Bruce Warrington thông qua Unsplash
Lý do khiến các mô hình học máy nói chung trở nên thông minh hơn là do chúng phụ thuộc vào việc sử dụng dữ liệu được gắn nhãn để giúp chúng phân biệt giữa hai đối tượng tương tự.
Tuy nhiên, nếu không có các bộ dữ liệu được gắn nhãn này, bạn sẽ gặp phải những trở ngại lớn khi tạo mô hình học máy hiệu quả và đáng tin cậy nhất. Các bộ dữ liệu được gắn nhãn trong giai đoạn đào tạo của một mô hình rất quan trọng.
Học sâu đã được sử dụng rộng rãi để giải quyết các nhiệm vụ như Thị giác máy tính bằng cách sử dụng học có giám sát. Tuy nhiên, cũng như nhiều thứ trong cuộc sống, nó đi kèm với những hạn chế. Phân loại được giám sát yêu cầu số lượng và chất lượng cao của dữ liệu đào tạo được gắn nhãn để tạo ra một mô hình mạnh mẽ. Điều này có nghĩa là mô hình phân loại không thể xử lý các lớp không nhìn thấy.
Và tất cả chúng ta đều biết cần bao nhiêu sức mạnh tính toán, đào tạo lại, thời gian và tiền bạc để đào tạo một mô hình học sâu.
Nhưng một mô hình vẫn có thể phân biệt giữa hai đối tượng mà không cần sử dụng dữ liệu huấn luyện? Vâng, nó được gọi là học tập không bắn. Zero-shot learning là khả năng của một mô hình để có thể hoàn thành một nhiệm vụ mà không cần nhận hoặc sử dụng bất kỳ ví dụ đào tạo nào.
Con người có khả năng tự học một cách tự nhiên mà không cần phải nỗ lực nhiều. Bộ não của chúng ta đã lưu trữ từ điển và cho phép chúng ta phân biệt các đối tượng bằng cách xem xét các đặc tính vật lý của chúng nhờ vào cơ sở kiến thức hiện tại của chúng ta. Chúng ta có thể sử dụng cơ sở tri thức này để thấy sự giống và khác nhau giữa các đối tượng và tìm ra mối liên hệ giữa chúng.
Ví dụ: giả sử chúng ta đang cố gắng xây dựng một mô hình phân loại trên các loài động vật. Dựa theo Thế giới của chúng tôiInData, tính đến năm 2.13 đã có 2021 triệu loài. Do đó, nếu muốn tạo ra mô hình phân loại hiệu quả nhất cho các loài động vật, chúng ta sẽ cần đến 2.13 triệu lớp khác nhau. Cũng cần thiết sẽ có rất nhiều dữ liệu. Số lượng và chất lượng dữ liệu cao là khó khăn để đi qua.
Vậy cách học zero-shot giải quyết vấn đề này như thế nào?
Bởi vì phương pháp học zero-shot không yêu cầu mô hình phải học dữ liệu huấn luyện và cách phân loại các lớp, nên nó cho phép chúng tôi ít phụ thuộc vào nhu cầu của mô hình đối với dữ liệu được dán nhãn.
Sau đây là những gì dữ liệu của bạn sẽ cần bao gồm để tiến hành học tập không cần bắn.
Các lớp đã xem
Điều này bao gồm các lớp dữ liệu đã được sử dụng trước đây để huấn luyện một mô hình.
Lớp học không nhìn thấy
Điều này bao gồm các lớp dữ liệu KHÔNG được sử dụng để đào tạo một mô hình và mô hình học tập không bắn mới sẽ khái quát hóa.
Thông tin phụ trợ
Vì dữ liệu trong các lớp không nhìn thấy không được gắn nhãn, nên việc học trực tiếp sẽ yêu cầu thông tin phụ trợ để học và tìm các mối tương quan, liên kết và thuộc tính. Điều này có thể ở dạng nhúng từ, mô tả và thông tin ngữ nghĩa.
Phương pháp học Zero-shot
Zero-shot learning thường được sử dụng trong:
- Phương pháp dựa trên phân loại
- phương pháp dựa trên trường hợp
Các giai đoạn
Zero-shot learning được sử dụng để xây dựng các mô hình cho các lớp không đào tạo bằng cách sử dụng dữ liệu được gắn nhãn, do đó, nó yêu cầu hai giai đoạn sau:
1. đào tạo
Giai đoạn đào tạo là quá trình của phương pháp học cố gắng nắm bắt càng nhiều kiến thức càng tốt về chất lượng của dữ liệu. Chúng ta có thể xem đây là giai đoạn học tập.
2. Suy luận
Trong giai đoạn suy luận, tất cả kiến thức đã học được từ giai đoạn huấn luyện được áp dụng và sử dụng để phân loại các ví dụ thành một tập hợp các lớp mới. Chúng ta có thể xem đây là giai đoạn đưa ra dự đoán.
Làm thế nào nó làm việc?
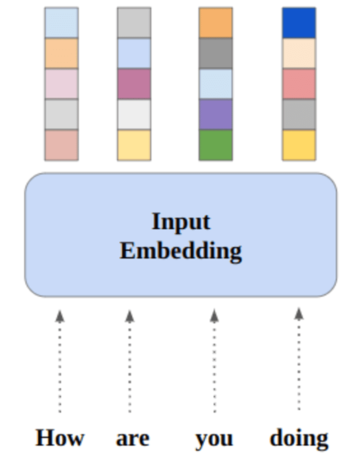
Tri thức từ các lớp nhìn thấy sẽ được chuyển sang các lớp không nhìn thấy trong không gian vectơ nhiều chiều; đây được gọi là không gian ngữ nghĩa. Ví dụ, trong phân loại ảnh, không gian ngữ nghĩa cùng với ảnh sẽ trải qua hai bước:
1. Không gian nhúng chung
Đây là nơi mà các vectơ ngữ nghĩa và các vectơ của tính năng trực quan được chiếu tới.
2. Độ tương đồng cao nhất
Đây là nơi các tính năng được đối sánh với các tính năng của một lớp không nhìn thấy.
Để giúp hiểu quá trình với hai giai đoạn (đào tạo và suy luận), hãy áp dụng chúng trong việc sử dụng phân loại hình ảnh.
Hội thảo

Jari Hytonen thông qua Unsplash
Là một con người, nếu bạn đọc dòng chữ bên phải trong hình trên, bạn sẽ ngay lập tức cho rằng có 4 chú mèo con trong một chiếc giỏ màu nâu. Nhưng giả sử bạn không biết 'mèo con' là gì. Bạn sẽ cho rằng có một cái giỏ màu nâu bên trong có 4 thứ gọi là 'mèo con'. Khi bạn bắt gặp nhiều hình ảnh có chứa thứ gì đó trông giống như 'mèo con', bạn sẽ có thể phân biệt 'mèo con' với các động vật khác.
Đây là những gì xảy ra khi bạn sử dụng Đào tạo trước ngôn ngữ-hình ảnh tương phản (CLIP) của OpenAI để học không ảnh trong phân loại hình ảnh. Nó được gọi là thông tin phụ trợ.
Bạn có thể đang nghĩ, 'đó chỉ là dữ liệu được dán nhãn'. Tôi hiểu tại sao bạn lại nghĩ như vậy, nhưng họ thì không. Thông tin phụ trợ không phải là nhãn của dữ liệu, chúng là một dạng giám sát để giúp mô hình học trong giai đoạn huấn luyện.
Khi mô hình học tập không ảnh hưởng thấy đủ số lượng ghép nối hình ảnh-văn bản, nó sẽ có thể phân biệt và hiểu các cụm từ cũng như cách chúng tương quan với các mẫu nhất định trong hình ảnh. Sử dụng kỹ thuật CLIP 'học tương phản', mô hình học zero-shot đã có thể tích lũy một nền tảng kiến thức tốt để có thể đưa ra dự đoán về các nhiệm vụ phân loại.
Đây là bản tóm tắt về phương pháp CLIP trong đó họ đào tạo bộ mã hóa hình ảnh và bộ mã hóa văn bản cùng nhau để dự đoán các cặp chính xác của một lô ví dụ đào tạo (hình ảnh, văn bản). Xin vui lòng xem hình ảnh dưới đây:

Học các mô hình trực quan có thể chuyển đổi từ giám sát ngôn ngữ tự nhiên
Sự suy luận
Khi mô hình đã trải qua giai đoạn đào tạo, nó có một nền tảng kiến thức tốt về ghép nối hình ảnh-văn bản và giờ đây có thể được sử dụng để đưa ra dự đoán. Nhưng trước khi có thể đưa ra dự đoán ngay, chúng ta cần thiết lập tác vụ phân loại bằng cách tạo danh sách tất cả các nhãn có thể có mà mô hình có thể xuất ra.
Ví dụ, với nhiệm vụ phân loại hình ảnh về các loài động vật, chúng ta sẽ cần một danh sách tất cả các loài động vật. Mỗi một trong những nhãn này sẽ được mã hóa, T? đến T? bằng cách sử dụng bộ mã hóa văn bản được đào tạo trước trong giai đoạn đào tạo.
Khi các nhãn đã được mã hóa, chúng tôi có thể nhập hình ảnh thông qua bộ mã hóa hình ảnh được đào tạo trước. Chúng tôi sẽ sử dụng độ tương tự cosine theo số liệu khoảng cách để tính toán độ tương tự giữa mã hóa hình ảnh và từng mã hóa nhãn văn bản.
Việc phân loại ảnh được thực hiện dựa trên nhãn có độ tương đồng lớn nhất với ảnh. Và đó là cách đạt được khả năng học tập không ảnh hưởng, cụ thể là trong phân loại hình ảnh.
Sự khan hiếm dữ liệu
Như đã đề cập trước đây, bạn khó có được dữ liệu chất lượng và số lượng lớn. Không giống như con người vốn đã sở hữu khả năng học tập ngay lập tức, máy móc yêu cầu dữ liệu được gắn nhãn đầu vào để học và sau đó có thể thích ứng với các phương sai có thể xảy ra một cách tự nhiên.
Nếu chúng ta nhìn vào ví dụ về loài động vật, thì có rất nhiều. Và khi số lượng danh mục tiếp tục tăng lên trong các lĩnh vực khác nhau, sẽ mất rất nhiều công sức để theo kịp việc thu thập dữ liệu chú thích.
Do đó, việc học không bắn đã trở nên có giá trị hơn đối với chúng tôi. Ngày càng có nhiều nhà nghiên cứu quan tâm đến việc nhận dạng thuộc tính tự động để bù đắp cho việc thiếu dữ liệu sẵn có.
Ghi nhãn dữ liệu
Một lợi ích khác của zero-shot learning là thuộc tính ghi nhãn dữ liệu của nó. Ghi nhãn dữ liệu có thể tốn nhiều công sức và rất tẻ nhạt, do đó có thể dẫn đến sai sót trong quá trình này. Việc ghi nhãn dữ liệu yêu cầu các chuyên gia, chẳng hạn như các chuyên gia y tế đang làm việc trên bộ dữ liệu y sinh, việc này rất tốn kém và tốn thời gian.
Zero-shot learning đang trở nên phổ biến hơn do những hạn chế về dữ liệu nêu trên. Có một vài bài báo tôi khuyên bạn nên đọc nếu bạn quan tâm đến khả năng của nó:
Nisha Arya là Nhà khoa học dữ liệu và Nhà văn kỹ thuật tự do. Cô ấy đặc biệt quan tâm đến việc cung cấp lời khuyên hoặc hướng dẫn nghề nghiệp về Khoa học Dữ liệu và kiến thức dựa trên lý thuyết về Khoa học Dữ liệu. Cô cũng mong muốn khám phá những cách khác nhau mà Trí tuệ nhân tạo có thể mang lại / có thể mang lại lợi ích cho sự trường tồn của cuộc sống con người. Một người ham học hỏi, tìm cách mở rộng kiến thức công nghệ và kỹ năng viết của mình, đồng thời giúp hướng dẫn người khác.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2022/12/zeroshot-learning-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=zero-shot-learning-explained
- 2021
- a
- khả năng
- có khả năng
- Có khả năng
- Giới thiệu
- ở trên
- Theo
- Tích trữ
- đạt được
- ngang qua
- thích ứng
- tư vấn
- chống lại
- Tất cả
- cho phép
- Đã
- số lượng
- và
- động vật
- động vật
- áp dụng
- Đăng Nhập
- phương pháp tiếp cận
- xung quanh
- nhân tạo
- trí tuệ nhân tạo
- Tự động
- có sẵn
- cơ sở
- dựa
- giỏ
- trở nên
- trở thành
- trước
- được
- phía dưới
- hưởng lợi
- giữa
- y sinh
- nới rộng
- xây dựng
- tính
- gọi là
- Có thể có được
- không thể
- có khả năng
- nắm bắt
- Tuyển Dụng
- đố
- nhất định
- tốt nghiệp lớp XNUMX
- các lớp học
- phân loại
- Phân loại
- Thu
- Đến
- hoàn thành
- khả năng tính toán
- Tính
- máy tính
- Tầm nhìn máy tính
- liên tiếp
- có thể
- tạo
- Tạo
- Current
- dữ liệu
- khoa học dữ liệu
- nhà khoa học dữ liệu
- bộ dữ liệu
- sâu
- học kĩ càng
- Phụ thuộc
- sự khác biệt
- khác nhau
- phân biệt
- khoảng cách
- lĩnh vực
- suốt trong
- mỗi
- Hiệu quả
- nỗ lực
- lỗi
- ví dụ
- ví dụ
- đắt tiền
- các chuyên gia
- Giải thích
- khám phá
- Đặc tính
- Tính năng
- vài
- Tìm kiếm
- tiếp theo
- hình thức
- freelance
- từ
- Tổng Quát
- được
- tốt
- lớn nhất
- Phát triển
- hướng dẫn
- xử lý
- Tay bài
- xảy ra
- Cứng
- có
- giúp đỡ
- giúp đỡ
- Cao
- cao nhất
- cao
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTTPS
- Nhân loại
- Con người
- ý tưởng
- hình ảnh
- Phân loại hình ảnh
- hình ảnh
- quan trọng
- in
- thông tin
- đầu vào
- Sự thông minh
- quan tâm
- IT
- Keen
- Giữ
- Biết
- kiến thức
- nổi tiếng
- nhãn
- ghi nhãn
- Nhãn
- Thiếu sót
- Ngôn ngữ
- dẫn
- LEARN
- học
- học tập
- Cuộc sống
- hạn chế
- LINK
- liên kết
- Danh sách
- tuổi thọ
- Xem
- tìm kiếm
- NHÌN
- Rất nhiều
- máy
- học máy
- Máy móc
- chính
- làm cho
- Làm
- nhiều
- có nghĩa
- y khoa
- đề cập
- phương pháp
- phương pháp
- số liệu
- Might
- triệu
- kiểu mẫu
- mô hình
- tiền
- chi tiết
- hầu hết
- Tự nhiên
- Cần
- Mới
- con số
- đối tượng
- trở ngại
- xảy ra
- ONE
- OpenAI
- gọi món
- Nền tảng khác
- Khác
- cặp đôi
- cặp
- giấy tờ
- đặc biệt
- mô hình
- giai đoạn
- cụm từ
- vật lý
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- xin vui lòng
- Phổ biến
- có thể
- quyền lực
- dự đoán
- Dự đoán
- trước đây
- Vấn đề
- quá trình
- sản xuất
- chuyên gia
- dự
- tài sản
- cung cấp
- đặt
- chất lượng
- chất lượng
- số lượng, lượng
- Đọc
- lý do
- nhận
- công nhận
- giới thiệu
- yêu cầu
- đòi hỏi
- nhà nghiên cứu
- hạn chế
- mạnh mẽ
- Khoa học
- Nhà khoa học
- tìm kiếm
- nhìn
- định
- tương tự
- tương
- kỹ năng
- thông minh hơn
- So
- động SOLVE
- một cái gì đó
- Không gian
- đặc biệt
- Traineeship
- giai đoạn
- Các bước
- dính
- Vẫn còn
- hàng
- như vậy
- đủ
- TÓM TẮT
- giám sát
- Hãy
- mất
- Nhiệm vụ
- nhiệm vụ
- công nghệ cao
- Kỹ thuật
- Sản phẩm
- cung cấp their dịch
- vì thế
- điều
- Suy nghĩ
- Thông qua
- thời gian
- mất thời gian
- đến
- bên nhau
- Train
- Hội thảo
- chuyển
- đáng tin cậy
- hướng dẫn
- thường
- hiểu
- us
- sử dụng
- tận dụng
- Quý báu
- thông qua
- Xem
- tầm nhìn
- cách
- Điều gì
- cái nào
- Trong khi
- CHÚNG TÔI LÀ
- rộng rãi
- sẽ
- không có
- Từ
- Công việc
- đang làm việc
- sẽ
- nhà văn
- viết
- trên màn hình
- zephyrnet
- Học Zero-Shot