组织选择在 亚马逊简单存储服务 (亚马逊 S3)多年。 数据湖是组织存储由不同团队、跨业务领域、各种不同格式甚至历史记录生成的所有组织数据的最流行选择。 根据 一项研究,平均每家公司都发现他们的数据量以每年超过 50% 的速度增长,通常平均管理 33 个独特的数据源以供分析。
团队经常尝试使用相同的提取、转换和加载 (ETL) 模式从关系数据库复制数千个作业。 在维护工作状态和安排这些单独的工作方面需要付出很多努力。 这种方法可以帮助团队在添加表时进行少量更改,并以最少的工作量维护作业状态。 这可以极大地改进开发时间表并轻松跟踪工作。
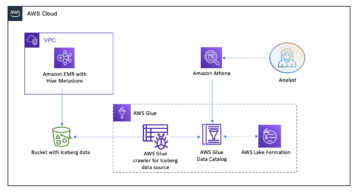
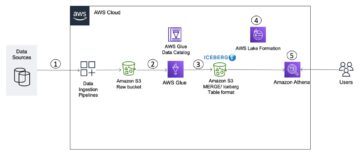
在本文中,我们将向您展示如何使用 Apache Iceberg 和单个 ETL 作业以自动化方式轻松地将所有关系数据存储复制到事务数据湖中 AWS胶水.
解决方案架构
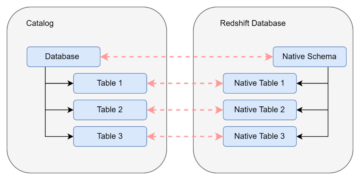
数据湖是 通常有组织的 对三层数据使用单独的 S3 存储桶:原始层包含原始形式的数据,阶段层包含针对消费优化的中间处理数据,分析层包含针对特定用例的聚合数据。 在原始层中,表通常根据其数据源进行组织,而在阶段层中的表则根据其所属的业务领域进行组织。
这篇文章提供了一个 AWS CloudFormation 部署 AWS Glue 作业的模板,该作业读取数据湖原始层的一个数据源的 Amazon S3 路径,并使用使用将数据提取到阶段层的 Apache Iceberg 表中 AWS Glue 对数据湖框架的支持. 作业期望原始层中的表以这种方式构建 AWS 数据库迁移服务 (AWS DMS) 摄取它们:架构,然后是表,然后是数据文件。
该解决方案使用 AWS Systems Manager参数存储 用于表配置。 您应该修改此参数,指定要处理的表以及处理方式,包括主键、分区和关联的业务域等信息。 该作业使用此信息为每个业务领域自动创建一个数据库(如果它尚不存在),创建 Iceberg 表,并执行数据加载。
最后,我们可以使用 亚马逊雅典娜 查询 Iceberg 表中的数据。
下图说明了此体系结构。

此实现有以下注意事项:
- 数据源中的所有表都必须有一个主键才能使用此解决方案进行复制。 主键可以是单个列或具有多个列的组合键。
- 如果数据湖包含不需要更新插入或没有主键的表,您可以将它们从参数配置中排除,并实现传统的 ETL 流程以将它们摄取到数据湖中。 这超出了本文的范围。
- 如果需要摄取额外的数据源,您可以部署多个 CloudFormation 堆栈,一个来处理每个数据源。
- AWS Glue 作业旨在分两个阶段处理数据:在 AWS DMS 完成完整加载任务后运行的初始加载,以及按应用 AWS DMS 捕获的变更数据捕获 (CDC) 文件的计划运行的增量加载。 增量处理是使用 AWS Glue 作业书签.
完成本教程有九个步骤:
- 为 AWS DMS 设置源终端节点。
- 使用 AWS CloudFormation 部署解决方案。
- 查看 AWS DMS 复制任务。
- (可选)添加加密和解密权限或 AWS湖形成.
- 查看 Parameter Store 上的表配置。
- 执行初始数据加载。
- 执行增量数据加载。
- 监控表摄取。
- 安排增量批量数据加载。
先决条件
在开始本教程之前,您应该已经熟悉 Iceberg。 如果不是,您可以按照中的说明复制单个表来开始 使用 Apache Iceberg 和 AWS Glue 在数据湖中实施基于 CDC 的 UPSERT. 此外,设置以下内容:
为 AWS DMS 设置源终端节点
在我们创建 AWS DMS 任务之前,我们需要设置一个源端点以连接到源数据库:
- 在 AWS DMS 控制台上,选择 端点 在导航窗格中。
- 创建端点.
- 如果您的数据库在 Amazon RDS 上运行,请选择 选择 RDS 数据库实例,然后从列表中选择实例。 否则,选择源引擎并通过以下方式提供连接信息 AWS机密管理器 或手动。
- 针对 端点标识符, 输入端点的名称; 例如,source-postgresql.
- 创建端点.
使用AWS CloudFormation部署解决方案
使用提供的模板创建 CloudFormation 堆栈。 完成以下步骤:
- 启动堆栈:

- 下一页.
- 提供堆栈名称,例如
transactionaldl-postgresql. - 输入所需参数:
- DMSS3EndpointIAM角色ARN – IAM 角色 ARN,供 AWS DMS 将数据写入 Amazon S3。
- 复制实例Arn – AWS DMS 复制实例 ARN。
- S3BucketStage – 用于数据湖阶段层的现有存储桶的名称。
- S3桶胶 – 用于存储 AWS Glue 脚本的现有 S3 存储桶的名称。
- S3BucketRaw – 用于数据湖原始层的现有存储桶的名称。
- 源端点Arn – 您之前创建的 AWS DMS 终端节点 ARN。
- 来源名称 – 要复制的数据源的任意标识符(例如,
postgres). 这用于定义将存储数据的数据湖(原始层)的 S3 路径。
- 不要修改以下参数:
- 来源S3BucketBlog – 存储提供的 AWS Glue 脚本的存储桶名称。
- 源S3BucketPrefix – 存储提供的 AWS Glue 脚本的存储桶前缀名称。
- 下一页 两次。
- 选择 我承认AWS CloudFormation可能会使用自定义名称创建IAM资源。
- 创建堆栈.
大约 5 分钟后,部署了 CloudFormation 堆栈。
查看 AWS DMS 复制任务
AWS CloudFormation 部署为您创建了一个 AWS DMS 目标终端节点。 由于两个特定的端点设置,数据将在我们需要时在 Amazon S3 上提取。
- 在 AWS DMS 控制台上,选择 端点 在导航窗格中。
- 搜索并选择开头为
dmsIcebergs3endpoint. - 查看端点设置:
DataFormat被指定为parquet.TimestampColumnName将添加列last_update_time以及在 Amazon S3 上创建记录的日期。

该部署还会创建一个 AWS DMS 复制任务,该任务以 dmsicebergtask.
- 复制任务 在导航窗格中并搜索任务。
你会看到 任务类型 被标记为 满载,持续复制. AWS DMS 将执行现有数据的初始完整加载,然后创建增量文件并对源数据库执行更改。
点击 映射规则 选项卡,有两种类型的规则:
- 一个选择规则,其中包含将从源数据库中提取的源模式和表的名称。 默认情况下,它使用先决条件中提供的示例数据库,
dms_sample, 以及所有带有关键字 % 的表。 - 将架构名称和表名称作为列包含在 Amazon S3 上的目标文件中的两个转换规则。 我们的 AWS Glue 作业使用它来了解数据湖中的文件对应于哪些表。
要了解有关如何为您自己的数据源自定义它的更多信息,请参阅 选择规则和操作.

让我们更改一些配置以完成我们的任务准备。
- 点击 行动 菜单中选择 修改.
- 在 任务设置 部分,下 满载完成后停止任务,选择 应用缓存更改后停止.
这样,我们可以将初始加载和增量文件生成控制为两个不同的步骤。 我们使用这种两步法每一步运行一次 AWS Glue 作业。
- 下 任务日志,选择 开启 CloudWatch 日志.
- 保存.
- 等待1分钟左右,数据库迁移任务状态显示为 各就各位.
加解密或Lake Formation权限
或者,您可以添加加密和解密或 Lake Formation 的权限。
添加加密解密权限
如果用于原始层和阶段层的 S3 存储桶使用 AWS密钥管理服务 (AWS KMS) 客户托管密钥,您需要添加权限以允许 AWS Glue 作业访问数据:
添加 Lake Formation 权限
如果您使用 Lake Formation 管理权限,则需要允许您的 AWS Glue 作业通过 IAM 角色创建您域的数据库和表 GlueJobRole.
- 授予创建数据库的权限(有关说明,请参阅 创建数据库).
- 授予 SUPER 权限
default数据库。 - 授予数据位置权限.
- 如果您手动创建数据库,请授予对所有数据库的创建表的权限。 参考 使用 Lake Formation 控制台和命名资源方法授予表权限 or 使用 LF-TBAC 方法授予数据目录权限 根据您的用例。
完成执行初始数据加载的后续步骤后,请确保还为消费者添加查询表的权限。 工作角色将成为所有创建的表的所有者,然后数据湖管理员可以对其他用户执行授权。
查看 Parameter Store 中的表配置
将数据提取到 Iceberg 表中的 AWS Glue 作业使用 Parameter Store 中提供的表规范。 完成以下步骤以查看为您自动配置的参数存储。 如果需要,请根据您自己的需要进行修改。
- 在 Parameter Store 控制台上,选择 我的参数 在导航窗格中。
CloudFormation 堆栈创建了两个参数:
iceberg-config用于作业配置iceberg-tables用于表配置
- 选择参数 冰山表.
JSON 结构包含 AWS Glue 用于在目标域上读取数据和写入 Iceberg 表的信息:
- 每桌一物 – 对象的名称是使用架构名称、句点和表名称创建的; 例如,
schema.table. - 首要的关键 – 这应该为每个源表指定。 您可以提供单个列或以逗号分隔的列列表(无空格)。
- 分区列 – 这可以选择性地对目标表的列进行分区。 如果您不想创建分区表,请提供一个空字符串。 否则,提供要使用的单个列或以逗号分隔的列列表(无空格)。
- 如果您想使用自己的数据源,请使用以下 JSON 代码并从提供的模板中替换 CAPS 中的文本。 如果您使用提供的示例数据源,请保留默认设置:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- 保存更改.
执行初始数据加载
现在所需的配置已完成,我们将摄取初始数据。 此步骤包括三个部分:从源关系数据库中提取数据到数据湖的原始层,在数据湖的舞台层创建 Iceberg 表,并使用 Athena 验证结果。
将数据提取到数据湖的原始层
要使用 Iceberg 从关系数据源(如果您使用提供的示例,则为 PostgreSQL)将数据提取到我们的事务数据湖,请完成以下步骤:
- 在 AWS DMS 控制台上,选择 数据库迁移任务 在导航窗格中。
- 选择您创建的复制任务并在 行动 菜单中选择 重启/恢复.
- 等待大约 5 分钟让复制任务完成。 您可以监控在 统计报表 复制任务的选项卡。

几分钟后,任务完成并显示消息 满载完成.
- 在 Amazon S3 控制台上,选择您定义为原始层的存储桶。
在 AWS DMS 上定义的 S3 前缀下(例如, postgres),您应该会看到具有以下结构的文件夹层次结构:
- 架构
- 表名
LOAD00000001.parquetLOAD0000000N.parquet
- 表名

如果您的 S3 存储桶为空,请查看 排查 AWS Database Migration Service 中的迁移任务 在运行 AWS Glue 作业之前。
创建数据并将其提取到 Iceberg 表中
在运行该作业之前,让我们浏览一下作为 CloudFormation 堆栈的一部分提供的 AWS Glue 作业的脚本,以了解其行为。
- 在 AWS Glue Studio 控制台上,选择 工作机会 在导航窗格中。
- 搜索开头为
IcebergJob-以及您的 CloudFormation 堆栈名称的后缀(例如,IcebergJob-transactionaldl-postgresql). - 选择工作。

作业脚本从 Parameter Store 获取所需的配置。 功能 getConfigFromSSM() 返回与作业相关的配置,例如需要从中读取和写入数据的源和目标存储桶。 变量 ssmparam_table_values 包含与表相关的信息,例如需要摄取的表的数据域、表名、分区列和主键。 请参阅以下 Python 代码:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']该脚本使用 Iceberg 的任意目录名称,定义为 my_catalog。 这是使用 Spark 配置在 AWS Glue 数据目录上实现的,因此指向 my_catalog 的 SQL 操作将应用于数据目录。 请参见以下代码:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
该脚本遍历 Parameter Store 中定义的表并执行检测表是否存在以及传入数据是初始加载还是更新插入的逻辑:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}') initialLoadRecordsSparkSQL() 当 S3 文件中没有操作列时,函数加载初始数据。 AWS DMS 仅将此列添加到由连续复制 (CDC) 生成的 Parquet 数据文件。 数据加载是使用 SparkSQL 的 INSERT INTO 命令执行的。 请参见以下代码:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
现在我们运行 AWS Glue 作业以将初始数据提取到 Iceberg 表中。 CloudFormation 堆栈添加了 --datalake-formats 参数,将所需的 Iceberg 库添加到作业中。
- 运行工作.
- 作业运行 监控状态。 等到状态为 运行成功.
验证加载的数据
要确认作业是否按预期处理了数据,请完成以下步骤:
- 在Athena控制台上,选择 查询编辑器 在导航窗格中。
- 确认
AwsDataCatalog被选为数据源。 - 下 数据库,根据您在参数存储中定义的配置,选择您要探索的数据域。 如果使用提供的示例数据库,请使用
sports.
下 表和视图,我们可以看到由 AWS Glue 作业创建的表列表。
- 选择第一个表名称旁边的选项菜单(三个点),然后选择 预览数据.
您可以看到加载到 Iceberg 表中的数据。 
执行增量数据加载
现在我们开始从我们的关系数据库中捕获更改并将它们应用到事务数据湖。 此步骤也分为三个部分:捕获更改、将它们应用到 Iceberg 表以及验证结果。
从关系数据库捕获更改
由于我们指定的配置,复制任务在运行完全加载阶段后停止。 现在我们重新启动任务,将更改后的增量文件添加到数据湖的原始层中。
- 在 AWS DMS 控制台上,选择我们之前创建并运行的任务。
- 点击 行动 菜单中选择 简历.
- 开始任务 开始捕捉变化。
- 要触发在数据湖上创建新文件,请使用您首选的数据库管理工具对源数据库的表执行插入、更新或删除操作。 如果使用提供的示例数据库,您可以运行以下 SQL 命令:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- 在 AWS DMS 任务详细信息页面上,选择 表统计 选项卡以查看捕获的更改。

- 打开数据湖的原始层,找到一个新文件,其中包含每个表前缀内的增量更改,例如在
sporting_event字首。
更改的记录 sporting_event 表看起来像下面的屏幕截图。

请注意 Op 开头的列用更新标识(U). 此外,第二个日期/时间值是 AWS DMS 在捕获更改时添加的控制列。

使用 AWS Glue 在 Iceberg 表上应用更改
现在我们再次运行 AWS Glue 作业,它会自动处理新的增量文件,因为启用了作业书签。 让我们回顾一下它是如何工作的。
dedupCDCRecords() 函数执行数据重复数据删除,因为可以在 Amazon S3 上的同一数据文件中捕获对单个记录 ID 的多次更改。 重复数据删除是基于 last_update_time AWS DMS 添加的列,指示捕获更改时的时间戳。 请参阅以下 Python 代码:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDF在第99行, upsertRecordsSparkSQL() 函数以与初始加载类似的方式执行更新插入,但这次使用 SQL MERGE 命令。
查看应用的更改
打开 Athena 控制台并运行查询以选择源数据库中已更改的记录。 如果使用提供的示例数据库,请使用以下 SQL 查询之一:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

监控表摄取
AWS Glue 作业脚本编码简单 Python异常处理 在处理特定表期间捕获错误。 作业书签在每个表成功完成处理后保存,以避免在对有错误的表重试作业运行时重新处理表。
AWS命令行界面 (AWS CLI) 提供了一个 get-job-bookmark AWS Glue 的命令,可以深入了解每个已处理表的书签状态。
- 在 AWS Glue Studio 控制台上,选择 ETL 作业。
- 选择 作业运行 选项卡并复制作业运行 ID。
- 在针对 AWS CLI 进行身份验证的终端上运行以下命令,替换
<GLUE_JOB_RUN_ID>在第 1 行使用您复制的值。 如果您的 CloudFormation 堆栈未命名transactionaldl-postgresql, 在脚本的第 2 行提供您的工作名称:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrun在这个方案中,当表处理出现异常时,AWS Glue job不会按照这个逻辑失败。 相反,该表将被添加到一个数组中,该数组在作业完成后打印。 在这种情况下,作业将在尝试处理在原始数据源上检测到的其余表后被标记为失败。 这样,没有错误的表不必等到用户识别并解决冲突表上的问题。 用户可以使用 AWS Glue 作业运行状态快速检测有问题的作业运行,并使用作业运行的 CloudWatch 日志确定哪些特定表导致问题。
- 作业脚本使用以下 Python 代码实现此功能:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')以下屏幕截图显示了 CloudWatch 日志如何查找导致处理错误的表。

与 AWS 架构完善的框架数据分析视角 在实践中,您可以采用更复杂的控制机制来识别并在数据管道上出现错误时通知利益相关者。 例如,您可以使用 Amazon DynamoDB 控制表存储所有表和作业运行错误,或使用 亚马逊简单通知服务 (亚马逊 SNS)到 向操作员发送警报 当满足某些条件时。
安排增量批量数据加载
CloudFormation 堆栈部署了一个 亚马逊EventBridge 可以触发 AWS Glue 作业按计划运行的规则(默认情况下禁用)。 要提供您自己的计划并启用规则,请完成以下步骤:
- 在 EventBridge 控制台上,选择 规则 在导航窗格中。
- 搜索以您的 CloudFormation 堆栈名称为前缀的规则,后跟
JobTrigger(例如,transactionaldl-postgresql-JobTrigger-randomvalue). - 选择规则。
- 下 日程安排,选择 编辑.
默认计划配置为每小时触发一次。
- 提供您要运行作业的计划。
- 此外,您可以使用 EventBridge cron 表达式 通过选择 一个细粒度的时间表.

- 完成 cron 表达式的设置后,选择 下一页 三遍,最后选择 更新规则 保存更改。
该规则创建时默认禁用,以允许您首先运行初始数据加载。
- 通过选择激活规则 启用.
您可以使用 灭菌监测 选项卡以查看规则调用,或直接在 AWS Glue 上 作业运行 细节。
结论
部署此解决方案后,您已在单个关系数据源上自动提取表。 使用数据湖作为其中央数据平台的组织通常需要处理多个,有时甚至是数十个数据源。 此外,越来越多的用例要求组织对数据湖实施交易功能。 您可以使用此解决方案来加速在所有关系数据源中采用此类功能,以启用新的业务用例,自动化实施过程以从您的数据中获取更多价值。
作者简介
 路易斯·赫拉尔多·贝萨 是 Amazon Web Services (AWS) 数据实验室的大数据架构师。 他在帮助医疗保健、金融和教育部门的组织采用企业架构程序、云计算和数据分析功能方面拥有 12 年的经验。 Luis 目前帮助拉丁美洲的组织加速战略数据计划。
路易斯·赫拉尔多·贝萨 是 Amazon Web Services (AWS) 数据实验室的大数据架构师。 他在帮助医疗保健、金融和教育部门的组织采用企业架构程序、云计算和数据分析功能方面拥有 12 年的经验。 Luis 目前帮助拉丁美洲的组织加速战略数据计划。
 赛基兰·雷迪·埃努古 是 Amazon Web Services (AWS) 数据实验室的数据架构师。 他在实施数据加载、转换和可视化过程方面拥有 10 年的经验。 SaiKiran 目前帮助北美的组织采用现代数据架构,例如数据湖和数据网格。 他在零售、航空和金融领域拥有丰富经验。
赛基兰·雷迪·埃努古 是 Amazon Web Services (AWS) 数据实验室的数据架构师。 他在实施数据加载、转换和可视化过程方面拥有 10 年的经验。 SaiKiran 目前帮助北美的组织采用现代数据架构,例如数据湖和数据网格。 他在零售、航空和金融领域拥有丰富经验。
 纳伦德拉梅拉 是 Amazon Web Services (AWS) 数据实验室的数据架构师。 他在设计和生产实时和面向批处理的数据管道以及在云和本地环境中构建数据湖方面拥有 12 年的经验。 Narendra 目前帮助北美的组织构建和设计强大的数据架构,并在电信和金融领域拥有丰富的经验。
纳伦德拉梅拉 是 Amazon Web Services (AWS) 数据实验室的数据架构师。 他在设计和生产实时和面向批处理的数据管道以及在云和本地环境中构建数据湖方面拥有 12 年的经验。 Narendra 目前帮助北美的组织构建和设计强大的数据架构,并在电信和金融领域拥有丰富的经验。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- 关于
- 加快
- ACCESS
- 根据
- 承认
- 横过
- 适应
- 添加
- 额外
- 另外
- 添加
- 管理员
- 管理
- 采用
- 采用
- 后
- 航空公司
- 所有类型
- 已经
- Amazon
- 亚马逊雅典娜
- 亚马逊RDS
- 亚马逊网络服务
- 亚马逊网络服务(AWS)
- 美国
- 分析
- 分析
- 和
- 洛杉矶
- 阿帕奇
- 出现
- 应用领域
- 应用的
- 应用
- 的途径
- 约
- 架构
- 排列
- 相关
- 认证
- 自动化
- 自动化
- 自动
- 自动化
- 避免
- AWS
- AWS CloudFormation
- AWS胶水
- 基于
- 蝙蝠
- 因为
- 成为
- before
- 开始
- 大
- 大数据运用
- 建立
- 建设者
- 建筑物
- 商业
- 可以得到
- 能力
- 粒
- 捕获
- 捕获
- 案件
- 例
- 检索目录
- 摔角
- 原因
- 原因
- 造成
- 疾病预防控制中心
- 中央
- 一定
- 更改
- 更改
- 选择
- 选择
- 选择
- 云端技术
- 云计算
- 码
- 柱
- 列
- 公司
- 完成
- 计算
- 配置
- 配置
- 确认
- 冲突的
- 分享链接
- 地都
- 注意事项
- 安慰
- 消费者
- 消费
- 包含
- 继续
- 连续
- 控制
- 可以
- 创建信息图
- 创建
- 创建
- 创造
- 创建
- 标准
- 目前
- 习俗
- 顾客
- 定制
- data
- 数据分析
- 数据湖
- 数据平台
- 数据库
- 数据库
- 日期
- 默认
- 定义
- 部署
- 部署
- 部署
- 部署
- 部署
- 设计
- 设计
- 设计
- 详情
- 检测
- 研发支持
- 不同
- 直接
- 禁用
- 分
- 不会
- 域
- 域名
- 别
- ,我们将参加
- 每
- 此前
- 容易
- 教育
- 努力
- 或
- enable
- 启用
- 加密
- 加密
- 端点
- 发动机
- 输入
- 企业
- 环境中
- 故障
- 醚(ETH)
- 甚至
- 所有的
- 例子
- 超过
- 除
- 例外
- 现有
- 存在
- 预期
- 预计
- 体验
- 探索
- 扩展
- 提取
- 失败
- 熟悉
- 时尚
- 专栏
- 少数
- 文件
- 档
- 终于
- 金融
- 金融
- 找到最适合您的地方
- 完
- 姓氏:
- 其次
- 以下
- 对于消费者
- 申请
- 训练
- 骨架
- 止
- ,
- 功能
- 产生
- 代
- 得到
- 授予
- 补助金
- 成长
- 处理
- 医疗保健
- 帮助
- 帮助
- 等级制度
- 历史
- 保持
- 创新中心
- How To
- HTML
- HTTPS
- 巨大
- IAM
- 确定
- 识别码
- 识别
- 鉴定
- 实施
- 履行
- 实施
- 实施
- 器物
- 改进
- in
- 包括
- 包括
- 包含
- 来电
- 表示
- 个人
- 信息
- 初始
- 项目
- 刀片
- 洞察
- 例
- 代替
- 说明
- 中级
- 问题
- 问题
- IT
- 迭代
- 工作
- 工作机会
- JSON
- 保持
- 键
- 键
- 知道
- 实验室
- 湖泊
- 拉丁语
- 拉美
- 层
- 层
- 铅
- 学习用品
- 库
- 极限
- Line
- 清单
- 加载
- 装载
- 负载
- 圖書分館的位置
- 看
- LOOKS
- 该
- 洛杉矶
- 占地
- 主要
- 维护
- 使
- 管理
- 颠覆性技术
- 经理
- 管理的
- 手动
- 许多
- 制图
- 标
- 菜单
- 合并
- 的话
- 可能
- 移民
- 最低限度
- 分钟
- 分钟
- 现代
- 修改
- 显示器
- 监控
- 更多
- 最先进的
- 最受欢迎的产品
- 多
- 姓名
- 命名
- 名称
- 导航
- 旅游导航
- 需求
- 打印车票
- 需要
- 全新
- 下页
- 北
- 北美
- 通知
- 数
- 对象
- 对象
- 一
- 正在进行
- OP
- 操作
- 优化
- 附加选项
- 组织
- 组织
- 举办
- 原版的
- 除此以外
- 学校以外
- 己
- 业主
- 面包
- 参数
- 参数
- 部分
- 部分
- 径
- 模式
- 演出
- 执行
- 施行
- 期间
- 权限
- 相
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 热门
- 帖子
- PostgreSQL的
- 做法
- 首选
- 先决条件
- 当下
- 小学
- 市场问题
- 过程
- 过程
- 处理
- 生成
- 训练课程
- 提供
- 提供
- 提供
- 蟒蛇
- 很快
- 提高
- 率
- 原
- 原始数据
- 阅读
- 实时的
- 记录
- 记录
- 更换
- 复制
- 复制
- 要求
- 必须
- 资源
- 资源
- REST的
- 成果
- 零售
- 回报
- 回报
- 检讨
- 健壮
- 角色
- 第
- 定位、竞价/采购和分析/优化数字媒体采购,但算法只不过是解决问题的操作和规则。
- 运行
- 运行
- 同
- 保存
- 脚本
- 始你
- 范围
- 脚本
- 搜索
- 其次
- 行业
- 看到
- 选
- 选择
- 选择
- 分开
- 特色服务
- 集
- 设置
- 设置
- 应该
- 显示
- 作品
- 类似
- 简易
- 自
- 单
- So
- 方案,
- 解决
- 一些
- 极致
- 来源
- 来源
- 剩余名额
- 火花
- 具体的
- 规范
- 指定
- 运动
- SQL
- 堆
- 堆栈
- 阶段
- 利益相关者
- 开始
- 开始
- 开始
- 启动
- 州
- 统计
- Status
- 步
- 步骤
- 停止
- 存储
- 商店
- 存储
- 商店
- 善用
- 结构体
- 结构化
- 工作室
- 顺利
- 这样
- 超级
- SUPPORT
- 产品
- 表
- 目标
- 任务
- 任务
- 团队
- 队
- 电信
- 模板
- 终端
- 其
- 数千
- 三
- 通过
- 次
- 时间表
- 时
- 时间戳
- 至
- 工具
- 最佳
- 合计
- 跟踪
- 传统
- 交易
- 改造
- 转型
- 触发
- 教程
- 类型
- 下
- 理解
- 独特
- 更新
- 最新动态
- 使用
- 用例
- 用户
- 用户
- 平时
- 折扣值
- 验证
- 查看
- 可视化
- 体积
- 等待
- 仓库保管
- 卷筒纸
- Web服务
- 这
- 将
- 中
- 也完全不需要
- 合作
- 写
- 书面
- 雅姆
- 年
- 年
- 您一站式解决方案
- 和风网