Bài đăng này được đồng viết với Karthik Kondamudi và Jenny Thompson từ Stitch Fix.
Fix Stitch là dịch vụ tạo kiểu quần áo cá nhân dành cho nam giới, phụ nữ và trẻ em. Tại Stitch Fix, chúng tôi đã được hỗ trợ bởi khoa học dữ liệu kể từ khi thành lập và dựa vào nhiều công nghệ xử lý dữ liệu và hồ dữ liệu hiện đại. Trong cơ sở hạ tầng của chúng tôi, Apache Kafka đã nổi lên như một công cụ mạnh mẽ để quản lý các luồng sự kiện và hỗ trợ xử lý dữ liệu theo thời gian thực. Tại Stitch Fix, chúng tôi đã sử dụng Kafka rộng rãi như một phần cơ sở hạ tầng dữ liệu của mình để hỗ trợ các nhu cầu khác nhau trong toàn doanh nghiệp trong hơn sáu năm. Kafka đóng vai trò trung tâm trong nỗ lực của Stitch Fix nhằm cải tổ cơ sở hạ tầng phân phối sự kiện và xây dựng nền tảng tích hợp dữ liệu tự phục vụ.
Nếu bạn muốn biết thêm thông tin cơ bản về cách chúng tôi sử dụng Kafka tại Stitch Fix, vui lòng tham khảo bài đăng trên blog đã xuất bản trước đây của chúng tôi, Đưa sức mạnh của Kafka vào tay các nhà khoa học dữ liệu. Bài đăng này bao gồm nhiều thông tin hơn về các trường hợp sử dụng kinh doanh, sơ đồ kiến trúc và cơ sở hạ tầng kỹ thuật.
Trong bài đăng này, chúng tôi sẽ mô tả cách thức và lý do chúng tôi quyết định chuyển từ Kafka tự quản lý sang Amazon Managed Streaming cho Apache Kafka (Amazon MSK). Chúng ta sẽ bắt đầu với phần tổng quan về Kafka tự quản lý của chúng tôi, lý do chúng tôi chọn di chuyển sang Amazon MSK và cuối cùng là cách chúng tôi thực hiện điều đó.
- Tổng quan về cụm Kafka
- Tại sao di chuyển sang Amazon MSK
- Cách chúng tôi di chuyển sang Amazon MSK
- Vượt qua những thách thức và bài học kinh nghiệm
- Kết luận
Tổng quan về cụm Kafka
Tại Stitch Fix, chúng tôi dựa vào một số cụm Kafka khác nhau dành riêng cho các mục đích cụ thể. Điều này cho phép chúng tôi mở rộng quy mô các cụm này một cách độc lập và áp dụng SLA nghiêm ngặt hơn cũng như đảm bảo gửi thư cho mỗi cụm. Điều này cũng làm giảm rủi ro tổng thể bằng cách giảm thiểu tác động của các thay đổi và nâng cấp, đồng thời cho phép chúng tôi tách biệt và khắc phục mọi sự cố xảy ra trong một cụm duy nhất.
Cụm Kafka chính của chúng tôi đóng vai trò là xương sống của cơ sở hạ tầng dữ liệu của chúng tôi. Nó xử lý vô số chức năng quan trọng, bao gồm quản lý các sự kiện kinh doanh, hỗ trợ giao tiếp vi dịch vụ, hỗ trợ tạo tính năng cho quy trình học máy, v.v. Sự ổn định, độ tin cậy và hiệu suất của cụm này là vô cùng quan trọng đối với hoạt động của chúng tôi.
Cụm ghi nhật ký của chúng tôi đóng một vai trò quan trọng trong cơ sở hạ tầng dữ liệu của chúng tôi. Nó phục vụ như một kho lưu trữ tập trung cho các nhật ký ứng dụng khác nhau, bao gồm nhật ký máy chủ web và nhật ký máy chủ Nginx. Những nhật ký này cung cấp những hiểu biết có giá trị cho mục đích giám sát và khắc phục sự cố. Cụm ghi nhật ký đảm bảo hoạt động trơn tru và phân tích dữ liệu nhật ký hiệu quả.
Tại sao di chuyển sang Amazon MSK
Trong sáu năm qua, nhóm cơ sở hạ tầng dữ liệu của chúng tôi đã quản lý chặt chẽ các cụm Kafka của chúng tôi. Mặc dù nhóm của chúng tôi đã có được kiến thức sâu rộng trong việc duy trì Kafka, nhưng chúng tôi cũng phải đối mặt với những thách thức như triển khai luân phiên để nâng cấp phiên bản, áp dụng các bản vá hệ điều hành và chi phí vận hành tổng thể.
Tại Stitch Fix, các kỹ sư của chúng tôi phát triển mạnh mẽ trong việc tạo ra các tính năng mới và mở rộng các dịch vụ cung cấp để làm hài lòng khách hàng. Tuy nhiên, chúng tôi nhận ra rằng việc phân bổ nguồn lực đáng kể để bảo trì Kafka đang lấy đi thời gian quý báu của quá trình đổi mới. Để vượt qua thử thách này, chúng tôi đã bắt đầu tìm một nhà cung cấp dịch vụ được quản lý có thể xử lý các tác vụ bảo trì như nâng cấp và vá lỗi, đồng thời cấp cho chúng tôi toàn quyền kiểm soát các hoạt động của cụm, bao gồm quản lý phân vùng và cân bằng lại. Chúng tôi cũng đã tìm kiếm một giải pháp mở rộng quy mô dễ dàng cho dung lượng lưu trữ, giúp kiểm soát chi phí trong khi sẵn sàng đáp ứng sự tăng trưởng trong tương lai.
Sau khi đánh giá kỹ lưỡng nhiều tùy chọn, chúng tôi đã tìm thấy sự kết hợp hoàn hảo ở Amazon MSK vì nó cho phép chúng tôi chuyển việc bảo trì cụm cho các kỹ sư Amazon có tay nghề cao. Với Amazon MSK đã sẵn sàng, giờ đây các nhóm của chúng tôi có thể tập trung năng lượng vào việc phát triển các ứng dụng cải tiến độc đáo và có giá trị cho Stitch Fix, thay vì bị cuốn vào các nhiệm vụ quản trị Kafka.
Amazon MSK hợp lý hóa quy trình, loại bỏ nhu cầu cấu hình thủ công, cài đặt phần mềm bổ sung và lo lắng về việc mở rộng quy mô. Nó chỉ đơn giản là có tác dụng, cho phép chúng tôi tập trung vào việc mang lại giá trị đặc biệt cho những khách hàng thân yêu của mình.
Cách chúng tôi di chuyển sang Amazon MSK
Trong khi lập kế hoạch di chuyển, chúng tôi mong muốn chuyển đổi từng dịch vụ cụ thể sang Amazon MSK mà không có thời gian ngừng hoạt động, đảm bảo rằng mỗi lần chỉ có một tập hợp con dịch vụ cụ thể được di chuyển. Cơ sở hạ tầng tổng thể sẽ chạy trong môi trường kết hợp trong đó một số dịch vụ kết nối với Amazon MSK và các dịch vụ khác với cơ sở hạ tầng Kafka hiện có.
Chúng tôi quyết định bắt đầu di chuyển với cụm ghi nhật ký ít quan trọng hơn trước, sau đó tiến hành di chuyển cụm chính. Mặc dù nhật ký rất cần thiết cho mục đích giám sát và khắc phục sự cố nhưng chúng có tầm quan trọng tương đối ít hơn đối với các hoạt động kinh doanh cốt lõi. Ngoài ra, số lượng cũng như loại người tiêu dùng và nhà sản xuất cho cụm ghi nhật ký nhỏ hơn, khiến việc bắt đầu trở thành lựa chọn dễ dàng hơn. Sau đó, chúng tôi có thể áp dụng những kiến thức đã học được từ quá trình di chuyển cụm ghi nhật ký vào cụm chính. Sự lựa chọn có chủ ý này cho phép chúng tôi thực hiện quá trình di chuyển một cách có kiểm soát, giảm thiểu mọi gián đoạn tiềm ẩn đối với các hệ thống quan trọng của chúng tôi.
Trong những năm qua, đội ngũ cơ sở hạ tầng dữ liệu giàu kinh nghiệm của chúng tôi đã đã sử dụng Apache Kafka MirrorMaker 2 (MM2) để sao chép dữ liệu giữa các cụm Kafka khác nhau. Hiện tại, chúng tôi dựa vào MM2 để sao chép dữ liệu từ hai cụm Kafka sản xuất khác nhau. Với thành tích đã được chứng minh trong tổ chức của mình, chúng tôi đã quyết định sử dụng MM2 làm công cụ chính cho quá trình di chuyển dữ liệu của mình.
Hướng dẫn chung cho MM2 như sau:
- Bắt đầu với các ứng dụng ít quan trọng hơn.
- Thực hiện di chuyển tích cực.
- Làm quen với các phương pháp thực hành chính tốt nhất cho MM2.
- Thực hiện giám sát để xác nhận việc di chuyển.
- Tích lũy những hiểu biết cần thiết để di chuyển các ứng dụng khác.
MM2 cung cấp các tùy chọn triển khai linh hoạt, cho phép nó hoạt động như một cụm độc lập hoặc được nhúng trong cụm Kafka Connect hiện có. Đối với dự án di chuyển của mình, chúng tôi đã triển khai cụm Kafka Connect chuyên dụng hoạt động ở chế độ phân tán.
Thiết lập này cung cấp khả năng mở rộng mà chúng tôi cần, cho phép chúng tôi dễ dàng mở rộng cụm độc lập nếu cần. Tùy thuộc vào các trường hợp sử dụng cụ thể như khoảng cách địa lý, tính sẵn sàng cao (HA) hoặc di chuyển, MM2 có thể được định cấu hình để sao chép chủ động-chủ động, sao chép chủ động-thụ động hoặc cả hai. Trong trường hợp của chúng tôi, khi di chuyển từ Kafka tự quản lý sang Amazon MSK, chúng tôi đã chọn cấu hình chủ động-thụ động, trong đó MirrorMaker được sử dụng cho mục đích di chuyển và sau đó chuyển sang chế độ ngoại tuyến sau khi hoàn thành.
Chính sách sao chép và cấu hình MirrorMaker
Theo mặc định, MirrorMaker đổi tên các chủ đề sao chép bằng cách thêm tiền tố tên của cụm Kafka nguồn vào cụm đích. Ví dụ: nếu chúng tôi sao chép chủ đề A từ cụm nguồn “hiện có” sang cụm mới “newkafka”, thì chủ đề được sao chép sẽ được đặt tên là “hiện có.A” trong “newkafka”. Tuy nhiên, hành vi mặc định này có thể được sửa đổi để duy trì tên chủ đề nhất quán trong cụm MSK mới được tạo.
Để duy trì các tên chủ đề nhất quán trong cụm MSK mới được tạo và tránh các vấn đề tiếp theo, chúng tôi đã sử dụng Chính sách sao chép tùy chỉnh jar do AWS cung cấp. Bình này, được bao gồm trong thiết lập MirrorMaker của chúng tôi, cho phép chúng tôi sao chép các chủ đề có tên giống hệt nhau trong cụm MSK. Ngoài ra, chúng tôi đã sử dụng MirrorCheckpointConnector để đồng bộ hóa các khoản bù đắp cho người tiêu dùng từ cụm nguồn đến cụm đích và MirrorHeartbeatConnector để đảm bảo khả năng kết nối giữa các cụm.
Giám sát và đo lường
MirrorMaker được trang bị các số liệu tích hợp để theo dõi độ trễ sao chép và các thông số cần thiết khác. Chúng tôi đã tích hợp các số liệu này vào thiết lập MirrorMaker của mình, xuất chúng sang Grafana để trực quan hóa. Vì chúng tôi đang sử dụng Grafana để giám sát các hệ thống khác nên chúng tôi cũng quyết định sử dụng nó trong quá trình di chuyển. Điều này cho phép chúng tôi giám sát chặt chẽ trạng thái sao chép trong quá trình di chuyển. Các số liệu cụ thể mà chúng tôi theo dõi sẽ được mô tả chi tiết hơn bên dưới.
Ngoài ra, chúng tôi đã giám sát MirrorCheckpointConnector đi kèm với MirrorMaker vì nó phát ra các điểm kiểm tra trong cụm đích theo định kỳ. Các điểm kiểm tra này chứa các khoản chênh lệch cho từng nhóm người tiêu dùng trong cụm nguồn, đảm bảo đồng bộ hóa liền mạch giữa các cụm.
Bố trí mạng
Tại Stitch Fix, chúng tôi sử dụng một số đám mây riêng ảo (VPC) thông qua Amazon Virtual Private Cloud (Amazon VPC) để cách ly môi trường trong mỗi tài khoản AWS của chúng tôi. Chúng tôi đã sử dụng các VPC sản xuất và dàn dựng riêng biệt kể từ khi bắt đầu sử dụng AWS. Khi cần thiết, việc ngang hàng các VPC trên các tài khoản sẽ được xử lý thông qua AWS Transit Gateway. Để duy trì sự tách biệt mạnh mẽ giữa các môi trường mà chúng tôi đã sử dụng từ trước đến nay, chúng tôi đã tạo các cụm MSK riêng biệt trong các VPC tương ứng của chúng cho môi trường sản xuất và chạy thử.
Lưu ý bên lề: Giờ đây, việc kết nối nhanh chóng các máy khách Kafka được lưu trữ trên các đám mây riêng ảo khác nhau với các đám mây được công bố gần đây sẽ dễ dàng hơn Kết nối riêng tư đa VPC của Amazon MSK, không có sẵn tại thời điểm chúng tôi di chuyển.
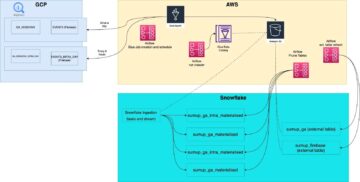
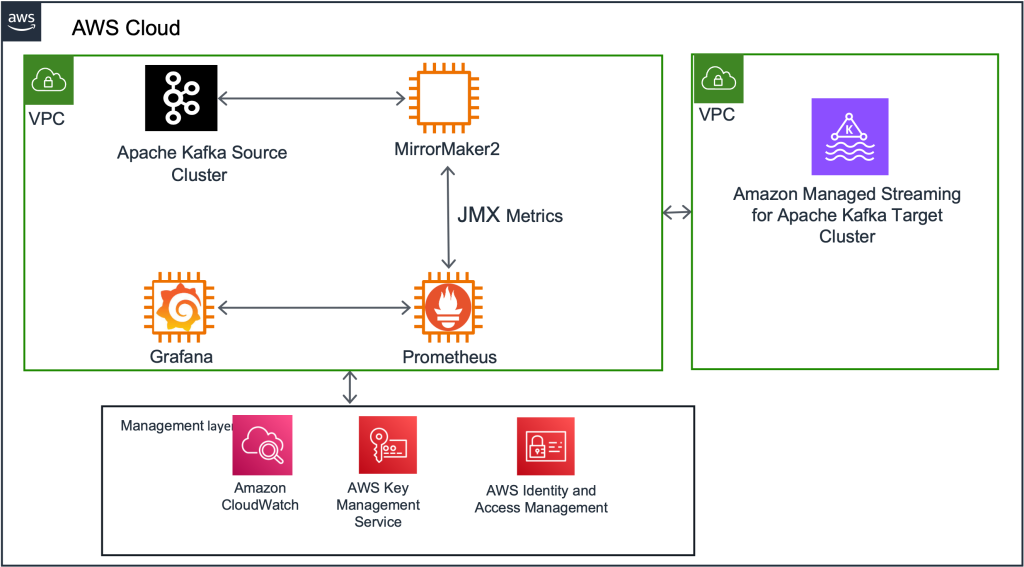
Các bước di chuyển: Tổng quan cấp cao
Trong phần này, chúng tôi phác thảo chuỗi sự kiện cấp cao cho quá trình di chuyển.
![]()
Thiết lập Kafka Connect và triển khai MM2
Đầu tiên, chúng tôi đã triển khai cụm Kafka Connect mới trên cụm Amazon Elastic Computing Cloud (Amazon EC2) làm trung gian giữa cụm Kafka hiện tại và cụm MSK mới. Tiếp theo, chúng tôi đã triển khai 3 trình kết nối MirrorMaker vào cụm Kafka Connect này. Ban đầu, cụm này được định cấu hình để phản ánh tất cả các chủ đề hiện có và cấu hình của chúng vào cụm MSK đích. (Cuối cùng, chúng tôi đã thay đổi cấu hình này để chi tiết hơn, như được mô tả trong phần “Điều hướng những thách thức và bài học kinh nghiệm” bên dưới.)
Theo dõi tiến trình sao chép bằng số liệu MM
Tận dụng các số liệu JMX do MirrorMaker cung cấp để theo dõi tiến trình sao chép dữ liệu. Ngoài các số liệu toàn diện, chúng tôi chủ yếu tập trung vào các số liệu chính, cụ thể là sao chép-độ trễ-ms và điểm kiểm tra-độ trễ-ms. Các số liệu này cung cấp những hiểu biết vô giá về trạng thái sao chép, bao gồm các khía cạnh quan trọng như độ trễ sao chép và độ trễ điểm kiểm tra. Bằng cách xuất liền mạch các số liệu này sang Grafana, bạn có được khả năng trực quan hóa và theo dõi chặt chẽ tiến trình sao chép, đảm bảo MirrorMaker tái tạo thành công cả dữ liệu lịch sử và dữ liệu mới.
Đánh giá số liệu sử dụng và cung cấp
Phân tích số liệu sử dụng của cụm MSK mới để đảm bảo cung cấp phù hợp. Xem xét các yếu tố như lưu trữ, thông lượng và hiệu suất. Nếu được yêu cầu, hãy thay đổi kích thước cụm để đáp ứng các kiểu sử dụng được quan sát. Mặc dù việc thay đổi kích thước có thể khiến quá trình di chuyển tốn thêm thời gian nhưng đây là biện pháp tiết kiệm chi phí về lâu dài.
Đồng bộ hóa khoản bù đắp của người tiêu dùng giữa các cụm nguồn và mục tiêu
Đảm bảo rằng khoản bù đắp cho người tiêu dùng được đồng bộ hóa giữa cụm nguồn nội bộ và cụm MSK đích. Sau khi đồng bộ hóa các khoản bù đắp cho người tiêu dùng, hãy chuyển hướng người tiêu dùng của cụm nội bộ hiện có để sử dụng dữ liệu từ cụm MSK mới. Bước này đảm bảo quá trình chuyển đổi liền mạch cho người tiêu dùng và cho phép luồng dữ liệu không bị gián đoạn trong quá trình di chuyển.
Cập nhật ứng dụng của nhà sản xuất
Sau khi xác nhận rằng tất cả người tiêu dùng đang sử dụng thành công dữ liệu từ cụm MSK mới, hãy cập nhật ứng dụng của nhà sản xuất để ghi dữ liệu trực tiếp vào cụm mới. Bước cuối cùng này hoàn tất quá trình di chuyển, đảm bảo rằng tất cả dữ liệu hiện đang được ghi vào cụm MSK mới và tận dụng tối đa các khả năng của nó.
Vượt qua những thách thức và bài học kinh nghiệm
Trong quá trình di chuyển, chúng tôi đã gặp phải ba thách thức cần được chú ý cẩn thận: bộ nhớ có thể mở rộng, cấu hình cấu hình sao chép chi tiết hơn và phân bổ bộ nhớ.
Ban đầu, chúng tôi gặp phải vấn đề với việc tự động mở rộng quy mô bộ lưu trữ Amazon MSK. Chúng tôi đã biết rằng việc tự động mở rộng quy mô bộ nhớ cần có khoảng thời gian chờ 24 giờ trước khi một sự kiện mở rộng quy mô khác có thể xảy ra. Chúng tôi đã quan sát thấy điều này khi di chuyển cụm ghi nhật ký và chúng tôi đã áp dụng những bài học rút ra từ điều này cũng như tính đến giai đoạn tạm dừng trong quá trình di chuyển cụm sản xuất.
Ngoài ra, để tối ưu hóa tốc độ sao chép MirrorMaker, chúng tôi đã cập nhật cấu hình ban đầu để chia công việc sao chép thành các đợt dựa trên khối lượng và phân bổ nhiều nhiệm vụ hơn cho các chủ đề có khối lượng lớn.
Trong giai đoạn đầu, chúng tôi đã bắt đầu sao chép bằng cách sử dụng một trình kết nối duy nhất để chuyển tất cả các chủ đề từ cụm nguồn sang cụm đích, bao gồm một số lượng đáng kể các nhiệm vụ. Tuy nhiên, chúng tôi gặp phải những thách thức như tăng độ trễ sao chép đối với các chủ đề có khối lượng lớn và sao chép chậm hơn đối với các chủ đề cụ thể. Sau khi kiểm tra cẩn thận các số liệu, chúng tôi đã áp dụng một cách tiếp cận khác bằng cách tách các chủ đề có số lượng lớn thành nhiều trình kết nối. Về bản chất, chúng tôi chia các chủ đề thành các loại âm lượng cao, trung bình và thấp, gán chúng cho các trình kết nối tương ứng và điều chỉnh số lượng tác vụ dựa trên độ trễ sao chép. Sự điều chỉnh chiến lược này mang lại kết quả tích cực, cho phép chúng tôi sao chép dữ liệu nhanh hơn và hiệu quả hơn trên diện rộng.
Cuối cùng, chúng tôi đã gặp phải tình trạng cạn kiệt bộ nhớ heap của máy ảo Java, dẫn đến thiếu số liệu khi chạy bản sao MirrorMaker. Để giải quyết vấn đề này, chúng tôi đã tăng mức phân bổ bộ nhớ và khởi động lại quy trình MirrorMaker.
Kết luận
Việc Stitch Fix chuyển từ Kafka tự quản lý sang Amazon MSK đã cho phép chúng tôi chuyển trọng tâm từ nhiệm vụ bảo trì sang mang lại giá trị cho khách hàng. Nó đã giảm 40% chi phí cơ sở hạ tầng của chúng tôi và mang lại cho chúng tôi niềm tin rằng chúng tôi có thể dễ dàng mở rộng quy mô các cụm trong tương lai nếu cần. Bằng cách lập kế hoạch di chuyển một cách chiến lược và sử dụng Apache Kafka MirrorMaker, chúng tôi đã đạt được quá trình chuyển đổi liền mạch trong khi vẫn đảm bảo tính sẵn sàng cao. Việc tích hợp giám sát và số liệu đã cung cấp những hiểu biết có giá trị trong quá trình di chuyển và Stitch Fix đã vượt qua thành công các thách thức trong quá trình di chuyển. Việc di chuyển sang Amazon MSK đã giúp Stitch Fix tối đa hóa khả năng của Kafka, đồng thời hưởng lợi từ chuyên môn của các kỹ sư Amazon, tạo tiền đề cho sự phát triển và đổi mới liên tục.
Đọc thêm
Về các tác giả
![]() Karthik Kondamudi là Giám đốc Kỹ thuật trong Nhóm Nền tảng Dữ liệu và ML tại StitchFix. Mối quan tâm của anh nằm ở Hệ thống phân tán và xử lý dữ liệu quy mô lớn. Ngoài công việc, anh thích dành thời gian cho gia đình và đi bộ đường dài. Là một người yêu chó, anh ấy cũng đam mê thể thao, đặc biệt là môn cricket, quần vợt và bóng đá.
Karthik Kondamudi là Giám đốc Kỹ thuật trong Nhóm Nền tảng Dữ liệu và ML tại StitchFix. Mối quan tâm của anh nằm ở Hệ thống phân tán và xử lý dữ liệu quy mô lớn. Ngoài công việc, anh thích dành thời gian cho gia đình và đi bộ đường dài. Là một người yêu chó, anh ấy cũng đam mê thể thao, đặc biệt là môn cricket, quần vợt và bóng đá.
![]() Jenny thompson là Kỹ sư nền tảng dữ liệu tại Stitch Fix. Cô làm việc trên nhiều hệ thống khác nhau dành cho Nhà khoa học dữ liệu và thích làm cho mọi thứ trở nên sạch sẽ, đơn giản và dễ sử dụng. Cô ấy cũng thích làm bánh kếp và bánh Pavlova, tìm kiếm đồ nội thất trên Craigslist và hứng chịu mưa khi đi dã ngoại.
Jenny thompson là Kỹ sư nền tảng dữ liệu tại Stitch Fix. Cô làm việc trên nhiều hệ thống khác nhau dành cho Nhà khoa học dữ liệu và thích làm cho mọi thứ trở nên sạch sẽ, đơn giản và dễ sử dụng. Cô ấy cũng thích làm bánh kếp và bánh Pavlova, tìm kiếm đồ nội thất trên Craigslist và hứng chịu mưa khi đi dã ngoại.
![]() Rahul Nammireddy là Kiến trúc sư giải pháp cấp cao tại AWS, tập trung vào việc hướng dẫn khách hàng gốc kỹ thuật số thông qua quá trình chuyển đổi gốc trên nền tảng đám mây của họ. Với niềm đam mê công nghệ AI/ML, anh làm việc với khách hàng trong các ngành như bán lẻ và viễn thông, giúp họ đổi mới với tốc độ nhanh chóng. Trong suốt hơn 23 năm sự nghiệp của mình, Rahul đã giữ các vai trò lãnh đạo kỹ thuật quan trọng ở nhiều công ty khác nhau, từ các công ty khởi nghiệp đến các tổ chức niêm yết đại chúng, thể hiện chuyên môn của mình với tư cách là người xây dựng và thúc đẩy sự đổi mới. Trong thời gian rảnh rỗi, anh ấy thích xem bóng đá và chơi cricket.
Rahul Nammireddy là Kiến trúc sư giải pháp cấp cao tại AWS, tập trung vào việc hướng dẫn khách hàng gốc kỹ thuật số thông qua quá trình chuyển đổi gốc trên nền tảng đám mây của họ. Với niềm đam mê công nghệ AI/ML, anh làm việc với khách hàng trong các ngành như bán lẻ và viễn thông, giúp họ đổi mới với tốc độ nhanh chóng. Trong suốt hơn 23 năm sự nghiệp của mình, Rahul đã giữ các vai trò lãnh đạo kỹ thuật quan trọng ở nhiều công ty khác nhau, từ các công ty khởi nghiệp đến các tổ chức niêm yết đại chúng, thể hiện chuyên môn của mình với tư cách là người xây dựng và thúc đẩy sự đổi mới. Trong thời gian rảnh rỗi, anh ấy thích xem bóng đá và chơi cricket.
![]() Todd McGrath là chuyên gia truyền dữ liệu tại Amazon Web Services, nơi ông tư vấn cho khách hàng về chiến lược truyền dữ liệu, tích hợp, kiến trúc và giải pháp của họ. Về mặt cá nhân, anh ấy thích theo dõi và hỗ trợ 3 thanh thiếu niên của mình trong các hoạt động ưa thích của chúng cũng như theo đuổi các sở thích của riêng anh ấy như câu cá, ném bóng, khúc côn cầu trên băng và giờ vui vẻ với bạn bè và gia đình trên thuyền phao. Kết nối với anh ấy trên LinkedIn.
Todd McGrath là chuyên gia truyền dữ liệu tại Amazon Web Services, nơi ông tư vấn cho khách hàng về chiến lược truyền dữ liệu, tích hợp, kiến trúc và giải pháp của họ. Về mặt cá nhân, anh ấy thích theo dõi và hỗ trợ 3 thanh thiếu niên của mình trong các hoạt động ưa thích của chúng cũng như theo đuổi các sở thích của riêng anh ấy như câu cá, ném bóng, khúc côn cầu trên băng và giờ vui vẻ với bạn bè và gia đình trên thuyền phao. Kết nối với anh ấy trên LinkedIn.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/stitch-fix-seamless-migration-transitioning-from-self-managed-kafka-to-amazon-msk/
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 100
- 40
- a
- có khả năng
- Có khả năng
- Giới thiệu
- chứa
- Trợ Lý Giám Đốc
- Đạt được
- đạt được
- mua lại
- ngang qua
- hoạt động
- hoạt động
- Ngoài ra
- thêm vào
- Ngoài ra
- địa chỉ
- điều chỉnh
- Điều chỉnh
- quản lý
- con nuôi
- Lợi thế
- AI / ML
- Tất cả
- phân bổ
- phân bổ
- cho phép
- Cho phép
- cho phép
- dọc theo
- Ngoài ra
- thay thế
- Mặc dù
- đàn bà gan dạ
- Amazon EC2
- Amazon Web Services
- an
- phân tích
- và
- công bố
- Một
- bất kì
- Apache
- Kafka Apache
- Các Ứng Dụng
- các ứng dụng
- áp dụng
- Đăng Nhập
- Nộp đơn
- phương pháp tiếp cận
- kiến trúc
- LÀ
- AS
- các khía cạnh
- At
- sự chú ý
- tự động
- sẵn có
- có sẵn
- tránh
- xa
- AWS
- Xương sống
- lý lịch
- dựa
- BE
- bởi vì
- được
- trước
- hành vi
- được
- phía dưới
- hưởng lợi
- BEST
- thực hành tốt nhất
- giữa
- Ngoài
- Blog
- bảng
- cả hai
- Duyệt
- xây dựng
- xây dựng
- được xây dựng trong
- kinh doanh
- hoạt động kinh doanh
- by
- CAN
- khả năng
- Tuyển Dụng
- cẩn thận
- trường hợp
- trường hợp
- đố
- bị bắt
- trung tâm
- tập trung
- thách thức
- thách thức
- thay đổi
- Những thay đổi
- kiểm tra
- sự lựa chọn
- chọn
- khách hàng
- chặt chẽ
- Quần áo
- đám mây
- Mây bản địa
- cụm
- đến
- Giao tiếp
- Các công ty
- hoàn thành
- Hoàn thành
- hoàn thành
- toàn diện
- Tính
- tập trung
- sự tự tin
- Cấu hình
- cấu hình
- cấu hình
- Kết nối
- Kết nối
- Hãy xem xét
- thích hợp
- ăn
- người tiêu dùng
- Người tiêu dùng
- chứa
- tiếp tục
- điều khiển
- kiểm soát
- Trung tâm
- chi phí-hiệu quả
- Chi phí
- có thể
- tạo ra
- Tạo
- dế
- quan trọng
- quan trọng
- Hiện nay
- khách hàng
- dữ liệu
- cơ sở hạ tầng dữ liệu
- tích hợp dữ liệu
- Hồ dữ liệu
- Nền tảng dữ liệu
- xử lý dữ liệu
- khoa học dữ liệu
- quyết định
- dành riêng
- Mặc định
- hân hoan
- phân phối
- giao hàng
- Tùy
- triển khai
- triển khai
- triển khai
- mô tả
- mô tả
- mong muốn
- điểm đến
- chi tiết
- phát triển
- sơ đồ
- ĐÃ LÀM
- khác nhau
- kỹ thuật số
- siêng năng
- trực tiếp
- sự gián đoạn
- phân phối
- hệ thống phân phối
- khác nhau
- phân chia
- Chia
- Dog
- thời gian chết
- lái xe
- suốt trong
- mỗi
- dễ dàng hơn
- dễ dàng
- dễ dàng
- hiệu quả
- nỗ lực
- những nỗ lực
- loại bỏ
- nhúng
- xuất hiện
- trao quyền
- kích hoạt
- cho phép
- bao trùm
- năng lượng
- ky sư
- Kỹ Sư
- Kỹ sư
- đảm bảo
- đảm bảo
- đảm bảo
- Môi trường
- môi trường
- đã trang bị
- bản chất
- thiết yếu
- Ether (ETH)
- đánh giá
- Sự kiện
- sự kiện
- cuối cùng
- kiểm tra
- đặc biệt
- thi hành
- hiện tại
- Mở rộng
- mở rộng
- kinh nghiệm
- chuyên môn
- mở rộng
- rộng rãi
- phải đối mặt
- tạo điều kiện
- nhân tố
- các yếu tố
- gia đình
- nhanh hơn
- Đặc tính
- Tính năng
- cuối cùng
- Tìm kiếm
- Tên
- Đánh bắt cá
- Sửa chữa
- linh hoạt
- dòng chảy
- Tập trung
- tập trung
- tiếp theo
- sau
- Bóng đá
- Trong
- Dành cho người tiêu dùng
- tìm thấy
- Nền tảng
- bạn bè
- từ
- Full
- chức năng
- chức năng
- tương lai
- tăng trưởng trong tương lai
- Thu được
- cửa ngõ
- Tổng Quát
- thế hệ
- nhận được
- được
- cấp
- Nhóm
- Tăng trưởng
- bảo đảm
- hướng dẫn
- xử lý
- xử lý
- Xử lý
- Tay bài
- vui mừng
- Có
- he
- Được tổ chức
- giúp đỡ
- Cao
- cấp độ cao
- cao
- đi bộ đường dài
- anh ta
- của mình
- lịch sử
- tổ chức
- tổ chức
- giờ
- Độ đáng tin của
- Tuy nhiên
- HTML
- HTTPS
- Hỗn hợp
- ICE
- giống hệt nhau
- if
- Va chạm
- tầm quan trọng
- in
- bao gồm
- bao gồm
- Bao gồm
- tăng
- tăng
- độc lập
- Cá nhân
- các ngành công nghiệp
- thông tin
- Cơ sở hạ tầng
- ban đầu
- ban đầu
- khởi xướng
- đổi mới
- sự đổi mới
- sáng tạo
- những hiểu biết
- ví dụ
- thay vì
- tích hợp
- hội nhập
- lợi ích
- người Trung gian
- trong
- giới thiệu
- vô giá
- cô lập
- các vấn đề
- IT
- ITS
- Java
- việc làm
- jpg
- Kafka
- giữ
- Key
- trẻ em
- Biết
- kiến thức
- hồ
- quy mô lớn
- Độ trễ
- Lãnh đạo
- học
- học tập
- ít
- Bài học
- nói dối
- Lượt thích
- Lượt thích
- Liệt kê
- đăng nhập
- khai thác gỗ
- dài
- Thấp
- máy
- học máy
- Chủ yếu
- duy trì
- duy trì
- bảo trì
- Làm
- quản lý
- quản lý
- giám đốc
- quản lý
- cách thức
- nhãn hiệu
- nhiều
- Trận đấu
- Tối đa hóa
- Có thể..
- đo
- trung bình
- Gặp gỡ
- Bộ nhớ
- Dành cho Nam
- tin nhắn
- Metrics
- di chuyển
- di cư
- di cư
- di cư
- giảm thiểu
- gương
- mất tích
- ML
- Chế độ
- hiện đại
- sửa đổi
- Màn Hình
- theo dõi
- giám sát
- chi tiết
- hiệu quả hơn
- nhiều
- nhiều
- nhiều
- tên
- Được đặt theo tên
- cụ thể là
- tên
- tự nhiên
- cần thiết
- Cần
- cần thiết
- nhu cầu
- Mới
- Các tính năng mới
- mới
- tiếp theo
- nginx
- Không
- ghi
- tại
- con số
- quan sát
- xảy ra
- of
- cung cấp
- Cung cấp
- Cung cấp
- Ngoại tuyến
- bù đắp
- on
- hàng loạt
- có thể
- hoạt động
- hoạt động
- Hoạt động
- Tối ưu hóa
- Các lựa chọn
- or
- cơ quan
- tổ chức
- nguyên
- OS
- Nền tảng khác
- Khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- ra
- kết quả
- đề cương
- kết thúc
- tổng thể
- Vượt qua
- Đại tu
- tổng quan
- riêng
- Hòa bình
- thông số
- một phần
- đặc biệt
- niềm đam mê
- đam mê
- qua
- Các bản vá lỗi
- Vá
- mô hình
- mỗi
- phần trăm
- hoàn hảo
- hiệu suất
- thời gian
- riêng
- Cá nhân
- giai đoạn
- Nơi
- lập kế hoạch
- nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- chơi
- đóng
- xin vui lòng
- tích cực
- Bài đăng
- tiềm năng
- quyền lực
- -
- mạnh mẽ
- thực hành
- Quí
- ưa thích
- trước đây
- chủ yếu
- chính
- riêng
- tiến hành
- quá trình
- xử lý
- sản xuất
- Các nhà sản xuất
- Sản lượng
- Tiến độ
- dự án
- đúng
- đã được chứng minh
- cho
- cung cấp
- nhà cung cấp dịch vụ
- công khai
- niêm yết công khai
- công bố
- mục đích
- Đặt
- Mau
- phạm vi
- nhanh
- sẵn sàng
- thời gian thực
- dữ liệu theo thời gian thực
- tái cân bằng
- gần đây
- công nhận
- ghi
- chuyển hướng
- Giảm
- làm giảm
- xem
- tương đối
- độ tin cậy
- dựa
- nhân rộng
- nhân rộng
- kho
- sinh sản
- cần phải
- đòi hỏi
- Thông tin
- mà
- khởi động lại
- kết quả
- bán lẻ
- Nguy cơ
- Vai trò
- vai trò
- Lăn
- chạy
- chạy
- khả năng mở rộng
- khả năng mở rộng
- Quy mô
- mở rộng quy mô
- Giải pháp chia tỷ lệ
- Khoa học
- các nhà khoa học
- liền mạch
- liền mạch
- Phần
- Tự phục vụ
- cao cấp
- riêng biệt
- Trình tự
- máy chủ
- phục vụ
- dịch vụ
- Nhà cung cấp dịch vụ
- DỊCH VỤ
- định
- thiết lập
- thiết lập
- một số
- chị ấy
- thay đổi
- giới th
- bên
- ý nghĩa
- có ý nghĩa
- Đơn giản
- đơn giản
- kể từ khi
- duy nhất
- Six
- lành nghề
- nhỏ hơn
- trơn tru
- Phần mềm
- giải pháp
- Giải pháp
- một số
- tìm kiếm
- nguồn
- chuyên gia
- riêng
- tốc độ
- Chi
- Thể thao
- Tính ổn định
- Traineeship
- dàn dựng
- độc lập
- Bắt đầu
- bắt đầu
- Startups
- Trạng thái
- Bước
- Các bước
- là gắn
- Chiến lược
- Chiến lược
- chiến lược
- trực tuyến
- dòng
- mạnh mẽ
- Sau đó
- thành công
- Thành công
- như vậy
- hỗ trợ
- Hỗ trợ
- Công tắc điện
- đồng bộ hóa
- hệ thống
- Lấy
- dùng
- Mục tiêu
- nhiệm vụ
- nhóm
- đội
- Kỹ thuật
- Công nghệ
- thanh thiếu niên
- viễn thông
- quần vợt
- việc này
- Sản phẩm
- Tương lai
- Nguồn
- cung cấp their dịch
- Them
- sau đó
- Kia là
- họ
- điều
- điều này
- thompson
- số ba
- Phát triển mạnh
- Thông qua
- khắp
- thông lượng
- thời gian
- đến
- công cụ
- chủ đề
- Chủ đề
- theo dõi
- Hồ sơ theo dõi
- chuyển
- Chuyển đổi
- quá cảnh
- quá trình chuyển đổi
- chuyển đổi
- hai
- loại
- Cuối cùng
- độc đáo
- Cập nhật
- cập nhật
- nâng cấp
- trên
- us
- Sử dụng
- sử dụng
- đã sử dụng
- sử dụng
- tận dụng
- HIỆU LỰC
- Quý báu
- giá trị
- nhiều
- khác nhau
- phiên bản
- ảo
- máy ảo
- hình dung
- hình dung
- quan trọng
- khối lượng
- khối lượng
- là
- xem
- Đường..
- we
- web
- máy chủ web
- các dịch vụ web
- TỐT
- là
- khi nào
- cái nào
- trong khi
- tại sao
- sẽ
- với
- ở trong
- Dành cho Nữ
- Công việc
- Luồng công việc
- công trinh
- sẽ
- viết
- viết
- năm
- mang lại
- bạn
- mình
- zephyrnet