یہ پوسٹ VMware کاربن بلیک میں ماہیما اگروال، مشین لرننگ انجینئر، اور دیپک میٹم، سینئر انجینئرنگ مینیجر کے ساتھ مل کر لکھی گئی ہے۔
VMware کاربن بلیک جدید سائبر حملوں کے مکمل اسپیکٹرم کے خلاف تحفظ فراہم کرنے والا ایک مشہور سیکورٹی حل ہے۔ پروڈکٹ کے ذریعہ تیار کردہ ٹیرا بائٹس ڈیٹا کے ساتھ، سیکورٹی اینالیٹکس ٹیم سطحی اہم حملوں اور شور سے ابھرتے ہوئے خطرات سے نمٹنے کے لیے مشین لرننگ (ML) حل بنانے پر توجہ مرکوز کرتی ہے۔
VMware کاربن بلیک ٹیم کے لیے ایک حسب ضرورت اختتام سے آخر تک MLOps پائپ لائن کو ڈیزائن اور بنانا بہت اہم ہے جو ML لائف سائیکل میں ورک فلو کو آرکیسٹریٹ اور خود کار بناتی ہے اور ماڈل ٹریننگ، تشخیص اور تعیناتیوں کو قابل بناتی ہے۔
اس پائپ لائن کی تعمیر کے دو اہم مقاصد ہیں: ڈیٹا سائنسدانوں کی دیر سے مرحلے کے ماڈل کی ترقی کے لیے معاونت کریں، اور اعلیٰ حجم اور حقیقی وقت میں پیداواری ٹریفک میں ماڈلز پیش کر کے پروڈکٹ میں سطحی ماڈل کی پیش گوئیاں کریں۔ لہذا، VMware کاربن بلیک اور AWS کا استعمال کرتے ہوئے اپنی مرضی کے مطابق MLOps پائپ لائن بنانے کا انتخاب کیا۔ ایمیزون سیج میکر اس کے استعمال میں آسانی، استعداد، اور مکمل طور پر منظم انفراسٹرکچر کے لیے۔ ہم اپنی ایم ایل ٹریننگ اور تعیناتی پائپ لائنوں کا استعمال کرتے ہوئے آرکیسٹریٹ کرتے ہیں۔ Apache Airflow کے لیے Amazon کے زیر انتظام ورک فلوز (Amazon MWAA)، جو ہمیں آٹو اسکیلنگ یا انفراسٹرکچر کی دیکھ بھال کے بارے میں فکر کیے بغیر پروگرام کے مطابق ورک فلوز اور پائپ لائنوں کی تصنیف پر زیادہ توجہ مرکوز کرنے کے قابل بناتا ہے۔
اس پائپ لائن کے ساتھ، جو کبھی Jupyter نوٹ بک سے چلنے والی ML تحقیق تھی اب ڈیٹا سائنسدانوں کی تھوڑی دستی مداخلت کے ساتھ ماڈلز کو پروڈکشن میں تعینات کرنے والا ایک خودکار عمل ہے۔ اس سے پہلے، ایک ماڈل کی تربیت، تشخیص، اور تعیناتی کے عمل میں ایک دن لگ سکتا ہے۔ اس نفاذ کے ساتھ، سب کچھ صرف ایک محرک دور ہے اور اس نے مجموعی وقت کو چند منٹ تک کم کر دیا ہے۔
اس پوسٹ میں، VMware کاربن بلیک اور AWS آرکیٹیکٹس اس بات پر تبادلہ خیال کرتے ہیں کہ ہم نے کس طرح اپنی مرضی کے مطابق ML ورک فلو کو بنایا اور اس کا نظم کیا۔ گیت لاب، ایمیزون ایم ڈبلیو اے اے، اور سیج میکر۔ ہم بحث کرتے ہیں کہ ہم نے اب تک کیا حاصل کیا، پائپ لائن میں مزید اضافہ کیا، اور راستے میں سیکھے گئے اسباق۔
حل جائزہ
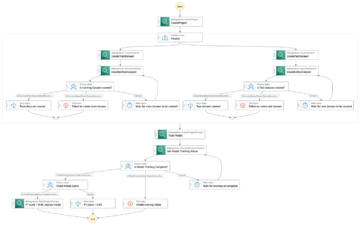
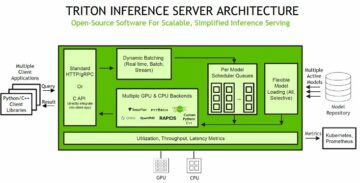
مندرجہ ذیل خاکہ ایم ایل پلیٹ فارم کے فن تعمیر کو واضح کرتا ہے۔

اعلی سطحی حل ڈیزائن
یہ ML پلیٹ فارم مختلف کوڈ ریپوزٹریز میں مختلف ماڈلز کے ذریعے استعمال کرنے کے لیے تصور اور ڈیزائن کیا گیا تھا۔ ہماری ٹیم تمام کوڈ ریپوزٹری کو برقرار رکھنے کے لیے GitLab کو بطور سورس کوڈ مینجمنٹ ٹول استعمال کرتی ہے۔ ماڈل ریپوزٹری سورس کوڈ میں کسی بھی تبدیلی کو استعمال کرتے ہوئے مسلسل مربوط کیا جاتا ہے۔ Gitlab CI، جو پائپ لائن (ماڈل ٹریننگ، تشخیص، اور تعیناتی) میں بعد میں کام کے بہاؤ کو مدعو کرتا ہے۔
مندرجہ ذیل آرکیٹیکچر کا خاکہ آخر سے آخر تک ورک فلو اور ہماری MLOps پائپ لائن میں شامل اجزاء کو واضح کرتا ہے۔

اینڈ ٹو اینڈ ورک فلو
ایم ایل ماڈل کی تربیت، تشخیص، اور تعیناتی پائپ لائنوں کو ایمیزون ایم ڈبلیو اے اے کا استعمال کرتے ہوئے ترتیب دیا گیا ہے، جس کا حوالہ دیا جاتا ہے۔ ڈائریکٹڈ Acyclic گراف (ڈی اے جی)۔ ڈی اے جی ایک ساتھ کاموں کا ایک مجموعہ ہے، جو انحصار اور رشتوں کے ساتھ ترتیب دیا جاتا ہے تاکہ یہ بتایا جا سکے کہ انہیں کیسے چلنا چاہیے۔
اعلی سطح پر، حل فن تعمیر میں تین اہم اجزاء شامل ہیں:
- ایم ایل پائپ لائن کوڈ ذخیرہ
- ایم ایل ماڈل ٹریننگ اور ایویلیویشن پائپ لائن
- ایم ایل ماڈل کی تعیناتی پائپ لائن
آئیے اس بات پر بات کرتے ہیں کہ ان مختلف اجزاء کو کس طرح منظم کیا جاتا ہے اور وہ ایک دوسرے کے ساتھ کیسے تعامل کرتے ہیں۔
ایم ایل پائپ لائن کوڈ ذخیرہ
ماڈل ریپو کے MLOps ریپو کو ان کی ڈاون اسٹریم پائپ لائن کے طور پر مربوط کرنے کے بعد، اور ایک ڈیٹا سائنسدان اپنے ماڈل ریپو میں کوڈ کا ارتکاب کرتا ہے، ایک GitLab رنر اس ریپو میں بیان کردہ معیاری کوڈ کی توثیق اور جانچ کرتا ہے اور کوڈ کی تبدیلیوں کی بنیاد پر MLOps پائپ لائن کو متحرک کرتا ہے۔ ہم اس ٹرگر کو مختلف ریپوز میں فعال کرنے کے لیے Gitlab کی ملٹی پروجیکٹ پائپ لائن کا استعمال کرتے ہیں۔
MLOps GitLab پائپ لائن مراحل کے ایک مخصوص سیٹ پر چلتی ہے۔ یہ پائلنٹ کا استعمال کرتے ہوئے بنیادی کوڈ کی توثیق کرتا ہے، ڈوکر امیج کے اندر ماڈل کی ٹریننگ اور انفرنس کوڈ کو پیک کرتا ہے، اور کنٹینر امیج کو شائع کرتا ہے۔ ایمیزون لچکدار کنٹینر رجسٹری (ایمیزون ای سی آر)۔ Amazon ECR ایک مکمل طور پر منظم کنٹینر رجسٹری ہے جو اعلی کارکردگی کی میزبانی پیش کرتی ہے، لہذا آپ قابل اعتماد طریقے سے ایپلیکیشن کی تصاویر اور نمونے کہیں بھی تعینات کر سکتے ہیں۔
ایم ایل ماڈل ٹریننگ اور ایویلیویشن پائپ لائن
تصویر شائع ہونے کے بعد، یہ تربیت اور تشخیص کو متحرک کرتا ہے۔ اپاچی ایئر فلو کے ذریعے پائپ لائن او ڈبلیو ایس لامبڈا۔ فنکشن لیمبڈا ایک سرور لیس، ایونٹ سے چلنے والی کمپیوٹ سروس ہے جو آپ کو کسی بھی قسم کی ایپلیکیشن یا بیک اینڈ سروس کے لیے سرورز کی فراہمی یا انتظام کیے بغیر کوڈ چلانے دیتی ہے۔
پائپ لائن کے کامیابی سے متحرک ہونے کے بعد، یہ ٹریننگ اینڈ ایویلیوایشن DAG چلاتا ہے، جس کے نتیجے میں SageMaker میں ماڈل ٹریننگ شروع ہوتی ہے۔ اس ٹریننگ پائپ لائن کے اختتام پر، شناخت شدہ صارف گروپ کو ای میل کے ذریعے تربیت اور ماڈل کی تشخیص کے نتائج کے ساتھ ایک اطلاع ملتی ہے۔ ایمیزون سادہ نوٹیفکیشن سروس (ایمیزون ایس این ایس) اور سلیک۔ Amazon SNS A2A اور A2P پیغام رسانی کے لیے مکمل طور پر منظم پب/سب سروس ہے۔
تشخیص کے نتائج کے باریک بینی سے تجزیہ کرنے کے بعد، ڈیٹا سائنسدان یا ایم ایل انجینئر نئے ماڈل کو تعینات کر سکتے ہیں اگر نئے تربیت یافتہ ماڈل کی کارکردگی پچھلے ورژن کے مقابلے بہتر ہو۔ ماڈلز کی کارکردگی کا اندازہ ماڈل کے مخصوص میٹرکس (جیسے F1 سکور، MSE، یا کنفیوژن میٹرکس) کی بنیاد پر کیا جاتا ہے۔
ایم ایل ماڈل کی تعیناتی پائپ لائن
تعیناتی شروع کرنے کے لیے، صارف GitLab جاب شروع کرتا ہے جو اسی Lambda فنکشن کے ذریعے تعیناتی DAG کو متحرک کرتا ہے۔ پائپ لائن کے کامیابی سے چلنے کے بعد، یہ نئے ماڈل کے ساتھ سیج میکر اینڈ پوائنٹ کو تخلیق یا اپ ڈیٹ کرتا ہے۔ یہ ایمیزون ایس این ایس اور سلیک کا استعمال کرتے ہوئے ای میل پر اختتامی نقطہ کی تفصیلات کے ساتھ ایک اطلاع بھی بھیجتا ہے۔
کسی بھی پائپ لائن میں ناکامی کی صورت میں، صارفین کو انہی مواصلاتی چینلز پر مطلع کیا جاتا ہے۔
سیج میکر ریئل ٹائم انفرنس پیش کرتا ہے جو کم تاخیر اور اعلی تھرو پٹ ضروریات کے ساتھ انفرنس ورک بوجھ کے لیے مثالی ہے۔ یہ اختتامی پوائنٹس مکمل طور پر منظم، لوڈ متوازن، اور خودکار پیمانے پر ہیں، اور زیادہ دستیابی کے لیے متعدد دستیابی زونز میں تعینات کیے جا سکتے ہیں۔ ہماری پائپ لائن کسی ماڈل کے کامیابی سے چلنے کے بعد اس کے لیے ایک ایسا اختتامی نقطہ بناتی ہے۔
مندرجہ ذیل حصوں میں، ہم مختلف اجزاء کو وسعت دیتے ہیں اور تفصیلات میں غوطہ لگاتے ہیں۔
GitLab: پیکیج ماڈل اور ٹرگر پائپ لائنز
ہم GitLab کو اپنے کوڈ کے ذخیرے کے طور پر استعمال کرتے ہیں اور ماڈل کوڈ کو پیک کرنے کے لیے پائپ لائن کے لیے اور ڈاؤن اسٹریم ایئر فلو DAGs کو متحرک کرتے ہیں۔
ملٹی پروجیکٹ پائپ لائن
ملٹی پروجیکٹ GitLab پائپ لائن کی خصوصیت استعمال کی جاتی ہے جہاں پیرنٹ پائپ لائن (اپ اسٹریم) ایک ماڈل ریپو ہے اور چائلڈ پائپ لائن (ڈاؤن اسٹریم) MLOps ریپو ہے۔ ہر ریپو ایک .gitlab-ci.yml کو برقرار رکھتا ہے، اور اپ اسٹریم پائپ لائن میں فعال درج ذیل کوڈ بلاک نیچے کی طرف MLOps پائپ لائن کو متحرک کرتا ہے۔
اپ اسٹریم پائپ لائن ماڈل کوڈ کو ڈاون اسٹریم پائپ لائن پر بھیجتی ہے جہاں پیکیجنگ اور پبلشنگ CI ملازمتیں شروع ہوتی ہیں۔ ماڈل کوڈ کو کنٹینرائز کرنے اور اسے Amazon ECR پر شائع کرنے کا کوڈ MLOps پائپ لائن کے ذریعہ برقرار اور منظم کیا جاتا ہے۔ یہ متغیرات بھیجتا ہے جیسے ACCESS_TOKEN (کے تحت بنایا جا سکتا ہے۔ ترتیبات, تک رسائی)، JOB_ID (اپ اسٹریم آرٹفیکٹس تک رسائی حاصل کرنے کے لیے)، اور $CI_PROJECT_ID (ماڈل ریپو کا پروجیکٹ ID) متغیرات، تاکہ MLOps پائپ لائن ماڈل کوڈ فائلوں تک رسائی حاصل کر سکے۔ کے ساتہ کام کے نمونے Gitlab کی خصوصیت، ڈاؤن اسٹریم ریپو درج ذیل کمانڈ کا استعمال کرتے ہوئے ریموٹ فن پاروں تک رسائی حاصل کرتا ہے۔
ماڈل ریپو ایک ہی ریپو سے متعدد ماڈلز کے لیے ڈاون اسٹریم پائپ لائنز استعمال کر سکتا ہے اس مرحلے کو بڑھا کر جو اسے متحرک کرتا ہے توسیع GitLab سے مطلوبہ لفظ، جو آپ کو مختلف مراحل میں ایک ہی ترتیب کو دوبارہ استعمال کرنے کی اجازت دیتا ہے۔
ایمیزون ای سی آر پر ماڈل امیج شائع کرنے کے بعد، ایم ایل او پی ایس پائپ لائن لیمبڈا کا استعمال کرتے ہوئے ایمیزون ایم ڈبلیو اے اے ٹریننگ پائپ لائن کو متحرک کرتی ہے۔ صارف کی منظوری کے بعد، یہ اسی Lambda فنکشن کا استعمال کرتے ہوئے ماڈل کی تعیناتی Amazon MWAA پائپ لائن کو متحرک کرتا ہے۔
سیمنٹک ورژننگ اور پاسنگ ورژنز بہاو
ہم نے ورژن ECR امیجز اور سیج میکر ماڈلز کے لیے حسب ضرورت کوڈ تیار کیا۔ MLOps پائپ لائن اس مرحلے کے حصے کے طور پر امیجز اور ماڈلز کے لیے سیمنٹک ورژننگ منطق کا انتظام کرتی ہے جہاں ماڈل کوڈ کنٹینرائز ہو جاتا ہے، اور ورژنز کو بعد کے مراحل میں نمونے کے طور پر منتقل کرتا ہے۔
دوبارہ تربیت
چونکہ دوبارہ تربیت ML لائف سائیکل کا ایک اہم پہلو ہے، اس لیے ہم نے اپنی پائپ لائن کے حصے کے طور پر دوبارہ تربیت کی صلاحیتوں کو نافذ کیا ہے۔ ہم یہ شناخت کرنے کے لیے SageMaker list-model API کا استعمال کرتے ہیں کہ آیا یہ ماڈل ری ٹریننگ ورژن نمبر اور ٹائم اسٹیمپ کی بنیاد پر دوبارہ تربیت دے رہا ہے۔
ہم استعمال کرتے ہوئے دوبارہ ٹریننگ پائپ لائن کے روزانہ شیڈول کا انتظام کرتے ہیں۔ GitLab کی شیڈول پائپ لائنز.
ٹیرافارم: انفراسٹرکچر سیٹ اپ
ایمیزون ایم ڈبلیو اے اے کلسٹر، ای سی آر ریپوزٹریز، لیمبڈا فنکشنز، اور ایس این ایس موضوع کے علاوہ، یہ حل بھی استعمال کرتا ہے۔ AWS شناخت اور رسائی کا انتظام (IAM) کردار، صارفین اور پالیسیاں؛ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) بالٹیاں، اور ایک ایمیزون کلاؤڈ واچ لاگ فارورڈر.
ہماری پوری پائپ لائن میں شامل خدمات کے لیے بنیادی ڈھانچے کے سیٹ اپ اور دیکھ بھال کو ہموار کرنے کے لیے، ہم استعمال کرتے ہیں۔ ٹرافیفار بنیادی ڈھانچے کو کوڈ کے طور پر نافذ کرنا۔ جب بھی انفرا اپ ڈیٹ کی ضرورت ہوتی ہے، کوڈ کی تبدیلیاں ایک GitLab CI پائپ لائن کو متحرک کرتی ہیں جو ہم نے ترتیب دی ہے، جو مختلف ماحول میں تبدیلیوں کی توثیق اور تعیناتی کرتی ہے (مثال کے طور پر، dev، اسٹیج اور پروڈ اکاؤنٹس میں IAM پالیسی میں اجازت شامل کرنا)۔
ایمیزون ای سی آر، ایمیزون ایس 3، اور لیمبڈا: پائپ لائن کی سہولت
ہم اپنی پائپ لائن کی سہولت کے لیے درج ذیل کلیدی خدمات استعمال کرتے ہیں:
- ایمیزون ای سی آر - ماڈل کنٹینر امیجز کو برقرار رکھنے اور آسانی سے بازیافت کرنے کی اجازت دینے کے لیے، ہم انہیں سیمنٹک ورژنز کے ساتھ ٹیگ کرتے ہیں اور انہیں ECR ریپوزٹریز پر اپ لوڈ کرتے ہیں۔
${project_name}/${model_name}Terraform کے ذریعے. یہ مختلف ماڈلز کے درمیان تنہائی کی ایک اچھی پرت کو قابل بناتا ہے، اور ہمیں حسب ضرورت الگورتھم استعمال کرنے اور مطلوبہ ماڈل مینی فیسٹ معلومات (ماڈل کا نام، ورژن، ٹریننگ ڈیٹا پاتھ، وغیرہ) شامل کرنے کے لیے تخمینہ کی درخواستوں اور جوابات کو فارمیٹ کرنے کی اجازت دیتا ہے۔ - ایمیزون S3 - ہم ماڈل ٹریننگ ڈیٹا، تربیت یافتہ ماڈل نمونے فی ماڈل، ایئر فلو ڈی اے جی، اور پائپ لائنز کے لیے درکار دیگر اضافی معلومات کو برقرار رکھنے کے لیے S3 بالٹیاں استعمال کرتے ہیں۔
- لامڈا - چونکہ ہمارا ایئر فلو کلسٹر سیکورٹی کے حوالے سے ایک علیحدہ VPC میں تعینات ہے، اس لیے DAGs تک براہ راست رسائی نہیں کی جا سکتی۔ لہذا، ہم ڈی اے جی کے نام سے متعین کسی بھی ڈی اے جی کو متحرک کرنے کے لیے لیمبڈا فنکشن کا استعمال کرتے ہیں، جسے Terraform کے ساتھ بھی برقرار رکھا جاتا ہے۔ مناسب IAM سیٹ اپ کے ساتھ، GitLab CI جاب لیمبڈا فنکشن کو متحرک کرتا ہے، جو کہ کنفیگریشنز کے ذریعے درخواست کردہ ٹریننگ یا تعیناتی DAGs تک جاتا ہے۔
ایمیزون MWAA: ٹریننگ اور تعیناتی پائپ لائنز
جیسا کہ پہلے ذکر کیا گیا ہے، ہم Amazon MWAA کو تربیت اور تعیناتی پائپ لائنوں کو ترتیب دینے کے لیے استعمال کرتے ہیں۔ ہم میں دستیاب سیج میکر آپریٹرز استعمال کرتے ہیں۔ ایئر فلو کے لیے ایمیزون فراہم کنندہ پیکیج سیج میکر کے ساتھ ضم کرنے کے لیے (جنجا ٹیمپلیٹنگ سے بچنے کے لیے)۔
ہم اس ٹریننگ پائپ لائن میں درج ذیل آپریٹرز استعمال کرتے ہیں (مندرجہ ذیل ورک فلو ڈایاگرام میں دکھایا گیا ہے):

MWAA ٹریننگ پائپ لائن
ہم درج ذیل آپریٹرز کو تعیناتی پائپ لائن میں استعمال کرتے ہیں (مندرجہ ذیل ورک فلو خاکہ میں دکھایا گیا ہے):

ماڈل تعیناتی پائپ لائن
ہم دونوں پائپ لائنوں میں غلطی/کامیابی کے پیغامات اور تشخیصی نتائج شائع کرنے کے لیے Slack اور Amazon SNS کا استعمال کرتے ہیں۔ Slack پیغامات کو حسب ضرورت بنانے کے لیے اختیارات کی ایک وسیع رینج فراہم کرتا ہے، بشمول درج ذیل:
- SnsPublishOperator - ہم استعمال کرتے ہیں SnsPublishOperator صارف کی ای میلز پر کامیابی/ناکامی کی اطلاعات بھیجنے کے لیے
- سلیک API - ہم نے تخلیق کیا۔ آنے والا ویب ہک URL مطلوبہ چینل پر پائپ لائن کی اطلاعات حاصل کرنے کے لیے
CloudWatch اور VMware Wavefront: مانیٹرنگ اور لاگنگ
ہم اینڈ پوائنٹ مانیٹرنگ اور لاگنگ کو کنفیگر کرنے کے لیے CloudWatch ڈیش بورڈ استعمال کرتے ہیں۔ یہ ہر پروجیکٹ کے لیے مخصوص مختلف آپریشنل اور ماڈل پرفارمنس میٹرکس کو دیکھنے اور ان پر نظر رکھنے میں مدد کرتا ہے۔ ان میں سے کچھ کو ٹریک کرنے کے لیے ترتیب دی گئی آٹو اسکیلنگ پالیسیوں کے اوپری حصے میں، ہم CPU اور میموری کے استعمال میں ہونے والی تبدیلیوں، فی سیکنڈ کی درخواستوں، جوابی تاخیر، اور ماڈل میٹرکس کی مسلسل نگرانی کرتے ہیں۔
یہاں تک کہ CloudWatch کو VMware Tanzu Wavefront ڈیش بورڈ کے ساتھ مربوط کیا گیا ہے تاکہ یہ ماڈل اینڈ پوائنٹس کے ساتھ ساتھ پروجیکٹ کی سطح پر دیگر خدمات کے میٹرکس کا تصور کر سکے۔
کاروباری فوائد اور آگے کیا ہے۔
ML پائپ لائنز ML خدمات اور خصوصیات کے لیے بہت اہم ہیں۔ اس پوسٹ میں، ہم نے AWS کی صلاحیتوں کا استعمال کرتے ہوئے ایک اختتام سے آخر تک ML استعمال کے معاملے پر تبادلہ خیال کیا۔ ہم نے SageMaker اور Amazon MWAA کا استعمال کرتے ہوئے ایک حسب ضرورت پائپ لائن بنائی، جسے ہم پراجیکٹس اور ماڈلز میں دوبارہ استعمال کر سکتے ہیں، اور ML لائف سائیکل کو خودکار بنایا، جس نے ماڈل ٹریننگ سے پروڈکشن تعیناتی تک کا وقت کم کر کے 10 منٹ کر دیا۔
ایم ایل لائف سائیکل بوجھ کو سیج میکر پر منتقل کرنے کے ساتھ، اس نے ماڈل ٹریننگ اور تعیناتی کے لیے بہتر اور قابل توسیع انفراسٹرکچر فراہم کیا۔ SageMaker کے ساتھ پیش کرنے والے ماڈل نے ملی سیکنڈ کی تاخیر اور نگرانی کی صلاحیتوں کے ساتھ حقیقی وقت کی پیش گوئیاں کرنے میں ہماری مدد کی۔ ہم نے سیٹ اپ کی آسانی اور انفراسٹرکچر کو منظم کرنے کے لیے Terraform کا استعمال کیا۔
اس پائپ لائن کے لیے اگلے اقدامات ماڈل ٹریننگ پائپ لائن کو دوبارہ تربیت دینے کی صلاحیتوں کے ساتھ بڑھانا ہوں گے چاہے یہ طے شدہ ہو یا ماڈل ڈرفٹ ڈٹیکشن، سپورٹ شیڈو تعیناتی یا تیز رفتار اور قابل ماڈل تعیناتی کے لیے A/B ٹیسٹنگ، اور ML نسب ٹریکنگ پر مبنی ہو۔ ہم بھی اندازہ لگانے کا ارادہ رکھتے ہیں۔ ایمیزون سیج میکر پائپ لائنز کیونکہ GitLab انضمام اب تعاون یافتہ ہے۔
سیکھا اسباق
اس حل کو بنانے کے حصے کے طور پر، ہم نے سیکھا کہ آپ کو جلد عام کرنا چاہیے، لیکن زیادہ عام نہ کریں۔ جب ہم نے پہلی بار آرکیٹیکچر ڈیزائن مکمل کیا، تو ہم نے بہترین عمل کے طور پر ماڈل کوڈ کے لیے کوڈ ٹیمپلیٹنگ بنانے اور نافذ کرنے کی کوشش کی۔ تاہم، یہ ترقی کے عمل میں اتنی جلدی تھی کہ ٹیمپلیٹس کو یا تو بہت زیادہ عام کیا گیا تھا یا مستقبل کے ماڈلز کے لیے دوبارہ قابل استعمال ہونے کے لیے بہت تفصیلی تھی۔
پائپ لائن کے ذریعے پہلا ماڈل فراہم کرنے کے بعد، ٹیمپلیٹس قدرتی طور پر ہمارے پچھلے کام کی بصیرت کی بنیاد پر سامنے آئے۔ ایک پائپ لائن پہلے دن سے سب کچھ نہیں کر سکتی۔
ماڈل کے تجربات اور پروڈکشن کی ضروریات اکثر بہت مختلف ہوتی ہیں (یا بعض اوقات متضاد بھی)۔ ایک ٹیم کے طور پر شروع سے ہی ان ضروریات کو متوازن کرنا اور اس کے مطابق ترجیح دینا بہت ضروری ہے۔
مزید برآں، ہو سکتا ہے کہ آپ کو کسی سروس کی ہر خصوصیت کی ضرورت نہ ہو۔ سروس سے ضروری خصوصیات کا استعمال اور ماڈیولرائزڈ ڈیزائن زیادہ موثر ترقی اور لچکدار پائپ لائن کی کلید ہیں۔
نتیجہ
اس پوسٹ میں، ہم نے دکھایا کہ کس طرح ہم نے SageMaker اور Amazon MWAA کا استعمال کرتے ہوئے ایک MLOps حل بنایا جس نے ڈیٹا سائنسدانوں کی تھوڑی دستی مداخلت کے ساتھ، پروڈکشن میں ماڈلز کی تعیناتی کے عمل کو خودکار بنایا۔ ہم آپ کی حوصلہ افزائی کرتے ہیں کہ مختلف AWS سروسز جیسے SageMaker، Amazon MWAA، Amazon S3، اور Amazon ECR کا جائزہ لیں تاکہ ایک مکمل MLOps حل بنایا جا سکے۔
*Apache، Apache Airflow، اور Airflow یا تو رجسٹرڈ ٹریڈ مارک یا ٹریڈ مارک ہیں۔ اپاچی سافٹ ویئر فاؤنڈیشن امریکہ اور/یا دوسرے ممالک میں۔
مصنفین کے بارے میں
 دیپک میٹم VMware، کاربن بلیک یونٹ میں ایک سینئر انجینئرنگ مینیجر ہے۔ وہ اور ان کی ٹیم سٹریمنگ پر مبنی ایپلی کیشنز اور خدمات کی تعمیر پر کام کرتی ہے جو صارفین کو حقیقی وقت میں مشین لرننگ پر مبنی حل لانے کے لیے انتہائی دستیاب، قابل توسیع اور لچکدار ہیں۔ وہ اور ان کی ٹیم ڈیٹا سائنسدانوں کے لیے اپنے ML ماڈلز کی تیاری، تربیت، تعیناتی اور توثیق کرنے کے لیے ضروری ٹولز بنانے کے لیے بھی ذمہ دار ہے۔
دیپک میٹم VMware، کاربن بلیک یونٹ میں ایک سینئر انجینئرنگ مینیجر ہے۔ وہ اور ان کی ٹیم سٹریمنگ پر مبنی ایپلی کیشنز اور خدمات کی تعمیر پر کام کرتی ہے جو صارفین کو حقیقی وقت میں مشین لرننگ پر مبنی حل لانے کے لیے انتہائی دستیاب، قابل توسیع اور لچکدار ہیں۔ وہ اور ان کی ٹیم ڈیٹا سائنسدانوں کے لیے اپنے ML ماڈلز کی تیاری، تربیت، تعیناتی اور توثیق کرنے کے لیے ضروری ٹولز بنانے کے لیے بھی ذمہ دار ہے۔
 مہیما اگروال VMware، کاربن بلیک یونٹ میں مشین لرننگ انجینئر ہے۔
مہیما اگروال VMware، کاربن بلیک یونٹ میں مشین لرننگ انجینئر ہے۔
وہ VMware CB SBU کے لیے مشین لرننگ پلیٹ فارم کے بنیادی اجزاء اور فن تعمیر کی ڈیزائننگ، تعمیر اور ترقی پر کام کرتی ہے۔
 ومشی کرشنا اینابوتھلا AWS میں ایک سینئر اپلائیڈ اے آئی سپیشلسٹ آرکیٹیکٹ ہے۔ وہ اعلیٰ اثر والے ڈیٹا، تجزیات، اور مشین لرننگ کے اقدامات کو تیز کرنے کے لیے مختلف شعبوں کے صارفین کے ساتھ کام کرتا ہے۔ وہ AI اور ML میں سفارشی نظام، NLP، اور کمپیوٹر وژن کے شعبوں کے بارے میں پرجوش ہیں۔ کام سے باہر، Vamshi ایک RC پرجوش ہے، RC سازوسامان (ہوائی جہاز، کاریں، اور ڈرون) بناتا ہے، اور باغبانی سے بھی لطف اندوز ہوتا ہے۔
ومشی کرشنا اینابوتھلا AWS میں ایک سینئر اپلائیڈ اے آئی سپیشلسٹ آرکیٹیکٹ ہے۔ وہ اعلیٰ اثر والے ڈیٹا، تجزیات، اور مشین لرننگ کے اقدامات کو تیز کرنے کے لیے مختلف شعبوں کے صارفین کے ساتھ کام کرتا ہے۔ وہ AI اور ML میں سفارشی نظام، NLP، اور کمپیوٹر وژن کے شعبوں کے بارے میں پرجوش ہیں۔ کام سے باہر، Vamshi ایک RC پرجوش ہے، RC سازوسامان (ہوائی جہاز، کاریں، اور ڈرون) بناتا ہے، اور باغبانی سے بھی لطف اندوز ہوتا ہے۔
 ساحل تھاپر ایک انٹرپرائز سلوشنز آرکیٹیکٹ ہے۔ وہ صارفین کے ساتھ کام کرتا ہے تاکہ وہ AWS کلاؤڈ پر انتہائی دستیاب، قابل توسیع، اور لچکدار ایپلیکیشنز بنانے میں ان کی مدد کرے۔ فی الحال اس کی توجہ کنٹینرز اور مشین لرننگ سلوشنز پر ہے۔
ساحل تھاپر ایک انٹرپرائز سلوشنز آرکیٹیکٹ ہے۔ وہ صارفین کے ساتھ کام کرتا ہے تاکہ وہ AWS کلاؤڈ پر انتہائی دستیاب، قابل توسیع، اور لچکدار ایپلیکیشنز بنانے میں ان کی مدد کرے۔ فی الحال اس کی توجہ کنٹینرز اور مشین لرننگ سلوشنز پر ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- : ہے
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- ہمارے بارے میں
- رفتار کو تیز تر
- تک رسائی حاصل
- رسائی
- اس کے مطابق
- اکاؤنٹس
- حاصل کیا
- کے پار
- تیزابیت
- اس کے علاوہ
- ایڈیشنل
- اضافی معلومات
- کے بعد
- کے خلاف
- AI
- یلگوردمز
- تمام
- کی اجازت دیتا ہے
- ایمیزون
- ایمیزون سیج میکر
- تجزیہ
- تجزیاتی
- اور
- کہیں
- اپاچی
- اے پی آئی
- درخواست
- ایپلی کیشنز
- اطلاقی
- اپلائیڈ اے آئی
- منظوری
- فن تعمیر
- کیا
- علاقوں
- AS
- پہلو
- At
- حملے
- تصنیف
- آٹو
- آٹومیٹڈ
- خودکار
- دستیابی
- دستیاب
- سے اجتناب
- AWS
- پسدید
- متوازن
- کی بنیاد پر
- بنیادی
- BE
- کیونکہ
- شروع
- فوائد
- BEST
- بہتر
- کے درمیان
- سیاہ
- بلاک
- برانچ
- لانے
- تعمیر
- عمارت
- تعمیر
- بوجھ
- by
- کر سکتے ہیں
- نہیں کر سکتے ہیں
- صلاحیتوں
- کاربن
- کاریں
- کیس
- CB
- کچھ
- تبدیلیاں
- چینل
- بچے
- کا انتخاب کیا
- بادل
- کلسٹر
- کوڈ
- مجموعہ
- مواصلات
- مقابلے میں
- مکمل
- اجزاء
- کمپیوٹنگ
- کمپیوٹر
- کمپیوٹر ویژن
- انعقاد کرتا ہے
- ترتیب
- ترتیب
- متضاد
- الجھن
- خیالات
- بسم
- بسم
- کنٹینر
- کنٹینر
- مسلسل
- آسان
- کور
- سکتا ہے
- ممالک
- CPU
- تخلیق
- بنائی
- پیدا
- تخلیق
- اہم
- اہم
- اس وقت
- اپنی مرضی کے
- گاہکوں
- اپنی مرضی کے مطابق
- سائبرٹیکس
- ماؤنٹین
- روزانہ
- ڈیش بورڈ
- اعداد و شمار
- ڈیٹا سائنسدان
- دن
- کی وضاحت
- ترسیل
- تعیناتی
- تعینات
- تعینات
- تعیناتی
- تعینات
- تعینات کرتا ہے
- ڈیزائن
- ڈیزائن
- ڈیزائننگ
- تفصیلی
- تفصیلات
- کھوج
- دیو
- ترقی یافتہ
- ترقی
- ترقی
- مختلف
- براہ راست
- بات چیت
- بات چیت
- میں Docker
- نہیں
- نیچے
- ڈرون
- ہر ایک
- اس سے قبل
- ابتدائی
- استعمال میں آسانی
- ہنر
- یا تو
- ای میل
- کرنڈ
- کو چالو کرنے کے
- چالو حالت میں
- کے قابل بناتا ہے
- کی حوصلہ افزائی
- آخر سے آخر تک
- اختتام پوائنٹ
- انجینئر
- انجنیئرنگ
- انٹرپرائز
- انٹرپرائز کے حل
- حوصلہ افزائی
- ماحول
- کا سامان
- ضروری
- Ether (ETH)
- اندازہ
- اندازہ
- کا جائزہ لینے
- تشخیص
- اندازہ
- بھی
- واقعہ
- ہر کوئی
- سب کچھ
- مثال کے طور پر
- توسیع
- توسیع
- f1
- سہولت
- ناکامی
- دور
- تیز تر
- نمایاں کریں
- خصوصیات
- چند
- فائلوں
- پہلا
- لچکدار
- توجہ مرکوز
- توجہ مرکوز
- توجہ مرکوز
- کے بعد
- کے لئے
- فارمیٹ
- سے
- مکمل
- مکمل سپیکٹرم
- مکمل طور پر
- تقریب
- افعال
- مزید
- مستقبل
- پیدا
- حاصل
- اچھا
- گروپ
- ہے
- ہونے
- مدد
- مدد
- مدد کرتا ہے
- ہائی
- اعلی کارکردگی
- انتہائی
- ہوسٹنگ
- کس طرح
- تاہم
- HTML
- HTTP
- HTTPS
- IAM
- ID
- مثالی
- کی نشاندہی
- شناخت
- شناختی
- تصویر
- تصاویر
- پر عملدرآمد
- نفاذ
- عملدرآمد
- in
- شامل
- شامل ہیں
- سمیت
- معلومات
- انفراسٹرکچر
- اقدامات
- بصیرت
- ضم
- ضم
- انٹیگریٹٹس
- انضمام
- بات چیت
- مداخلت
- پکارتے ہیں۔
- ملوث
- تنہائی
- IT
- میں
- ایوب
- نوکریاں
- فوٹو
- رکھیں
- کلیدی
- چابیاں
- تاخیر
- پرت
- سیکھا ہے
- سیکھنے
- اسباق
- سبق سیکھا
- آو ہم
- سطح
- زندگی کا دورانیہ
- کی طرح
- تھوڑا
- لوڈ
- لو
- مشین
- مشین لرننگ
- مین
- برقرار رکھنے کے
- برقرار رکھتا ہے
- دیکھ بھال
- بنا
- انتظام
- میں کامیاب
- انتظام
- مینیجر
- انتظام کرتا ہے
- مینیجنگ
- دستی
- میٹرکس
- یاد داشت
- ذکر کیا
- پیغامات
- پیغام رسانی
- پیمائش کا معیار
- شاید
- ملی سیکنڈ
- منٹ
- ML
- ایم ایل اوپس
- ماڈل
- ماڈل
- جدید
- کی نگرانی
- نگرانی
- زیادہ
- زیادہ موثر
- ایک سے زیادہ
- نام
- قدرتی طور پر
- ضروری
- ضرورت ہے
- نئی
- اگلے
- ویزا
- شور
- نوٹیفیکیشن
- اطلاعات
- تعداد
- of
- کی پیشکش
- تجویز
- on
- ایک
- آپریشنل
- آپریٹرز
- اصلاح
- آپشنز کے بھی
- آرکسٹری
- منظم
- دیگر
- باہر
- مجموعی طور پر
- پیکج
- پیکجوں کے
- پیکیجنگ
- حصہ
- گزرتا ہے
- پاسنگ
- جذباتی
- راستہ
- کارکردگی
- اجازت
- پائپ لائن
- منصوبہ
- ہوائی جہاز
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- پالیسیاں
- پالیسی
- پوسٹ
- پریکٹس
- پیشن گوئی
- پچھلا
- ترجیح دیں
- عمل
- مصنوعات
- پیداوار
- منصوبے
- منصوبوں
- مناسب
- تحفظ
- فراہم
- فراہم کنندہ
- فراہم کرتا ہے
- شائع
- شائع
- شائع کرتا ہے
- پبلشنگ
- مقاصد
- تعلیم یافتہ
- رینج
- اصل وقت
- سفارش
- کم
- کہا جاتا ہے
- رجسٹرڈ
- رجسٹری
- تعلقات
- ریموٹ
- معروف
- ذخیرہ
- درخواست کی
- درخواستوں
- ضرورت
- ضروریات
- تحقیق
- لچکدار
- جواب
- ذمہ دار
- نتائج کی نمائش
- دوبارہ پڑھنا
- قابل اعتماد
- کردار
- رن
- دوسرے نمبر پر
- sagemaker
- اسی
- توسیع پذیر
- سکیلنگ
- شیڈول
- شیڈول کے مطابق
- سائنسدان
- سائنسدانوں
- دوسری
- سیکشنز
- سیکٹر
- سیکورٹی
- سینئر
- علیحدہ
- بے سرور
- سرورز
- سروس
- سروسز
- خدمت
- مقرر
- سیٹ اپ
- شیڈو
- منتقلی
- ہونا چاہئے
- دکھایا گیا
- سادہ
- سست
- So
- اب تک
- سافٹ ویئر کی
- حل
- حل
- کچھ
- ماخذ
- ماخذ کوڈ
- ماہر
- مخصوص
- مخصوص
- سپیکٹرم
- کے لئے نشان راہ
- اسٹیج
- مراحل
- معیار
- شروع کریں
- شروع ہوتا ہے
- امریکہ
- مراحل
- ذخیرہ
- حکمت عملی
- محرومی
- کارگر
- بعد میں
- کامیابی کے ساتھ
- اس طرح
- حمایت
- تائید
- سطح
- سسٹمز
- TAG
- لے لو
- کاموں
- ٹیم
- سانچے
- ٹرافیفار
- ٹیسٹنگ
- کہ
- ۔
- ان
- ان
- لہذا
- یہ
- خطرات
- تین
- کے ذریعے
- بھر میں
- تھرو پٹ
- وقت
- ٹائمسٹیمپ
- کرنے کے لئے
- مل کر
- بھی
- کے آلے
- اوزار
- سب سے اوپر
- موضوع
- ٹریک
- ٹریکنگ
- ٹریڈ مارکس
- ٹریفک
- ٹرین
- تربیت یافتہ
- ٹریننگ
- ٹرگر
- متحرک
- ٹرن
- کے تحت
- یونٹ
- متحدہ
- ریاست ہائے متحدہ امریکہ
- تازہ ترین معلومات
- us
- استعمال
- استعمال کی شرائط
- استعمال کیس
- رکن کا
- صارفین
- تصدیق کریں۔
- توثیق
- متغیرات
- مختلف
- ورژن
- بنیادی طور پر
- نقطہ نظر
- تصور کرنا
- vmware
- حجم
- راستہ..
- اچھا ہے
- کیا
- چاہے
- جس
- وسیع
- وسیع رینج
- ساتھ
- کے اندر
- بغیر
- کام
- کام کا بہاؤ
- کام کے بہاؤ
- کام کرتا ہے
- گا
- زیفیرنیٹ
- زپ
- علاقوں