阿帕奇·冰山 是一种用于非常大的分析数据集的开放表格式,它捕获有关数据集状态的元数据信息,因为它们会随着时间的推移而发展和变化。 它使用类似于 SQL 表的高性能表格式将表添加到计算引擎,包括 Spark、Trino、PrestoDB、Flink 和 Hive。 Iceberg 因其对数据湖中 ACID 事务的支持以及模式和分区演化、时间旅行和回滚等功能而变得非常流行。
Apache Iceberg 集成由 AWS 分析服务支持,包括 亚马逊电子病历, 亚马逊雅典娜及 AWS胶水. Amazon EMR 可以使用可以运行 Iceberg 的 Spark、Hive、Trino 和 Flink 来配置集群。 从 Amazon EMR 版本 6.5.0 开始,您可以 将 Iceberg 与您的 EMR 集群一起使用 无需引导操作。 2022 年初,AWS 宣布全面推出由 Apache Iceberg 提供支持的 Athena ACID 事务。 最近发布的 Athena 查询引擎版本 3 提供与 Iceberg 表格格式更好的集成。 AWS Glue 3.0 及更高版本 支持 Apache Iceberg 框架 对于数据湖。
在本文中,我们将讨论客户在现代数据湖中的需求以及 Apache Iceberg 如何帮助满足客户需求。 然后我们通过一个解决方案来构建一个高性能和不断发展的 Iceberg 数据湖 亚马逊简单存储服务 (Amazon S3) 并通过运行插入、更新和删除 SQL 语句来处理增量数据。 最后,我们将向您展示如何对流程进行性能调优以提高读写性能。
Apache Iceberg 如何满足客户在现代数据湖中的需求
越来越多的客户正在使用结构化和非结构化数据构建数据湖,以支持众多用户、应用程序和分析工具。 越来越需要数据湖来支持类似数据库的功能,例如 ACID 事务、记录级更新和删除、时间旅行和回滚。 Apache Iceberg 旨在支持 Amazon S3 上具有成本效益的 PB 级数据湖上的这些功能。
Apache Iceberg 通过在创建单个数据文件时捕获有关数据集的丰富元数据信息来满足客户需求。 Iceberg 表的架构分为三层:Iceberg 目录、元数据层和数据层,如下图所示(资源).

Iceberg 目录存储指向当前表元数据文件的元数据指针。 When a select query is reading an Iceberg table, the query engine first goes to the Iceberg catalog, then retrieves the location of the current metadata file. 每当 Iceberg 表有更新时,都会创建该表的新快照,并且元数据指针指向当前表的元数据文件。
以下是使用 AWS Glue 实施的 Iceberg 目录示例。 您可以看到数据库名称、Iceberg 表的位置(S3 路径)和元数据位置。

元数据层具有三种类型的文件:元数据文件、清单列表和层次结构中的清单文件。 层次结构的顶部是元数据文件,它存储有关表的架构、分区信息和快照的信息。 快照指向清单列表。 清单列表包含构成快照的每个清单文件的信息,例如清单文件的位置、它所属的分区以及它跟踪的数据文件的分区列的下限和上限。 清单文件跟踪数据文件以及有关每个文件的其他详细信息,例如文件格式。 所有这三个文件都在一个层次结构中工作,以跟踪 Iceberg 表中的快照、模式、分区、属性和数据文件。
数据层具有 Iceberg 表的各个数据文件。 Iceberg 支持多种文件格式,包括 Parquet、ORC 和 Avro。 由于 Iceberg 表跟踪单个数据文件,而不是仅指向数据文件所在的分区位置,因此它将写入操作与读取操作隔离开来。 您可以随时写入数据文件,但只能明确提交更改,这会创建新版本的快照和元数据文件。
解决方案概述
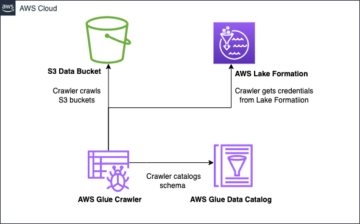
在本文中,我们将带您了解在 Amazon S3 上构建高性能 Apache Iceberg 数据湖的解决方案; 使用插入、更新和删除 SQL 语句处理增量数据; 调优Iceberg表,提升读写性能。 下图说明了解决方案架构。

为了演示这个解决方案,我们使用 亚马逊顾客评论 S3 存储桶中的数据集 (s3://amazon-reviews-pds/parquet/). 在实际用例中,它将是存储在 S3 存储桶中的原始数据。 我们可以在下面的代码中检查数据大小 AWS命令行界面 (AWS CLI):
对象总数为 430,总大小为 47.4 GiB。
要设置和测试此解决方案,我们完成以下高级步骤:
- 在 curated zone 中设置 S3 存储桶,以 Iceberg 表格式存储转换后的数据。
- 为 Apache Iceberg 启动具有适当配置的 EMR 集群。
- 在 EMR Studio 中创建笔记本。
- 为 Apache Iceberg 配置 Spark 会话。
- 将数据转换为 Iceberg 表格式并将数据移动到精选区域。
- 在 Athena 中运行插入、更新和删除查询以处理增量数据。
- 进行性能调优。
先决条件
要跟随本演练,您必须有一个 AWS账户 与 AWS身份和访问管理 (IAM) 角色,该角色具有足够的访问权限来供应所需的资源。
在数据湖的精选区域中为 Iceberg 数据设置 S3 存储桶
选择要在其中创建 S3 存储桶的区域并提供唯一名称:
启动 EMR 集群以使用 Spark 运行 Iceberg 作业
您可以从 AWS管理控制台、亚马逊 EMR CLI,或 AWS云开发套件 (AWS CDK)。 在这篇博文中,我们将向您介绍如何从控制台创建 EMR 集群。
- 在 Amazon EMR 控制台上,选择 创建集群.
- 高级选项.
- 针对 软件配置, 选择最新的 Amazon EMR 版本。 截至 2023 年 6.9.0 月,最新版本为 6.5.0。 Iceberg 需要 XNUMX 及以上版本。
- 选择 Jupyter企业网关 和 火花 作为要安装的软件。
- 针对 编辑软件设置, 选择 输入配置 并进入
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - 将其他设置保留为默认值并选择 下一页.

- 针对 硬件, 使用默认设置。
- 下一页.
- 针对 集群名称, 输入名称。 我们用
iceberg-blog-cluster. - 保持其余设置不变并选择 下一页.
- 创建集群.
在 EMR Studio 中创建笔记本
我们现在将向您介绍如何从控制台在 EMR Studio 中创建笔记本。
- 在IAM控制台上, 创建 EMR Studio 服务角色.
- 在 Amazon EMR 控制台上,选择 电子病历工作室.
- 前往在线商城.
前往在线商城 页面出现在新选项卡中。
- 创建工作室 在新标签中。
- 输入名称。 我们使用冰山工作室。
- 选择与EMR集群相同的VPC和子网,以及默认的安全组。
- AWS身份和访问管理(IAM) 用于身份验证,并选择您刚刚创建的 EMR Studio 服务角色。
- 选择 S3 路径 工作区备份.
- 创建工作室.
- 创建 Studio 后,选择 Studio 访问 URL。
- 在 EMR Studio 仪表板上,选择 创建工作区.
- 输入工作区的名称。 我们用
iceberg-workspace. - 扩大 高级配置 并选择 将 Workspace 附加到 EMR 集群.
- 选择您之前创建的 EMR 集群。
- 创建工作区.
- 选择工作区名称以打开新选项卡。
在导航窗格中,有一个与工作区同名的笔记本。 在我们的例子中,它是 iceberg-workspace。
- 打开笔记本。
- 当提示选择内核时,选择 火花.
为 Apache Iceberg 配置 Spark 会话
使用以下代码,提供您自己的 S3 存储桶名称:
这将设置以下 Spark 会话配置:
- spark.sql.目录.demo – 注册一个名为 demo 的 Spark 目录,它使用 Iceberg Spark 目录插件。
- Spark.sql.catalog.demo.catalog-impl – 演示 Spark 目录使用 AWS Glue 作为物理目录来存储 Iceberg 数据库和表信息。
- Spark.sql.catalog.demo.warehouse – 演示 Spark 目录将所有 Iceberg 元数据和数据文件存储在此属性定义的根路径下:
s3://iceberg-curated-blog-data. - spark.sql.扩展 – 添加对 Iceberg Spark SQL 扩展的支持,它允许您运行 Iceberg Spark 过程和一些 Iceberg-only SQL 命令(您将在后面的步骤中使用它)。
- Spark.sql.catalog.demo.io-impl – Iceberg 允许用户通过 S3FileIO 将数据写入 Amazon S3。 AWS Glue 数据目录默认使用此 FileIO,其他目录可以使用 io-impl 目录属性加载此 FileIO。
将数据转换为 Iceberg 表格式
您可以使用 Amazon EMR 上的 Spark 或 Athena 加载 Iceberg 表。 在 EMR Studio Workspace Notebook Spark 会话中,运行以下命令加载数据:
运行代码后,您应该会发现在数据仓库 S3 路径中创建了两个前缀 (s3://iceberg-curated-blog-data/reviews.db/all_reviews): 数据和元数据。
在 Athena 中使用插入、更新和删除 SQL 语句处理增量数据
Athena 是一个无服务器查询引擎,您可以使用它对 Iceberg 表执行读取、写入、更新和优化任务。 为了演示 Apache Iceberg 数据湖格式如何支持增量数据摄取,我们在数据湖上运行插入、更新和删除 SQL 语句。
导航到 Athena 控制台并选择 查询编辑器. 如果这是您第一次使用 Athena 查询编辑器,您需要 配置查询结果位置 成为您之前创建的 S3 存储桶。 您应该能够看到表 reviews.all_reviews 可用于查询。 运行以下查询以验证您是否已成功加载 Iceberg 表:
通过insert、update、delete SQL语句处理增量数据:
性能调优
在本节中,我们介绍了提高 Apache Iceberg 读写性能的不同方法。
配置 Apache Iceberg 表属性
Apache Iceberg 是一种表格格式,它支持表格属性来配置表格行为,例如读取、写入和目录。 您可以通过调整表属性来提高 Iceberg 表的读写性能。
例如,如果您注意到您为 Iceberg 表写入了太多小文件,您可以配置写入文件大小以写入更少但更大的文件,以帮助提高查询性能。
| 以高 | 默认 | 产品描述 |
| 写入目标文件大小字节 | 536870912(512 MB) | 控制生成的文件大小以定位大约这么多字节 |
使用以下代码更改表格格式:
分区和排序
为了使查询运行得更快,读取的数据越少越好。 Iceberg 利用它在写入时捕获的丰富元数据,并促进扫描计划、分区、修剪和列级统计信息(如最小/最大值)等技术跳过没有匹配记录的数据文件。 我们将向您介绍查询扫描计划和分区在 Iceberg 中的工作原理,以及我们如何使用它们来提高查询性能。
查询扫描规划
对于给定的查询,查询引擎的第一步是扫描计划,这是在表中查找查询所需文件的过程。 在 Iceberg 表中进行规划非常高效,因为除了过滤不包含匹配数据的数据文件外,Iceberg 丰富的元数据还可用于修剪不需要的元数据文件。 在我们的测试中,我们观察到与转换为 Iceberg 格式之前的原始数据相比,Athena 为 Iceberg 表上的给定查询扫描了 50% 或更少的数据。
有两种类型的过滤:
- 元数据过滤 – Iceberg 使用两个级别的元数据来跟踪快照中的文件:清单列表和清单文件。 它首先使用清单列表,它充当清单文件的索引。 在规划过程中,Iceberg 会根据清单列表中的分区值范围过滤清单,而不会读取所有清单文件。 然后它使用选定的清单文件来获取数据文件。
- 数据过滤 – 选择清单文件列表后,Iceberg 使用清单文件中存储的每个数据文件的分区数据和列级统计信息来过滤数据文件。 在规划期间,查询谓词被转换为分区数据上的谓词,并首先应用于过滤数据文件。 然后,使用列级值计数、空值计数、下限和上限等列统计信息来过滤掉无法匹配查询谓词的数据文件。 Iceberg 通过在计划时使用上限和下限来过滤数据文件,大大提高了查询性能。
分区和排序
分区是一种以书面形式将具有相同键列值的记录分组在一起的方法。 分区的好处是查询速度更快,只访问部分数据,如前面查询扫描计划:数据过滤中所述。 Iceberg 通过支持隐藏分区使分区变得简单,就像 Iceberg 通过获取列值并选择性地转换它来生成分区值的方式一样。
在我们的用例中,我们首先在未分区的 Iceberg 表上运行以下查询。 然后我们将 Iceberg 表按评论的类别进行分区,将在查询 WHERE 条件中使用它来过滤记录。 通过分区,查询可以扫描更少的数据。 请参见以下代码:
在非分区 all_reviews 表与分区表上运行以下 select 语句以查看性能差异:
下表显示了数据分区的性能提升,性能提升约 50%,扫描的数据减少 70%。
| 数据集名称 | 非分区数据集 | 分区数据集 |
| 运行时间(秒) | 8.20 | 4.25 |
| 扫描数据 (MB) | 131.55 | 33.79 |
请注意,运行时间是我们测试中多次运行的平均运行时间。
分区后我们看到了良好的性能提升。 但是,这可以通过使用 Iceberg 清单文件中的列级统计信息来进一步改进。 为了有效地使用列级统计信息,您希望根据查询模式进一步对记录进行排序。 使用查询中经常使用的列对整个数据集进行排序将以这样一种方式重新排序数据,即每个数据文件最终都具有特定列的唯一值范围。 如果在查询条件中使用这些列,则允许查询引擎进一步跳过数据文件,从而实现更快的查询。
写时复制与合并时读
在数据湖中的 Iceberg 表上实现更新和删除时,Iceberg 表属性定义了两种方法:
- 写时复制 – 使用这种方法,当 Iceberg 表发生变化时,无论是更新还是删除,与受影响记录相关的数据文件将被复制和更新。 将从重复的数据文件中更新或删除记录。 将创建 Iceberg 表的新快照并指向更新版本的数据文件。 这使得整体写入速度变慢。 可能存在需要并发写入但有冲突的情况,因此必须进行重试,这会进一步增加写入时间。 另一方面,读取数据时,不需要额外的处理。 查询将从最新版本的数据文件中检索数据。
- 阅读合并 – 采用这种方式,当Iceberg表有更新或删除时,不会重写已有的数据文件; 相反,将创建新的删除文件来跟踪更改。 对于删除,将使用已删除的记录创建一个新的删除文件。 在读取 Iceberg 表时,删除文件将应用于检索数据以过滤掉删除记录。 对于更新,将创建一个新的删除文件以将更新的记录标记为已删除。 然后将为这些记录创建一个新文件,但具有更新的值。 读取 Iceberg 表时,删除文件和新文件都将应用于检索到的数据,以反映最新的更改并产生正确的结果。 因此,对于任何后续查询,将发生将数据文件与删除文件和新文件合并的额外步骤,这通常会增加查询时间。 另一方面,写入可能会更快,因为不需要重写现有的数据文件。
要测试这两种方法的影响,您可以运行以下代码来设置 Iceberg 表属性:
在 Athena 中运行更新、删除和选择 SQL 语句以显示写时复制与读时合并的运行时差异:
下表总结了查询运行时间。
| 询问 | 写时复制 | 合并阅读 | ||||
| 更新 | 删除 | 选择 | 更新 | 删除 | 选择 | |
| 运行时间(秒) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| 扫描数据 (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
请注意,运行时间是我们测试中多次运行的平均运行时间。
正如我们的测试结果所示,这两种方法总是需要权衡取舍。 使用哪种方法取决于您的用例。 总之,考虑因素归结为读取与写入的延迟。 您可以参考下表并做出正确的选择。
| . | 写时复制 | 合并阅读 |
| 优点 | 读取速度更快 | 更快的写入 |
| 缺点 | 昂贵的写入 | 更高的读取延迟 |
| 何时使用 | 适用于频繁读取、不频繁更新和删除或大批量更新 | 适用于频繁更新和删除的表 |
数据压缩
如果您的数据文件很小,您最终可能会在 Iceberg 表中拥有数千或数百万个文件。 这会显着增加 I/O 操作并减慢查询速度。 此外,Iceberg 跟踪数据集中的每个数据文件。 更多的数据文件导致更多的元数据。 这反过来又增加了读取元数据文件的开销和 I/O 操作。 为了提高查询性能,建议将小数据文件压缩成大数据文件。
在更新和删除 Iceberg 表中的记录时,如果使用 read-on-merge 方法,您可能最终会得到许多小的删除或新的数据文件。 运行压缩将合并所有这些文件并创建一个更新版本的数据文件。 这消除了在读取期间协调它们的需要。 建议定期进行压缩作业,以尽可能减少对读取的影响,同时仍保持更快的写入速度。
运行以下数据压缩命令,然后从 Athena 运行选择查询:
下表比较了数据压缩前后的运行时间。 您可以看到大约 40% 的性能提升。
| 询问 | 数据压缩之前 | 数据压缩后 |
| 运行时间(秒) | 97.75 | 32.676秒 |
| 扫描数据 (MB) | 137.16 M | 189.19 M |
请注意,选择查询运行在 all_reviews 更新和删除操作之后的表,数据压缩之前和之后。 运行时间是我们测试中多次运行的平均运行时间。
清理
按照解决方案演练执行用例后,完成以下步骤以清理资源并避免进一步的成本:
- 从 Athena 删除 AWS Glue 表和数据库或在您的笔记本中运行以下代码:
- 在 EMR Studio 控制台上,选择 工作区 在导航窗格中。
- 选择您创建的工作区并选择 删除.
- 在 EMR 控制台上,导航到 工作室 页面上发布服务提醒。
- 选择您创建的工作室并选择 删除.
- 在 EMR 控制台上,选择 集群 在导航窗格中。
- 选择集群并选择 终止.
- 删除 S3 存储桶和您作为本文先决条件的一部分创建的任何其他资源。
结论
在本文中,我们介绍了 Apache Iceberg 框架以及它如何帮助解决我们在现代数据湖中面临的一些挑战。 然后,我们向您介绍了使用 Apache Iceberg 处理数据湖中增量数据的解决方案。 最后,我们深入研究了性能调优,以提高我们用例的读写性能。
我们希望这篇文章能为您提供一些有用的信息,帮助您决定是否要在数据湖解决方案中采用 Apache Iceberg。
作者简介
 胡锦涛 是 AWS 数据实验室的高级常驻架构师。 她帮助企业客户制定数据分析策略并构建解决方案以加速他们的业务成果。 在业余时间,她喜欢打网球、跳萨尔萨舞和旅行。
胡锦涛 是 AWS 数据实验室的高级常驻架构师。 她帮助企业客户制定数据分析策略并构建解决方案以加速他们的业务成果。 在业余时间,她喜欢打网球、跳萨尔萨舞和旅行。
 丹尼尔李 是 Amazon Web Services 的高级解决方案架构师。 他专注于帮助客户开发、采用和实施云服务和战略。 不工作时,他喜欢和家人一起在户外度过。
丹尼尔李 是 Amazon Web Services 的高级解决方案架构师。 他专注于帮助客户开发、采用和实施云服务和战略。 不工作时,他喜欢和家人一起在户外度过。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- Able
- 关于我们
- 以上
- 加快
- ACCESS
- 访问管理
- 操作
- 行为
- 增加
- 额外
- 地址
- 地址
- 添加
- 采用
- 优点
- 后
- 驳
- 所有类型
- 允许
- 时刻
- Amazon
- 亚马逊电子病历
- 亚马逊网络服务
- 解析
- 分析
- 和
- 公布
- 阿帕奇
- 应用领域
- 应用的
- 的途径
- 方法
- 适当
- 架构
- 相关
- 认证
- 可用性
- 可使用
- 避免
- AWS
- AWS胶水
- 基于
- 因为
- 成为
- before
- 得益
- 更好
- 之间
- 大
- 引导
- 建立
- 建筑物
- 企业
- 捕获
- 捕获
- 案件
- 例
- 检索目录
- 目录
- 产品类别
- 挑战
- 更改
- 更改
- 查
- 选择
- 分类
- 云端技术
- 云服务
- 簇
- 码
- 柱
- 列
- 结合
- 如何
- 承诺
- 相比
- 完成
- 计算
- 并发
- 流程条件
- 配置
- 注意事项
- 安慰
- 转化
- 转换
- 经济有效
- 成本
- 可以
- 创建信息图
- 创建
- 创建
- 策划
- 电流
- 顾客
- 合作伙伴
- 跳舞
- XNUMX月XNUMX日
- data
- 数据分析
- 数据湖
- 数据处理
- 数据仓库
- 数据库
- 数据集
- 深
- 深潜
- 默认
- 定义
- 演示
- 演示
- 依靠
- 设计
- 详情
- 开发
- 研发支持
- 差异
- 不同
- 讨论
- 别
- 向下
- 显着
- 下降
- ,我们将参加
- 每
- 此前
- 早
- 编辑
- 只
- 高效
- 或
- 消除
- 启用
- 使
- 结束
- 发动机
- 引擎
- 输入
- 企业
- 企业客户
- 醚(ETH)
- 甚至
- 进化
- 发展
- 演变
- 例子
- 现有
- 存在
- 解释
- 扩展
- 额外
- 功能有助于
- 家庭
- 高效率
- 快
- 特征
- 数字
- 文件
- 档
- 过滤
- 过滤
- 过滤器
- 终于
- 找到最适合您的地方
- 姓氏:
- 第一次
- 重点
- 遵循
- 以下
- 格式
- 骨架
- 频繁
- 止
- 进一步
- 此外
- 总类
- 产生
- 得到
- 特定
- GOES
- 非常好
- 非常
- 团队
- 手
- 发生
- 帮助
- 帮助
- 帮助
- 老旧房屋
- 等级制度
- 高水平
- 高性能
- 高绩效
- 蜂房
- 抱有希望
- 创新中心
- How To
- 但是
- HTML
- HTTPS
- IAM
- 身分
- 身份和访问管理
- 影响力故事
- 影响
- 实施
- 履行
- 实施
- 改善
- 改善
- 改进
- 提高
- in
- 包含
- 增加
- 增加
- 增加
- 指数
- 个人
- 信息
- 安装
- 代替
- 积分
- 介绍
- 分离
- IT
- 一月
- 工作机会
- 键
- 实验室
- 湖泊
- 大
- 大
- 潜伏
- 最新
- 最新发布的
- 层
- 层
- 铅
- 各级
- 极限
- Line
- 清单
- 小
- 加载
- 圖書分館的位置
- 使
- 制作
- 颠覆性技术
- 许多
- 标记
- 市场
- 匹配
- 匹配
- 合并
- 元数据
- 可能
- 百万
- 现代
- 更多
- 移动
- 多
- 姓名
- 命名
- 导航
- 旅游导航
- 需求
- 打印车票
- 需要
- 全新
- 笔记本
- 对象
- 打开
- 操作
- 运营
- 优化
- 优化
- 秩序
- 原版的
- 其他名称
- 户外活动
- 最划算
- 己
- 面包
- 部分
- 径
- 模式
- 演出
- 性能
- 的
- 规划行程
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 播放
- 插入
- 点
- 热门
- 可能
- 帖子
- 供电
- 先决条件
- 程序
- 过程
- 处理
- 生产
- 财产
- 提供
- 提供
- 优
- 规定
- 范围
- 原
- 原始数据
- 阅读
- 阅读
- 真实
- 最近
- 建议
- 记录
- 反映
- 地区
- 寄存器
- 定期
- 释放
- 发布
- 其余
- 必须
- 需要
- 资源
- 导致
- 成果
- 评论
- 丰富
- 角色
- 根
- 运行
- 运行
- 同
- 浏览
- 秒
- 部分
- 保安
- 选
- 选择
- 无服务器
- 服务
- 特色服务
- 会议
- 集
- 套数
- 设置
- 设置
- 应该
- 显示
- 作品
- 简易
- 情况
- 尺寸
- 减慢
- 小
- 快照
- So
- 软件
- 方案,
- 解决方案
- 一些
- 火花
- 具体的
- 速度
- 花费
- SQL
- 开始
- 州/领地
- 个人陈述
- 声明
- 统计
- 步
- 步骤
- 仍
- 存储
- 商店
- 存储
- 商店
- 策略
- 策略
- 结构化
- 结构化和非结构化数据
- 工作室
- 子网
- 随后
- 顺利
- 这样
- 足够
- 概要
- SUPPORT
- 支持
- 支持
- 支持
- 表
- 需要
- 服用
- 目标
- 任务
- 技术
- 网球
- test
- 测试
- 测试
- 信息
- 国家
- 其
- 从而
- 数千
- 三
- 通过
- 次
- 时间旅行
- 至
- 一起
- 也有
- 工具
- 最佳
- 合计
- 跟踪时
- 交易
- 转型
- 旅行
- 旅游
- 转
- 类型
- 下
- 独特
- 更新
- 更新
- 最新动态
- 更新
- 网址
- 使用
- 用例
- 用户
- 平时
- VAL
- 折扣值
- 价值观
- 确认
- 版本
- 走
- 演练
- 仓库保管
- 手表
- 方法
- 卷筒纸
- Web服务
- 什么是
- 是否
- 这
- 而
- 宽
- 大范围
- 将
- 也完全不需要
- 工作
- 加工
- 合作
- 将
- 写
- 写作
- 您一站式解决方案
- 和风网