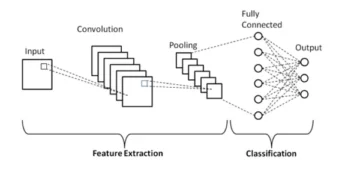
介绍
在这个项目中,我们将重点关注来自印度的数据。 我们的目标是创建一个 预测模型,比如Logistic回归等,这样当我们给出候选人的特征时,模型就可以预测他们是否会招聘。
数据集 围绕印度商学院的安置季展开。 该数据集包含候选人的各种因素,例如工作经验、考试百分比等。最后,它包含招聘状况和薪酬详细信息。

校园招聘是一种寻找、吸引和雇用年轻人才担任实习和初级职位的策略。 它通常涉及与大学就业服务中心合作并参加招聘会,与大学生和应届毕业生见面。
这篇文章是作为 数据科学博客马拉松。
目录
解决问题涉及的步骤
在本文中,我们将导入该数据集,清理它,然后准备它来构建逻辑回归模型。 我们的目标如下:
首先,我们要准备数据集 二元分类。 现在,我的意思是什么? 当我们尝试预测一个连续值(例如公寓的价格)时,它可以是零到数百万美元之间的任何数字。 我们称之为回归问题。
但在这个项目中,情况有点不同。 我们不是预测连续值,而是尝试在它们之间预测离散的组或类。 所以这称为分类问题,因为在我们的项目中,我们只有两个组可供选择,这使得它成为二元分类。
第二个目标是创建逻辑回归模型来预测招聘。 我们的第三个目标是使用优势比解释我们模型的预测。
现在就机器学习工作流程而言,我们将遵循的步骤以及一些新事物,我们将一路学习。 因此,在导入阶段,我们将准备数据以使用二进制目标。 在探索阶段,我们将关注班级平衡。 那么基本上,有多少比例的候选人是受欢迎的,哪些比例不是? 在特征编码阶段,我们将对分类特征进行编码。 在分割部分,我们将进行随机训练测试分割。
对于模型构建阶段,首先,我们将设置基线,因为我们将使用准确性分数,所以我们将更多地讨论什么是准确性分数以及当我们感兴趣的指标时如何构建基线。其次,我们将进行逻辑回归。 最后但并非最不重要的一点是,我们将进入评估阶段。 我们将再次关注准确性分数。 最后,为了传达结果,我们将查看优势比。
最后,在深入工作之前,让我们先介绍一下我们将在项目中使用的库。 首先,我们将 Google Colabe 笔记本中的数据导入到 io 库中。 然后,由于我们将使用逻辑回归模型,因此我们将从 scikit-learn 导入该模型。 之后,也从 scikit学习,我们将导入我们的性能指标、准确性分数和训练-测试-分割。
我们将使用 Matplotlib 和seaborn用于我们的可视化,以及 NumPy的 只是为了一点数学。
我们需要 大熊猫 操纵我们的数据,标签编码器对我们的分类变量进行编码,标准缩放器对数据进行标准化。 这就是我们需要的库。
让我们开始准备数据。
#import libraries
import io
import warnings import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler warnings.simplefilter(action="ignore", category=FutureWarning)准备数据
进口
为了开始准备数据,让我们开始重要的工作。 首先,我们加载数据文件,然后需要将它们放入 DataFrame“df”中。
from google.colab import files
uploaded = files.upload()# Read CSV file
df = pd.read_csv(io.BytesIO(uploaded["Placement_Data_Full_Class.csv"]))
print(df.shape)
df.head()
我们可以看到漂亮的 DataFrame,有 215 条记录和 15 列,其中包括我们的目标“status”属性。 这是所有功能的描述。

浏览
现在我们已经拥有了我们将要探索的所有这些功能。 那么让我们开始我们的 探索性数据分析。 首先,让我们看一下该数据框的信息,看看是否需要保留其中的任何内容,或者是否需要删除其中的任何内容。
# Inspect DataFrame
df.info() <class 'pandas.core.frame.DataFrame'>
RangeIndex: 215 entries, 0 to 214
Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sl_no 215 non-null int64 1 gender 215 non-null object 2 ssc_p 215 non-null float64 3 ssc_b 215 non-null object 4 hsc_p 215 non-null float64 5 hsc_b 215 non-null object 6 hsc_s 215 non-null object 7 degree_p 215 non-null float64 8 degree_t 215 non-null object 9 workex 215 non-null object 10 etest_p 215 non-null float64 11 specialisation 215 non-null object 12 mba_p 215 non-null float64 13 status 215 non-null object 14 salary 148 non-null float64
dtypes: float64(6), int64(1), object(8)
memory usage: 25.3+ KB现在,当我们查看“df”信息时,我们正在寻找一些东西,我们的数据框中有 215 行,我们要问自己的问题是,是否有丢失的数据? 如果我们看这里,除了薪资栏之外,似乎我们没有丢失数据,正如预期的那样,这是由于尚未录用的候选人造成的。
我们在这里关心的另一个问题是,是否有任何泄漏的功能会向我们的模型提供如果部署在现实世界中则不会有的信息? 请记住,我们希望我们的模型能够预测候选人是否会入职,并且我们希望我们的模型能够在招聘发生之前做出这些预测。 因此,我们不想在招聘后提供有关这些候选人的任何信息。
因此,很明显,这个“薪资”功能提供了有关公司提供的薪资的信息。 而且因为这个工资是给那些被接受的人的,所以这个功能在这里构成了泄漏,我们不得不放弃它。
df.drop(columns="salary", inplace=True)我想看的第二件事是这些不同功能的数据类型。 因此,看看这些数据类型,我们有八个带有目标的分类特征和七个数字特征,一切都是正确的。 因此,现在我们有了这些想法,让我们花一些时间来更深入地探讨它们。
我们知道我们的目标有两个类别。 我们已经安排了候选人,也没有安排候选人。 问题是,这两个类别的相对比例是多少? 它们的平衡程度相同吗? 或者一个比另一个多很多? 这是你在做分类问题时需要考虑的事情。 所以这是我们 EDA 的重要一步。
# Plot class balance
df["status"].value_counts(normalize=True).plot( kind="bar", xlabel="Class", ylabel="Relative Frequency", title="Class Balance"
);
我们的正类“已放置”占我们观察值的 65% 以上,而负类“未放置”则占 30% 左右。 现在,如果这些非常不平衡,比如,如果它更像 80 甚至更多,我会说这些是不平衡的类。 我们必须做一些工作来确保我们的模型能够以正确的方式运行。 但这是一个不错的平衡。
让我们制作另一个可视化来注意我们的特征和目标之间的联系。 让我们从数字特征开始。
首先,我们将使用分布图查看特征的个体分布,并且还将使用箱线图查看数值特征与目标之间的关系。
fig,ax=plt.subplots(5,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("number").drop(columns="sl_no")): plt.suptitle("Visualizing Distribution of Numerical Columns Indivualy and by Class",size=20) sns.histplot(data=df, x=i, kde=True, ax=ax[index,0]) sns.boxplot(data=df, x='status', y=i, ax=ax[index,1]);
在绘图的第一列中,我们可以看到所有分布都遵循正态分布,并且大多数候选人的教育表现都在 60-80% 之间。
在第二列中,我们有一个双箱形图,右侧为“已放置”类,左侧为“未放置”类。 对于“etest_p”和“mba_p”特征,从模型构建的角度来看,这两个分布没有太大差异。 各个类别的分布存在显着的重叠,因此这些特征不能很好地预测我们的目标。 至于其余的特征,它们足够明显,可以作为我们目标的潜在良好预测因子。 让我们继续讨论分类特征。 为了探索它们,我们将使用计数图。
fig,ax=plt.subplots(7,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("object").drop(columns="status")): plt.suptitle("Visualizing Count of Categorical Columns",size=20) sns.countplot(data=df,x=i,ax=ax[index,0]) sns.countplot(data=df,x=i,ax=ax[index,1],hue="status")
从情节上看,我们发现男性候选人比女性候选人多。 我们的大多数候选人都没有任何工作经验,但这些候选人比有工作经验的候选人得到了更多的聘用。 我们有将商业作为“HSC”课程的候选人,除了本科生外,具有科学背景的候选人在这两种情况下都排名第二。
关于逻辑回归模型的一点说明,虽然它们用于分类,但它们与线性回归等其他线性模型属于同一组,因此,因为它们都是线性模型。 我们还需要担心多重共线性的问题。 因此,我们需要创建一个相关矩阵,然后需要将其绘制在热图中。 我们不想在这里查看所有特征,我们只想查看数字特征,并且不想包含我们的目标。 因为如果我们的目标与我们的某些特征相关,那就非常好。
corr = df.select_dtypes("number").corr()
# Plot heatmap of `correlation`
plt.title('Correlation Matrix')
sns.heatmap(corr, vmax=1, square=True, annot=True, cmap='GnBu');
这里是浅蓝色,这意味着几乎没有相关性,而深蓝色则意味着相关性较高。 所以我们要留意那些深蓝色的。 我们可以看到一条深蓝色的线,一条沿着该图中间的对角线。 这些是与其自身相关的特征。 然后,我们看到一些黑色的方块。 这意味着我们的特征之间存在大量相关性。
在 EDA 的最后一步,我们需要检查分类特征中的高低基数。 基数是指分类变量中唯一值的数量。 高基数意味着分类特征具有大量唯一值。 不存在使特征具有高基数的唯一值的确切数量。 但是,如果分类特征的值对于几乎所有观察都是唯一的,则通常可以将其删除。
# Check for high- and low-cardinality categorical features
df.select_dtypes("object").nunique() gender 2
ssc_b 2
hsc_b 2
hsc_s 3
degree_t 3
workex 2
specialisation 2
status 2
dtype: int64我没有看到任何唯一值的数量为 XNUMX 或任何超高的列。 但我认为我们在这里缺少一个分类类型列。 原因是它不是被编码为对象而是作为整数。 “sl_no”列不是我们所知意义上的整数。 这些候选人按一定顺序排列。 只是一个独特的名称标签,名称就像一个类别,对吧? 所以这是一个分类变量。 它没有任何信息,所以我们需要删除它。
df.drop(columns="sl_no", inplace=True)特征编码
我们完成了分析,接下来需要做的就是对分类特征进行编码,我将使用“LabelEncoder”。 标签编码是一种用于处理分类变量的流行编码技术。 通过使用这种技术,每个标签都会根据字母顺序分配一个唯一的整数。
lb = LabelEncoder () cat_data = ['gender', 'ssc_b', 'hsc_b', 'hsc_s', 'degree_t', 'workex', 'specialisation', 'status']
for i in cat_data: df[i] = lb.fit_transform(df[i]) df.head()
分裂
我们导入并清理了数据。 我们已经完成了一些探索性数据分析,现在我们需要拆分数据。 我们有两种类型的分割:垂直分割或特征目标和水平分割或训练测试集。让我们从垂直分割开始。 我们将创建特征矩阵“X”和目标向量“y”。 我们的目标是“地位”。 我们的特征应该是“df”中保留的所有列。
#vertical split
target = "status"
X = df.drop(columns = target)
y = df[target]当模型拥有标准化数据进行训练时,通常会表现得更好,那么什么是标准化呢? 正常化 正在将多个变量的值转换为相似的范围。 我们的目标是标准化我们的变量。 因此它们的值范围为 0 到 1。让我们这样做,我将使用“StandardScaler”。
scaler = StandardScaler()
X = scaler.fit_transform(X)现在让我们进行水平分割或训练测试集。 我们需要使用随机训练-测试分割将数据(X 和 y)划分为训练集和测试集。 我们的测试集应该占总数据的 20%。 我们不会忘记设置 random_state 以实现可重复性。
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.2, random_state = 42 ) print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape) X_train shape: (172, 12)
y_train shape: (172,)
X_test shape: (43, 12)
y_test shape: (43,)构建逻辑回归模型
底线
所以现在我们需要开始构建我们的模型,并且我们需要开始订购来设置我们的基线。 请记住,我们正在处理的问题类型是分类问题,并且有不同的指标来评估分类模型。 我想关注的是准确性分数。
现在,准确率分数是多少? 机器学习中的准确度分数是一种评估指标,衡量模型正确预测的数量占预测总数的比例。 我们通过将正确预测的数量除以预测总数来计算它。 这意味着准确度分数介于 0 和 1 之间。零不好。 那就是你不想成为的地方,而其中一个是完美的。 因此,让我们牢记这一点并记住,基线是一个模型,它会一遍又一遍地给出一个预测,无论观察结果是什么,对我们来说只有一个猜测。
在我们的例子中,我们有两个类,放置或未放置。 那么,如果我们只能做出一种预测,我们的猜测会是什么? 如果你说的是多数类。 我认为这是有道理的,对吗? 如果我们只能有一种预测,我们可能应该选择数据集中观测值最高的预测。 因此,我们的基线将使用大多数类别在训练数据中出现的百分比。 如果模型没有超过这个基线,那么这些特征就不会添加有价值的信息来对我们的观察结果进行分类。
我们可以使用“value_counts”方法和“normalize = True”参数来计算基线精度:
acc_baseline = y_train.value_counts(normalize=True).max()
print("Baseline Accuracy:", round(acc_baseline, 2)) Baseline Accuracy: 0.68我们可以看到我们的基线准确率为 68%,即比例为 0.68。 因此,为了增加有用的价值,我们希望超过该数字并接近 XNUMX。 这就是我们的目标,现在让我们开始构建我们的模型。
迭代
现在是时候使用逻辑回归构建我们的模型了。 我们将使用逻辑回归,但在此之前,让我们先谈谈什么是逻辑回归以及它是如何工作的,然后我们就可以进行编码了。 为此,我们在这里有一个小网格。
沿着 x 轴,假设我的数据集中有 p_ Degrees 的候选者。 当我从右向左移动时,度数变得越来越高,然后沿着 Y 轴,我有可能的放置类别:零和一。

那么,如果我们要绘制出数据点,它会是什么样子? 我们的分析表明,“p_ Degree”高的候选人更有可能被雇用。 所以,它可能看起来像这样,其中“p_ Degree”较小的候选人将降到零。 具有高“p_ Degree”的候选人将上升一位。

现在假设我们想用它来做线性回归。 假设我们想绘制一条线。
现在,如果我们这样做,会发生的情况是,该线将以尽可能接近所有点的方式绘制。 所以我们最终可能会得到一条看起来像这样的线。 这会是一个好的模型吗?

并不真地。 会发生的情况是,无论候选者的 p_ Degree 是多少,我们总是会得到某种值。 这对我们没有帮助,因为在这种情况下,数字没有任何意义。 该分类问题需要为零或一。 所以,它不会那样工作。
另一方面,因为这是一条线,如果我们有一个 p_ Degree 非常低的候选者怎么办? 突然之间,我们的估计变成了负数。 再说一次,这没有任何意义。 没有负数必须是零或一。 同样地,如果我们有一位 p_ Degree 非常高的候选人,我可能会得到一个积极的、高于 XNUMX 的结果。 再说一遍,这没有任何意义。 我们需要有一个零或一。

所以我们在这里看到的是使用线性回归进行分类的一些严重限制。 那么我们需要做什么呢? 我们需要创建一个第一的模型:不会低于零或高于一,因此它需要限制在零和一之间。 第二个,无论该函数得出什么结果,我们创建的方程,我们也许不应该将其视为预测本身,而应将其视为做出最终预测的一步。
现在,让我解开我刚才所说的内容,让我们提醒自己,当我们进行线性回归模型时,我们最终会得到这个线性方程,这是最简单的形式。 这就是给我们这条直线的方程或函数。

有一种方法可以将这条线绑定在 0 和 1 之间。我们可以做的就是将我们刚刚创建的这个函数包含在另一个函数中,即所谓的 sigmoid 函数。

所以,我将采用我们刚刚得到的线性方程,并将其在 sigmoid 函数中缩小,并将其作为指数。

所发生的情况是,我们得到的不是一条直线,而是一条看起来像这样的线。 就卡在一个了它进来并向下弯曲。 然后它就卡在零了。

是的,这就是这条线的样子,我们可以看到我们已经解决了第一个问题。 无论我们从这个函数中得到什么,都将在 0 和 1 之间。在第二步中,我们不会将这个方程得出的任何结果视为最终预测。 相反,我们会将其视为概率。

我是什么意思? 这意味着当我进行预测时,我将得到 0 到 1 之间的一些浮点值。我要做的就是将其视为我的预测属于正类的概率。
所以我得到的值是 0.9999。 我想说的是,这位候选人属于我们的积极、排名类别的概率是 99%。 所以我几乎可以肯定它属于正类。 相反,如果它下降到 0.001 点或其他什么位置,我会说这个数字很低。 该特定观察结果属于正类、放置类的概率几乎为零。 所以,我想说它属于零级。
因此,这对于接近 0.5 或接近 XNUMX 的数字是有意义的。 但您可能会问自己,我该如何处理介于两者之间的其他值? 工作的方式是我们在 XNUMX 处设置一条截止线,所以我得到的任何低于该线的值,我都会将其设置为零,所以我的预测是否定的,如果它高于该线,如果它高于第五点,我会把这个放在正类中,我的预测是一个。

所以,现在我有一个函数可以给我一个介于 0.5 和 50 之间的预测,我将其视为概率。 如果这个概率高于 50 或 1000%,我会说,好吧,正一类。 如果低于 XNUMX%,我会说,那就是负类,零。 这就是逻辑回归的工作原理。 现在我们明白了这一点,让我们对其进行编码并安装它。 我将超参数“max_iter”设置为 XNUMX。该参数指的是求解器收敛的最大迭代次数。
# Build model
model = LogisticRegression(max_iter=1000) # Fit model to training data
model.fit(X_train, y_train) LogisticRegression(max_iter=1000)评估
现在是时候看看我们的模型表现如何了。 现在是评估 Logistic 回归模型的时候了。 所以,让我们记住,这一次,我们感兴趣的性能指标是准确性分数,我们想要一个准确的分数。 我们希望打破 0.68 的基线。 模型精度可以使用 precision_score 函数计算。 该函数需要两个参数:真实标签和预测标签。
acc_train = accuracy_score(y_train, model.predict(X_train))
acc_test = model.score(X_test, y_test) print("Training Accuracy:", round(acc_train, 2))
print("Test Accuracy:", round(acc_test, 2)) Training Accuracy: 0.9
Test Accuracy: 0.88我们可以看到我们的训练准确率为 90%。 它超过了基线。 我们的测试准确率稍低,为 88%。 它也超过了基线,并且非常接近我们的训练准确性。 所以这是个好消息,因为这意味着我们的模型没有过度拟合或其他任何东西。
逻辑回归模型的结果
请记住,通过逻辑回归,我们最终会得到零或一的最终预测。 但在该预测之下,存在着介于 XNUMX 和 XNUMX 之间的浮点数的概率,有时了解这些概率估计值会很有帮助。 让我们看看我们的训练预测,然后看看前五个。 “预测”方法预测未标记观察的目标。
model.predict(X_train)[:5] array([0, 1, 1, 1, 1])这些就是最终的预测,但它们背后的概率是多少? 为了获得这些,我们需要编写稍微不同的代码。 我将在我们的训练数据中使用“predict_proba”,而不是在我们的模型中使用“predict”方法。
y_train_pred_proba = model.predict_proba(X_train)
print(y_train_pred_proba[:5]) [[0.92003219 0.07996781] [0.03202019 0.96797981] [0.00678421 0.99321579] [0.03889446 0.96110554] [0.00245525 0.99754475]]我们可以看到一种嵌套列表,其中有两个不同的列。 左边的列代表候选人未被安置或我们的负类“未安置”的概率。 另一列表示正类别“已放置”或候选者被放置的概率。 我们将重点关注第二栏。 如果我们看一下第一个概率估计,我们可以看到这是 0.07。 因此,由于该比例低于 50%,我们的模型表示,我的预测为零。 对于下面的预测,我们可以看到它们都在 0.5 以上,这就是为什么我们的模型最终预测为 XNUMX。
现在我们要提取特征名称和重要性并将它们放在一个系列中。 因为我们需要将特征重要性显示为优势比,所以我们只需要通过计算重要性的指数来进行一些数学转换。
# Features names
features = ['gender', 'ssc_p', 'ssc_b', 'hsc_p', 'hsc_b', 'hsc_s', 'degree_p' ,'degree_t', 'workex', 'etest_p', 'specialisation', 'mba_p']
# Get importances
importances = model.coef_[0]
# Put importances into a Series
odds_ratios = pd.Series(np.exp(importances), index= features).sort_values()
# Review odds_ratios.head() mba_p 0.406590
degree_t 0.706021
specialisation 0.850301
hsc_b 0.876864
etest_p 0.877831
dtype: float64在讨论优势比及其含义之前,让我们先将它们绘制在水平条形图上。 让我们使用 pandas 来绘制图,并记住我们将寻找五个最大的系数。 我们不想使用所有的优势比。 所以我们要使用尾巴。
# Horizontal bar chart, five largest coefficients
odds_ratios.tail().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("High Importance Features");
现在我想让你想象一条位于 5 处的垂直线,我想从观察它开始。 让我们分别讨论其中的每一个或仅讨论前几个。 因此,让我们从“ssc_p”开始,它指的是“中学教育百分比 - 10 年级”。 我们可以看到优势比为 30。现在,这意味着什么? 这意味着,如果候选人的“ssc_p”较高,那么在所有条件相同的情况下,其获得录取的几率是其他候选人的六倍。 因此,另一种思考方式是,当候选人拥有“ssc_p”时,候选人被招募的机会增加六倍。
因此,任何超过 XNUMX 的优势比都会增加候选人被安置的几率。 这就是为什么我们在 XNUMX 处有那条垂直线。 这五种特征是与招聘增加最相关的特征。 这就是我们的优势比。 现在,我们已经了解了与招聘增加最相关的功能。 让我们看看与之相关的特征,即招聘人数的减少。 所以现在是时候看看最小的了。 所以我们不看尾巴,而看它。
odds_ratios.head().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("Low Importance Features");
我们在这里需要看到的第一件事是注意 x 轴上的所有内容都是 0.45 或以下。 这是什么意思? 那么让我们来看看这里的最小优势比。 mba_p 指的是 MBA 百分比。 我们可以看到它在 0.45 左右就准备好了。 这是什么意思? 那么,1 和 0.55 之间的差异是 55。 好的? 这个数字意味着什么? 在其他条件相同的情况下,拥有 MBA 学位的候选人被录用的可能性要低 0.55%。 好的? 因此,它将招募的几率降低了 55 倍或 XNUMX%。 这里的一切都是如此。
结论
那么我们学到了什么? 首先,在准备数据阶段,我们了解到我们正在使用逻辑回归进行分类,特别是二元分类。 在探索数据方面,我们做了很多事情,但在亮点方面,我们关注了班级平衡,对吗? 我们的正类和负类的比例。 然后我们分割数据。
由于逻辑回归是一种分类模型,因此我们了解了一个新的性能指标,即准确度得分。 现在,准确度分数介于 0 和 1 之间。XNUMX 表示不好,XNUMX 表示好。 当我们迭代时,我们了解了逻辑回归。 这是一种神奇的方法,您可以将一个线性方程、一条直线放入另一个函数、一个 sigmoid 函数和一个激活函数中,从中得到概率估计,并将该概率估计转化为预测。
最后,我们了解了优势比以及解释系数的方式,以确定给定的特征是否会增加我们招募候选人的几率。
项目源码: https://github.com/SawsanYusuf/Campus-Recruitment.git
本文中显示的媒体不属于 Analytics Vidhya 所有,其使用由作者自行决定。
相关
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.analyticsvidhya.com/blog/2023/03/campus-recruitment-a-classification-problem-with-logistic-regression/
- :是
- $UP
- 1
- 10
- 11
- 214
- 7
- 8
- 9
- a
- 关于
- 以上
- 公认
- 精准的
- 活化
- 后
- 所有类型
- 尽管
- 时刻
- 分析
- 分析
- 分析维迪亚
- 和
- 另一个
- 公寓
- 保健
- 论点
- 参数
- 围绕
- 刊文
- AS
- 相关
- At
- 出席
- 轴
- 背景
- 坏
- 当前余额
- 酒吧
- 底线
- 基本上
- BE
- 美丽
- 因为
- before
- 开始
- 背后
- 作为
- 如下。
- 更好
- 之间
- 绑定
- 位
- 博客马拉松
- 蓝色
- 界
- 盒子
- 建立
- 建筑物
- 束
- 商业
- 商学院
- by
- 计算
- 计算
- 呼叫
- 被称为
- 校园
- CAN
- 候选人
- 候选人
- 寻找工作
- 案件
- 例
- 产品类别
- 中心
- 机会
- 特点
- 图表
- 查
- 程
- 类
- 分类
- 分类
- 清除
- 关闭
- 接近
- 码
- 编码
- 学院
- 柱
- 列
- 商业
- 通信
- 关心
- 结论
- 地都
- 包含
- 上下文
- 连续
- 汇集
- 核心
- 公司
- 相关
- 相关
- 可以
- 情侣
- 课程
- 创建信息图
- 创建
- 切
- 黑暗
- data
- 数据分析
- 数据点
- 数据科学
- 数据集
- 处理
- 减少
- 部署
- 描述
- 详情
- DID
- 差异
- 不同
- 酌处权
- 讨论
- 屏 显:
- 不同
- 分配
- 分布
- 不会
- 做
- 美元
- 别
- 翻番
- 向下
- 下降
- 下降
- 每
- 教育
- 教育的
- 或
- 从事
- 更多
- 入门级
- 评估
- 估计
- 等
- 醚(ETH)
- 评估
- 评估
- 甚至
- 一切
- 考试
- 除
- 预期
- 体验
- 说明
- 勘探
- 探索性数据分析
- 探索
- 探索
- 指数
- 提取
- 因素
- 专栏
- 特征
- 女性
- 文件
- 档
- 最后
- 终于
- 姓氏:
- 适合
- 漂浮的
- 专注焦点
- 聚焦
- 遵循
- 以下
- 针对
- 申请
- FRAME
- 频率
- 止
- 功能
- 性别
- 通常
- 得到
- 越来越
- 混帐
- 给
- 给
- Go
- 目标
- 理想中
- GOES
- 去
- 非常好
- 谷歌
- 图形
- 更大的
- 格
- 团队
- 组的
- 手
- 处理
- 发生
- 发生
- 有
- 帮助
- 有帮助
- 此处
- 高
- 更高
- 最高
- 亮点
- 招聘
- 横
- 创新中心
- How To
- HTTPS
- i
- 生病
- 思路
- 失调
- 进口
- 重要性
- 重要
- in
- 包括
- 增加
- 增加
- 增加
- 指数
- 印度
- 个人
- 个别地
- info
- 信息
- 代替
- 有兴趣
- 介绍
- 介绍
- 参与
- 涉及
- 问题
- IT
- 迭代
- 保持
- 类
- 知道
- 标签
- 标签
- 大
- 最大
- 名:
- 学习用品
- 知道
- 学习
- 库
- 自学资料库
- 光
- 喜欢
- 容易
- 限制
- Line
- 清单
- 小
- 加载
- 看
- 看起来像
- 看着
- 寻找
- LOOKS
- 占地
- 低
- 机
- 机器学习
- 制成
- 多数
- 使
- 制作
- 制作
- 许多
- 数学
- 数学的
- matplotlib
- 矩阵
- 最多
- MBA
- 手段
- 措施
- 媒体
- 满足
- 内存
- 方法
- 公
- 指标
- 中间
- 可能
- 百万
- 百万美元
- 介意
- 失踪
- 模型
- 模型
- 更多
- 最先进的
- 移动
- 姓名
- 名称
- 需求
- 需要
- 负
- 全新
- 消息
- 下页
- 正常
- 笔记本
- 数
- 数字
- 麻木
- 对象
- 可能性
- of
- 最多线路
- 好
- on
- 一
- 秩序
- 其他名称
- 拥有
- 大熊猫
- 参数
- 部分
- 特别
- 百分比
- 演出
- 性能
- 表演
- 人
- 透视
- 相
- 地方
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 点
- 点
- 热门
- 职位
- 积极
- 可能
- 潜力
- 预测
- 都曾预测
- 预测
- 预测
- 预测
- 预报器
- 预测
- Prepare
- 准备
- 准备
- 漂亮
- 车资
- 可能性
- 大概
- 市场问题
- 问题
- 项目
- 出版
- 放
- 题
- 随机化
- 范围
- 排名
- 比
- 阅读
- 准备
- 真实
- 真实的世界
- 原因
- 最近
- 记录
- 招聘
- 指
- 而不管
- 回归
- 关系
- 留
- 纪念
- 报酬
- 代表
- 需要
- REST的
- 成果
- 检讨
- 说
- 薪水
- 同
- 说
- 学校
- 科学
- scikit学习
- 海生的
- 季节
- 其次
- 似乎
- 感
- 系列
- 严重
- 特色服务
- 集
- 套数
- XNUMX所
- 几个
- 形状
- 应该
- 如图
- 作品
- 显著
- 自
- SIX
- 略有不同
- 小
- 最少
- So
- 解决
- 一些
- 东西
- 来源
- 源代码
- 采购
- 特别是
- 分裂
- 广场
- 标准
- 开始
- Status
- 步
- 步骤
- 直
- 策略
- 学生
- 这样
- 突
- 超级
- 行李牌
- 采取
- 服用
- 天赋
- 谈论
- 目标
- 条款
- test
- 这
- 其
- 他们
- 他们自己
- 博曼
- 事
- 事
- 认为
- 第三
- 次
- 时
- 至
- 吨
- 合计
- 向
- 培训
- 产品培训
- 转型
- 转型
- 治疗
- true
- 转
- 类型
- 全功能包
- 理解
- 独特
- 大学
- 上传
- us
- 用法
- 使用
- 平时
- 有价值
- 有价值的信息
- 折扣值
- 价值观
- 变量
- 各个
- 可视化
- 通缉
- 方法..
- 井
- 什么是
- 什么是
- 是否
- 这
- WHO
- 将
- 工作
- 工作流程
- 加工
- 合作
- 世界
- 将
- 会给
- X
- 年轻
- 你自己
- 和风网
- 零