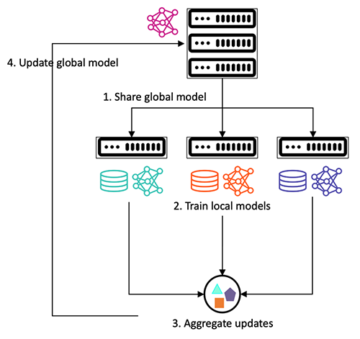
亚马逊SageMaker 是一项完全托管的机器学习 (ML) 服务。 借助 SageMaker,数据科学家和开发人员可以快速轻松地构建和训练 ML 模型,然后将它们直接部署到生产就绪的托管环境中。 它提供了一个集成的 Jupyter 创作笔记本实例,可以轻松访问您的数据源以进行探索和分析,因此您无需管理服务器。 它还提供了常见的 ML算法 经过优化以针对分布式环境中的超大数据高效运行。
SageMaker 实时推理非常适合具有实时、交互式、低延迟要求的工作负载。 借助 SageMaker 实时推理,您可以部署由具有一定计算量和内存量的特定实例类型支持的 REST 端点。 部署 SageMaker 实时端点只是许多客户生产路径的第一步。 我们希望能够最大限度地提高端点的性能,以在遵守延迟要求的同时实现目标每秒事务数 (TPS)。 推理性能优化的很大一部分是确保您选择正确的实例类型并计数以支持端点。
这篇文章描述了对 SageMaker 端点进行负载测试以找到适合实例数量和大小的正确配置的最佳实践。 这可以帮助我们了解满足延迟和 TPS 要求的最低配置实例要求。 从那里,我们深入探讨如何跟踪和了解 SageMaker 端点的指标和性能 亚马逊CloudWatch 指标。
我们首先在单个实例上对模型的性能进行基准测试,以确定它可以根据我们可接受的延迟要求处理的 TPS。 然后我们推断调查结果,以决定处理生产流量所需的实例数量。 最后,我们模拟生产级流量并为实时 SageMaker 端点设置负载测试,以确认我们的端点可以处理生产级负载。 该示例的整套代码如下所示 GitHub存储库.
解决方案概述
对于这篇文章,我们部署了一个预训练的 抱脸 DistilBERT 模型 来自 拥抱脸中心. 这个模型可以执行许多任务,但我们发送了一个专门用于情感分析和文本分类的有效载荷。 使用此示例负载,我们努力实现 1000 TPS。
部署实时端点
这篇文章假设您熟悉如何部署模型。 参考 创建您的端点并部署您的模型 了解托管端点背后的内部结构。 现在,我们可以在 Hugging Face Hub 中快速指向这个模型,并使用以下代码片段部署一个实时端点:
让我们使用要用于负载测试的示例有效负载快速测试我们的端点:

请注意,我们使用单个 亚马逊弹性计算云 (Amazon EC2) 类型为 ml.m5.12xlarge 的实例,其中包含 48 个 vCPU 和 192 GiB 内存。 vCPU 的数量很好地表明了实例可以处理的并发性。 通常,建议测试不同的实例类型,以确保我们拥有一个资源得到正确利用的实例。 要查看 SageMaker 实例的完整列表及其相应的实时推理计算能力,请参阅 Amazon SageMaker定价.
要跟踪的指标
在我们开始负载测试之前,必须了解要跟踪哪些指标以了解 SageMaker 端点的性能故障。 CloudWatch 是 SageMaker 用来帮助您了解描述端点性能的不同指标的主要日志记录工具。 您可以利用 CloudWatch 日志来调试端点调用; 您在推理代码中的所有日志记录和打印语句都在此处捕获。 有关详细信息,请参阅 Amazon CloudWatch 的工作原理.
CloudWatch 为 SageMaker 涵盖了两种不同类型的指标:实例级指标和调用指标。
实例级指标
要考虑的第一组参数是实例级指标: CPUUtilization 和 MemoryUtilization (对于基于 GPU 的实例, GPUUtilization)。 对于 CPUUtilization,您最初可能会在 CloudWatch 中看到高于 100% 的百分比。 重要的是要意识到 CPUUtilization,显示所有 CPU 内核的总和。 例如,如果您端点后面的实例包含 4 个 vCPU,这意味着利用率范围高达 400%。 MemoryUtilization另一方面,在 0–100% 的范围内。
具体来说,您可以使用 CPUUtilization 更深入地了解您是否拥有足够或什至过多的硬件。 如果您有未充分利用的实例(低于 30%),您可能会缩减实例类型。 相反,如果您的利用率在 80-90% 左右,那么选择一个具有更大计算/内存的实例会有好处。 根据我们的测试,我们建议您的硬件利用率约为 60-70%。
调用指标
顾名思义,调用指标是我们可以跟踪对端点的任何调用的端到端延迟的地方。 您可以利用调用指标来捕获错误计数以及您的端点可能遇到的错误类型(5xx、4xx 等)。 更重要的是,您可以了解端点调用的延迟细分。 其中很多都可以用 ModelLatency 和 OverheadLatency 指标,如下图所示。

ModelLatency 指标捕获推理在 SageMaker 端点后面的模型容器内花费的时间。 请注意,模型容器还包含您为推理传递的任何自定义推理代码或脚本。 该单位以微秒为单位作为调用指标捕获,通常您可以绘制 CloudWatch 的百分位数(p99、p90 等)以查看您是否达到了目标延迟。 请注意,有几个因素会影响模型和容器延迟,例如:
- 自定义推理脚本 – 无论您是实施了自己的容器,还是使用了基于 SageMaker 的容器和自定义推理处理程序,最好的做法是分析您的脚本以捕获任何特别会增加大量延迟时间的操作。
- 通讯协议 – 考虑 REST 与 gRPC 连接到模型容器内的模型服务器。
- 模型框架优化 – 这是特定于框架的,例如 TensorFlow,有许多您可以调整的环境变量,它们是特定于 TF 服务的。 确保检查您正在使用的容器,以及是否有任何特定于框架的优化可以添加到脚本中或作为环境变量注入到容器中。
OverheadLatency 从 SageMaker 收到请求到它向客户端返回响应的时间减去模型延迟。 这部分在很大程度上不在您的控制范围内,属于 SageMaker 开销所花费的时间。
端到端延迟作为一个整体取决于多种因素,不一定是以下因素的总和 ModelLatency 加 OverheadLatency. 例如,如果您的客户正在制作 InvokeEndpoint 通过 Internet 调用 API,从客户端的角度来看,端到端延迟为 internet + ModelLatency + OverheadLatency. 因此,在对端点进行负载测试以准确地对端点本身进行基准测试时,建议关注端点指标 (ModelLatency, OverheadLatency及 InvocationsPerInstance) 以准确地对 SageMaker 端点进行基准测试。 然后可以单独隔离与端到端延迟相关的任何问题。
端到端延迟需要考虑的几个问题:
- 调用端点的客户端在哪里?
- 您的客户端和 SageMaker 运行时之间是否有任何中间层?
自动缩放
我们不会在这篇文章中具体介绍自动缩放,但这是一个重要的考虑因素,以便根据工作负载提供正确数量的实例。 根据您的流量模式,您可以附加 自动缩放策略 到您的 SageMaker 端点。 有不同的缩放选项,例如 TargetTrackingScaling, SimpleScaling及 StepScaling. 这允许您的端点根据您的流量模式自动缩小和缩小。
一个常见的选项是目标跟踪,您可以在其中指定您定义的 CloudWatch 指标或自定义指标,并基于该指标进行扩展。 自动缩放的一个频繁使用是跟踪 InvocationsPerInstance 公制。 在确定某个 TPS 的瓶颈后,您通常可以将其用作衡量标准,以扩展到更多实例,从而能够处理峰值流量负载。 要更深入地了解自动缩放 SageMaker 端点,请参阅 在 Amazon SageMaker 中配置自动缩放推理终端节点.
负载测试
尽管我们利用 Locust 来展示我们如何进行大规模负载测试,但如果您试图调整端点后面的实例的大小, SageMaker 推理推荐器 是一个更有效的选择。 使用第三方负载测试工具,您必须跨不同实例手动部署端点。 借助 Inference Recommender,您只需传递一组要针对其进行负载测试的实例类型,SageMaker 就会启动 工作 对于这些实例中的每一个。
刺槐
对于这个例子,我们使用 刺槐,一种可以使用 Python 实现的开源负载测试工具。 Locust 与许多其他开源负载测试工具类似,但有一些特定的好处:
- 易于设置 – 正如我们在本文中演示的那样,我们将传递一个简单的 Python 脚本,该脚本可以针对您的特定端点和有效负载轻松重构。
- 分布式和可扩展 – Locust 基于事件并利用 事件 在引擎盖下。 这对于测试高并发工作负载和模拟数千个并发用户非常有用。 您可以通过运行 Locust 的单个进程实现高 TPS,但它也有一个 分布式负载生成 使您能够扩展到多个进程和客户端计算机的功能,正如我们将在本文中探讨的那样。
- Locust 指标和 UI – Locust 还捕获端到端延迟作为指标。 这可以帮助补充您的 CloudWatch 指标以描绘您的测试的全貌。 这一切都在 Locust UI 中捕获,您可以在其中跟踪并发用户、工作人员等。
要进一步了解 Locust,请查看他们的 文件.
亚马逊 EC2 设置
您可以在适合您的任何环境中设置 Locust。 对于这篇文章,我们设置了一个 EC2 实例并在那里安装了 Locust 来进行我们的测试。 我们使用 c5.18xlarge EC2 实例。 客户端计算能力也是需要考虑的因素。 有时,当您在客户端用完计算能力时,这通常不会被捕获,并被误认为是 SageMaker 端点错误。 将您的客户端放置在能够处理您正在测试的负载的足够计算能力的位置非常重要。 对于我们的 EC2 实例,我们使用 Ubuntu 深度学习 AMI,但您可以使用任何 AMI,只要您可以在机器上正确设置 Locust。 要了解如何启动和连接到您的 EC2 实例,请参阅教程 开始使用 Amazon EC2 Linux 实例.
Locust UI 可通过端口 8089 访问。我们可以通过调整 EC2 实例的入站安全组规则来打开它。 我们还打开端口 22,以便我们可以通过 SSH 连接到 EC2 实例。 考虑将源范围缩小到您从中访问 EC2 实例的特定 IP 地址。

在您连接到您的 EC2 实例后,我们设置了一个 Python 虚拟环境并通过 CLI 安装开源 Locust API:
我们现在准备好使用 Locust 来对我们的端点进行负载测试。
蝗虫测试
所有 Locust 负载测试都是基于 蝗虫档案 你提供的。 这个 Locust 文件定义了负载测试的任务; 这是我们定义 Boto3 的地方 invoke_endpoint API 调用。 请参见以下代码:
在前面的代码中,调整您的 invoke 端点调用参数以适合您的特定模型调用。 我们使用 InvokeEndpoint API使用Locust文件中的以下代码; 这是我们的负载测试运行点。 我们使用的 Locust 文件是 蝗虫脚本.py.
现在我们已经准备好 Locust 脚本,我们想要运行分布式 Locust 测试来对我们的单个实例进行压力测试,以了解我们的实例可以处理多少流量。
Locust 分布式模式比单进程 Locust 测试更细微。 在分布式模式下,我们有一个主要的和多个工人。 主要工作人员指导工作人员如何生成和控制发送请求的并发用户。 在我们的 分布式.sh 脚本,我们看到默认情况下 240 个用户将分布在 60 个工作人员中。 请注意, --headless Locust CLI 中的标志删除了 Locust 的 UI 功能。
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
我们首先在支持端点的单个实例上运行分布式测试。 这里的想法是,我们希望完全最大化单个实例,以了解实现目标 TPS 所需的实例数,同时保持在我们的延迟要求之内。 请注意,如果要访问 UI,请更改 Locust_UI 环境变量为 True 并获取 EC2 实例的公共 IP 并将端口 8089 映射到 URL。
以下屏幕截图显示了我们的 CloudWatch 指标。

最终,我们注意到虽然我们最初达到了 200 的 TPS,但我们开始注意到 EC5 客户端日志中出现 2xx 错误,如以下屏幕截图所示。
我们还可以通过查看我们的实例级指标来验证这一点,特别是 CPUUtilization.
 这里我们注意到
这里我们注意到 CPUUtilization 接近 4,800%。 我们的 ml.m5.12x.large 实例有 48 个 vCPU (48 * 100 = 4800~)。 这使整个实例饱和,这也有助于解释我们的 5xx 错误。 我们也看到增加 ModelLatency.
似乎我们的单个实例正在倒塌,并且没有计算来维持超过我们观察到的 200 TPS 的负载。 我们的目标 TPS 是 1000,所以让我们尝试将实例数增加到 5。在生产环境中这可能必须更多,因为我们在某个时间点后观察到 200 TPS 的错误。

我们在 Locust UI 和 CloudWatch 日志中都看到我们的 TPS 接近 1000,有五个实例支持端点。

 如果即使使用此硬件设置也开始遇到错误,请确保监控
如果即使使用此硬件设置也开始遇到错误,请确保监控 CPUUtilization 了解端点托管背后的全貌。 了解您的硬件利用率对于了解您是否需要扩大甚至缩小规模至关重要。 有时容器级别的问题会导致 5xx 错误,但如果 CPUUtilization 很低,这表明它不是您的硬件,而是容器或模型级别的某些东西可能会导致这些问题(例如,未设置工作人员数量的适当环境变量)。 另一方面,如果您注意到您的实例已完全饱和,则表明您需要增加当前实例队列或尝试使用较小队列的较大实例。
尽管我们将实例数增加到 5 以处理 100 TPS,但我们可以看到 ModelLatency 指标仍然很高。 这是由于实例饱和。 一般而言,我们建议将实例的资源利用率定在 60-70% 之间。
清理
负载测试后,确保通过 SageMaker 控制台或通过 删除端点 Boto3 API 调用。 此外,请确保停止您的 EC2 实例或您必须停止的任何客户端设置,以免在那里产生任何进一步的费用。
总结
在本文中,我们介绍了如何对 SageMaker 实时端点进行负载测试。 我们还讨论了在对端点进行负载测试以了解性能故障时应该评估哪些指标。 请务必检查 SageMaker 推理推荐器 进一步了解实例大小调整和更多性能优化技术。
作者简介
 马克卡普 是 SageMaker 服务团队的 ML 架构师。 他专注于帮助客户大规模设计、部署和管理 ML 工作负载。 在业余时间,他喜欢旅行和探索新的地方。
马克卡普 是 SageMaker 服务团队的 ML 架构师。 他专注于帮助客户大规模设计、部署和管理 ML 工作负载。 在业余时间,他喜欢旅行和探索新的地方。
 拉姆·维吉拉茹 是 SageMaker 服务团队的 ML 架构师。 他专注于帮助客户在 Amazon SageMaker 上构建和优化他们的 AI/ML 解决方案。 在业余时间,他喜欢旅行和写作。
拉姆·维吉拉茹 是 SageMaker 服务团队的 ML 架构师。 他专注于帮助客户在 Amazon SageMaker 上构建和优化他们的 AI/ML 解决方案。 在业余时间,他喜欢旅行和写作。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Able
- 以上
- 可接受
- ACCESS
- 无障碍
- 访问
- 准确
- 横过
- 增加
- 地址
- 后
- 驳
- AI / ML
- 致力
- 所有类型
- 允许
- 尽管
- Amazon
- Amazon EC2
- 亚马逊SageMaker
- 量
- 分析
- 和
- API
- 围绕
- 排列
- 连接
- 创作
- 汽车
- 自动
- 可使用
- AWS
- 背部
- 已备份
- 后盾
- 基于
- 因为
- 背后
- 作为
- 基准
- 得益
- 好处
- 最佳
- 最佳实践
- 之间
- 身体
- 击穿
- 建立
- C + +中
- 呼叫
- 呼叫
- 可以得到
- 捕获
- 捕获
- 摔角
- 一定
- 更改
- 收费
- 查
- 程
- 分类
- 客户
- 码
- 相当常见
- 兼容
- 计算
- 并发
- 进行
- 配置
- 确认
- 分享链接
- 已联繫
- 连接
- 考虑
- 考虑
- 安慰
- 容器
- 包含
- 上下文
- 控制
- 相应
- 可以
- 外壳
- 占地面积
- 中央处理器
- 创建信息图
- 关键
- 电流
- 习俗
- 合作伙伴
- data
- 深
- 深入学习
- 更深
- 默认
- 定义
- 演示
- 根据
- 依靠
- 部署
- 部署
- 描述
- 描述
- 设计
- 开发
- 不同
- 直接
- 讨论
- 屏 显:
- 分布
- 不会
- 别
- 向下
- 每
- 容易
- 高效
- 有效
- 或
- 使
- 端至端
- 端点
- 整个
- 环境
- 错误
- 故障
- 必要
- 醚(ETH)
- 甚至
- 例子
- 例外
- 执行
- 经历
- 说明
- 勘探
- 探索
- 探索
- 出口
- 非常
- 面部彩妆
- 因素
- 下降
- 熟悉
- 专栏
- 少数
- 文件
- 终于
- 找到最适合您的地方
- 姓氏:
- 舰队
- 专注焦点
- 重点
- 以下
- 格式
- 骨架
- 频繁
- 止
- ,
- 充分
- 进一步
- 总类
- 通常
- 得到
- 越来越
- 非常好
- 图形
- 更大的
- 团队
- 组的
- 处理
- 快乐
- 硬件
- 帮助
- 帮助
- 帮助
- 点击此处
- 高
- 高度
- 兜帽
- 主持人
- 托管
- 托管
- 创新中心
- How To
- HTML
- HTTPS
- 中心
- 主意
- 理想
- 确定
- 鉴定
- 影响力故事
- 实施
- 实施
- 进口
- 重要
- in
- 包括
- 增加
- 增加
- 表示
- 迹象
- 信息
- 原来
- 安装
- 例
- 集成
- 互动
- 网络
- 所调用
- IP
- IP地址
- 孤立
- 问题
- IT
- 本身
- JSON
- 大
- 在很大程度上
- 大
- 潜伏
- 发射
- 层
- 铅
- 领导
- 学习
- Level
- Linux的
- 清单
- 小
- 加载
- 负载
- 圖書分館的位置
- 长
- 寻找
- 占地
- 低
- 机
- 机器学习
- 机
- 使
- 制作
- 管理
- 管理
- 手动
- 许多
- 地图
- 生产力
- 手段
- 满足
- 会议
- 内存
- 公
- 指标
- 可能
- 最低限度
- ML
- 时尚
- 模型
- 模型
- 显示器
- 更多
- 更高效
- 多
- 姓名
- 几乎
- 一定
- 需求
- 全新
- 笔记本
- 数
- 一
- 打开
- 开放源码
- 运营
- 优化
- 优化
- 优化
- 附加选项
- 附加选项
- 秩序
- 其他名称
- 学校以外
- 己
- 涂料
- 参数
- 部分
- 通过
- 过去
- 径
- 模式
- 模式
- 高峰
- 演出
- 性能
- 透视
- 挑
- 图片
- 片
- 地方
- 地方
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 加
- 点
- 帖子
- 可能
- 功率
- 在练习上
- 做法
- 预报器
- 小学
- 打印
- 问题
- 过程
- 过程
- 生产
- 本人简介
- 正确
- 正确
- 提供
- 提供
- 规定
- 国家
- 蟒蛇
- 问题
- 很快
- 范围
- 准备
- 实时的
- 实现
- 接收
- 建议
- 地区
- 有关
- 请求
- 岗位要求
- 资源
- 响应
- REST的
- 导致
- 成果
- 回报
- 定位、竞价/采购和分析/优化数字媒体采购,但算法只不过是解决问题的操作和规则。
- 运行
- 运行
- sagemaker
- SageMaker 推理
- 鳞片
- 缩放
- 科学家
- 作用域
- 脚本
- 其次
- 保安
- 似乎
- 自
- 发送
- 情绪
- 服务
- 服务
- 集
- 设置
- 设置
- 格局
- 几个
- 应该
- 如图
- 作品
- 签署
- 类似
- 简易
- 只是
- 单
- 尺寸
- 小
- So
- 解决方案
- 东西
- 来源
- 来源
- 卵
- 具体的
- 特别是
- 纺
- 标准
- 开始
- 开始
- 声明
- 步
- 仍
- Stop 停止
- 应力
- 努力
- 这样
- 足够
- 如下
- 超级
- 补充
- 采取
- 需要
- 目标
- 任务
- 任务
- 团队
- 技术
- test
- 试运行
- 测试
- 测试
- 文字分类
- 其
- 第三方
- 数千
- 通过
- 次
- 时
- 至
- 工具
- 工具
- TPS
- 跟踪时
- 跟踪
- 交通
- 培训
- 交易
- 旅游
- true
- 教程
- 类型
- Ubuntu
- ui
- 下
- 理解
- 理解
- 单元
- 网址
- us
- 使用
- 用户
- 利用
- 利用
- 利用
- 利用
- 各种
- 确认
- 通过
- 在线会议
- 什么是
- 是否
- 这
- 而
- 将
- 中
- 工作
- 工人
- 工人
- 将
- 写作
- 您一站式解决方案
- 和风网