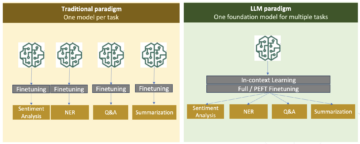
Các mô hình biến áp dựa trên sự chú ý lớn đã thu được lợi nhuận lớn về xử lý ngôn ngữ tự nhiên (NLP). Tuy nhiên, việc đào tạo các mạng khổng lồ này từ đầu đòi hỏi một lượng lớn dữ liệu và máy tính. Đối với các bộ dữ liệu NLP nhỏ hơn, một chiến lược đơn giản nhưng hiệu quả là sử dụng một máy biến áp được đào tạo trước, thường được đào tạo theo cách không giám sát trên các bộ dữ liệu rất lớn và tinh chỉnh nó trên bộ dữ liệu quan tâm. Ôm mặt duy trì một vườn thú mô hình lớn gồm những máy biến áp đã được đào tạo trước này và giúp chúng dễ dàng tiếp cận ngay cả với những người mới sử dụng.
Tuy nhiên, việc tinh chỉnh các mô hình này vẫn đòi hỏi kiến thức chuyên môn, vì chúng khá nhạy cảm với các siêu tham số của chúng, chẳng hạn như tốc độ học hoặc kích thước lô. Trong bài đăng này, chúng tôi chỉ ra cách tối ưu hóa các siêu tham số này bằng khung mã nguồn mở Giai điệu Syne để tối ưu hóa siêu tham số phân tán (HPO). Syne Tune cho phép chúng tôi tìm ra cấu hình siêu tham số tốt hơn đạt được sự cải thiện tương đối từ 1-4% so với siêu tham số mặc định trên phổ biến KEO bộ dữ liệu điểm chuẩn. Bản thân sự lựa chọn của mô hình được đào tạo trước cũng có thể được coi là một siêu thông số và do đó được chọn tự động bởi Syne Tune. Đối với vấn đề phân loại văn bản, điều này dẫn đến việc tăng thêm độ chính xác lên xấp xỉ 5% so với mô hình mặc định. Tuy nhiên, chúng tôi có thể tự động hóa nhiều quyết định hơn mà người dùng cần thực hiện; chúng tôi chứng minh điều này bằng cách hiển thị loại cá thể là một siêu tham số mà sau này chúng tôi sử dụng để triển khai mô hình. Bằng cách chọn loại phiên bản phù hợp, chúng tôi có thể tìm thấy các cấu hình đánh đổi tối ưu chi phí và độ trễ.
Để được giới thiệu về Syne Tune, vui lòng tham khảo Chạy các công việc điều chỉnh siêu tham số và kiến trúc thần kinh phân tán với Syne Tune.
Tối ưu hóa siêu tham số với Syne Tune
Chúng tôi sẽ sử dụng KEO bộ tiêu chuẩn, bao gồm chín bộ dữ liệu cho các nhiệm vụ hiểu ngôn ngữ tự nhiên, chẳng hạn như nhận dạng văn bản hoặc phân tích tình cảm. Vì vậy, chúng tôi điều chỉnh khuôn mặt của Hugging run_glue.py kịch bản đào tạo. Bộ dữ liệu GLUE đi kèm với bộ đào tạo và đánh giá được xác định trước có nhãn cũng như bộ kiểm tra tạm dừng không có nhãn. Do đó, chúng tôi chia tập hợp đào tạo thành một tập hợp đào tạo và xác nhận (phân tách 70% / 30%) và sử dụng tập hợp đánh giá làm tập dữ liệu kiểm tra lưu giữ của chúng tôi. Hơn nữa, chúng tôi thêm một hàm gọi lại khác vào API huấn luyện viên của Hugging Face để báo cáo hiệu suất xác thực sau mỗi kỷ nguyên quay lại Syne Tune. Xem đoạn mã sau:
Chúng tôi bắt đầu với việc tối ưu hóa các siêu thông số đào tạo điển hình: tỷ lệ học tập, tỷ lệ khởi động để tăng tỷ lệ học tập và kích thước lô để tinh chỉnh BERT được đào tạo trước (bert-cơ sở-trường hợp), là mô hình mặc định trong ví dụ về Khuôn mặt ôm. Xem đoạn mã sau:
Là phương pháp HPO của chúng tôi, chúng tôi sử dụng ASHA, lấy mẫu các cấu hình siêu tham số một cách đồng nhất ngẫu nhiên và lặp đi lặp lại việc đánh giá các cấu hình hoạt động kém. Mặc dù các phương pháp phức tạp hơn sử dụng mô hình xác suất của hàm mục tiêu, chẳng hạn như BO hoặc MoBster tồn tại, chúng tôi sử dụng ASHA cho bài đăng này vì nó không có bất kỳ giả định nào về không gian tìm kiếm.
Trong hình sau, chúng tôi so sánh sự cải thiện tương đối về lỗi thử nghiệm so với cấu hình siêu tham số mặc định của Hugging Faces.
![]()
Để đơn giản, chúng tôi giới hạn so sánh với MRPC, COLA và STSB, nhưng chúng tôi cũng quan sát thấy những cải tiến tương tự cũng đối với các bộ dữ liệu GLUE khác. Đối với mỗi tập dữ liệu, chúng tôi chạy ASHA trên một ml.g4dn.xlarge Amazon SageMaker ví dụ với ngân sách thời gian chạy là 1,800 giây, tương ứng với khoảng 13, 7 và 9 đánh giá chức năng đầy đủ tương ứng trên các tập dữ liệu này. Để tính đến tính ngẫu nhiên nội tại của quá trình đào tạo, ví dụ như do lấy mẫu theo lô nhỏ gây ra, chúng tôi chạy cả ASHA và cấu hình mặc định cho năm lần lặp lại với một hạt giống độc lập cho trình tạo số ngẫu nhiên và báo cáo độ lệch chuẩn và trung bình của cải thiện tương đối qua các lần lặp lại. Chúng ta có thể thấy rằng, trên tất cả các tập dữ liệu, trên thực tế, chúng ta có thể cải thiện hiệu suất dự đoán từ 1-3% so với hiệu suất của cấu hình mặc định được chọn cẩn thận.
Tự động chọn mô hình được đào tạo trước
Chúng tôi có thể sử dụng HPO để không chỉ tìm các siêu tham số mà còn tự động chọn đúng mô hình được đào tạo trước. Tại sao chúng tôi muốn làm điều này? Bởi vì không có một mô hình nào hoạt động tốt hơn trên tất cả các tập dữ liệu, chúng tôi phải chọn mô hình phù hợp cho một tập dữ liệu cụ thể. Để chứng minh điều này, chúng tôi đánh giá một loạt các mẫu biến áp phổ biến của Ôm Face. Đối với mỗi tập dữ liệu, chúng tôi xếp hạng từng mô hình theo hiệu suất thử nghiệm của nó. Thứ hạng trên các tập dữ liệu (xem Hình sau) thay đổi và không có một mô hình nào đạt điểm cao nhất trên mọi tập dữ liệu. Để tham khảo, chúng tôi cũng hiển thị hiệu suất kiểm tra tuyệt đối của từng mô hình và tập dữ liệu trong hình sau.
Để tự động chọn mô hình phù hợp, chúng tôi có thể chọn mô hình dưới dạng tham số phân loại và thêm thông số này vào không gian tìm kiếm siêu tham số của chúng tôi:
Mặc dù không gian tìm kiếm hiện đã lớn hơn, nhưng điều đó không nhất thiết có nghĩa là việc tối ưu hóa khó hơn. Hình dưới đây cho thấy lỗi kiểm tra của cấu hình được quan sát tốt nhất (dựa trên lỗi xác thực) trên tập dữ liệu MRPC của ASHA theo thời gian khi chúng tôi tìm kiếm trong không gian ban đầu (đường màu xanh lam) (với mô hình được đào tạo trước dựa trên BERT-base-cased ) hoặc trong không gian tìm kiếm tăng cường mới (dòng màu cam). Với cùng một ngân sách, ASHA có thể tìm thấy cấu hình siêu tham số hoạt động tốt hơn nhiều trong không gian tìm kiếm mở rộng so với trong không gian nhỏ hơn.
![]()
Tự động chọn loại phiên bản
Trên thực tế, chúng tôi có thể không chỉ quan tâm đến việc tối ưu hóa hiệu suất dự đoán. Chúng tôi cũng có thể quan tâm đến các mục tiêu khác, chẳng hạn như thời gian đào tạo, chi phí (đô la), độ trễ hoặc các chỉ số công bằng. Chúng ta cũng cần thực hiện các lựa chọn khác ngoài các siêu tham số của mô hình, ví dụ như chọn kiểu cá thể.
Mặc dù kiểu phiên bản không ảnh hưởng đến hiệu suất dự đoán, nhưng nó tác động mạnh đến chi phí (đô la), thời gian chạy đào tạo và độ trễ. Điều sau trở nên đặc biệt quan trọng khi mô hình được triển khai. Chúng ta có thể gọi HPO là một bài toán tối ưu hóa đa mục tiêu, trong đó chúng tôi hướng đến việc tối ưu hóa nhiều mục tiêu đồng thời. Tuy nhiên, không có giải pháp duy nhất nào tối ưu hóa tất cả các chỉ số cùng một lúc. Thay vào đó, chúng tôi hướng đến việc tìm ra một tập hợp các cấu hình có thể đánh đổi một cách tối ưu mục tiêu này so với mục tiêu khác. Đây được gọi là Bộ Pareto.
Để phân tích thêm cài đặt này, chúng tôi thêm lựa chọn loại cá thể làm siêu tham số phân loại bổ sung vào không gian tìm kiếm của chúng tôi:
Chúng tôi sử dụng MO-ASHA, điều này giúp ASHA điều chỉnh cho phù hợp với kịch bản đa mục tiêu bằng cách sử dụng phân loại không bị chi phối. Trong mỗi lần lặp lại, MO-ASHA cũng chọn cho mỗi cấu hình cũng như kiểu phiên bản mà chúng tôi muốn đánh giá. Để chạy HPO trên một tập hợp các trường hợp không đồng nhất, Syne Tune cung cấp chương trình phụ trợ SageMaker. Với phần phụ trợ này, mỗi bản thử nghiệm được đánh giá là một công việc đào tạo SageMaker độc lập trên bản thể hiện của chính nó. Số lượng công nhân xác định có bao nhiêu công việc SageMaker mà chúng tôi chạy song song tại một thời điểm nhất định. Bản thân trình tối ưu hóa, MO-ASHA trong trường hợp của chúng tôi, chạy trên máy cục bộ, máy tính xách tay Sagemaker hoặc trên một công việc đào tạo SageMaker riêng biệt. Xem đoạn mã sau:
Các số liệu sau đây cho thấy độ trễ so với lỗi kiểm tra ở bên trái và độ trễ so với chi phí ở bên phải đối với các cấu hình ngẫu nhiên được lấy mẫu bởi MO-ASHA (chúng tôi giới hạn trục cho khả năng hiển thị) trên tập dữ liệu MRPC sau khi chạy nó trong 10,800 giây trên bốn công nhân. Màu sắc cho biết loại phiên bản. Đường gạch ngang màu đen thể hiện tập hợp Pareto, có nghĩa là tập hợp các điểm chiếm ưu thế tất cả các điểm khác trong ít nhất một mục tiêu.
Chúng ta có thể quan sát thấy sự cân bằng giữa độ trễ và lỗi kiểm tra, có nghĩa là cấu hình tốt nhất với lỗi kiểm tra thấp nhất sẽ không đạt được độ trễ thấp nhất. Dựa trên sở thích của mình, bạn có thể chọn cấu hình siêu thông số hy sinh hiệu suất thử nghiệm nhưng đi kèm với độ trễ nhỏ hơn. Chúng tôi cũng nhận thấy sự cân bằng giữa độ trễ và chi phí. Ví dụ: bằng cách sử dụng một phiên bản ml.g4dn.xlarge nhỏ hơn, chúng tôi chỉ tăng độ trễ một chút, nhưng phải trả một phần tư chi phí của một phiên bản ml.g4dn.8xlarge.
Kết luận
Trong bài đăng này, chúng tôi đã thảo luận về tối ưu hóa siêu tham số để tinh chỉnh các mô hình biến áp được đào tạo trước từ Hugging Face dựa trên Syne Tune. Chúng tôi thấy rằng bằng cách tối ưu hóa các siêu tham số như tốc độ học, kích thước lô và tỷ lệ khởi động, chúng tôi có thể cải thiện dựa trên cấu hình mặc định được chọn cẩn thận. Chúng tôi cũng có thể mở rộng điều này bằng cách tự động chọn mô hình được đào tạo trước thông qua tối ưu hóa siêu tham số.
Với sự trợ giúp của chương trình phụ trợ SageMaker của Syne Tune, chúng ta có thể coi kiểu cá thể như một siêu tham số. Mặc dù kiểu phiên bản không ảnh hưởng đến hiệu suất, nhưng nó có tác động đáng kể đến độ trễ và chi phí. Do đó, bằng cách sử dụng HPO như một bài toán tối ưu hóa đa mục tiêu, chúng tôi có thể tìm thấy một tập hợp các cấu hình đánh đổi một cách tối ưu mục tiêu này so với mục tiêu kia. Nếu bạn muốn tự mình thử điều này, hãy xem ví dụ máy tính xách tay.
Về các tác giả
![]() Aaron Klein là Nhà khoa học ứng dụng tại AWS.
Aaron Klein là Nhà khoa học ứng dụng tại AWS.
![]() Matthias Seeger là Nhà Khoa học Ứng dụng Chính tại AWS.
Matthias Seeger là Nhà Khoa học Ứng dụng Chính tại AWS.
![]() David Salinas là Nhà Khoa học Ứng dụng Sr tại AWS.
David Salinas là Nhà Khoa học Ứng dụng Sr tại AWS.
![]() Emily Webber đã tham gia AWS ngay sau khi SageMaker ra mắt và kể từ đó đã cố gắng nói cho cả thế giới biết về điều đó! Ngoài việc xây dựng trải nghiệm ML mới cho khách hàng, Emily thích thiền định và nghiên cứu Phật giáo Tây Tạng.
Emily Webber đã tham gia AWS ngay sau khi SageMaker ra mắt và kể từ đó đã cố gắng nói cho cả thế giới biết về điều đó! Ngoài việc xây dựng trải nghiệm ML mới cho khách hàng, Emily thích thiền định và nghiên cứu Phật giáo Tây Tạng.
![]() Cedric Archambeau là Nhà Khoa học Ứng dụng Chính tại AWS và là Thành viên của Phòng thí nghiệm Châu Âu về Hệ thống Học tập và Thông minh.
Cedric Archambeau là Nhà Khoa học Ứng dụng Chính tại AWS và là Thành viên của Phòng thí nghiệm Châu Âu về Hệ thống Học tập và Thông minh.
- Coinsmart. Sàn giao dịch Bitcoin và tiền điện tử tốt nhất Châu Âu.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. TRUY CẬP MIỄN PHÍ.
- CryptoHawk. Radar Altcoin. Dùng thử miễn phí.
- Nguồn: https://aws.amazon.com/blogs/machine-learning/hyperparameter-optimization-for-fine-tuning-pre-trained-transformer-models-from-hugging-face/
- "
- 10
- 100
- 7
- 9
- a
- Giới thiệu
- Tuyệt đối
- có thể truy cập
- Tài khoản
- Đạt được
- ngang qua
- thêm vào
- ảnh hưởng đến
- Tất cả
- cho phép
- Mặc dù
- đàn bà gan dạ
- số lượng
- phân tích
- phân tích
- Một
- api
- áp dụng
- khoảng
- kiến trúc
- tăng cường
- tự động hóa
- tự động
- Trung bình cộng
- AWS
- Trục
- bởi vì
- điểm chuẩn
- BEST
- Hơn
- giữa
- Ngoài
- Đen
- đậm
- tăng
- ngân sách
- Xây dựng
- mà
- trường hợp
- gây ra
- sự lựa chọn
- lựa chọn
- lựa chọn
- tốt nghiệp lớp XNUMX
- phân loại
- mã
- Đến
- so
- Tính
- Cấu hình
- điều khiển
- khách hàng
- dữ liệu
- quyết định
- chứng minh
- triển khai
- triển khai
- phân phối
- Không
- Đô la
- mỗi
- dễ dàng
- Hiệu quả
- Châu Âu
- đánh giá
- đánh giá
- ví dụ
- Kinh nghiệm
- chuyên gia
- thêm
- Đối mặt
- Thời trang
- Hình
- tiếp theo
- Khung
- từ
- Full
- chức năng
- xa hơn
- Hơn nữa
- máy phát điện
- giúp đỡ
- tại đây
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTTPS
- Va chạm
- quan trọng
- nâng cao
- cải thiện
- Tăng lên
- độc lập
- ảnh hưởng
- ví dụ
- Thông minh
- quan tâm
- IT
- chính nó
- Việc làm
- việc làm
- gia nhập
- kiến thức
- phòng thí nghiệm
- Nhãn
- Ngôn ngữ
- lớn
- lớn hơn
- phát động
- Dẫn
- học tập
- LIMIT
- Dòng
- địa phương
- máy
- làm cho
- LÀM CHO
- lớn
- có nghĩa là
- phương pháp
- Metrics
- Might
- ML
- kiểu mẫu
- mô hình
- chi tiết
- nhiều
- Tự nhiên
- nhất thiết
- nhu cầu
- mạng
- máy tính xách tay
- con số
- mục tiêu
- thu được
- tối ưu hóa
- Tối ưu hóa
- tối ưu hóa
- nguyên
- Nền tảng khác
- riêng
- đặc biệt
- Trả
- hiệu suất
- biểu diễn
- xin vui lòng
- điểm
- Phổ biến
- thực hành
- Hiệu trưởng
- Vấn đề
- quá trình
- xử lý
- cung cấp
- phạm vi
- Xếp hạng
- báo cáo
- phóng viên
- Báo cáo
- đại diện cho
- đòi hỏi
- Kết quả
- chạy
- chạy
- tương tự
- Nhà khoa học
- Tìm kiếm
- giây
- hạt giống
- chọn
- tình cảm
- định
- thiết lập
- hiển thị
- có ý nghĩa
- tương tự
- Đơn giản
- duy nhất
- Kích thước máy
- giải pháp
- tinh vi
- Không gian
- riêng
- chia
- Tiêu chuẩn
- Bắt đầu
- Tiểu bang
- Vẫn còn
- Chiến lược
- hệ thống
- nhiệm vụ
- thử nghiệm
- Sản phẩm
- thế giới
- vì thế
- thời gian
- thương mại
- Hội thảo
- điều trị
- kinh hai
- thử nghiệm
- sự hiểu biết
- us
- sử dụng
- Người sử dụng
- thường
- sử dụng
- xác nhận
- khả năng hiển thị
- Wikipedia
- không có
- công nhân
- thế giới
- trên màn hình