تعارف
جب یہ آتا ہے چہرے کی شناخت, researchers are constantly pushing the boundaries of accuracy and scalability. However, a significant challenge arises with the exponential growth of identities juxtaposed with the finite capacity of GPU memory. Previous studies have primarily focused on refining loss functions for facial feature extraction networks, with softmax-based loss functions driving advancements in face recognition performance. Nevertheless, bridging the widening disparity between the escalating number of identities and the limitations of GPU memory has proven increasingly challenging. In this article, we will explore strategies for Face Recognition at Massive Scale with Partial FC.

سیکھنے کے مقاصد
- Discover challenges posed by softmax loss in large-scale face recognition, like computational overhead and identity volume.
- Explore Partial Fully Connected (PFC) layer, optimizing memory and computation in face recognition tasks, including its pros, cons, and applications.
- Implement Partial FC in face recognition projects, with practical tips, code snippets, and resources.
اس مضمون کے ایک حصے کے طور پر شائع کیا گیا تھا۔ ڈیٹا سائنس بلاگتھون۔
فہرست
What is Softmax Bottleneck?
The softmax loss and its variants have been widely adopted as objectives for face recognition tasks. These functions make global feature-to-class comparisons during the multiplication between the embedding features and the linear transformation matrix.
However, when dealing with a massive number of identities in the training set, the cost of storing and computing the final linear matrix often exceeds the capabilities of current GPU hardware. This can result in training failures.
Previous Attempts at Acceleration
Researchers have explored various techniques to alleviate this bottleneck. Each has its own set of trade-offs and limitations.
HF-softmax employs a dynamic selection process for active class centers within each mini-batch. This selection is facilitated through the construction of a random hash forest in the embedding space, enabling the retrieval of approximate nearest class centers based on features. However, it’s crucial to note that storing all class centers in RAM and not overlooking the computational overhead for feature retrieval are essential.
On the other hand, Softmax Dissection divides the softmax loss into intra-class and inter-class objectives, thereby reducing redundant computations for the inter-class component. While this approach is commendable, it is limited in its adaptability and versatility, as it is applicable only to specific softmax-based loss functions.
Both of these methods operate on the principle of data parallelism during multi-GPU training. Despite attempting to approximate the softmax loss function with a subset of class centers, they still incur significant inter-GPU communication costs for gradient averaging and SGD synchronization. Additionally, the selection of class centers is constrained by the memory capacity of individual GPUs, further restricting their scalability.
Model Parallel: A Step in the Right Direction
ArcFace loss function introduced model parallelism, which separates the softmax weight matrix across different GPUs and calculates the full-class softmax loss with minimal communication overhead. This approach successfully trained 1 million identities using eight GPUs on a single machine.
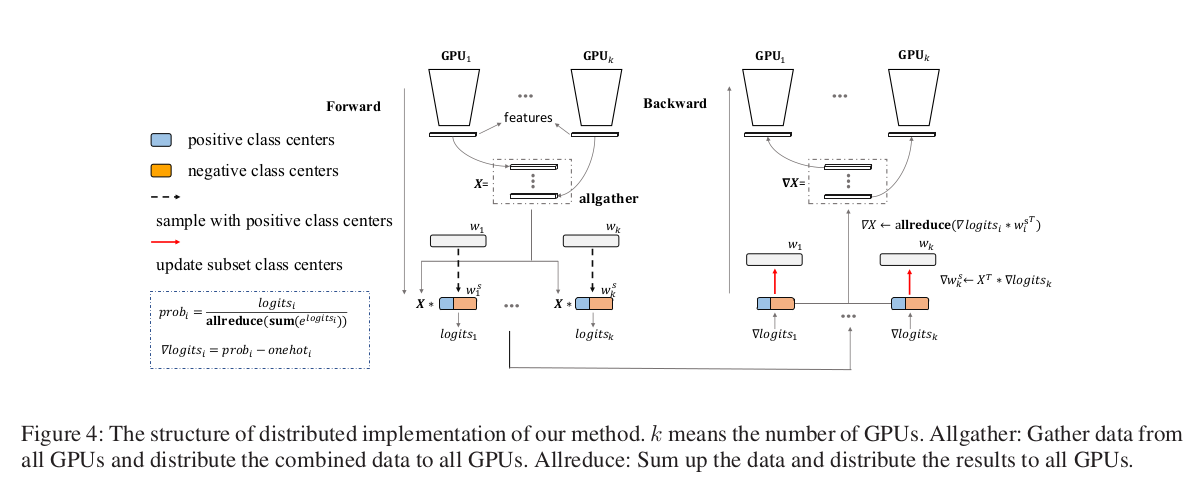
The model parallel approach partitions the softmax weight matrix W ∈ R (d×C) into k sub-matrices w of size d × (C/k), where d is the embedding feature dimension and C is the number of classes. Each sub-matrix wi is then placed on the ith GPU.
To calculate the final softmax outputs, each GPU independently computes the numerator e^((wi)T * X), where X is the input feature. The denominator ∑ j=1 to C e^((wj)T * X) requires gathering information from all other GPUs, which is done by first calculating the local sum on each GPU and then communicating the local sums to compute the global sum.
This approach significantly reduces inter-GPU communication compared to naive data parallelism, as only the local sums need to be communicated instead of the gradients for the entire weight matrix W.
For more details on the arcface loss function please go through my previous blog(ArcFace loss function for Deep Face Recognition) in which i have explained in detail.
Memory Limits of Model Parallel
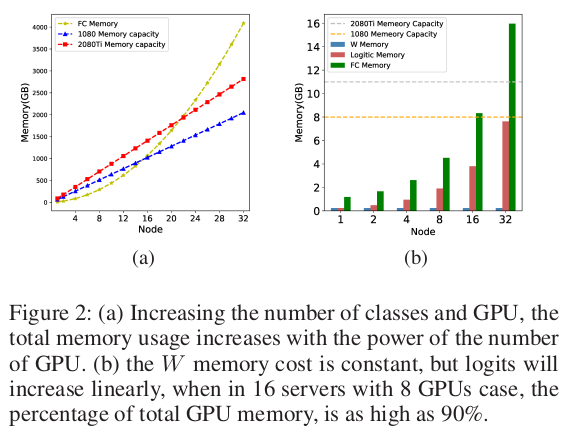
While model parallelism mitigates the memory burden of storing the weight matrix W, it introduces a new bottleneck – the storage of predicted logits.
The predicted logits are intermediate values computed during the forward pass, and their storage requirements scale with the total batch size across all GPUs. As the number of identities and GPUs increase, the memory consumption for storing logits can quickly exceed the GPU memory capacity.
This limitation restricts the scalability of the model parallel approach, even with an increasing number of GPUs.
Introducing Partial FC
To overcome the limitations of previous approaches, the authors of the “Partial FC” paper propose a groundbreaking solution!
Partial FC (Fully Connected)
Partial FC introduces a softmax approximation algorithm that can maintain state-of-the-art accuracy while using only a fraction (e.g., 10%) of the class centers. By carefully selecting a subset of class centers during training, it can significantly reduces the memory and computational requirements. This will further enable the training of face recognition models with an unprecedented number of identities.
The Magic of Partial FC
The key to Partial FC’s magic lies in how it selects the class centers for each iteration. Two strategies are proposed:
- Completely Random: A random subset (r%) of class centers is selected for calculating the loss and updating weights. This may or may not include all positive class centers in that iteration.
- Positive Plus Randomly Negative (PPRN): A subset (r%) of class centers is selected, but this time, it includes all positive class centers and randomly chosen negative class centers.
According to the research, PPRN outperforms the completely random approach, especially at lower sampling rates. This is because PPRN ensures that the gradients learn both the direction to push the sample away from negative centers and the intra-class clustering objective.
By splitting the softmax weight matrix across multiple GPUs and partitioning the input samples across these GPUs, Partial FC ensures that each GPU only processes a subset of the identities. This ingenious approach not only tackles the memory bottleneck but also minimizes the costly inter-GPU communication required for gradient synchronization.
Advantages of Partial FC
- By randomly sampling negative class centers, Partial FC is less affected by label noise or inter-class conflicts.
- In long-tailed distributions, where some classes have significantly fewer samples than others, Partial FC avoids overly updating the less frequent classes, leading to better performance.
- Partial FC can train over 10 million identities with just 8 GPUs, while ArcFace can only handle 1 million identities with the same GPU count.
Disadvantages of Partial FC
- Choosing an appropriate sampling rate (r%) is crucial for maintaining accuracy and efficiency. Too low a rate may degrade performance, while too high a rate may negate the memory and computational benefits.
- The random sampling process may introduce noise, which could potentially affect the model’s performance if not handled properly.
Unleashing the Power of Partial FC
Partial FC is easy to use. The paper gives clear instructions and code to add it to your projects. Plus, they released a massive, high-quality dataset (Glint360K) to train your models with Partial FC. With these tools, anyone can unlock the power of large-scale face recognition.
def sample(self, labels, index_positive):
with torch.no_grad():
positive = torch.unique(labels[index_positive], sorted=True).cuda()
if self.num_sample - positive.size(0) >= 0:
perm = torch.rand(size=[self.num_local]).cuda()
perm[positive] = 2.0
index = torch.topk(perm, k=self.num_sample)[1].cuda()
index = index.sort()[0].cuda()
else:
index = positive
self.weight_index = index
labels[index_positive] = torch.searchsorted(index, labels[index_positive])
return self.weight[self.weight_index]The provided code block can implement Partial FC in Python. For reference, you can explore my ذخیرہ, sourced from the insight face repository.
نتیجہ
Partial FC is a game-changer in face recognition. It lets you train models with way more identities than ever before. This technique rethinks how to scale models, balancing memory, speed, and accuracy. With Partial FC, the future of large-scale face recognition is amazing! Keep an eye on Partial FC, it’s going to revolutionize the field.
کلیدی لے لو
- Partial FC tackles the softmax bottleneck in face recognition by optimizing memory and computation.
- Partial FC selects subsets of class centers for training, boosting scalability and robustness.
- Advantages include robustness against noise and conflicts, and massive scalability up to 10M identities.
- Disadvantages involve careful sampling rate selection and potential noise introduction.
- Implementing Partial FC involves partitioning softmax weights across GPUs and selecting subsets for training.
- Code snippets like the provided sample() function enable easy implementation of Partial FC.
- Partial FC redefines large-scale face recognition, offering unprecedented scalability and accuracy.
اس مضمون میں دکھایا گیا میڈیا Analytics ودھیا کی ملکیت نہیں ہے اور مصنف کی صوابدید پر استعمال ہوتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.analyticsvidhya.com/blog/2024/03/guide-to-face-recognition-at-massive-scale-with-partial-fc/
- : ہے
- : ہے
- : نہیں
- :کہاں
- 10 ڈالر ڈالر
- $UP
- 1
- 10
- 10m
- 2%
- 8
- a
- تیزی
- درستگی
- کے پار
- فعال
- اطلاق
- شامل کریں
- اس کے علاوہ
- اپنایا
- ترقی
- پر اثر انداز
- متاثر
- کے خلاف
- یلگورتم
- تمام
- کم
- بھی
- an
- تجزیاتی
- تجزیات ودھیا
- اور
- کسی
- قابل اطلاق
- ایپلی کیشنز
- نقطہ نظر
- نقطہ نظر
- مناسب
- تخمینہ
- کیا
- پیدا ہوتا ہے
- مضمون
- AS
- At
- کوشش کرنا
- کوششیں
- مصنفین
- نگرانی
- بچا جائے
- دور
- توازن
- کی بنیاد پر
- BE
- کیونکہ
- رہا
- اس سے پہلے
- فوائد
- بہتر
- کے درمیان
- بلاک
- بلاگتھون
- اضافے کا باعث
- دونوں
- رکاوٹ
- حدود
- پلنگ
- بوجھ
- لیکن
- by
- حساب
- حساب کرتا ہے
- حساب
- کر سکتے ہیں
- صلاحیتوں
- اہلیت
- ہوشیار
- احتیاط سے
- مراکز
- چیلنج
- چیلنجوں
- چیلنج
- منتخب کیا
- طبقے
- کلاس
- واضح
- clustering کے
- کوڈ
- آتا ہے
- قابل تعریف
- بات چیت
- بات چیت
- مواصلات
- مقابلے میں
- موازنہ
- مکمل طور پر
- جزو
- حساب
- کمپیوٹیشنل
- گنتی
- کمپیوٹنگ
- شمار
- کمپیوٹنگ
- تنازعات
- منسلک
- خامیاں
- مسلسل
- مجبور
- تعمیر
- کھپت
- قیمت
- مہنگی
- اخراجات
- سکتا ہے
- شمار
- اہم
- موجودہ
- اعداد و شمار
- معاملہ
- گہری
- کے باوجود
- تفصیل
- تفصیلات
- مختلف
- طول و عرض
- سمت
- صوابدید
- تفاوت
- تقسیم
- تقسیم ہوتا ہے
- کیا
- ڈرائیونگ
- کے دوران
- متحرک
- e
- ہر ایک
- آسان
- کارکردگی
- آٹھ
- اور
- سرایت کرنا
- ملازمت کرتا ہے
- کو چالو کرنے کے
- کو فعال کرنا
- یقینی بناتا ہے
- پوری
- بڑھتی ہوئی
- خاص طور پر
- ضروری
- بھی
- کبھی نہیں
- حد سے تجاوز
- سے تجاوز
- وضاحت کی
- تلاش
- وضاحت کی
- ظالمانہ
- اسیاتی اضافہ
- نکالنے
- آنکھ
- چہرہ
- چہرے کی شناخت
- چہرے
- سہولت
- ناکامیوں
- fc
- نمایاں کریں
- خصوصیات
- کم
- میدان
- فائنل
- مکمل
- پہلا
- توجہ مرکوز
- کے لئے
- جنگل
- آگے
- کسر
- بار بار اس
- سے
- مکمل طور پر
- تقریب
- افعال
- مزید
- مستقبل
- کھیل مبدل
- جمع
- فراہم کرتا ہے
- گلوبل
- Go
- جا
- GPU
- GPUs
- میلان
- جھنڈا
- ترقی
- رہنمائی
- ہاتھ
- ہینڈل
- سنبھالا
- ہارڈ ویئر
- ہیش
- ہے
- ہائی
- اعلی معیار کی
- کس طرح
- کیسے
- تاہم
- HTTPS
- i
- شناخت
- شناختی
- if
- پر عملدرآمد
- نفاذ
- in
- شامل
- شامل ہیں
- سمیت
- اضافہ
- اضافہ
- دن بدن
- آزادانہ طور پر
- انڈکس
- انفرادی
- معلومات
- ان پٹ
- بصیرت
- کے بجائے
- ہدایات
- انٹرمیڈیٹ
- میں
- متعارف کرانے
- متعارف
- متعارف کرواتا ہے
- تعارف
- شامل
- شامل ہے
- IT
- تکرار
- میں
- فوٹو
- صرف
- رکھیں
- کلیدی
- لیبل
- لیبل
- بڑے پیمانے پر
- پرت
- معروف
- جانیں
- کم
- آو ہم
- جھوٹ ہے
- کی طرح
- حد کے
- حدود
- لمیٹڈ
- حدود
- لکیری
- مقامی
- بند
- لو
- کم
- مشین
- ماجک
- برقرار رکھنے کے
- برقرار رکھنے
- بنا
- بڑے پیمانے پر
- میٹرکس
- زیادہ سے زیادہ چوڑائی
- مئی..
- میڈیا
- یاد داشت
- طریقوں
- دس لاکھ
- کم سے کم
- کم سے کم
- ماڈل
- ماڈل
- زیادہ
- ایک سے زیادہ
- ضرب
- my
- بولی
- ضرورت ہے
- منفی
- نیٹ ورک
- پھر بھی
- نئی
- شور
- براہ مہربانی نوٹ کریں
- تعداد
- مقصد
- مقاصد
- of
- کی پیشکش
- اکثر
- on
- صرف
- کام
- اصلاح
- or
- دیگر
- دیگر
- Outperforms
- نتائج
- پر
- پر قابو پانے
- زمین کے اوپر
- خود
- ملکیت
- کاغذ.
- متوازی
- حصہ
- جزوی
- منظور
- کارکردگی
- رکھ دیا
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- مہربانی کرکے
- علاوہ
- درپیش
- مثبت
- ممکنہ
- ممکنہ طور پر
- طاقت
- عملی
- پیش گوئی
- پچھلا
- بنیادی طور پر
- اصول
- عمل
- عمل
- منصوبوں
- مناسب طریقے سے
- تجویز کریں
- مجوزہ
- پیشہ
- ثابت
- فراہم
- شائع
- پش
- دھکیلنا
- ازگر
- جلدی سے
- R
- RAM
- بے ترتیب
- شرح
- قیمتیں
- تسلیم
- کم
- کو کم کرنے
- بے حد
- حوالہ
- ادائیگی
- جاری
- ذخیرہ
- ضرورت
- ضروریات
- کی ضرورت ہے
- تحقیق
- محققین
- وسائل
- پابندی لگانا
- نتیجہ
- بازیافت
- واپسی
- انقلاب
- ٹھیک ہے
- مضبوطی
- اسی
- نمونہ
- اسکیل ایبلٹی
- پیمانے
- سائنس
- منتخب
- منتخب
- انتخاب
- SELF
- مقرر
- SGD
- دکھایا گیا
- اہم
- نمایاں طور پر
- ایک
- سائز
- کچھ
- ھٹا
- خلا
- مخصوص
- تیزی
- ریاستی آرٹ
- مرحلہ
- ابھی تک
- ذخیرہ
- ذخیرہ کرنے
- حکمت عملیوں
- مطالعہ
- کامیابی کے ساتھ
- رقم
- رقم
- ہم آہنگی
- احاطہ
- کاموں
- تکنیک
- تکنیک
- سے
- کہ
- ۔
- مستقبل
- ان
- تو
- اس طرح
- یہ
- وہ
- اس
- کے ذریعے
- وقت
- تجاویز
- کرنے کے لئے
- بھی
- اوزار
- مشعل
- کل
- ٹرین
- تربیت یافتہ
- ٹریننگ
- تبدیلی
- دو
- انلاک
- بے مثال
- اپ ڈیٹ
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- کا استعمال کرتے ہوئے
- اقدار
- متغیرات
- مختلف
- ورزش
- حجم
- W
- تھا
- راستہ..
- we
- وزن
- جب
- جس
- جبکہ
- بڑے پیمانے پر
- گے
- ساتھ
- کے اندر
- X
- آپ
- اور
- زیفیرنیٹ