جب اوپنائی جولائی 2020 میں اپنے مشین لرننگ (ML) ماڈل کی تیسری نسل جاری کی جو ٹیکسٹ جنریشن میں مہارت رکھتی ہے، میں جانتا تھا کہ کچھ مختلف ہے۔ اس ماڈل نے ایسے اعصاب کو مارا جو اس سے پہلے کوئی نہیں آیا تھا۔ اچانک میں نے دوستوں اور ساتھیوں کو سنا، جو ٹیکنالوجی میں دلچسپی رکھتے ہیں لیکن عام طور پر AI/ML کی جگہ میں ہونے والی تازہ ترین پیشرفت کی زیادہ پرواہ نہیں کرتے، اس کے بارے میں بات کرتے ہیں۔ یہاں تک کہ گارڈین نے لکھا ایک مضمون اس کے بارے میں. یا، عین مطابق ہونے کے لیے، the ماڈل مضمون لکھا اور گارڈین نے اسے ایڈٹ کرکے شائع کیا۔ اس سے انکار نہیں تھا - GPT-3 گیم چینجر تھا۔
ماڈل کے جاری ہونے کے بعد، لوگوں نے فوری طور پر اس کے لیے ممکنہ درخواستیں لینا شروع کر دیں۔ ہفتوں کے اندر، بہت سے متاثر کن ڈیمو بنائے گئے، جو کہ پر مل سکتے ہیں۔ GPT-3 ویب سائٹ. ایک خاص ایپلی کیشن جس نے میری آنکھ پکڑی۔ متن کا خلاصہ - دیئے گئے متن کو پڑھنے اور اس کے مواد کا خلاصہ کرنے کے لئے کمپیوٹر کی صلاحیت۔ یہ کمپیوٹر کے لیے سب سے مشکل کاموں میں سے ایک ہے کیونکہ یہ نیچرل لینگویج پروسیسنگ (NLP) کے شعبے میں دو شعبوں کو یکجا کرتا ہے: پڑھنے کی سمجھ اور متن کی تخلیق۔ یہی وجہ ہے کہ میں متن کے خلاصے کے لیے GPT-3 ڈیمو سے بہت متاثر ہوا۔
آپ ان کو آزما سکتے ہیں۔ ہگنگ فیس اسپیس ویب سائٹ. اس وقت میرا پسندیدہ ایک ہے۔ درخواست جو صرف ان پٹ کے بطور مضمون کے URL کے ساتھ خبروں کے مضامین کے خلاصے تیار کرتا ہے۔
اس دو حصوں کی سیریز میں، میں تنظیموں کے لیے ایک عملی گائیڈ تجویز کرتا ہوں تاکہ آپ اپنے ڈومین کے لیے ٹیکسٹ سمریائزیشن ماڈلز کے معیار کا اندازہ لگا سکیں۔
ٹیوٹوریل کا جائزہ
بہت سی تنظیمیں جن کے ساتھ میں کام کرتا ہوں (خیرات، کمپنیاں، این جی اوز) ان کے پاس متن کی بڑی مقدار ہوتی ہے جنہیں پڑھنے اور خلاصہ کرنے کی ضرورت ہوتی ہے – مالیاتی رپورٹس یا خبریں، سائنسی تحقیقی مقالے، پیٹنٹ کی درخواستیں، قانونی معاہدے، اور بہت کچھ۔ قدرتی طور پر، یہ تنظیمیں NLP ٹیکنالوجی کے ساتھ ان کاموں کو خودکار کرنے میں دلچسپی رکھتی ہیں۔ ممکنہ فن کا مظاہرہ کرنے کے لیے، میں اکثر متن کا خلاصہ ڈیمو استعمال کرتا ہوں، جو متاثر کرنے میں تقریباً کبھی ناکام نہیں ہوتے۔
لیکن اب کیا؟
ان تنظیموں کے لیے چیلنج یہ ہے کہ وہ متن کے خلاصے کے ماڈلز کا اندازہ لگانا چاہتے ہیں جو کہ ایک وقت میں ایک نہیں بلکہ بہت ساری دستاویزات کے خلاصوں پر مبنی ہیں۔ وہ کسی ایسے انٹرن کی خدمات حاصل نہیں کرنا چاہتے جس کا واحد کام درخواست کو کھولنا، کسی دستاویز میں چسپاں کرنا، دبانا ہے۔ مختصر بٹن، آؤٹ پٹ کا انتظار کریں، اندازہ لگائیں کہ آیا خلاصہ اچھا ہے، اور ہزاروں دستاویزات کے لیے یہ سب دوبارہ کریں۔
میں نے یہ ٹیوٹوریل چار ہفتے پہلے اپنے ماضی کی ذات کو ذہن میں رکھتے ہوئے لکھا تھا – یہ وہ ٹیوٹوریل ہے کاش جب میں نے اس سفر کا آغاز کیا تو میں واپس آتا۔ اس لحاظ سے، اس ٹیوٹوریل کا ہدف سامعین وہ ہے جو AI/ML سے واقف ہے اور اس سے پہلے ٹرانسفارمر ماڈل استعمال کر چکا ہے، لیکن وہ اپنے متن کے خلاصے کے سفر کے آغاز میں ہے اور اس میں مزید گہرائی میں جانا چاہتا ہے۔ چونکہ یہ ایک "ابتدائی" کے ذریعہ لکھا گیا ہے اور ابتدائیوں کے لئے، میں اس حقیقت پر زور دینا چاہتا ہوں کہ یہ ٹیوٹوریل a عملی گائیڈ - نہیں la عملی گائیڈ. براہ کرم اس کے ساتھ سلوک کریں۔ جارج ای پی باکس کہا تھا:
![]()
اس ٹیوٹوریل میں کتنی تکنیکی معلومات کی ضرورت ہے اس لحاظ سے: اس میں Python میں کچھ کوڈنگ شامل ہے، لیکن زیادہ تر وقت ہم صرف APIs کو کال کرنے کے لیے کوڈ کا استعمال کرتے ہیں، اس لیے کوڈنگ کے گہرے علم کی بھی ضرورت نہیں ہے۔ ML کے کچھ تصورات سے واقف ہونا مددگار ہے، جیسے کہ اس کا کیا مطلب ہے۔ ٹرین اور تعیناتی ایک ماڈل، کے تصورات تربیت, توثیق، اور ٹیسٹ ڈیٹاسیٹ، اور اسی طرح. کے ساتھ dabbled ہونے کے علاوہ ٹرانسفارمرز لائبریری پہلے مفید ہو سکتا ہے، کیونکہ ہم اس ٹیوٹوریل میں اس لائبریری کو بڑے پیمانے پر استعمال کرتے ہیں۔ میں ان تصورات کو مزید پڑھنے کے لیے مفید لنکس بھی شامل کرتا ہوں۔
چونکہ یہ ٹیوٹوریل ایک مبتدی نے لکھا ہے، میں توقع نہیں کرتا کہ NLP ماہرین اور اعلیٰ درجے کے ڈیپ لرننگ پریکٹیشنرز اس ٹیوٹوریل کا زیادہ حصہ حاصل کریں گے۔ کم از کم تکنیکی نقطہ نظر سے نہیں – آپ اب بھی پڑھنے سے لطف اندوز ہو سکتے ہیں، تاہم، اس لیے براہ کرم ابھی مت چھوڑیں! لیکن آپ کو میری آسانیاں کے حوالے سے صبر کرنا پڑے گا - میں نے اس ٹیوٹوریل میں ہر چیز کو ممکن حد تک آسان بنانے کے تصور کے مطابق رہنے کی کوشش کی، لیکن آسان نہیں۔
اس ٹیوٹوریل کی ساخت
یہ سلسلہ چار حصوں پر پھیلا ہوا ہے جس کو دو خطوط میں تقسیم کیا گیا ہے، جس میں ہم متن کے خلاصے کے منصوبے کے مختلف مراحل سے گزرتے ہیں۔ پہلی پوسٹ (سیکشن 1) میں، ہم متن کے خلاصے کے کاموں کے لیے ایک میٹرک متعارف کرواتے ہوئے شروع کرتے ہیں - کارکردگی کا ایک پیمانہ جو ہمیں اندازہ لگانے کی اجازت دیتا ہے کہ خلاصہ اچھا ہے یا برا۔ ہم اس ڈیٹاسیٹ کو بھی متعارف کراتے ہیں جسے ہم خلاصہ کرنا چاہتے ہیں اور no-ML ماڈل کا استعمال کرتے ہوئے ایک بیس لائن بنانا چاہتے ہیں - ہم دیئے گئے متن سے خلاصہ تیار کرنے کے لیے ایک سادہ heuristic کا استعمال کرتے ہیں۔ اس بیس لائن کو بنانا کسی بھی ML پروجیکٹ میں ایک انتہائی اہم قدم ہے کیونکہ یہ ہمیں اس بات کا اندازہ لگانے کے قابل بناتا ہے کہ ہم آگے بڑھ کر AI کا استعمال کرکے کتنی ترقی کرتے ہیں۔ یہ ہمیں اس سوال کا جواب دینے کی اجازت دیتا ہے کہ "کیا یہ واقعی AI ٹیکنالوجی میں سرمایہ کاری کے قابل ہے؟"
دوسری پوسٹ میں، ہم ایک ایسے ماڈل کا استعمال کرتے ہیں جو خلاصہ بنانے کے لیے پہلے سے تربیت یافتہ ہے (سیکشن 2)۔ یہ ML میں ایک جدید نقطہ نظر کے ساتھ ممکن ہے۔ منتقلی سیکھنے. یہ ایک اور مفید قدم ہے کیونکہ ہم بنیادی طور پر ایک آف دی شیلف ماڈل لیتے ہیں اور اسے اپنے ڈیٹاسیٹ پر جانچتے ہیں۔ یہ ہمیں ایک اور بیس لائن بنانے کی اجازت دیتا ہے، جس سے ہمیں یہ دیکھنے میں مدد ملتی ہے کہ جب ہم واقعی اپنے ڈیٹاسیٹ پر ماڈل کو تربیت دیتے ہیں تو کیا ہوتا ہے۔ نقطہ نظر کہا جاتا ہے صفر شاٹ خلاصہ، کیونکہ ماڈل کو ہمارے ڈیٹاسیٹ میں صفر کی نمائش ہوئی ہے۔
اس کے بعد، یہ پہلے سے تربیت یافتہ ماڈل کو استعمال کرنے اور اسے اپنے ڈیٹا سیٹ (سیکشن 3) پر تربیت دینے کا وقت ہے۔ اسے بھی کہتے ہیں۔ ٹھیک ٹیوننگ. یہ ماڈل کو ہمارے ڈیٹا کے نمونوں اور محاورات سے سیکھنے اور آہستہ آہستہ اس کے مطابق ڈھالنے کے قابل بناتا ہے۔ ماڈل کو تربیت دینے کے بعد، ہم اسے خلاصے بنانے کے لیے استعمال کرتے ہیں (سیکشن 4)۔
: مختصر
- حصہ 1:
- سیکشن 1: بیس لائن قائم کرنے کے لیے No-ML ماڈل استعمال کریں۔
- حصہ 2:
- سیکشن 2: زیرو شاٹ ماڈل کے ساتھ خلاصے تیار کریں۔
- سیکشن 3: خلاصہ ماڈل کو تربیت دیں۔
- سیکشن 4: تربیت یافتہ ماڈل کا اندازہ لگائیں۔
اس ٹیوٹوریل کا پورا کوڈ درج ذیل میں دستیاب ہے۔ GitHub repo.
اس ٹیوٹوریل کے اختتام تک ہم نے کیا حاصل کیا ہوگا؟
اس ٹیوٹوریل کے اختتام تک، ہم نہیں کرے گا ایک متن کا خلاصہ ماڈل ہے جو پیداوار میں استعمال کیا جا سکتا ہے. ہمارے پاس ایک بھی نہیں ہوگا۔ اچھا خلاصہ ماڈل (یہاں scream emoji داخل کریں)!
اس کے بجائے ہمارے پاس جو ہوگا وہ پروجیکٹ کے اگلے مرحلے کا نقطہ آغاز ہے، جو کہ تجرباتی مرحلہ ہے۔ یہ وہ جگہ ہے جہاں ڈیٹا سائنس میں "سائنس" آتا ہے، کیونکہ اب یہ سب کچھ مختلف ماڈلز اور مختلف سیٹنگز کے ساتھ تجربہ کرنے کے بارے میں ہے تاکہ یہ سمجھا جا سکے کہ آیا دستیاب ٹریننگ ڈیٹا کے ساتھ ایک اچھا خلاصہ ماڈل تیار کیا جا سکتا ہے۔
اور، مکمل طور پر شفاف ہونے کے لیے، اس نتیجے پر پہنچنے کا ایک اچھا موقع ہے کہ ٹیکنالوجی ابھی تیار نہیں ہوئی ہے اور یہ کہ اس منصوبے کو نافذ نہیں کیا جائے گا۔ اور آپ کو اپنے کاروباری اسٹیک ہولڈرز کو اس امکان کے لیے تیار کرنا ہوگا۔ لیکن یہ ایک اور پوسٹ کا موضوع ہے۔
سیکشن 1: بیس لائن قائم کرنے کے لیے No-ML ماڈل استعمال کریں۔
یہ ہمارے ٹیوٹوریل کا پہلا سیکشن ہے جس میں ٹیکسٹ سمریائزیشن پروجیکٹ ترتیب دیا گیا ہے۔ اس سیکشن میں، ہم اصل میں ML استعمال کیے بغیر، ایک بہت ہی آسان ماڈل کا استعمال کرتے ہوئے ایک بیس لائن قائم کرتے ہیں۔ یہ کسی بھی ML پروجیکٹ میں ایک بہت اہم قدم ہے، کیونکہ یہ ہمیں یہ سمجھنے کی اجازت دیتا ہے کہ پروجیکٹ کے وقت کے ساتھ ساتھ ML کتنی قدر میں اضافہ کرتا ہے اور کیا اس میں سرمایہ کاری کرنے کے قابل ہے۔
ٹیوٹوریل کا کوڈ درج ذیل میں پایا جا سکتا ہے۔ GitHub repo.
ڈیٹا، ڈیٹا، ڈیٹا
ہر ایم ایل پروجیکٹ ڈیٹا سے شروع ہوتا ہے! اگر ممکن ہو تو، ہمیں ہمیشہ اس سے متعلق ڈیٹا کا استعمال کرنا چاہیے جو ہم ٹیکسٹ سمریائزیشن پروجیکٹ کے ساتھ حاصل کرنا چاہتے ہیں۔ مثال کے طور پر، اگر ہمارا مقصد پیٹنٹ ایپلی کیشنز کا خلاصہ کرنا ہے، تو ہمیں ماڈل کی تربیت کے لیے پیٹنٹ ایپلی کیشنز کا بھی استعمال کرنا چاہیے۔ ایم ایل پروجیکٹ کے لیے ایک بڑا انتباہ یہ ہے کہ تربیتی ڈیٹا کو عام طور پر لیبل لگانے کی ضرورت ہوتی ہے۔ متن کے خلاصہ کے تناظر میں، اس کا مطلب ہے کہ ہمیں خلاصہ کرنے کے لیے متن کے ساتھ ساتھ خلاصہ (لیبل) بھی فراہم کرنے کی ضرورت ہے۔ صرف دونوں فراہم کرنے سے ہی ماڈل سیکھ سکتا ہے کہ ایک اچھا خلاصہ کیسا لگتا ہے۔
اس ٹیوٹوریل میں، ہم عوامی طور پر دستیاب ڈیٹاسیٹ کا استعمال کرتے ہیں، لیکن اگر ہم اپنی مرضی کے مطابق یا نجی ڈیٹاسیٹ کا استعمال کرتے ہیں تو مراحل اور کوڈ بالکل وہی رہتے ہیں۔ اور ایک بار پھر، اگر آپ کے ذہن میں اپنے متن کے خلاصے کے ماڈل کے لیے کوئی مقصد ہے اور آپ کے پاس متعلقہ ڈیٹا ہے، تو براہ کرم اس سے زیادہ سے زیادہ فائدہ اٹھانے کے بجائے اپنا ڈیٹا استعمال کریں۔
ہم جو ڈیٹا استعمال کرتے ہیں وہ ہے۔ arXiv ڈیٹاسیٹ، جس میں arXiv پیپرز کے خلاصہ کے ساتھ ساتھ ان کے عنوانات بھی شامل ہیں۔ اپنے مقصد کے لیے، ہم خلاصہ کو بطور متن استعمال کرتے ہیں جسے ہم خلاصہ کرنا چاہتے ہیں اور عنوان کو بطور حوالہ خلاصہ۔ ڈیٹا کو ڈاؤن لوڈ اور پری پروسیسنگ کے تمام مراحل درج ذیل میں دستیاب ہیں۔ نوٹ بک. ہمیں ایک کی ضرورت ہے۔ AWS شناخت اور رسائی کا انتظام (IAM) کا کردار جو ڈیٹا کو لوڈ کرنے کی اجازت دیتا ہے۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) اس نوٹ بک کو کامیابی سے چلانے کے لیے۔ ڈیٹاسیٹ کو کاغذ کے حصے کے طور پر تیار کیا گیا تھا۔ ڈیٹا سیٹ کے طور پر ArXiv کے استعمال پر اور کے تحت لائسنس یافتہ ہے۔ Creative Commons CC0 1.0 یونیورسل پبلک ڈومین ڈیڈیکیشن.
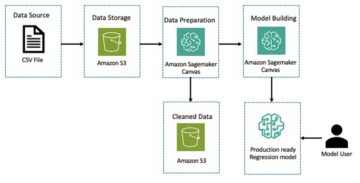
ڈیٹا کو تین ڈیٹا سیٹس میں تقسیم کیا گیا ہے: تربیت، توثیق، اور ٹیسٹ ڈیٹا۔ اگر آپ اپنا ڈیٹا استعمال کرنا چاہتے ہیں تو یقینی بنائیں کہ ایسا بھی ہے۔ درج ذیل خاکہ اس بات کی وضاحت کرتا ہے کہ ہم مختلف ڈیٹاسیٹس کو کس طرح استعمال کرتے ہیں۔
![]()
قدرتی طور پر، اس وقت ایک عام سوال یہ ہے کہ: ہمیں کتنے ڈیٹا کی ضرورت ہے؟ جیسا کہ آپ شاید پہلے ہی اندازہ لگا سکتے ہیں، جواب ہے: یہ منحصر ہے۔ یہ اس بات پر منحصر ہے کہ ڈومین کتنا ماہر ہے (پیٹنٹ ایپلی کیشنز کا خلاصہ نیوز آرٹیکلز کا خلاصہ کرنے سے بالکل مختلف ہے)، ماڈل کو کارآمد ہونے کے لیے کتنا درست ہونا چاہیے، ماڈل کی تربیت پر کتنا خرچ ہونا چاہیے، وغیرہ۔ ہم بعد میں اس سوال پر واپس آتے ہیں جب ہم اصل میں ماڈل کو تربیت دیتے ہیں، لیکن اس کا مختصر یہ ہے کہ جب ہم پروجیکٹ کے تجرباتی مرحلے میں ہوں تو ہمیں مختلف ڈیٹاسیٹ کے سائز کو آزمانا پڑتا ہے۔
کیا ایک اچھا ماڈل بناتا ہے؟
بہت سے ML پروجیکٹس میں، ماڈل کی کارکردگی کی پیمائش کرنا بالکل سیدھا ہے۔ اس کی وجہ یہ ہے کہ عام طور پر اس بارے میں تھوڑا سا ابہام ہوتا ہے کہ آیا ماڈل کا نتیجہ درست ہے۔ ڈیٹاسیٹ میں لیبل اکثر بائنری ہوتے ہیں (سچ/غلط، ہاں/نہیں) یا واضح۔ کسی بھی صورت میں، اس منظر نامے میں ماڈل کے آؤٹ پٹ کا لیبل سے موازنہ کرنا اور اسے صحیح یا غلط کے بطور نشان زد کرنا آسان ہے۔
متن تیار کرتے وقت، یہ زیادہ مشکل ہو جاتا ہے۔ ہم اپنے ڈیٹاسیٹ میں جو خلاصے (لیبلز) فراہم کرتے ہیں وہ متن کا خلاصہ کرنے کا صرف ایک طریقہ ہے۔ لیکن دیئے گئے متن کا خلاصہ کرنے کے بہت سے امکانات ہیں۔ لہذا، یہاں تک کہ اگر ماڈل ہمارے لیبل 1:1 سے میل نہیں کھاتا ہے، تب بھی آؤٹ پٹ ایک درست اور مفید خلاصہ ہو سکتا ہے۔ تو ہم اپنے فراہم کردہ ماڈل کے خلاصے کا موازنہ کیسے کریں؟ ایک ماڈل کے معیار کی پیمائش کے لیے متن کے خلاصے میں اکثر استعمال ہونے والا میٹرک ہے۔ ROUGE سکور. اس میٹرک کی میکانکس کو سمجھنے کے لیے رجوع کریں۔ NLP میں الٹیمیٹ پرفارمنس میٹرک. خلاصہ طور پر، ROUGE سکور کے اوورلیپ کی پیمائش کرتا ہے۔ این گرام (مسلسل ترتیب n آئٹمز) ماڈل کے خلاصے (امیدوار کا خلاصہ) اور حوالہ کے خلاصے کے درمیان (جو لیبل ہم اپنے ڈیٹاسیٹ میں فراہم کرتے ہیں)۔ لیکن، یقینا، یہ ایک مکمل پیمائش نہیں ہے. اس کی حدود کو سمجھنے کے لیے، چیک آؤٹ کریں۔ ROUGE یا ROUGE کو نہیں؟
تو، ہم ROUGE سکور کا حساب کیسے لگاتے ہیں؟ اس میٹرک کی گنتی کرنے کے لیے بہت سے Python پیکجز موجود ہیں۔ مستقل مزاجی کو یقینی بنانے کے لیے، ہمیں اپنے پورے پروجیکٹ میں ایک ہی طریقہ استعمال کرنا چاہیے۔ کیونکہ ہم، اس ٹیوٹوریل کے بعد میں، اپنے لکھنے کے بجائے ٹرانسفارمرز لائبریری سے تربیتی اسکرپٹ استعمال کریں گے، ہم صرف اس میں جھانک سکتے ہیں۔ ماخذ کوڈ اسکرپٹ کا اور اس کوڈ کو کاپی کریں جو ROUGE سکور کی گنتی کرتا ہے:
اسکور کا حساب لگانے کے لیے اس طریقہ کو استعمال کرتے ہوئے، ہم اس بات کو یقینی بناتے ہیں کہ ہم ہمیشہ سیب کا موازنہ پورے پروجیکٹ میں سیب سے کریں۔
یہ فنکشن کئی ROUGE سکور کی گنتی کرتا ہے: rouge1, rouge2, rougeL، اور rougeLsum. "جمع" میں rougeLsum اس حقیقت کی طرف اشارہ کرتا ہے کہ اس میٹرک کو پورے خلاصے پر شمار کیا جاتا ہے، جبکہ rougeL انفرادی جملوں پر اوسط کے طور پر شمار کیا جاتا ہے۔ تو، ہمیں اپنے پروجیکٹ کے لیے کون سا ROUGE سکور استعمال کرنا چاہیے؟ ایک بار پھر، ہمیں تجرباتی مرحلے میں مختلف طریقوں کو آزمانا ہوگا۔ اس کے قابل کیا ہے کے لئے، اصل ROUGE کاغذ بیان کرتا ہے کہ "ROUGE-2 اور ROUGE-L نے واحد دستاویز کے خلاصے کے کاموں میں اچھی طرح سے کام کیا" جبکہ "ROUGE-1 اور ROUGE-L مختصر خلاصوں کا جائزہ لینے میں بہترین کارکردگی کا مظاہرہ کرتے ہیں۔"
بیس لائن بنائیں
اس کے بعد ہم ایک سادہ، no-ML ماڈل کا استعمال کرکے بیس لائن بنانا چاہتے ہیں۔ اس کا کیا مطلب ہے؟ متن کے خلاصے کے میدان میں، بہت سے مطالعات ایک بہت ہی آسان طریقہ استعمال کرتے ہیں: وہ سب سے پہلے لیتے ہیں۔ n متن کے جملے اور اسے امیدوار کا خلاصہ قرار دیں۔ اس کے بعد وہ امیدوار کے خلاصے کا حوالہ کے خلاصے سے موازنہ کرتے ہیں اور ROUGE سکور کا حساب لگاتے ہیں۔ یہ ایک سادہ لیکن طاقتور طریقہ ہے جسے ہم کوڈ کی چند سطروں میں لاگو کر سکتے ہیں (اس حصے کا پورا کوڈ درج ذیل ہے نوٹ بک):
ہم اس تشخیص کے لیے ٹیسٹ ڈیٹاسیٹ استعمال کرتے ہیں۔ یہ سمجھ میں آتا ہے کیونکہ ماڈل کو تربیت دینے کے بعد، ہم حتمی تشخیص کے لیے وہی ٹیسٹ ڈیٹا سیٹ بھی استعمال کرتے ہیں۔ ہم مختلف نمبروں کے لیے بھی کوشش کرتے ہیں۔ n: ہم امیدوار کے خلاصے کے طور پر صرف پہلے جملے سے شروع کرتے ہیں، پھر پہلے دو جملے، اور آخر میں پہلے تین جملے۔
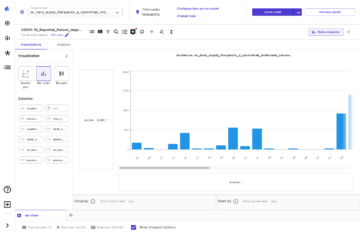
مندرجہ ذیل اسکرین شاٹ ہمارے پہلے ماڈل کے نتائج دکھاتا ہے۔
![]()
ROUGE کے اسکور سب سے زیادہ ہیں، امیدوار کے خلاصے کے طور پر صرف پہلا جملہ ہے۔ اس کا مطلب ہے کہ ایک سے زیادہ جملے لینے سے خلاصہ بہت زیادہ لفظی ہو جاتا ہے اور اسکور کم ہو جاتا ہے۔ تو اس کا مطلب ہے کہ ہم ایک جملے کے خلاصے کے اسکور کو اپنی بنیادی لائن کے طور پر استعمال کریں گے۔
یہ نوٹ کرنا ضروری ہے کہ، اس طرح کے ایک سادہ نقطہ نظر کے لیے، یہ نمبر دراصل کافی اچھے ہیں، خاص طور پر کے لیے rouge1 سکور ان نمبروں کو سیاق و سباق میں ڈالنے کے لیے، ہم حوالہ دے سکتے ہیں۔ پیگاسس ماڈلز، جو مختلف ڈیٹا سیٹس کے لیے جدید ترین ماڈل کے اسکور دکھاتا ہے۔
نتیجہ اور آگے کیا ہے۔
ہماری سیریز کے حصہ 1 میں، ہم نے ڈیٹاسیٹ متعارف کرایا جسے ہم خلاصہ کے منصوبے میں استعمال کرتے ہیں اور ساتھ ہی خلاصوں کا جائزہ لینے کے لیے ایک میٹرک۔ اس کے بعد ہم نے ایک سادہ، no-ML ماڈل کے ساتھ درج ذیل بیس لائن بنائی۔
![]()
میں اگلی پوسٹ، ہم ایک زیرو شاٹ ماڈل استعمال کرتے ہیں – خاص طور پر، ایک ایسا ماڈل جسے خاص طور پر عوامی خبروں کے مضامین پر متن کے خلاصے کے لیے تربیت دی گئی ہے۔ تاہم، اس ماڈل کو ہمارے ڈیٹاسیٹ پر بالکل بھی تربیت نہیں دی جائے گی (اس لیے نام "زیرو شاٹ")۔
میں اسے ہوم ورک کے طور پر آپ پر چھوڑتا ہوں کہ اس بات کا اندازہ لگائیں کہ یہ زیرو شاٹ ماڈل ہماری انتہائی سادہ بیس لائن کے مقابلے میں کیسا کارکردگی دکھائے گا۔ ایک طرف، یہ ایک بہت زیادہ نفیس ماڈل ہوگا (یہ دراصل ایک نیورل نیٹ ورک ہے)۔ دوسری طرف، یہ صرف خبروں کے مضامین کا خلاصہ کرنے کے لیے استعمال ہوتا ہے، اس لیے یہ ان نمونوں کے ساتھ جدوجہد کر سکتا ہے جو arXiv ڈیٹاسیٹ میں شامل ہیں۔
مصنف کے بارے میں
![]() ہیکو ہوٹز اے آئی اور مشین لرننگ کے سینئر سولیوشن آرکیٹیکٹ ہیں اور AWS کے اندر نیچرل لینگویج پروسیسنگ (NLP) کمیونٹی کی رہنمائی کرتے ہیں۔ اس کردار سے پہلے، وہ ایمیزون کی EU کسٹمر سروس کے ڈیٹا سائنس کے سربراہ تھے۔ Heiko ہمارے صارفین کو AWS پر ان کے AI/ML سفر میں کامیاب ہونے میں مدد کرتا ہے اور اس نے کئی صنعتوں میں تنظیموں کے ساتھ کام کیا ہے، بشمول انشورنس، مالیاتی خدمات، میڈیا اور تفریح، صحت کی دیکھ بھال، یوٹیلٹیز، اور مینوفیکچرنگ۔ اپنے فارغ وقت میں ہیکو زیادہ سے زیادہ سفر کرتا ہے۔
ہیکو ہوٹز اے آئی اور مشین لرننگ کے سینئر سولیوشن آرکیٹیکٹ ہیں اور AWS کے اندر نیچرل لینگویج پروسیسنگ (NLP) کمیونٹی کی رہنمائی کرتے ہیں۔ اس کردار سے پہلے، وہ ایمیزون کی EU کسٹمر سروس کے ڈیٹا سائنس کے سربراہ تھے۔ Heiko ہمارے صارفین کو AWS پر ان کے AI/ML سفر میں کامیاب ہونے میں مدد کرتا ہے اور اس نے کئی صنعتوں میں تنظیموں کے ساتھ کام کیا ہے، بشمول انشورنس، مالیاتی خدمات، میڈیا اور تفریح، صحت کی دیکھ بھال، یوٹیلٹیز، اور مینوفیکچرنگ۔ اپنے فارغ وقت میں ہیکو زیادہ سے زیادہ سفر کرتا ہے۔
- '
- "
- &
- 100
- 2020
- ہمارے بارے میں
- خلاصہ
- تک رسائی حاصل
- درست
- حاصل کیا
- اعلی درجے کی
- ترقی
- AI
- تمام
- پہلے ہی
- ایمیزون
- محیط
- مقدار
- ایک اور
- APIs
- درخواست
- ایپلی کیشنز
- نقطہ نظر
- ارد گرد
- فن
- مضمون
- مضامین
- سامعین
- دستیاب
- اوسط
- AWS
- بیس لائن
- بنیادی طور پر
- شروع
- کیا جا رہا ہے
- کاروبار
- فون
- پرواہ
- پکڑے
- چیلنج
- کوڈ
- کوڈنگ
- کامن
- کمیونٹی
- کمپنیاں
- مقابلے میں
- مکمل طور پر
- کمپیوٹنگ
- تصور
- پر مشتمل ہے
- مواد
- معاہدے
- تخلیق
- اپنی مرضی کے
- کسٹمر سروس
- گاہکوں
- اعداد و شمار
- ڈیٹا سائنس
- گہرے
- ترقی یافتہ
- مختلف
- دستاویزات
- نہیں کرتا
- ڈومین
- تفریح
- خاص طور پر
- قائم کرو
- EU
- سب کچھ
- مثال کے طور پر
- توقع ہے
- ماہرین
- آنکھ
- چہرہ
- قطعات
- آخر
- مالی
- مالیاتی خدمات
- پہلا
- کے بعد
- آگے
- ملا
- تقریب
- مزید
- کھیل ہی کھیل میں
- پیدا
- نسل
- مقصد
- جا
- اچھا
- عظیم
- ولی
- رہنمائی
- ہونے
- سر
- صحت کی دیکھ بھال
- مدد گار
- مدد کرتا ہے
- یہاں
- کرایہ پر لینا
- کس طرح
- HTTPS
- بھاری
- شناختی
- پر عملدرآمد
- عملدرآمد
- اہم
- شامل
- سمیت
- انفرادی
- صنعتوں
- انشورنس
- متعارف کرانے
- سرمایہ کاری
- IT
- ایوب
- جولائی
- کلیدی
- علم
- لیبل
- زبان
- تازہ ترین
- لیڈز
- جانیں
- سیکھنے
- چھوڑ دو
- قانونی
- لائبریری
- لائسنس یافتہ
- لنکس
- تھوڑا
- مشین
- مشین لرننگ
- بناتا ہے
- بنانا
- مینوفیکچرنگ
- نشان
- میچ
- پیمائش
- میڈیا
- برا
- ML
- ماڈل
- ماڈل
- زیادہ
- سب سے زیادہ
- قدرتی
- نیٹ ورک
- خبر
- نوٹ بک
- تعداد
- کھول
- حکم
- تنظیمیں
- دیگر
- کاغذ.
- پیٹنٹ
- لوگ
- کارکردگی
- نقطہ نظر
- مرحلہ
- پوائنٹ
- امکانات
- امکان
- ممکن
- مراسلات
- ممکنہ
- طاقتور
- نجی
- پیداوار
- منصوبے
- منصوبوں
- تجویز کریں
- فراہم
- فراہم کرنے
- عوامی
- مقصد
- معیار
- سوال
- رینج
- RE
- پڑھنا
- رپورٹیں
- کی ضرورت
- ضرورت
- تحقیق
- نتائج کی نمائش
- رن
- کہا
- سائنس
- احساس
- سیریز
- سروس
- سروسز
- مقرر
- قائم کرنے
- مختصر
- سادہ
- So
- حل
- کسی
- کچھ
- بہتر
- خلا
- خالی جگہیں
- خصوصی
- مہارت دیتا ہے
- خاص طور پر
- تقسیم
- شروع کریں
- شروع
- شروع ہوتا ہے
- ریاستی آرٹ
- امریکہ
- ذخیرہ
- کشیدگی
- مطالعہ
- کامیاب
- کامیابی کے ساتھ
- بات
- ہدف
- کاموں
- ٹیکنیکل
- ٹیکنالوجی
- ٹیسٹ
- ہزاروں
- کے ذریعے
- بھر میں
- وقت
- عنوان
- ٹریننگ
- شفاف
- علاج
- حتمی
- سمجھ
- یونیورسل
- us
- استعمال کی شرائط
- عام طور پر
- قیمت
- انتظار
- کیا
- چاہے
- ڈبلیو
- وکیپیڈیا
- کے اندر
- بغیر
- کام
- کام کیا
- قابل
- تحریری طور پر
- X
- صفر