亚马逊雅典娜 是一种无服务器和交互式查询服务,可让您轻松分析数据 亚马逊简单存储服务 (Amazon S3) 和 25 多个数据源,包括本地数据源或使用 SQL 或 Python 的其他云系统。 Athena 内置功能包括查询 地理空间数据; 例如,你可以 计算加利福尼亚州每个县的地震次数. 在县一级进行分析的一个缺点是,它可能会给您一种误导性印象,即加利福尼亚州的哪些地区发生地震最多。 这是因为县的大小不均; 一个县可能仅仅因为它是一个大县就发生了更多的地震。 如果我们想要一个分层系统,允许我们放大和缩小以聚合不同大小相同的地理区域的数据怎么办?
在这篇文章中,我们提出了一个解决方案,它使用 Uber 的六边形层次空间索引 (H3) 将地球划分为大小相等的六边形。 然后我们使用 Athena 用户定义函数 (UDF) 来确定每次历史地震发生在哪个六边形。由于六边形大小相同,因此该分析给出了地震倾向于发生的位置的公平印象。
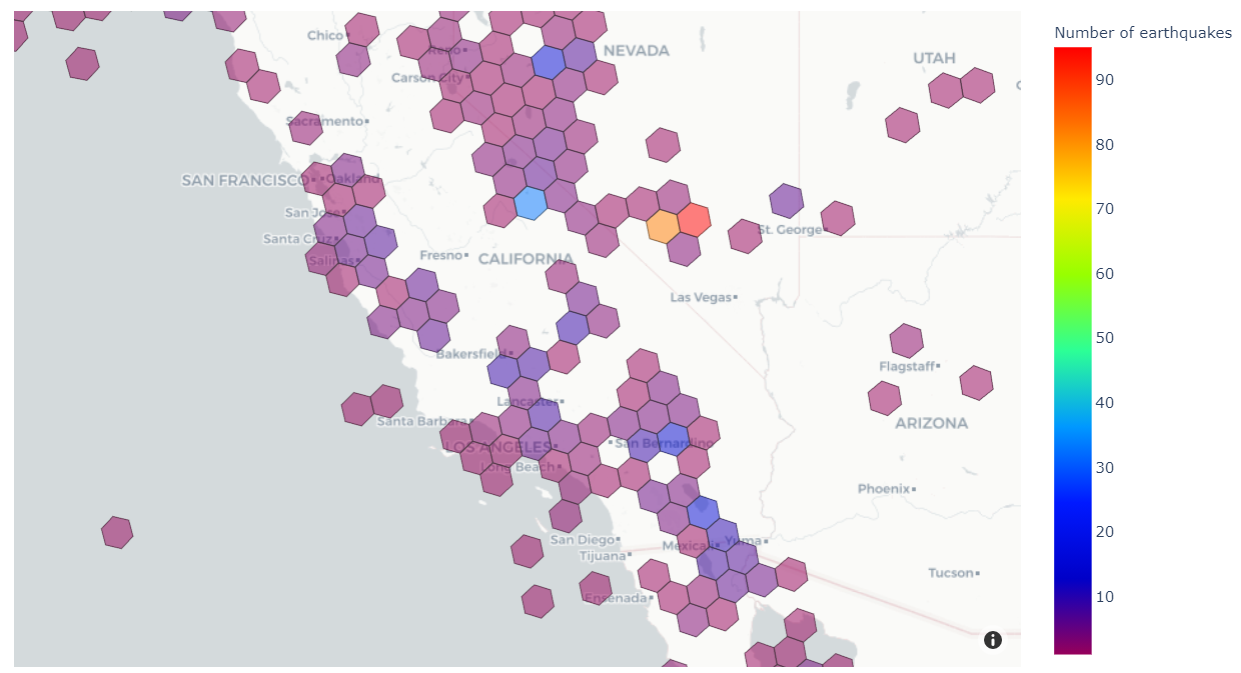
最后,我们将生成如下图所示的可视化效果,显示美国西部不同地区的历史地震次数。
H3 将地球划分为大小相等的正六边形。 六边形的数量取决于所选择的 分辨率,这可能在 0(122 个六边形,每个边长约为 1,100 公里)到 15(569,707,381,193,162 个六边形,每个边长约为 50 厘米)之间变化。 H3 可以在区域级别进行分析,每个区域具有相同的大小和形状。
解决方案概述
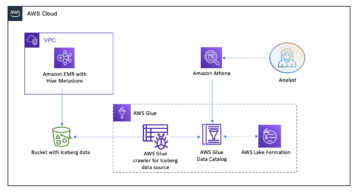
解决方案扩展 Athena 的内置地理空间功能 通过创建一个由 AWS Lambda. 最后,我们使用一个 亚马逊SageMaker 笔记本 运行呈现为 霍罗珀斯地图. 下图说明了此体系结构。

端到端架构如下:
- 将历史地震的 CSV 文件上传到 S3 存储桶中。
- An AWS胶水 外部表是基于地震 CSV 创建的。
- Lambda 函数计算参数(纬度、经度、分辨率)的 H3 六边形。 该函数是用 Java 编写的,可以使用 Athena 中的查询作为 UDF 调用。
- SageMaker 笔记本使用 适用于熊猫的 AWS 开发工具包 在 Athena 中运行 SQL 查询的包,包括 UDF。
- Plotly Express 包渲染了每个六边形中地震次数的等值线图。
先决条件
在本文中,我们使用 Athena 读取 Amazon S3 中的数据,使用与我们的地震数据集关联的 AWS Glue 数据目录中定义的表。 在权限方面,主要有两个要求:
配置亚马逊 S3
第一步是创建一个S3 bucket来存储地震数据集,如下:
- 从以下位置下载历史地震的 CSV 文件 GitHub上.
- 在Amazon S3控制台上,选择 水桶 在导航窗格中。
- 创建存储桶.
- 针对 桶名,为您的数据桶输入一个全球唯一的名称。
- 创建文件夹, 然后输入文件夹名称
earthquakes. - 将文件上传到 S3 存储桶。 在这个例子中,我们上传
earthquakes.csv文件到earthquakes字首。

在 Athena 中创建表
导航到 Athena 控制台以创建表。 完成以下步骤:
- 在Athena控制台上,选择 查询编辑器.
- 使用下拉菜单选择您喜欢的工作组。

- 在 SQL 编辑器中,使用以下代码在默认数据库中创建一个表:
为 Athena UDF 创建 Lambda 函数
有关如何构建 Athena UDF 的详尽说明,请参阅 使用用户定义的函数查询. 我们使用 Java 11 和 优步 H3 Java 绑定 构建 H3 UDF。 我们提供 UDF 的实现 GitHub上.
有几种选择 使用 Lambda 部署 UDF. 在这个例子中,我们使用 AWS管理控制台. 对于生产部署,您可能希望使用基础设施即代码,例如 AWS云开发套件 (AWS CDK)。 有关如何使用 AWS CDK 部署 Lambda 函数的信息,请参阅 项目代码库. 另一个可能的部署选项是使用 AWS Serverless Application Repository (SAR)。
部署 UDF
使用控制台部署 Uber H3 绑定 UDF,如下所示:
- 转到二进制目录中 GitHub上 存储库,并下载
aws-h3-athena-udf-*.jar到您的本地桌面。 - 创建一个名为 Lambda 的函数
H3UDF运行时 设置 Java 11(Corretto)及 建筑 设置 x86_64.
- 上载
aws-h3-athena-udf*.jar文件中。
- 将处理程序名称更改为
com.aws.athena.udf.h3.H3AthenaHandler.
- 在 一般配置 部分中,选择 编辑 将 Lambda 函数的内存设置为 4096 MB,这是适用于我们示例的内存量。 您可能需要为您的用例设置更大的内存大小。

使用 Lambda 函数作为 Athena UDF
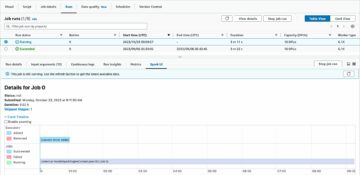
创建 Lambda 函数后,您就可以将其用作 UDF。 以下屏幕截图显示了函数的详细信息。

您现在可以将该函数用作 Athena UDF。 在 Athena 控制台上,运行以下命令:

udf/examples 文件夹中 GitHub上 存储库包含 Athena 查询的更多示例。
开发 UDF
现在我们已经向您展示了如何使用 Lambda 为 Athena 部署 UDF,让我们更深入地了解如何开发这些类型的 UDF。 如中所述 使用用户定义的函数查询,为了开发一个UDF,我们首先需要实现一个继承的类 UserDefinedFunctionHandler. 然后我们需要实现类内部的功能,可以用作 Athena 的 UDF。
我们通过定义一个类来开始 UDF 实现 H3AthenaHandler 继承了 UserDefinedFunctionHandler. 然后我们实现函数,作为定义在 优步 H3 Java 绑定. 我们确保 H3 Java 绑定 API 中定义的所有函数都已映射,以便它们可以在 Athena 中用作 UDF。 例如,我们映射 lat_lng_to_cell_address 前面例子中使用的函数 latLngToCell H3 Java 绑定。
除了调用 Java 绑定之外, H3AthenaHandler 检查输入参数是否为空。 空检查很有用,因为我们不假设输入为非空。 实际上,H3 索引或地址的空值并不罕见。
下面的代码显示了实现 get_resolution 功能:
一些H3 API函数,例如 cellToLatLng 回报 List<Double> 两个元素,其中第一个元素是纬度,第二个元素是经度。 我们实现的 H3 UDF 提供了一个返回的函数 知名文本 (WKT) 表示。 例如,我们提供 cell_to_lat_lng_wkt,它返回一个 Point WKT 字符串而不是 List<Double>. 然后我们可以使用的输出 cell_to_lat_lng_wkt 结合内置的空间雅典娜功能 ST_GeometryFromText 如下:
Athena UDF 仅支持标量数据类型,不支持嵌套类型。 但是,某些 H3 API 会返回嵌套类型。 例如, polygonToCells H3 中的函数需要一个 List<List<List<GeoCoord>>>. 我们的实施 polygon_to_cells UDF 收到一个 Polygon 取而代之的是 WKT。 下面显示了使用此 UDF 的示例 Athena 查询:
使用 SageMaker 笔记本进行可视化
A SageMaker 笔记本 是运行 Jupyter notebook 应用程序的托管机器学习计算实例。 在此示例中,我们将使用 SageMaker notebook 编写和运行我们的代码以可视化我们的结果,但如果您的用例包括 Apache Spark,则使用 适用于 Apache Spark 的亚马逊雅典娜 将是一个不错的选择。 有关 SageMaker 安全最佳实践的建议,请参阅 使用Amazon SageMaker构建安全的机器学习环境. 您可以按照以下说明创建自己的 SageMaker notebook:
- 在SageMaker控制台上,选择 笔记本 在导航窗格中。
- 笔记本实例.
- 创建笔记本实例.
- 输入笔记本实例的名称。
- 选择现有的 IAM 角色或 创建一个角色 允许您运行 SageMaker 并授予对 Amazon S3 和 Athena 的访问权限。
- 创建笔记本实例.

- 等待笔记本状态从
Creating至InService. - 通过选择打开笔记本实例 朱皮特 or Jupyter实验室.
探索数据
我们现在已准备好探索数据。
- 在 Jupyter 控制台上,在 全新,选择 笔记本.
- 点击 选择内核 下拉菜单,选择 conda_python3。
- 通过选择加号添加新单元格。
- 在您的第一个单元中,下载标准 SageMaker 环境中未包含的以下 Python 模块:
GeoJSON 是一种流行的格式,用于以 JSON 格式存储空间数据。 这
geojson模块允许您使用 Python 轻松读写 GeoJSON 数据。 我们安装的第二个模块,awswrangler, 是个 适用于熊猫的 AWS 开发工具包. 这是将数据从各种 AWS 数据源读取到 Pandas 数据框中的一种非常简单的方法。 我们用它从 Athena 表中读取地震数据。 - 接下来,我们导入所有用于导入数据、重塑数据并可视化的包:
- 我们开始使用
athena.read_sql._queryAWS SDK for pandas 中的功能。 Athena 查询有一个使用 UDF 添加列的子查询h3_cell到每一行earthquakes表,根据地震的纬度和经度。 解析函数COUNT然后用于找出每个 H3 单元格中的地震次数。 对于这个可视化,我们只对地震感兴趣 在美国境内,因此我们过滤掉数据框中感兴趣区域之外的行:以下屏幕截图显示了我们的结果。
按照我们的其余步骤进行操作 Jupyter笔记本 了解我们如何使用 H3 UDF 数据分析和可视化我们的示例。
可视化结果
为了可视化我们的结果,我们使用 情节快车 模块来创建我们数据的等值线图。 等值线图是一种基于定量值着色的可视化类型。 这对我们的用例来说是一个很好的可视化,因为我们根据地震的频率对不同的区域进行着色。
在由此产生的视觉效果中,我们可以看到北美不同地区的地震频率范围。 请注意,此地图中的 H3 分辨率低于早期地图中的分辨率,这使得每个六边形覆盖了更大的地球区域。

清理
为避免您的帐户产生额外费用,请删除您创建的资源:
- 在 SageMaker 控制台上,选择笔记本并在 行动 菜单中选择 Stop 停止.
- 等待笔记本的状态变为
Stopped,然后再次选择笔记本并在 行动 菜单中选择 删除. - 在 Amazon S3 控制台上,选择您创建的存储桶并选择 空的.
- 输入存储桶名称并选择 空的.
- 再次选择存储桶并选择 删除.
- 输入存储桶名称并选择 删除存储桶.
- 在 Lambda 控制台上,选择函数名称并在 行动 菜单中选择 删除.
结论
在本文中,您了解了如何通过添加您自己的用户定义函数来扩展 Athena 中的函数以进行地理空间分析。 虽然我们在此演示中使用了 Uber 的 H3 地理空间索引,但您可以为自己的自定义地理空间分析带来自己的地理空间索引。
在本文中,我们使用 Athena、Lambda 和 SageMaker notebooks 来可视化我们在美国西部的 UDF 结果。 代码示例在 h3-udf-换雅典娜 GitHub仓库。
下一步,您可以修改本文中的代码并根据您自己的需要对其进行自定义,以便从您自己的地理数据中获得更多见解。 例如,您可以想象其他情况,例如干旱、洪水和森林砍伐。
作者简介
 约翰·特尔福德 是 Amazon Web Services 的高级顾问。 他是大数据和数据仓库方面的专家。 约翰拥有布鲁内尔大学的计算机科学学位。
约翰·特尔福德 是 Amazon Web Services 的高级顾问。 他是大数据和数据仓库方面的专家。 约翰拥有布鲁内尔大学的计算机科学学位。
 安华黎刹 是驻巴黎的高级机器学习顾问。 他与 AWS 客户合作开发数据和 AI 解决方案,以可持续地发展他们的业务。
安华黎刹 是驻巴黎的高级机器学习顾问。 他与 AWS 客户合作开发数据和 AI 解决方案,以可持续地发展他们的业务。
 丁宝琳 是 AWS 专业服务团队的数据科学家。 她通过开发可持续的 AI/ML 解决方案来支持客户实现并加速他们的业务成果。 在业余时间,Pauline 喜欢旅行、冲浪和尝试新的甜品店。
丁宝琳 是 AWS 专业服务团队的数据科学家。 她通过开发可持续的 AI/ML 解决方案来支持客户实现并加速他们的业务成果。 在业余时间,Pauline 喜欢旅行、冲浪和尝试新的甜品店。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/extend-geospatial-queries-in-amazon-athena-with-udfs-and-aws-lambda/
- :是
- 1
- 10
- 100
- 11
- 7
- 70
- 8
- 9
- a
- 关于
- 加速
- ACCESS
- 账号管理
- 实现
- 法案
- 地址
- 忠告
- AI
- AI / ML
- 所有类型
- 允许
- 尽管
- Amazon
- 亚马逊雅典娜
- 亚马逊网络服务
- 美国
- 量
- 分析
- 解析
- 分析
- 分析
- 和
- 另一个
- 阿帕奇
- Apache Spark
- API
- APIs
- 应用领域
- 架构
- 保健
- 国家 / 地区
- 地区
- AS
- 相关
- At
- 避免
- AWS
- AWS胶水
- AWS Lambda
- AWS专业服务
- 基于
- BE
- 因为
- 开始
- 如下。
- 最佳
- 最佳实践
- 之间
- 大
- 大数据运用
- 捆绑
- 带来
- 建立
- 内建的
- 商业
- by
- 计算
- 加州
- 呼叫
- 被称为
- CAN
- 能力
- 案件
- 例
- 检索目录
- 细胞
- 更改
- 收费
- 查
- 选择
- 选择
- 选择
- 程
- 云端技术
- 码
- 柱
- 组合
- 完成
- 计算
- 一台
- 计算机科学
- 配置
- 安慰
- 顾问
- 可以
- 县
- 外壳
- 创建信息图
- 创建
- 创造
- 习俗
- 合作伙伴
- 定制
- data
- 数据科学家
- 数据仓库
- 数据库
- 更深
- 默认
- 定义
- 定义
- 毁林
- 学位
- 依靠
- 部署
- 部署
- 部署
- 深度
- 通过电脑捐款
- 详情
- 确定
- 开发
- 发展
- 研发支持
- 不同
- 坏处
- 距离
- 别
- 翻番
- 下载
- 每
- 此前
- 地震
- 容易
- 易
- 边缘
- 编辑
- element
- 分子
- 使
- 端至端
- 输入
- 环境
- 环境中
- 一样
- 醚(ETH)
- 例子
- 例子
- 现有
- 解释
- 解释
- 探索
- 特快
- 延长
- 外部
- 额外
- 公平
- 字段
- 文件
- 过滤
- 最后
- 终于
- 找到最适合您的地方
- 姓氏:
- 以下
- 如下
- 针对
- 格式
- FRAME
- 频率
- 止
- 功能
- 功能
- 进一步
- Gain增益
- 差距
- 地理
- 地域
- 几何
- 得到
- GitHub上
- 给
- 给
- 在全球范围内
- 地球
- 补助金
- 大
- 团队
- 增长
- 有
- 历史的
- 创新中心
- How To
- 但是
- HTML
- HTTP
- HTTPS
- IAM
- 实施
- 履行
- 进口
- 输入
- in
- 包括
- 包括
- 包括
- 包含
- 指数
- 信息
- 基础设施
- 输入
- 可行的洞见
- 安装
- 例
- 代替
- 说明
- 互动
- 兴趣
- 有兴趣
- IT
- 爪哇岛
- John
- JSON
- Jupyter笔记本
- 大
- 纬度
- 学习
- Level
- 喜欢
- LNG
- 负载
- 本地
- 圖書分館的位置
- 长
- 机
- 机器学习
- 主要
- 使
- 制作
- 管理
- 颠覆性技术
- 许多
- 地图
- 制图
- 内存
- 菜单
- 修改
- 模块
- 模块
- 更多
- 姓名
- 旅游导航
- 需求
- 需要
- 全新
- 下页
- 北
- 北美
- 笔记本
- 笔记本电脑
- 数
- 发生
- of
- on
- 一
- 附加选项
- 附加选项
- 秩序
- 其他名称
- 成果
- 产量
- 学校以外
- 己
- 包
- 包
- 大熊猫
- 面包
- 参数
- 参数
- 巴黎
- 部分
- 权限
- 地方
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 加
- Polygon
- 热门
- 可能
- 帖子
- 供电
- 在练习上
- 做法
- 首选
- 当下
- 大概
- 生产
- 生产
- 所以专业
- 提供
- 提供
- 国家
- 蟒蛇
- 量
- 范围
- RE
- 阅读
- 准备
- 接收
- 地区
- 定期
- 呈现
- 更换
- 知识库
- 表示
- 岗位要求
- 分辨率
- 资源
- REST的
- 导致
- 导致
- 成果
- 回报
- 回报
- 角色
- 行
- 运行
- sagemaker
- 同
- 科学
- 科学家
- SDK
- 其次
- 安全
- 保安
- 前辈
- 无服务器
- 服务
- 特色服务
- 集
- 几个
- 形状
- 作品
- 签署
- 简易
- 只是
- 尺寸
- So
- 方案,
- 解决方案
- 一些
- 来源
- 来源
- 火花
- 空间的
- 专家
- SQL
- 标准
- Status
- 步
- 步骤
- 存储
- 商店
- 存储
- 这样
- SUPPORT
- 支持
- 可持续发展
- 系统
- 产品
- 表
- 需要
- 团队
- 条款
- 这
- 区域
- 其
- 博曼
- 次
- 至
- 最佳
- 旅游
- 类型
- 尤伯杯
- 下
- 独特
- 大学
- 异常
- 上传
- us
- 美国
- 使用
- 用例
- 用户
- 价值观
- 各个
- 可视化
- 想像
- 通缉
- 方法..
- 卷筒纸
- Web服务
- 西式
- 什么是
- 是否
- 这
- 维基百科上的数据
- 将
- 中
- 工作日
- 工作组
- 合作
- 将
- 写
- 书面
- 您一站式解决方案
- 和风网
- 放大