اپاچی آئس برگ بہت بڑے تجزیاتی ڈیٹاسیٹس کے لیے ایک کھلا ٹیبل فارمیٹ ہے، جو ڈیٹا سیٹس کی حالت پر میٹا ڈیٹا کی معلومات حاصل کرتا ہے کیونکہ وہ وقت کے ساتھ ساتھ تیار ہوتے اور تبدیل ہوتے ہیں۔ یہ ایک اعلی کارکردگی والے ٹیبل فارمیٹ کا استعمال کرتے ہوئے Spark، Trino، PrestoDB، Flink، اور Hive سمیت انجنوں کو کمپیوٹ کرنے کے لیے ٹیبلز کا اضافہ کرتا ہے جو بالکل SQL ٹیبل کی طرح کام کرتا ہے۔ آئس برگ ڈیٹا لیکس میں ACID ٹرانزیکشنز اور اسکیما اور پارٹیشن ایوولوشن، ٹائم ٹریول اور رول بیک جیسی خصوصیات کے لیے بہت مشہور ہو گیا ہے۔
Apache Iceberg انضمام بشمول AWS تجزیاتی خدمات کے ذریعہ تعاون یافتہ ہے۔ ایمیزون ای ایم آر, ایمیزون ایتینا، اور AWS گلو. Amazon EMR Spark، Hive، Trino، اور Flink کے ساتھ کلسٹر فراہم کر سکتا ہے جو آئس برگ کو چلا سکتے ہیں۔ ایمیزون EMR ورژن 6.5.0 کے ساتھ شروع کرتے ہوئے، آپ کر سکتے ہیں۔ اپنے EMR کلسٹر کے ساتھ آئس برگ کا استعمال کریں۔ بوٹسٹریپ ایکشن کی ضرورت کے بغیر۔ 2022 کے اوائل میں، AWS نے Apache Iceberg سے چلنے والے Athena ACID ٹرانزیکشنز کی عام دستیابی کا اعلان کیا۔ حال ہی میں جاری کردہ ایتھینا استفسار انجن ورژن 3 آئس برگ ٹیبل فارمیٹ کے ساتھ بہتر انضمام فراہم کرتا ہے۔ AWS Glue 3.0 اور بعد میں اپاچی آئس برگ فریم ورک کی حمایت کرتا ہے۔ ڈیٹا لیکس کے لیے۔
اس پوسٹ میں، ہم اس بات پر تبادلہ خیال کرتے ہیں کہ جدید ڈیٹا لیکس میں صارفین کیا چاہتے ہیں اور کس طرح اپاچی آئس برگ صارفین کی ضروریات کو پورا کرنے میں مدد کرتا ہے۔ پھر ہم ایک اعلیٰ کارکردگی اور ابھرتی ہوئی آئس برگ ڈیٹا لیک کو بنانے کے حل کے ذریعے چلتے ہیں۔ ایمیزون سادہ اسٹوریج سروس (Amazon S3) اور ایس کیو ایل اسٹیٹمنٹس کو داخل، اپ ڈیٹ اور ڈیلیٹ چلا کر انکریمنٹل ڈیٹا پر کارروائی کریں۔ آخر میں، ہم آپ کو دکھاتے ہیں کہ پڑھنے اور لکھنے کی کارکردگی کو بہتر بنانے کے لیے پرفارمنس کو کس طرح ٹیون کیا جائے۔
اپاچی آئس برگ جدید ڈیٹا لیکس میں کسٹمرز کی خواہش کو کیسے حل کرتا ہے۔
بہت سے صارفین، ایپلیکیشنز اور تجزیاتی ٹولز کو سپورٹ کرنے کے لیے زیادہ سے زیادہ گاہک ساختی اور غیر ساختہ ڈیٹا کے ساتھ ڈیٹا لیکس بنا رہے ہیں۔ ACID ٹرانزیکشنز، ریکارڈ لیول اپڈیٹس اور ڈیلیٹس، ٹائم ٹریول اور رول بیک جیسی خصوصیات جیسے ڈیٹا بیس کو سپورٹ کرنے کے لیے ڈیٹا لیکس کی ضرورت بڑھ رہی ہے۔ Apache Iceberg کو Amazon S3 پر لاگت سے موثر پیٹا بائٹ اسکیل ڈیٹا لیکس پر ان خصوصیات کو سپورٹ کرنے کے لیے ڈیزائن کیا گیا ہے۔
اپاچی آئس برگ انفرادی ڈیٹا فائلوں کی تخلیق کے وقت ڈیٹاسیٹ کے بارے میں بھرپور میٹا ڈیٹا معلومات حاصل کرکے کسٹمر کی ضروریات کو پورا کرتا ہے۔ آئس برگ ٹیبل کے فن تعمیر میں تین پرتیں ہیں: آئس برگ کیٹلاگ، میٹا ڈیٹا لیئر، اور ڈیٹا لیئر، جیسا کہ مندرجہ ذیل تصویر میں دکھایا گیا ہے (ذرائع).

آئس برگ کیٹلاگ میٹا ڈیٹا پوائنٹر کو موجودہ ٹیبل میٹا ڈیٹا فائل میں اسٹور کرتا ہے۔ جب کوئی منتخب سوال آئس برگ ٹیبل پڑھ رہا ہوتا ہے، استفسار کا انجن پہلے آئس برگ کیٹلاگ میں جاتا ہے، پھر موجودہ میٹا ڈیٹا فائل کا مقام بازیافت کرتا ہے۔ جب بھی آئس برگ ٹیبل میں کوئی اپ ڈیٹ ہوتا ہے، ٹیبل کا ایک نیا سنیپ شاٹ بنایا جاتا ہے، اور میٹا ڈیٹا پوائنٹر موجودہ ٹیبل میٹا ڈیٹا فائل کی طرف اشارہ کرتا ہے۔
ذیل میں AWS Glue کے نفاذ کے ساتھ Iceberg کیٹلاگ کی ایک مثال ہے۔ آپ ڈیٹا بیس کا نام، آئس برگ ٹیبل کا مقام (S3 پاتھ) اور میٹا ڈیٹا کا مقام دیکھ سکتے ہیں۔

میٹا ڈیٹا پرت میں تین قسم کی فائلیں ہوتی ہیں: میٹا ڈیٹا فائل، مینی فیسٹ لسٹ، اور مینی فیسٹ فائل درجہ بندی میں۔ درجہ بندی کے اوپری حصے میں میٹا ڈیٹا فائل ہے، جو ٹیبل کے اسکیما، پارٹیشن کی معلومات، اور سنیپ شاٹس کے بارے میں معلومات کو اسٹور کرتی ہے۔ سنیپ شاٹ مینی فیسٹ لسٹ کی طرف اشارہ کرتا ہے۔ مینی فیسٹ لسٹ میں ہر ایک مینی فیسٹ فائل کے بارے میں معلومات ہوتی ہیں جو اسنیپ شاٹ بناتی ہے، جیسے کہ مینی فیسٹ فائل کا محل وقوع، اس سے تعلق رکھنے والے پارٹیشنز، اور ڈیٹا فائلوں کے لیے پارٹیشن کالم کے نچلے اور اوپری حدود جو یہ ٹریک کرتا ہے۔ مینی فیسٹ فائل ڈیٹا فائلوں کے ساتھ ساتھ ہر فائل کے بارے میں اضافی تفصیلات جیسے فائل فارمیٹ کو ٹریک کرتی ہے۔ آئس برگ ٹیبل میں سنیپ شاٹس، اسکیما، پارٹیشننگ، پراپرٹیز اور ڈیٹا فائلوں کو ٹریک کرنے کے لیے تینوں فائلیں ایک درجہ بندی میں کام کرتی ہیں۔
ڈیٹا لیئر میں آئس برگ ٹیبل کی انفرادی ڈیٹا فائلیں ہوتی ہیں۔ آئس برگ فائل فارمیٹس کی ایک وسیع رینج کو سپورٹ کرتا ہے جس میں Parquet، ORC، اور Avro شامل ہیں۔ چونکہ آئس برگ ٹیبل ڈیٹا فائلوں کے ساتھ پارٹیشن لوکیشن کی طرف اشارہ کرنے کے بجائے انفرادی ڈیٹا فائلوں کو ٹریک کرتا ہے، یہ تحریری کارروائیوں کو پڑھنے کے عمل سے الگ کرتا ہے۔ آپ ڈیٹا فائلوں کو کسی بھی وقت لکھ سکتے ہیں، لیکن صرف واضح طور پر تبدیلی کا ارتکاب کریں، جو اسنیپ شاٹ اور میٹا ڈیٹا فائلوں کا ایک نیا ورژن بناتا ہے۔
حل جائزہ
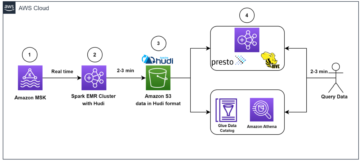
اس پوسٹ میں، ہم آپ کو Amazon S3 پر اعلیٰ کارکردگی کا مظاہرہ کرنے والی Apache Iceberg Data Lake بنانے کے حل کے بارے میں بتاتے ہیں۔ ایس کیو ایل بیانات داخل کرنے، اپ ڈیٹ کرنے اور حذف کرنے کے ساتھ اضافی ڈیٹا پر کارروائی کریں۔ اور پڑھنے اور لکھنے کی کارکردگی کو بہتر بنانے کے لیے آئس برگ ٹیبل کو ٹیون کریں۔ مندرجہ ذیل خاکہ حل کے فن تعمیر کی وضاحت کرتا ہے۔

اس حل کو ظاہر کرنے کے لیے، ہم استعمال کرتے ہیں۔ ایمیزون کسٹمر جائزہ S3 بالٹی میں ڈیٹاسیٹ (s3://amazon-reviews-pds/parquet/)۔ حقیقی استعمال کے معاملے میں، یہ آپ کے S3 بالٹی میں ذخیرہ شدہ خام ڈیٹا ہوگا۔ ہم درج ذیل کوڈ کے ساتھ ڈیٹا کا سائز چیک کر سکتے ہیں۔ AWS کمانڈ لائن انٹرفیس (AWS CLI):
کل آبجیکٹ کی گنتی 430 ہے، اور کل سائز 47.4 GiB ہے۔
اس حل کو ترتیب دینے اور جانچنے کے لیے، ہم درج ذیل اعلیٰ سطحی مراحل کو مکمل کرتے ہیں:
- تبدیل شدہ ڈیٹا کو آئس برگ ٹیبل فارمیٹ میں اسٹور کرنے کے لیے کیوریٹڈ زون میں ایک S3 بالٹی سیٹ کریں۔
- Apache Iceberg کے لیے مناسب ترتیب کے ساتھ EMR کلسٹر شروع کریں۔
- EMR اسٹوڈیو میں ایک نوٹ بک بنائیں۔
- اپاچی آئس برگ کے لیے اسپارک سیشن کو ترتیب دیں۔
- ڈیٹا کو آئس برگ ٹیبل فارمیٹ میں تبدیل کریں اور ڈیٹا کو کیوریٹڈ زون میں منتقل کریں۔
- انکریمنٹل ڈیٹا پر کارروائی کرنے کے لیے ایتھینا میں سوالات داخل کریں، اپ ڈیٹ کریں اور حذف کریں چلائیں۔
- کارکردگی کی ٹیوننگ کو انجام دیں۔
شرائط
اس واک تھرو کے ساتھ چلنے کے لیے، آپ کے پاس ایک ہونا ضروری ہے۔ AWS اکاؤنٹ کے ساتھ ایک AWS شناخت اور رسائی کا انتظام (IAM) کا کردار جس میں مطلوبہ وسائل کی فراہمی کے لیے کافی رسائی ہو۔
اپنی ڈیٹا لیک میں کیوریٹڈ زون میں آئس برگ ڈیٹا کے لیے S3 بالٹی سیٹ اپ کریں۔
وہ علاقہ منتخب کریں جس میں آپ S3 بالٹی بنانا چاہتے ہیں اور ایک منفرد نام فراہم کرنا چاہتے ہیں:
اسپارک کا استعمال کرتے ہوئے آئس برگ جابز چلانے کے لیے ایک EMR کلسٹر شروع کریں۔
آپ سے ایک EMR کلسٹر بنا سکتے ہیں۔ AWS مینجمنٹ کنسول، ایمیزون EMR CLI، یا AWS کلاؤڈ ڈویلپمنٹ کٹ (AWS CDK)۔ اس پوسٹ کے لیے، ہم آپ کو بتاتے ہیں کہ کنسول سے EMR کلسٹر کیسے بنایا جائے۔
- ایمیزون EMR کنسول پر، منتخب کریں۔ کلسٹر بنائیں.
- میں سے انتخاب کریں اعلی درجے کے اختیارات.
- کے لئے سافٹ ویئر کی تشکیل، تازہ ترین ایمیزون EMR ریلیز کا انتخاب کریں۔ جنوری 2023 تک، تازہ ترین ریلیز 6.9.0 ہے۔ آئس برگ کو ریلیز 6.5.0 اور اس سے اوپر کی ضرورت ہے۔
- منتخب کریں JupyterEnterpriseGateway اور چنگاری جیسا کہ سافٹ ویئر انسٹال کرنا ہے۔
- کے لئے سافٹ ویئر کی ترتیبات میں ترمیم کریں۔منتخب کنفیگریشن درج کریں۔ اور داخل
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - دیگر ترتیبات کو ان کے ڈیفالٹ پر چھوڑ دیں اور منتخب کریں۔ اگلے.

- کے لئے ہارڈ ویئر، پہلے سے طے شدہ ترتیب استعمال کریں۔
- میں سے انتخاب کریں اگلے.
- کے لئے کلسٹر کا نام، ایک نام درج کریں۔ ہم استعمال کرتے ہیں
iceberg-blog-cluster. - باقی سیٹنگز کو بغیر تبدیلی کے رہنے دیں اور منتخب کریں۔ اگلے.
- میں سے انتخاب کریں کلسٹر بنائیں.
EMR اسٹوڈیو میں ایک نوٹ بک بنائیں
اب ہم آپ کو کنسول سے EMR اسٹوڈیو میں ایک نوٹ بک بنانے کے طریقہ کے بارے میں بتاتے ہیں۔
- IAM کنسول پر، EMR اسٹوڈیو سروس رول بنائیں.
- ایمیزون EMR کنسول پر، منتخب کریں۔ EMR اسٹوڈیو.
- میں سے انتخاب کریں شروع کریں.
۔ شروع کریں صفحہ ایک نئے ٹیب میں ظاہر ہوتا ہے۔
- میں سے انتخاب کریں اسٹوڈیو بنائیں نئے ٹیب میں۔
- ایک نام درج کریں۔ ہم آئس برگ اسٹوڈیو استعمال کرتے ہیں۔
- وہی وی پی سی اور سب نیٹ منتخب کریں جو EMR کلسٹر اور ڈیفالٹ سیکیورٹی گروپ کے لیے ہیں۔
- میں سے انتخاب کریں AWS شناخت اور رسائی کا انتظام (IAM) تصدیق کے لیے، اور EMR اسٹوڈیو سروس رول کا انتخاب کریں جو آپ نے ابھی بنایا ہے۔
- کے لیے ایک S3 راستہ منتخب کریں۔ ورک اسپیس بیک اپ.
- میں سے انتخاب کریں اسٹوڈیو بنائیں.
- اسٹوڈیو بننے کے بعد، اسٹوڈیو تک رسائی کا URL منتخب کریں۔
- EMR اسٹوڈیو ڈیش بورڈ پر، منتخب کریں۔ کام کی جگہ بنائیں.
- اپنے ورک اسپیس کے لیے ایک نام درج کریں۔ ہم استعمال کرتے ہیں
iceberg-workspace. - توسیع اعلی درجے کی ترتیب اور منتخب کریں ورک اسپیس کو EMR کلسٹر سے منسلک کریں۔.
- EMR کلسٹر کا انتخاب کریں جو آپ نے پہلے بنایا تھا۔
- میں سے انتخاب کریں ورک اسپیس بنائیں.
- نیا ٹیب کھولنے کے لیے ورک اسپیس کا نام منتخب کریں۔
نیویگیشن پین میں، ایک نوٹ بک ہے جس کا نام ورک اسپیس ہے۔ ہمارے معاملے میں، یہ آئس برگ ورک اسپیس ہے۔
- نوٹ بک کھولیں۔
- جب دانا منتخب کرنے کا اشارہ کیا جائے تو منتخب کریں۔ چنگاری.
اپاچی آئس برگ کے لیے اسپارک سیشن کو ترتیب دیں۔
اپنا S3 بالٹی نام فراہم کرتے ہوئے درج ذیل کوڈ کا استعمال کریں:
یہ مندرجہ ذیل سپارک سیشن کنفیگریشنز کو سیٹ کرتا ہے:
- spark.sql.catalog.demo - ڈیمو نامی اسپارک کیٹلاگ کو رجسٹر کرتا ہے، جو آئس برگ اسپارک کیٹلاگ پلگ ان کا استعمال کرتا ہے۔
- spark.sql.catalog.demo.catalog-impl - ڈیمو اسپارک کیٹلاگ AWS Glue کو Iceberg ڈیٹا بیس اور ٹیبل کی معلومات کو ذخیرہ کرنے کے لیے فزیکل کیٹلاگ کے طور پر استعمال کرتا ہے۔
- spark.sql.catalog.demo.warehouse - ڈیمو اسپارک کیٹلاگ تمام آئس برگ میٹا ڈیٹا اور ڈیٹا فائلوں کو اس پراپرٹی کے ذریعہ بیان کردہ روٹ پاتھ کے تحت اسٹور کرتا ہے۔
s3://iceberg-curated-blog-data. - spark.sql.extensions - آئس برگ اسپارک ایس کیو ایل ایکسٹینشنز میں سپورٹ شامل کرتا ہے، جو آپ کو آئس برگ اسپارک کے طریقہ کار اور کچھ آئس برگ صرف ایس کیو ایل کمانڈز چلانے کی اجازت دیتا ہے (آپ اسے بعد کے مرحلے میں استعمال کرتے ہیں)۔
- spark.sql.catalog.demo.io-impl - آئس برگ صارفین کو S3FileIO کے ذریعے Amazon S3 پر ڈیٹا لکھنے کی اجازت دیتا ہے۔ AWS Glue Data Catalog بذریعہ ڈیفالٹ اس FileIO کو استعمال کرتا ہے، اور دیگر کیٹلاگ io-impl کیٹلاگ پراپرٹی کا استعمال کرتے ہوئے اس FileIO کو لوڈ کر سکتے ہیں۔
ڈیٹا کو آئس برگ ٹیبل فارمیٹ میں تبدیل کریں۔
آئس برگ ٹیبل لوڈ کرنے کے لیے آپ ایمیزون EMR یا ایتھینا پر Spark استعمال کر سکتے ہیں۔ EMR اسٹوڈیو ورک اسپیس نوٹ بک اسپارک سیشن میں، ڈیٹا لوڈ کرنے کے لیے درج ذیل کمانڈز چلائیں:
کوڈ چلانے کے بعد، آپ کو اپنے ڈیٹا گودام S3 پاتھ (s3://iceberg-curated-blog-data/reviews.db/all_reviews): ڈیٹا اور میٹا ڈیٹا۔
ایتھینا میں ایس کیو ایل سٹیٹمنٹس داخل، اپ ڈیٹ اور ڈیلیٹ کا استعمال کرتے ہوئے انکریمنٹل ڈیٹا پر کارروائی کریں۔
ایتھینا ایک سرور لیس کوئوری انجن ہے جسے آپ آئس برگ ٹیبلز کے خلاف پڑھنے، لکھنے، اپ ڈیٹ کرنے اور اصلاح کے کام انجام دینے کے لیے استعمال کر سکتے ہیں۔ یہ ظاہر کرنے کے لیے کہ اپاچی آئس برگ ڈیٹا لیک فارمیٹ کس طرح اضافی ڈیٹا انجیشن کو سپورٹ کرتا ہے، ہم ڈیٹا لیک پر ایس کیو ایل اسٹیٹمنٹس داخل، اپ ڈیٹ اور ڈیلیٹ کرتے ہیں۔
ایتھینا کنسول پر جائیں اور منتخب کریں۔ سوال ایڈیٹر. اگر یہ آپ پہلی بار ایتھینا استفسار ایڈیٹر استعمال کر رہے ہیں، تو آپ کو کرنے کی ضرورت ہے۔ استفسار کے نتیجے کے مقام کو ترتیب دیں۔ S3 بالٹی بننے کے لیے جو آپ نے پہلے بنایا تھا۔ آپ کو یہ دیکھنے کے قابل ہونا چاہئے کہ ٹیبل reviews.all_reviews استفسار کے لیے دستیاب ہے۔ اس بات کی توثیق کرنے کے لیے درج ذیل استفسار کو چلائیں کہ آپ نے آئس برگ ٹیبل کو کامیابی کے ساتھ لوڈ کیا ہے:
ایس کیو ایل اسٹیٹمنٹس کو داخل، اپ ڈیٹ، اور ڈیلیٹ چلا کر انکریمنٹ ڈیٹا پر کارروائی کریں:
پرفارمنس ٹیوننگ
اس سیکشن میں، ہم Apache Iceberg پڑھنے اور لکھنے کی کارکردگی کو بہتر بنانے کے لیے مختلف طریقوں سے گزرتے ہیں۔
اپاچی آئس برگ ٹیبل کی خصوصیات کو ترتیب دیں۔
Apache Iceberg ایک ٹیبل فارمیٹ ہے، اور یہ ٹیبل کے رویے کو ترتیب دینے کے لیے ٹیبل کی خصوصیات کو سپورٹ کرتا ہے جیسے پڑھنا، لکھنا اور کیٹلاگ۔ آپ ٹیبل کی خصوصیات کو ایڈجسٹ کرکے آئس برگ ٹیبلز پر پڑھنے اور لکھنے کی کارکردگی کو بہتر بنا سکتے ہیں۔
مثال کے طور پر، اگر آپ دیکھتے ہیں کہ آپ ایک آئس برگ ٹیبل کے لیے بہت زیادہ چھوٹی فائلیں لکھتے ہیں، تو آپ استفسار کی کارکردگی کو بہتر بنانے میں مدد کے لیے، کم لیکن بڑے سائز کی فائلیں لکھنے کے لیے رائٹ فائل کا سائز ترتیب دے سکتے ہیں۔
| پراپرٹی | پہلے سے طے شدہ | Description |
| write.target-file-size-bytes | 536870912 (512 MB) | اس بہت سے بائٹس کے بارے میں ہدف بنانے کے لیے تیار کردہ فائلوں کے سائز کو کنٹرول کرتا ہے۔ |
ٹیبل فارمیٹ کو تبدیل کرنے کے لیے درج ذیل کوڈ کا استعمال کریں:
تقسیم اور چھانٹنا
استفسار کو تیزی سے چلانے کے لیے، جتنا کم ڈیٹا پڑھا جائے اتنا ہی بہتر ہے۔ آئس برگ اس بھرپور میٹا ڈیٹا سے فائدہ اٹھاتا ہے جسے وہ لکھنے کے وقت حاصل کرتا ہے اور تکنیکوں کو سہولت فراہم کرتا ہے جیسے اسکین پلاننگ، پارٹیشننگ، پرننگ، اور کالم کی سطح کے اعدادوشمار جیسے کہ کم سے کم/زیادہ سے زیادہ اقدار ڈیٹا فائلوں کو چھوڑنے کے لیے جن میں میچ ریکارڈ نہیں ہوتا ہے۔ ہم آپ کو اس بارے میں بتاتے ہیں کہ آئس برگ میں استفسار اسکین پلاننگ اور پارٹیشننگ کیسے کام کرتی ہے اور ہم استفسار کی کارکردگی کو بہتر بنانے کے لیے ان کا استعمال کیسے کرتے ہیں۔
اسکین پلاننگ سے استفسار کریں۔
دی گئی استفسار کے لیے، استفسار کے انجن میں پہلا قدم اسکین پلاننگ ہے، جو کہ ایک سوال کے لیے درکار ٹیبل میں فائلوں کو تلاش کرنے کا عمل ہے۔ آئس برگ ٹیبل میں منصوبہ بندی کرنا بہت کارآمد ہے، کیونکہ آئس برگ کا بھرپور میٹا ڈیٹا ان میٹا ڈیٹا فائلوں کو چھانٹنے کے لیے استعمال کیا جا سکتا ہے جن کی ضرورت نہیں ہے، اس کے علاوہ ان ڈیٹا فائلوں کو فلٹر کرنے کے لیے جو مماثل ڈیٹا پر مشتمل نہیں ہیں۔ اپنے ٹیسٹوں میں، ہم نے مشاہدہ کیا کہ ایتھینا نے آئس برگ کی شکل میں تبدیل ہونے سے پہلے اصل ڈیٹا کے مقابلے آئس برگ ٹیبل پر دیے گئے سوال کے لیے 50% یا اس سے کم ڈیٹا کو اسکین کیا۔
فلٹرنگ کی دو قسمیں ہیں:
- میٹا ڈیٹا فلٹرنگ - آئس برگ اسنیپ شاٹ میں فائلوں کو ٹریک کرنے کے لیے میٹا ڈیٹا کی دو سطحوں کا استعمال کرتا ہے: مینی فیسٹ لسٹ اور مینی فیسٹ فائلز۔ یہ سب سے پہلے مینی فیسٹ لسٹ کا استعمال کرتا ہے، جو مینی فیسٹ فائلوں کے انڈیکس کے طور پر کام کرتا ہے۔ منصوبہ بندی کے دوران، آئس برگ فلٹرز تمام مینی فیسٹ فائلوں کو پڑھے بغیر مینی فیسٹ لسٹ میں پارٹیشن ویلیو رینج کا استعمال کرتے ہوئے ظاہر کرتا ہے۔ پھر یہ ڈیٹا فائلوں کو حاصل کرنے کے لیے منتخب مینی فیسٹ فائلوں کا استعمال کرتا ہے۔
- ڈیٹا فلٹرنگ - مینی فیسٹ فائلوں کی فہرست کو منتخب کرنے کے بعد، آئس برگ ڈیٹا فائلوں کو فلٹر کرنے کے لیے مینی فیسٹ فائلوں میں محفوظ ہر ڈیٹا فائل کے لیے پارٹیشن ڈیٹا اور کالم لیول کے اعدادوشمار کا استعمال کرتا ہے۔ منصوبہ بندی کے دوران، استفسار کی پیشین گوئیوں کو پارٹیشن ڈیٹا پر پیشین گوئی میں تبدیل کیا جاتا ہے اور ڈیٹا فائلوں کو فلٹر کرنے کے لیے پہلے لاگو کیا جاتا ہے۔ پھر، کالم کے اعدادوشمار جیسے کالم لیول ویلیو کاؤنٹ، نال کاؤنٹ، لوئر باؤنڈز، اور اپر باؤنڈز کو ڈیٹا فائلوں کو فلٹر کرنے کے لیے استعمال کیا جاتا ہے جو استفسار کی پیشین گوئی سے مماثل نہیں ہو سکتیں۔ منصوبہ بندی کے وقت ڈیٹا فائلوں کو فلٹر کرنے کے لیے اوپری اور نچلی حدود کا استعمال کرتے ہوئے، آئس برگ استفسار کی کارکردگی کو بہت بہتر بناتا ہے۔
تقسیم اور چھانٹنا
تقسیم کاری ایک ایسا طریقہ ہے جس میں ایک ہی کلیدی کالم اقدار کے ساتھ ریکارڈز کو تحریری طور پر اکٹھا کیا جائے۔ تقسیم کرنے کا فائدہ تیز تر استفسارات ہیں جو ڈیٹا کے صرف ایک حصے تک رسائی حاصل کرتے ہیں، جیسا کہ پہلے استفسار اسکین پلاننگ میں بیان کیا گیا ہے: ڈیٹا فلٹرنگ۔ آئس برگ پوشیدہ تقسیم کی حمایت کرتے ہوئے تقسیم کو آسان بناتا ہے، اس طرح کہ آئس برگ کالم کی قیمت لے کر اور اختیاری طور پر اسے تبدیل کر کے تقسیم کی اقدار پیدا کرتا ہے۔
ہمارے استعمال کے معاملے میں، ہم سب سے پہلے درج ذیل استفسار کو آئس برگ ٹیبل پر چلاتے ہیں جسے تقسیم نہیں کیا گیا ہے۔ پھر ہم آئس برگ ٹیبل کو جائزوں کے زمرے کے لحاظ سے تقسیم کرتے ہیں، جو ریکارڈ کو فلٹر کرنے کے لیے WHERE حالت میں استفسار کیا جائے گا۔ تقسیم کے ساتھ، استفسار بہت کم ڈیٹا کو اسکین کر سکتا ہے۔ درج ذیل کوڈ دیکھیں:
کارکردگی کا فرق دیکھنے کے لیے غیر تقسیم شدہ all_reviews ٹیبل بمقابلہ تقسیم شدہ ٹیبل پر درج ذیل منتخب بیان کو چلائیں:
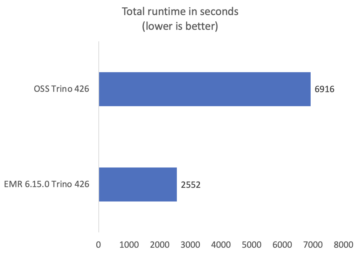
مندرجہ ذیل جدول ڈیٹا کی تقسیم کی کارکردگی میں بہتری کو ظاہر کرتا ہے، جس میں تقریباً 50% کارکردگی میں بہتری اور 70% کم ڈیٹا اسکین کیا گیا ہے۔
| ڈیٹاسیٹ کا نام | غیر تقسیم شدہ ڈیٹا سیٹ | تقسیم شدہ ڈیٹا سیٹ |
| رن ٹائم (سیکنڈز) | 8.20 | 4.25 |
| ڈیٹا اسکین (MB) | 131.55 | 33.79 |
نوٹ کریں کہ رن ٹائم ہمارے ٹیسٹ میں متعدد رنز کے ساتھ اوسط رن ٹائم ہے۔
تقسیم کے بعد ہم نے کارکردگی میں بہتری دیکھی۔ تاہم، آئس برگ مینی فیسٹ فائلوں سے کالم لیول کے اعدادوشمار کا استعمال کرکے اسے مزید بہتر کیا جا سکتا ہے۔ کالم کی سطح کے اعدادوشمار کو مؤثر طریقے سے استعمال کرنے کے لیے، آپ استفسار کے نمونوں کی بنیاد پر اپنے ریکارڈ کو مزید ترتیب دینا چاہتے ہیں۔ سوالات میں اکثر استعمال ہونے والے کالموں کا استعمال کرتے ہوئے پورے ڈیٹاسیٹ کو ترتیب دینے سے ڈیٹا کو اس طرح ترتیب دیا جائے گا کہ ہر ڈیٹا فائل مخصوص کالموں کے لیے قدروں کی ایک منفرد رینج کے ساتھ ختم ہو۔ اگر یہ کالم استفسار کی حالت میں استعمال کیے جاتے ہیں، تو یہ استفسار کے انجنوں کو ڈیٹا فائلوں کو مزید چھوڑنے کی اجازت دیتا ہے، اس طرح اور بھی تیز تر استفسارات کو قابل بناتا ہے۔
کاپی آن رائٹ بمقابلہ پڑھنے پر ضم کرنا
ڈیٹا لیک میں آئس برگ ٹیبلز پر اپ ڈیٹ اور ڈیلیٹ کو لاگو کرتے وقت، آئس برگ ٹیبل کی خصوصیات کے ذریعہ بیان کردہ دو طریقے ہیں:
- کاپی آن لکھیں - اس نقطہ نظر کے ساتھ، جب آئس برگ ٹیبل میں تبدیلیاں ہوں گی، یا تو اپ ڈیٹ ہوں گی یا ڈیلیٹ ہوں گی، متاثرہ ریکارڈ سے وابستہ ڈیٹا فائلوں کو ڈپلیکیٹ اور اپ ڈیٹ کیا جائے گا۔ ریکارڈز کو یا تو اپ ڈیٹ کیا جائے گا یا ڈپلیکیٹ ڈیٹا فائلوں سے حذف کر دیا جائے گا۔ آئس برگ ٹیبل کا ایک نیا سنیپ شاٹ بنایا جائے گا اور ڈیٹا فائلوں کے نئے ورژن کی طرف اشارہ کیا جائے گا۔ یہ مجموعی طور پر لکھنے کو سست بناتا ہے۔ ایسے حالات ہوسکتے ہیں کہ تنازعات کے ساتھ ساتھ لکھنے کی ضرورت ہوتی ہے لہذا دوبارہ کوشش کرنی ہوگی، جس سے لکھنے کا وقت اور بھی بڑھ جاتا ہے۔ دوسری طرف، ڈیٹا کو پڑھتے وقت، کسی اضافی عمل کی ضرورت نہیں ہے۔ استفسار ڈیٹا فائلوں کے تازہ ترین ورژن سے ڈیٹا بازیافت کرے گا۔
- ضم پر پڑھنا - اس نقطہ نظر کے ساتھ، جب آئس برگ ٹیبل پر اپ ڈیٹس یا ڈیلیٹ ہوتے ہیں، موجودہ ڈیٹا فائلوں کو دوبارہ نہیں لکھا جائے گا۔ اس کے بجائے تبدیلیوں کو ٹریک کرنے کے لیے نئی ڈیلیٹ فائلیں بنائی جائیں گی۔ حذف کرنے کے لیے، حذف شدہ ریکارڈ کے ساتھ ایک نئی حذف فائل بنائی جائے گی۔ آئس برگ ٹیبل کو پڑھتے وقت، ڈیلیٹ فائل کو ڈیلیٹ ریکارڈز کو فلٹر کرنے کے لیے بازیافت شدہ ڈیٹا پر لاگو کیا جائے گا۔ اپ ڈیٹس کے لیے، ایک نئی ڈیلیٹ فائل بنائی جائے گی تاکہ اپ ڈیٹ شدہ ریکارڈز کو ڈیلیٹ کر دیا جائے۔ پھر ان ریکارڈز کے لیے ایک نئی فائل بنائی جائے گی لیکن اپ ڈیٹ شدہ اقدار کے ساتھ۔ آئس برگ ٹیبل کو پڑھتے وقت، تازہ ترین تبدیلیوں کی عکاسی کرنے اور درست نتائج پیدا کرنے کے لیے ڈیلیٹ اور نئی فائلیں بازیافت شدہ ڈیٹا پر لاگو ہوں گی۔ لہذا، کسی بھی بعد کے سوالات کے لیے، ڈیٹا فائلوں کو ڈیلیٹ اور نئی فائلوں کے ساتھ ضم کرنے کا ایک اضافی مرحلہ ہوگا، جو عام طور پر استفسار کے وقت میں اضافہ کرے گا۔ دوسری طرف، تحریریں تیز ہوسکتی ہیں کیونکہ موجودہ ڈیٹا فائلوں کو دوبارہ لکھنے کی ضرورت نہیں ہے۔
دو طریقوں کے اثرات کو جانچنے کے لیے، آپ آئس برگ ٹیبل کی خصوصیات کو سیٹ کرنے کے لیے درج ذیل کوڈ کو چلا سکتے ہیں:
کاپی آن رائٹ بمقابلہ مرج آن ریڈ کے رن ٹائم فرق کو دکھانے کے لیے ایتھینا میں اپ ڈیٹ چلائیں، ڈیلیٹ کریں اور ایس کیو ایل اسٹیٹمنٹس کو منتخب کریں:
مندرجہ ذیل جدول استفسار کے رن ٹائمز کا خلاصہ کرتا ہے۔
| طلب | کاپی آن رائٹ | مرج آن ریڈ | ||||
| اپ ڈیٹ | DELETE | کا انتخاب کریں | اپ ڈیٹ | DELETE | کا انتخاب کریں | |
| رن ٹائم (سیکنڈز) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| ڈیٹا اسکین (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
نوٹ کریں کہ رن ٹائم ہمارے ٹیسٹ میں متعدد رنز کے ساتھ اوسط رن ٹائم ہے۔
جیسا کہ ہمارے ٹیسٹ کے نتائج ظاہر کرتے ہیں، دونوں طریقوں میں ہمیشہ تجارت ہوتی ہے۔ کون سا طریقہ استعمال کرنا ہے اس کا انحصار آپ کے استعمال کے معاملات پر ہے۔ خلاصہ طور پر، غور و فکر پڑھنے بمقابلہ لکھنے میں تاخیر پر آتا ہے۔ آپ مندرجہ ذیل جدول کا حوالہ دے سکتے ہیں اور صحیح انتخاب کر سکتے ہیں۔
| . | کاپی آن رائٹ | مرج آن ریڈ |
| پیشہ | تیز پڑھتا ہے۔ | تیز لکھتے ہیں۔ |
| خامیاں | مہنگی تحریر | پڑھنے پر زیادہ تاخیر |
| جب استعمال کریں | بار بار پڑھنے، کبھی کبھار اپ ڈیٹس اور ڈیلیٹس یا بڑے بیچ اپڈیٹس کے لیے اچھا ہے۔ | بار بار اپ ڈیٹس اور ڈیلیٹ کرنے والی میزوں کے لیے اچھا ہے۔ |
ڈیٹا کمپیکشن
اگر آپ کی ڈیٹا فائل کا سائز چھوٹا ہے تو، آپ کو آئس برگ ٹیبل میں ہزاروں یا لاکھوں فائلیں مل سکتی ہیں۔ یہ ڈرامائی طور پر I/O آپریشن کو بڑھاتا ہے اور سوالات کو سست کر دیتا ہے۔ مزید برآں، آئس برگ ہر ڈیٹا فائل کو ڈیٹاسیٹ میں ٹریک کرتا ہے۔ زیادہ ڈیٹا فائلیں زیادہ میٹا ڈیٹا کا باعث بنتی ہیں۔ اس کے نتیجے میں میٹا ڈیٹا فائلوں کو پڑھنے پر اوور ہیڈ اور I/O آپریشن میں اضافہ ہوتا ہے۔ استفسار کی کارکردگی کو بہتر بنانے کے لیے، چھوٹی ڈیٹا فائلوں کو بڑی ڈیٹا فائلوں میں کمپیکٹ کرنے کی سفارش کی جاتی ہے۔
آئس برگ ٹیبل میں ریکارڈز کو اپ ڈیٹ اور ڈیلیٹ کرتے وقت، اگر ریڈ آن ضم کرنے کا طریقہ استعمال کیا جاتا ہے، تو آپ کو بہت سی چھوٹی ڈیلیٹ یا نئی ڈیٹا فائلز مل سکتی ہیں۔ رننگ کمپیکشن ان تمام فائلوں کو یکجا کر دے گا اور ڈیٹا فائل کا ایک نیا ورژن بنائے گا۔ یہ پڑھنے کے دوران ان کو ملانے کی ضرورت کو ختم کرتا ہے۔ لکھنے کی تیز رفتار کو برقرار رکھتے ہوئے پڑھنے کو کم سے کم اثر انداز کرنے کے لیے باقاعدہ کمپیکشن جابز رکھنے کی سفارش کی جاتی ہے۔
درج ذیل ڈیٹا کومپیکشن کمانڈ چلائیں، پھر ایتھینا سے منتخب سوال چلائیں:
مندرجہ ذیل جدول ڈیٹا کمپیکشن کے بعد کے رن ٹائم کا موازنہ کرتا ہے۔ آپ کارکردگی میں تقریباً 40 فیصد بہتری دیکھ سکتے ہیں۔
| طلب | ڈیٹا کمپیکشن سے پہلے | ڈیٹا کمپیکشن کے بعد |
| رن ٹائم (سیکنڈز) | 97.75 | 32.676 سیکنڈ |
| ڈیٹا اسکین (MB) | 137.16 ایم | 189.19 ایم |
نوٹ کریں کہ منتخب سوالات پر چلتے ہیں۔ all_reviews جدول اپ ڈیٹ اور ڈیلیٹ آپریشنز کے بعد، ڈیٹا کمپیکشن سے پہلے اور بعد میں۔ رن ٹائم ہمارے ٹیسٹ میں متعدد رنز کے ساتھ اوسط رن ٹائم ہے۔
صاف کرو
استعمال کے معاملات کو انجام دینے کے لیے آپ کے حل کے راستے پر عمل کرنے کے بعد، اپنے وسائل کو صاف کرنے اور مزید اخراجات سے بچنے کے لیے درج ذیل اقدامات مکمل کریں:
- AWS Glue ٹیبلز اور ڈیٹا بیس کو Athena سے گرائیں یا اپنی نوٹ بک میں درج ذیل کوڈ کو چلائیں:
- EMR اسٹوڈیو کنسول پر، منتخب کریں۔ ورکشاپ نیوی گیشن پین میں.
- آپ نے جو ورک اسپیس بنائی ہے اسے منتخب کریں اور منتخب کریں۔ خارج کر دیں.
- EMR کنسول پر، تشریف لے جائیں۔ اسٹوڈیوز صفحہ.
- آپ نے جو اسٹوڈیو بنایا ہے اسے منتخب کریں اور منتخب کریں۔ خارج کر دیں.
- EMR کنسول پر، منتخب کریں۔ کلسٹر نیوی گیشن پین میں.
- کلسٹر کو منتخب کریں اور منتخب کریں۔ ختم کریں۔.
- S3 بالٹی اور کسی دوسرے وسائل کو حذف کریں جو آپ نے اس پوسٹ کے لیے ضروری شرائط کے حصے کے طور پر بنائے ہیں۔
نتیجہ
اس پوسٹ میں، ہم نے اپاچی آئس برگ کے فریم ورک کو متعارف کرایا اور یہ کہ یہ جدید ڈیٹا لیک میں ہمارے سامنے موجود کچھ چیلنجوں کو حل کرنے میں کس طرح مدد کرتا ہے۔ پھر ہم نے آپ کو اپاچی آئس برگ کا استعمال کرتے ہوئے ڈیٹا لیک میں اضافی ڈیٹا پر کارروائی کرنے کے حل کے بارے میں بتایا۔ آخر میں، ہم نے اپنے استعمال کے معاملات کے لیے پڑھنے اور لکھنے کی کارکردگی کو بہتر بنانے کے لیے پرفارمنس ٹیوننگ میں گہرا غوطہ لگایا۔
ہمیں امید ہے کہ یہ پوسٹ آپ کو یہ فیصلہ کرنے کے لیے کچھ مفید معلومات فراہم کرے گی کہ آیا آپ اپنے ڈیٹا لیک حل میں Apache Iceberg کو اپنانا چاہتے ہیں۔
مصنفین کے بارے میں
 فلورا وو AWS ڈیٹا لیب میں ایک سینئر رہائشی آرکیٹیکٹ ہے۔ وہ انٹرپرائز صارفین کو ڈیٹا اینالیٹکس کی حکمت عملی بنانے اور اپنے کاروبار کے نتائج کو تیز کرنے کے لیے حل تیار کرنے میں مدد کرتی ہے۔ اپنے فارغ وقت میں، وہ ٹینس کھیلنا، سالسا ڈانس کرنا اور سفر کرنا پسند کرتی ہے۔
فلورا وو AWS ڈیٹا لیب میں ایک سینئر رہائشی آرکیٹیکٹ ہے۔ وہ انٹرپرائز صارفین کو ڈیٹا اینالیٹکس کی حکمت عملی بنانے اور اپنے کاروبار کے نتائج کو تیز کرنے کے لیے حل تیار کرنے میں مدد کرتی ہے۔ اپنے فارغ وقت میں، وہ ٹینس کھیلنا، سالسا ڈانس کرنا اور سفر کرنا پسند کرتی ہے۔
 ڈینیل لی ایمیزون ویب سروسز میں ایک سینئر حل آرکیٹیکٹ ہے۔ وہ کلاؤڈ سروسز اور حکمت عملی کو تیار کرنے، اپنانے اور لاگو کرنے میں صارفین کی مدد کرنے پر توجہ مرکوز کرتا ہے۔ جب وہ کام نہیں کرتا ہے، تو وہ اپنے خاندان کے ساتھ باہر وقت گزارنا پسند کرتا ہے۔
ڈینیل لی ایمیزون ویب سروسز میں ایک سینئر حل آرکیٹیکٹ ہے۔ وہ کلاؤڈ سروسز اور حکمت عملی کو تیار کرنے، اپنانے اور لاگو کرنے میں صارفین کی مدد کرنے پر توجہ مرکوز کرتا ہے۔ جب وہ کام نہیں کرتا ہے، تو وہ اپنے خاندان کے ساتھ باہر وقت گزارنا پسند کرتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- قابلیت
- ہمارے بارے میں
- اوپر
- رفتار کو تیز تر
- تک رسائی حاصل
- رسائی کا انتظام
- عمل
- کام کرتا ہے
- اس کے علاوہ
- ایڈیشنل
- پتہ
- پتے
- جوڑتا ہے
- اپنانے
- فائدہ
- کے بعد
- کے خلاف
- تمام
- کی اجازت دیتا ہے
- ہمیشہ
- ایمیزون
- ایمیزون ای ایم آر
- ایمیزون ویب سروسز
- تجزیاتی
- تجزیاتی
- اور
- کا اعلان کیا ہے
- اپاچی
- ایپلی کیشنز
- اطلاقی
- نقطہ نظر
- نقطہ نظر
- مناسب
- فن تعمیر
- منسلک
- کی توثیق
- دستیابی
- دستیاب
- اوسط
- سے اجتناب
- AWS
- AWS گلو
- کی بنیاد پر
- کیونکہ
- بن
- اس سے پہلے
- فائدہ
- بہتر
- کے درمیان
- بڑا
- بوٹسٹریپ
- تعمیر
- عمارت
- کاروبار
- قبضہ
- گرفتاری
- کیس
- مقدمات
- کیٹلوگ
- کیٹلاگ
- قسم
- چیلنجوں
- تبدیل
- تبدیلیاں
- چیک کریں
- انتخاب
- میں سے انتخاب کریں
- درجہ بندی
- بادل
- بادل کی خدمات
- کلسٹر
- کوڈ
- کالم
- کالم
- جمع
- کس طرح
- وعدہ کرنا
- مقابلے میں
- مکمل
- کمپیوٹنگ
- سمورتی
- شرط
- ترتیب
- خیالات
- کنسول
- تبادلوں سے
- تبدیل
- سرمایہ کاری مؤثر
- اخراجات
- سکتا ہے
- تخلیق
- بنائی
- پیدا
- cured
- موجودہ
- گاہک
- گاہکوں
- رقص
- ڈیش بورڈ
- اعداد و شمار
- ڈیٹا تجزیات
- ڈیٹا لیک
- ڈیٹا پروسیسنگ
- ڈیٹا گودام
- ڈیٹا بیس
- ڈیٹاسیٹس
- گہری
- گہری ڈبکی
- پہلے سے طے شدہ
- کی وضاحت
- ڈیمو
- مظاہرہ
- انحصار کرتا ہے
- ڈیزائن
- تفصیلات
- ترقی
- ترقی
- فرق
- مختلف
- بات چیت
- نہیں
- نیچے
- ڈرامائی طور پر
- چھوڑ
- کے دوران
- ہر ایک
- اس سے قبل
- ابتدائی
- ایڈیٹر
- مؤثر طریقے
- ہنر
- یا تو
- ختم
- چالو حالت میں
- کو فعال کرنا
- ختم ہو جاتا ہے
- انجن
- انجن
- درج
- انٹرپرائز
- انٹرپرائز گاہکوں
- Ether (ETH)
- بھی
- ارتقاء
- تیار
- تیار ہوتا ہے
- مثال کے طور پر
- موجودہ
- موجود ہے
- وضاحت کی
- ملانے
- اضافی
- سہولت
- خاندان
- فاسٹ
- تیز تر
- خصوصیات
- اعداد و شمار
- فائل
- فائلوں
- فلٹر
- فلٹرنگ
- فلٹر
- آخر
- مل
- پہلا
- پہلی بار
- توجہ مرکوز
- پر عمل کریں
- کے بعد
- فارمیٹ
- فریم ورک
- بار بار اس
- سے
- مزید
- مزید برآں
- جنرل
- پیدا
- حاصل
- دی
- جاتا ہے
- اچھا
- بہت
- گروپ
- ہاتھ
- ہو
- مدد
- مدد
- مدد کرتا ہے
- پوشیدہ
- درجہ بندی
- اعلی سطحی
- اعلی کارکردگی
- اعلی کارکردگی
- چھتہ
- امید ہے کہ
- کس طرح
- کیسے
- تاہم
- HTML
- HTTPS
- IAM
- شناختی
- شناخت اور رسائی کا انتظام
- اثر
- متاثر
- پر عملدرآمد
- نفاذ
- پر عمل درآمد
- کو بہتر بنانے کے
- بہتر
- بہتری
- بہتر ہے
- in
- سمیت
- اضافہ
- اضافہ
- اضافہ
- انڈکس
- انفرادی
- معلومات
- انسٹال
- کے بجائے
- انضمام
- متعارف
- الگ تھلگ
- IT
- جنوری
- نوکریاں
- کلیدی
- لیب
- جھیل
- بڑے
- بڑے
- تاخیر
- تازہ ترین
- تازہ ترین رہائی
- پرت
- تہوں
- قیادت
- سطح
- LIMIT
- لائن
- لسٹ
- تھوڑا
- لوڈ
- محل وقوع
- بنا
- بناتا ہے
- انتظام
- بہت سے
- نشان
- بازار
- میچ
- کے ملاپ
- ضم کریں
- میٹا ڈیٹا
- شاید
- لاکھوں
- جدید
- زیادہ
- منتقل
- ایک سے زیادہ
- نام
- نامزد
- تشریف لے جائیں
- سمت شناسی
- ضرورت ہے
- ضرورت
- ضروریات
- نئی
- نوٹ بک
- اعتراض
- کھول
- آپریشن
- آپریشنز
- اصلاح کے
- کی اصلاح کریں
- حکم
- اصل
- دیگر
- باہر
- مجموعی طور پر
- خود
- پین
- حصہ
- راستہ
- پیٹرن
- انجام دینے کے
- کارکردگی
- جسمانی
- منصوبہ بندی
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیل
- رابطہ بحال کرو
- پوائنٹس
- مقبول
- ممکن
- پوسٹ
- طاقت
- ضروریات
- طریقہ کار
- عمل
- پروسیسنگ
- پیدا
- خصوصیات
- جائیداد
- فراہم
- فراہم کرتا ہے
- فراہم کرنے
- پراجیکٹ
- رینج
- خام
- خام ڈیٹا
- پڑھیں
- پڑھنا
- اصلی
- حال ہی میں
- سفارش کی
- ریکارڈ
- کی عکاسی
- خطے
- رجسٹر
- باقاعدہ
- جاری
- جاری
- باقی
- ضرورت
- کی ضرورت ہے
- وسائل
- نتیجہ
- نتائج کی نمائش
- جائزہ
- امیر
- کردار
- جڑ
- رن
- چل رہا ہے
- اسی
- اسکین
- سیکنڈ
- سیکشن
- سیکورٹی
- منتخب
- منتخب
- بے سرور
- سروس
- سروسز
- اجلاس
- مقرر
- سیٹ
- قائم کرنے
- ترتیبات
- ہونا چاہئے
- دکھائیں
- شوز
- سادہ
- حالات
- سائز
- سست
- چھوٹے
- سنیپشاٹ
- So
- سافٹ ویئر کی
- حل
- حل
- کچھ
- چنگاری
- مخصوص
- تیزی
- خرچ کرنا۔
- SQL
- شروع
- حالت
- بیان
- بیانات
- اعدادوشمار
- مرحلہ
- مراحل
- ابھی تک
- ذخیرہ
- ذخیرہ
- ذخیرہ
- پردہ
- حکمت عملیوں
- حکمت عملی
- منظم
- منظم اور غیر منظم ڈیٹا
- سٹوڈیو
- سب نیٹ
- بعد میں
- کامیابی کے ساتھ
- اس طرح
- کافی
- خلاصہ
- حمایت
- تائید
- امدادی
- کی حمایت کرتا ہے
- ٹیبل
- لیتا ہے
- لینے
- ہدف
- کاموں
- تکنیک
- ٹینس
- ٹیسٹ
- ٹیسٹنگ
- ٹیسٹ
- ۔
- کے بارے میں معلومات
- ریاست
- ان
- اس طرح
- ہزاروں
- تین
- کے ذریعے
- وقت
- وقت سفر
- کرنے کے لئے
- مل کر
- بھی
- اوزار
- سب سے اوپر
- کل
- ٹریک
- معاملات
- تبدیل
- سفر
- سفر
- ٹرن
- اقسام
- کے تحت
- منفرد
- اپ ڈیٹ کریں
- اپ ڈیٹ
- تازہ ترین معلومات
- اپ ڈیٹ
- URL
- استعمال کی شرائط
- استعمال کیس
- صارفین
- عام طور پر
- ویل
- قیمت
- اقدار
- اس بات کی تصدیق
- ورژن
- چلا گیا
- واک تھرو
- گودام
- گھڑیاں
- طریقوں
- ویب
- ویب خدمات
- کیا
- چاہے
- جس
- جبکہ
- وسیع
- وسیع رینج
- گے
- بغیر
- کام
- کام کر
- کام کرتا ہے
- گا
- لکھنا
- تحریری طور پر
- اور
- زیفیرنیٹ