Các tổ chức đã chọn xây dựng hồ dữ liệu trên Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) trong nhiều năm. Hồ dữ liệu là lựa chọn phổ biến nhất cho các tổ chức để lưu trữ tất cả dữ liệu tổ chức của họ được tạo bởi các nhóm khác nhau, trên các lĩnh vực kinh doanh, từ tất cả các định dạng khác nhau và thậm chí trong lịch sử. Dựa theo một nghiên cứu, trung bình một công ty đang chứng kiến khối lượng dữ liệu của họ tăng lên với tốc độ vượt quá 50% mỗi năm, thường quản lý trung bình 33 nguồn dữ liệu duy nhất để phân tích.
Các nhóm thường cố gắng sao chép hàng nghìn công việc từ cơ sở dữ liệu quan hệ với cùng một mẫu trích xuất, biến đổi và tải (ETL). Có rất nhiều nỗ lực trong việc duy trì trạng thái công việc và lên lịch cho các công việc riêng lẻ này. Cách tiếp cận này giúp các nhóm thêm bảng với ít thay đổi và cũng duy trì trạng thái công việc với nỗ lực tối thiểu. Điều này có thể dẫn đến một cải tiến lớn trong tiến trình phát triển và theo dõi các công việc một cách dễ dàng.
Trong bài đăng này, chúng tôi chỉ cho bạn cách dễ dàng sao chép tất cả các kho lưu trữ dữ liệu quan hệ của bạn thành hồ dữ liệu giao dịch theo cách tự động với một tác vụ ETL duy nhất bằng cách sử dụng Apache Iceberg và Keo AWS.
Giải pháp xây dựng
Hồ dữ liệu là thường được tổ chức sử dụng các bộ chứa S3 riêng biệt cho ba lớp dữ liệu: lớp thô chứa dữ liệu ở dạng ban đầu, lớp giai đoạn chứa dữ liệu được xử lý trung gian được tối ưu hóa để sử dụng và lớp phân tích chứa dữ liệu tổng hợp cho các trường hợp sử dụng cụ thể. Trong lớp thô, các bảng thường được sắp xếp dựa trên nguồn dữ liệu của chúng, trong khi các bảng trong lớp giai đoạn được sắp xếp dựa trên các lĩnh vực kinh doanh mà chúng thuộc về.
Bài đăng này cung cấp một Hình thành đám mây AWS mẫu triển khai công việc AWS Glue đọc đường dẫn Amazon S3 cho một nguồn dữ liệu của lớp thô của hồ dữ liệu và nhập dữ liệu vào các bảng Apache Iceberg trên lớp sân khấu bằng cách sử dụng Hỗ trợ AWS Glue cho các khung dữ liệu. Công việc yêu cầu các bảng trong lớp thô được cấu trúc theo cách Dịch vụ di chuyển cơ sở dữ liệu AWS (AWS DMS) nhập chúng: lược đồ, sau đó là bảng, sau đó là tệp dữ liệu.
Giải pháp này sử dụng Cửa hàng thông số trình quản lý hệ thống AWS cho cấu hình bảng. Bạn nên sửa đổi tham số này chỉ định các bảng bạn muốn xử lý và cách xử lý, bao gồm thông tin như khóa chính, phân vùng và miền kinh doanh được liên kết. Công việc sử dụng thông tin này để tự động tạo cơ sở dữ liệu (nếu nó chưa tồn tại) cho mọi miền doanh nghiệp, tạo bảng Iceberg và thực hiện tải dữ liệu.
Cuối cùng, chúng ta có thể sử dụng amazon Athena để truy vấn dữ liệu trong các bảng Iceberg.
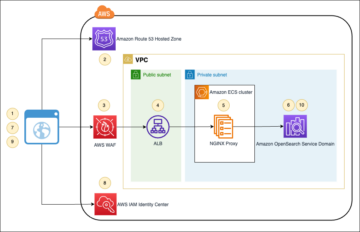
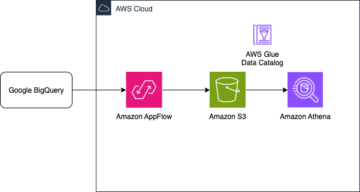
Sơ đồ sau minh họa kiến trúc này.

Việc triển khai này có những cân nhắc sau:
- Tất cả các bảng từ nguồn dữ liệu phải có khóa chính để được sao chép bằng giải pháp này. Khóa chính có thể là một cột đơn hoặc khóa tổng hợp có nhiều cột.
- Nếu hồ dữ liệu chứa các bảng không cần upserts hoặc không có khóa chính, thì bạn có thể loại trừ chúng khỏi cấu hình tham số và triển khai các quy trình ETL truyền thống để nhập chúng vào hồ dữ liệu. Đó là ngoài phạm vi của bài viết này.
- Nếu có các nguồn dữ liệu bổ sung cần được nhập, bạn có thể triển khai nhiều ngăn xếp CloudFormation, một ngăn xếp để xử lý từng nguồn dữ liệu.
- Tác vụ AWS Glue được thiết kế để xử lý dữ liệu theo hai giai đoạn: tải ban đầu chạy sau khi AWS DMS hoàn thành tác vụ tải đầy đủ và tải gia tăng chạy theo lịch trình áp dụng các tệp thu thập dữ liệu thay đổi (CDC) do AWS DMS ghi lại. Xử lý gia tăng được thực hiện bằng cách sử dụng một Dấu trang công việc AWS Glue.
Có chín bước để hoàn thành hướng dẫn này:
- Thiết lập điểm cuối nguồn cho AWS DMS.
- Triển khai giải pháp bằng AWS CloudFormation.
- Xem lại tác vụ sao chép AWS DMS.
- Tùy chọn, thêm quyền để mã hóa và giải mã hoặc Sự hình thành hồ AWS.
- Xem lại cấu hình bảng trên Parameter Store.
- Thực hiện nạp dữ liệu ban đầu.
- Thực hiện tải dữ liệu gia tăng.
- Theo dõi quá trình nhập bảng.
- Lên lịch tải dữ liệu hàng loạt gia tăng.
Điều kiện tiên quyết
Trước khi bắt đầu hướng dẫn này, bạn nên làm quen với Iceberg. Nếu chưa, bạn có thể bắt đầu bằng cách sao chép một bảng duy nhất theo hướng dẫn trong Triển khai UPSERT dựa trên CDC trong hồ dữ liệu bằng Apache Iceberg và AWS Glue. Ngoài ra, hãy thiết lập như sau:
Thiết lập điểm cuối nguồn cho AWS DMS
Trước khi tạo tác vụ AWS DMS, chúng ta cần thiết lập điểm cuối nguồn để kết nối với cơ sở dữ liệu nguồn:
- Trên bảng điều khiển AWS DMS, hãy chọn Điểm cuối trong khung điều hướng.
- Chọn Tạo điểm cuối.
- Nếu cơ sở dữ liệu của bạn đang chạy trên Amazon RDS, hãy chọn Chọn phiên bản RDS DB, sau đó chọn phiên bản từ danh sách. Nếu không, hãy chọn công cụ nguồn và cung cấp thông tin kết nối thông qua Quản lý bí mật AWS hoặc thủ công.
- Trong định danh điểm cuối, nhập tên cho điểm cuối; ví dụ: nguồn-postgresql.
- Chọn Tạo điểm cuối.
Triển khai giải pháp bằng AWS CloudFormation
Tạo ngăn xếp CloudFormation bằng mẫu được cung cấp. Hoàn thành các bước sau:
- Chọn Khởi chạy ngăn xếp:

- Chọn Sau.
- Cung cấp tên ngăn xếp, chẳng hạn như
transactionaldl-postgresql. - Nhập các thông số cần thiết:
- DMSS3EndpointIAMRoleARN – Vai trò IAM ARN cho AWS DMS để ghi dữ liệu vào Amazon S3.
- Sao chépInstanceArn – Phiên bản sao chép AWS DMS ARN.
- S3Giai đoạn xô – Tên của bộ chứa hiện có được sử dụng cho lớp giai đoạn của kho dữ liệu.
- S3XôKeo Dán – Tên của bộ chứa S3 hiện có để lưu trữ tập lệnh AWS Glue.
- S3XôLiệu – Tên của bộ chứa hiện có được sử dụng cho lớp thô của kho dữ liệu.
- NguồnEndpointArn – ARN điểm cuối AWS DMS mà bạn đã tạo trước đó.
- Tên nguồn – Mã định danh tùy ý của nguồn dữ liệu để sao chép (ví dụ:
postgres). Điều này được sử dụng để xác định đường dẫn S3 của hồ dữ liệu (lớp thô) nơi dữ liệu sẽ được lưu trữ.
- Không sửa đổi các thông số sau:
- NguồnS3BucketBlog – Tên bộ chứa nơi lưu trữ tập lệnh AWS Glue được cung cấp.
- NguồnS3BucketPrefix – Tên tiền tố bộ chứa nơi lưu trữ tập lệnh AWS Glue được cung cấp.
- Chọn Sau hai lần.
- Chọn Tôi xác nhận rằng AWS CloudFormation có thể tạo tài nguyên IAM với tên tùy chỉnh.
- Chọn Tạo ngăn xếp.
Sau khoảng 5 phút, ngăn xếp CloudFormation được triển khai.
Xem lại tác vụ sao chép AWS DMS
Việc triển khai AWS CloudFormation đã tạo một điểm cuối đích AWS DMS cho bạn. Do có hai cài đặt điểm cuối cụ thể, dữ liệu sẽ được nhập khi chúng tôi cần trên Amazon S3.
- Trên bảng điều khiển AWS DMS, hãy chọn Điểm cuối trong khung điều hướng.
- Tìm kiếm và chọn điểm cuối bắt đầu bằng
dmsIcebergs3endpoint. - Xem lại cài đặt điểm cuối:
DataFormatđược chỉ định làparquet.TimestampColumnNamesẽ thêm cộtlast_update_timevới ngày tạo bản ghi trên Amazon S3.

Việc triển khai cũng tạo ra một tác vụ sao chép AWS DMS bắt đầu bằng dmsicebergtask.
- Chọn nhiệm vụ sao chép trong ngăn dẫn hướng và tìm kiếm tác vụ.
Bạn sẽ thấy rằng Loại công việc được đánh dấu là Tải đầy đủ, sao chép liên tục. AWS DMS sẽ thực hiện tải toàn bộ dữ liệu hiện có ban đầu, sau đó tạo các tệp gia tăng với các thay đổi được thực hiện đối với cơ sở dữ liệu nguồn.
trên quy tắc ánh xạ tab, có hai loại quy tắc:
- Quy tắc lựa chọn có tên của lược đồ nguồn và các bảng sẽ được nhập từ cơ sở dữ liệu nguồn. Theo mặc định, nó sử dụng cơ sở dữ liệu mẫu được cung cấp trong điều kiện tiên quyết,
dms_sample, và tất cả các bảng có từ khóa %. - Hai quy tắc chuyển đổi bao gồm tên lược đồ và tên bảng dưới dạng cột trong các tệp đích trên Amazon S3. Điều này được công việc AWS Glue của chúng tôi sử dụng để biết các tệp trong kho dữ liệu tương ứng với bảng nào.
Để tìm hiểu thêm về cách tùy chỉnh điều này cho các nguồn dữ liệu của riêng bạn, hãy tham khảo Quy tắc lựa chọn và hành động.

Hãy thay đổi một số cấu hình để hoàn thành việc chuẩn bị nhiệm vụ của chúng ta.
- trên Hoạt động menu, chọn Sửa đổi.
- Trong tạp chí Cài đặt tác vụ phần, dưới Dừng tác vụ sau khi hoàn thành tải đầy đủ, chọn Dừng sau khi áp dụng các thay đổi được lưu trong bộ nhớ cache.
Bằng cách này, chúng tôi có thể kiểm soát tải ban đầu và tạo tệp gia tăng theo hai bước khác nhau. Chúng tôi sử dụng phương pháp hai bước này để chạy tác vụ AWS Glue một lần cho mỗi bước.
- Theo Nhật ký tác vụ, chọn Bật nhật ký CloudWatch.
- Chọn Lưu.
- Đợi khoảng 1 phút để trạng thái tác vụ di chuyển cơ sở dữ liệu hiển thị dưới dạng Sẵn sàng.
Thêm quyền để mã hóa và giải mã hoặc Lake Formation
Theo tùy chọn, bạn có thể thêm quyền để mã hóa và giải mã hoặc Lake Formation.
Thêm quyền mã hóa và giải mã
Nếu bộ chứa S3 của bạn được sử dụng cho lớp thô và lớp giai đoạn được mã hóa bằng cách sử dụng Dịch vụ quản lý khóa AWS (AWS KMS) do khách hàng quản lý, bạn cần thêm quyền để cho phép tác vụ AWS Glue truy cập dữ liệu:
Thêm quyền Formation hồ
Nếu đang quản lý quyền bằng Lake Formation, bạn cần cho phép công việc AWS Glue của mình tạo bảng và cơ sở dữ liệu cho miền của bạn thông qua vai trò IAM GlueJobRole.
- Cấp quyền để tạo cơ sở dữ liệu (để biết hướng dẫn, hãy tham khảo Tạo cơ sở dữ liệu).
- Cấp quyền SUPER cho
defaultcơ sở dữ liệu. - Cấp quyền vị trí dữ liệu.
- Nếu bạn tạo cơ sở dữ liệu theo cách thủ công, hãy cấp quyền trên tất cả các cơ sở dữ liệu để tạo bảng. tham khảo Cấp quyền cho bảng bằng bảng điều khiển Lake Formation và phương thức tài nguyên được đặt tên or Cấp quyền cho Danh mục dữ liệu bằng phương pháp LF-TBAC theo trường hợp sử dụng của bạn.
Sau khi bạn hoàn thành bước sau để thực hiện tải dữ liệu ban đầu, hãy đảm bảo cũng thêm quyền cho người tiêu dùng để truy vấn các bảng. Vai trò công việc sẽ trở thành chủ sở hữu của tất cả các bảng được tạo và sau đó, quản trị viên hồ dữ liệu có thể thực hiện cấp quyền cho người dùng bổ sung.
Xem lại cấu hình bảng trong Cửa hàng thông số
Công việc AWS Glue thực hiện việc nhập dữ liệu vào các bảng Iceberg sử dụng đặc tả bảng được cung cấp trong Lưu trữ thông số. Hoàn thành các bước sau để xem lại kho lưu trữ thông số đã được định cấu hình tự động cho bạn. Nếu cần, sửa đổi theo nhu cầu của riêng bạn.
- Trên bảng điều khiển Cửa hàng tham số, chọn thông số của tôi trong khung điều hướng.
Ngăn xếp CloudFormation đã tạo hai tham số:
iceberg-configcho cấu hình công việciceberg-tablescho cấu hình bảng
- Chọn tham số tảng băng trôi.
Cấu trúc JSON chứa thông tin mà AWS Glue sử dụng để đọc dữ liệu và ghi các bảng Iceberg trên miền đích:
- Một đối tượng trên mỗi bảng – Tên của đối tượng được tạo bằng cách sử dụng tên lược đồ, dấu chấm và tên bảng; Ví dụ,
schema.table. - khóa chính – Điều này phải được chỉ định cho mọi bảng nguồn. Bạn có thể cung cấp một cột hoặc danh sách các cột được phân tách bằng dấu phẩy (không có dấu cách).
- phân vùngCols – Điều này tùy chọn phân vùng các cột cho các bảng mục tiêu. Nếu bạn không muốn tạo các bảng được phân vùng, hãy cung cấp một chuỗi trống. Nếu không, hãy cung cấp một cột hoặc danh sách các cột được phân tách bằng dấu phẩy sẽ được sử dụng (không có dấu cách).
- Nếu bạn muốn sử dụng nguồn dữ liệu của riêng mình, hãy sử dụng mã JSON sau đây và thay thế văn bản bằng CHỮ HOA từ mẫu được cung cấp. Nếu bạn đang sử dụng nguồn dữ liệu mẫu được cung cấp, hãy giữ cài đặt mặc định:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Chọn Lưu các thay đổi.
Thực hiện tải dữ liệu ban đầu
Bây giờ cấu hình cần thiết đã hoàn tất, chúng tôi nhập dữ liệu ban đầu. Bước này bao gồm ba phần: nhập dữ liệu từ cơ sở dữ liệu quan hệ nguồn vào lớp thô của hồ dữ liệu, tạo bảng Iceberg trên lớp sân khấu của hồ dữ liệu và xác minh kết quả bằng Athena.
Nhập dữ liệu vào lớp thô của hồ dữ liệu
Để nhập dữ liệu từ nguồn dữ liệu quan hệ (PostgreSQL nếu bạn đang sử dụng mẫu được cung cấp) vào kho dữ liệu giao dịch của chúng tôi bằng Iceberg, hãy hoàn thành các bước sau:
- Trên bảng điều khiển AWS DMS, hãy chọn Nhiệm vụ di chuyển cơ sở dữ liệu trong khung điều hướng.
- Chọn tác vụ sao chép bạn đã tạo và trên Hoạt động menu, chọn Khởi động lại / Tiếp tục.
- Đợi khoảng 5 phút để tác vụ sao chép hoàn tất. Bạn có thể theo dõi các bảng được nhập trên Thống kê học tab của tác vụ sao chép.

Sau vài phút, nhiệm vụ kết thúc với thông báo Hoàn thành tải đầy đủ.
- Trên bảng điều khiển Amazon S3, chọn bộ chứa mà bạn đã xác định là lớp thô.
Theo tiền tố S3 được xác định trên AWS DMS (ví dụ: postgres), bạn sẽ thấy hệ thống phân cấp các thư mục có cấu trúc sau:
- Schema
- Tên bảng
LOAD00000001.parquetLOAD0000000N.parquet
- Tên bảng

Nếu bộ chứa S3 của bạn trống, hãy xem lại Khắc phục sự cố các tác vụ di chuyển trong Dịch vụ di chuyển cơ sở dữ liệu AWS trước khi chạy tác vụ AWS Glue.
Tạo và nhập dữ liệu vào bảng Iceberg
Trước khi chạy tác vụ, hãy điều hướng tập lệnh của tác vụ AWS Glue được cung cấp như một phần của ngăn xếp CloudFormation để hiểu hành vi của tác vụ.
- Trên bảng điều khiển AWS Glue Studio, hãy chọn việc làm trong khung điều hướng.
- Tìm kiếm công việc bắt đầu với
IcebergJob-và một hậu tố của tên ngăn xếp CloudFormation của bạn (ví dụ:IcebergJob-transactionaldl-postgresql). - Chọn công việc.

Tập lệnh công việc lấy cấu hình cần thiết từ Cửa hàng tham số. Chức năng getConfigFromSSM() trả về các cấu hình liên quan đến công việc, chẳng hạn như nhóm nguồn và đích từ nơi dữ liệu cần được đọc và ghi. biến ssmparam_table_values chứa thông tin liên quan đến bảng như miền dữ liệu, tên bảng, cột phân vùng và khóa chính của bảng cần nhập. Xem mã Python sau:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Tập lệnh sử dụng tên danh mục tùy ý cho Iceberg được xác định là my_catalog. Điều này được triển khai trên Danh mục dữ liệu AWS Glue bằng cách sử dụng cấu hình Spark, do đó, thao tác SQL trỏ đến my_catalog sẽ được áp dụng trên Danh mục dữ liệu. Xem đoạn mã sau:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Tập lệnh lặp lại trên các bảng được xác định trong Lưu trữ tham số và thực hiện logic để phát hiện xem bảng có tồn tại hay không và liệu dữ liệu đến là tải ban đầu hay tải lên:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')Sản phẩm initialLoadRecordsSparkSQL() chức năng tải dữ liệu ban đầu khi không có cột thao tác nào trong tệp S3. AWS DMS chỉ thêm cột này vào các tệp dữ liệu Parquet do quá trình sao chép liên tục (CDC) tạo ra. Việc tải dữ liệu được thực hiện bằng lệnh INSERT INTO với SparkSQL. Xem đoạn mã sau:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Bây giờ, chúng tôi chạy công việc AWS Glue để nhập dữ liệu ban đầu vào các bảng Iceberg. Ngăn xếp CloudFormation thêm --datalake-formats tham số, thêm các thư viện Iceberg cần thiết vào công việc.
- Chọn Chạy công việc.
- Chọn Chạy công việc để theo dõi trạng thái. Chờ cho đến khi trạng thái Chạy thành công.
Xác minh dữ liệu đã tải
Để xác nhận rằng công việc đã xử lý dữ liệu như mong đợi, hãy hoàn tất các bước sau:
- Trên bảng điều khiển Athena, chọn Trình soạn thảo truy vấn trong khung điều hướng.
- Xác minh
AwsDataCatalogđược chọn làm nguồn dữ liệu. - Theo Cơ sở dữ liệu, chọn miền dữ liệu mà bạn muốn khám phá, dựa trên cấu hình bạn đã xác định trong kho lưu trữ tham số. Nếu sử dụng cơ sở dữ liệu mẫu được cung cấp, hãy sử dụng
sports.
Theo Bảng và dạng xem, chúng ta có thể xem danh sách các bảng được tạo bởi tác vụ AWS Glue.
- Chọn menu tùy chọn (ba dấu chấm) bên cạnh tên bảng đầu tiên, sau đó chọn Xem trước dữ liệu.
Bạn có thể xem dữ liệu được tải vào các bảng Iceberg. 
Thực hiện tải dữ liệu gia tăng
Bây giờ, chúng tôi bắt đầu nắm bắt các thay đổi từ cơ sở dữ liệu quan hệ của mình và áp dụng chúng vào kho dữ liệu giao dịch. Bước này cũng được chia thành ba phần: nắm bắt các thay đổi, áp dụng chúng cho các bảng Iceberg và xác minh kết quả.
Nắm bắt các thay đổi từ cơ sở dữ liệu quan hệ
Do cấu hình chúng tôi đã chỉ định, tác vụ sao chép đã dừng sau khi chạy toàn bộ giai đoạn tải. Bây giờ, chúng tôi khởi động lại tác vụ để thêm các tệp gia tăng có thay đổi vào lớp thô của hồ dữ liệu.
- Trên bảng điều khiển AWS DMS, chọn tác vụ chúng tôi đã tạo và chạy trước đó.
- trên Hoạt động menu, chọn Sơ yếu lý lịch.
- Chọn Bắt đầu công việc để bắt đầu nắm bắt các thay đổi.
- Để kích hoạt quá trình tạo tệp mới trên hồ dữ liệu, hãy thực hiện thao tác chèn, cập nhật hoặc xóa trên các bảng của cơ sở dữ liệu nguồn bằng công cụ quản trị cơ sở dữ liệu ưa thích của bạn. Nếu sử dụng cơ sở dữ liệu mẫu được cung cấp, bạn có thể chạy các lệnh SQL sau:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- Trên trang chi tiết tác vụ AWS DMS, hãy chọn Bảng thống kê tab để xem các thay đổi được ghi lại.

- Mở lớp thô của hồ dữ liệu để tìm một tệp mới chứa các thay đổi gia tăng bên trong tiền tố của mỗi bảng, ví dụ: bên dưới
sporting_eventtiếp đầu ngữ.
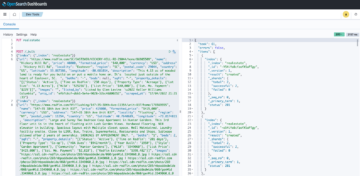
Bản ghi với những thay đổi cho sporting_event bảng trông giống như ảnh chụp màn hình sau đây.

Chú ý Op cột ở phần đầu được xác định bằng một bản cập nhật (U). Ngoài ra, giá trị ngày/giờ thứ hai là cột kiểm soát được AWS DMS thêm vào cùng với thời điểm thay đổi được ghi lại.

Áp dụng các thay đổi trên bảng Iceberg bằng AWS Glue
Bây giờ, chúng tôi chạy lại công việc AWS Glue và nó sẽ tự động chỉ xử lý các tệp gia tăng mới kể từ khi đánh dấu công việc được bật. Hãy xem lại nó hoạt động như thế nào.
Sản phẩm dedupCDCRecords() chức năng thực hiện chống trùng lặp dữ liệu vì có thể ghi lại nhiều thay đổi đối với một ID bản ghi trong cùng một tệp dữ liệu trên Amazon S3. Chống trùng lặp được thực hiện dựa trên last_update_time cột do AWS DMS thêm vào cho biết dấu thời gian khi thay đổi được ghi lại. Xem mã Python sau:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFTrên dòng 99, upsertRecordsSparkSQL() chức năng thực hiện upsert theo cách tương tự như tải ban đầu, nhưng lần này với lệnh SQL MERGE.
Xem lại các thay đổi đã áp dụng
Mở bảng điều khiển Athena và chạy truy vấn chọn các bản ghi đã thay đổi trên cơ sở dữ liệu nguồn. Nếu sử dụng cơ sở dữ liệu mẫu được cung cấp, hãy sử dụng một trong các truy vấn SQL sau:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Theo dõi quá trình nhập bảng
Kịch bản công việc AWS Glue được mã hóa đơn giản xử lý ngoại lệ Python để bắt lỗi trong quá trình xử lý một bảng cụ thể. Dấu trang công việc được lưu sau khi mỗi bảng kết thúc xử lý thành công, để tránh xử lý lại các bảng nếu chạy lại công việc cho các bảng có lỗi.
Sản phẩm Giao diện dòng lệnh AWS (AWS CLI) cung cấp một get-job-bookmark lệnh cho AWS Glue cung cấp thông tin chi tiết về trạng thái của dấu trang đối với từng bảng được xử lý.
- Trên bảng điều khiển AWS Glue Studio, chọn công việc ETL.
- Chọn Chạy công việc tab và sao chép ID chạy công việc.
- Chạy lệnh sau trên thiết bị đầu cuối được xác thực cho AWS CLI, thay thế
<GLUE_JOB_RUN_ID>trên dòng 1 với giá trị bạn đã sao chép. Nếu ngăn xếp CloudFormation của bạn không được đặt têntransactionaldl-postgresql, cung cấp tên công việc của bạn trên dòng 2 của tập lệnh:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunTrong giải pháp này, khi quá trình xử lý bảng gây ra ngoại lệ, tác vụ AWS Glue sẽ không bị lỗi theo logic này. Thay vào đó, bảng sẽ được thêm vào một mảng được in sau khi công việc hoàn tất. Trong trường hợp như vậy, công việc sẽ được đánh dấu là không thành công sau khi nó cố xử lý phần còn lại của bảng được phát hiện trên nguồn dữ liệu thô. Bằng cách này, các bảng không có lỗi không phải đợi cho đến khi người dùng xác định và giải quyết vấn đề trên các bảng xung đột. Người dùng có thể nhanh chóng phát hiện các lần chạy công việc gặp sự cố bằng cách sử dụng trạng thái chạy công việc AWS Glue và xác định bảng cụ thể nào đang gây ra sự cố bằng cách sử dụng nhật ký CloudWatch cho lần chạy công việc.
- Tập lệnh công việc triển khai tính năng này bằng mã Python sau:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')Ảnh chụp màn hình sau đây cho thấy cách nhật ký CloudWatch tìm kiếm các bảng gây ra lỗi khi xử lý.

Phù hợp với Ống kính phân tích dữ liệu khung kiến trúc tối ưu AWS thực tiễn, bạn có thể điều chỉnh các cơ chế kiểm soát phức tạp hơn để xác định và thông báo cho các bên liên quan khi lỗi xuất hiện trên đường ống dẫn dữ liệu. Ví dụ, bạn có thể sử dụng một Máy phát điện Amazon bảng điều khiển để lưu trữ tất cả các bảng và công việc chạy có lỗi hoặc sử dụng Dịch vụ thông báo đơn giản của Amazon (Amazon SNS) đến gửi cảnh báo cho các nhà khai thác khi một số tiêu chí được đáp ứng.
Lên lịch tải dữ liệu hàng loạt gia tăng
Ngăn xếp CloudFormation triển khai một Sự kiện Amazon quy tắc (được tắt theo mặc định) có thể kích hoạt công việc AWS Glue chạy theo lịch trình. Để cung cấp lịch biểu của riêng bạn và kích hoạt quy tắc, hãy hoàn thành các bước sau:
- Trên bảng điều khiển EventBridge, chọn Nội quy trong khung điều hướng.
- Tìm kiếm quy tắc có tiền tố là tên của ngăn xếp CloudFormation của bạn, sau đó là
JobTrigger(ví dụ,transactionaldl-postgresql-JobTrigger-randomvalue). - Chọn quy tắc.
- Theo Lịch sự kiện, chọn Chỉnh sửa.
Lịch trình mặc định được định cấu hình để kích hoạt mỗi giờ.
- Cung cấp lịch trình bạn muốn chạy công việc.
- Ngoài ra, bạn có thể sử dụng một Biểu thức cron EventBridge bằng việc lựa chọn Một lịch trình chi tiết.

- Khi bạn thiết lập xong biểu thức cron, hãy chọn Sau ba lần, và cuối cùng chọn Cập nhật quy tắc để lưu thay đổi.
Quy tắc được tạo bị vô hiệu hóa theo mặc định để cho phép bạn chạy tải dữ liệu ban đầu trước.
- Kích hoạt quy tắc bằng cách chọn Kích hoạt tính năng.
Bạn có thể sử dụng Giám sát tab để xem các yêu cầu quy tắc hoặc trực tiếp trên AWS Glue chạy công việc chi tiết.
Kết luận
Sau khi triển khai giải pháp này, bạn đã tự động nhập các bảng của mình trên một nguồn dữ liệu quan hệ duy nhất. Các tổ chức sử dụng hồ dữ liệu làm nền tảng dữ liệu trung tâm của họ thường cần xử lý nhiều, đôi khi thậm chí hàng chục nguồn dữ liệu. Ngoài ra, ngày càng có nhiều trường hợp sử dụng yêu cầu các tổ chức triển khai các khả năng giao dịch cho kho dữ liệu. Bạn có thể sử dụng giải pháp này để đẩy nhanh việc áp dụng các khả năng như vậy trên tất cả các nguồn dữ liệu quan hệ của mình để kích hoạt các trường hợp sử dụng kinh doanh mới, tự động hóa quy trình triển khai để thu được nhiều giá trị hơn từ dữ liệu của bạn.
Về các tác giả
 Luis Gerardo Baeza là Kiến trúc sư dữ liệu lớn trong Phòng thí nghiệm dữ liệu Amazon Web Services (AWS). Ông có 12 năm kinh nghiệm trợ giúp các tổ chức trong lĩnh vực chăm sóc sức khỏe, tài chính và giáo dục áp dụng các chương trình kiến trúc doanh nghiệp, điện toán đám mây và khả năng phân tích dữ liệu. Luis hiện đang giúp các tổ chức trên khắp Châu Mỹ Latinh đẩy nhanh các sáng kiến dữ liệu chiến lược.
Luis Gerardo Baeza là Kiến trúc sư dữ liệu lớn trong Phòng thí nghiệm dữ liệu Amazon Web Services (AWS). Ông có 12 năm kinh nghiệm trợ giúp các tổ chức trong lĩnh vực chăm sóc sức khỏe, tài chính và giáo dục áp dụng các chương trình kiến trúc doanh nghiệp, điện toán đám mây và khả năng phân tích dữ liệu. Luis hiện đang giúp các tổ chức trên khắp Châu Mỹ Latinh đẩy nhanh các sáng kiến dữ liệu chiến lược.
 SaiKiran Reddy Aenugu là Kiến trúc sư dữ liệu trong Phòng thí nghiệm dữ liệu Amazon Web Services (AWS). Ông có 10 năm kinh nghiệm triển khai các quy trình tải, chuyển đổi và trực quan hóa dữ liệu. SaiKiran hiện đang giúp các tổ chức ở Bắc Mỹ áp dụng các kiến trúc dữ liệu hiện đại như hồ dữ liệu và lưới dữ liệu. Ông có kinh nghiệm trong lĩnh vực bán lẻ, hàng không và tài chính.
SaiKiran Reddy Aenugu là Kiến trúc sư dữ liệu trong Phòng thí nghiệm dữ liệu Amazon Web Services (AWS). Ông có 10 năm kinh nghiệm triển khai các quy trình tải, chuyển đổi và trực quan hóa dữ liệu. SaiKiran hiện đang giúp các tổ chức ở Bắc Mỹ áp dụng các kiến trúc dữ liệu hiện đại như hồ dữ liệu và lưới dữ liệu. Ông có kinh nghiệm trong lĩnh vực bán lẻ, hàng không và tài chính.
 Narendra Merla là Kiến trúc sư dữ liệu trong Phòng thí nghiệm dữ liệu Amazon Web Services (AWS). Anh ấy có 12 năm kinh nghiệm trong việc thiết kế và sản xuất các đường ống dữ liệu theo định hướng hàng loạt và theo thời gian thực cũng như xây dựng các hồ dữ liệu trên cả môi trường đám mây và tại chỗ. Narendra hiện đang giúp các tổ chức ở Bắc Mỹ xây dựng và thiết kế các kiến trúc dữ liệu mạnh mẽ, đồng thời có kinh nghiệm trong lĩnh vực tài chính và viễn thông.
Narendra Merla là Kiến trúc sư dữ liệu trong Phòng thí nghiệm dữ liệu Amazon Web Services (AWS). Anh ấy có 12 năm kinh nghiệm trong việc thiết kế và sản xuất các đường ống dữ liệu theo định hướng hàng loạt và theo thời gian thực cũng như xây dựng các hồ dữ liệu trên cả môi trường đám mây và tại chỗ. Narendra hiện đang giúp các tổ chức ở Bắc Mỹ xây dựng và thiết kế các kiến trúc dữ liệu mạnh mẽ, đồng thời có kinh nghiệm trong lĩnh vực tài chính và viễn thông.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Giới thiệu
- đẩy nhanh tiến độ
- truy cập
- Theo
- công nhận
- ngang qua
- thích ứng
- thêm
- thêm vào
- Ngoài ra
- Thêm
- quản trị viên
- quản lý
- nhận nuôi
- Nhận con nuôi
- Sau
- hãng hàng không
- Tất cả
- Đã
- đàn bà gan dạ
- amazon Athena
- Amazon RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- Mỹ
- phân tích
- phân tích
- và
- Angeles
- Apache
- xuất hiện
- Các Ứng Dụng
- áp dụng
- Nộp đơn
- phương pháp tiếp cận
- khoảng
- kiến trúc
- Mảng
- liên kết
- chứng thực
- tự động hóa
- Tự động
- tự động
- tự động hóa
- Trung bình cộng
- tránh
- AWS
- Hình thành đám mây AWS
- Keo AWS
- dựa
- đánh nhau
- bởi vì
- trở nên
- trước
- Bắt đầu
- lớn
- Dữ Liệu Lớn.
- xây dựng
- xây dựng
- Xây dựng
- kinh doanh
- Có thể có được
- khả năng
- mũ
- nắm bắt
- Chụp
- trường hợp
- trường hợp
- Danh mục hàng
- Catch
- Nguyên nhân
- nguyên nhân
- gây ra
- CDC
- trung tâm
- nhất định
- thay đổi
- Những thay đổi
- sự lựa chọn
- Chọn
- lựa chọn
- lựa chọn
- đám mây
- điện toán đám mây
- mã
- Cột
- Cột
- công ty
- hoàn thành
- máy tính
- Cấu hình
- cấu hình
- Xác nhận
- Mâu thuẫn
- Kết nối
- liên quan
- sự cân nhắc
- An ủi
- Người tiêu dùng
- tiêu thụ
- chứa
- tiếp tục
- liên tục
- điều khiển
- có thể
- tạo
- tạo ra
- tạo ra
- Tạo
- tạo
- tiêu chuẩn
- Hiện nay
- khách hàng
- khách hàng
- tùy chỉnh
- dữ liệu
- Phân tích dữ liệu
- Hồ dữ liệu
- Nền tảng dữ liệu
- Cơ sở dữ liệu
- cơ sở dữ liệu
- Ngày
- Mặc định
- xác định
- triển khai
- triển khai
- triển khai
- triển khai
- triển khai
- Thiết kế
- thiết kế
- thiết kế
- chi tiết
- phát hiện
- Phát triển
- khác nhau
- trực tiếp
- bị vô hiệu hóa
- Chia
- Không
- miền
- lĩnh vực
- dont
- suốt trong
- mỗi
- Sớm hơn
- dễ dàng
- Đào tạo
- nỗ lực
- hay
- cho phép
- kích hoạt
- mã hóa
- mã hóa
- Điểm cuối
- Động cơ
- đăng ký hạng mục thi
- Doanh nghiệp
- môi trường
- lỗi
- Ether (ETH)
- Ngay cả
- Mỗi
- ví dụ
- vượt quá
- Trừ
- ngoại lệ
- hiện tại
- tồn tại
- dự kiến
- kỳ vọng
- kinh nghiệm
- khám phá
- mở rộng
- trích xuất
- thất bại
- quen
- Thời trang
- Đặc tính
- vài
- Tập tin
- Các tập tin
- Cuối cùng
- tài chính
- tài chính
- Tìm kiếm
- hoàn thành
- Tên
- sau
- tiếp theo
- Dành cho người tiêu dùng
- hình thức
- hình thành
- Khung
- từ
- Full
- chức năng
- tạo ra
- thế hệ
- được
- cấp
- tài trợ
- Phát triển
- xử lý
- chăm sóc sức khỏe
- giúp đỡ
- giúp
- hệ thống cấp bậc
- lịch sử
- tổ chức
- Độ đáng tin của
- Hướng dẫn
- HTML
- HTTPS
- lớn
- IAM
- xác định
- định danh
- xác định
- xác định
- thực hiện
- thực hiện
- thực hiện
- thực hiện
- thực hiện
- cải thiện
- in
- bao gồm
- bao gồm
- Bao gồm
- Incoming
- chỉ
- hệ thống riêng biệt,
- thông tin
- ban đầu
- khả năng phán đoán
- Chèn
- cái nhìn sâu sắc
- ví dụ
- thay vì
- hướng dẫn
- Trung cấp
- vấn đề
- các vấn đề
- IT
- sự lặp lại
- Việc làm
- việc làm
- json
- Giữ
- Key
- phím
- Biết
- phòng thí nghiệm
- hồ
- Tiếng Latin
- Mỹ La-tinh
- lớp
- lớp
- dẫn
- LEARN
- thư viện
- LIMIT
- Dòng
- Danh sách
- tải
- tải
- tải
- địa điểm thư viện nào
- Xem
- NHÌN
- các
- Los Angeles
- Rất nhiều
- Chủ yếu
- duy trì
- làm cho
- quản lý
- quản lý
- giám đốc
- quản lý
- thủ công
- nhiều
- lập bản đồ
- đánh dấu
- Menu
- đi
- tin nhắn
- Might
- di cư
- tối thiểu
- phút
- phút
- hiện đại
- sửa đổi
- Màn Hình
- giám sát
- chi tiết
- hầu hết
- Phổ biến nhất
- nhiều
- tên
- Được đặt theo tên
- tên
- Điều hướng
- THÔNG TIN
- Cần
- cần thiết
- nhu cầu
- Mới
- tiếp theo
- Bắc
- Bắc Mỹ
- thông báo
- con số
- vật
- đối tượng
- ONE
- đang diễn ra
- OP
- hoạt động
- tối ưu hóa
- Các lựa chọn
- tổ chức
- tổ chức
- Tổ chức
- nguyên
- nếu không thì
- bên ngoài
- riêng
- chủ sở hữu
- cửa sổ
- tham số
- thông số
- một phần
- các bộ phận
- con đường
- Họa tiết
- thực hiện
- biểu diễn
- thực hiện
- thời gian
- quyền
- giai đoạn
- nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Phổ biến
- Bài đăng
- postgresql
- thực hành
- ưa thích
- điều kiện tiên quyết
- trình bày
- chính
- Vấn đề
- quá trình
- Quy trình
- xử lý
- Sản xuất
- Khóa Học
- cho
- cung cấp
- cung cấp
- Python
- Mau
- nâng cao
- Tỷ lệ
- Nguyên
- dữ liệu thô
- Đọc
- thời gian thực
- ghi
- hồ sơ
- thay thế
- nhân rộng
- nhân rộng
- yêu cầu
- cần phải
- tài nguyên
- Thông tin
- REST của
- Kết quả
- bán lẻ
- trở lại
- Trả về
- xem xét
- mạnh mẽ
- Vai trò
- Quy tắc
- quy tắc
- chạy
- chạy
- tương tự
- Lưu
- kịch bản
- lịch trình
- phạm vi
- kịch bản
- Tìm kiếm
- Thứ hai
- Ngành
- nhìn thấy
- chọn
- lựa chọn
- lựa chọn
- riêng biệt
- DỊCH VỤ
- định
- thiết lập
- thiết lập
- nên
- hiển thị
- Chương trình
- tương tự
- Đơn giản
- kể từ khi
- duy nhất
- So
- giải pháp
- Giải quyết
- một số
- tinh vi
- nguồn
- nguồn
- không gian
- Spark
- riêng
- đặc điểm kỹ thuật
- quy định
- Thể thao
- SQL
- ngăn xếp
- Stacks
- Traineeship
- các bên liên quan
- Bắt đầu
- bắt đầu
- Bắt đầu
- bắt đầu
- Bang
- số liệu thống kê
- Trạng thái
- Bước
- Các bước
- dừng lại
- là gắn
- hàng
- lưu trữ
- cửa hàng
- Chiến lược
- cấu trúc
- cấu trúc
- phòng thu
- Thành công
- như vậy
- lớn
- hỗ trợ
- hệ thống
- bàn
- Mục tiêu
- Nhiệm vụ
- nhiệm vụ
- nhóm
- đội
- viễn thông
- mẫu
- Thiết bị đầu cuối
- Sản phẩm
- Nguồn
- cung cấp their dịch
- hàng ngàn
- số ba
- Thông qua
- thời gian
- timeline
- thời gian
- dấu thời gian
- đến
- công cụ
- hàng đầu
- Tổng số:
- Theo dõi
- truyền thống
- giao dịch
- Chuyển đổi
- Chuyển đổi
- kích hoạt
- hướng dẫn
- loại
- Dưới
- hiểu
- độc đáo
- Cập nhật
- Cập nhật
- sử dụng
- ca sử dụng
- người sử dang
- Người sử dụng
- thường
- giá trị
- xác minh
- Xem
- hình dung
- khối lượng
- chờ đợi
- Kho
- web
- các dịch vụ web
- cái nào
- sẽ
- ở trong
- không có
- công trinh
- viết
- viết
- khoai mỡ
- năm
- năm
- trên màn hình
- zephyrnet