Loạt bài gồm ba phần này trình bày cách sử dụng mạng lưới thần kinh đồ thị (GNN) và Sao Hải vương Amazon để tạo các đề xuất phim bằng cách sử dụng IMDb và Box Office Mojo Phim/TV/OTT gói dữ liệu có thể cấp phép, cung cấp nhiều loại siêu dữ liệu giải trí, bao gồm hơn 1 tỷ xếp hạng của người dùng; tín dụng cho hơn 11 triệu diễn viên và thành viên phi hành đoàn; 9 triệu tựa phim, truyền hình và giải trí; và dữ liệu báo cáo phòng vé toàn cầu từ hơn 60 quốc gia. Nhiều khách hàng phương tiện và giải trí AWS cấp phép cho dữ liệu IMDb thông qua Trao đổi dữ liệu AWS để cải thiện khả năng khám phá nội dung và tăng mức độ tương tác cũng như giữ chân khách hàng.
In Phần 1, chúng tôi đã thảo luận về các ứng dụng của GNN cũng như cách chuyển đổi và chuẩn bị dữ liệu IMDb của chúng tôi để truy vấn. Trong bài đăng này, chúng tôi thảo luận về quy trình sử dụng Neptune để tạo các nhúng được sử dụng để tiến hành tìm kiếm ngoài danh mục của chúng tôi trong Phần 3 . Chúng tôi cũng đi qua Amazon Sao Hải Vương ML, tính năng học máy (ML) của Neptune và mã chúng tôi sử dụng trong quá trình phát triển của mình. Trong Phần 3 , chúng ta sẽ tìm hiểu cách áp dụng các nhúng sơ đồ tri thức vào trường hợp sử dụng tìm kiếm ngoài danh mục.
Tổng quan về giải pháp
Các tập dữ liệu lớn được kết nối thường chứa thông tin có giá trị khó có thể trích xuất bằng các truy vấn chỉ dựa trên trực giác của con người. Các kỹ thuật ML có thể giúp tìm ra các mối tương quan ẩn trong biểu đồ với hàng tỷ mối quan hệ. Những mối tương quan này có thể hữu ích cho việc giới thiệu sản phẩm, dự đoán giá trị tín dụng, xác định gian lận và nhiều trường hợp sử dụng khác.
Neptune ML cho phép xây dựng và đào tạo các mô hình ML hữu ích trên các biểu đồ lớn trong vài giờ thay vì vài tuần. Để thực hiện điều này, Neptune ML sử dụng công nghệ GNN được hỗ trợ bởi Amazon SageMaker và Thư viện đồ thị sâu (DGL) (đó là mã nguồn mở). GNN là một lĩnh vực mới nổi trong trí tuệ nhân tạo (ví dụ, xem Khảo sát Toàn diện về Mạng Neural Đồ thị). Để có hướng dẫn thực hành về cách sử dụng GNN với DGL, hãy xem Học mạng lưới thần kinh đồ thị với Thư viện đồ thị sâu.
Trong bài đăng này, chúng tôi trình bày cách sử dụng Neptune trong hệ thống của chúng tôi để tạo nhúng.
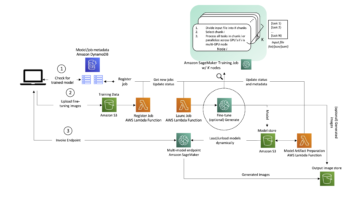
Sơ đồ sau mô tả toàn bộ luồng dữ liệu IMDb từ tải xuống đến tạo nhúng.
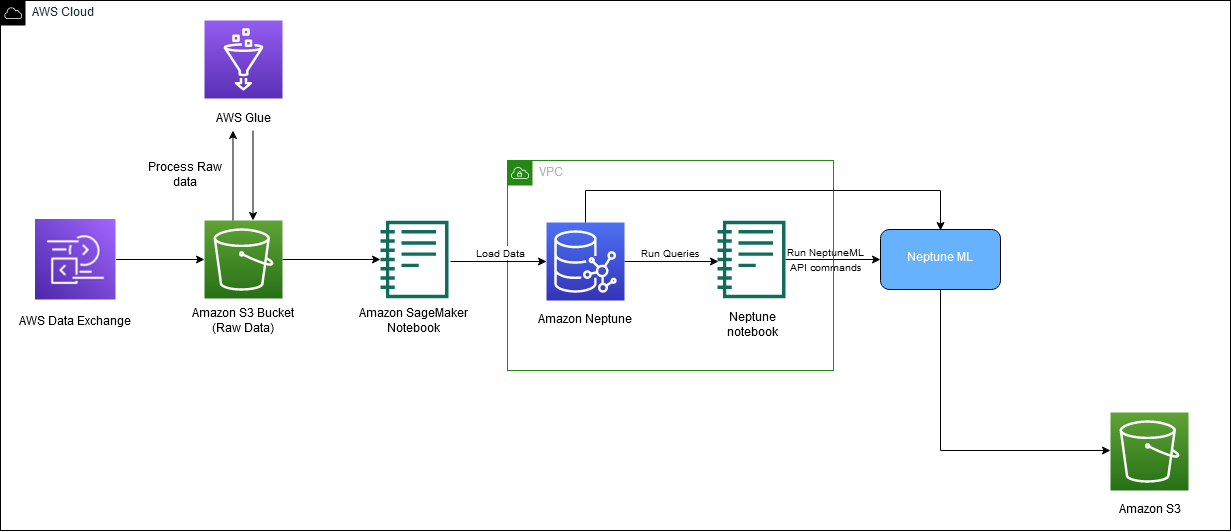
Chúng tôi sử dụng các dịch vụ AWS sau để triển khai giải pháp:
Trong bài đăng này, chúng tôi hướng dẫn bạn qua các bước cấp cao sau:
- Thiết lập biến môi trường
- Tạo một công việc xuất khẩu.
- Tạo một công việc xử lý dữ liệu.
- Gửi một công việc đào tạo.
- Tải về nhúng.
Mã cho các lệnh Neptune ML
Chúng tôi sử dụng các lệnh sau đây như một phần của việc triển khai giải pháp này:
Chúng tôi sử dụng neptune_ml export để kiểm tra trạng thái hoặc bắt đầu quy trình xuất Neptune ML và neptune_ml training để bắt đầu và kiểm tra trạng thái của công việc đào tạo người mẫu Neptune ML.
Để biết thêm thông tin về các lệnh này và các lệnh khác, hãy tham khảo Sử dụng ma thuật bàn làm việc của Neptune trong sổ ghi chép của bạn.
Điều kiện tiên quyết
Để làm theo cùng với bài đăng này, bạn nên có những điều sau đây:
- An Tài khoản AWS
- Quen thuộc với SageMaker, Amazon S3 và AWS CloudFormation
- Dữ liệu đồ thị được tải vào cụm Sao Hải Vương (xem Phần 1 để biết thêm thông tin)
Thiết lập biến môi trường
Trước khi chúng tôi bắt đầu, bạn sẽ cần thiết lập môi trường của mình bằng cách đặt các biến sau: s3_bucket_uri và processed_folder. s3_bucket_uri là tên của thùng được sử dụng trong Phần 1 và processed_folder là vị trí Amazon S3 cho đầu ra từ tác vụ xuất .
Tạo một công việc xuất khẩu
Trong Phần 1, chúng ta đã tạo sổ ghi chép SageMaker và dịch vụ xuất để xuất dữ liệu từ cụm Neptune DB sang Amazon S3 ở định dạng bắt buộc.
Bây giờ dữ liệu của chúng tôi đã được tải và dịch vụ xuất đã được tạo, chúng tôi cần tạo một công việc xuất để bắt đầu dịch vụ đó. Để làm điều này, chúng tôi sử dụng NeptuneExportApiUri và tạo tham số cho công việc xuất. Trong đoạn mã sau, chúng tôi sử dụng các biến expo và export_params. Bộ expo để của bạn NeptuneExportApiUri giá trị mà bạn có thể tìm thấy trên Kết quả đầu ra tab của ngăn xếp CloudFormation của bạn. Vì export_params, chúng tôi sử dụng điểm cuối của cụm Sao Hải Vương của bạn và cung cấp giá trị cho outputS3path, là vị trí Amazon S3 cho đầu ra từ tác vụ xuất.
Để gửi công việc xuất sử dụng lệnh sau:
Để kiểm tra trạng thái của tác vụ xuất, hãy sử dụng lệnh sau:
Sau khi công việc của bạn hoàn tất, hãy đặt processed_folder biến để cung cấp vị trí Amazon S3 của kết quả được xử lý:
Tạo một công việc xử lý dữ liệu
Bây giờ, quá trình xuất đã hoàn tất, chúng tôi tạo một công việc xử lý dữ liệu để chuẩn bị dữ liệu cho quy trình đào tạo Neptune ML. Điều này có thể được thực hiện một vài cách khác nhau. Đối với bước này, bạn có thể thay đổi job_name và modelType các biến, nhưng tất cả các tham số khác phải giữ nguyên. Phần chính của mã này là modelType tham số, có thể là các mô hình đồ thị không đồng nhất (heterogeneous) hoặc đồ thị tri thức (kge).
Công việc xuất khẩu còn bao gồm training-data-configuration.json. Sử dụng tệp này để thêm hoặc xóa bất kỳ nút hoặc cạnh nào mà bạn không muốn cung cấp cho quá trình đào tạo (ví dụ: nếu bạn muốn dự đoán liên kết giữa hai nút, bạn có thể xóa liên kết đó trong tệp cấu hình này). Đối với bài đăng trên blog này, chúng tôi sử dụng tệp cấu hình ban đầu. Để biết thêm thông tin, xem Chỉnh sửa tệp cấu hình đào tạo.
Tạo công việc xử lý dữ liệu của bạn với đoạn mã sau:
Để kiểm tra trạng thái của tác vụ xuất, hãy sử dụng lệnh sau:
Gửi một công việc đào tạo
Sau khi công việc xử lý hoàn tất, chúng tôi có thể bắt đầu công việc đào tạo của mình, đây là nơi chúng tôi tạo các phần nhúng của mình. Chúng tôi khuyên dùng loại phiên bản ml.m5.24xlarge nhưng bạn có thể thay đổi loại này để phù hợp với nhu cầu sử dụng máy tính của mình. Xem đoạn mã sau:
Chúng tôi in biến training_results để lấy ID cho công việc đào tạo. Sử dụng lệnh sau để kiểm tra trạng thái công việc của bạn:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Tải xuống nhúng
Sau khi công việc đào tạo của bạn hoàn tất, bước cuối cùng là tải xuống các bản nhúng thô của bạn. Các bước sau đây chỉ cho bạn cách tải xuống các nhúng được tạo bằng KGE (bạn có thể sử dụng quy trình tương tự cho RGCN).
Trong đoạn mã sau, chúng tôi sử dụng neptune_ml.get_mapping() và get_embeddings() để tải xuống tệp ánh xạ (mapping.info) và tệp nhúng thô (entity.npy). Sau đó, chúng ta cần ánh xạ các phần nhúng phù hợp với ID tương ứng của chúng.
Để tải xuống RGCN, hãy làm theo quy trình tương tự với tên công việc đào tạo mới bằng cách xử lý dữ liệu với tham số modelType được đặt thành heterogeneous, sau đó đào tạo mô hình của bạn với tham số modelName được đặt thành rgcn xem tại đây để biết thêm chi tiết. Khi đã xong, hãy gọi cho get_mapping và get_embeddings các chức năng để tải xuống mới của bạn map.info và thực thể.npy các tập tin. Sau khi bạn có thực thể và tệp ánh xạ, quá trình tạo tệp CSV giống hệt nhau.
Cuối cùng, tải các phần nhúng của bạn lên vị trí Amazon S3 mong muốn:
Hãy chắc chắn rằng bạn nhớ vị trí S3 này, bạn sẽ cần sử dụng nó trong Phần 3.
Làm sạch
Khi bạn sử dụng xong giải pháp, hãy nhớ dọn sạch mọi tài nguyên để tránh bị tính phí liên tục.
Kết luận
Trong bài đăng này, chúng tôi đã thảo luận cách sử dụng Neptune ML để đào tạo các nhúng GNN từ dữ liệu IMDb.
Một số ứng dụng liên quan của nhúng biểu đồ tri thức là các khái niệm như tìm kiếm ngoài danh mục, đề xuất nội dung, quảng cáo được nhắm mục tiêu, dự đoán các liên kết bị thiếu, tìm kiếm chung và phân tích theo nhóm. Tìm kiếm ngoài danh mục là quá trình tìm kiếm nội dung mà bạn không sở hữu và tìm hoặc đề xuất nội dung trong danh mục của bạn gần với nội dung người dùng đã tìm kiếm nhất có thể. Chúng ta sẽ tìm hiểu sâu hơn về tìm kiếm ngoài danh mục trong Phần 3.
Về các tác giả
 Matthew Rhodes là Nhà khoa học dữ liệu, tôi làm việc trong Phòng thí nghiệm giải pháp ML của Amazon. Anh ấy chuyên xây dựng các quy trình Machine Learning liên quan đến các khái niệm như Xử lý ngôn ngữ tự nhiên và Thị giác máy tính.
Matthew Rhodes là Nhà khoa học dữ liệu, tôi làm việc trong Phòng thí nghiệm giải pháp ML của Amazon. Anh ấy chuyên xây dựng các quy trình Machine Learning liên quan đến các khái niệm như Xử lý ngôn ngữ tự nhiên và Thị giác máy tính.
 Divya Bhargavi là Nhà khoa học dữ liệu và Trưởng nhóm ngành truyền thông và giải trí tại Phòng thí nghiệm giải pháp máy học của Amazon, nơi cô giải quyết các vấn đề kinh doanh có giá trị cao cho khách hàng AWS bằng Machine Learning. Cô ấy nghiên cứu về hiểu biết hình ảnh/video, hệ thống đề xuất sơ đồ tri thức, các trường hợp sử dụng quảng cáo dự đoán.
Divya Bhargavi là Nhà khoa học dữ liệu và Trưởng nhóm ngành truyền thông và giải trí tại Phòng thí nghiệm giải pháp máy học của Amazon, nơi cô giải quyết các vấn đề kinh doanh có giá trị cao cho khách hàng AWS bằng Machine Learning. Cô ấy nghiên cứu về hiểu biết hình ảnh/video, hệ thống đề xuất sơ đồ tri thức, các trường hợp sử dụng quảng cáo dự đoán.
 Gaurav phát hành là Nhà khoa học dữ liệu tại Amazon ML Solution Lab, nơi ông làm việc với khách hàng AWS trên các ngành dọc khác nhau để đẩy nhanh việc sử dụng máy học và các dịch vụ Đám mây AWS để giải quyết các thách thức kinh doanh của họ.
Gaurav phát hành là Nhà khoa học dữ liệu tại Amazon ML Solution Lab, nơi ông làm việc với khách hàng AWS trên các ngành dọc khác nhau để đẩy nhanh việc sử dụng máy học và các dịch vụ Đám mây AWS để giải quyết các thách thức kinh doanh của họ.
 Karan Sindwani là Nhà khoa học dữ liệu tại Phòng thí nghiệm giải pháp học máy của Amazon, nơi anh xây dựng và triển khai các mô hình học sâu. Ông chuyên về lĩnh vực thị giác máy tính. Trong thời gian rảnh rỗi, anh ấy thích đi bộ đường dài.
Karan Sindwani là Nhà khoa học dữ liệu tại Phòng thí nghiệm giải pháp học máy của Amazon, nơi anh xây dựng và triển khai các mô hình học sâu. Ông chuyên về lĩnh vực thị giác máy tính. Trong thời gian rảnh rỗi, anh ấy thích đi bộ đường dài.
 Soji Adeshina là Nhà khoa học ứng dụng tại AWS, nơi ông phát triển các mô hình dựa trên mạng thần kinh đồ thị cho máy học trên các tác vụ đồ thị với các ứng dụng chống gian lận & lạm dụng, đồ thị tri thức, hệ thống đề xuất và khoa học đời sống. Trong thời gian rảnh rỗi, anh ấy thích đọc sách và nấu ăn.
Soji Adeshina là Nhà khoa học ứng dụng tại AWS, nơi ông phát triển các mô hình dựa trên mạng thần kinh đồ thị cho máy học trên các tác vụ đồ thị với các ứng dụng chống gian lận & lạm dụng, đồ thị tri thức, hệ thống đề xuất và khoa học đời sống. Trong thời gian rảnh rỗi, anh ấy thích đọc sách và nấu ăn.
 Vidya Sagar Ravipati là Người quản lý tại Phòng thí nghiệm giải pháp máy học của Amazon, nơi anh tận dụng kinh nghiệm dày dặn của mình trong các hệ thống phân tán quy mô lớn và niềm đam mê học máy của mình để giúp khách hàng AWS trên các ngành dọc khác nhau đẩy nhanh quá trình áp dụng AI và đám mây của họ.
Vidya Sagar Ravipati là Người quản lý tại Phòng thí nghiệm giải pháp máy học của Amazon, nơi anh tận dụng kinh nghiệm dày dặn của mình trong các hệ thống phân tán quy mô lớn và niềm đam mê học máy của mình để giúp khách hàng AWS trên các ngành dọc khác nhau đẩy nhanh quá trình áp dụng AI và đám mây của họ.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Giới thiệu
- lạm dụng
- đẩy nhanh tiến độ
- ngang qua
- thêm vào
- thông tin bổ sung
- Nhận con nuôi
- Quảng cáo
- Sau
- AI
- Tất cả
- cô đơn
- đàn bà gan dạ
- Phòng thí nghiệm giải pháp Amazon ML
- phân tích
- và
- các ứng dụng
- áp dụng
- Đăng Nhập
- thích hợp
- KHU VỰC
- nhân tạo
- trí tuệ nhân tạo
- AWS
- dựa
- giữa
- Tỷ
- tỷ
- Blog
- Hộp
- phòng vé
- xây dựng
- Xây dựng
- xây dựng
- kinh doanh
- cuộc gọi
- trường hợp
- trường hợp
- Danh mục hàng
- thách thức
- thay đổi
- tải
- kiểm tra
- Đóng
- đám mây
- áp dụng đám mây
- dịch vụ điện toán đám mây
- cụm
- mã
- Đội quân
- hoàn thành
- toàn diện
- máy tính
- Tầm nhìn máy tính
- máy tính
- khái niệm
- Tiến hành
- Cấu hình
- kết nối
- nội dung
- Tương ứng
- nước
- tạo
- tạo ra
- tín dụng
- tín
- khách hàng
- Cam kết của khách hàng
- khách hàng
- dữ liệu
- xử lý dữ liệu
- nhà khoa học dữ liệu
- bộ dữ liệu
- sâu
- học kĩ càng
- sâu sắc hơn
- triển khai
- chi tiết
- Phát triển
- phát triển
- dgl
- khác nhau
- phát hiện
- thảo luận
- thảo luận
- phân phối
- hệ thống phân phối
- dont
- tải về
- hay
- mới nổi
- Điểm cuối
- Tham gia
- Giải trí
- thực thể
- Môi trường
- Ether (ETH)
- ví dụ
- kinh nghiệm
- xuất khẩu
- trích xuất
- Đặc tính
- vài
- lĩnh vực
- Tập tin
- Các tập tin
- Tìm kiếm
- tìm kiếm
- dòng chảy
- theo
- tiếp theo
- định dạng
- gian lận
- từ
- Full
- chức năng
- Tổng Quát
- tạo ra
- thế hệ
- được
- Toàn cầu
- Go
- đồ thị
- đồ thị
- hands-on
- Cứng
- giúp đỡ
- hữu ích
- Thành viên ẩn danh
- cấp độ cao
- GIỜ LÀM VIỆC
- Độ đáng tin của
- Hướng dẫn
- HTML
- HTTPS
- Nhân loại
- giống hệt nhau
- xác định
- thực hiện
- thực hiện
- nâng cao
- in
- bao gồm
- Bao gồm
- Tăng lên
- chỉ số
- ngành công nghiệp
- Thông tin
- thông tin
- ví dụ
- thay vì
- Sự thông minh
- liên quan
- IT
- Việc làm
- json
- Key
- kiến thức
- phòng thí nghiệm
- Ngôn ngữ
- lớn
- quy mô lớn
- Họ
- dẫn
- học tập
- đòn bẩy
- Thư viện
- Giấy phép
- Cuộc sống
- Khoa học đời sống
- LINK
- liên kết
- địa điểm thư viện nào
- máy
- học máy
- Chủ yếu
- LÀM CHO
- giám đốc
- nhiều
- bản đồ
- lập bản đồ
- Phương tiện truyền thông
- trung bình
- Các thành viên
- Siêu dữ liệu
- triệu
- mất tích
- ML
- kiểu mẫu
- mô hình
- chi tiết
- phim
- tên
- Tự nhiên
- Xử lý ngôn ngữ tự nhiên
- Cần
- nhu cầu
- Neptune
- dựa trên mạng
- mạng
- mạng thần kinh
- Mới
- các nút
- máy tính xách tay
- Office
- đang diễn ra
- nguyên
- Nền tảng khác
- tổng thể
- riêng
- gói
- tham số
- thông số
- một phần
- niềm đam mê
- đường ống dẫn
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- có thể
- Bài đăng
- quyền lực
- -
- dự đoán
- dự đoán
- Chuẩn bị
- In
- vấn đề
- quá trình
- xử lý
- Sản phẩm
- Hồ sơ
- cho
- cung cấp
- phạm vi
- xếp hạng
- Nguyên
- Reading
- giới thiệu
- Khuyến nghị
- khuyến nghị
- đề nghị
- liên quan
- Mối quan hệ
- vẫn
- nhớ
- tẩy
- Báo cáo
- cần phải
- Thông tin
- Kết quả
- giữ
- nhà làm hiền triết
- tương tự
- KHOA HỌC
- Nhà khoa học
- Tìm kiếm
- tìm kiếm
- Loạt Sách
- dịch vụ
- DỊCH VỤ
- định
- thiết lập
- nên
- hiển thị
- giải pháp
- Giải pháp
- động SOLVE
- Giải quyết
- chuyên
- ngăn xếp
- Bắt đầu
- Trạng thái
- Bước
- Các bước
- hàng
- trình
- như vậy
- Bộ đồ
- Khảo sát
- hệ thống
- nhắm mục tiêu
- nhiệm vụ
- kỹ thuật
- Công nghệ
- Sản phẩm
- Khu vực
- cung cấp their dịch
- Thông qua
- thời gian
- trò chơi
- đến
- Train
- Hội thảo
- Chuyển đổi
- đúng
- hướng dẫn
- tv
- sự hiểu biết
- sử dụng
- ca sử dụng
- người sử dang
- Quý báu
- giá trị
- Lớn
- phiên bản
- ngành dọc
- tầm nhìn
- cách
- tuần
- Điều gì
- cái nào
- rộng
- Phạm vi rộng
- sẽ
- đang làm việc
- công trinh
- trên màn hình
- zephyrnet