Mọi doanh nghiệp đều cần có khả năng dự đoán tương lai một cách chính xác để đưa ra quyết định tốt hơn và mang lại cho công ty lợi thế cạnh tranh. Với dữ liệu lịch sử, doanh nghiệp có thể hiểu xu hướng, đưa ra dự đoán về điều gì có thể xảy ra và thời điểm xảy ra, đồng thời kết hợp thông tin đó vào kế hoạch tương lai của họ, từ nhu cầu sản phẩm đến lập kế hoạch tồn kho và nhân sự. Nếu dự báo quá cao, các công ty có thể đầu tư quá mức vào sản phẩm và nhân viên, dẫn đến lãng phí đầu tư. Nếu dự báo quá thấp, các công ty có thể đầu tư dưới mức, dẫn đến thiếu hụt nguyên liệu thô và hàng tồn kho, tạo ra trải nghiệm kém cho khách hàng.
Dự báo chuỗi thời gian là một kỹ thuật dự đoán dữ liệu chuỗi thời gian trong tương lai dựa trên dữ liệu lịch sử. Dự báo chuỗi thời gian rất hữu ích trong nhiều lĩnh vực, bao gồm bán lẻ, tài chính, hậu cần và chăm sóc sức khỏe. Dự báo nhu cầu sử dụng dữ liệu chuỗi thời gian lịch sử để đưa ra ước tính trong tương lai liên quan đến nhu cầu của khách hàng trong một khoảng thời gian cụ thể và hợp lý hóa quá trình ra quyết định cung-cầu giữa các doanh nghiệp. Các trường hợp sử dụng dự báo nhu cầu bao gồm dự đoán doanh số bán vé trong ngành vận tải, giá cổ phiếu, số lượt đến bệnh viện, số lượng đại diện khách hàng cần thuê cho nhiều địa điểm trong tháng tới, doanh số bán sản phẩm trên nhiều khu vực trong quý tiếp theo, mức sử dụng máy chủ đám mây cho ngày hôm sau đối với dịch vụ truyền phát video, mức tiêu thụ điện cho nhiều khu vực trong tuần tới, số lượng thiết bị và cảm biến IoT như mức tiêu thụ năng lượng, v.v.
Dữ liệu chuỗi thời gian được phân loại là đơn biến và đa biến. Ví dụ, tổng mức tiêu thụ điện của một hộ gia đình là một chuỗi thời gian đơn biến trong một khoảng thời gian. Khi nhiều chuỗi thời gian đơn biến được xếp chồng lên nhau, nó được gọi là chuỗi thời gian nhiều biến. Ví dụ: tổng mức tiêu thụ điện của 10 hộ gia đình khác nhau (nhưng có mối tương quan) trong một khu phố tạo thành một tập dữ liệu chuỗi thời gian đa biến.
Các phương pháp truyền thống để dự báo chuỗi thời gian bao gồm trung bình di chuyển tích hợp hồi quy tự động (ARIMA) cho dữ liệu chuỗi thời gian đơn biến và tự hồi quy vector (VAR) cho dữ liệu chuỗi thời gian đa biến. Những phương pháp này thường yêu cầu quá trình tiền xử lý dữ liệu tẻ nhạt và tạo ra các tính năng trước khi đào tạo mô hình. Những thách thức này được giải quyết bằng phương pháp học sâu (DL) bằng cách tự động hóa bước tạo tính năng trước khi đào tạo mô hình, chẳng hạn như kết hợp các chuẩn hóa dữ liệu khác nhau, độ trễ, thang thời gian khác nhau, một số dữ liệu phân loại, xử lý các giá trị bị thiếu, v.v., với khả năng dự đoán tốt hơn đào tạo và triển khai hỗ trợ GPU nhanh chóng và mạnh mẽ.
Trong bài đăng này, chúng tôi chỉ cho bạn cách triển khai giải pháp dự báo nhu cầu bằng cách sử dụng Khởi động Amazon SageMaker. Chúng tôi sẽ hướng dẫn bạn giải pháp toàn diện cho nhiệm vụ dự báo nhu cầu bằng cách sử dụng ba thuật toán chuỗi thời gian hiện đại: LSTNet, Tiên trivà SageMaker DeepAR, có sẵn trong GluonTS và Amazon SageMaker. Dữ liệu đầu vào là chuỗi thời gian đa biến bao gồm hàng giờ Tiêu thụ điện trong số 321 người dùng từ năm 2012–2014. Tiếp theo, mỗi thuật toán lấy dữ liệu chuỗi thời gian tương quan và đa biến trong lịch sử để huấn luyện và tạo ra các dự đoán chính xác (giá trị đa biến) trong một khoảng thời gian dự đoán. Đối với mỗi thuật toán chuỗi thời gian, chúng ta có hai kết quả đầu ra: một mô hình được huấn luyện theo giờ dữ liệu tiêu thụ điện và điểm cuối SageMaker có thể dự đoán các giá trị trong tương lai (đa biến) trong một khoảng dự đoán.
Ngoài ra, nếu bạn đang tìm kiếm một dịch vụ được quản lý hoàn toàn để cung cấp các dự báo có độ chính xác cao mà không cần viết mã, chúng tôi khuyên bạn nên kiểm tra Dự báo Amazon. Dự báo của Amazon là dịch vụ dự báo chuỗi thời gian dựa trên máy học (ML) và được xây dựng để phân tích số liệu kinh doanh. Dựa trên cùng một công nghệ được sử dụng tại Amazon.com, Amazon Dự báo sử dụng công nghệ máy học để kết hợp dữ liệu chuỗi thời gian với các biến số bổ sung nhằm xây dựng dự báo.
Tổng quan về giải pháp
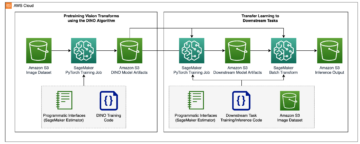
Sơ đồ sau đây thể hiện kiến trúc của quá trình đào tạo và triển khai từ đầu đến cuối.

Quy trình giải pháp như sau:
- Dữ liệu đầu vào cho quá trình huấn luyện được đặt trong một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) xô.
- Cung cấp Sổ ghi chép SageMaker lấy dữ liệu đầu vào và khởi chạy các bước sau.
- Đối với mỗi LSTNet, Tiên trivà SageMaker DeepAR thuật toán, huấn luyện mô hình và đánh giá kết quả bằng SageMaker.
- Triển khai mô hình đã đào tạo và tạo điểm cuối SageMaker, đây là điểm cuối Điểm cuối HTTPS có khả năng đưa ra dự đoán.
- Giám sát việc đào tạo và triển khai mô hình thông qua amazoncloudwatch.
- Dữ liệu đầu vào để suy luận được đặt trong nhóm S3. Từ sổ ghi chép SageMaker, gửi yêu cầu đến điểm cuối SageMaker và đưa ra dự đoán.
Điều kiện tiên quyết
Để thử giải pháp trong tài khoản của riêng bạn, hãy đảm bảo rằng bạn có sẵn những thứ sau:
- Một tài khoản AWS để sử dụng giải pháp này. Nếu bạn chưa có tài khoản, bạn có thể đăng ký một.
- Giải pháp được nêu trong bài viết này là một phần của Khởi động Amazon SageMaker. Để chạy Giải pháp JumpStart 1P này và triển khai cơ sở hạ tầng vào tài khoản AWS của bạn, bạn cần tạo một tài khoản đang hoạt động. Xưởng sản xuất Amazon SageMaker ví dụ (xem Tích hợp vào Miền Amazon SageMaker).
Khi phiên bản Studio đã sẵn sàng, bạn có thể khởi chạy Studio và truy cập JumpStart. Các tính năng JumpStart không có sẵn trong phiên bản sổ ghi chép SageMaker và bạn không thể truy cập chúng thông qua API SageMaker hoặc Giao diện dòng lệnh AWS (AWS CLI).
Khởi chạy giải pháp
Để khởi chạy giải pháp, hãy hoàn thành các bước sau:
- Mở JumpStart bằng cách sử dụng trình khởi chạy JumpStart trong Bắt Đầu hoặc bằng cách chọn biểu tượng Khởi động ở thanh bên trái.
- Trong tạp chí Giải pháp phần, chọn Dự báo nhu cầu để mở giải pháp trong một tab Studio khác.

- Trên tab Dự báo nhu cầu, chọn Khởi chạy để triển khai tài nguyên giải pháp.

- Một tab khác mở ra hiển thị trạng thái triển khai và các tạo phẩm được tạo. Khi quá trình triển khai kết thúc, nút Mở Notebook sẽ xuất hiện. Chọn Mở Notebook để mở sổ tay giải pháp trong Studio.

Trong các phần sau, chúng tôi sẽ hướng dẫn bạn các bước của giải pháp dự báo nhu cầu chuyên sâu.
Chuẩn bị và trực quan hóa dữ liệu
Tập dữ liệu chúng tôi sử dụng ở đây là chuỗi thời gian đa biến tiêu thụ điện dữ liệu lấy từ Dua, D. và Graff, C. (2019). Kho lưu trữ máy học UCI, Irvine, CA: Đại học California, Trường Khoa học Thông tin và Máy tính. Chúng tôi sử dụng phiên bản dữ liệu đã được làm sạch chứa 321 chuỗi thời gian với tần suất 1 giờ, bắt đầu từ ngày 1 tháng 2012 năm 26,304 với XNUMX bước thời gian. Chúng tôi cũng đã cung cấp tỷ giá hối đoái tập dữ liệu trong trường hợp bạn muốn thử với các tập dữ liệu khác.
Chúng tôi đã cung cấp các tiện ích để tạo khung dữ liệu từ dữ liệu đào tạo và thử nghiệm. Dữ liệu đào tạo bao gồm các giá trị tiêu thụ điện hàng giờ (đối với 321 hộ gia đình) từ 2012-01-01 00:00:00 đến 2014-05-26 19:00:00 và dữ liệu thử nghiệm chứa các giá trị từ 2012-01-01 00 :00:00 đến 2014-06-02 19:00:00 (thêm 7 ngày dữ liệu hàng giờ so với dữ liệu huấn luyện). Để huấn luyện mô hình dự báo chuỗi thời gian, CONTEXT_LENGTH xác định độ dài của từng chuỗi thời gian đầu vào và PREDICTION_LENGTH xác định độ dài của mỗi chuỗi thời gian đầu ra.
Bởi vì CONTEXT_LENGTH và PREDICTION_LENGTH được đặt thành 168 (7 ngày) và 24 (1 ngày tiếp theo), chúng tôi vẽ sơ đồ 7 ngày cuối cùng của dữ liệu huấn luyện và 1 ngày tiếp theo của dữ liệu thử nghiệm cho mục đích trình diễn. Dữ liệu đào tạo và dữ liệu thử nghiệm được vẽ là từ 2014-05-19 20:00:00 đến 2014-05-26 19:00:00 và từ 2014-05-26 20:00:00 đến 2014-05-27 02 :00:00 tương ứng. Với mục đích trình diễn, chúng tôi chỉ vẽ chuỗi 11 thời gian trên tổng số 321, như thể hiện trong hình dưới đây.

Đào tạo người mẫu
Phần này trình bày việc đào tạo một LSTNet sử dụng mô hình GluonTS, Một Tiên tri sử dụng mô hình GluonTSVà SageMaker DeepAR mô hình có và không có tối ưu hóa siêu tham số (HPO). Đối với mỗi điều này, trước tiên chúng tôi huấn luyện mô hình không có HPO, sau đó chúng tôi huấn luyện mô hình bằng HPO. Chúng tôi chứng minh hiệu suất của mô hình tăng lên như thế nào với HPO bằng cách hiển thị các số liệu so sánh, cụ thể là RRSE (Lỗi bình phương tương đối gốc), MAPE (Lỗi phần trăm tuyệt đối trung bình) và sMAPE (Lỗi phần trăm tuyệt đối trung bình đối xứng). Đối với HPO, chúng tôi sử dụng RRSE làm thước đo đánh giá cho cả ba thuật toán.
Huấn luyện mô hình LSTNet tối ưu bằng GluonTS
LSTNet là một mô hình học sâu kết hợp các mô hình tuyến tính hồi quy tự động truyền thống song song với phần mạng thần kinh phi tuyến tính, giúp mô hình học sâu phi tuyến tính trở nên mạnh mẽ hơn đối với các chuỗi thời gian vi phạm các thay đổi về tỷ lệ. Để biết thông tin về toán học đằng sau LSTNet, hãy xem Mô hình hóa các mô hình tạm thời dài hạn và ngắn hạn với mạng lưới thần kinh sâu.
Đầu tiên chúng tôi đào tạo mô hình LSTNet không có HPO. Với các siêu tham số được xác định, chúng ta có thể chạy công việc đào tạo. Chúng tôi sử dụng GluonTS với MXNet làm khung học sâu phụ trợ để xác định và đào tạo mô hình LSTNet của chúng tôi. SageMaker thực hiện điều này bằng các công cụ ước tính khung đã thiết lập sẵn các khung học sâu. Tại đây, chúng tôi tạo công cụ ước tính SageMaker MXNet và chuyển vào tập lệnh đào tạo mô hình, siêu tham số cũng như số lượng và loại phiên bản đào tạo mà chúng tôi muốn.
Tiếp theo, chúng tôi huấn luyện mô hình LSTNet tối ưu với HPO và cải thiện hơn nữa hiệu suất của mô hình với SageMaker điều chỉnh mô hình tự động. Điều chỉnh mô hình tự động SageMaker, còn được gọi là điều chỉnh siêu tham số, tìm phiên bản tốt nhất của mô hình bằng cách chạy nhiều công việc đào tạo trên tập dữ liệu của bạn bằng thuật toán và phạm vi siêu tham số mà bạn chỉ định. Sau đó, nó chọn các giá trị siêu tham số dẫn đến mô hình hoạt động tốt nhất, được đo bằng số liệu bạn chọn. Mô hình tốt nhất và các siêu tham số tương ứng của nó được chọn trên dữ liệu xác thực từ 2014/05/26 20:00:00 đến 2014-06-01 19:00:00 (tương ứng với 6 ngày). Tiếp theo, chúng tôi triển khai mô hình tốt nhất ở điểm cuối mà chúng tôi có thể truy vấn để dự đoán. Cuối cùng, mô hình tốt nhất được đánh giá dựa trên dữ liệu thử nghiệm loại trừ từ 2014-06-01 20:00:00 đến 2014-06-02 19:00:00 (tương ứng với 1 ngày tiếp theo). Bảng sau so sánh hiệu suất của mô hình.
| Metrics | LSTNet không có HPO | LSTNet với HPO |
| RRSE | 0.555 | 0.506 |
| BẢN ĐỒ | 0.318 | 0.301 |
| sMAPE | 0.337 | 0.323 |
| Thời gian đào tạo (phút) | 10.780 | 57.242 |
| Thời gian suy luận (giây) | 5.202 | 5.340 |
Ngoại trừ thời gian huấn luyện và suy luận, đối với RRSE, MAPE và sMAPE, các giá trị nhỏ hơn cho thấy hiệu suất dự đoán tốt hơn. Do đó, chúng ta có thể quan sát thấy hiệu suất của mô hình được đào tạo bằng HPO tốt hơn đáng kể so với mô hình được đào tạo không có HPO.
Huấn luyện mô hình Tiên tri tối ưu bằng GluonTS với HPO
Tiên tri là một thuật toán để dự báo dữ liệu chuỗi thời gian dựa trên mô hình cộng tính trong đó các xu hướng phi tuyến tính phù hợp với tính thời vụ hàng năm, hàng tuần và hàng ngày, cộng với các hiệu ứng ngày lễ. Nó hoạt động tốt nhất với chuỗi thời gian có tác động mạnh mẽ theo mùa và một số mùa dữ liệu lịch sử. Prophet có khả năng xử lý tốt dữ liệu bị thiếu và những thay đổi trong xu hướng, đồng thời thường xử lý tốt các ngoại lệ. Để thực hiện thuật toán Prophet, chúng tôi sử dụng GluonTS phiên bản, là một trình bao bọc mỏng để gọi tiên tri fb bưu kiện. Đầu tiên, chúng tôi huấn luyện mô hình Prophet không có HPO bằng Công cụ ước tính SageMaker. Tiếp theo, chúng tôi huấn luyện một mô hình Tiên tri tối ưu với Điều chỉnh mô hình tự động SageMaker (HPO) và cải thiện hơn nữa hiệu suất của mô hình.
| Metrics | Nhà tiên tri không có HPO | Nhà tiên tri với HPO |
| RRSE | 0.183 | 0.147 |
| BẢN ĐỒ | 0.288 | 0.278 |
| sMAPE | 0.278 | 0.289 |
| Thời gian đào tạo (phút) | – | 45.633 |
| Thời gian suy luận (giây) | 44.813 | 45.327 |
Các giá trị số liệu có điều chỉnh HPO nhỏ hơn các giá trị không điều chỉnh HPO trên cùng một dữ liệu thử nghiệm. Điều này chỉ ra rằng việc điều chỉnh HPO sẽ cải thiện hơn nữa hiệu suất của mô hình.
Huấn luyện mô hình SageMaker DeepAR tối ưu với HPO
Thuật toán dự báo SageMaker DeepAR là thuật toán học có giám sát để dự báo chuỗi thời gian vô hướng (một chiều) bằng cách sử dụng mạng thần kinh hồi quy (RNN). Các phương pháp dự báo cổ điển, chẳng hạn như đường trung bình động tích hợp tự hồi quy (ARIMA) hoặc làm mịn hàm mũ (ETS), phù hợp với một mô hình duy nhất cho từng chuỗi thời gian riêng lẻ. Sau đó, họ sử dụng mô hình đó để ngoại suy chuỗi thời gian về tương lai.
Tuy nhiên, trong nhiều ứng dụng, bạn có nhiều chuỗi thời gian tương tự trên một tập hợp các đơn vị chéo. Ví dụ: bạn có thể có các nhóm chuỗi thời gian cho nhu cầu đối với các sản phẩm khác nhau, lượt tải máy chủ và yêu cầu đối với các trang web. Đối với loại ứng dụng này, bạn có thể hưởng lợi từ việc cùng nhau đào tạo một mô hình duy nhất trong suốt chuỗi thời gian. DeepAR áp dụng cách tiếp cận này. Khi tập dữ liệu của bạn chứa hàng trăm chuỗi thời gian liên quan, DeepAR sẽ hoạt động tốt hơn các phương pháp ARIMA và ETS tiêu chuẩn. Bạn cũng có thể sử dụng mô hình đã đào tạo để tạo dự báo cho chuỗi thời gian mới tương tự với chuỗi thời gian đã được đào tạo. Để biết thông tin về toán học đằng sau DeepAR, hãy xem DeepAR: Dự báo xác suất với Mạng lặp lại tự động phục hồi.
Tương tự như cài đặt trong các mô hình trước, trước tiên chúng tôi huấn luyện mô hình DeepAR không có HPO. Tiếp theo, chúng tôi đào tạo mô hình DeepAR tối ưu với HPO. Sau đó, chúng tôi triển khai mô hình tốt nhất ở điểm cuối mà chúng tôi có thể truy vấn để dự đoán. Bảng sau so sánh hiệu suất của mô hình.
| Metrics | DeepAR không có HPO | DeepAR với HPO |
| RRSE | 0.136 | 0.098 |
| BẢN ĐỒ | 0.087 | 0.099 |
| sMAPE | 0.104 | 0.116 |
| Thời gian đào tạo (phút) | 24.048 | 210.530 |
| Thời gian suy luận (giây) | 68.411 | 72.829 |
Các giá trị số liệu có điều chỉnh HPO nhỏ hơn các giá trị không điều chỉnh HPO trên cùng một dữ liệu thử nghiệm. Điều này chỉ ra rằng việc điều chỉnh HPO sẽ cải thiện hơn nữa hiệu suất của mô hình.
Đánh giá hiệu suất mô hình của cả ba thuật toán trên cùng một dữ liệu thử nghiệm nắm giữ
Trong phần này, chúng tôi so sánh hiệu suất của mô hình từ ba mô hình được đào tạo từ HPO. Dựa trên dữ liệu đầu vào, các so sánh có thể khác nhau đối với các tập dữ liệu đầu vào khác nhau. Bảng sau so sánh ba thuật toán cho dữ liệu đầu vào điện mẫu được sử dụng trong bài viết này.
| Metrics | LSTNet với HPO | Nhà tiên tri với HPO | DeepAR với HPO |
| RRSE | 0.506 | 0.147 | 0.098 |
| BẢN ĐỒ | 0.302 | 0.278 | 0.099 |
| sMAPE | 0.323 | 0.289 | 0.116 |
| Thời gian đào tạo (phút) | 57.242 | 45.633 | 210.530 |
| Thời gian suy luận (giây) | 5.340 | 45.327 | 72.829 |
Các số liệu sau đây trực quan hóa những kết quả này.

Hình dưới đây là một cách khác để hình dung kết quả.
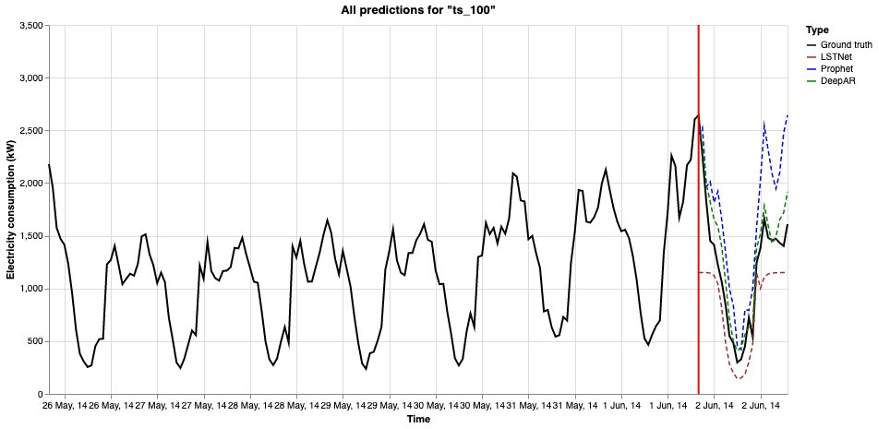
Dữ liệu huấn luyện và kiểm tra (sự thật trên mặt đất) được hiển thị dưới dạng đường liền màu đen (được phân tách bằng đường thẳng đứng màu đỏ) trong biểu đồ. Dự đoán từ các thuật toán dự báo khác nhau được hiển thị dưới dạng đường gạch ngang. Đường gạch ngang càng gần với đường liền màu đen thì dự đoán càng chính xác.
Làm sạch
Khi bạn hoàn thành giải pháp này, hãy đảm bảo rằng bạn xóa tất cả tài nguyên AWS không mong muốn để tránh phát sinh các khoản phí ngoài ý muốn. Sổ tay giải pháp cung cấp mã dọn dẹp. Trên tab giải pháp, bạn cũng có thể chọn Xóa tất cả tài nguyên trong Xóa giải pháp phần.

Kết luận
Trong bài đăng này, chúng tôi đã giới thiệu giải pháp toàn diện cho nhiệm vụ dự báo nhu cầu bằng cách sử dụng ba thuật toán chuỗi thời gian tiên tiến: LSTNet, Prophet và SageMaker DeepAR, có sẵn trong GluonTS và SageMaker. Chúng tôi đã thảo luận về ba phương pháp đào tạo: đào tạo mô hình LSTNet tối ưu bằng GlaonTS, đào tạo mô hình Prophet tối ưu bằng GluonTS và đào tạo mô hình SageMaker DeepAR tối ưu bằng HPO. Đối với mỗi điều này, trước tiên chúng tôi huấn luyện mô hình không có HPO, sau đó huấn luyện mô hình bằng HPO. Chúng tôi đã chứng minh hiệu suất mô hình tăng lên như thế nào với HPO bằng cách so sánh các số liệu, cụ thể là RRSE, MAPE và sMAPE.
Trong bài đăng này, chúng tôi đã sử dụng dữ liệu điện làm tập dữ liệu đầu vào. Tuy nhiên, bạn có thể thay đổi đầu vào và đưa dữ liệu của riêng mình vào bộ chứa S3. Bạn có thể sử dụng dữ liệu đó để huấn luyện các mô hình và nhận được các kết quả hiệu suất khác nhau, đồng thời chọn thuật toán tốt nhất cho phù hợp.
Trên bảng điều khiển SageMaker, hãy mở Studio và khởi chạy giải pháp trong JumpStart để bắt đầu hoặc bạn có thể xem giải pháp Kho GitHub để xem lại mã và biết thêm thông tin.
Về các tác giả
 Alak Eswaradass là Kiến trúc sư giải pháp cấp cao tại AWS có trụ sở tại Chicago, Illinois. Cô đam mê giúp đỡ khách hàng thiết kế kiến trúc đám mây sử dụng dịch vụ AWS để giải quyết các thách thức kinh doanh. Cô có bằng Thạc sĩ về kỹ thuật khoa học máy tính. Trước khi gia nhập AWS, cô đã làm việc cho nhiều tổ chức chăm sóc sức khỏe khác nhau và có kinh nghiệm chuyên sâu về kiến trúc các hệ thống phức tạp, đổi mới công nghệ và nghiên cứu. Cô đi chơi với các con gái và khám phá thế giới ngoài trời khi rảnh rỗi.
Alak Eswaradass là Kiến trúc sư giải pháp cấp cao tại AWS có trụ sở tại Chicago, Illinois. Cô đam mê giúp đỡ khách hàng thiết kế kiến trúc đám mây sử dụng dịch vụ AWS để giải quyết các thách thức kinh doanh. Cô có bằng Thạc sĩ về kỹ thuật khoa học máy tính. Trước khi gia nhập AWS, cô đã làm việc cho nhiều tổ chức chăm sóc sức khỏe khác nhau và có kinh nghiệm chuyên sâu về kiến trúc các hệ thống phức tạp, đổi mới công nghệ và nghiên cứu. Cô đi chơi với các con gái và khám phá thế giới ngoài trời khi rảnh rỗi.
 Tiến sĩ Xin Huang là Nhà khoa học ứng dụng cho các thuật toán tích hợp của Amazon SageMaker JumpStart và Amazon SageMaker. Anh tập trung vào việc phát triển các thuật toán học máy có thể mở rộng. Mối quan tâm nghiên cứu của ông là trong lĩnh vực xử lý ngôn ngữ tự nhiên, học sâu có thể giải thích được trên dữ liệu dạng bảng và phân tích mạnh mẽ về phân cụm không-thời gian phi tham số.
Tiến sĩ Xin Huang là Nhà khoa học ứng dụng cho các thuật toán tích hợp của Amazon SageMaker JumpStart và Amazon SageMaker. Anh tập trung vào việc phát triển các thuật toán học máy có thể mở rộng. Mối quan tâm nghiên cứu của ông là trong lĩnh vực xử lý ngôn ngữ tự nhiên, học sâu có thể giải thích được trên dữ liệu dạng bảng và phân tích mạnh mẽ về phân cụm không-thời gian phi tham số.
- Coinsmart. Sàn giao dịch Bitcoin và tiền điện tử tốt nhất Châu Âu.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. TRUY CẬP MIỄN PHÍ.
- CryptoHawk. Radar Altcoin. Dùng thử miễn phí.
- Nguồn: https://aws.amazon.com/blogs/machine-learning/deep-demand-forecasting-with-amazon-sagemaker/
- "
- 10
- 100
- 11
- 2019
- 7
- a
- có khả năng
- Giới thiệu
- Tuyệt đối
- truy cập
- cho phù hợp
- Tài khoản
- chính xác
- ngang qua
- hoạt động
- thêm vào
- Lợi thế
- thuật toán
- thuật toán
- Tất cả
- Đã
- đàn bà gan dạ
- phân tích
- Một
- API
- Các Ứng Dụng
- các ứng dụng
- áp dụng
- phương pháp tiếp cận
- cách tiếp cận
- kiến trúc
- KHU VỰC
- Tự động
- tự động hóa
- có sẵn
- Trung bình cộng
- AWS
- trước
- sau
- hưởng lợi
- BEST
- Hơn
- Đen
- đậm
- biên giới
- mang lại
- xây dựng
- được xây dựng trong
- kinh doanh
- các doanh nghiệp
- california
- có khả năng
- trường hợp
- trường hợp
- thách thức
- thay đổi
- tải
- kiểm tra
- Chicago
- Chọn
- gần gũi hơn
- đám mây
- mã
- Các công ty
- công ty
- so
- cạnh tranh
- hoàn thành
- phức tạp
- máy tính
- Khoa học Máy tính
- An ủi
- tiêu thụ
- chứa
- Tương ứng
- có thể
- tạo
- Tạo
- khách hàng
- kinh nghiệm khach hang
- khách hàng
- tiền thưởng
- Dash
- dữ liệu
- ngày
- Ngày
- xử lý
- quyết định
- sâu
- Nhu cầu
- chứng minh
- chứng minh
- triển khai
- triển khai
- Thiết kế
- phát triển
- Thiết bị (Devices)
- khác nhau
- mỗi
- hiệu ứng
- điện
- Cuối cùng đến cuối
- Điểm cuối
- năng lượng
- Kỹ Sư
- đánh giá
- đánh giá
- ví dụ
- kinh nghiệm
- NHANH
- Đặc tính
- Tính năng
- Lĩnh vực
- Hình
- Cuối cùng
- tài chính
- tìm thấy
- Tên
- phù hợp với
- tập trung
- tiếp theo
- sau
- Khung
- khung
- Miễn phí
- từ
- xa hơn
- tương lai
- tạo ra
- tạo ra
- thế hệ
- GitHub
- xảy ra
- chăm sóc sức khỏe
- cao
- giúp đỡ
- tại đây
- Cao
- cao
- Thuê
- lịch sử
- hộ gia đình
- hộ gia đình
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTTPS
- Hàng trăm
- ICON
- Illinois
- thực hiện
- nâng cao
- bao gồm
- bao gồm
- Bao gồm
- chỉ
- hệ thống riêng biệt,
- ngành công nghiệp
- thông tin
- Cơ sở hạ tầng
- sự đổi mới
- đầu vào
- ví dụ
- tích hợp
- lợi ích
- hàng tồn kho
- đầu tư
- iốt
- thiết bị iot
- IT
- Tháng một
- Việc làm
- việc làm
- tham gia
- nổi tiếng
- Ngôn ngữ
- phóng
- ra mắt
- Dẫn
- học tập
- Dòng
- dòng
- . Các địa điểm
- hậu cần
- tìm kiếm
- máy
- học máy
- làm cho
- LÀM CHO
- quản lý
- thạc sĩ
- nguyên vật liệu
- toán học
- phương pháp
- Metrics
- Might
- ML
- kiểu mẫu
- mô hình
- tháng
- chi tiết
- di chuyển
- nhiều
- cụ thể là
- Tự nhiên
- nhu cầu
- mạng
- mạng
- tiếp theo
- máy tính xách tay
- con số
- mở
- mở ra
- tối ưu hóa
- gọi món
- tổ chức
- Nền tảng khác
- ngoài trời
- riêng
- gói
- một phần
- đam mê
- tỷ lệ phần trăm
- hiệu suất
- thời gian
- lập kế hoạch
- kế hoạch
- người nghèo
- quyền lực
- dự đoán
- dự đoán
- Dự đoán
- trước
- quá trình
- xử lý
- sản xuất
- Sản phẩm
- Sản phẩm
- cung cấp
- cung cấp
- mục đích
- Quý
- Nguyên
- giới thiệu
- yêu cầu
- yêu cầu
- nghiên cứu
- Thông tin
- Kết quả
- bán lẻ
- xem xét
- nguồn gốc
- chạy
- chạy
- bán hàng
- tương tự
- khả năng mở rộng
- Quy mô
- Trường học
- Khoa học
- Nhà khoa học
- giây
- chọn
- Loạt Sách
- dịch vụ
- DỊCH VỤ
- định
- một số
- thời gian ngắn
- thiếu hụt
- hiển thị
- thể hiện
- tương tự
- Đơn giản
- duy nhất
- rắn
- giải pháp
- Giải pháp
- động SOLVE
- một số
- riêng
- Tiêu chuẩn
- bắt đầu
- nhà nước-of-the-art
- Trạng thái
- cổ phần
- là gắn
- trực tuyến
- Dịch vụ truyền trực tuyến
- hợp lý hóa
- mạnh mẽ
- phòng thu
- hệ thống
- Công nghệ
- thử nghiệm
- Kiểm tra
- Sản phẩm
- vì thế
- số ba
- Thông qua
- vé
- thời gian
- truyền thống
- Train
- Hội thảo
- giao thông vận tải
- Xu hướng
- thường
- hiểu
- các đơn vị
- trường đại học
- Đại học California
- sử dụng
- Người sử dụng
- tiện ích
- Bằng cách sử dụng
- xác nhận
- khác nhau
- phiên bản
- Video
- tuần
- hàng tuần
- Điều gì
- Wikipedia
- không có
- làm việc
- công trinh
- viết
- trên màn hình