Amazon SageMaker Tự động lái giúp bạn hoàn thành quy trình công việc học máy (ML) end-to-end bằng cách tự động hóa các bước của kỹ thuật tính năng, đào tạo, điều chỉnh và triển khai mô hình ML để suy luận. Bạn cung cấp cho SageMaker Autopilot một tập dữ liệu dạng bảng và một thuộc tính mục tiêu để dự đoán. Sau đó, SageMaker Autopilot tự động khám phá dữ liệu của bạn, đào tạo, điều chỉnh, xếp hạng và tìm ra mô hình tốt nhất. Cuối cùng, bạn có thể triển khai mô hình này vào sản xuất để suy luận bằng một cú nhấp chuột.
Gì mới?
Tính năng mới ra mắt, Báo cáo chất lượng mô hình lái tự động của SageMaker, bây giờ báo cáo các chỉ số của mô hình của bạn để cung cấp khả năng hiển thị tốt hơn về hiệu suất của mô hình đối với các vấn đề hồi quy và phân loại. Bạn có thể tận dụng các chỉ số này để thu thập thêm thông tin chi tiết về mô hình tốt nhất trong bảng xếp hạng Mô hình.
Các chỉ số và báo cáo này có sẵn trong tab "Hiệu suất" mới trong "Chi tiết mô hình" của mô hình tốt nhất bao gồm ma trận nhầm lẫn, một khu vực dưới đường cong đặc tính hoạt động của máy thu (AUC-ROC) và một khu vực dưới đường cong nhớ lại độ chính xác (AUC-PR). Các chỉ số này giúp bạn hiểu rõ dương tính giả / âm tính giả (FP / FN), sự cân bằng giữa dương tính thực (TP) và dương tính giả (FP), cũng như sự cân bằng giữa độ chính xác và thu hồi để đánh giá các đặc điểm hiệu suất tốt nhất của mô hình.
Chạy thử nghiệm Lái xe tự động của SageMaker
Tập dữ liệu
Chúng tôi sử dụng Bộ dữ liệu tiếp thị ngân hàng của UCI để chứng minh Báo cáo chất lượng mô hình lái tự động của SageMaker. Dữ liệu này chứa các thuộc tính của khách hàng, chẳng hạn như tuổi, loại công việc, tình trạng hôn nhân và các thuộc tính khác mà chúng tôi sẽ sử dụng để dự đoán liệu khách hàng có mở tài khoản với ngân hàng hay không. Tập dữ liệu đề cập đến tài khoản này như một khoản tiền gửi có kỳ hạn. Điều này làm cho trường hợp của chúng tôi trở thành một vấn đề phân loại nhị phân - dự đoán sẽ là “có” hoặc “không”. SageMaker Autopilot sẽ thay mặt chúng tôi tạo ra một số mô hình để dự đoán chính xác nhất về khách hàng tiềm năng. Sau đó, chúng tôi sẽ kiểm tra Báo cáo chất lượng mô hình cho Máy lái tự động của SageMaker Mô hình tốt nhất.
Điều kiện tiên quyết
Để bắt đầu thử nghiệm Tự động lái của SageMaker, trước tiên bạn phải đặt dữ liệu của mình vào Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3). Chỉ định nhóm và tiền tố mà bạn muốn sử dụng để đào tạo. Đảm bảo rằng nhóm nằm trong cùng Khu vực với thử nghiệm Lái xe tự động của SageMaker. Bạn cũng phải đảm bảo rằng chức năng Autopilot với vai trò Quản lý danh tính và truy cập (IAM) có quyền truy cập vào dữ liệu trong Amazon S3.
Tạo thử nghiệm
Bạn có một số tùy chọn để tạo thử nghiệm SageMaker Autopilot trong SageMaker Studio. Bằng cách mở một launcher mới, bạn có thể truy cập trực tiếp vào SageMaker Autopilot. Nếu không, bạn có thể chọn biểu tượng tài nguyên SageMaker ở phía bên trái. Tiếp theo, bạn có thể chọn Thử nghiệm và thử nghiệm từ trình đơn thả xuống.
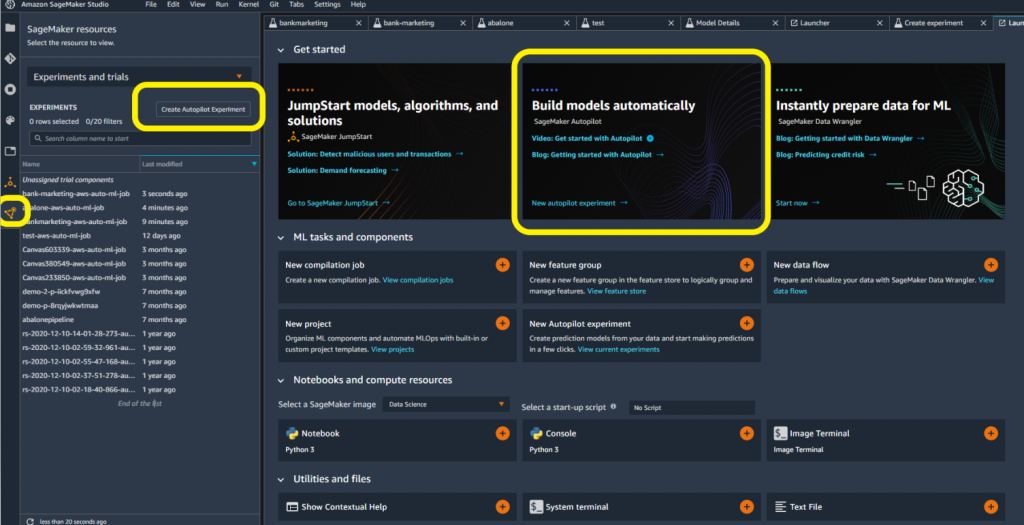
- Đặt tên cho thử nghiệm của bạn.
- Kết nối với nguồn dữ liệu của bạn bằng cách chọn nhóm Amazon S3 và tên tệp.
- Chọn vị trí dữ liệu đầu ra trong Amazon S3.
- Chọn cột mục tiêu cho tập dữ liệu của bạn. Trong trường hợp này, chúng tôi đang nhắm mục tiêu cột "y" để biểu thị có / không.
- Theo tùy chọn, cung cấp tên điểm cuối nếu bạn muốn SageMaker Autopilot tự động triển khai điểm cuối mô hình.
- Để tất cả các cài đặt nâng cao khác làm mặc định và chọn Tạo thử nghiệm.

Sau khi thử nghiệm hoàn tất, bạn có thể xem kết quả trong SageMaker Studio. SageMaker Autopilot sẽ trình bày mô hình tốt nhất trong số các mô hình khác nhau mà nó đào tạo. Bạn có thể xem chi tiết và kết quả cho các thử nghiệm khác nhau, nhưng chúng tôi sẽ sử dụng mô hình tốt nhất để chứng minh việc sử dụng Báo cáo chất lượng mô hình.
- Chọn kiểu máy và nhấp chuột phải vào Mở chi tiết mô hình.
- Trong chi tiết mô hình, hãy chọn HIỆU QUẢ chuyển hướng. Phần này hiển thị các số liệu của mô hình thông qua hình ảnh hóa và biểu đồ.
- Theo HIỆU QUẢ, lựa chọn Tải xuống Báo cáo Hiệu suất dưới dạng PDF.


Diễn giải Báo cáo chất lượng của mô hình lái tự động SageMaker
Báo cáo Chất lượng Mô hình tóm tắt công việc Lái xe tự động SageMaker và chi tiết mô hình. Chúng tôi sẽ tập trung vào định dạng PDF của báo cáo, nhưng bạn cũng có thể truy cập kết quả dưới dạng JSON. Bởi vì SageMaker Autopilot xác định tập dữ liệu của chúng tôi là một vấn đề phân loại nhị phân, SageMaker Autopilot nhằm mục đích tối đa hóa Chỉ số chất lượng F1 để tìm ra mô hình tốt nhất. SageMaker Autopilot chọn tùy chọn này theo mặc định. Tuy nhiên, có sự linh hoạt để chọn các số liệu khách quan khác, chẳng hạn như độ chính xác và AUC. Điểm F1 của mô hình của chúng tôi là 0.61. Để diễn giải điểm F1, trước tiên cần hiểu ma trận nhầm lẫn, được giải thích bằng Báo cáo chất lượng mô hình trong tệp PDF xuất ra.
Ma trận hỗn loạn
Ma trận nhầm lẫn giúp hình dung hiệu suất của mô hình bằng cách so sánh các lớp và nhãn khác nhau. Thử nghiệm Tự động lái của SageMaker đã tạo ra một ma trận nhầm lẫn hiển thị các nhãn thực tế dưới dạng hàng và các nhãn dự đoán dưới dạng cột trong Báo cáo Chất lượng Mô hình. Hộp phía trên bên trái hiển thị những khách hàng không mở tài khoản với ngân hàng đã được mô hình dự đoán chính xác là 'không'. đó là phủ định thực sự (TN). Hộp phía dưới bên phải hiển thị những khách hàng đã mở tài khoản với ngân hàng đã được mô hình dự đoán chính xác là 'có'. đó là mặt tích cực thực sự (PT).

Góc dưới bên trái hiển thị số lượng phủ định sai (FN). Mô hình dự đoán rằng khách hàng sẽ không mở tài khoản, nhưng khách hàng đã làm. Góc trên bên phải hiển thị số dương tính giả (FP). Mô hình dự đoán rằng khách hàng sẽ mở tài khoản, nhưng khách hàng đã không thực sự làm như vậy.
Số liệu Báo cáo Chất lượng Mô hình
Báo cáo Chất lượng Mô hình giải thích cách tính toán tỷ lệ dương tính giả (FPR) và tỷ lệ dương tính thực (TPR).
Tỷ lệ dương tính thu hồi hoặc sai (FPR) đo lường tỷ lệ số lần phủ định thực tế được dự đoán sai khi mở tài khoản (số lần tích cực). Phạm vi từ 0 đến 1 và giá trị nhỏ hơn cho biết độ chính xác của dự đoán tốt hơn.

Lưu ý rằng FPR cũng được biểu thị dưới dạng 1-Độ cụ thể, trong đó Độ cụ thể hoặc Tỷ lệ phủ định thực (TNR) là tỷ lệ TN được xác định chính xác là không mở tài khoản (phủ định).

Nhớ lại / Độ nhạy / Tỷ lệ dương tính thực (TPR) đo lường phần tích cực thực tế được dự đoán khi mở tài khoản. Phạm vi cũng từ 0 đến 1 và giá trị lớn hơn cho biết độ chính xác của dự đoán tốt hơn. Điều này còn được gọi là Nhớ lại / Độ nhạy. Phép đo này thể hiện khả năng tìm thấy tất cả các trường hợp có liên quan trong một tập dữ liệu.
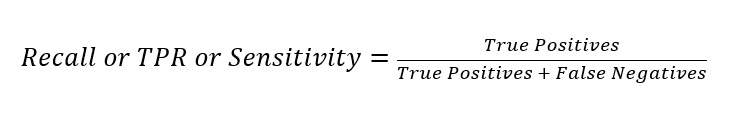
Độ chính xác đo lường phần tích cực thực tế được dự đoán là tích cực trong số tất cả những người được dự đoán là tích cực. Phạm vi từ 0 đến 1 và giá trị lớn hơn cho biết độ chính xác tốt hơn. Độ chính xác thể hiện tỷ lệ các điểm dữ liệu mà mô hình của chúng tôi cho là có liên quan và thực sự có liên quan. Độ chính xác là một biện pháp tốt để xem xét, đặc biệt là khi chi phí FP cao - ví dụ như với tính năng phát hiện thư rác email.

Mô hình của chúng tôi cho thấy độ chính xác là 0.53 và độ thu hồi là 0.72.
Điểm F1 thể hiện chỉ số mục tiêu của chúng tôi, là trung bình hài hòa của độ chính xác và thu hồi. Vì tập dữ liệu của chúng tôi không cân bằng theo hướng có nhiều dự đoán 'không', F1 tính đến cả FP và FN để đưa ra cùng một trọng số cho độ chính xác và thu hồi.
Báo cáo giải thích cách diễn giải các chỉ số này. Điều này có thể hữu ích nếu bạn không quen với các thuật ngữ này. Trong ví dụ của chúng tôi, độ chính xác và thu hồi là các số liệu quan trọng đối với bài toán phân loại nhị phân, vì chúng được sử dụng để tính điểm F1. Báo cáo giải thích rằng điểm F1 có thể thay đổi từ 0 đến 1. Thành tích tốt nhất có thể sẽ đạt 1, trong khi 0 sẽ cho thấy điểm kém nhất. Hãy nhớ rằng điểm F1 của mô hình của chúng tôi là 0.61.

Điểm Fβ là giá trị trung bình hài có trọng số của độ chính xác và độ thu hồi. Hơn nữa, điểm F1 giống Fβ với β = 1. Báo cáo cung cấp Điểm Fβ của bộ phân loại, trong đó β lấy 0.5, 1 và 2.

Bảng chỉ số
Tùy thuộc vào vấn đề, bạn có thể thấy rằng SageMaker Autopilot tối đa hóa một số liệu khác, chẳng hạn như độ chính xác, cho một vấn đề phân loại nhiều lớp. Bất kể loại sự cố nào, Báo cáo chất lượng mô hình tạo ra một bảng tóm tắt các chỉ số của mô hình của bạn có sẵn cả nội tuyến và trong báo cáo PDF. Bạn có thể tìm hiểu thêm về bảng chỉ số trong tài liệu hướng dẫn.

Bộ phân loại hằng số tốt nhất - bộ phân loại đóng vai trò là đường cơ sở đơn giản để so sánh với các bộ phân loại phức tạp hơn - luôn dự đoán nhãn đa số không đổi do người dùng cung cấp. Trong trường hợp của chúng tôi, một mô hình 'hằng số' sẽ dự đoán 'không', vì đó là lớp thường xuyên nhất và được coi là một nhãn phủ định. Các số liệu cho các mô hình bộ phân loại được đào tạo (chẳng hạn như f1, f2 hoặc gọi lại) có thể được so sánh với các số liệu cho bộ phân loại không đổi, tức là đường cơ sở. Điều này đảm bảo rằng mô hình được đào tạo hoạt động tốt hơn bộ phân loại hằng số. Điểm Fβ (f0_5, f1 và f2, trong đó β nhận các giá trị tương ứng là 0.5, 1 và 2) là giá trị trung bình hài có trọng số của độ chính xác và độ thu hồi. Giá trị này đạt đến giá trị tối ưu là 1 và giá trị xấu nhất của nó là 0.
Trong trường hợp của chúng tôi, bộ phân loại hằng số tốt nhất luôn dự đoán là 'không'. Do đó, độ chính xác cao ở mức 0.89, nhưng điểm số thu hồi, độ chính xác và Fβ là 0. Nếu tập dữ liệu được cân bằng hoàn hảo trong đó không có đa số hoặc nhóm thiểu số, chúng ta sẽ thấy nhiều khả năng thú vị hơn đối với độ chính xác, thu hồi, và điểm Fβ của bộ phân loại hằng số.
Hơn nữa, bạn có thể xem các kết quả này ở định dạng JSON như trong ví dụ sau. Bạn có thể truy cập cả tệp PDF và JSON thông qua giao diện người dùng, cũng như SDK Python SageMaker của Amazon sử dụng phần tử S3OutputPath trong Cấu hình dữ liệu đầu ra cấu trúc trong TạoAutoMLJob/Mô tảAutoMLJob Phản hồi API.
{ "version" : 0.0, "dataset" : { "item_count" : 9152, "evaluation_time" : "2022-03-16T20:49:18.661Z" }, "binary_classification_metrics" : { "confusion_matrix" : { "no" : { "no" : 7468, "yes" : 648 }, "yes" : { "no" : 295, "yes" : 741 } }, "recall" : { "value" : 0.7152509652509652, "standard_deviation" : 0.00439996600081394 }, "precision" : { "value" : 0.5334773218142549, "standard_deviation" : 0.007335840278445563 }, "accuracy" : { "value" : 0.8969624125874126, "standard_deviation" : 0.0011703516093899595 }, "recall_best_constant_classifier" : { "value" : 0.0, "standard_deviation" : 0.0 }, "precision_best_constant_classifier" : { "value" : 0.0, "standard_deviation" : 0.0 }, "accuracy_best_constant_classifier" : { "value" : 0.8868006993006993, "standard_deviation" : 0.0016707401772078998 }, "true_positive_rate" : { "value" : 0.7152509652509652, "standard_deviation" : 0.00439996600081394 }, "true_negative_rate" : { "value" : 0.9201577131591917, "standard_deviation" : 0.0010233756436643213 }, "false_positive_rate" : { "value" : 0.07984228684080828, "standard_deviation" : 0.0010233756436643403 }, "false_negative_rate" : { "value" : 0.2847490347490348, "standard_deviation" : 0.004399966000813983 },
………………….
ROC và AUC
Tùy thuộc vào loại sự cố, bạn có thể có các ngưỡng khác nhau cho những gì có thể chấp nhận được dưới dạng FPR. Ví dụ: nếu bạn đang cố gắng dự đoán liệu khách hàng có mở tài khoản hay không, thì doanh nghiệp có thể chấp nhận được tỷ lệ FP cao hơn. Có thể rủi ro hơn nếu bỏ lỡ việc mở rộng ưu đãi cho những khách hàng được dự đoán không chính xác là "không", trái ngược với việc đưa ra những khách hàng được dự đoán sai là "có". Việc thay đổi các ngưỡng này để tạo ra các FPR khác nhau đòi hỏi bạn phải tạo ma trận nhầm lẫn mới.
Các thuật toán phân loại trả về các giá trị liên tục được gọi là xác suất dự đoán. Các xác suất này phải được chuyển đổi thành một giá trị nhị phân (để phân loại nhị phân). Trong các bài toán phân loại nhị phân, ngưỡng (hoặc ngưỡng quyết định) là một giá trị phân đôi xác suất thành một quyết định nhị phân đơn giản. Đối với xác suất dự kiến chuẩn hóa trong phạm vi từ 0 đến 1, ngưỡng được đặt thành 0.5 theo mặc định.
Đối với các mô hình phân loại nhị phân, số liệu đánh giá hữu ích là diện tích bên dưới đường cong Đặc tính Hoạt động của Máy thu (ROC). Báo cáo Chất lượng Mô hình bao gồm biểu đồ ROC với tỷ lệ TP là trục y và FPR là trục x. Vùng dưới đặc tính hoạt động của máy thu (AUC-ROC) thể hiện sự cân bằng giữa TPR và FPR.
Bạn tạo đường cong ROC bằng cách sử dụng công cụ dự đoán phân loại nhị phân, sử dụng giá trị ngưỡng và gán nhãn với xác suất dự đoán. Khi bạn thay đổi ngưỡng cho một mô hình, bạn sẽ bao gồm hai thái cực. Khi TPR và FPR đều bằng 0, điều đó có nghĩa là mọi thứ đều được gắn nhãn “không” và khi cả TPR và FPR đều bằng 1, nó ngụ ý rằng mọi thứ đều được gắn nhãn “có”.
Một dự đoán ngẫu nhiên gắn nhãn “Có” trong nửa thời gian và “Không” trong nửa thời gian còn lại sẽ có ROC là một đường chéo thẳng (đường chấm đỏ). Đường thẳng này cắt hình vuông đơn vị thành hai hình tam giác có kích thước bằng nhau. Do đó, diện tích dưới đường cong là 0.5. Giá trị AUC-ROC là 0.5 có nghĩa là người dự đoán của bạn không thể phân biệt giữa hai loại tốt hơn so với việc đoán ngẫu nhiên liệu khách hàng có mở tài khoản hay không. Giá trị AUC-ROC càng gần với 1.0, thì các dự đoán của nó càng tốt. Giá trị dưới 0.5 cho thấy rằng chúng tôi thực sự có thể làm cho mô hình của mình tạo ra các dự đoán tốt hơn bằng cách đảo ngược câu trả lời mà nó cung cấp cho chúng tôi. Đối với mô hình tốt nhất của chúng tôi, AUC là 0.93.

Đường cong thu hồi chính xác
Báo cáo chất lượng mô hình cũng tạo ra một Đường cong thu hồi độ chính xác (PR) để vẽ biểu đồ độ chính xác (trục y) và thu hồi (trục x) cho các ngưỡng khác nhau - giống như đường cong ROC. Đường cong PR, thường được sử dụng trong Truy xuất thông tin, là một giải pháp thay thế cho đường cong ROC cho các bài toán phân loại có độ lệch lớn trong phân phối lớp.
Đối với các tập dữ liệu không cân bằng về lớp này, Đường cong PR đặc biệt trở nên hữu ích khi lớp tích cực thiểu số thú vị hơn lớp phủ định đa số. Hãy nhớ rằng mô hình của chúng tôi cho thấy độ chính xác là 0.53 và độ thu hồi là 0.72. Hơn nữa, hãy nhớ rằng trình phân loại hằng số tốt nhất không thể phân biệt giữa 'có' và 'không'. Nó sẽ dự đoán một lớp ngẫu nhiên hoặc một lớp không đổi mọi lúc.
Đường cong cho tập dữ liệu cân bằng giữa 'có' và 'không' sẽ là một đường nằm ngang ở mức 0.5 và do đó sẽ có diện tích bên dưới đường cong PR (AUPRC) là 0.5. Để tạo PRC, chúng tôi vẽ các mô hình khác nhau trên đường cong ở các ngưỡng khác nhau, theo cách giống như đường cong ROC. Đối với dữ liệu của chúng tôi, AUPRC là 0.61.

Đầu ra Báo cáo Chất lượng Mô hình
Bạn có thể tìm thấy Báo cáo chất lượng mô hình trong nhóm Amazon S3 mà bạn đã chỉ định khi chỉ định đường dẫn đầu ra trước khi chạy thử nghiệm SageMaker AutoPilot. Bạn sẽ tìm thấy các báo cáo trong documentation/model_monitor/output/<autopilot model name>/ prefix được lưu dưới dạng PDF.
Kết luận
Báo cáo chất lượng mô hình lái tự động của SageMaker giúp bạn dễ dàng xem và chia sẻ nhanh kết quả của thử nghiệm lái tự động của SageMaker. Bạn có thể dễ dàng hoàn thành việc đào tạo và điều chỉnh mô hình bằng cách sử dụng SageMaker Autopilot, sau đó tham khảo các báo cáo đã tạo để diễn giải kết quả. Cho dù bạn kết thúc bằng cách sử dụng mô hình tốt nhất của SageMaker Autopilot hay một ứng cử viên khác, những kết quả này có thể là điểm khởi đầu hữu ích để đánh giá công việc đào tạo và điều chỉnh mô hình sơ bộ. Báo cáo chất lượng mô hình lái tự động của SageMaker giúp giảm thời gian cần thiết để viết mã và tạo ra các hình ảnh trực quan để đánh giá và so sánh hiệu suất.
Bạn có thể dễ dàng kết hợp autoML vào các trường hợp kinh doanh của mình ngay hôm nay mà không cần phải xây dựng một nhóm khoa học dữ liệu. SageMaker tài liệu hướng dẫn cung cấp nhiều mẫu để giúp bạn bắt đầu.
Về các tác giả
 Peter Chung là Kiến trúc sư giải pháp cho AWS và rất đam mê giúp khách hàng khám phá thông tin chi tiết từ dữ liệu của họ. Ông đã và đang xây dựng các giải pháp để giúp các tổ chức đưa ra quyết định dựa trên dữ liệu ở cả khu vực công và tư nhân. Anh ấy có tất cả các chứng chỉ AWS cũng như hai chứng chỉ GCP. Anh ấy thích cà phê, nấu ăn, năng động và dành thời gian cho gia đình.
Peter Chung là Kiến trúc sư giải pháp cho AWS và rất đam mê giúp khách hàng khám phá thông tin chi tiết từ dữ liệu của họ. Ông đã và đang xây dựng các giải pháp để giúp các tổ chức đưa ra quyết định dựa trên dữ liệu ở cả khu vực công và tư nhân. Anh ấy có tất cả các chứng chỉ AWS cũng như hai chứng chỉ GCP. Anh ấy thích cà phê, nấu ăn, năng động và dành thời gian cho gia đình.
 Arunprasath Shankar là Kiến trúc sư chuyên về giải pháp trí tuệ nhân tạo và máy học (AI / ML) của AWS, giúp khách hàng toàn cầu mở rộng quy mô các giải pháp AI của họ một cách hiệu quả và hiệu quả trên đám mây. Khi rảnh rỗi, Arun thích xem phim khoa học viễn tưởng và nghe nhạc cổ điển.
Arunprasath Shankar là Kiến trúc sư chuyên về giải pháp trí tuệ nhân tạo và máy học (AI / ML) của AWS, giúp khách hàng toàn cầu mở rộng quy mô các giải pháp AI của họ một cách hiệu quả và hiệu quả trên đám mây. Khi rảnh rỗi, Arun thích xem phim khoa học viễn tưởng và nghe nhạc cổ điển.
 Ali Takbiri là một Kiến trúc sư giải pháp chuyên gia về AI / ML và giúp khách hàng bằng cách sử dụng Học máy để giải quyết các thách thức kinh doanh của họ trên Đám mây AWS.
Ali Takbiri là một Kiến trúc sư giải pháp chuyên gia về AI / ML và giúp khách hàng bằng cách sử dụng Học máy để giải quyết các thách thức kinh doanh của họ trên Đám mây AWS.
 Pradeep Reddy là Giám đốc Sản phẩm Cấp cao trong nhóm SageMaker Low / No Code ML, bao gồm SageMaker Autopilot, SageMaker Automatic Model Tuner. Ngoài giờ làm việc, Pradeep thích đọc sách, chạy và tìm hiểu với các máy tính có kích thước bằng lòng bàn tay như raspberry pi và các công nghệ tự động hóa gia đình khác.
Pradeep Reddy là Giám đốc Sản phẩm Cấp cao trong nhóm SageMaker Low / No Code ML, bao gồm SageMaker Autopilot, SageMaker Automatic Model Tuner. Ngoài giờ làm việc, Pradeep thích đọc sách, chạy và tìm hiểu với các máy tính có kích thước bằng lòng bàn tay như raspberry pi và các công nghệ tự động hóa gia đình khác.
- Coinsmart. Sàn giao dịch Bitcoin và tiền điện tử tốt nhất Châu Âu.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. TRUY CẬP MIỄN PHÍ.
- CryptoHawk. Radar Altcoin. Dùng thử miễn phí.
- Nguồn: https://aws.amazon.com/blogs/machine-learning/automatically-generate-model-evaluation-metrics-using-sagemaker-autopilot-model-quality-reports/
- "
- 100
- 7
- Giới thiệu
- truy cập
- Tài khoản
- hoạt động
- tiên tiến
- AI
- thuật toán
- Tất cả
- đàn bà gan dạ
- trong số
- Một
- api
- KHU VỰC
- nhân tạo
- trí tuệ nhân tạo
- Trí tuệ nhân tạo và học máy
- thuộc tính
- Tự động hóa
- có sẵn
- AWS
- Ngân hàng
- Baseline
- trở nên
- BEST
- biên giới
- Hộp
- xây dựng
- Xây dựng
- kinh doanh
- trường hợp
- thách thức
- Chọn
- tốt nghiệp lớp XNUMX
- các lớp học
- phân loại
- gần gũi hơn
- đám mây
- mã
- Cà Phê
- Cột
- so
- phức tạp
- máy tính
- nhầm lẫn
- chứa
- Chi phí
- có thể
- tạo ra
- Tạo
- đường cong
- khách hàng
- dữ liệu
- khoa học dữ liệu
- tập dữ liệu
- chứng minh
- triển khai
- triển khai
- Phát hiện
- ĐÃ LÀM
- khác nhau
- trực tiếp
- phân phối
- dễ dàng
- Điểm cuối
- Kỹ Sư
- đặc biệt
- tất cả mọi thứ
- ví dụ
- thử nghiệm
- gia đình
- Đặc tính
- Cuối cùng
- tìm thấy
- Tên
- Linh hoạt
- Tập trung
- tiếp theo
- định dạng
- tạo ra
- Toàn cầu
- tốt
- có
- giúp đỡ
- hữu ích
- giúp
- Cao
- cao hơn
- giữ
- Trang Chủ
- Trang chủ Tự động hóa
- Độ đáng tin của
- Hướng dẫn
- HTTPS
- ICON
- Bản sắc
- quan trọng
- bao gồm
- thông tin
- những hiểu biết
- Sự thông minh
- IT
- Việc làm
- nổi tiếng
- Nhãn
- lớn
- lớn hơn
- LEARN
- học tập
- Tỉ lệ đòn bẩy
- Dòng
- Listening
- địa điểm thư viện nào
- máy
- học máy
- Đa số
- LÀM CHO
- quản lý
- giám đốc
- Marketing
- Matrix
- đo
- Metrics
- dân tộc thiểu số
- ML
- kiểu mẫu
- mô hình
- chi tiết
- hầu hết
- Phim Điện Ảnh
- Âm nhạc
- con số
- nhiều
- cung cấp
- Cung cấp
- mở
- mở
- hoạt động
- Các lựa chọn
- tổ chức
- Nền tảng khác
- đam mê
- hiệu suất
- Điểm
- tích cực
- khả năng
- có thể
- tiềm năng
- dự đoán
- dự đoán
- Dự đoán
- trình bày
- riêng
- Vấn đề
- vấn đề
- sản xuất
- Sản phẩm
- Sản lượng
- cho
- cung cấp
- công khai
- chất lượng
- Mau
- phạm vi
- Reading
- giảm
- có liên quan
- báo cáo
- Báo cáo
- đại diện cho
- Thông tin
- phản ứng
- Kết quả
- chạy
- Quy mô
- Khoa học
- Ngành
- định
- Chia sẻ
- Đơn giản
- So
- Giải pháp
- động SOLVE
- thư rác
- Chi
- vuông
- bắt đầu
- Trạng thái
- là gắn
- phòng thu
- Mục tiêu
- nhóm
- công nghệ cao
- Thông qua
- thời gian
- bây giờ
- TPR
- Hội thảo
- tàu hỏa
- ui
- khám phá
- hiểu
- us
- sử dụng
- giá trị
- khác nhau
- Xem
- khả năng hiển thị
- liệu
- CHÚNG TÔI LÀ
- không có
- Công việc
- sẽ