Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Giới thiệu
Nói chung, học máy có thể được phân thành bốn loại: học máy có giám sát, học máy không giám sát, học máy bán giám sát và học tăng cường. Học máy có giám sát là một loại máy học thuộc loại hoặc nhánh khoa học dữ liệu dễ nhất và ít phức tạp nhất. Bài viết sẽ thảo luận về học tăng cường và học siêu tăng cường trong khoa học dữ liệu. Bài viết này sẽ giúp một người hiểu được ý tưởng cơ bản và trực giác cốt lõi đằng sau phương pháp học siêu tăng cường và cơ chế hoạt động của nó. Chúng ta sẽ bắt đầu bằng cách xem xét lại khái niệm học tăng cường và nhanh chóng chuyển sang học siêu tăng cường và trực giác cốt lõi của nó.
Học tăng cường
Học tăng cường là một loại học máy trong đó có ba điều chính: tác nhân, môi trường và hành động của tác nhân. Ở đây, tác nhân là mô hình học máy hoặc thuật toán chưa được đào tạo ban đầu. Tác nhân được đưa vào môi trường. Bây giờ tác nhân sẽ thực hiện các hành động và tùy theo các hành động đã thực hiện và kết quả, tác nhân sẽ được thưởng một số điểm.
Dựa trên số điểm được trao cho mô hình hoặc tác nhân, tác nhân học cách ở lại và hành động phù hợp trong môi trường và đây là cách đào tạo mô hình được thực hiện trong học tăng cường.
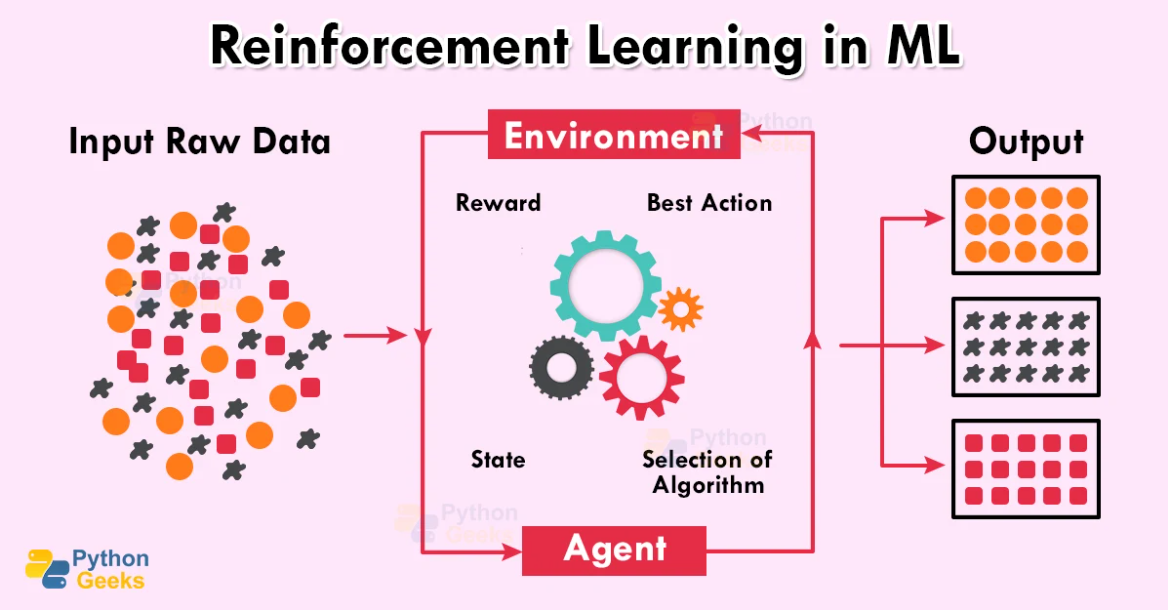
Trong hình trên, chúng ta có thể thấy rằng một số dữ liệu đầu vào đang được cung cấp cho mô hình. Sau khi dữ liệu đã được cung cấp cho hệ thống, tác nhân sẽ chọn mô hình phù hợp nhất tùy theo môi trường, mô hình sẽ đào tạo trên cùng một thuật toán và dữ liệu đầu vào và cơ sở kết quả giống nhau, và một số điểm sẽ trao giải cho kiểu mẫu. Giờ đây, mô hình có thể dễ dàng chọn thuật toán phù hợp nhất bằng cách điều chỉnh và xem số điểm được trao.
Kịch bản dữ liệu hạn chế
Độ phức tạp về thời gian của các mô hình học tăng cường cao vì chúng cần nhiều thời gian để đào tạo mô hình. Mô hình RL là loại mô hình thực hiện nhiều tính toán để giới thiệu một mô hình thành công, mô hình này cũng đòi hỏi sức mạnh tính toán cao hơn. Các mô hình học tăng cường tốt được đào tạo trên các kích thước dữ liệu quan trọng để đạt được độ chính xác và kết quả tốt hơn từ mô hình.
Nhưng trong mọi trường hợp, có thể có nhiều dữ liệu và thời gian để huấn luyện mô hình học tăng cường. Trong những trường hợp như vậy, học tăng cường meta giúp thực hiện các nhiệm vụ đó. Kiến thức siêu gia cố được sử dụng trong kịch bản này để chuẩn bị cùng một mô hình nhanh hơn với dữ liệu hạn chế có sẵn.
Học tăng cường meta
Học tăng cường meta là một loại học tăng cường được sử dụng để đào tạo các mô hình học tăng cường với dữ liệu và thời gian hạn chế. Cách tiếp cận này chủ yếu được sử dụng để đào tạo các mô hình khi không có sẵn dữ liệu lớn liên quan đến tuyên bố vấn đề và cần phải chuẩn bị một mô hình càng nhanh càng tốt.
Trong cách tiếp cận này, trạng thái ban đầu của cấu trúc của mô hình được sử dụng nhiều nhất. Ở đây, các giai đoạn cơ bản hoặc ít hơn của tác nhân mô hình được sử dụng để huấn luyện tác nhân và sau đó tùy thuộc vào kiến thức này về tác nhân, các bước trong tương lai được thực hiện tự động.
Ví dụ, trong trường hợp mạng nơ-ron, cấu trúc cơ bản hoặc cấu trúc ban đầu của mạng nơ-ron được nghiên cứu. Bây giờ để đào tạo mô hình hơn nữa, kiến thức thu được từ các bước ban đầu và các tài nguyên có sẵn với cùng một nhiệm vụ được sử dụng để đào tạo và chuẩn bị cho mô hình tiếp theo với dữ liệu hạn chế.

Trong hình trên, chúng ta có thể thấy rằng tác nhân hành động theo môi trường và được trao giải thưởng bằng hành động của nó. Ở đây, tác nhân quan sát môi trường và điều chỉnh các tham số theo nó. Sự khác biệt chính ở đây là tác nhân chăm sóc các phần thưởng và quan sát trước đó và sử dụng thông tin cụ thể đó để thực hiện bước tiếp theo.

Trong hình trên, chúng ta có thể thấy một tác nhân và môi trường. Tác nhân thực hiện hành động ở chế độ nền và được thưởng tùy theo hoạt động của nó. Quá trình này diễn ra nhiều lần và tác nhân sẽ quan tâm đến các quan sát và phần thưởng trước đó, đồng thời các chính sách đang được thực hiện để hành động theo môi trường trong bước tiếp theo. Điều này sẽ giúp mô hình thực hiện nhiệm vụ rất hiệu quả với dữ liệu hạn chế và không mất nhiều thời gian cho việc huấn luyện.
Học tăng cường so với học siêu tăng cường
Theo cấu trúc của mô hình gia cố, cả hai kỹ thuật đều giống nhau, nhưng có một chút khác biệt giữa chúng trong cơ chế hoạt động của mô hình. Trong học tăng cường, mô hình thực hiện các hành động trong môi trường và được trao kết quả để hình thành các hoạt động cụ thể. Ở đây, dữ liệu hoặc các quan sát từ các bước trước không được sử dụng để thực hiện hành động sau.
Trong học tăng cường meta, tác nhân hành động theo môi trường và thực hiện hành động. Nhân viên quan sát cài đặt cho các bước cụ thể và được khen thưởng theo kết quả. Không, trong bước tiếp theo, tác nhân lại hành động trong các môi trường, nhưng ở đây, tác nhân cũng sẽ ghi nhớ các quan sát và phần thưởng từ bước trước.
Đây là sự khác biệt chính giữa hai điều này, giúp cho việc học siêu tăng cường hoạt động nhanh hơn và hiệu quả hơn. Kiến thức thu được từ các bước trước được ghi lại và giúp thực hiện các bước sau, giúp đào tạo mô hình ngay cả với dữ liệu hạn chế.
Kết luận
Trong bài viết này, chúng tôi đã thảo luận về các kỹ thuật học tăng cường và siêu tăng cường với ý tưởng cơ bản, trực giác cốt lõi và cơ chế hoạt động của chúng. Kiến thức về kỹ thuật này sẽ; giúp một người hiểu rõ hơn về khái niệm thuật toán RL và cho phép một người trả lời các câu hỏi phỏng vấn phức tạp liên quan đến nó một cách hiệu quả.
Một số Chìa khóa chính từ bài viết này là:
1. Học tăng cường là một nhánh của khoa học dữ liệu liên quan đến tác nhân, môi trường cũng như các hành động và quan sát của nó.
2. Trong các thuật toán Gia cố thông thường, dữ liệu hoặc các quan sát từ bước trước không được sử dụng để thực hiện tác vụ tiếp theo.
3. Trong quá trình học siêu tăng cường, các quan sát và phần thưởng của bước trước đó được ghi lại và đưa vào giai đoạn tiếp theo của các hành động của tác nhân.
4. Học siêu tăng cường có thể có lợi cho việc thực hiện các tác vụ chỉ có một lượng dữ liệu hạn chế và nghiên cứu cần được hoàn thành nhanh chóng mà không mất thêm thời gian.
Bạn muốn liên hệ với tác giả?
Theo dõi Parth Shukla @Phân tíchVidhya, LinkedIn, Twittervà Trung bình để biết thêm nội dung.
Liên hệ với Parth Shukla @Phần Shukla | danh mục đầu tư or Phần Shukla | E-mail liên hệ với tôi.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2022/12/meta-reinforcement-learning-in-data-science/
- a
- Giới thiệu
- ở trên
- Theo
- chính xác
- Đạt được
- Hành động
- Hoạt động
- hành động
- hoạt động
- hành vi
- Đại lý
- thuật toán
- thuật toán
- số lượng
- phân tích
- và
- trả lời
- phương pháp tiếp cận
- thích hợp
- thích hợp
- bài viết
- tác giả
- tự động
- có sẵn
- giải thưởng
- trao
- lý lịch
- cơ bản
- cơ sở
- sau
- được
- mang lại lợi ích
- BEST
- Hơn
- giữa
- Chi nhánh
- mà
- trường hợp
- trường hợp
- phân loại
- Hoàn thành
- phức tạp
- phức tạp
- tính toán
- khái niệm
- liên lạc
- nội dung
- Trung tâm
- dữ liệu
- khoa học dữ liệu
- Ưu đãi
- Tùy
- sự khác biệt
- tùy ý
- thảo luận
- thảo luận
- dễ nhất
- dễ dàng
- hiệu quả
- Môi trường
- môi trường
- kỷ nguyên
- Ether (ETH)
- Ngay cả
- ví dụ
- NHANH
- nhanh hơn
- Fed
- tiếp theo
- hình thức
- từ
- xa hơn
- tương lai
- tốt
- giúp đỡ
- giúp
- tại đây
- Cao
- cao hơn
- Độ đáng tin của
- HTTPS
- ý tưởng
- hình ảnh
- in
- bao gồm
- thông tin
- ban đầu
- ban đầu
- đầu vào
- Phỏng vấn
- Câu hỏi phỏng vấn
- giới thiệu
- IT
- kiến thức
- học tập
- Hạn chế
- tìm kiếm
- máy
- học máy
- thực hiện
- Chủ yếu
- LÀM CHO
- cơ chế
- Phương tiện truyền thông
- ML
- kiểu mẫu
- mô hình
- chi tiết
- hầu hết
- di chuyển
- nhiều
- Cần
- nhu cầu
- mạng
- mạng thần kinh
- tiếp theo
- Quan sát
- ONE
- sở hữu
- thông số
- một phần
- riêng
- thực hiện
- biểu diễn
- Nơi
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- điểm
- Chính sách
- có thể
- quyền hạn
- Chuẩn bị
- trình bày
- trước
- Vấn đề
- quá trình
- cung cấp
- công bố
- đặt
- Câu hỏi
- Mau
- ghi lại
- đều đặn
- liên quan
- nhớ
- yêu cầu
- đòi hỏi
- Thông tin
- Kết quả
- thưởng
- Thưởng
- tương tự
- Khoa học
- thiết lập
- thể hiện
- có ý nghĩa
- kích thước
- một số
- giai đoạn
- Bắt đầu
- Tiểu bang
- Tuyên bố
- ở lại
- Bước
- Các bước
- cấu trúc
- nghiên cứu
- Học tập
- thành công
- như vậy
- hệ thống
- mất
- dùng
- Nhiệm vụ
- nhiệm vụ
- kỹ thuật
- Sản phẩm
- cung cấp their dịch
- điều
- số ba
- thời gian
- thời gian
- đến
- Train
- đào tạo
- Hội thảo
- giai điệu
- loại
- hiểu
- Lớn
- cái nào
- sẽ
- không có
- Công việc
- đang làm việc
- zephyrnet