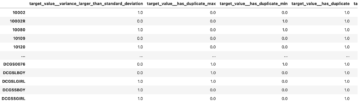
کمپیوٹر ویژن میں، سیمنٹک سیگمنٹیشن ایک تصویر میں ہر پکسل کو لیبل کے معروف سیٹ سے کلاس کے ساتھ درجہ بندی کرنے کا کام ہے جیسے کہ ایک ہی لیبل والے پکسلز کچھ خصوصیات کا اشتراک کرتے ہیں۔ یہ ان پٹ امیجز کا سیگمنٹیشن ماسک تیار کرتا ہے۔ مثال کے طور پر، درج ذیل تصاویر میں سیگمنٹیشن ماسک دکھایا گیا ہے۔ cat لیبل
 |
 |
نومبر 2018 میں، ایمیزون سیج میکر SageMaker سیمنٹک سیگمنٹیشن الگورتھم کے آغاز کا اعلان کیا۔ اس الگورتھم کے ساتھ، آپ اپنے ماڈلز کو عوامی ڈیٹاسیٹ یا اپنے ڈیٹاسیٹ سے تربیت دے سکتے ہیں۔ مشہور تصویری سیگمنٹیشن ڈیٹاسیٹس میں Common Objects in Context (COCO) ڈیٹاسیٹ اور PASCAL Visual Object Classes (PASCAL VOC) شامل ہیں، لیکن ان کے لیبلز کی کلاسیں محدود ہیں اور ہو سکتا ہے کہ آپ ایسے ماڈل کو ٹارگٹ آبجیکٹ پر تربیت دینا چاہیں جو اس میں شامل نہیں ہیں۔ عوامی ڈیٹاسیٹس۔ اس صورت میں، آپ استعمال کر سکتے ہیں ایمیزون سیج میکر گراؤنڈ ٹروتھ اپنے ڈیٹاسیٹ کو لیبل کرنے کے لیے۔
اس پوسٹ میں، میں مندرجہ ذیل حل دکھاتا ہوں:
- سیمنٹک سیگمنٹیشن ڈیٹاسیٹ کو لیبل کرنے کے لیے زمینی سچائی کا استعمال
- SageMaker بلٹ ان semantic segmentation algorithm کے لیے زمینی سچ سے نتائج کو مطلوبہ ان پٹ فارمیٹ میں تبدیل کرنا
- ایک ماڈل کو تربیت دینے اور اندازہ لگانے کے لیے سیمنٹک سیگمنٹیشن الگورتھم کا استعمال
سیمنٹک سیگمنٹیشن ڈیٹا لیبلنگ
سیمنٹک سیگمنٹیشن کے لیے مشین لرننگ ماڈل بنانے کے لیے، ہمیں پکسل لیول پر ڈیٹا سیٹ کو لیبل کرنے کی ضرورت ہے۔ گراؤنڈ ٹروتھ آپ کو انسانی تشریحی استعمال کرنے کا اختیار دیتا ہے۔ ایمیزون میکانی ترک، فریق ثالث فروش، یا آپ کی اپنی نجی افرادی قوت۔ افرادی قوت کے بارے میں مزید جاننے کے لیے، رجوع کریں۔ افرادی قوتیں بنائیں اور ان کا نظم کریں۔. اگر آپ خود لیبلنگ ورک فورس کا انتظام نہیں کرنا چاہتے ہیں، ایمیزون سیج میکر گراؤنڈ ٹروتھ پلس ایک نئی ٹرنکی ڈیٹا لیبلنگ سروس کے طور پر ایک اور بہترین آپشن ہے جو آپ کو اعلیٰ معیار کے تربیتی ڈیٹا سیٹس کو تیزی سے بنانے کے قابل بناتا ہے اور اخراجات کو 40% تک کم کرتا ہے۔ اس پوسٹ کے لیے، میں آپ کو دکھاتا ہوں کہ گراؤنڈ ٹروتھ آٹو سیگمنٹ فیچر اور مکینیکل ترک ورک فورس کے ساتھ کراؤڈ سورس لیبلنگ کے ساتھ ڈیٹاسیٹ کو دستی طور پر لیبل کرنے کا طریقہ۔
زمینی سچائی کے ساتھ دستی لیبلنگ
دسمبر 2019 میں، گراؤنڈ ٹروتھ نے لیبلنگ تھرو پٹ کو بڑھانے اور درستگی کو بہتر بنانے کے لیے سیمنٹک سیگمنٹیشن لیبلنگ یوزر انٹرفیس میں ایک آٹو سیگمنٹ فیچر شامل کیا۔ مزید معلومات کے لیے رجوع کریں۔ ایمیزون سیج میکر گراؤنڈ ٹروتھ کے ساتھ سیمنٹک سیگمنٹیشن لیبلنگ کرتے وقت آبجیکٹ کو خود سے الگ کرنا. اس نئی خصوصیت کے ساتھ، آپ سیگمنٹیشن کے کاموں پر اپنے لیبلنگ کے عمل کو تیز کر سکتے ہیں۔ کسی تصویر میں کسی شے کو کیپچر کرنے کے لیے ایک مضبوطی سے فٹنگ پولیگون بنانے یا برش ٹول کا استعمال کرنے کے بجائے، آپ صرف چار پوائنٹس کھینچتے ہیں: آبجیکٹ کے سب سے اوپر، سب سے نیچے، بائیں سب سے زیادہ، اور دائیں طرف۔ گراؤنڈ ٹروتھ ان چار پوائنٹس کو ان پٹ کے طور پر لیتا ہے اور ڈیپ ایکسٹریم کٹ (DEXTR) الگورتھم کو استعمال کرتا ہے تاکہ آبجیکٹ کے گرد مضبوطی سے فٹنگ ماسک تیار کیا جا سکے۔ تصویری سیمنٹک سیگمنٹیشن لیبلنگ کے لیے گراؤنڈ ٹروتھ کا استعمال کرتے ہوئے ٹیوٹوریل کے لیے رجوع کریں۔ تصویری سیمنٹک سیگمنٹیشن. مندرجہ ذیل ایک مثال ہے کہ کس طرح آٹو سیگمنٹیشن ٹول آپ کے کسی شے کے چار انتہائی پوائنٹس کو منتخب کرنے کے بعد خود بخود سیگمنٹیشن ماسک تیار کرتا ہے۔


مکینیکل ترک افرادی قوت کے ساتھ کراؤڈ سورسنگ لیبلنگ
اگر آپ کے پاس ایک بڑا ڈیٹاسیٹ ہے اور آپ خود سینکڑوں یا ہزاروں تصاویر کو دستی طور پر لیبل نہیں کرنا چاہتے ہیں، تو آپ مکینیکل ترک استعمال کر سکتے ہیں، جو ایک آن ڈیمانڈ، توسیع پذیر، انسانی افرادی قوت فراہم کرتا ہے تاکہ وہ ملازمتیں مکمل کر سکیں جو انسان کمپیوٹر سے بہتر کر سکتے ہیں۔ مکینیکل ترک سافٹ ویئر ان ہزاروں کارکنوں کو ملازمت کی پیشکشوں کو باضابطہ بناتا ہے جو ان کی سہولت کے مطابق ٹکڑا کام کرنے کو تیار ہیں۔ سافٹ ویئر انجام دیئے گئے کام کو بھی بازیافت کرتا ہے اور اسے آپ کے لیے مرتب کرتا ہے، درخواست گزار، جو کارکنوں کو تسلی بخش کام کے لیے ادائیگی کرتا ہے (صرف)۔ مکینیکل ترک کے ساتھ شروع کرنے کے لیے رجوع کریں۔ ایمیزون مکینیکل ترک کا تعارف.
لیبلنگ کا کام بنائیں
سمندری کچھوے کے ڈیٹاسیٹ کے لیے مکینیکل ترک لیبلنگ کام کی ایک مثال درج ذیل ہے۔ سمندری کچھوے کا ڈیٹاسیٹ Kaggle مقابلہ سے ہے۔ سمندری کچھوے کے چہرے کا پتہ لگانا، اور میں نے مظاہرے کے مقاصد کے لیے ڈیٹاسیٹ کی 300 تصاویر منتخب کیں۔ سمندری کچھوا عوامی ڈیٹاسیٹ میں ایک عام کلاس نہیں ہے لہذا یہ ایسی صورتحال کی نمائندگی کر سکتا ہے جس میں بڑے ڈیٹاسیٹ کو لیبل لگانے کی ضرورت ہوتی ہے۔
- سیج میکر کنسول پر، منتخب کریں۔ لیبلنگ نوکریاں نیوی گیشن پین میں.
- میں سے انتخاب کریں لیبلنگ کا کام بنائیں.
- اپنے کام کے لیے ایک نام درج کریں۔
- کے لئے ان پٹ ڈیٹا سیٹ اپمنتخب خودکار ڈیٹا سیٹ اپ.
یہ ان پٹ ڈیٹا کا ایک مینی فیسٹ تیار کرتا ہے۔ - کے لئے ان پٹ ڈیٹاسیٹس کے لیے S3 مقامڈیٹا سیٹ کے لیے راستہ درج کریں۔

- کے لئے ٹاسک زمرہمنتخب کریں تصویر.
- کے لئے کام کا انتخابمنتخب سنمک تقسیم.

- کے لئے ورکرز کی اقساممنتخب ایمیزون میکانی ترک.
- ٹاسک ٹائم آؤٹ، ٹاسک ختم ہونے کا وقت، اور فی ٹاسک کی قیمت کے لیے اپنی سیٹنگز کو کنفیگر کریں۔

- ایک لیبل شامل کریں (اس پوسٹ کے لیے،
sea turtle)، اور لیبلنگ کی ہدایات فراہم کریں۔ - میں سے انتخاب کریں تخلیق کریں.

لیبلنگ کا کام سیٹ کرنے کے بعد، آپ SageMaker کنسول پر لیبلنگ کی پیشرفت کو چیک کر سکتے ہیں۔ جب اسے مکمل کے طور پر نشان زد کیا جاتا ہے، تو آپ نتائج کو چیک کرنے کے لیے کام کا انتخاب کر سکتے ہیں اور اگلے مراحل کے لیے انہیں استعمال کر سکتے ہیں۔

ڈیٹا سیٹ کی تبدیلی
گراؤنڈ ٹروتھ سے آؤٹ پٹ حاصل کرنے کے بعد، آپ اس ڈیٹاسیٹ پر ماڈل کو تربیت دینے کے لیے SageMaker بلٹ ان الگورتھم استعمال کر سکتے ہیں۔ سب سے پہلے، آپ کو SageMaker سیمنٹک سیگمنٹیشن الگورتھم کے لیے درخواست کردہ ان پٹ انٹرفیس کے طور پر لیبل لگا ڈیٹاسیٹ تیار کرنے کی ضرورت ہے۔
ان پٹ ڈیٹا چینلز کی درخواست کی۔
SageMaker semantic segmentation توقع کرتا ہے کہ آپ کے تربیتی ڈیٹاسیٹ کو محفوظ کیا جائے گا۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3)۔ ایمیزون S3 میں ڈیٹا سیٹ کو دو چینلز میں پیش کیے جانے کی امید ہے، ایک کے لیے train اور ایک کے لئے validationچار ڈائریکٹریز کا استعمال کرتے ہوئے، دو تصاویر کے لیے اور دو تشریحات کے لیے۔ تشریحات کو غیر کمپریسڈ PNG امیجز کی توقع ہے۔ ڈیٹاسیٹ میں ایک لیبل کا نقشہ بھی ہو سکتا ہے جو بیان کرتا ہے کہ تشریحی نقشہ جات کیسے قائم کیے جاتے ہیں۔ اگر نہیں، تو الگورتھم ڈیفالٹ استعمال کرتا ہے۔ اندازہ کے لیے، ایک اختتامی نقطہ ایک کے ساتھ تصاویر کو قبول کرتا ہے۔ image/jpeg مواد کی قسم. مندرجہ ذیل ڈیٹا چینلز کی مطلوبہ ساخت ہے:
ٹرین اور توثیق ڈائریکٹریز میں ہر JPG امیج میں اسی نام کے ساتھ اسی PNG لیبل کی تصویر ہوتی ہے۔ train_annotation اور validation_annotation ڈائریکٹریز نام دینے کا یہ کنونشن الگورتھم کو تربیت کے دوران ایک لیبل کو اس کی متعلقہ تصویر کے ساتھ منسلک کرنے میں مدد کرتا ہے۔ ریل گاڑی، train_annotation، توثیق، اور validation_annotation چینلز لازمی ہیں. تشریحات سنگل چینل PNG امیجز ہیں۔ فارمیٹ تب تک کام کرتا ہے جب تک کہ تصویر میں موجود میٹا ڈیٹا (موڈز) الگورتھم کو تشریحی تصاویر کو سنگل چینل 8 بٹ غیر دستخط شدہ عدد میں پڑھنے میں مدد کرتا ہے۔
گراؤنڈ ٹروتھ لیبلنگ کام سے آؤٹ پٹ
گراؤنڈ ٹروتھ لیبلنگ جاب سے پیدا ہونے والے آؤٹ پٹس میں درج ذیل فولڈر کا ڈھانچہ ہوتا ہے:
سیگمنٹیشن ماسک اس میں محفوظ ہیں۔ s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. ہر تشریحی تصویر ایک .png فائل ہے جس کا نام ماخذ کی تصویر کے اشاریہ اور اس تصویر کے لیبلنگ کے مکمل ہونے کے وقت کے بعد رکھا گیا ہے۔ مثال کے طور پر، مندرجہ ذیل سورس امیج (Image_1.jpg) اور مکینیکل ترک ورک فورس (0_2022-02-10T17:41:04.724225.png) کے ذریعے تیار کردہ اس کا سیگمنٹیشن ماسک ہے۔ نوٹ کریں کہ ماسک کا انڈیکس سورس امیج کے نام میں موجود نمبر سے مختلف ہے۔
 |
 |
لیبلنگ جاب سے آؤٹ پٹ مینی فیسٹ میں ہے۔ /manifests/output/output.manifest فائل یہ ایک JSON فائل ہے، اور ہر لائن سورس امیج اور اس کے لیبل اور دیگر میٹا ڈیٹا کے درمیان میپنگ ریکارڈ کرتی ہے۔ درج ذیل JSON لائن دکھائی گئی سورس امیج اور اس کی تشریح کے درمیان میپنگ کو ریکارڈ کرتی ہے۔
ماخذ کی تصویر کو Image_1.jpg کہا جاتا ہے، اور تشریح کا نام 0_2022-02-10T17:41: 04.724225.png ہے۔ ڈیٹا کو SageMaker semantic segmentation algorithm کے مطلوبہ ڈیٹا چینل فارمیٹس کے طور پر تیار کرنے کے لیے، ہمیں تشریح کا نام تبدیل کرنے کی ضرورت ہے تاکہ اس کا وہی نام ہو جو ماخذ JPG امیجز کا ہے۔ اور ہمیں ڈیٹاسیٹ کو اس میں تقسیم کرنے کی بھی ضرورت ہے۔ train اور validation ماخذ کی تصاویر اور تشریحات کے لیے ڈائریکٹریز۔
گراؤنڈ ٹروتھ لیبلنگ جاب سے آؤٹ پٹ کو مطلوبہ ان پٹ فارمیٹ میں تبدیل کریں۔
آؤٹ پٹ کو تبدیل کرنے کے لیے، درج ذیل مراحل کو مکمل کریں:
- ایمیزون S3 سے لیبلنگ جاب کی تمام فائلوں کو مقامی ڈائریکٹری میں ڈاؤن لوڈ کریں:
- مینی فیسٹ فائل کو پڑھیں اور تشریح کے ناموں کو انہی ناموں میں تبدیل کریں جیسے سورس امیجز:
- ٹرین اور توثیق ڈیٹاسیٹس کو تقسیم کریں:
- سیمنٹک سیگمنٹیشن الگورتھم ڈیٹا چینلز کے لیے مطلوبہ فارمیٹ میں ایک ڈائرکٹری بنائیں:
- ٹرین اور توثیق کی تصاویر اور ان کی تشریحات کو بنائی گئی ڈائریکٹریوں میں منتقل کریں۔
- تصاویر کے لیے، درج ذیل کوڈ کا استعمال کریں:
- تشریحات کے لیے درج ذیل کوڈ کا استعمال کریں:
- ٹرین اور توثیق ڈیٹاسیٹس اور ان کے تشریحی ڈیٹاسیٹس کو Amazon S3 پر اپ لوڈ کریں:
سیج میکر سیمنٹک سیگمنٹیشن ماڈل ٹریننگ
اس سیکشن میں، ہم آپ کے سیمنٹک سیگمنٹیشن ماڈل کو تربیت دینے کے لیے اقدامات کرتے ہیں۔
نمونہ نوٹ بک پر عمل کریں اور ڈیٹا چینلز ترتیب دیں۔
آپ میں دی گئی ہدایات پر عمل کر سکتے ہیں۔ سیمنٹک سیگمنٹیشن الگورتھم اب ایمیزون سیج میکر میں دستیاب ہے۔ اپنے لیبل والے ڈیٹاسیٹ پر سیمنٹک سیگمنٹیشن الگورتھم کو نافذ کرنے کے لیے۔ یہ نمونہ نوٹ بک الگورتھم کو متعارف کرانے والی ایک آخر سے آخر تک مثال دکھاتا ہے۔ نوٹ بک میں، آپ سیکھتے ہیں کہ مکمل طور پر کنولوشنل نیٹ ورک (FCN) الگورتھم کا استعمال کرتے ہوئے پاسکل VOC ڈیٹاسیٹ تربیت کے لیے چونکہ میں پاسکل VOC ڈیٹاسیٹ سے کسی ماڈل کو تربیت دینے کا ارادہ نہیں رکھتا، اس لیے میں نے اس نوٹ بک میں مرحلہ 3 (ڈیٹا کی تیاری) کو چھوڑ دیا۔ اس کے بجائے، میں نے براہ راست تخلیق کیا train_channel, train_annotation_channe, validation_channel، اور validation_annotation_channel S3 مقامات کا استعمال کرتے ہوئے جہاں میں نے اپنی تصاویر اور تشریحات کو محفوظ کیا تھا:
SageMaker تخمینہ کار میں اپنے اپنے ڈیٹاسیٹ کے لیے ہائپر پیرامیٹر کو ایڈجسٹ کریں۔
میں نے نوٹ بک کی پیروی کی اور ایک SageMaker تخمینہ کرنے والا آبجیکٹ بنایا (ss_estimator) میرے سیگمنٹیشن الگورتھم کو تربیت دینے کے لیے۔ ایک چیز جو ہمیں نئے ڈیٹاسیٹ کے لیے اپنی مرضی کے مطابق کرنے کی ضرورت ہے وہ ہے۔ ss_estimator.set_hyperparameters: ہمیں تبدیل کرنے کی ضرورت ہے۔ num_classes=21 کرنے کے لئے num_classes=2 (turtle اور background)، اور میں بھی بدل گیا۔ epochs=10 کرنے کے لئے epochs=30 کیونکہ 10 صرف ڈیمو مقاصد کے لیے ہے۔ پھر میں نے ترتیب دے کر ماڈل ٹریننگ کے لیے p3.2xlarge مثال استعمال کی۔ instance_type="ml.p3.2xlarge". تربیت 8 منٹ میں مکمل ہوئی۔ سب سے اچھا MIoU 0.846 کا (میین انٹرسیکشن اوور یونین) ایک کے ساتھ epoch 11 پر حاصل کیا جاتا ہے pix_acc (آپ کی تصویر میں پکسلز کا فیصد جس کی صحیح درجہ بندی کی گئی ہے) 0.925، جو اس چھوٹے ڈیٹاسیٹ کے لیے بہت اچھا نتیجہ ہے۔
ماڈل قیاس کے نتائج
میں نے کم لاگت ml.c5.xlarge مثال پر ماڈل کی میزبانی کی:
آخر میں، میں نے تربیت یافتہ سیگمنٹیشن ماڈل کا نتیجہ دیکھنے کے لیے کچھوؤں کی 10 تصاویر کا ایک ٹیسٹ سیٹ تیار کیا:
مندرجہ ذیل تصاویر نتائج دکھاتی ہیں۔

سمندری کچھوؤں کے سیگمنٹیشن ماسک درست نظر آتے ہیں اور میں مکینیکل ترک کارکنوں کے لیبل والے 300 امیج ڈیٹاسیٹ پر تربیت یافتہ اس نتیجے سے خوش ہوں۔ آپ دوسرے دستیاب نیٹ ورکس کو بھی دریافت کر سکتے ہیں جیسے پرامڈ منظر پارسنگ نیٹ ورک (PSP) or DeepLab-V3 آپ کے ڈیٹاسیٹ کے ساتھ نمونہ نوٹ بک میں۔
صاف کرو
مسلسل اخراجات سے بچنے کے لیے اختتامی نقطہ کو ختم کر دیں:
نتیجہ
اس پوسٹ میں، میں نے دکھایا کہ SageMaker کا استعمال کرتے ہوئے سیمنٹک سیگمنٹیشن ڈیٹا لیبلنگ اور ماڈل ٹریننگ کو کس طرح اپنی مرضی کے مطابق بنایا جائے۔ سب سے پہلے، آپ آٹو سیگمنٹیشن ٹول کے ساتھ لیبلنگ کا کام ترتیب دے سکتے ہیں یا مکینیکل ترک ورک فورس (نیز دیگر اختیارات) استعمال کر سکتے ہیں۔ اگر آپ کے پاس 5,000 سے زیادہ اشیاء ہیں، تو آپ خودکار ڈیٹا لیبلنگ بھی استعمال کر سکتے ہیں۔ پھر آپ اپنے گراؤنڈ ٹروتھ لیبلنگ جاب سے آؤٹ پٹس کو سیج میکر بلٹ ان سیمنٹک سیگمنٹیشن ٹریننگ کے لیے مطلوبہ ان پٹ فارمیٹس میں تبدیل کرتے ہیں۔ اس کے بعد، آپ ایک تیز رفتار کمپیوٹنگ مثال (جیسے p2 یا p3) کو درج ذیل کے ساتھ سیمنٹک سیگمنٹیشن ماڈل کو تربیت دینے کے لیے استعمال کر سکتے ہیں۔ نوٹ بک اور ماڈل کو زیادہ کفایتی مثال (جیسے ml.c5.xlarge) پر تعینات کریں۔ آخر میں، آپ کوڈ کی چند سطروں کے ساتھ اپنے ٹیسٹ ڈیٹاسیٹ پر نتائج کا جائزہ لے سکتے ہیں۔
SageMaker semantic segmentation کے ساتھ شروع کریں۔ ڈیٹا لیبلنگ اور ماڈل کی تربیت اپنے پسندیدہ ڈیٹاسیٹ کے ساتھ!
مصنف کے بارے میں
 کارا یانگ AWS پروفیشنل سروسز میں ڈیٹا سائنٹسٹ ہے۔ وہ AWS کلاؤڈ سروسز کے ساتھ صارفین کو ان کے کاروباری اہداف حاصل کرنے میں مدد کرنے کے بارے میں پرجوش ہے۔ اس نے تنظیموں کو متعدد صنعتوں جیسے مینوفیکچرنگ، آٹوموٹیو، ماحولیاتی پائیداری اور ایرو اسپیس میں ایم ایل سلوشنز بنانے میں مدد کی ہے۔
کارا یانگ AWS پروفیشنل سروسز میں ڈیٹا سائنٹسٹ ہے۔ وہ AWS کلاؤڈ سروسز کے ساتھ صارفین کو ان کے کاروباری اہداف حاصل کرنے میں مدد کرنے کے بارے میں پرجوش ہے۔ اس نے تنظیموں کو متعدد صنعتوں جیسے مینوفیکچرنگ، آٹوموٹیو، ماحولیاتی پائیداری اور ایرو اسپیس میں ایم ایل سلوشنز بنانے میں مدد کی ہے۔
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- ہمارے بارے میں
- رفتار کو تیز تر
- تیز
- درست
- حاصل
- حاصل کیا
- کے پار
- شامل کیا
- ایرواسپیس
- یلگورتم
- یلگوردمز
- تمام
- ایمیزون
- کا اعلان کیا ہے
- ایک اور
- ارد گرد
- ایسوسی ایٹ
- آٹومیٹڈ
- خود کار طریقے سے
- آٹوموٹو
- دستیاب
- AWS
- پس منظر
- کیونکہ
- BEST
- بہتر
- کے درمیان
- تعمیر
- تعمیر میں
- کاروبار
- قبضہ
- کیس
- کچھ
- تبدیل
- چینل
- میں سے انتخاب کریں
- طبقے
- کلاس
- درجہ بندی
- بادل
- بادل کی خدمات
- کوڈ
- کامن
- مقابلہ
- مکمل
- کمپیوٹر
- کمپیوٹر
- کمپیوٹنگ
- آپکا اعتماد
- کنسول
- مواد
- سہولت
- اسی کے مطابق
- سرمایہ کاری مؤثر
- اخراجات
- تخلیق
- بنائی
- گاہکوں
- اپنی مرضی کے مطابق
- اعداد و شمار
- ڈیٹا سائنسدان
- گہری
- مظاہرہ
- تعیناتی
- مختلف
- براہ راست
- ڈرائنگ
- کے دوران
- ہر ایک
- کے قابل بناتا ہے
- آخر سے آخر تک
- اختتام پوائنٹ
- درج
- ماحولیاتی
- قائم
- مثال کے طور پر
- اس کے علاوہ
- توقع
- امید ہے
- تلاش
- انتہائی
- چہرہ
- نمایاں کریں
- پہلا
- پر عمل کریں
- کے بعد
- فارمیٹ
- سے
- پیدا
- اہداف
- اچھا
- بھوری رنگ
- عظیم
- خوش
- مدد
- مدد
- مدد کرتا ہے
- اعلی معیار کی
- میزبانی کی
- کس طرح
- کیسے
- HTTPS
- انسانی
- انسان
- سینکڑوں
- تصویر
- تصاویر
- پر عملدرآمد
- کو بہتر بنانے کے
- شامل
- شامل
- اضافہ
- انڈکس
- صنعتوں
- معلومات
- ان پٹ
- مثال کے طور پر
- انٹرفیس
- چوراہا
- متعارف کرانے
- IT
- ایوب
- نوکریاں
- جانا جاتا ہے
- لیبل
- لیبل
- لیبل
- بڑے
- شروع
- جانیں
- سیکھنے
- سطح
- لمیٹڈ
- لائن
- لائنوں
- لسٹ
- مقامی
- محل وقوع
- مقامات
- لانگ
- دیکھو
- مشین
- مشین لرننگ
- انتظام
- لازمی
- دستی طور پر
- مینوفیکچرنگ
- نقشہ
- تعریفیں
- ماسک
- ماسک
- بڑے پیمانے پر
- میکانی
- شاید
- ML
- ماڈل
- ماڈل
- زیادہ
- ایک سے زیادہ
- نام
- نام
- سمت شناسی
- نیٹ ورک
- نیٹ ورک
- اگلے
- نوٹ بک
- تعداد
- تجویز
- اختیار
- آپشنز کے بھی
- تنظیمیں
- دیگر
- خود
- جذباتی
- فیصد
- کارکردگی کا مظاہرہ
- پوائنٹس
- کثیرالاضلاع
- مقبول
- تیار
- خوبصورت
- قیمت
- نجی
- عمل
- پیدا
- پیشہ ورانہ
- فراہم
- فراہم کرتا ہے
- عوامی
- مقاصد
- جلدی سے
- RE
- ریکارڈ
- کی نمائندگی
- ضرورت
- کی ضرورت ہے
- نتائج کی نمائش
- کا جائزہ لینے کے
- اسی
- توسیع پذیر
- سائنسدان
- سمندر
- انقطاع
- منتخب
- سروس
- سروسز
- مقرر
- قائم کرنے
- سیکنڈ اور
- دکھائیں
- دکھایا گیا
- سادہ
- صورتحال
- چھوٹے
- So
- سافٹ ویئر کی
- حل
- تقسیم
- شروع
- ذخیرہ
- پائیداری
- ہدف
- کاموں
- ٹیم
- ٹیسٹ
- ۔
- ماخذ
- بات
- تیسری پارٹی
- ہزاروں
- کے ذریعے
- تھرو پٹ
- وقت
- کے آلے
- ٹرین
- ٹریننگ
- تبدیل
- یونین
- استعمال کی شرائط
- توثیق
- دکانداروں
- نقطہ نظر
- ڈبلیو
- کام
- کارکنوں
- افرادی قوت۔
- کام کرتا ہے
- اور