介绍
我们已经看到了 AI 和深度学习的一些奇特术语,例如预训练模型、迁移学习等。让我向您介绍一种广泛使用的技术,也是最重要和最有效的技术之一:使用 YOLOv5 进行迁移学习。
You Only Look Once,或 YOLO 是使用最广泛的基于深度学习的对象识别方法之一。 本文将使用自定义数据集向您展示如何训练其最新变体之一 YOLOv5。
学习目标
- 本文将主要关注在自定义数据集实现上训练 YOLOv5 模型。
- 我们将看到什么是预训练模型,什么是迁移学习。
- 我们将了解 YOLOv5 是什么以及为什么我们使用 YOLO 的第 5 版。
所以,不浪费时间,让我们开始这个过程
表的内容
- 预训练模型
- 转移学习
- 什么以及为什么使用 YOLOv5?
- 迁移学习涉及的步骤
- SAP系统集成计划实施
- 您可能面临的一些挑战
- 结论
预训练模型
您可能听说过数据科学家广泛使用术语“预训练模型”。 在解释了深度学习模型/网络的作用之后,我将解释这个术语。 深度学习模型是一种包含多个层堆叠在一起的模型,以服务于一个单独的目的,例如分类、检测等。深度学习网络通过发现提供给它们的数据中的复杂结构并将权重保存在一个文件中来学习以后用于执行类似的任务。 预训练模型是已经训练好的深度学习模型。 这意味着他们已经在包含数百万张图像的庞大数据集上接受过训练。
这是 TensorFlow 网站定义预训练模型: 预训练模型是一个保存的网络,之前在大型数据集上训练过,通常是在大规模图像分类任务上。
一些高度优化和非常高效的 预训练模型 可在互联网上获得。 不同的模型用于执行不同的任务。 一些预训练模型是 VGG-16、VGG-19、YOLOv5、YOLOv3 和 残差网络 50.
使用哪种模型取决于您要执行的任务。 例如,如果我想执行一个 目标检测 任务,我将使用 YOLOv5 模型。
转移学习
转移学习 是减轻数据科学家任务的最重要技术。 训练模型是一项繁重且耗时的任务; 如果一个模型是从头开始训练的,它通常不会给出很好的结果。 即使我们训练一个类似于预训练模型的模型,它的表现也不会那么有效,而且模型训练可能需要数周时间。 相反,我们可以使用预训练模型并通过在自定义数据集上训练它们来使用已经学习的权重来执行类似的任务。 这些模型在架构和性能方面非常高效和精致,并且它们通过在不同竞赛中表现更好而跻身榜首。 这些模型是在非常大量的数据上训练的,使它们的知识更加多样化。
因此,迁移学习基本上意味着迁移通过在先前数据上训练模型获得的知识,以帮助模型更好更快地学习以执行不同但相似的任务。
比如用一个YOLOv5做object detection,但是这个object不是之前用的object的data。
什么以及为什么使用 YOLOv5?
YOLOv5 是一种预训练模型,代表你只看一次版本 5 用于实时对象检测,并已被证明在准确性和推理时间方面非常高效。 YOLO 还有其他版本,但正如人们所预测的那样,YOLOv5 的性能优于其他版本。 YOLOv5 快速且易于使用。 它基于 PyTorch 框架,该框架拥有比 Yolo v4 Darknet 更大的社区。
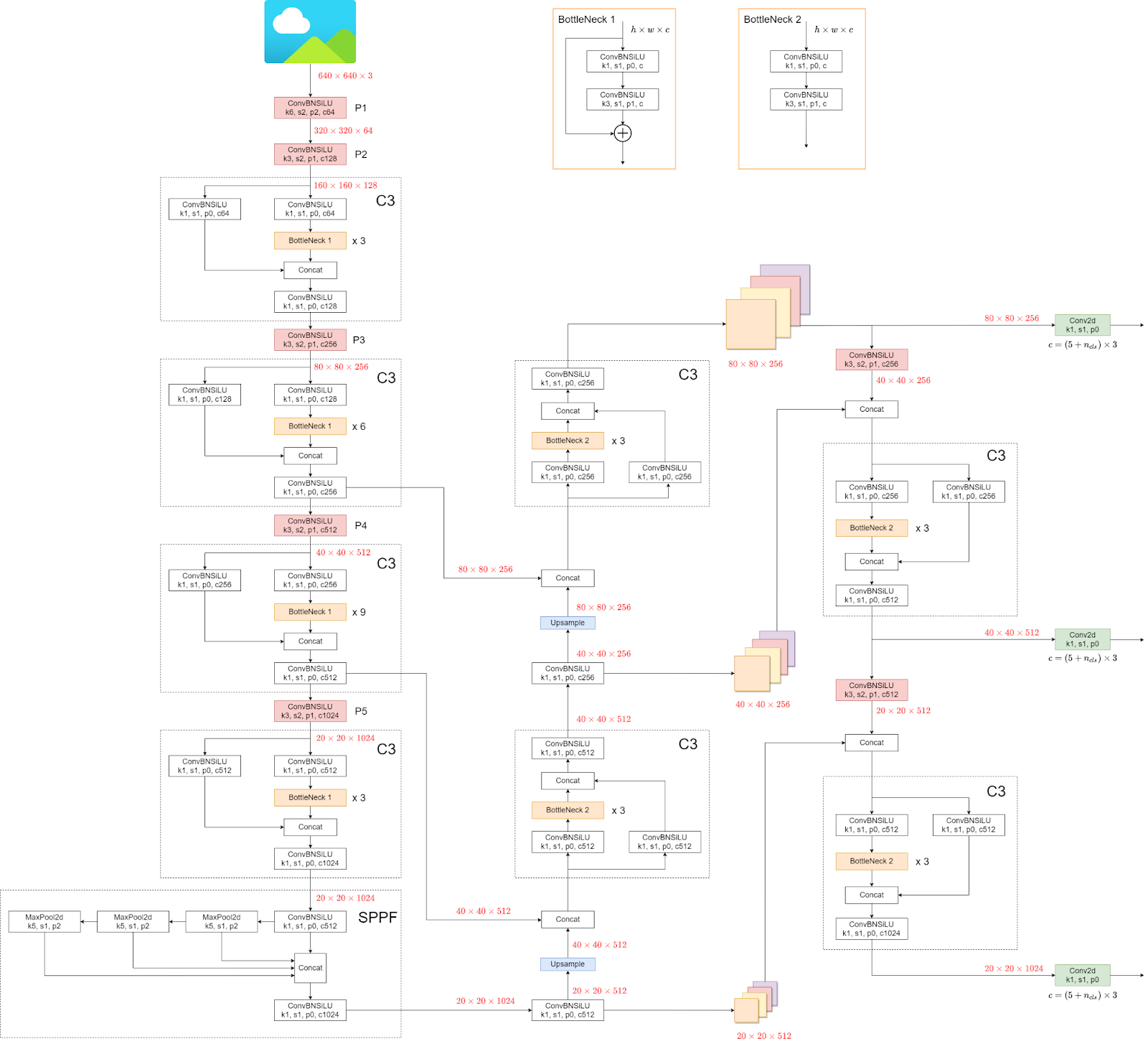
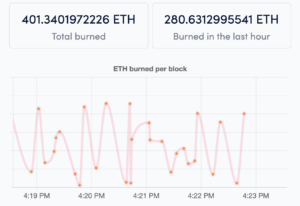
我们现在来看看 YOLOv5 的架构。
结构可能看起来很混乱,但没关系,因为我们不必看架构,而是直接使用模型和权重。
在迁移学习中,我们使用自定义数据集,即模型以前从未见过的数据或模型未训练的数据。 由于模型已经在大型数据集上进行了训练,因此我们已经有了权重。 我们现在可以在我们想要处理的数据上训练多个时期的模型。 需要进行培训,因为模型是第一次看到数据,并且需要一些知识才能执行任务。
迁移学习涉及的步骤
迁移学习是一个简单的过程,我们可以通过几个简单的步骤来完成:
- 资料准备
- 注释的正确格式
- 如果你想换几层
- 重新训练模型进行几次迭代
- 验证/测试
资料准备
如果您选择的数据有点大,数据准备可能会很耗时。 数据准备意味着对图像进行注释,这是一个通过在图像中的对象周围制作一个框来标记图像的过程。 通过这样做,标记对象的坐标将保存在一个文件中,然后将其提供给模型进行训练。 有几个网站,比如 通俗易懂的.ai 和 roboflow.com, 这可以帮助您标记数据。
以下是如何在 makesense.ai 上为 YOLOv5 模型注释数据。
1. 参观 https://www.makesense.ai/.
2. 单击屏幕右下角的开始。
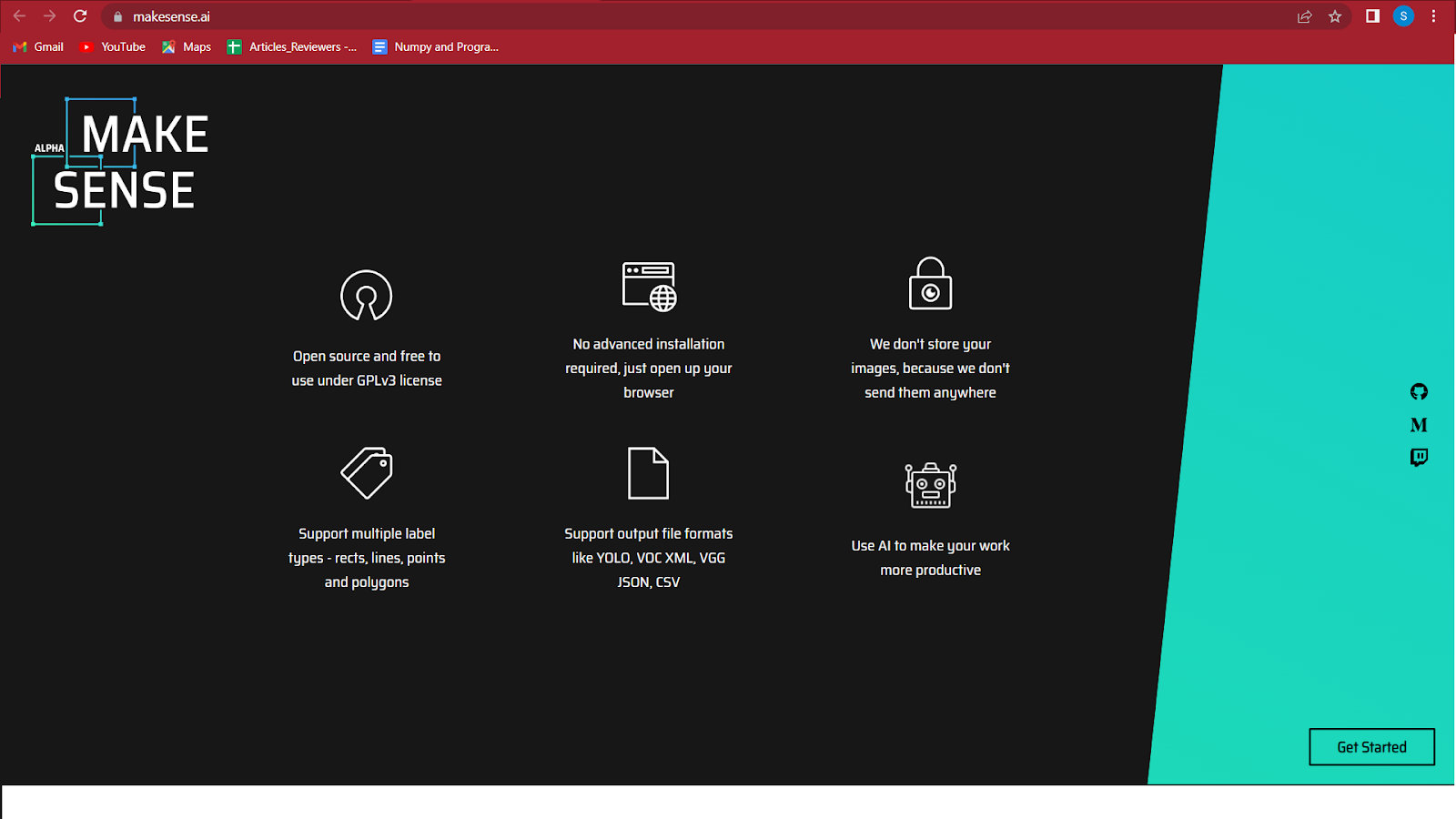
3. 通过单击在中心突出显示的框来选择要标记的图像。
加载要注释的图像并单击对象检测。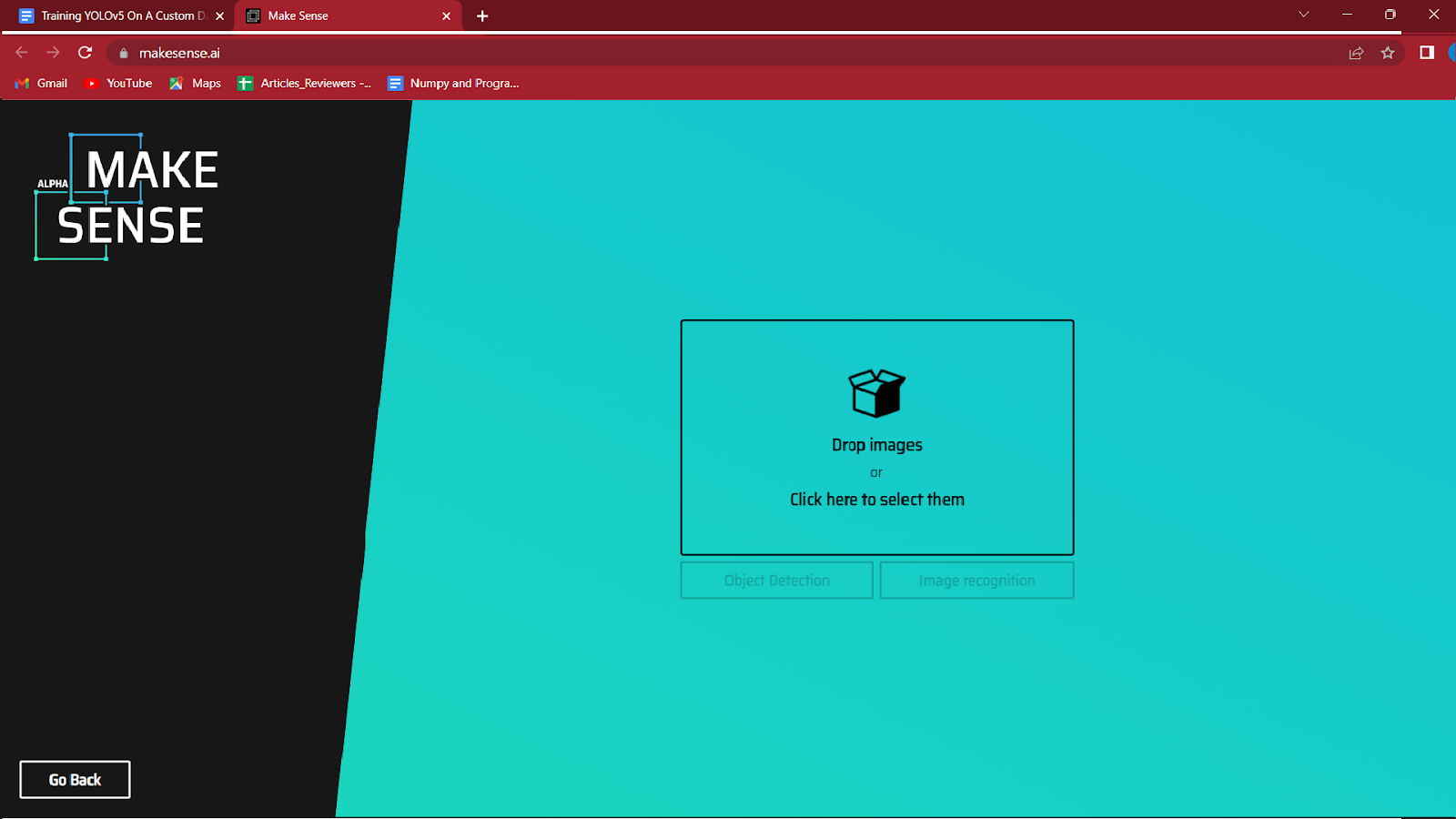
4. 加载图像后,系统会要求您为数据集的不同类别创建标签。
我正在检测车辆上的车牌,所以我将使用的唯一标签是“车牌”。 您可以通过单击对话框左侧的“+”按钮按回车键来制作更多标签。
创建所有标签后,单击开始项目。
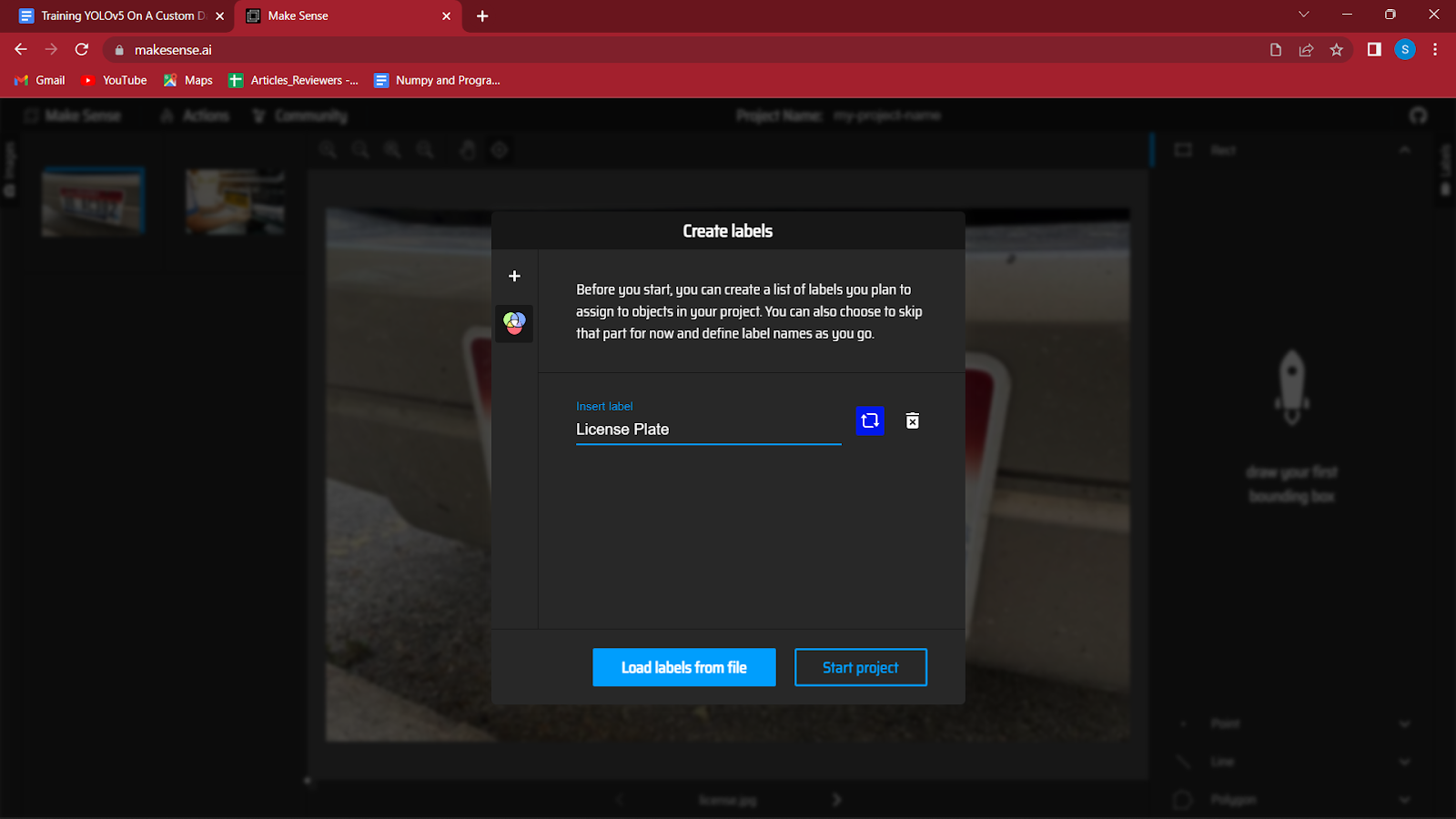
如果您遗漏了任何标签,您可以稍后通过单击操作然后编辑标签来编辑它们。
5. 开始在图像中的对象周围创建边界框。 这个练习一开始可能有点有趣,但是对于非常大的数据,它可能会很累。
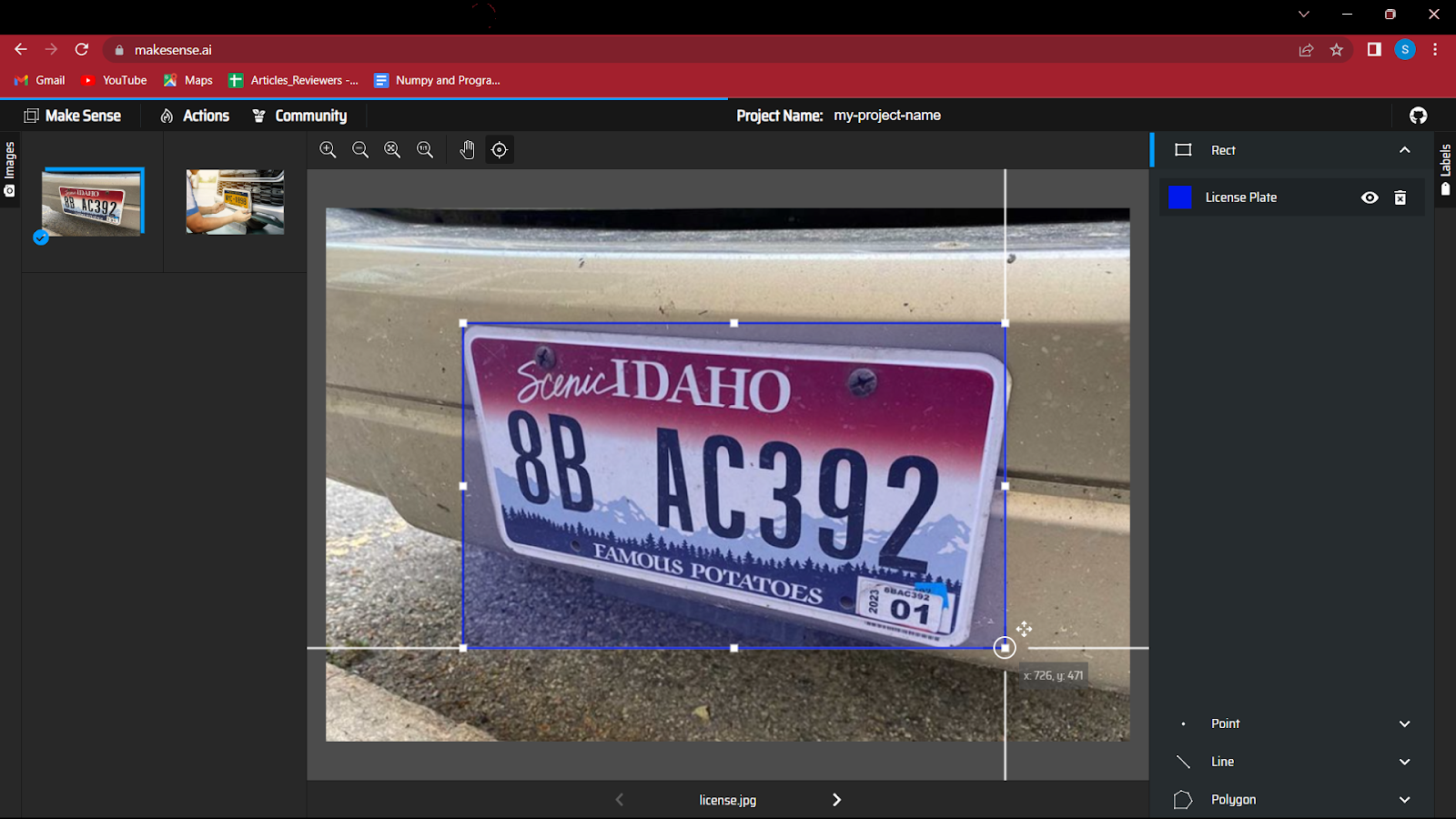
6. 注释完所有图像后,您需要保存文件,该文件将包含边界框的坐标以及类。
因此,您需要转到操作按钮并单击导出注释,不要忘记选中“包含 YOLO 格式文件的 zip 包”选项,因为这将按照 YOLO 模型的要求以正确的格式保存文件。
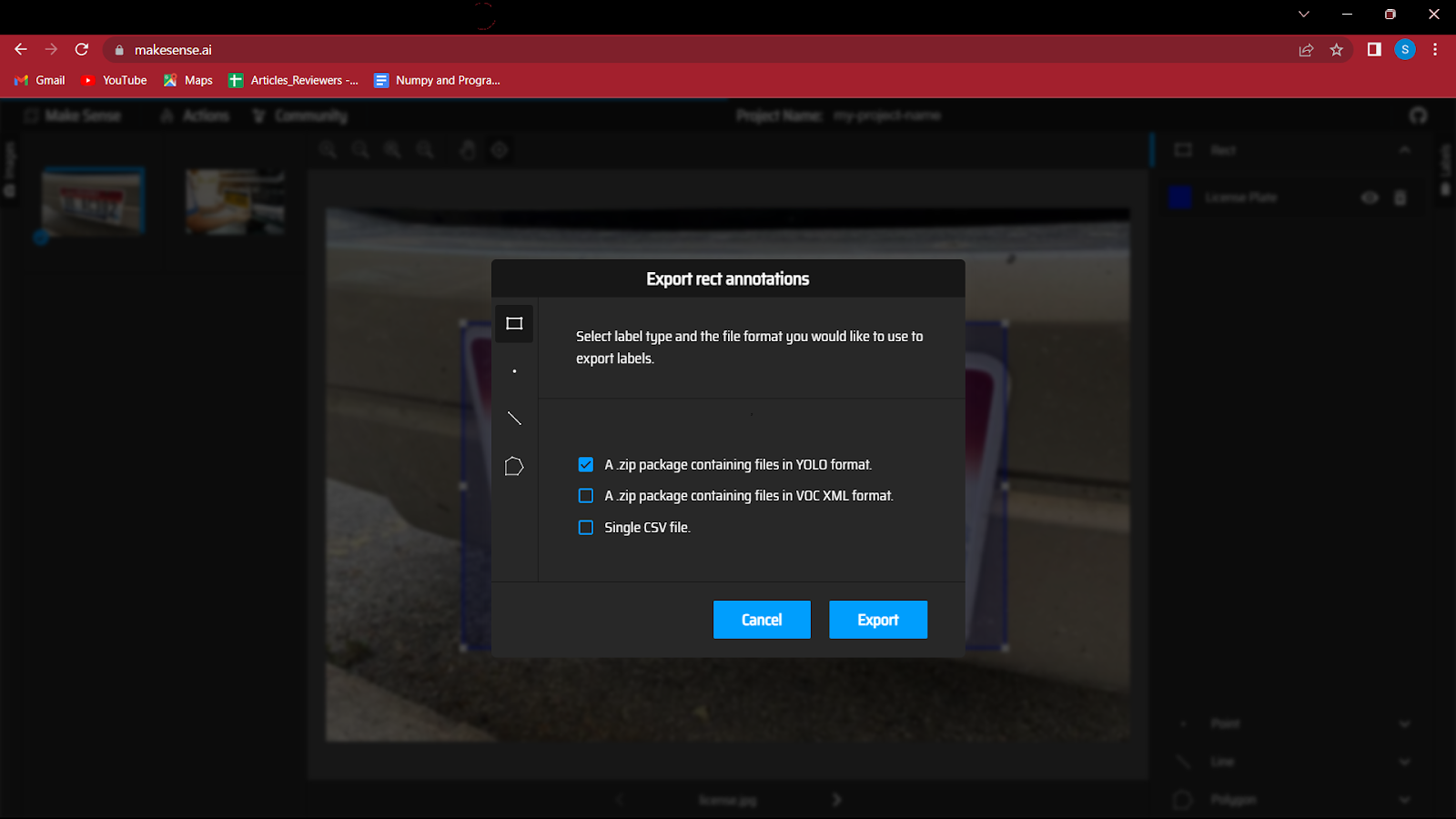
7. 这是重要的一步,因此请仔细执行。
拥有所有文件和图像后,创建一个任意名称的文件夹。 单击文件夹并在文件夹内创建两个名称为 images 和 labels 的文件夹。 不要忘记将文件夹命名为与上面相同的名称,因为在命令中输入训练路径后模型会自动搜索标签。
为了让您了解该文件夹,我创建了一个名为“CarsData”的文件夹,并在该文件夹中创建了两个文件夹——“图像”和“标签”。
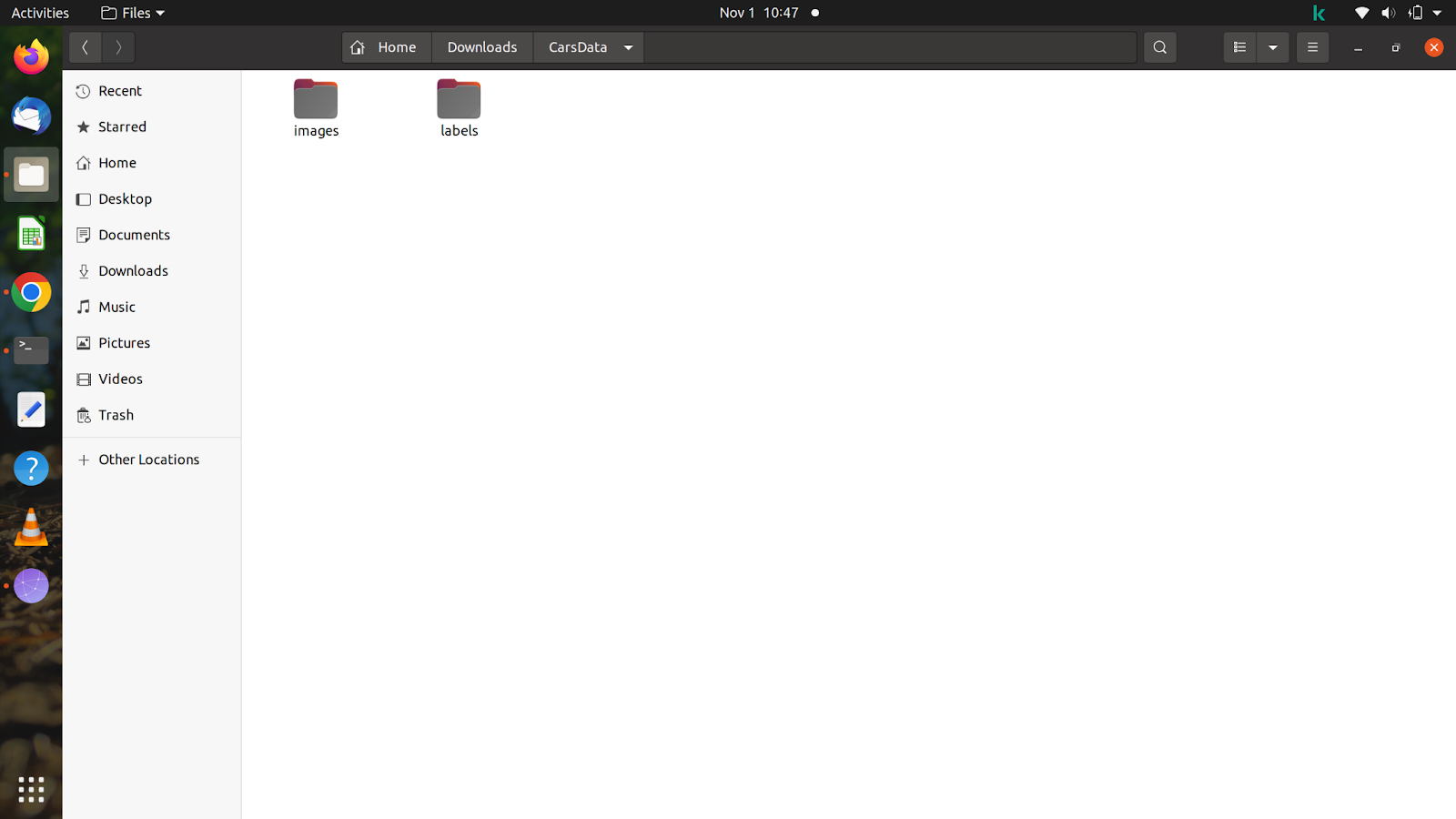
在这两个文件夹中,您必须再创建两个名为“train”和“val”的文件夹。 在images文件夹中,你可以随意分割图片,但是分割label的时候一定要小心,label要和你分割好的图片相匹配
8. 现在制作该文件夹的 zip 文件并将其上传到驱动器,以便我们可以在 colab 中使用它。
SAP系统集成计划实施
现在我们将进入实现部分,这非常简单但也很棘手。 如果您不知道要准确更改哪些文件,您将无法在自定义数据集上训练模型。
下面是在自定义数据集上训练 YOLOv5 模型时应遵循的代码
我建议您在本教程中使用 google colab,因为它还提供 GPU,可以提供更快的计算速度。
1. !git 克隆 https://github.com/ultralytics/yolov5
这将制作 YOLOv5 存储库的副本,该存储库是由 ultralytics 创建的 GitHub 存储库。
2. cd yolov5
这是一个命令行 shell 命令,用于将当前工作目录更改为 YOLOv5 目录。
3. !pip install -rrequirements.txt
此命令将安装用于训练模型的所有包和库。
4. !unzip '/content/drive/MyDrive/CarsData.zip'
在google colab中解压包含图片和标签的文件夹
这是最重要的一步......
您现在已经执行了几乎所有步骤,需要再编写一行代码来训练模型,但是,在此之前,您需要执行更多步骤并更改一些目录以提供自定义数据集的路径并根据该数据训练您的模型。
这是你需要做的。
执行上述 4 个步骤后,您将在您的 google colab 中拥有 yolov5 文件夹。 转到 yolov5 文件夹,然后单击“数据”文件夹。 现在您将看到一个名为“coco128.yaml”的文件夹。
继续下载这个文件夹。
下载文件夹后,您需要对其进行一些更改并将其上传回您下载它的同一文件夹。
现在让我们看看我们下载的文件的内容,它看起来像这样。
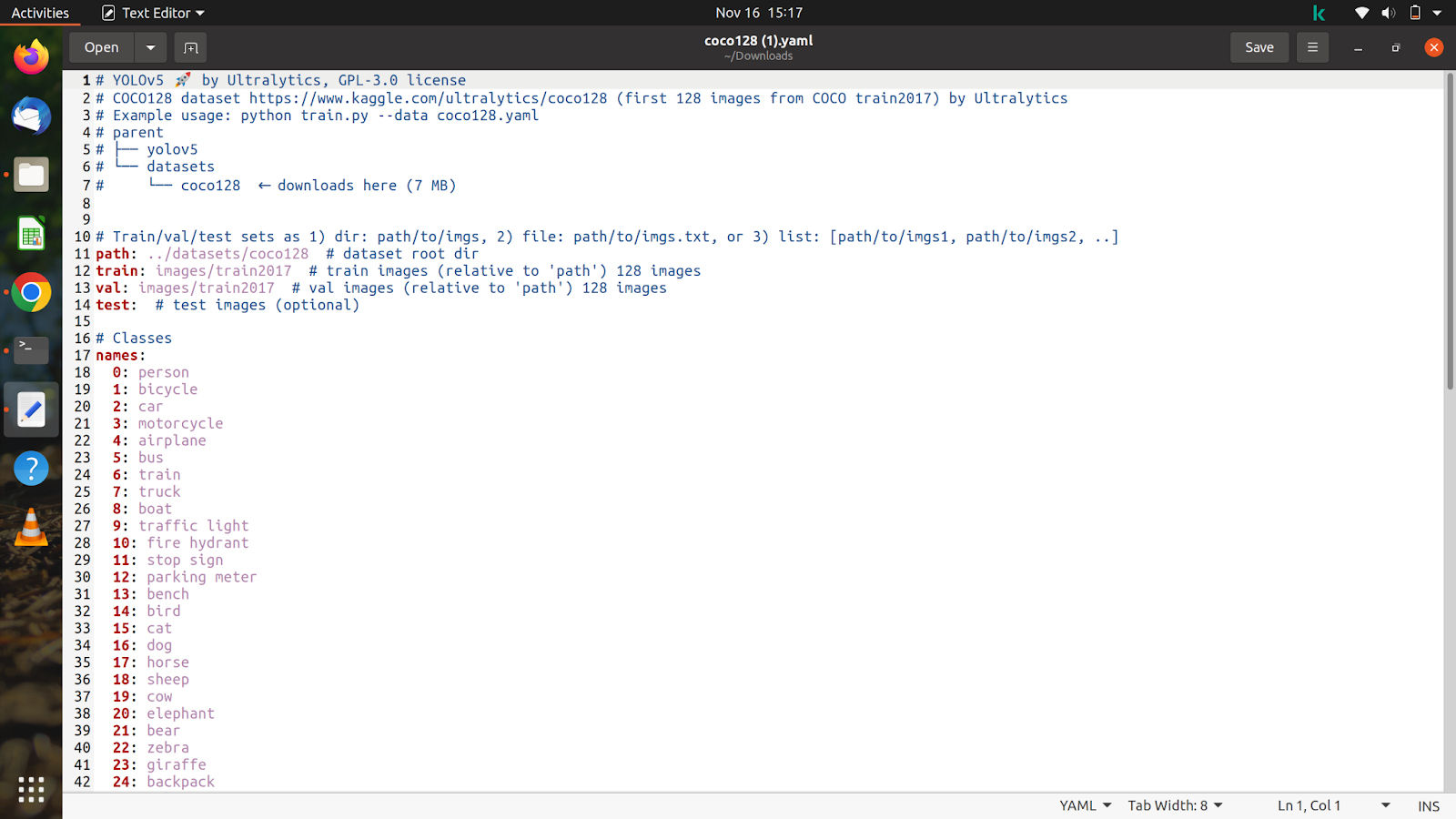
我们将根据我们的数据集和注释自定义此文件。
我们已经在 colab 上解压缩了数据集,因此我们将复制训练图像和验证图像的路径。 复制火车图像的路径后,将位于数据集文件夹中,看起来像这样“/content/yolov5/CarsData/images/train”,将其粘贴到我们刚刚下载的 coco128.yaml 文件中。
对测试和验证图像执行相同操作。
完成此操作后,我们将提及类的数量,如“nc: 1”。 在这种情况下,类的数量只有 1。然后我们将提及名称,如下图所示。 删除所有其他类和不需要的注释部分,之后我们的文件应该看起来像这样。
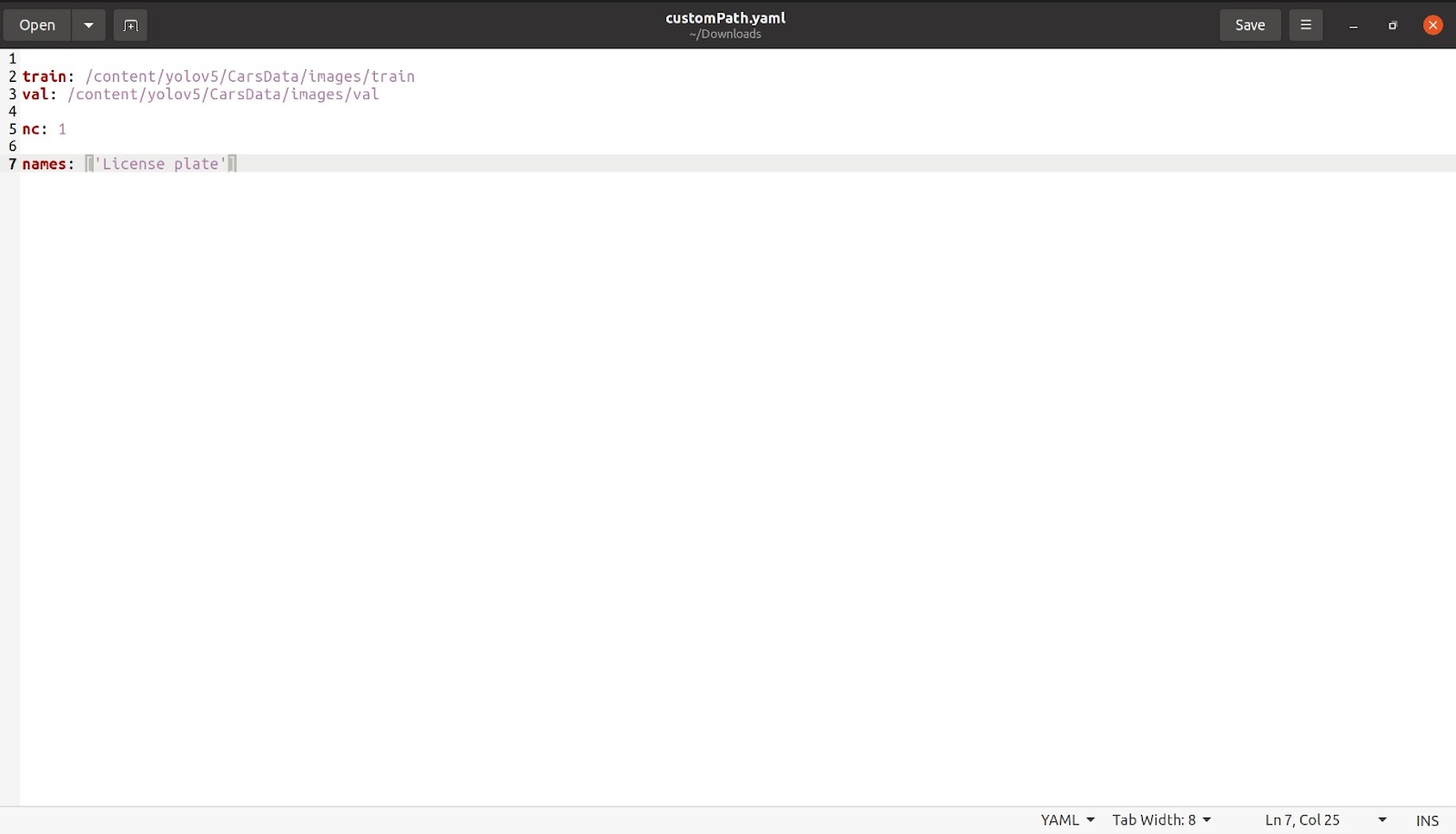
使用您想要的任何名称保存此文件。 我保存了名为 customPath.yaml 的文件,现在将此文件上传回 coco128.yaml 所在的同一位置的 colab。
现在我们完成了编辑部分并准备好训练模型。
运行以下命令来训练您的模型以在您的自定义数据集上进行一些交互。
不要忘记更改您上传的文件的名称('customPath.yaml)。 您还可以更改要训练模型的时期数。 在这种情况下,我将只训练模型 3 个时期。
5. !python train.py –img 640 –batch 16 –epochs 10 –data /content/yolov5/customPath.yaml –weights yolov5s.pt
请记住上传文件夹的路径。 如果更改路径,则命令将根本不起作用。
运行此命令后,您的模型应该开始训练,您将在屏幕上看到类似这样的内容。
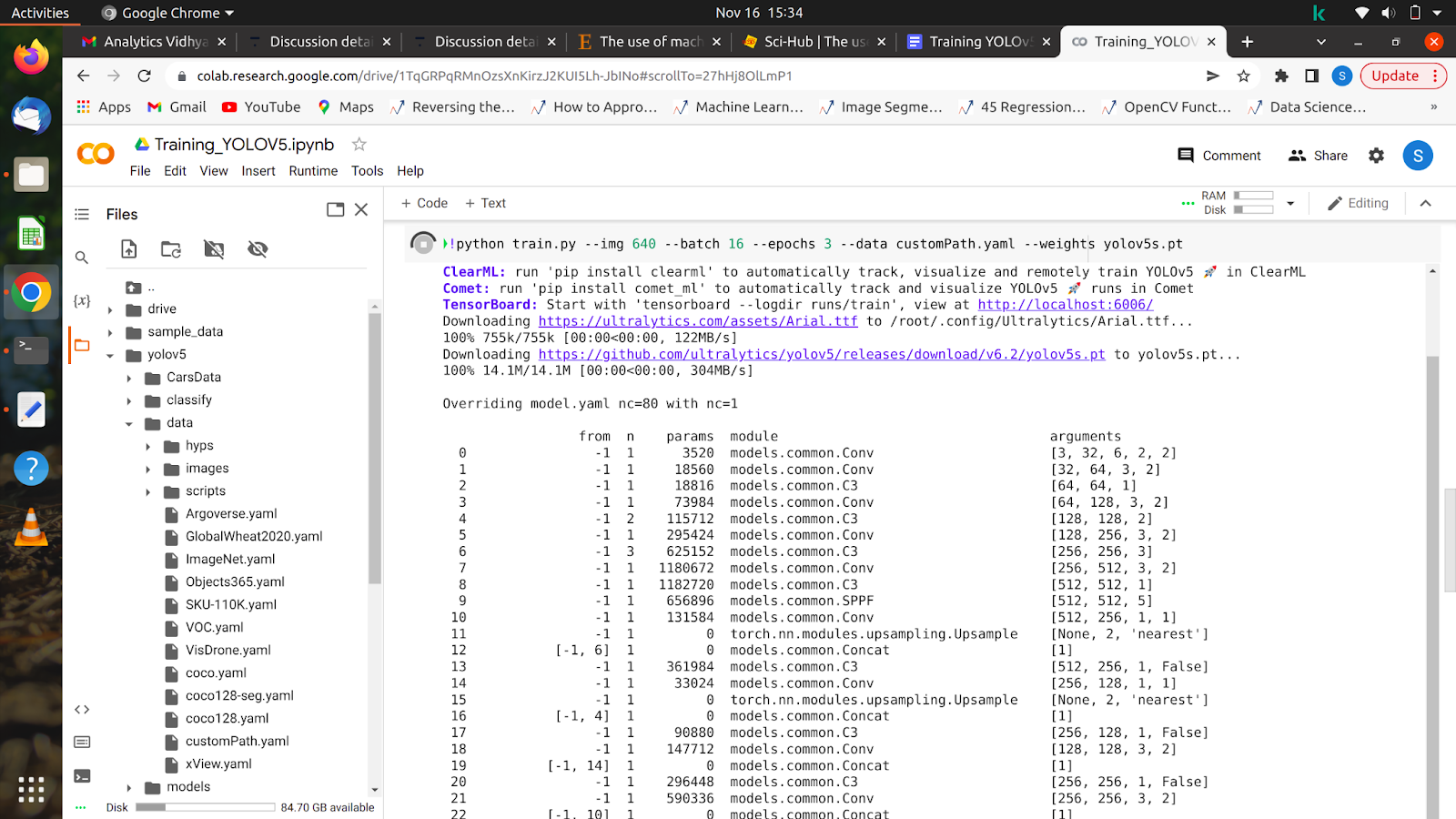
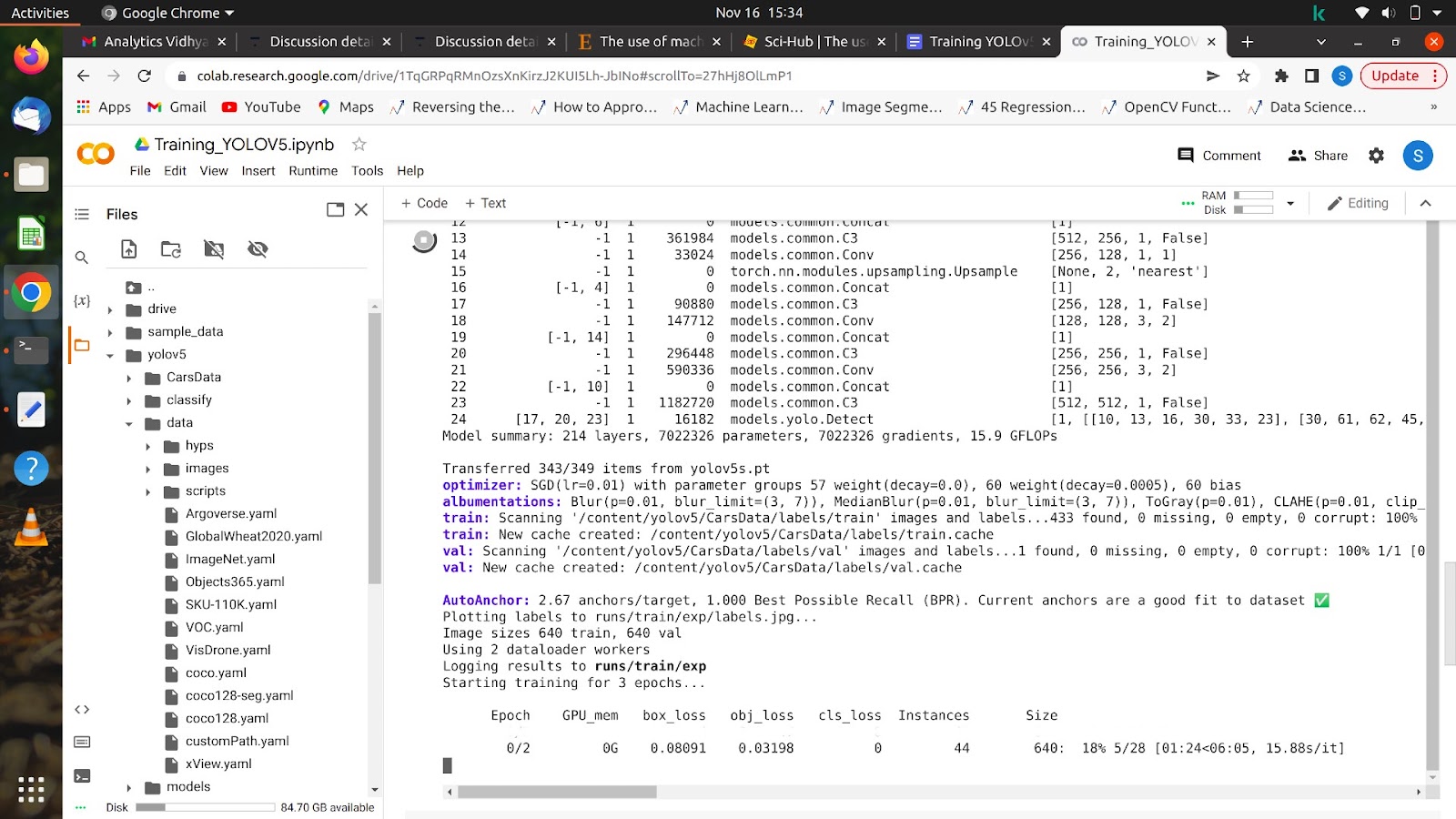
在完成所有 epoch 后,您的模型可以在任何图像上进行测试。
您可以在 detect.py 文件中对要保存的内容和不喜欢的内容、检测牌照的检测等进行更多自定义。
6. !python detector.py –weight /content/yolov5/runs/train/exp/weights/best.pt –source path_of_the_image
您可以使用此命令来测试模型对某些图像的预测。
您可能面临的一些挑战
尽管上面解释的步骤是正确的,但如果不严格按照这些步骤操作,您可能会遇到一些问题。
- 错误的路径:这可能是一个令人头疼的问题。 如果你在训练图像的时候某处输入了错误的路径,就不容易识别,你就无法训练模型。
- 标签格式错误:这是人们在训练 YOLOv5 时普遍面临的问题。 该模型只接受一种格式,其中每个图像都有自己的文本文件,其中包含所需的格式。 通常,XLS 格式文件或单个 CSV 文件被提供给网络,从而导致错误。 如果您从某个地方下载数据,而不是对每张图像进行注释,则可以使用不同的文件格式来保存标签。 这里有一篇将XLS格式转换成YOLO格式的文章。 (文章完成后链接)。
- 未正确命名文件:未正确命名文件将再次导致错误。 命名文件夹时注意步骤,避免出现此错误。
结论
在本文中,我们了解了迁移学习是什么以及预训练模型。 我们了解了何时以及为何使用 YOLOv5 模型以及如何在自定义数据集上训练模型。 我们经历了每一个步骤,从准备数据集到更改路径,最后将它们提供给网络以实现该技术,并彻底理解了这些步骤。 我们还研究了在训练 YOLOv5 时面临的常见问题及其解决方案。 我希望本文能帮助您在自定义数据集上训练您的第一个 YOLOv5,并且您喜欢这篇文章。
有关
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- Able
- 以上
- 接受
- 根据
- 行动
- 后
- 向前
- AI
- 所有类型
- 已经
- 量
- 和
- 架构
- 围绕
- 刊文
- 关注我们
- 自动
- 可使用
- 避免
- 背部
- 基于
- 基本上
- before
- 如下。
- 更好
- 位
- 半身裙/裤
- 盒子
- 箱
- 按键
- 小心
- 小心
- 案件
- CD
- Center
- 挑战
- 更改
- 更改
- 改变
- 查
- 选择
- 程
- 类
- 分类
- 码
- 如何
- 评论
- 相当常见
- 社体的一部分
- 完成
- 完成
- 复杂
- 计算
- 扑朔迷离
- 包含
- 内容
- 兑换
- 仿形
- 正确地
- 创建信息图
- 创建
- 创造
- 电流
- 习俗
- 定制
- 定制
- 暗网
- data
- 资料准备
- 数据科学家
- 深
- 深入学习
- 定义
- 依靠
- 检测
- 检测
- 对话
- 不同
- 直接
- 目录
- 发现
- 不同
- 做
- 别
- 下载
- 驾驶
- 每
- 例
- 教育
- 有效
- 只
- 高效
- 输入
- 进入
- 时代
- 错误
- 等
- 甚至
- 所有的
- 究竟
- 例子
- 锻炼
- 说明
- 解释
- 说明
- 出口
- 异常地
- 面部彩妆
- 面临
- 高效率
- 快
- 美联储
- 喂养
- 少数
- 文件
- 档
- 终于
- 姓氏:
- 第一次
- 专注焦点
- 遵循
- 以下
- 格式
- 骨架
- 止
- 开玩笑
- 得到
- GitHub上
- 给
- Go
- 去
- 非常好
- 谷歌
- GPU
- 头
- 听说
- 帮助
- 帮助
- 点击此处
- 突出
- 高度
- 打
- 抱有希望
- 创新中心
- How To
- HTTPS
- 巨大
- 主意
- 鉴定
- 鉴定
- 图片
- 图片
- 履行
- 重要
- in
- 原来
- 安装
- 代替
- 互动
- 网络
- 参与
- IT
- 知道
- 知识
- 标签
- 标签
- 大
- 大规模
- 大
- 层
- 铅
- 学习用品
- 知道
- 学习
- 库
- 执照
- Line
- 友情链接
- 装载
- 看
- 看着
- LOOKS
- 制成
- 使
- 制作
- 标
- 匹配
- 问题
- 最大宽度
- 手段
- 方法
- 可能
- 百万
- 介意
- 模型
- 模型
- 更多
- 最先进的
- 姓名
- 命名
- 命名
- 需求
- 打印车票
- 网络
- 网络
- 数
- 对象
- 物体检测
- 一
- 优化
- 附加选项
- 秩序
- 其他名称
- 己
- 包
- 包
- 部分
- 径
- 员工
- 演出
- 性能
- 执行
- 施行
- 地方
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 预测
- 预测
- 准备
- 以前
- 先前
- 市场问题
- 问题
- 过程
- 项目
- 成熟
- 提供
- 目的
- pytorch
- 准备
- 实时的
- 最近
- 建议
- 精
- 去掉
- 知识库
- 要求
- 必须
- 岗位要求
- 导致
- 成果
- 运行
- 同
- 保存
- 保存
- 科学家
- 科学家
- 屏风
- 服务
- 壳
- 应该
- 显示
- 如图
- 显著
- 类似
- 简易
- 只是
- 自
- 单
- So
- 方案,
- 一些
- 东西
- 某处
- 分裂
- 堆叠
- 看台
- 开始
- 开始
- 步
- 步骤
- 结构体
- 这样
- 采取
- 任务
- 任务
- 专业技术
- 条款
- test
- 其
- 透
- 通过
- 次
- 耗时的
- 至
- 一起
- 最佳
- 培训
- 熟练
- 产品培训
- 转让
- 传输
- 教程
- 一般
- 理解
- 了解
- 使用
- 平时
- 验证
- 各个
- 汽车
- 版本
- 您的网站
- 网站
- 周
- 什么是
- 这
- 而
- 广泛
- 广泛
- 将
- 也完全不需要
- 工作
- 加工
- 将
- 写
- 错误
- 雅姆
- YOLO
- 您一站式解决方案
- 和风网
- 压缩