Bài đăng này được đồng viết với Mahima Agarwal, Kỹ sư máy học và Deepak Mettem, Giám đốc kỹ thuật cấp cao, tại VMware Carbon Black
VMware Carbon đen là một giải pháp bảo mật nổi tiếng cung cấp khả năng bảo vệ chống lại toàn bộ các cuộc tấn công mạng hiện đại. Với hàng terabyte dữ liệu do sản phẩm tạo ra, nhóm phân tích bảo mật tập trung vào việc xây dựng các giải pháp máy học (ML) để đối phó với các cuộc tấn công nghiêm trọng và phát hiện các mối đe dọa mới nổi từ tiếng ồn.
Điều quan trọng đối với nhóm VMware Carbon Black là thiết kế và xây dựng một đường dẫn MLOps từ đầu đến cuối tùy chỉnh để điều phối và tự động hóa các quy trình công việc trong vòng đời ML và cho phép đào tạo, đánh giá và triển khai mô hình.
Có hai mục đích chính để xây dựng quy trình này: hỗ trợ các nhà khoa học dữ liệu phát triển mô hình ở giai đoạn cuối và dự đoán mô hình bề mặt trong sản phẩm bằng cách phục vụ các mô hình với số lượng lớn và trong lưu lượng sản xuất thời gian thực. Do đó, VMware Carbon Black và AWS đã chọn xây dựng đường dẫn MLOps tùy chỉnh bằng cách sử dụng Amazon SageMaker vì tính dễ sử dụng, tính linh hoạt và cơ sở hạ tầng được quản lý đầy đủ. Chúng tôi sắp xếp các đường ống triển khai và đào tạo ML của mình bằng cách sử dụng Quy trình công việc được quản lý của Amazon cho Luồng khí Apache (Amazon MWAA), cho phép chúng tôi tập trung hơn vào các quy trình và quy trình tác giả lập trình mà không phải lo lắng về việc tự động thay đổi quy mô hoặc bảo trì cơ sở hạ tầng.
Với quy trình này, nghiên cứu ML dựa trên máy tính xách tay Jupyter từng là một quy trình tự động triển khai các mô hình vào sản xuất mà ít có sự can thiệp thủ công từ các nhà khoa học dữ liệu. Trước đây, quá trình đào tạo, đánh giá và triển khai một mô hình có thể mất hơn một ngày; với cách triển khai này, mọi thứ chỉ là một thao tác kích hoạt và đã giảm tổng thời gian xuống còn vài phút.
Trong bài đăng này, các kiến trúc sư của VMware Carbon Black và AWS thảo luận về cách chúng tôi xây dựng và quản lý quy trình công việc ML tùy chỉnh bằng cách sử dụng Gitlab, Amazon MWAA và SageMaker. Chúng tôi thảo luận về những gì chúng tôi đã đạt được cho đến nay, những cải tiến hơn nữa đối với quy trình bán hàng và các bài học kinh nghiệm trong quá trình thực hiện.
Tổng quan về giải pháp
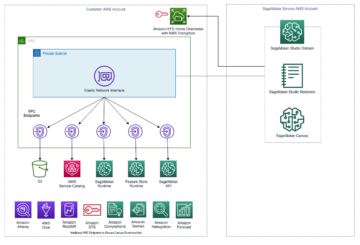
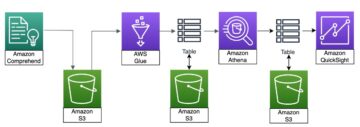
Sơ đồ sau đây minh họa kiến trúc nền tảng ML.

Thiết kế giải pháp cấp cao
Nền tảng ML này đã được hình dung và thiết kế để được sử dụng bởi các mô hình khác nhau trên các kho lưu trữ mã khác nhau. Nhóm của chúng tôi sử dụng GitLab làm công cụ quản lý mã nguồn để duy trì tất cả các kho lưu trữ mã. Mọi thay đổi trong mã nguồn kho lưu trữ mô hình được tích hợp liên tục bằng cách sử dụng CI Gitlab, gọi các quy trình công việc tiếp theo trong quy trình (đào tạo mô hình, đánh giá và triển khai).
Sơ đồ kiến trúc sau đây minh họa quy trình làm việc từ đầu đến cuối và các thành phần liên quan đến đường dẫn MLOps của chúng tôi.

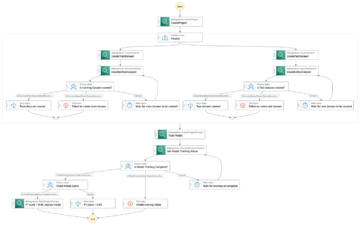
Quy trình làm việc từ đầu đến cuối
Quy trình đào tạo, đánh giá và triển khai mô hình ML được sắp xếp bằng cách sử dụng Amazon MWAA, được gọi là Đồ thị Acyclic có hướng (DAG). DAG là một tập hợp các tác vụ cùng nhau, được tổ chức với các phụ thuộc và mối quan hệ để cho biết chúng nên chạy như thế nào.
Ở cấp độ cao, kiến trúc giải pháp bao gồm ba thành phần chính:
- Kho lưu trữ mã đường ống ML
- Quy trình đào tạo và đánh giá mô hình ML
- Quy trình triển khai mô hình ML
Hãy thảo luận về cách các thành phần khác nhau này được quản lý và cách chúng tương tác với nhau.
Kho lưu trữ mã đường ống ML
Sau khi kho lưu trữ mô hình tích hợp kho lưu trữ MLOps làm đường dẫn hạ nguồn của họ và một nhà khoa học dữ liệu cam kết mã trong kho lưu trữ mô hình của họ, một trình chạy GitLab sẽ thực hiện kiểm tra và xác thực mã tiêu chuẩn được xác định trong kho lưu trữ đó và kích hoạt đường dẫn MLOps dựa trên các thay đổi mã. Chúng tôi sử dụng quy trình đa dự án của Gitlab để kích hoạt trình kích hoạt này trên các kho lưu trữ khác nhau.
Đường dẫn MLOps GitLab chạy một tập hợp các giai đoạn nhất định. Nó tiến hành xác thực mã cơ bản bằng cách sử dụng pylint, đóng gói mã suy luận và đào tạo của mô hình trong hình ảnh Docker và xuất bản hình ảnh vùng chứa lên Đăng ký container đàn hồi Amazon (ECR của Amazon). Amazon ECR là sổ đăng ký bộ chứa được quản lý hoàn toàn cung cấp dịch vụ lưu trữ hiệu suất cao, vì vậy bạn có thể triển khai các hình ảnh ứng dụng và thành phần lạ ở bất cứ đâu một cách đáng tin cậy.
Quy trình đào tạo và đánh giá mô hình ML
Sau khi hình ảnh được xuất bản, nó sẽ kích hoạt quá trình đào tạo và đánh giá Luồng khí Apache đường ống thông qua AWS Lambda chức năng. Lambda là dịch vụ điện toán hướng sự kiện, không cần máy chủ, cho phép bạn chạy mã cho hầu như mọi loại ứng dụng hoặc dịch vụ phụ trợ mà không cần cung cấp hoặc quản lý máy chủ.
Sau khi quy trình được kích hoạt thành công, quy trình sẽ chạy DAG Đào tạo và Đánh giá, từ đó bắt đầu đào tạo mô hình trong SageMaker. Khi kết thúc quy trình đào tạo này, nhóm người dùng được xác định sẽ nhận được thông báo về kết quả đánh giá mô hình và đào tạo qua email thông qua Dịch vụ thông báo đơn giản của Amazon (Amazon SNS) và Slack. Amazon SNS là dịch vụ pub/sub được quản lý hoàn toàn cho nhắn tin A2A và A2P.
Sau khi phân tích tỉ mỉ các kết quả đánh giá, nhà khoa học dữ liệu hoặc kỹ sư ML có thể triển khai mô hình mới nếu hiệu suất của mô hình mới được đào tạo tốt hơn so với phiên bản trước. Hiệu suất của các mô hình được đánh giá dựa trên các chỉ số dành riêng cho mô hình (chẳng hạn như điểm F1, MSE hoặc ma trận nhầm lẫn).
Quy trình triển khai mô hình ML
Để bắt đầu triển khai, người dùng bắt đầu công việc GitLab kích hoạt DAG triển khai thông qua cùng chức năng Lambda. Sau khi quy trình chạy thành công, quy trình sẽ tạo hoặc cập nhật điểm cuối SageMaker bằng mô hình mới. Thao tác này cũng gửi thông báo có chi tiết điểm cuối qua email bằng Amazon SNS và Slack.
Trong trường hợp xảy ra lỗi ở một trong hai đường ống, người dùng sẽ được thông báo qua cùng một kênh liên lạc.
SageMaker cung cấp khả năng suy luận theo thời gian thực lý tưởng cho khối lượng công việc suy luận với độ trễ thấp và yêu cầu thông lượng cao. Các điểm cuối này được quản lý hoàn toàn, cân bằng tải và tự động thay đổi quy mô, đồng thời có thể được triển khai trên nhiều Vùng sẵn sàng để có tính sẵn sàng cao. Quy trình của chúng tôi tạo một điểm cuối như vậy cho một mô hình sau khi mô hình chạy thành công.
Trong các phần sau, chúng tôi mở rộng trên các thành phần khác nhau và đi sâu vào chi tiết.
GitLab: Các mô hình gói và đường dẫn kích hoạt
Chúng tôi sử dụng GitLab làm kho lưu trữ mã của mình và cho đường ống để đóng gói mã mô hình và kích hoạt các DAG luồng không khí xuôi dòng.
Đường ống đa dự án
Tính năng đường dẫn GitLab đa dự án được sử dụng trong đó đường dẫn chính (ngược dòng) là một kho lưu trữ mô hình và đường dẫn con (hạ lưu) là kho lưu trữ MLOps. Mỗi repo duy trì một .gitlab-ci.yml và khối mã sau đây được kích hoạt trong đường ống ngược dòng sẽ kích hoạt đường ống MLOps xuôi dòng.
Đường ống ngược dòng gửi mã mô hình đến đường ống xuôi dòng nơi các công việc đóng gói và xuất bản CI được kích hoạt. Mã để chứa mã mô hình và xuất bản lên Amazon ECR được duy trì và quản lý bởi đường dẫn MLOps. Nó gửi các biến như ACCESS_TOKEN (có thể được tạo dưới Cài đặt, Truy Cập), các biến JOB_ID (để truy cập các tạo phẩm ngược dòng) và $CI_PROJECT_ID (ID dự án của repo mô hình), để đường dẫn MLOps có thể truy cập các tệp mã mô hình. với hiện vật công việc tính năng từ Gitlab, repo xuôi dòng sẽ truy cập các tạo phẩm từ xa bằng cách sử dụng lệnh sau:
Repo mô hình có thể sử dụng các đường ống xuôi dòng cho nhiều mô hình từ cùng một repo bằng cách mở rộng giai đoạn kích hoạt nó bằng cách sử dụng kéo dài từ khóa từ GitLab, cho phép bạn sử dụng lại cùng một cấu hình qua các giai đoạn khác nhau.
Sau khi xuất bản hình ảnh mô hình lên Amazon ECR, quy trình MLOps kích hoạt quy trình đào tạo Amazon MWAA bằng Lambda. Sau khi được người dùng phê duyệt, nó cũng kích hoạt quy trình triển khai mô hình Amazon MWAA bằng cách sử dụng cùng chức năng Lambda.
Phiên bản ngữ nghĩa và chuyển phiên bản xuôi dòng
Chúng tôi đã phát triển mã tùy chỉnh cho phiên bản hình ảnh ECR và mô hình SageMaker. Đường dẫn MLOps quản lý logic lập phiên bản ngữ nghĩa cho hình ảnh và mô hình như một phần của giai đoạn nơi mã mô hình được chứa và chuyển các phiên bản sang các giai đoạn sau dưới dạng tạo tác.
Đào tạo lại
Vì đào tạo lại là một khía cạnh quan trọng của vòng đời ML nên chúng tôi đã triển khai các khả năng đào tạo lại như một phần trong quy trình của chúng tôi. Chúng tôi sử dụng API mô hình danh sách SageMaker để xác định xem nó có đang đào tạo lại hay không dựa trên dấu thời gian và số phiên bản đào tạo lại mô hình.
Chúng tôi quản lý lịch trình hàng ngày của quy trình đào tạo lại bằng cách sử dụng Đường ống lịch trình của GitLab.
Terraform: Thiết lập cơ sở hạ tầng
Ngoài cụm Amazon MWAA, kho lưu trữ ECR, hàm Lambda và chủ đề SNS, giải pháp này còn sử dụng Quản lý truy cập và nhận dạng AWS (IAM) vai trò, người dùng và chính sách; Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) nhóm và một amazoncloudwatch đăng nhập giao nhận.
Để hợp lý hóa việc thiết lập và bảo trì cơ sở hạ tầng cho các dịch vụ liên quan trong toàn bộ hệ thống của chúng tôi, chúng tôi sử dụng Terraform để triển khai cơ sở hạ tầng dưới dạng mã. Bất cứ khi nào cần cập nhật cơ sở hạ tầng, các thay đổi về mã sẽ kích hoạt quy trình GitLab CI mà chúng tôi thiết lập. Quy trình này sẽ xác thực và triển khai các thay đổi trong các môi trường khác nhau (ví dụ: thêm quyền cho chính sách IAM trong tài khoản nhà phát triển, giai đoạn và nhà sản xuất).
Amazon ECR, Amazon S3 và Lambda: Hỗ trợ đường ống
Chúng tôi sử dụng các dịch vụ chính sau đây để tạo thuận lợi cho đường ống của chúng tôi:
- Amazon ECR – Để duy trì và cho phép truy xuất hình ảnh vùng chứa mô hình một cách thuận tiện, chúng tôi gắn thẻ chúng với các phiên bản ngữ nghĩa và tải chúng lên kho lưu trữ ECR được thiết lập mỗi
${project_name}/${model_name}thông qua Terraform. Điều này cho phép tạo ra một lớp cách ly tốt giữa các mô hình khác nhau và cho phép chúng tôi sử dụng các thuật toán tùy chỉnh cũng như định dạng các yêu cầu và phản hồi suy luận để bao gồm thông tin kê khai mô hình mong muốn (tên mô hình, phiên bản, đường dẫn dữ liệu đào tạo, v.v.). - Amazon S3 – Chúng tôi sử dụng bộ chứa S3 để duy trì dữ liệu đào tạo mô hình, thành phần tạo mẫu mô hình được đào tạo trên mỗi mô hình, DAG luồng khí và các thông tin bổ sung khác theo yêu cầu của đường ống.
- Lambda – Vì cụm Luồng không khí của chúng tôi được triển khai trong một VPC riêng biệt để cân nhắc về bảo mật nên không thể truy cập trực tiếp vào các DAG. Do đó, chúng tôi sử dụng hàm Lambda, cũng được duy trì bằng Terraform, để kích hoạt bất kỳ DAG nào được chỉ định bởi tên DAG. Với thiết lập IAM phù hợp, công việc GitLab CI sẽ kích hoạt chức năng Lambda, chức năng này sẽ chuyển các cấu hình xuống DAG đào tạo hoặc triển khai được yêu cầu.
Amazon MWAA: Quy trình đào tạo và triển khai
Như đã đề cập trước đó, chúng tôi sử dụng Amazon MWAA để sắp xếp các quy trình đào tạo và triển khai. Chúng tôi sử dụng toán tử SageMaker có sẵn trong Gói nhà cung cấp Amazon cho Airflow để tích hợp với SageMaker (để tránh tạo khuôn mẫu jinja).
Chúng tôi sử dụng các toán tử sau trong quy trình đào tạo này (được hiển thị trong sơ đồ quy trình công việc sau):

Đường ống đào tạo MWAA
Chúng tôi sử dụng các toán tử sau trong quy trình triển khai (được hiển thị trong sơ đồ quy trình công việc sau):

Đường ống triển khai mô hình
Chúng tôi sử dụng Slack và Amazon SNS để xuất bản thông báo lỗi/thành công và kết quả đánh giá trong cả hai quy trình. Slack cung cấp nhiều tùy chọn để tùy chỉnh thông báo, bao gồm các tùy chọn sau:
- Toán tử SnsPublish - Chúng tôi sử dụng Toán tử SnsPublish để gửi thông báo thành công/thất bại tới email người dùng
- API chậm – Chúng tôi đã tạo ra URL webhook đến để nhận thông báo đường dẫn đến kênh mong muốn
CloudWatch và VMware Wavefront: Theo dõi và ghi nhật ký
Chúng tôi sử dụng bảng điều khiển CloudWatch để định cấu hình giám sát và ghi nhật ký điểm cuối. Nó giúp trực quan hóa và theo dõi các số liệu hiệu suất hoạt động và mô hình khác nhau cụ thể cho từng dự án. Ngoài các chính sách tự động thay đổi quy mô được thiết lập để theo dõi một số trong số chúng, chúng tôi liên tục theo dõi các thay đổi về mức sử dụng CPU và bộ nhớ, yêu cầu mỗi giây, độ trễ phản hồi và chỉ số mô hình.
CloudWatch thậm chí còn được tích hợp với bảng điều khiển VMware Tanzu Wavefront để có thể trực quan hóa các số liệu cho điểm cuối mô hình cũng như các dịch vụ khác ở cấp dự án.
Lợi ích kinh doanh và những gì tiếp theo
Đường ống ML rất quan trọng đối với các tính năng và dịch vụ ML. Trong bài đăng này, chúng tôi đã thảo luận về trường hợp sử dụng ML toàn diện bằng cách sử dụng các khả năng từ AWS. Chúng tôi đã xây dựng một quy trình tùy chỉnh bằng cách sử dụng SageMaker và Amazon MWAA, chúng tôi có thể sử dụng lại quy trình này trên các dự án và mô hình, đồng thời tự động hóa vòng đời ML, giúp giảm thời gian từ đào tạo mô hình đến triển khai sản xuất xuống chỉ còn 10 phút.
Với việc chuyển gánh nặng vòng đời ML sang SageMaker, nó đã cung cấp cơ sở hạ tầng được tối ưu hóa và có thể mở rộng để đào tạo và triển khai mô hình. Việc phục vụ mô hình với SageMaker đã giúp chúng tôi đưa ra các dự đoán theo thời gian thực với độ trễ mili giây và khả năng giám sát. Chúng tôi đã sử dụng Terraform để dễ thiết lập và quản lý cơ sở hạ tầng.
Các bước tiếp theo cho quy trình này sẽ là tăng cường quy trình đào tạo mô hình với các khả năng đào tạo lại cho dù nó được lên lịch hay dựa trên phát hiện sai lệch mô hình, hỗ trợ triển khai bóng tối hoặc thử nghiệm A/B để triển khai mô hình đủ điều kiện và nhanh hơn cũng như theo dõi dòng ML. Chúng tôi cũng có kế hoạch đánh giá Đường ống Amazon SageMaker vì tích hợp GitLab hiện đã được hỗ trợ.
Bài học kinh nghiệm
Là một phần của việc xây dựng giải pháp này, chúng tôi đã học được rằng bạn nên khái quát hóa sớm, nhưng đừng khái quát hóa quá mức. Khi chúng tôi hoàn thành thiết kế kiến trúc lần đầu tiên, chúng tôi đã cố gắng tạo và thực thi việc tạo khuôn mẫu mã cho mã mô hình như một phương pháp hay nhất. Tuy nhiên, quá trình phát triển còn quá sớm nên các mẫu quá chung chung hoặc quá chi tiết để có thể tái sử dụng cho các mẫu trong tương lai.
Sau khi phân phối mô hình đầu tiên thông qua quy trình bán hàng, các mẫu xuất hiện một cách tự nhiên dựa trên thông tin chi tiết từ công việc trước đây của chúng tôi. Một quy trình không thể làm mọi thứ ngay từ ngày đầu tiên.
Thử nghiệm mô hình và sản xuất thường có các yêu cầu rất khác nhau (hoặc đôi khi thậm chí mâu thuẫn). Điều quan trọng là phải cân bằng các yêu cầu này ngay từ đầu với tư cách là một nhóm và sắp xếp thứ tự ưu tiên cho phù hợp.
Ngoài ra, bạn có thể không cần mọi tính năng của một dịch vụ. Sử dụng các tính năng thiết yếu từ một dịch vụ và có thiết kế được mô đun hóa là chìa khóa để phát triển hiệu quả hơn và một quy trình linh hoạt.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách chúng tôi xây dựng giải pháp MLOps bằng cách sử dụng SageMaker và Amazon MWAA để tự động hóa quy trình triển khai các mô hình vào sản xuất mà ít có sự can thiệp thủ công từ các nhà khoa học dữ liệu. Chúng tôi khuyến khích bạn đánh giá các dịch vụ AWS khác nhau như SageMaker, Amazon MWAA, Amazon S3 và Amazon ECR để xây dựng một giải pháp MLOps hoàn chỉnh.
*Apache, Apache Airflow và Airflow là nhãn hiệu đã đăng ký hoặc nhãn hiệu của Quỹ phần mềm Apache ở Hoa Kỳ và / hoặc các quốc gia khác.
Về các tác giả
 Deepak Mettem là Giám đốc Kỹ thuật Cấp cao tại VMware, Đơn vị Carbon Black. Anh ấy và nhóm của mình làm việc để xây dựng các ứng dụng và dịch vụ dựa trên phát trực tuyến có tính khả dụng cao, khả năng mở rộng và linh hoạt để mang đến cho khách hàng các giải pháp dựa trên máy học trong thời gian thực. Anh ấy và nhóm của mình cũng chịu trách nhiệm tạo ra các công cụ cần thiết cho các nhà khoa học dữ liệu để xây dựng, đào tạo, triển khai và xác thực các mô hình ML của họ trong sản xuất.
Deepak Mettem là Giám đốc Kỹ thuật Cấp cao tại VMware, Đơn vị Carbon Black. Anh ấy và nhóm của mình làm việc để xây dựng các ứng dụng và dịch vụ dựa trên phát trực tuyến có tính khả dụng cao, khả năng mở rộng và linh hoạt để mang đến cho khách hàng các giải pháp dựa trên máy học trong thời gian thực. Anh ấy và nhóm của mình cũng chịu trách nhiệm tạo ra các công cụ cần thiết cho các nhà khoa học dữ liệu để xây dựng, đào tạo, triển khai và xác thực các mô hình ML của họ trong sản xuất.
 Mahima Agarwal là Kỹ sư Máy học tại VMware, Đơn vị Carbon Black.
Mahima Agarwal là Kỹ sư Máy học tại VMware, Đơn vị Carbon Black.
Cô làm công việc thiết kế, xây dựng và phát triển các thành phần cốt lõi và kiến trúc của nền tảng máy học cho VMware CB SBU.
 Vamshi Krishna Enabothala là Kiến trúc sư chuyên gia AI ứng dụng cấp cao tại AWS. Anh ấy làm việc với các khách hàng từ các lĩnh vực khác nhau để tăng tốc các sáng kiến về dữ liệu, phân tích và học máy có tác động cao. Anh ấy đam mê các hệ thống đề xuất, NLP và các lĩnh vực thị giác máy tính trong AI và ML. Ngoài công việc, Vamshi là một người đam mê RC, chế tạo thiết bị RC (máy bay, ô tô và máy bay không người lái), đồng thời cũng thích làm vườn.
Vamshi Krishna Enabothala là Kiến trúc sư chuyên gia AI ứng dụng cấp cao tại AWS. Anh ấy làm việc với các khách hàng từ các lĩnh vực khác nhau để tăng tốc các sáng kiến về dữ liệu, phân tích và học máy có tác động cao. Anh ấy đam mê các hệ thống đề xuất, NLP và các lĩnh vực thị giác máy tính trong AI và ML. Ngoài công việc, Vamshi là một người đam mê RC, chế tạo thiết bị RC (máy bay, ô tô và máy bay không người lái), đồng thời cũng thích làm vườn.
 Sahil Thapar là một Kiến trúc sư Giải pháp Doanh nghiệp. Anh ấy làm việc với khách hàng để giúp họ xây dựng các ứng dụng có tính khả dụng cao, khả năng mở rộng và linh hoạt trên Đám mây AWS. Anh ấy hiện đang tập trung vào các giải pháp máy học và container.
Sahil Thapar là một Kiến trúc sư Giải pháp Doanh nghiệp. Anh ấy làm việc với khách hàng để giúp họ xây dựng các ứng dụng có tính khả dụng cao, khả năng mở rộng và linh hoạt trên Đám mây AWS. Anh ấy hiện đang tập trung vào các giải pháp máy học và container.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :là
- $ LÊN
- 1
- 10
- 100
- 7
- 8
- a
- Giới thiệu
- đẩy nhanh tiến độ
- truy cập
- truy cập
- cho phù hợp
- Trợ Lý Giám Đốc
- đạt được
- ngang qua
- xoay vòng
- Ngoài ra
- thêm vào
- thông tin bổ sung
- Sau
- chống lại
- AI
- thuật toán
- Tất cả
- cho phép
- đàn bà gan dạ
- Amazon SageMaker
- phân tích
- phân tích
- và
- bất cứ nơi nào
- Apache
- api
- Các Ứng Dụng
- các ứng dụng
- áp dụng
- AI ứng dụng
- phê duyệt
- kiến trúc
- LÀ
- khu vực
- AS
- khía cạnh
- At
- Các cuộc tấn công
- tác giả
- tự động
- Tự động
- tự động hóa
- sẵn có
- có sẵn
- tránh
- AWS
- Backend
- Cân đối
- dựa
- cơ bản
- BE
- bởi vì
- Bắt đầu
- Lợi ích
- BEST
- Hơn
- giữa
- Đen
- Chặn
- Chi nhánh
- mang lại
- xây dựng
- Xây dựng
- xây dựng
- gánh nặng
- by
- CAN
- không thể
- khả năng
- carbon
- xe ô tô
- trường hợp
- CB
- nhất định
- Những thay đổi
- kênh
- trẻ em
- chọn
- đám mây
- cụm
- mã
- bộ sưu tập
- Giao tiếp
- so
- hoàn thành
- các thành phần
- Tính
- máy tính
- Tầm nhìn máy tính
- tiến hành
- Cấu hình
- cấu hình
- Mâu thuẫn
- nhầm lẫn
- sự cân nhắc
- ăn
- tiêu thụ
- Container
- Container
- liên tục
- Tiện lợi
- Trung tâm
- có thể
- nước
- CPU
- tạo
- tạo ra
- tạo ra
- Tạo
- quan trọng
- quan trọng
- Hiện nay
- khách hàng
- khách hàng
- tùy chỉnh
- Tấn công mạng
- DAG
- tiền thưởng
- bảng điều khiển
- dữ liệu
- nhà khoa học dữ liệu
- ngày
- xác định
- phân phối
- triển khai
- triển khai
- triển khai
- triển khai
- triển khai
- triển khai
- Thiết kế
- thiết kế
- thiết kế
- chi tiết
- chi tiết
- Phát hiện
- Dev
- phát triển
- phát triển
- Phát triển
- khác nhau
- trực tiếp
- thảo luận
- thảo luận
- phu bến tàu
- dont
- xuống
- Các phương tiện bay không người lái
- mỗi
- Sớm hơn
- Đầu
- dễ sử dụng
- hiệu quả
- hay
- mới nổi
- cho phép
- kích hoạt
- cho phép
- khuyến khích
- Cuối cùng đến cuối
- Điểm cuối
- ky sư
- Kỹ Sư
- Doanh nghiệp
- Giải pháp doanh nghiệp
- người đam mê
- môi trường
- Trang thiết bị
- thiết yếu
- Ether (ETH)
- đánh giá
- đánh giá
- đánh giá
- đánh giá
- đánh giá
- Ngay cả
- Sự kiện
- Mỗi
- tất cả mọi thứ
- ví dụ
- Mở rộng
- mở rộng
- f1
- tạo điều kiện
- Không
- xa
- nhanh hơn
- Đặc tính
- Tính năng
- vài
- Các tập tin
- Tên
- linh hoạt
- Tập trung
- tập trung
- tập trung
- tiếp theo
- Trong
- định dạng
- từ
- Full
- toàn phổ
- đầy đủ
- chức năng
- chức năng
- xa hơn
- tương lai
- tạo ra
- được
- tốt
- Nhóm
- Có
- có
- giúp đỡ
- đã giúp
- giúp
- Cao
- hiệu suất cao
- cao
- lưu trữ
- Độ đáng tin của
- Tuy nhiên
- HTML
- http
- HTTPS
- IAM
- ID
- lý tưởng
- xác định
- xác định
- Bản sắc
- hình ảnh
- hình ảnh
- thực hiện
- thực hiện
- thực hiện
- in
- bao gồm
- bao gồm
- Bao gồm
- thông tin
- Cơ sở hạ tầng
- khả năng phán đoán
- những hiểu biết
- tích hợp
- tích hợp
- Tích hợp
- hội nhập
- tương tác
- can thiệp
- viện dẫn
- tham gia
- cô lập
- IT
- ITS
- Việc làm
- việc làm
- jpg
- Giữ
- Key
- phím
- Độ trễ
- lớp
- học
- học tập
- Bài học
- Bài học kinh nghiệm
- cho phép
- Cấp
- vòng đời
- Lượt thích
- ít
- tải
- Thấp
- máy
- học máy
- Chủ yếu
- duy trì
- duy trì
- bảo trì
- làm cho
- quản lý
- quản lý
- quản lý
- giám đốc
- quản lý
- quản lý
- nhãn hiệu
- Matrix
- Bộ nhớ
- đề cập
- tin nhắn
- tin nhắn
- Metrics
- Might
- mili giây
- phút
- ML
- MLOps
- kiểu mẫu
- mô hình
- hiện đại
- Màn Hình
- giám sát
- chi tiết
- hiệu quả hơn
- nhiều
- tên
- tự nhiên
- cần thiết
- Cần
- Mới
- tiếp theo
- nlp
- Tiếng ồn
- thông báo
- thông báo
- con số
- of
- cung cấp
- Cung cấp
- on
- ONE
- hoạt động
- khai thác
- tối ưu hóa
- Các lựa chọn
- dàn xếp
- Tổ chức
- Nền tảng khác
- bên ngoài
- tổng thể
- gói
- gói
- bao bì
- một phần
- vượt qua
- Đi qua
- đam mê
- con đường
- hiệu suất
- cho phép
- đường ống dẫn
- kế hoạch
- Máy bay
- nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Chính sách
- điều luật
- Bài đăng
- thực hành
- Dự đoán
- trước
- Ưu tiên
- quá trình
- Sản phẩm
- Sản lượng
- dự án
- dự án
- đúng
- bảo vệ
- cung cấp
- nhà cung cấp dịch vụ
- cung cấp
- xuất bản
- công bố
- Xuất bản
- Xuất bản
- mục đích
- đủ điều kiện
- phạm vi
- thời gian thực
- Khuyến nghị
- Giảm
- gọi
- đăng ký
- đăng ký
- Mối quan hệ
- xa
- Trứ danh
- kho
- yêu cầu
- yêu cầu
- cần phải
- Yêu cầu
- nghiên cứu
- đàn hồi
- phản ứng
- chịu trách nhiệm
- Kết quả
- đào tạo lại
- có thể tái sử dụng
- vai trò
- chạy
- Á hậu
- nhà làm hiền triết
- tương tự
- khả năng mở rộng
- mở rộng quy mô
- lịch trình
- lên kế hoạch
- Nhà khoa học
- các nhà khoa học
- Thứ hai
- phần
- Ngành
- an ninh
- cao cấp
- riêng biệt
- Không có máy chủ
- Các máy chủ
- dịch vụ
- DỊCH VỤ
- phục vụ
- định
- thiết lập
- Bóng tối
- VẬN CHUYỂN
- nên
- thể hiện
- Đơn giản
- lún xuống
- So
- cho đến nay
- Phần mềm
- giải pháp
- Giải pháp
- một số
- nguồn
- mã nguồn
- chuyên gia
- riêng
- quy định
- quang phổ
- Spotlight
- Traineeship
- giai đoạn
- Tiêu chuẩn
- Bắt đầu
- bắt đầu
- Bang
- Các bước
- là gắn
- Chiến lược
- trực tuyến
- hợp lý hóa
- tiếp theo
- Thành công
- như vậy
- hỗ trợ
- Hỗ trợ
- Bề mặt
- hệ thống
- TAG
- Hãy
- nhiệm vụ
- nhóm
- mẫu
- Terraform
- Kiểm tra
- việc này
- Sản phẩm
- cung cấp their dịch
- Them
- vì thế
- Kia là
- các mối đe dọa
- số ba
- Thông qua
- khắp
- thông lượng
- thời gian
- dấu thời gian
- đến
- bên nhau
- quá
- công cụ
- công cụ
- hàng đầu
- chủ đề
- theo dõi
- Theo dõi
- thương hiệu
- giao thông
- Train
- đào tạo
- Hội thảo
- kích hoạt
- được kích hoạt
- XOAY
- Dưới
- đơn vị
- Kỳ
- Hoa Kỳ
- Cập nhật
- us
- Sử dụng
- sử dụng
- ca sử dụng
- người sử dang
- Người sử dụng
- HIỆU LỰC
- xác nhận
- biến
- khác nhau
- phiên bản
- hầu như
- tầm nhìn
- hình dung
- vmware
- khối lượng
- Đường..
- TỐT
- Điều gì
- liệu
- cái nào
- rộng
- Phạm vi rộng
- với
- ở trong
- không có
- Công việc
- quy trình làm việc
- Luồng công việc
- công trinh
- sẽ
- zephyrnet
- Zip
- khu vực Ace