ہر روز، Amazon ڈیوائسز گلوبل شپنگ، انوینٹری، صلاحیت، سپلائی، سیلز، مارکیٹنگ، پروڈیوسرز، اور کسٹمر سروس ٹیموں سے اربوں ٹرانزیکشنز پر کارروائی اور تجزیہ کرتے ہیں۔ یہ ڈیٹا ایمیزون کے صارفین کے مطالبات کو پورا کرنے کے لیے آلات کی انوینٹری کی خریداری میں استعمال کیا جاتا ہے۔ اعداد و شمار کے حجم میں سال بہ سال دوہرے ہندسے کی شرح نمو ظاہر ہوتی ہے اور 2021 میں COVID وبائی بیماری عالمی لاجسٹکس میں خلل ڈالتی ہے، یہ قریب قریب ریئل ٹائم ڈیٹا کو پیمانہ اور تیار کرنے کے لیے زیادہ اہم ہو گیا ہے۔
یہ پوسٹ آپ کو دکھاتی ہے کہ ہم AWS پر بنی سرور لیس ڈیٹا لیک میں کیسے منتقل ہوئے جو متعدد ذرائع اور مختلف فارمیٹس سے ڈیٹا خود بخود استعمال کرتی ہے۔ مزید برآں، اس نے ہمارے ڈیٹا سائنسدانوں اور انجینئرز کے لیے ڈیٹا کو مسلسل فیڈ اور تجزیہ کرنے کے لیے AI اور مشین لرننگ (ML) سروسز استعمال کرنے کے مزید مواقع پیدا کیے ہیں۔
چیلنجز اور ڈیزائن کے خدشات
ہمارا میراثی فن تعمیر بنیادی طور پر استعمال ہوتا ہے۔ ایمیزون لچکدار کمپیوٹ کلاؤڈ (Amazon EC2) مختلف داخلی متفاوت ڈیٹا ذرائع اور REST APIs سے ڈیٹا نکالنے کے لیے ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) ڈیٹا لوڈ کرنے کے لیے اور ایمیزون ریڈ شفٹ مزید تجزیہ اور خریداری کے آرڈر تیار کرنے کے لیے۔
ہم نے پایا کہ اس نقطہ نظر کے نتیجے میں کچھ کمی ہوئی اور اس وجہ سے درج ذیل شعبوں میں بہتری آئی:
- ڈویلپر کی رفتار - اسکیما کے اتحاد اور دریافت کی کمی کی وجہ سے، جو رن ٹائم کی ناکامی کی بنیادی وجوہات ہیں، ڈویلپرز اکثر آپریشنل اور دیکھ بھال کے مسائل سے نمٹنے میں وقت صرف کرتے ہیں۔
- اسکیل ایبلٹی - ان میں سے زیادہ تر ڈیٹا سیٹس کا دنیا بھر میں اشتراک کیا جاتا ہے۔ لہذا، ڈیٹا سے استفسار کرتے وقت ہمیں اسکیلنگ کی حدود کو پورا کرنا چاہیے۔
- کم سے کم بنیادی ڈھانچے کی دیکھ بھال - موجودہ عمل ڈیٹا سورس کے لحاظ سے متعدد کمپیوٹ پر محیط ہے۔ لہذا، بنیادی ڈھانچے کی دیکھ بھال کو کم کرنا اہم ہے۔
- ڈیٹا سورس کی تبدیلیوں پر ردعمل - ہمارا موجودہ نظام مختلف متفاوت ڈیٹا اسٹورز اور خدمات سے ڈیٹا حاصل کرتا ہے۔ ان خدمات کی کسی بھی اپ ڈیٹ میں ڈویلپر سائیکلوں کے مہینوں لگتے ہیں۔ ڈیٹا کے ان ذرائع کے جوابی اوقات ہمارے اہم اسٹیک ہولڈرز کے لیے اہم ہیں۔ لہذا، ہمیں ایک اعلی کارکردگی والے فن تعمیر کو منتخب کرنے کے لیے ڈیٹا پر مبنی نقطہ نظر اختیار کرنا چاہیے۔
- ذخیرہ اور فالتو پن - متضاد ڈیٹا اسٹورز اور ماڈلز کی وجہ سے، مختلف کاروباری اسٹیک ہولڈر ٹیموں کے مختلف ڈیٹا سیٹس کو اسٹور کرنا مشکل تھا۔ لہٰذا، موازنہ کرنے کے لیے اضافی اور تفریق والے ڈیٹا کے ساتھ ورژن بنانا زیادہ بہتر منصوبے بنانے کی قابل ذکر صلاحیت فراہم کرے گا۔
- مفرور اور رسائی - لاجسٹکس کی غیر مستحکم نوعیت کی وجہ سے، چند کاروباری اسٹیک ہولڈر ٹیموں کو ڈیمانڈ پر ڈیٹا کا تجزیہ کرنے اور خریداری کے آرڈرز کے لیے قریب ترین حقیقی وقت کا بہترین منصوبہ تیار کرنے کی ضرورت ہے۔ یہ پولنگ اور ڈیٹا تک رسائی اور تجزیہ کرنے کے لیے قریب قریب حقیقی وقت دونوں کی ضرورت کو متعارف کراتا ہے۔
نفاذ کی حکمت عملی
ان تقاضوں کی بنیاد پر، ہم نے حکمت عملی تبدیل کی اور حل کی نشاندہی کرنے کے لیے ہر مسئلے کا تجزیہ کرنا شروع کیا۔ آرکیٹیکچرل طور پر، ہم نے سرور لیس ماڈل کا انتخاب کیا، اور ڈیٹا لیک آرکیٹیکچر ایکشن لائن سے مراد وہ تمام آرکیٹیکچرل خلا اور چیلنجنگ خصوصیات ہیں جن کا ہم نے تعین کیا کہ وہ بہتری کا حصہ ہیں۔ آپریشنل نقطہ نظر سے، ہم نے ڈیٹا کے استعمال کے لیے مشترکہ ذمہ داری کا ایک نیا ماڈل ڈیزائن کیا ہے۔ AWS گلو ڈیٹا کو نکالنے کے لیے Amazon EC2 پر ڈیزائن کردہ اندرونی خدمات (REST APIs) کے بجائے۔ ہم نے بھی استعمال کیا۔ او ڈبلیو ایس لامبڈا۔ ڈیٹا پروسیسنگ کے لیے۔ پھر ہم نے انتخاب کیا۔ ایمیزون ایتینا ہماری استفسار کی خدمت کے طور پر۔ اپنے ڈیٹا صارفین کے لیے ڈویلپر کی رفتار کو مزید بہتر اور بہتر بنانے کے لیے، ہم نے مزید کہا ایمیزون ڈائنومو ڈی بی ڈیٹا لیک میں اترنے والے مختلف ڈیٹا ذرائع کے لیے میٹا ڈیٹا اسٹور کے طور پر۔ ان دو فیصلوں نے ہمارے کیے گئے ہر ڈیزائن اور نفاذ کے فیصلے کو آگے بڑھایا۔
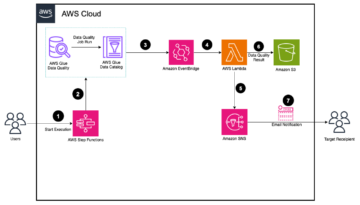
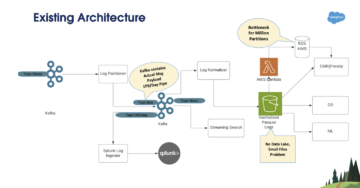
مندرجہ ذیل خاکہ فن تعمیر کو واضح کرتا ہے۔

مندرجہ ذیل حصوں میں، جب ہم عمل کے بہاؤ سے گزرتے ہیں تو ہم فن تعمیر کے ہر جزو کو مزید تفصیل سے دیکھتے ہیں۔
ETL کے لیے AWS گلو
نئے کاروباروں کے ڈیٹا ذرائع کے پیمانے کی حمایت کرتے ہوئے کسٹمر کی مانگ کو پورا کرنے کے لیے، ہمارے لیے مختلف ڈیٹا کے ذرائع سے استفسار کرنے میں اعلیٰ درجے کی چستی، اسکیل ایبلٹی، اور ردعمل کا ہونا بہت ضروری تھا۔
AWS Glue ایک سرور لیس ڈیٹا انٹیگریشن سروس ہے جو تجزیاتی صارفین کے لیے متعدد ذرائع سے ڈیٹا کو دریافت کرنا، تیار کرنا، منتقل کرنا اور انٹیگریٹ کرنا آسان بناتی ہے۔ آپ اسے تجزیات، ایم ایل، اور ایپلیکیشن ڈویلپمنٹ کے لیے استعمال کر سکتے ہیں۔ اس میں تصنیف، ملازمتیں چلانے، اور کاروباری ورک فلو کو نافذ کرنے کے لیے اضافی پیداواری صلاحیت اور DataOps ٹولنگ بھی شامل ہے۔
AWS Glue کے ساتھ، آپ 70 سے زیادہ متنوع ڈیٹا ذرائع کو دریافت کر سکتے ہیں اور ان سے جڑ سکتے ہیں اور مرکزی ڈیٹا کیٹلاگ میں اپنے ڈیٹا کا نظم کر سکتے ہیں۔ آپ اپنے ڈیٹا لیکس میں ڈیٹا لوڈ کرنے کے لیے بصری طور پر ایکسٹریکٹ، ٹرانسفارم، اور لوڈ (ETL) پائپ لائنز بنا سکتے ہیں، چلا سکتے ہیں اور مانیٹر کر سکتے ہیں۔ نیز، آپ ایتھینا کا استعمال کرتے ہوئے فوری طور پر کیٹلاگ ڈیٹا کو تلاش اور استفسار کرسکتے ہیں، ایمیزون ای ایم آر، اور ایمیزون ریڈ شفٹ سپیکٹرم.
AWS Glue نے ہمارے لیے مختلف ڈیٹا اسٹورز میں موجود ڈیٹا سے جڑنا، ضرورت کے مطابق ڈیٹا کو ایڈٹ کرنا اور صاف کرنا اور ڈیٹا کو AWS کے فراہم کردہ اسٹور میں ایک متحد منظر کے لیے لوڈ کرنا آسان بنا دیا۔ کلائنٹ کے وسائل اور ڈیٹا لیک سے ڈیٹا نکالنے کے لیے AWS Glue جابز کو شیڈول یا طلب کیا جا سکتا ہے۔
ان ملازمتوں کی کچھ ذمہ داریاں درج ذیل ہیں:
- ماخذ ہستی کو ڈیٹا ہستی میں نکالنا اور تبدیل کرنا
- بہتر کیٹلاگنگ کے لیے سال، مہینہ اور دن پر مشتمل ڈیٹا کو بہتر بنائیں اور بہتر استفسار کے لیے اسنیپ شاٹ ID شامل کریں۔
- Amazon S3 کے لیے ان پٹ کی توثیق اور پاتھ جنریشن کو انجام دیں۔
- ماخذ نظام کی بنیاد پر تسلیم شدہ میٹا ڈیٹا کو منسلک کریں۔
داخلی خدمات سے REST APIs سے استفسار کرنا ہمارے بنیادی چیلنجوں میں سے ایک ہے، اور کم سے کم انفراسٹرکچر پر غور کرتے ہوئے، ہم انہیں اس پروجیکٹ میں استعمال کرنا چاہتے تھے۔ AWS Glue کنیکٹرز نے ضرورت اور مقصد پر عمل کرنے میں ہماری مدد کی۔ REST APIs اور ڈیٹا کے دیگر ذرائع سے ڈیٹا استفسار کرنے کے لیے، ہم نے PySpark اور JDBC ماڈیولز کا استعمال کیا۔
AWS گلو کنکشن کی وسیع اقسام کی حمایت کرتا ہے۔ مزید تفصیلات کے لیے رجوع کریں۔ AWS Glue میں ETL کے لیے کنکشن کی اقسام اور اختیارات.
لینڈنگ زون کے طور پر S3 بالٹی
ہم نے نکالے گئے ڈیٹا کے فوری لینڈنگ زون کے طور پر S3 بالٹی کا استعمال کیا، جس پر مزید کارروائی اور اصلاح کی جاتی ہے۔
لیمبڈا بطور AWS گلو ای ٹی ایل ٹرگر
ہم نے لیمبڈا کو متحرک کرنے کے لیے S3 بالٹی پر S3 ایونٹ کی اطلاعات کو فعال کیا، جو ہمارے ڈیٹا کو مزید تقسیم کرتا ہے۔ ڈیٹا کو InputDataSetName، سال، مہینہ اور تاریخ پر تقسیم کیا گیا ہے۔ اس ڈیٹا کے اوپر چلنے والا کوئی بھی استفسار پروسیسر بہتر لاگت اور کارکردگی کو بہتر بنانے کے لیے ڈیٹا کے صرف ذیلی سیٹ کو اسکین کرے گا۔ ہمارا ڈیٹا مختلف فارمیٹس میں محفوظ کیا جا سکتا ہے، جیسے CSV، JSON، اور Parquet۔
خام ڈیٹا ہمارے استعمال کے زیادہ تر معاملات کے لیے بہترین منصوبہ تیار کرنے کے لیے مثالی نہیں ہے کیونکہ اس میں اکثر ڈپلیکیٹ یا غلط ڈیٹا کی قسمیں ہوتی ہیں۔ سب سے اہم بات یہ ہے کہ ڈیٹا متعدد فارمیٹس میں ہے، لیکن ہم نے ڈیٹا میں تیزی سے ترمیم کی اور Parquet فارمیٹ کے استعمال سے استفسار کی کارکردگی میں نمایاں اضافہ دیکھا۔ یہاں، ہم نے کارکردگی کی تجاویز میں سے ایک کا استعمال کیا۔ ایمیزون ایتھینا کے لیے پرفارمنس ٹیوننگ کے ٹاپ 10 ٹپس.
ETL کے لیے AWS Glue کی نوکریاں
ہم بہتر ڈیٹا کی علیحدگی اور رسائی چاہتے تھے، اس لیے ہم نے کارکردگی کو مزید بہتر بنانے کے لیے ایک مختلف S3 بالٹی کا انتخاب کیا۔ ہم نے اسی AWS Glue جابز کو مزید تبدیل کرنے اور ڈیٹا کو مطلوبہ S3 بالٹی میں اور نکالے گئے میٹا ڈیٹا کے ایک حصے کو DynamoDB میں لوڈ کرنے کے لیے استعمال کیا۔
DynamoDB بطور میٹا ڈیٹا اسٹور
اب جب کہ ہمارے پاس ڈیٹا ہے، مختلف کاروباری اسٹیک ہولڈرز اسے مزید استعمال کرتے ہیں۔ یہ ہمیں دو سوالات کے ساتھ چھوڑ دیتا ہے: ڈیٹا جھیل پر کون سا ذریعہ ڈیٹا رہتا ہے اور کون سا ورژن۔ ہم نے اپنے میٹا ڈیٹا اسٹور کے طور پر DynamoDB کا انتخاب کیا ہے، جو صارفین کو مؤثر طریقے سے ڈیٹا سے استفسار کرنے کے لیے تازہ ترین تفصیلات فراہم کرتا ہے۔ ہمارے سسٹم میں موجود ہر ڈیٹاسیٹ کی شناخت اسنیپ شاٹ ID سے ہوتی ہے، جسے ہم اپنے میٹا ڈیٹا اسٹور سے تلاش کر سکتے ہیں۔ کلائنٹ ایک API کے ساتھ اس ڈیٹا اسٹور تک رسائی حاصل کرتے ہیں۔
ایمیزون S3 بطور ڈیٹا لیک
بہتر ڈیٹا کوالٹی کے لیے، ہم نے اسی AWS Glue جاب کے ساتھ افزودہ ڈیٹا کو ایک اور S3 بالٹی میں نکالا۔
AWS گلو کرالر
کرالر ایک "خفیہ چٹنی" ہیں جو ہمیں اسکیما کی تبدیلیوں کا جواب دینے کے قابل بناتا ہے۔ پورے عمل کے دوران، ہم نے ہر قدم کو اسکیما-اگنوسٹک بنانے کا انتخاب کیا، جو کہ کسی بھی اسکیما کی تبدیلیوں کو اس وقت تک گزرنے دیتا ہے جب تک کہ وہ AWS Glue تک نہ پہنچ جائیں۔ ایک کرالر کے ساتھ، ہم اسکیما میں ہونے والی اگنوسٹک تبدیلیوں کو برقرار رکھ سکتے ہیں۔ اس سے ہمیں Amazon S3 سے ڈیٹا کو خود بخود کرال کرنے اور اسکیما اور ٹیبل بنانے میں مدد ملی۔
AWS گلو ڈیٹا کیٹلاگ
ڈیٹا کیٹلاگ نے Amazon S3 میں ڈیٹا کے مقام، اسکیما، اور رن ٹائم میٹرکس کے لیے کیٹلاگ کو انڈیکس کے طور پر برقرار رکھنے میں ہماری مدد کی۔ ڈیٹا کیٹلاگ میں معلومات کو میٹا ڈیٹا ٹیبل کے طور پر محفوظ کیا جاتا ہے، جہاں ہر جدول ایک ڈیٹا اسٹور کی وضاحت کرتا ہے۔
ایس کیو ایل کے سوالات کے لیے ایتھینا
Athena ایک انٹرایکٹو استفسار کی خدمت ہے جو معیاری SQL کا استعمال کرتے ہوئے Amazon S3 میں ڈیٹا کا تجزیہ کرنا آسان بناتی ہے۔ ایتھینا سرور لیس ہے، اس لیے انتظام کرنے کے لیے کوئی بنیادی ڈھانچہ نہیں ہے، اور آپ صرف ان سوالات کے لیے ادائیگی کرتے ہیں جو آپ چلاتے ہیں۔ ہم نے آپریشنل استحکام اور بڑھتے ہوئے ڈویلپر کی رفتار کو اپنے کلیدی بہتری کے عوامل کے طور پر سمجھا۔
ہم نے ایتھینا سے استفسار کرنے کے عمل کو مزید بہتر بنایا تاکہ صارفین درج ذیل کو بنا کر ایتھینا سے ڈیٹا حاصل کرنے کے لیے اقدار اور سوالات کو پلگ ان کر سکیں:
- An AWS کلاؤڈ ڈویلپمنٹ کٹ (AWS CDK) ٹیمپلیٹ ایتھینا انفراسٹرکچر بنانے کے لیے اور AWS شناخت اور رسائی کا انتظام (IAM) کسی بھی اکاؤنٹ سے ڈیٹا لیک S3 بالٹی اور ڈیٹا کیٹلاگ تک رسائی کے لیے کردار ادا کرتا ہے۔
- ایک لائبریری تاکہ کلائنٹ ایتھنا استفسار شروع کرنے کے لیے IAM رول، استفسار، ڈیٹا فارمیٹ، اور آؤٹ پٹ لوکیشن فراہم کر سکے اور اپنی پسند کی بالٹی میں چلائے گئے استفسار کی حیثیت اور نتیجہ حاصل کر سکے۔
ایتھینا سے استفسار کرنا ایک دو قدمی عمل ہے:
- StartQueryExecution - یہ استفسار شروع کرتا ہے اور رن ID حاصل کرتا ہے۔ صارف آؤٹ پٹ لوکیشن فراہم کر سکتے ہیں جہاں استفسار کا آؤٹ پٹ محفوظ کیا جائے گا۔
- GetQueryExecution - یہ استفسار کی حیثیت حاصل کرتا ہے کیونکہ رن غیر مطابقت پذیر ہے۔ کامیاب ہونے پر، آپ S3 فائل میں یا بذریعہ آؤٹ پٹ استفسار کرسکتے ہیں۔ API.
استفسار شروع کرنے اور نتیجہ حاصل کرنے کا مددگار طریقہ لائبریری میں ہوگا۔
ڈیٹا لیک میٹا ڈیٹا سروس
یہ سروس اپنی مرضی کے مطابق تیار کی گئی ہے اور میٹا ڈیٹا (ڈیٹا سیٹ کا نام، اسنیپ شاٹ ID، پارٹیشن سٹرنگ، ٹائم اسٹیمپ، اور ڈیٹا کا S3 لنک) REST API کی شکل میں حاصل کرنے کے لیے DynamoDB کے ساتھ بات چیت کرتی ہے۔ جب اسکیما دریافت ہوتا ہے، کلائنٹ ڈیٹا سے استفسار کرنے کے لیے ایتھینا کو اپنے استفسار پروسیسر کے طور پر استعمال کرتے ہیں۔
چونکہ تمام ڈیٹاسیٹس کی ایک اسنیپ شاٹ آئی ڈی تقسیم کی گئی ہے، اس لیے جوائن کے استفسار کے نتیجے میں مکمل ٹیبل اسکین نہیں ہوتا بلکہ Amazon S3 پر صرف ایک پارٹیشن اسکین ہوتا ہے۔ ہم نے اپنے استفسار کے بنیادی ڈھانچے کو منظم نہ کرنے میں آسانی کی وجہ سے ایتھینا کو اپنے استفسار پروسیسر کے طور پر استعمال کیا۔ بعد میں، اگر ہمیں لگتا ہے کہ ہمیں کچھ اور کی ضرورت ہے، تو ہم Redshift Spectrum یا Amazon EMR استعمال کر سکتے ہیں۔
نتیجہ
ایمیزون ڈیوائسز کی ٹیموں نے AWS Glue کا استعمال کرتے ہوئے ڈیٹا لیک آرکیٹیکچر میں جا کر اہم قدر دریافت کی، جس نے متعدد عالمی کاروباری اسٹیک ہولڈرز کو ڈیٹا کو زیادہ پیداواری طریقوں سے ہضم کرنے کے قابل بنایا۔ اس نے ٹیموں کو سپلائی چین، ڈیمانڈ اور پیشن گوئی کے مسائل کو حل کرنے کے لیے مناسب کاروباری منطق کے ساتھ قریب قریب حقیقی وقت میں مختلف ڈیٹا سیٹس کا تجزیہ کرکے آلات کے لیے خریداری کے آرڈر دینے کا بہترین منصوبہ تیار کرنے کے قابل بنایا۔
آپریشنل نقطہ نظر سے، سرمایہ کاری نے پہلے ہی ادائیگی شروع کردی ہے:
- اس نے ہمارے ادخال، سٹوریج، اور بازیافت کے طریقہ کار کو معیاری بنایا، آن بورڈنگ کے وقت کی بچت کی۔ اس سسٹم کے نفاذ سے پہلے، ایک ڈیٹا سیٹ کو جہاز میں آنے میں 1 ماہ کا وقت لگتا تھا۔ اپنے نئے فن تعمیر کی وجہ سے، ہم 15 ماہ سے بھی کم عرصے میں 2 نئے ڈیٹاسیٹس کو آن بورڈ کرنے میں کامیاب ہو گئے، جس سے ہماری چستی میں 70% بہتری آئی۔
- اس نے اسکیلنگ کی رکاوٹوں کو دور کیا، ایک یکساں نظام بنایا جو تیزی سے ہزاروں رنز تک پہنچ سکتا ہے۔
- حل نے کسی بھی ان پٹ کو قبول کرنے اور ڈیٹا کے معیار کی خلاف ورزیوں کا پتہ چلنے پر انہیں مسترد کرنے سے پہلے اسکیما اور ڈیٹا کے معیار کی توثیق کا اضافہ کیا۔
- اس نے ڈیٹاسیٹس کو بازیافت کرنا آسان بنا دیا جبکہ مستقبل کے سمولیشنز اور بیک ٹیسٹر کے استعمال کے کیسوں میں ورژن والے ان پٹ کی ضرورت ہوتی ہے۔ اس سے ماڈلز کی لانچنگ اور جانچ آسان ہو جائے گی۔
- اس حل نے ایک مشترکہ انفراسٹرکچر بنایا جسے آسانی سے DIAL کی دوسری ٹیموں تک بڑھایا جا سکتا ہے جن میں ڈیٹا کے انخلاء، ذخیرہ کرنے، اور بازیافت کے استعمال کے معاملات میں یکساں مسائل ہیں۔
- ہمارے آپریٹنگ اخراجات میں تقریباً 90 فیصد کمی آئی ہے۔
- اس ڈیٹا لیک تک ہمارے ڈیٹا سائنسدانوں اور انجینئرز کے ذریعے دیگر تجزیات کرنے کے لیے مؤثر طریقے سے رسائی حاصل کی جا سکتی ہے اور خریداری کے آرڈرز کے لیے درست منصوبے تیار کرنے کے مستقبل کے موقع کے طور پر پیشین گوئی کرنے والا نقطہ نظر حاصل کیا جا سکتا ہے۔
اس پوسٹ کے اقدامات آپ کو مختلف ذرائع سے ڈیٹا اکٹھا کرنے، خودکار طور پر میٹا ڈیٹا کیٹلاگ بنانے، ڈیٹا لیک اور ڈیٹا گودام کے درمیان بغیر کسی رکاوٹ کے ڈیٹا کا اشتراک کرنے، اور ایونٹ میں الرٹس بنانے کے لیے AWS کے زیر انتظام خدمات کا استعمال کرتے ہوئے اسی طرح کی جدید ڈیٹا حکمت عملی بنانے کا منصوبہ بنانے میں مدد کر سکتے ہیں۔ آرکیسٹریٹڈ ڈیٹا ورک فلو کی ناکامی۔
مصنفین کے بارے میں
 اویناش کولوری AWS میں ایک سینئر سولیوشن آرکیٹیکٹ ہے۔ وہ آرکیٹیکٹ اور جدید تقسیم شدہ حلوں کو ڈیزائن کرنے کے لیے ایمیزون الیکسا اور ڈیوائسز میں کام کرتا ہے۔ اس کا جنون AWS پر لاگت سے موثر اور انتہائی قابل توسیع حل تیار کرنا ہے۔ اپنے فارغ وقت میں، وہ فیوژن کی ترکیبیں پکانے اور سفر کرنے سے لطف اندوز ہوتے ہیں۔
اویناش کولوری AWS میں ایک سینئر سولیوشن آرکیٹیکٹ ہے۔ وہ آرکیٹیکٹ اور جدید تقسیم شدہ حلوں کو ڈیزائن کرنے کے لیے ایمیزون الیکسا اور ڈیوائسز میں کام کرتا ہے۔ اس کا جنون AWS پر لاگت سے موثر اور انتہائی قابل توسیع حل تیار کرنا ہے۔ اپنے فارغ وقت میں، وہ فیوژن کی ترکیبیں پکانے اور سفر کرنے سے لطف اندوز ہوتے ہیں۔
 وپل ورما Amazon.com پر ایک Sr. Software Engineer ہے۔ وہ 2015 سے ایمیزون کے ساتھ ہے، ٹیکنالوجی کے ذریعے حقیقی دنیا کے چیلنجوں کو حل کر رہا ہے جو ایمیزون کے صارفین کی زندگی کو براہ راست متاثر اور بہتر بناتا ہے۔ اپنے فارغ وقت میں وہ پیدل سفر سے لطف اندوز ہوتا ہے۔
وپل ورما Amazon.com پر ایک Sr. Software Engineer ہے۔ وہ 2015 سے ایمیزون کے ساتھ ہے، ٹیکنالوجی کے ذریعے حقیقی دنیا کے چیلنجوں کو حل کر رہا ہے جو ایمیزون کے صارفین کی زندگی کو براہ راست متاثر اور بہتر بناتا ہے۔ اپنے فارغ وقت میں وہ پیدل سفر سے لطف اندوز ہوتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/how-amazon-devices-scaled-and-optimized-real-time-demand-and-supply-forecasts-using-serverless-analytics/
- 1
- 10
- 100
- 2021
- 70
- a
- کی صلاحیت
- قابلیت
- تک رسائی حاصل
- رسائی
- رسائی پذیری
- معتبر
- درست
- کے پار
- عمل
- شامل کیا
- ایڈیشنل
- AI
- Alexaکی بنیاد پر IQ Option ، بائنومو سے اوپری پوزیشن پر ہے۔
- تمام
- کی اجازت دیتا ہے
- پہلے ہی
- ایمیزون
- ایمیزون الیکسا
- ایمیزون EC2
- ایمیزون ای ایم آر
- Amazon.com
- تجزیہ
- تجزیاتی
- تجزیے
- تجزیہ
- اور
- ایک اور
- اے پی آئی
- APIs
- درخواست
- درخواست کی ترقی
- نقطہ نظر
- مناسب
- ارکیٹیکچرل
- فن تعمیر
- علاقوں
- تصنیف
- خود کار طریقے سے
- AWS
- AWS گلو
- واپس
- کی بنیاد پر
- کیونکہ
- اس سے پہلے
- بہتر
- کے درمیان
- اربوں
- تعمیر
- تعمیر
- کاروبار
- کہا جاتا ہے
- اہلیت
- مقدمات
- کیٹلوگ
- کیٹلاگ
- مرکزی
- چین
- چیلنجوں
- چیلنج
- تبدیلیاں
- انتخاب
- کا انتخاب کیا
- کلائنٹ
- کلائنٹس
- بادل
- COM
- مجموعہ
- کامن
- موازنہ
- جزو
- کمپیوٹنگ
- رابطہ قائم کریں
- کنکشن
- سمجھا
- پر غور
- بسم
- صارفین
- مسلسل
- کھانا پکانے
- کور
- قیمت
- سرمایہ کاری مؤثر
- اخراجات
- سکتا ہے
- کوویڈ
- کرالر
- تخلیق
- بنائی
- تخلیق
- اہم
- موجودہ
- اپنی مرضی کے
- گاہک
- کسٹمر سروس
- گاہکوں
- سائیکل
- اعداد و شمار
- ڈیٹا انضمام
- ڈیٹا لیک
- ڈیٹا پروسیسنگ
- ڈیٹا کی معیار
- ڈیٹا کی حکمت عملی
- ڈیٹا گودام
- اعداد و شمار پر مبنی ہے
- ڈیٹاسیٹس
- تاریخ
- دن
- معاملہ
- فیصلہ
- فیصلے
- ڈگری
- ڈیمانڈ
- مطالبات
- منحصر ہے
- ڈیزائن
- ڈیزائن
- تفصیل
- تفصیلات
- کا تعین
- ترقی یافتہ
- ڈیولپر
- ڈویلپرز
- ترقی
- کے الات
- مختلف
- براہ راست
- دریافت
- دریافت
- دریافت
- تقسیم کئے
- متنوع
- نہیں کرتا
- نقل
- ہر ایک
- آسانی سے
- مؤثر طریقے
- مؤثر طریقے سے
- یا تو
- چالو حالت میں
- کے قابل بناتا ہے
- انجینئر
- انجینئرز
- افزودہ
- ہستی
- Ether (ETH)
- واقعہ
- ہر کوئی
- نکالنے
- ڈیٹا نکالیں
- عوامل
- ناکامی
- گر
- خصوصیات
- چند
- فائل
- بہاؤ
- کے بعد
- مندرجہ ذیل ہے
- پیشن گوئی
- فارم
- فارمیٹ
- ملا
- سے
- مکمل
- مزید
- مزید برآں
- فیوژن
- مستقبل
- فوائد
- پیدا
- پیدا کرنے والے
- نسل
- حاصل
- حاصل کرنے
- گلوبل
- عالمی کاروبار
- دنیا
- مقصد
- ترقی
- ہونے
- مدد
- مدد
- یہاں
- ہائی
- اعلی کارکردگی
- انتہائی
- لمبی پیدل سفر
- کس طرح
- HTML
- HTTPS
- IAM
- مثالی
- کی نشاندہی
- شناخت
- شناختی
- فوری طور پر
- فوری طور پر
- اثر
- نفاذ
- پر عمل درآمد
- کو بہتر بنانے کے
- بہتر
- بہتری
- بہتری
- in
- شامل
- شامل ہیں
- اضافہ
- انڈکس
- معلومات
- انفراسٹرکچر
- ان پٹ
- کے بجائے
- ضم
- انضمام
- انٹرایکٹو
- انٹرایکٹو
- اندرونی
- متعارف کرواتا ہے
- انوینٹری
- سرمایہ کاری
- مسئلہ
- مسائل
- IT
- ایوب
- نوکریاں
- میں شامل
- JSON
- کلیدی
- نہیں
- جھیل
- لینڈنگ
- تازہ ترین
- شروع
- سیکھنے
- کی وراست
- لائبریری
- زندگی
- حدود
- لائن
- LINK
- لوڈ
- محل وقوع
- لاجسٹکس
- دیکھو
- مشین
- مشین لرننگ
- بنا
- برقرار رکھنے کے
- دیکھ بھال
- بنا
- بناتا ہے
- انتظام
- مینیجنگ
- مارکیٹنگ
- سے ملو
- میٹا ڈیٹا
- طریقہ
- پیمائش کا معیار
- کم سے کم
- ML
- ماڈل
- ماڈل
- جدید
- نظر ثانی کی
- ماڈیولز
- کی نگرانی
- مہینہ
- ماہ
- زیادہ
- سب سے زیادہ
- منتقل
- منتقل
- ایک سے زیادہ
- نام
- فطرت، قدرت
- ضرورت ہے
- ضرورت
- نئی
- اطلاعات
- جہاز
- جہاز
- ایک
- کام
- آپریشنل
- مواقع
- مواقع
- زیادہ سے زیادہ
- اصلاح کے
- کی اصلاح کریں
- اصلاح
- آپشنز کے بھی
- احکامات
- دیگر
- وبائی
- حصہ
- جذبہ
- راستہ
- ادا
- فیصد
- انجام دینے کے
- کارکردگی
- نقطہ نظر
- مقام
- منصوبہ
- کی منصوبہ بندی
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- ممکن
- پوسٹ
- تیار
- بنیادی طور پر
- پرائمری
- مسائل
- عمل
- پروسیسنگ
- پروسیسر
- پروڈیوسرس
- پیداواری
- پیداوری
- منصوبے
- فراہم
- فراہم کرتا ہے
- خرید
- دھکیلنا
- معیار
- سوالات
- جلدی سے
- شرح
- خام
- خام ڈیٹا
- تک پہنچنے
- حقیقی دنیا
- اصل وقت
- وجوہات
- ترکیبیں
- کو کم کرنے
- مراد
- قابل ذکر
- ہٹا دیا گیا
- ضرورت
- ضرورت
- ضروریات
- وسائل
- جواب
- ذمہ داریاں
- ذمہ داری
- قبول
- باقی
- نتیجہ
- کردار
- کردار
- رن
- چل رہا ہے
- فروخت
- اسی
- بچت
- اسکیل ایبلٹی
- توسیع پذیر
- پیمانے
- سکیلنگ
- اسکین
- شیڈول کے مطابق
- سائنسدانوں
- بغیر کسی رکاوٹ کے
- تلاش کریں
- سیکشنز
- سینئر
- بے سرور
- سروس
- سروسز
- سیکنڈ اور
- مشترکہ
- شپنگ
- شوز
- اہم
- اسی طرح
- سادہ
- بعد
- ایک
- سنیپشاٹ
- So
- سافٹ ویئر کی
- سافٹ ویئر انجنیئر
- حل
- حل
- حل
- حل کرنا۔
- کچھ
- ماخذ
- ذرائع
- پھیلا ہوا ہے
- سپیکٹرم
- خرچ
- SQL
- استحکام
- حصہ دار
- اسٹیک ہولڈرز
- معیار
- شروع کریں
- شروع
- شروع
- شروع ہوتا ہے
- درجہ
- مرحلہ
- مراحل
- ذخیرہ
- ذخیرہ
- ذخیرہ
- پردہ
- حکمت عملیوں
- حکمت عملی
- کامیاب
- اس طرح
- فراہمی
- فراہمی کا سلسلہ
- امدادی
- کی حمایت کرتا ہے
- کے نظام
- ٹیبل
- لے لو
- لیتا ہے
- ٹیموں
- ٹیکنالوجی
- سانچے
- ٹیسٹنگ
- ۔
- ماخذ
- ان
- لہذا
- ہزاروں
- کے ذریعے
- بھر میں
- وقت
- اوقات
- ٹائمسٹیمپ
- تجاویز
- کرنے کے لئے
- سب سے اوپر
- معاملات
- تبدیل
- سفر
- ٹرگر
- اقسام
- متحد
- تازہ ترین معلومات
- us
- استعمال کی شرائط
- صارفین
- توثیق
- قیمت
- اقدار
- مختلف اقسام کے
- مختلف
- VeloCity
- ورژن
- کی طرف سے
- لنک
- خلاف ورزی
- واٹیٹائل
- جلد
- چاہتے تھے
- گودام
- طریقوں
- کیا
- جس
- جبکہ
- وسیع
- گے
- کام کا بہاؤ
- کام کے بہاؤ
- کام کرتا ہے
- گا
- سال
- اور
- زیفیرنیٹ