您是否曾经等待过那个显示“已发货”的昂贵包裹,但您不知道它在哪里? 五天前跟踪历史停止更新,你几乎绝望了。 但是等一下,11 天后,它就在您家门口。 您希望可追溯性可以更好,以减轻您所有焦急的等待。 这就是“可观察性”发挥作用的地方。
在技术领域,您希望避免这种情况发生在您的软件或数据系统上。 因此,您采用监控工具,收集系统的日志和指标,并通知您它们的内部状态。 当您希望系统通知您错误是什么、发生的地点和时间,但它不会告诉您如何解决错误时,监控最有效。
十多年前,监控工具缺乏对底层系统问题的背景和远见,团队将仅限于调试日常操作错误。 今天,我们工作和生活在一个由微服务和 数据管道; 即使使用多种监控工具也无法帮助您回答诸如“为什么我的应用程序总是很慢?”之类的业务问题。 或者“问题发生在什么阶段,它在堆栈中有多深?” 或“我怎样才能改善环境的整体性能?” 有必要主动做出这些决定并全面了解您的系统、应用程序和数据。
本篇 博客文章 由 Etsy 发表于十年前,它在第二段中陈述了事实:
“应用程序指标通常是三者中最难但也是最重要的。 它们非常适合您的业务,并且会随着您的应用程序的变化而变化(Etsy 变化很大)。”
那么,我们如何衡量一切? 我们从可观察性开始。
什么是可观察性?
“可观察性”一词是 创造 由 Rudolf Emil Kálmán 于 1960 年在他的工程论文中描述数学控制系统。 他将其定义为衡量一个系统的内部状态可以从其外部输出的知识中推断出来的程度。 但这听起来不像监控吗? 基本上,是的,它是监控。
如今,可观察性已成为一个热门话题。 根据多项市场调查,它是一个价值数十亿美元的平台。 许多组织已经采用了这个概念并将其用作分布式系统和管道的端到端可见性的框架。 但是,可观察性与监视相混淆。 现在,我可以说监控是可观察性的一个子集,可观察性是一个大的总称。
可观察性允许通过收集和聚合跟踪、日志和指标进行分布式跟踪。 让我们看看这些推断是什么:
- 痕迹: 当系统收到请求时,跟踪会告诉您该请求在整个生命周期中如何从源流向目标。 跟踪由“跨度”表示。 跟踪是跨度树,跨度是跟踪中的单个操作。 它们帮助您定位系统中的错误、延迟或瓶颈。
- 日志: 这些是机器生成的带有时间戳的事件,告诉您系统中发生的操作或更改。 日志通常用于查询系统中的这些错误或更改。
- 指标: 这些提供了有关 CPU、内存、磁盘使用情况以及系统在一段时间内的性能的定量见解。
这些属性增强了具有可追溯性的监控框架。 Traceability 为您提供了跟踪调用系统的请求的镜头,从一个组件遍历到另一个组件需要多长时间,它调用了哪些其他服务,它是否抛出任何错误,它产生了什么日志,它处于什么状态是在什么时候开始和结束,它在你的系统中停留的时间线是什么等等。当你收集、汇总和分析这些痕迹时,你能够做出有价值的明智决策,比如电子商务网站上的客户时间线,他们搜索产品需要多长时间,他们查看产品需要多长时间,HTML 页面是否加载了图像或嵌入式视频等完整详细信息,系统需要多长时间来验证和处理付款等。
我们在分布式环境中通过可观察性实现了什么?
当组织开始从他们的集中式单体架构转向分布式和分散式微服务架构时,分布式系统的演变就开始了。 这项工作仍在进行中,许多组织正在接受系统和应用程序的微服务特性。 而这一切都可以归因于 大数据 和缩放。 管理分布式环境需要持续学习、额外的劳动力、框架和政策的变化、IT 管理等。 这确实是一个很大的变化。
早些时候,在有限的单一环境中,硬件、软件、数据和数据库都位于同一个屋檐下。 随着 2000 年代大数据的出现,监控和扩展系统开始成为一个巨大的问题。 通常,组织采用不同的监控工具来满足其各种应用程序的需求。 因此,它很快成为一种运营开销,弹性、可见性和可靠性都很差。
所有这些问题都导致了可观察性的采用。 如今,存在多种可观察性工具用于安全、网络、应用程序和数据管道,以便在复杂环境中进行分布式跟踪。 它们与它们的表亲、监控工具共存,并利用从它们的表亲那里收集信息并从其自身的跟踪数据中聚合额外信息。
所有这些系统中都有很多移动组件,捕获它们的痕迹可以说明 5W 的故事:何时、何地、为什么、什么以及如何。 例如,您在下午 1:43 访问 DATAVERSITY 的网站阅读一些博客文章。 当您点击 dataversity.net 时,HTTP 请求会记录到系统中。 您开始搜索博客文章并转到数据治理帖子,您花了 17 分钟阅读该帖子,然后在下午 2:00 关闭选项卡
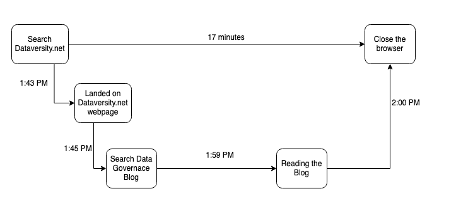
还将对网络系统进行其他调用以捕获网络数据包。 可观察性工具收集所有跨度并将它们统一在一个或多个跟踪中,使您能够看到它在其生命周期中形成的路径。 如果您遇到网络延迟或系统缺陷等问题,现在可以更轻松地剖析(剥洋葱)和调试问题(错误在哪一层)。
现在在大型分布式环境中,当您的应用程序收到数百万个请求时,跟踪数据会海量增长。 收集和分析这些痕迹对于存储消耗和数据传输来说是昂贵的。 所以,为了节省成本,对跟踪数据进行了采样,因为在大多数情况下,工程团队只需要其中的一部分来调查哪里出了问题或者错误模式是什么。
通过这个小例子,我们了解到我们对我们的系统有了更深入的了解。 因此,考虑到更大规模的系统,工程团队可以捕获并处理采样数据,以改进系统的当前结构、应用或淘汰新组件、添加另一个安全层、消除瓶颈等。
组织应该选择可观察性吗?
我们都应该明白,最终目标是更好的用户体验和更高的用户满意度。 通过自动化和主动的可观察性框架,可以更轻松地实现这些目标。 建立持续改进和优化的文化被认为是最佳的业务和领导方法。
在这个数字化转型的时代,可观察性已成为企业在数字化之旅中取得成功的必备条件。 为您提供有洞察力的跟踪,可观察性还使您了解数据,而不仅仅是数据驱动。
结论
尽管我们交替使用了监视和可观察性这两个术语,但我们已经看到,虽然监视可以帮助您了解有关系统健康状况和系统上发生的事件的信息,但可观察性可以帮助您根据从更深层收集的证据进行推断-到端的环境。
可观察性是并且也可以被视为数据治理框架的一个组成部分。 在这一代,不断增长的数据量驻留在商品硬件网络上,保持架构尽可能简单至关重要。 显然,管理环境成为一项不可能完成的任务。 因此,实施适当和自动化的治理策略和规则,以保持您的大型系统、管道和数据网格尽早采取行动。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- Able
- 关于我们
- 根据
- 实现
- 操作
- 额外
- 附加信息
- 采用
- 采用
- 采用
- 来临
- 所有类型
- 允许
- 时刻
- 分析
- 分析
- 和
- 另一个
- 回答
- 应用领域
- 应用领域
- 使用
- 的途径
- 适当
- 架构
- 属性
- 认证
- 自动化
- 避免
- 基于
- 基本上
- 因为
- 成为
- 成为
- 开始
- 最佳
- 更好
- 大
- 大数据运用
- 博客
- 博客文章
- 瓶颈
- 商业
- 呼叫
- 呼叫
- 捕获
- 例
- 集中
- 更改
- 更改
- 关闭
- 收集
- 收藏
- 商品
- 完成
- 复杂
- 元件
- 组件
- 概念
- 关心
- 困惑
- 考虑
- 考虑
- 消费
- 上下文
- 连续
- 控制
- 成本
- 可以
- 中央处理器
- 文化塑造
- 电流
- 顾客
- data
- 数据驱动
- 数据库
- 数据多样性
- 日复一日
- 一年中的
- 十
- 分散
- 决定
- 深
- 更深
- 定义
- 描述
- 目的地
- 详情
- DID
- 不同
- 数字
- 数字化改造
- 分布
- 分布式系统
- 不会
- 向下
- ,我们将参加
- 电子商务行业
- 更容易
- 嵌入式
- 拥抱
- 使
- 端至端
- 工程师
- 环境
- 错误
- 故障
- 建立
- 等
- 甚至
- 事件
- EVER
- 不断增加
- 一切
- 证据
- 进化
- 例子
- 昂贵
- 体验
- 外部
- 功能有助于
- 流动
- 形成
- 骨架
- 框架
- 止
- 代
- 得到
- Go
- 理想中
- 治理
- 更大的
- 成长
- 发生
- 事件
- 硬件
- 健康管理
- 帮助
- 帮助
- 历史
- 击中
- 抱有希望
- 热卖
- 创新中心
- How To
- 但是
- HTML
- HTTPS
- 巨大
- 图片
- 实施
- 重要
- 不可能
- 改善
- 改进
- in
- 信息
- 通知
- 可行的洞见
- 内部
- 调查
- 所调用
- 问题
- 问题
- IT
- IT管理
- 旅程
- 保持
- 知识
- 景观
- 大
- 大
- 潜伏
- 层
- 层
- 领导团队
- 学习
- 镜头
- 杠杆作用
- 生命周期
- 有限
- Line
- 生活
- 加载
- 长
- 占地
- 制成
- 使
- 制作
- 制作
- 管理
- 颠覆性技术
- 管理的
- 许多
- 市场
- 数学的
- 最大宽度
- 衡量
- 内存
- 指标
- 微服务
- 百万
- 分钟
- 监控
- 单片
- 最先进的
- 移动
- 移动
- 多
- 一定有
- 自然
- 必要
- 需求
- 需要
- 净
- 网络
- 网络系统
- 全新
- 一
- 操作
- 操作
- 运营
- 最佳
- 优化
- 组织
- 其他名称
- 最划算
- 己
- 纸类
- 径
- 模式
- 付款
- 感知
- 性能
- 执行
- 期间
- 件
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 播放
- 政策
- 贫困
- 可能
- 帖子
- 帖子
- 主动
- 市场问题
- 过程
- 产品
- 进展
- 提供
- 提供
- 优
- 出版
- 量
- 问题
- 宁
- 阅读
- 阅读
- 接收
- 接收
- 可靠性
- 去掉
- 代表
- 请求
- 要求
- 需要
- 弹性
- 受限
- 导致
- 上升
- 天台
- 定位、竞价/采购和分析/优化数字媒体采购,但算法只不过是解决问题的操作和规则。
- 满意
- 保存
- 鳞片
- 缩放
- 搜索
- 搜索
- 其次
- 保安
- 特色服务
- 几个
- 应该
- 作品
- 简易
- 单
- 放慢
- 小
- So
- 软件
- 解决
- 一些
- 不久
- 听起来
- 来源
- 跨度
- 具体的
- 花
- 堆
- 阶段
- 开始
- 开始
- 州/领地
- 州
- 住
- 仍
- 停止
- 存储
- 故事
- 结构体
- 成功
- 系统
- 产品
- 采取
- 需要
- 任务
- 队
- 文案
- 条款
- 信息
- 其
- 从而
- 三
- 通过
- 始终
- 次
- 时间表
- 至
- 今晚
- 工具
- 主题
- 追踪
- 可追溯分析仪
- 追踪
- 跟踪
- 转让
- 转型
- 伞
- 下
- 相关
- 理解
- 更新
- 用法
- 用户
- 用户体验
- 平时
- 有价值
- 各个
- 视频
- 能见度
- 重要
- 体积
- 等待
- 等候
- 您的网站
- 什么是
- 什么是
- 这
- 而
- 将
- 中
- 工作
- 劳动力
- 合作
- 世界
- 将
- 错误
- 您一站式解决方案
- 和风网











