我们最近宣布全面推出 亚马逊 OpenSearch 无服务器 ,一个新的选择 亚马逊开放搜索服务 这使得运行大规模搜索和分析工作负载变得轻松,而无需配置、管理或扩展 OpenSearch 集群。 借助 OpenSearch Serverless,您可以获得与 OpenSearch Service 相同的交互式毫秒响应时间,同时具有无服务器环境的简单性。
在本文中,您将了解如何使用 Logstash 将现有索引从 OpenSearch Service 托管集群域迁移到无服务器集合。
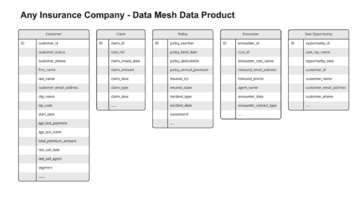
借助 OpenSearch 域,您可以在几分钟内为您的工作负载配置和优化专用、安全的集群。 您可以完全控制集群中计算、内存和存储资源的配置,以优化应用程序的成本和性能。 OpenSearch Serverless 提供了一种更简单的方法来运行搜索和分析工作负载,而无需考虑集群。 您只需创建一个集合和一组索引,就可以开始摄取和查询数据。
解决方案概述
Logstash 是为您的数据提供 ETL(提取、转换和加载)的开源软件。 您可以将 Logstash 配置为通过输入和输出插件连接到源和目标。 在此期间,您配置可以转换数据的过滤器。 这篇文章将引导您完成设置 Logstash 以将 OpenSearch 服务域(输入)连接到 OpenSearch 无服务器集合(输出)所需的步骤。
您在 Logstash 的配置文件中设置源插件和目标插件。 配置文件包含以下部分 Input, Filter及 Output. 配置完成后,Logstash 将向 OpenSearch Service 域发送请求,并根据您放入的查询读取数据 input 部分。 从 OpenSearch 服务读取数据后,您可以选择将其发送到下一阶段 Filter 用于转换,例如从输入数据中添加或删除字段或使用不同的值更新字段。 在此示例中,您不会使用 Filter 插入。 接下来是 Output 插入。 Logstash 的开源版本 (Logstash OSS) 提供了一种使用批量 API 将数据上传到您的集合的便捷方式。 OpenSearch Serverless 支持 logstash-输出-opensearch 输出插件,支持 AWS身份和访问管理 (IAM) 数据访问控制凭证。
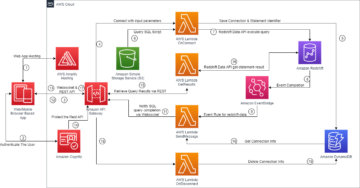
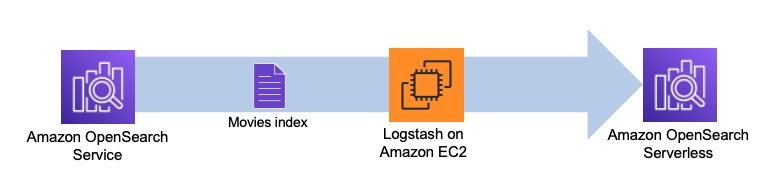
下图说明了我们的解决方案工作流程。
先决条件
在开始之前,请确保您已完成以下先决条件:
- 记下您的 OpenSearch 服务域的 ARN、用户名和密码。
- 创建一个 OpenSearch 无服务器集合。 如果您不熟悉 OpenSearch Serverless,请参阅 使用 Amazon OpenSearch Serverless 轻松进行日志分析 有关如何设置收藏的详细信息。
为 OpenSearch 设置 Logstash 和输入输出插件
完成以下步骤以设置 Logstash 和您的插件:
- 下载
logstash-oss-with-opensearch-output-plugin. (此示例使用 macos-x64 发行版。对于其他发行版,请参阅 文物.) - 提取下载的压缩包:
- 更新
logstash-output-opensearch插件到最新版本: - 安装
logstash-input-opensearch插入:
测试插件
让我们开始行动,看看插件是如何工作的。 以下配置文件从中检索数据 movies 在您的 OpenSearch 服务域中建立索引,并使用相同的索引名称为您的 OpenSearch Serverless 集合中的数据建立索引, movies.
新建一个文件并添加以下内容,然后将文件另存为 opensearch-serverless-migration.conf. 在下面提供 OpenSearch 服务域端点的值 HOST, USERNAME及 密码 ,在 input 部分,以及下面的 OpenSearch Serverless 收集端点详细信息 HOST 随着 地区, AWS_ACCESS_KEY_ID及 AWS_SECRET_ACCESS_KEY ,在 output 部分。
您可以在 input 前面配置的部分。 这 match_all 查询匹配中的所有数据 movies 指数。 如果要选择数据的子集,您可以更改查询。 您还可以通过使用指定不同数据切片的配置运行多个 Logstash 进程,使用查询来并行化数据传输。 您还可以通过针对多个索引运行 Logstash 进程来并行化(如果有的话)。
启动 Logstash
使用以下命令启动 Logstash:
运行该命令后,Logstash 将从您的 OpenSearch 服务域的源索引中检索数据,并将数据写入您的 OpenSearch Serverless 集合中的目标索引。 数据传输完成后,Logstash 将关闭。 请参见以下代码:
验证 OpenSearch Serverless 中的数据
您可以通过比较您域中的文档数和您的集合来验证 Logstash 是否复制了您的所有数据。 从 开发工具 选项卡,或与 curl, postman,或类似的 HTTP 客户端。 以下查询可帮助您搜索来自 movies 索引并返回排名靠前的文档以及计数。 默认情况下,OpenSearch 将返回最多 10,000 个文档计数。 添加 track_total_hits 如果文档计数超过 10,000,标志可帮助您获取文档的准确计数。
结论
在本文中,您使用 Logstash 的 OpenSearch 输入和输出插件将数据从 OpenSearch 服务域迁移到 OpenSearch Serverless 集合。
请继续关注一系列帖子,这些帖子重点介绍可供您使用 OpenSearch Serverless 构建有效日志分析和搜索解决方案的各种选项。 您也可以参考 Amazon OpenSearch 无服务器入门 研讨会以了解有关 OpenSearch Serverless 的更多信息。
如果您对这篇文章有任何反馈,请在评论部分提交。 如果您对这篇文章有任何疑问,请在 亚马逊开放搜索服务论坛 or 联系 AWS 支持.
关于作者
 Prashant Agrawal 是 Amazon OpenSearch Service 的高级搜索专家解决方案架构师。 他与客户密切合作,帮助他们将工作负载迁移到云端,并帮助现有客户微调他们的集群以获得更好的性能并节省成本。 在加入 AWS 之前,他帮助各种客户将 OpenSearch 和 Elasticsearch 用于他们的搜索和日志分析用例。 不工作时,您会发现他在旅行和探索新地方。 简而言之,他喜欢做 Eat → Travel → Repeat。
Prashant Agrawal 是 Amazon OpenSearch Service 的高级搜索专家解决方案架构师。 他与客户密切合作,帮助他们将工作负载迁移到云端,并帮助现有客户微调他们的集群以获得更好的性能并节省成本。 在加入 AWS 之前,他帮助各种客户将 OpenSearch 和 Elasticsearch 用于他们的搜索和日志分析用例。 不工作时,您会发现他在旅行和探索新地方。 简而言之,他喜欢做 Eat → Travel → Repeat。
 乔恩汉德勒 (@_searchgeek) 是位于加利福尼亚州帕洛阿尔托的 Amazon Web Services 的高级首席解决方案架构师。 Jon 与 CloudSearch 和 Elasticsearch 团队密切合作,为拥有希望迁移到 AWS 云的搜索工作负载的广泛客户提供帮助和指导。 在加入 AWS 之前,Jon 的软件开发人员职业生涯包括四年的大型电子商务搜索引擎编码工作。
乔恩汉德勒 (@_searchgeek) 是位于加利福尼亚州帕洛阿尔托的 Amazon Web Services 的高级首席解决方案架构师。 Jon 与 CloudSearch 和 Elasticsearch 团队密切合作,为拥有希望迁移到 AWS 云的搜索工作负载的广泛客户提供帮助和指导。 在加入 AWS 之前,Jon 的软件开发人员职业生涯包括四年的大型电子商务搜索引擎编码工作。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/migrate-your-indexes-to-amazon-opensearch-serverless-with-logstash/
- 000
- 10
- 100
- 28
- 39
- 7
- a
- 关于
- ACCESS
- 根据
- 操作
- 后
- 驳
- 经纪人
- 所有类型
- Amazon
- 亚马逊网络服务
- 分析
- 和
- 公布
- API
- 应用领域
- 可用性
- 可使用
- AWS
- 基于
- before
- 更好
- 之间
- 广阔
- 建立
- CA
- 寻找工作
- 例
- CD
- 更改
- 客户
- 密切
- 云端技术
- 簇
- 码
- 编码
- 采集
- 收藏
- 注释
- 比较
- 完成
- 完成
- 计算
- 配置
- 分享链接
- 内容
- 控制
- 便捷
- 价格
- 创建信息图
- 资历
- 合作伙伴
- data
- 数据访问
- 专用
- 默认
- 目的地
- 详情
- 开发商
- 不同
- 禁用
- 文件
- 文件
- 做
- 域
- 域名
- 向下
- 吃
- 电子商务
- 有效
- 或
- Elasticsearch
- 端点
- 发动机
- 环境
- 醚(ETH)
- 甚至
- EVER
- 例子
- 超过
- 现有
- 探索
- 提取
- 反馈
- 部分
- 文件
- 过滤器
- 找到最适合您的地方
- 聚焦
- 以下
- 止
- ,
- 其他咨询
- 得到
- 越来越
- 团队
- 有
- 帮助
- 帮助
- 帮助
- 创新中心
- How To
- HTTPS
- IAM
- 身分
- in
- 包括
- 指数
- 指标
- 指数
- info
- 输入
- 安装
- 互动
- IT
- 加盟
- 知道
- 大规模
- 最新
- 学习用品
- 加载
- 主要
- 使
- 制作
- 管理
- 管理
- 最多
- 内存
- 迁移
- 毫秒
- 分钟
- 更多
- 移动
- 电影
- 多
- 姓名
- 需求
- 全新
- 下页
- 开放源码
- 开源软件
- 优化
- 优化
- 附加选项
- 附加选项
- 我们
- 其他名称
- 帕洛阿尔托
- 密码
- 性能
- 管道
- 地方
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 插入
- 插件
- 帖子
- 帖子
- 先决条件
- 校长
- 先
- 过程
- 提供
- 提供
- 优
- 放
- 有疑问吗?
- 范围
- 阅读
- 最近
- 地区
- 注册处
- 去除
- 删除
- 重复
- 请求
- 资源
- 响应
- 回报
- 回报
- 运行
- 亚军
- 运行
- 同
- 保存
- 鳞片
- 搜索
- 搜索引擎
- 部分
- 部分
- 安全
- 系列
- 无服务器
- 服务
- 特色服务
- 集
- 短
- 关闭
- 关闭
- 类似
- 简单
- 只是
- 软件
- 方案,
- 解决方案
- 来源
- 专家
- 阶段
- 开始
- 开始
- 步骤
- 存储
- 提交
- 顺利
- 这样
- 支持
- 队
- 其
- 通过
- 时
- 至
- 最佳
- 转让
- 改造
- 转换
- 旅行
- 旅游
- true
- 下
- 更新
- 更新
- 使用
- 用户
- 价值观
- 各个
- 确认
- 版本
- 通过
- 卷筒纸
- Web服务
- 这
- WHO
- 将
- 也完全不需要
- 工作流程
- 加工
- 合作
- 车间
- 工作坊
- 写
- 年
- 您一站式解决方案
- 和风网