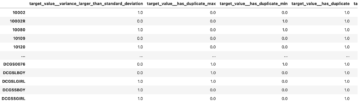
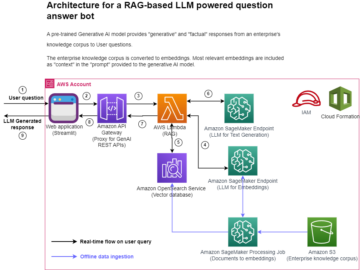
在计算机视觉中,语义分割是将图像中的每个像素与一组已知标签中的一个类进行分类的任务,使得具有相同标签的像素具有某些特征。 它生成输入图像的分割掩码。 例如,以下图像显示了 cat 带有
 |
 |
十一月2018, 亚马逊SageMaker 宣布推出 SageMaker 语义分割算法。 使用此算法,您可以使用公共数据集或您自己的数据集训练模型。 流行的图像分割数据集包括 Common Objects in Context (COCO) 数据集和 PASCAL Visual Object Classes (PASCAL VOC),但它们的标签类是有限的,您可能希望在未包含在目标对象上训练模型公共数据集。 在这种情况下,您可以使用 亚马逊SageMaker地面真相 标记您自己的数据集。
在这篇文章中,我演示了以下解决方案:
- 使用 Ground Truth 标记语义分割数据集
- 将结果从 Ground Truth 转换为 SageMaker 内置语义分割算法所需的输入格式
- 使用语义分割算法训练模型并执行推理
语义分割数据标注
为了构建用于语义分割的机器学习模型,我们需要在像素级别标记数据集。 Ground Truth 让您可以选择通过以下方式使用人工注释器 亚马逊Mechanical Turk、第三方供应商或您自己的私人劳动力。 要了解有关劳动力的更多信息,请参阅 创建和管理劳动力. 如果您不想自己管理标签工作人员, 亚马逊 SageMaker Ground Truth Plus 是另一个很好的选择,作为一种新的交钥匙数据标记服务,它使您能够快速创建高质量的训练数据集并将成本降低多达 40%。 在这篇文章中,我将向您展示如何使用 Ground Truth 自动分割功能手动标记数据集,并使用 Mechanical Turk 劳动力进行众包标记。
使用 Ground Truth 手动标记
2019 年 XNUMX 月,Ground Truth 在语义分割标注用户界面中添加了自动分割功能,以提高标注吞吐量并提高准确性。 有关详细信息,请参阅 使用 Amazon SageMaker Ground Truth 执行语义分割标签时自动分割对象. 借助这项新功能,您可以加快分段任务的标记过程。 无需绘制紧密拟合的多边形或使用画笔工具来捕获图像中的对象,您只需绘制四个点:对象的最顶部、最底部、最左侧和最右侧点。 Ground Truth 将这四个点作为输入,并使用 Deep Extreme Cut (DEXTR) 算法在对象周围生成紧密贴合的蒙版。 有关使用 Ground Truth 进行图像语义分割标记的教程,请参阅 图像语义分割. 以下是选择对象的四个极值点后自动分割工具如何自动生成分割蒙版的示例。


使用 Mechanical Turk 劳动力进行众包标签
如果您有一个大型数据集并且您不想自己手动标记数百或数千张图像,您可以使用 Mechanical Turk,它提供了按需、可扩展的人力来完成人类比计算机做得更好的工作。 Mechanical Turk 软件为成千上万愿意在方便时从事零碎工作的工人提供正式的工作机会。 该软件还检索执行的工作并为您(请求者)编译它,请求者(仅)向工人支付令人满意的工作。 要开始使用 Mechanical Turk,请参阅 亚马逊机械土耳其人简介.
创建标签作业
以下是海龟数据集的 Mechanical Turk 标记作业示例。 海龟数据集来自 Kaggle 比赛 海龟人脸检测,我选择了数据集的 300 张图像进行演示。 海龟不是公共数据集中的常见类别,因此它可以代表需要标记大量数据集的情况。
- 在SageMaker控制台上,选择 标签工作 在导航窗格中。
- 创建标签作业.
- 输入您的工作名称。
- 针对 输入数据设置, 选择 自动数据设置.
这会生成输入数据的清单。 - 针对 输入数据集的 S3 位置,输入数据集的路径。

- 针对 任务类别,选择 图片.
- 针对 任务选择, 选择 语义分割.

- 针对 工人类型, 选择 亚马逊Mechanical Turk.
- 配置任务超时、任务到期时间和每个任务的价格的设置。

- 添加标签(对于这篇文章,
sea turtle),并提供标签说明。 - 创建.

设置标记作业后,您可以在 SageMaker 控制台上检查标记进度。 当它被标记为完成时,您可以选择作业来检查结果并将其用于后续步骤。

数据集转换
从 Ground Truth 获得输出后,您可以使用 SageMaker 内置算法在此数据集上训练模型。 首先,您需要准备标记数据集作为 SageMaker 语义分割算法的请求输入接口。
请求的输入数据通道
SageMaker 语义分割希望您的训练数据集存储在 亚马逊简单存储服务 (亚马逊 S3)。 Amazon S3 中的数据集预计将在两个通道中呈现,一个用于 train 和一个用于 validation,使用四个目录,两个用于图像,两个用于注释。 注释应该是未压缩的 PNG 图像。 数据集还可能有一个标签映射,用于描述如何建立注释映射。 如果不是,算法使用默认值。 对于推理,端点接受带有 image/jpeg 内容类型。 以下是数据通道所需的结构:
train 和 validation 目录中的每个 JPG 图片在 train_annotation 和 validation_annotation 目录。 这种命名约定有助于算法在训练期间将标签与其对应的图像相关联。 火车, train_annotation,验证和 validation_annotation 频道是强制性的。 注释是单通道 PNG 图像。 只要图像中的元数据(模式)帮助算法将注释图像读入单通道 8 位无符号整数,该格式就可以工作。
Ground Truth 标记作业的输出
Ground Truth 标记作业生成的输出具有以下文件夹结构:
分割掩码保存在 s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. 每个注释图像都是一个 .png 文件,以源图像的索引和该图像标记完成的时间命名。 例如,以下是由 Mechanical Turk 劳动力生成的源图像 (Image_1.jpg) 及其分割掩码 (0_2022-02-10T17:41:04.724225.png)。 请注意,掩码的索引与源图像名称中的数字不同。
 |
 |
标记作业的输出清单位于 /manifests/output/output.manifest 文件。 它是一个 JSON 文件,每一行都记录了源图像与其标签和其他元数据之间的映射。 以下 JSON 行记录了显示的源图像与其注释之间的映射:
源图像名为 Image_1.jpg,注解名称为 0_2022-02-10T17:41: 04.724225.png。 要将数据准备为 SageMaker 语义分割算法所需的数据通道格式,我们需要更改注释名称,使其与源 JPG 图像具有相同的名称。 我们还需要将数据集拆分为 train 和 validation 源图像和注释的目录。
将地面实况标记作业的输出转换为请求的输入格式
要转换输出,请完成以下步骤:
- 将标记作业中的所有文件从 Amazon S3 下载到本地目录:
- 读取清单文件并将注解的名称更改为与源图像相同的名称:
- 拆分训练和验证数据集:
- 为语义分割算法数据通道制作所需格式的目录:
- 将训练和验证图像及其注释移动到创建的目录。
- 对于图像,请使用以下代码:
- 对于注释,请使用以下代码:
- 将训练和验证数据集及其注释数据集上传到 Amazon S3:
SageMaker 语义分割模型训练
在本节中,我们将介绍训练语义分割模型的步骤。
按照示例笔记本设置数据通道
您可以按照中的说明进行操作 语义分割算法现在在 Amazon SageMaker 中可用 对标记的数据集实施语义分割算法。 这个样本 笔记本 显示了介绍算法的端到端示例。 在笔记本中,您将学习如何使用全卷积网络训练和托管语义分割模型(FCN) 算法使用 Pascal VOC数据集 为了训练。 因为我不打算从 Pascal VOC 数据集训练模型,所以我跳过了本笔记本中的第 3 步(数据准备)。 相反,我直接创建 train_channel, train_annotation_channe, validation_channel及 validation_annotation_channel 使用我存储图像和注释的 S3 位置:
在 SageMaker 估计器中为您自己的数据集调整超参数
我按照笔记本创建了一个 SageMaker 估算器对象(ss_estimator) 来训练我的分割算法。 我们需要为新数据集定制的一件事是 ss_estimator.set_hyperparameters: 我们需要改变 num_classes=21 至 num_classes=2 (turtle 和 background),我也改变了 epochs=10 至 epochs=30 因为 10 仅用于演示目的。 然后我通过设置使用 p3.2xlarge 实例进行模型训练 instance_type="ml.p3.2xlarge". 培训在 8 分钟内完成。 最好的 MioU 在 epoch 0.846 达到 11 的(Union 上的平均交集) pix_acc (图像中被正确分类的像素百分比)为 0.925,这对于这个小型数据集来说是一个相当不错的结果。
模型推理结果
我将模型托管在一个低成本的 ml.c5.xlarge 实例上:
最后,我准备了10张海龟图像的测试集,看看训练好的分割模型的推理结果:
下图显示了结果。

海龟的分割掩码看起来很准确,我对这个结果很满意,这个结果是在 Mechanical Turk 工人标记的 300 图像数据集上训练的。 您还可以探索其他可用的网络,例如 金字塔场景解析网络 (PSP) or 深实验室-V3 在带有数据集的示例笔记本中。
清理
完成后删除端点以避免产生持续成本:
结论
在这篇文章中,我展示了如何使用 SageMaker 自定义语义分割数据标签和模型训练。 首先,您可以使用自动分段工具或使用 Mechanical Turk 劳动力(以及其他选项)设置标签作业。 如果您有超过 5,000 个对象,您还可以使用自动数据标记。 然后,您将 Ground Truth 标记作业的输出转换为 SageMaker 内置语义分割训练所需的输入格式。 之后,您可以使用加速计算实例(例如 p2 或 p3)来训练语义分割模型,如下所示 笔记本 并将模型部署到更具成本效益的实例(例如 ml.c5.xlarge)。 最后,您可以使用几行代码查看测试数据集的推理结果。
开始使用 SageMaker 语义分割 数据标签 和 模型训练 使用您最喜欢的数据集!
关于作者
 卡拉扬 是 AWS 专业服务的数据科学家。 她热衷于帮助客户使用 AWS 云服务实现业务目标。 她帮助组织在制造、汽车、环境可持续性和航空航天等多个行业构建了 ML 解决方案。
卡拉扬 是 AWS 专业服务的数据科学家。 她热衷于帮助客户使用 AWS 云服务实现业务目标。 她帮助组织在制造、汽车、环境可持续性和航空航天等多个行业构建了 ML 解决方案。
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- 关于
- 加快
- 加速
- 精准的
- 实现
- 横过
- 添加
- 航空航天
- 算法
- 算法
- 所有类型
- Amazon
- 公布
- 另一个
- 围绕
- 律师
- 自动化
- 自动
- 汽车
- 可使用
- AWS
- 背景
- 因为
- 最佳
- 更好
- 之间
- 建立
- 内建的
- 商业
- 捕获
- 案件
- 一定
- 更改
- 通道
- 程
- 类
- 机密
- 云端技术
- 云服务
- 码
- 相当常见
- 竞争
- 完成
- 一台
- 电脑
- 计算
- 信心
- 安慰
- 内容
- 方便
- 相应
- 经济有效
- 成本
- 创建信息图
- 创建
- 合作伙伴
- 定制
- data
- 数据科学家
- 深
- 演示
- 部署
- 不同
- 直接
- 画
- ,我们将参加
- 每
- 使
- 端至端
- 端点
- 输入
- 环境的
- 成熟
- 例子
- 除
- 预期
- 预计
- 探索
- 极端
- 面部彩妆
- 专栏
- 姓氏:
- 遵循
- 以下
- 格式
- 止
- 产生
- 理想中
- 非常好
- 灰色
- 大
- 快乐
- 帮助
- 帮助
- 帮助
- 高品质
- 托管
- 创新中心
- How To
- HTTPS
- 人
- 人类
- 数百
- 图片
- 图片
- 实施
- 改善
- 包括
- 包括
- 增加
- 指数
- 行业
- 信息
- 输入
- 例
- 接口
- 路口
- 介绍
- IT
- 工作
- 工作机会
- 已知
- 标签
- 标签
- 标签
- 大
- 发射
- 学习用品
- 学习
- Level
- 有限
- Line
- 线
- 清单
- 本地
- 圖書分館的位置
- 地点
- 长
- 看
- 机
- 机器学习
- 管理
- 强制性
- 手动
- 制造业
- 地图
- 制图
- 面膜
- 面膜
- 大规模
- 机械
- 可能
- ML
- 模型
- 模型
- 更多
- 多
- 名称
- 命名
- 旅游导航
- 网络
- 网络
- 下页
- 笔记本
- 数
- 优惠精选
- 附加选项
- 附加选项
- 组织
- 其他名称
- 己
- 多情
- 百分
- 执行
- 点
- Polygon
- 热门
- Prepare
- 漂亮
- 车资
- 私立
- 过程
- 生产
- 所以专业
- 提供
- 提供
- 国家
- 目的
- 很快
- RE
- 记录
- 代表
- 必须
- 需要
- 成果
- 检讨
- 同
- 可扩展性
- 科学家
- SEA
- 分割
- 选
- 服务
- 特色服务
- 集
- 设置
- Share
- 显示
- 如图
- 简易
- 情况
- 小
- So
- 软件
- 解决方案
- 分裂
- 开始
- 存储
- 永续发展
- 目标
- 任务
- 团队
- test
- 事
- 第三方
- 数千
- 通过
- 吞吐量
- 次
- 工具
- 培训
- 产品培训
- 改造
- 工会
- 使用
- 验证
- 厂商
- 愿景
- WHO
- 工作
- 工人
- 劳动力
- 合作
- 您一站式解决方案