کرتا ہے
- یہاں
- ہائی
- انتہائی
- ہڈ
- میزبان
- میزبانی کی
- ہوسٹنگ
- کس طرح
- کیسے
- HTML
- HTTPS
- حب
- خیال
- مثالی
- کی نشاندہی
- شناخت
- اثر
- پر عملدرآمد
- عملدرآمد
- درآمد
- اہم
- in
- شامل ہیں
- اضافہ
- اضافہ
- اشارہ کرتا ہے
- اشارہ
- معلومات
- ابتدائی طور پر
- انسٹال
- مثال کے طور پر
- ضم
- انٹرایکٹو
- انٹرنیٹ
- پکارتے ہیں۔
- IP
- IP ایڈریس
- الگ الگ
- مسائل
- IT
- خود
- JSON
- بڑے
- بڑے پیمانے پر
- بڑے
- تاخیر
- شروع
- تہوں
- قیادت
- معروف
- سیکھنے
- سطح
- لینکس
- لسٹ
- تھوڑا
- لوڈ
- بوجھ
- محل وقوع
- لانگ
- تلاش
- بہت
- لو
- مشین
- مشین لرننگ
- مشینیں
- بنا
- بنانا
- انتظام
- میں کامیاب
- دستی طور پر
- بہت سے
- نقشہ
- زیادہ سے زیادہ
- کا مطلب ہے کہ
- سے ملو
- اجلاس
- یاد داشت
- میٹرک۔
- پیمائش کا معیار
- شاید
- کم سے کم
- ML
- موڈ
- ماڈل
- ماڈل
- کی نگرانی
- زیادہ
- زیادہ موثر
- ایک سے زیادہ
- نام
- تقریبا
- ضروری ہے
- ضرورت ہے
- نئی
- نوٹ بک
- تعداد
- ایک
- کھول
- اوپن سورس
- آپریشنز
- اصلاح کے
- کی اصلاح کریں
- اصلاح
- اختیار
- آپشنز کے بھی
- حکم
- دیگر
- باہر
- خود
- پینٹ
- پیرامیٹرز
- حصہ
- منظور
- گزشتہ
- راستہ
- پاٹرن
- پیٹرن
- چوٹی
- انجام دینے کے
- کارکردگی
- نقطہ نظر
- لینے
- تصویر
- ٹکڑا
- مقام
- مقامات
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- علاوہ
- پوائنٹ
- پوسٹ
- ممکنہ طور پر
- طاقت
- پریکٹس
- طریقوں
- پیش گو
- پرائمری
- پرنٹ
- مسائل
- عمل
- عمل
- پیداوار
- پروفائل
- مناسب
- مناسب طریقے سے
- فراہم
- فراہم کرتا ہے
- پراجیکٹ
- عوامی
- ازگر
- سوالات
- جلدی سے
- رینج
- تیار
- اصل وقت
- احساس
- موصول
- سفارش کی
- خطے
- متعلقہ
- درخواست
- ضروریات
- وسائل
- جواب
- باقی
- نتیجہ
- نتائج کی نمائش
- واپسی
- قوانین
- رن
- چل رہا ہے
- sagemaker
- سیج میکر کا اندازہ
- پیمانے
- سکیلنگ
- سائنسدانوں
- اسکاپنگ
- سکرپٹ
- دوسری
- سیکورٹی
- لگتا ہے
- SELF
- بھیجنا
- جذبات
- سروس
- خدمت
- مقرر
- قائم کرنے
- ترتیبات
- سیٹ اپ
- کئی
- ہونا چاہئے
- دکھایا گیا
- شوز
- سائن ان کریں
- اسی طرح
- سادہ
- صرف
- ایک
- سائز
- چھوٹے
- So
- حل
- کچھ
- ماخذ
- ذرائع
- سپون
- مخصوص
- خاص طور پر
- سپن
- معیار
- شروع کریں
- شروع
- بیانات
- مرحلہ
- ابھی تک
- بند کرو
- کشیدگی
- کوشش کریں
- اس طرح
- کافی
- سوٹ
- سپر
- کو بڑھانے کے
- لے لو
- لیتا ہے
- ہدف
- ٹاسک
- کاموں
- ٹیم
- تکنیک
- ٹیسٹ
- آزمائشی تجربہ
- ٹیسٹنگ
- ٹیسٹ
- متن کی درجہ بندی
- ۔
- ماخذ
- ان
- تیسری پارٹی
- ہزاروں
- کے ذریعے
- وقت
- اوقات
- کرنے کے لئے
- کے آلے
- اوزار
- ٹی پی
- ٹریک
- ٹریکنگ
- ٹریفک
- ٹرین
- معاملات
- سفر
- سچ
- سبق
- اقسام
- اوبنٹو
- ui
- کے تحت
- سمجھ
- افہام و تفہیم
- یونٹ
- URL
- us
- استعمال کی شرائط
- صارفین
- استعمال
- استعمال کیا
- استعمال کرتا ہے
- استعمال کرنا۔
- مختلف اقسام کے
- اس بات کی تصدیق
- کی طرف سے
- مجازی
- کیا
- چاہے
- جس
- جبکہ
- گے
- کے اندر
- کام
- کارکن
- کارکنوں
- گا
- تحریری طور پر
- اور
- زیفیرنیٹ