神经网络通过数字学习,因此每个词都将映射到向量以表示一个特定的词。 嵌入层可以被认为是一个查找表,它存储词嵌入并使用索引检索它们。
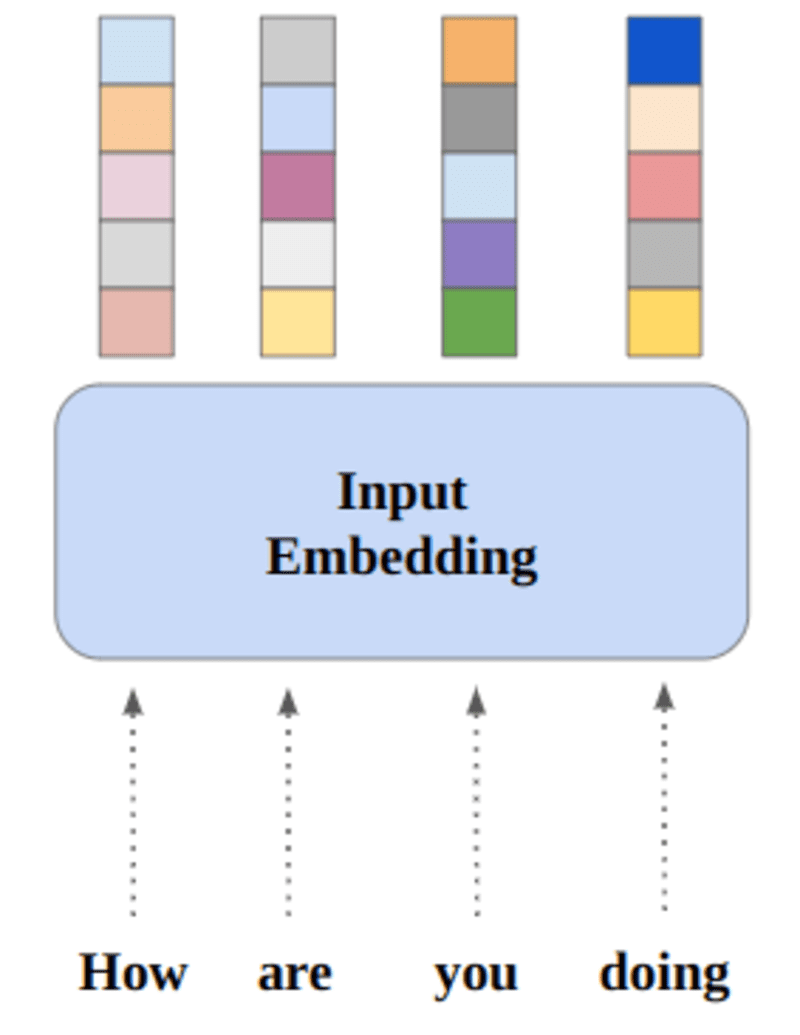
具有相同含义的词在欧氏距离/余弦相似度方面将很接近。 例如,在下面的单词表示中,“星期六”、“星期日”和“星期一”与相同的概念相关联,因此我们可以看到单词的结果相似。

词的位置判断,为什么要判断词的位置呢? 因为,transformer 编码器不像循环神经网络那样循环,我们必须在输入嵌入中添加一些关于位置的信息。 这是使用位置编码完成的。 该论文的作者使用以下函数对单词的位置进行建模。
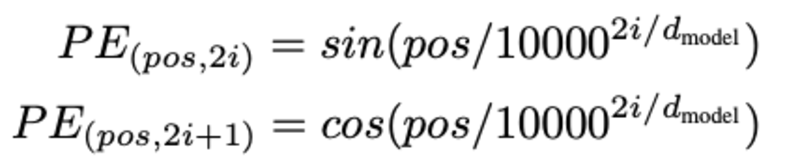
我们将尝试解释位置编码。
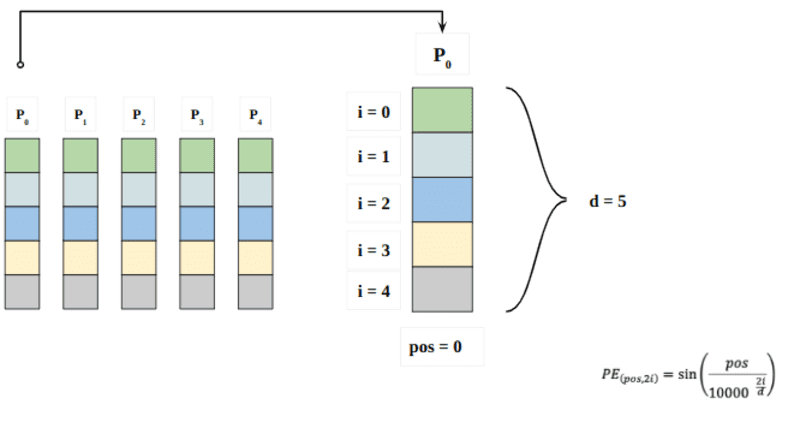
这里的“pos”指的是“word”在序列中的位置。 P0指的是第一个词的位置embedding; “d”表示单词/标记嵌入的大小。 在本例中 d=5。 最后,“i”指的是嵌入的 5 个单独维度中的每一个(即 0、1,2,3,4、XNUMX、XNUMX、XNUMX)
如果“i”在上面的等式中发生变化,您将得到一堆频率不同的曲线。 读取不同频率的位置嵌入值,在 P0 和 P4 的不同嵌入维度上给出不同的值。
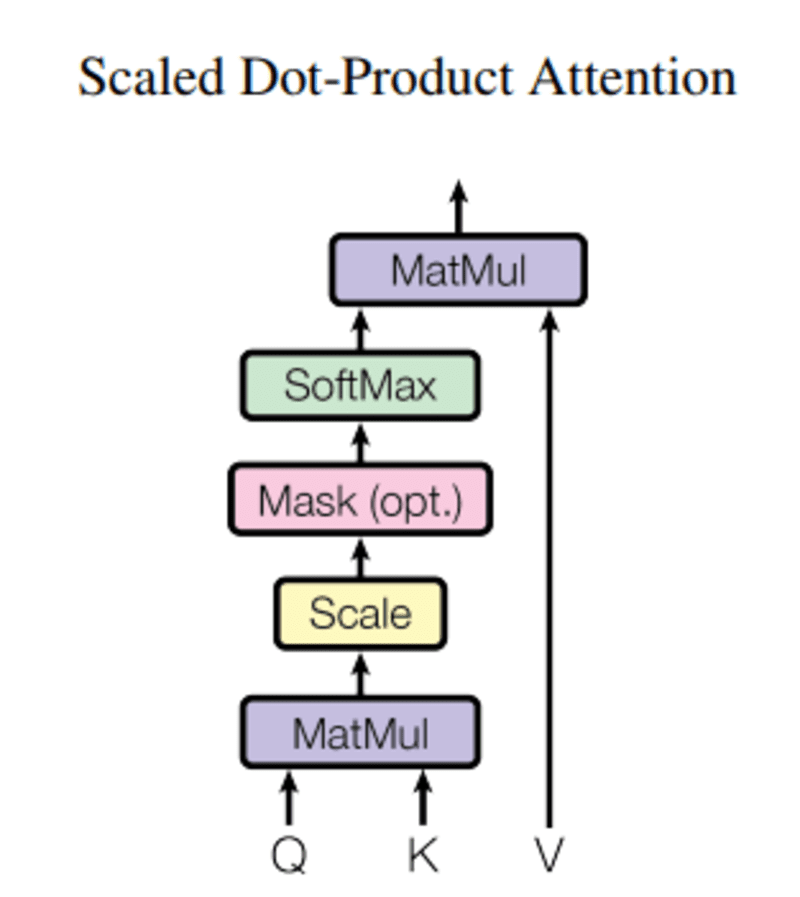
该 查询,Q 代表一个向量词, 键 K 是句子中的所有其他词,并且 值 V 表示词的向量。
注意力的目的是计算关键词相对于与同一人/事物或概念相关的查询词的重要性。
在我们的例子中,V 等于 Q。
注意机制告诉我们单词在句子中的重要性。
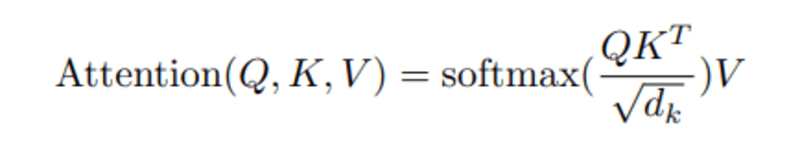
当我们计算查询和键之间的归一化点积时,我们得到一个张量,表示每个其他词对于查询的相对重要性。
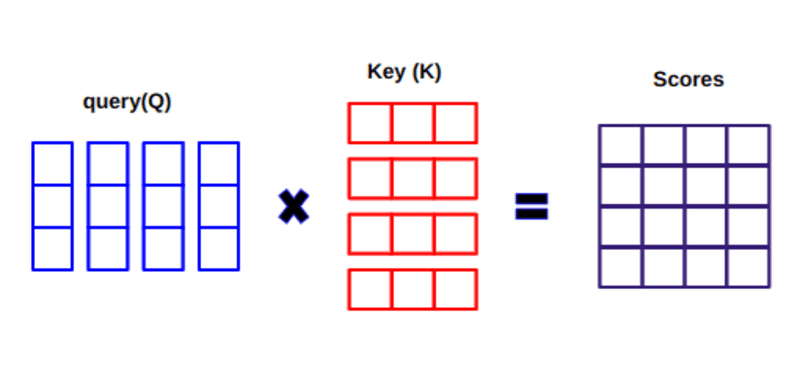
在计算 Q 和 KT 之间的点积时,我们尝试估计向量(即查询和关键字之间的词)如何对齐并返回句子中每个词的权重。
然后,我们将 d_k 和 softmax 函数的平方结果归一化,对项进行正则化,并在 0 和 1 之间重新缩放它们。
最后,我们将结果(即权重)乘以值(即所有词)以降低不相关词的重要性并仅关注最重要的词。
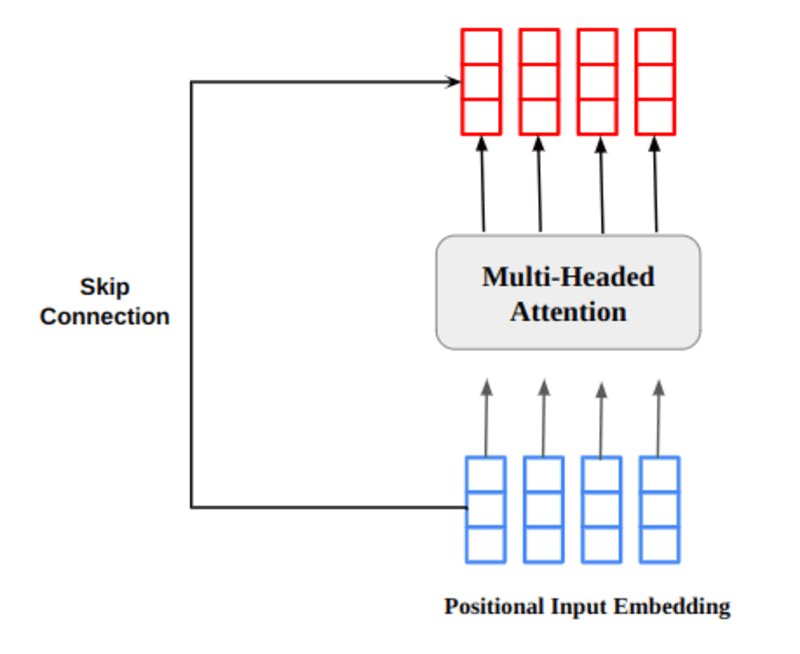
多头注意输出向量被添加到原始位置输入嵌入中。 这称为剩余连接/跳过连接。 残差连接的输出经过层归一化。 归一化残差输出通过逐点前馈网络进行进一步处理。
掩码是一个矩阵,其大小与注意力分数相同,填充了 0 和负无穷大的值。
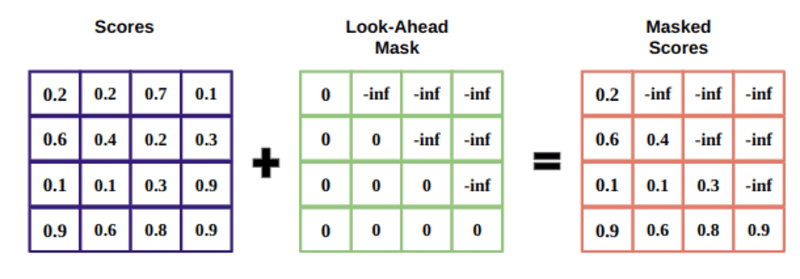
使用掩码的原因是,一旦您采用掩码分数的 softmax,负无穷大就会变为零,从而为未来的标记留下零注意力分数。
这告诉模型不要关注这些词。
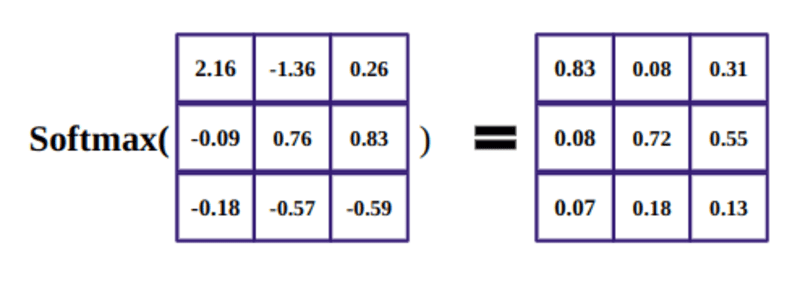
softmax 函数的目的是获取实数(正数和负数)并将它们转换为总和为 1 的正数。
拉维库马尔·纳杜文 正忙于使用 PyTorch 构建和理解 NLP 任务。
原版。 经许可重新发布。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- 关于我们
- 以上
- 添加
- 驳
- 对齐的
- 所有类型
- 和
- 相关
- 关注我们
- 作者
- 因为
- before
- 如下。
- 之间
- 建筑物
- 束
- 被称为
- 案件
- 关闭
- 相比
- 计算
- 计算
- 概念
- 概念
- 地都
- 确定
- 确定
- 不同
- 尺寸
- DOT
- 每
- 评估
- 例子
- 说明
- 满
- 终于
- 姓氏:
- 专注焦点
- 以下
- 功能
- 功能
- 进一步
- 未来
- 得到
- 越来越
- GitHub上
- 给
- 给予
- GOES
- 抢
- 创新中心
- HTTPS
- 重要性
- 重要
- in
- 指数
- 个人
- 信息
- 输入
- 掘金队
- 键
- 键
- 知道
- 层
- 学习用品
- 离开
- 查找
- 面膜
- 矩阵
- 意
- 手段
- 机制
- 模型
- 最先进的
- 需求
- 负
- 网络
- 网络
- 神经
- 神经网络
- NLP
- 数字
- 原版的
- 其他名称
- 纸类
- 特别
- 通过
- 允许
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 位置
- 职位
- 积极
- 处理
- 产品
- 目的
- 放
- pytorch
- 阅读
- 真实
- 原因
- 复发
- 减少
- 指
- 有关
- 代表
- 表示
- 代表
- 导致
- 导致
- 回报
- 同
- 句子
- 序列
- 应该
- 类似
- 尺寸
- So
- 一些
- 平方
- 商店
- 表
- 采取
- 任务
- 告诉
- 条款
- 思想
- 通过
- 至
- 令牌
- 变形金刚
- 转
- 理解
- us
- 折扣值
- 价值观
- 重量
- 这
- 将
- Word
- 话
- 和风网
- 零