المُقدّمة
كيف يمكنك مواجهة التحدي المتمثل في معالجة وتحليل كميات هائلة من البيانات بكفاءة؟ لقد ابتليت العديد من الشركات والمؤسسات بهذا السؤال أثناء تعاملها مع تعقيدات البيانات الضخمة. من تحليل السجل إلى النمذجة المالية، أصبحت الحاجة إلى حلول مرنة وقابلة للتطوير أكبر من أي وقت مضى. أدخل AWS EMR، أو Amazon Elastic MapReduce.
وفي هذه المقالة سنتعرف على مميزات وفوائد AWS EMR، واستكشاف كيف يمكن أن يحدث ثورة في نهج معالجة البيانات وتحليلها. بدءًا من تكاملها مع Apache Spark وApache Hive ووصولاً إلى قابلية التوسع السلسة على Amazon EC2 وS3، سنكشف عن قوة السجلات الطبية الإلكترونية (EMR) وقدرتها على تحفيز الابتكار في مؤسستك. لذا، فلنبدأ رحلة لإطلاق الإمكانات الكاملة لبياناتك باستخدام AWS EMR.
جدول المحتويات
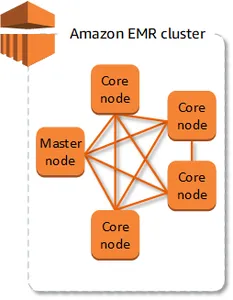
ما هي المجموعات والعقد؟
في قلب Amazon EMR يكمن المفهوم الأساسي لـ "المجموعة" - وهي مجموعة ديناميكية من مثيلات Amazon Elastic Compute Cloud (Amazon EC2)، مع الإشارة إلى كل مثيل على نحو مناسب باسم "العقدة". ضمن هذه المجموعة، تتولى كل عقدة دورًا مميزًا يُعرف باسم "نوع العقدة"، مما يحدد وظيفتها المحددة في مشهد التطبيقات الموزعة، بما في ذلك الأدوات البارزة مثل Apache Hadoop. يقوم Amazon EMR بتنسيق تكوين مكونات البرامج المختلفة بدقة على كل نوع عقدة، مما يؤدي بشكل فعال إلى تعيين الأدوار للعقد ضمن إطار التطبيق الموزع.
أنواع العقد في Amazon EMR
- العقدة الأساسية: تقوم هذه القوة الموثوقة بتنسيق المجموعة بأكملها، وتنفيذ مكونات البرامج المهمة لتنسيق توزيع البيانات وتخصيص المهام بين العقد الأخرى. تقوم العقدة الأساسية بتتبع حالة المهمة بعناية وتراقب صحة المجموعة بشكل عام. تشتمل كل مجموعة بطبيعتها على عقدة أساسية، ومن الممكن أيضًا إنشاء مجموعة ذات عقدة واحدة تتميز حصريًا بالعقدة الأساسية.
- العقدة الأساسية: تمثل العقد الأساسية العمود الفقري للمجموعة، وتضم مكونات برمجية متخصصة مصممة لتنفيذ المهام وتخزين البيانات في نظام الملفات الموزعة Hadoop (HDFS). في المجموعات متعددة العقد، تكون عقدة أساسية واحدة على الأقل جزءًا لا يتجزأ من البنية، مما يضمن التنفيذ السلس للمهام وتخزين البيانات.
- عقدة المهمة: تلعب عقد المهام دورًا مركزيًا، حيث تقوم بتشغيل المهام بشكل حصري دون المساهمة في تخزين البيانات في HDFS. تعمل عقد المهام، على الرغم من كونها اختيارية، على تعزيز تعدد استخدامات المجموعة من خلال تنفيذ المهام بكفاءة دون تحمل مسؤوليات تخزين البيانات.
تعمل بنية مجموعة Amazon EMR على تحسين معالجة البيانات وتخزينها باستخدام أنواع العقد المميزة، مما يوفر المرونة لتخصيص المجموعات وفقًا لمتطلبات التطبيقات المحددة.
نظرة عامة على بنية Amazon EMR
يتمحور الهيكل الأساسي لخدمة Amazon EMR حول بنية متعددة الطبقات، حيث تساهم كل طبقة بقدرات ووظائف مميزة في تشغيل المجموعة بشكل عام.
الخزائن
تشتمل طبقة التخزين على أنظمة ملفات متنوعة تشكل جزءًا لا يتجزأ من مجموعتك. تشمل الخيارات البارزة ما يلي:
نظام الملفات الموزعة Hadoop (HDFS)
نظام ملفات موزع وقابل للتطوير مصمم لـ Hadoop، حيث يقوم بتوزيع البيانات عبر مثيلات المجموعة لضمان المرونة في مواجهة حالات فشل المثيلات الفردية. يخدم HDFS أغراضًا مثل تخزين النتائج الوسيطة مؤقتًا أثناء معالجة MapReduce ومعالجة أعباء العمل باستخدام عمليات الإدخال/الإخراج العشوائية الكبيرة.
نظام ملفات السجلات الطبية الإلكترونية (EMRFS)
من خلال توسيع قدرات Hadoop، يتيح EMRFS الوصول المباشر إلى البيانات المخزنة في Amazon S3، ويدمجها بسلاسة كنظام ملفات مشابه لنظام HDFS. تسمح هذه المرونة للمستخدمين باختيار إما HDFS أو Amazon S3 كنظام ملفات، مع استخدام Amazon S3 بشكل شائع لتخزين بيانات الإدخال/الإخراج وHDFS للنتائج المتوسطة.
نظام الملفات المحلي
بالإشارة إلى الأقراص المتصلة محليًا، يعمل نظام الملفات المحلي على كتلة تخزين مكونة مسبقًا متصلة بمثيلات Amazon EC2 أثناء إنشاء مجموعة Hadoop. تستمر البيانات الموجودة على وحدات تخزين المثيلات هذه فقط طوال مدة دورة حياة مثيل Amazon EC2 المعني.
إدارة موارد الكتلة
تتحكم هذه الطبقة في التخصيص والجدولة الفعالة لموارد المجموعة لمهام معالجة البيانات. تقوم Amazon EMR افتراضيًا بالاستفادة من YARN (مفاوض موارد آخر)، وهو مكون تم تقديمه في Apache Hadoop 2.0 لإدارة الموارد المركزية. في حين أن مثيلات Spot غالبًا ما تقوم بتشغيل عقد المهام، فإن Amazon EMR يقوم بجدولة مهام YARN بذكاء لمنع حالات الفشل الناجمة عن إنهاء عقد المهام المستندة إلى مثيل Spot.
أطر معالجة البيانات
يوجد المحرك الذي يدفع معالجة البيانات وتحليلها في هذه الطبقة، مع أطر عمل مختلفة تلبي احتياجات المعالجة المتنوعة، مثل الدُفعات والتفاعلية والذاكرة والتدفق. تفتخر Amazon EMR بدعم أطر العمل الرئيسية، بما في ذلك:
Hadoop MapReduce
يعمل نموذج البرمجة مفتوح المصدر على تبسيط تطوير التطبيقات الموزعة المتوازية من خلال التعامل مع المنطق، بينما يوفر المستخدمون وظائف الخريطة والتقليل. وهو يدعم أطر عمل إضافية مثل Hive.
أباتشي سبارك
إطار عمل جماعي ونموذج برمجة لمعالجة أحمال عمل البيانات الضخمة، باستخدام الرسوم البيانية غير الدورية الموجهة والتخزين المؤقت في الذاكرة لتعزيز الكفاءة. يقوم Amazon EMR بدمج Spark بسلاسة، مما يسمح بالوصول المباشر إلى بيانات Amazon S3 عبر EMRFS.
التطبيقات والبرامج
يدعم Amazon EMR عددًا كبيرًا من التطبيقات مثل مكتبة Hive وPig وSpark Streaming، مما يوفر إمكانات مثل معالجة اللغة عالية المستوى وخوارزميات التعلم الآلي ومعالجة التدفق وتخزين البيانات. بالإضافة إلى ذلك، فهو يستوعب المشاريع مفتوحة المصدر مع وظائف إدارة المجموعات الخاصة بها. يتضمن التفاعل مع هذه التطبيقات استخدام مكتبات ولغات مختلفة، بما في ذلك Java وHive وPig وSpark Streaming وSpark SQL وMLlib وGraphX with Spark.
اقرأ أيضا: هل تريد أن تتعلم الحوسبة السحابية؟ ابدأ رحلتك مع AWS!
إعداد مجموعة السجلات الطبية الإلكترونية الأولى الخاصة بك
لتعيين مجموعة EMR الأولى لدينا، سنتبع الخطوات التالية:
إنشاء نظام الملفات في S3
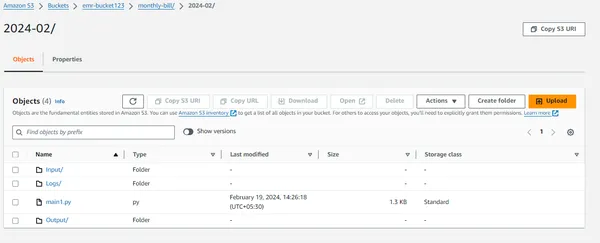
للبدء في إنشاء نظام ملفات EMR، تتضمن خطوتنا الأولى إنشاء حاوية S3. وبعد ذلك، ضمن هذه المجموعة، سنقوم بإنشاء مجلد معين وتنفيذ التشفير من جانب الخادم. سيتضمن التنظيم الإضافي داخل هذا المجلد إنشاء ثلاثة مجلدات فرعية: مجلد الإدخال لتلقي بيانات الإدخال، ومجلد الإخراج لتخزين المخرجات من عملية السجلات الطبية الإلكترونية، ومجلد السجلات للحفاظ على السجلات ذات الصلة.
ومن الضروري ملاحظة أنه أثناء إنشاء كل من هذه المجلدات، سيتم تمكين التشفير من جانب الخادم لتعزيز التدابير الأمنية. سوف تشبه بنية المجلد الناتج ما يلي:
└── emr-bucket123/
└── monthly-bill/
└── 2024-02/
├── Input
├── Output
└── Logs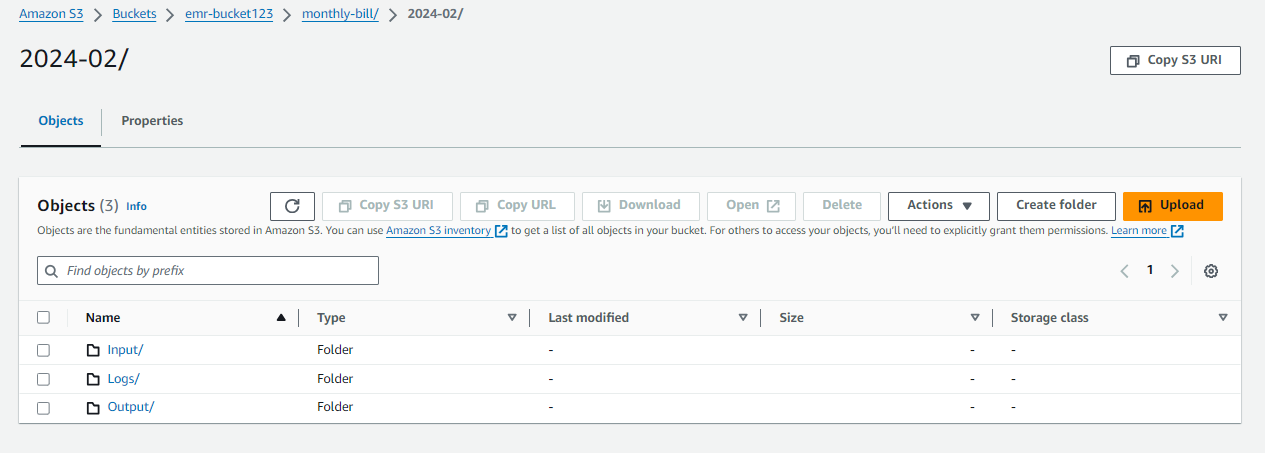
قم بإنشاء VPC
التالي على جدول أعمالنا هو إنشاء السحابة الافتراضية الخاصة (VPC). في هذا الإعداد، سنقوم بتكوين شبكتين فرعيتين عامتين مع إمكانية الوصول إلى الإنترنت، مما يضمن الاتصال السلس. ومع ذلك، لن تكون هناك أية شبكات فرعية خاصة في هذا التكوين المحدد.
للحصول على فهم شامل وإرشادات خطوة بخطوة حول إنشاء VPC، لا تتردد في استكشاف النظرة العامة والتعليمات الواردة أدناه:
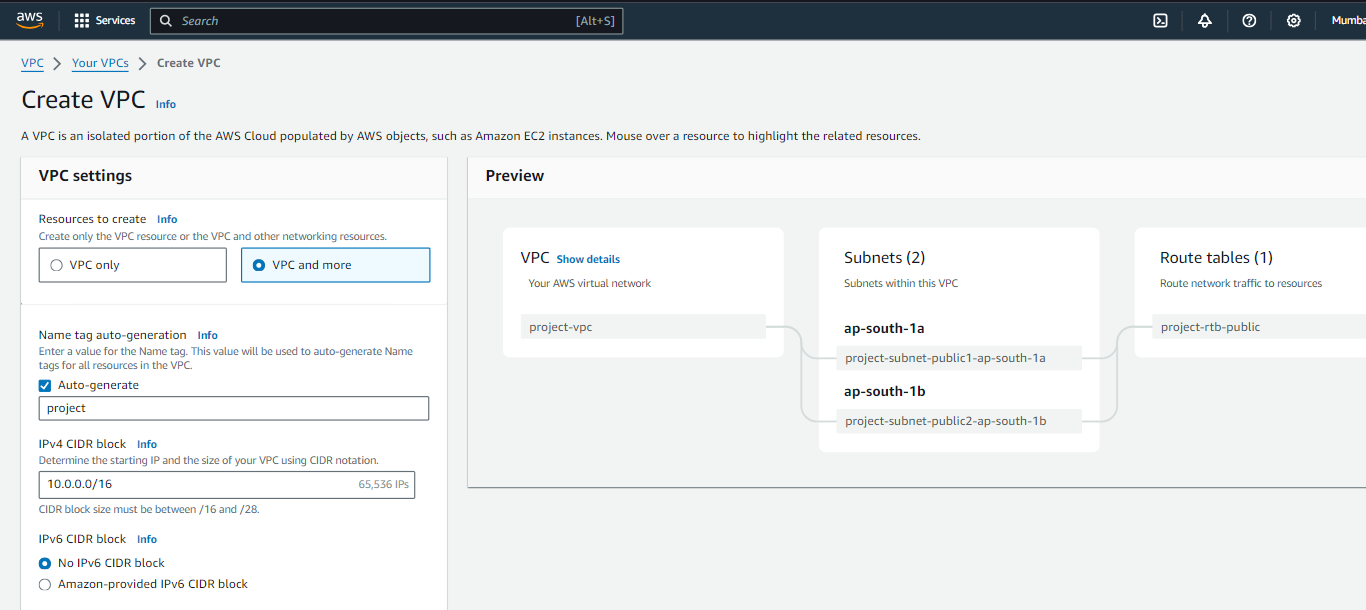
تكوين مجموعة السجلات الطبية الإلكترونية
بعد الإعداد، سننتقل إلى إنشاء مجموعة EMR. بمجرد النقر على خيار "إنشاء مجموعة"، ستكون الإعدادات الافتراضية متاحة:
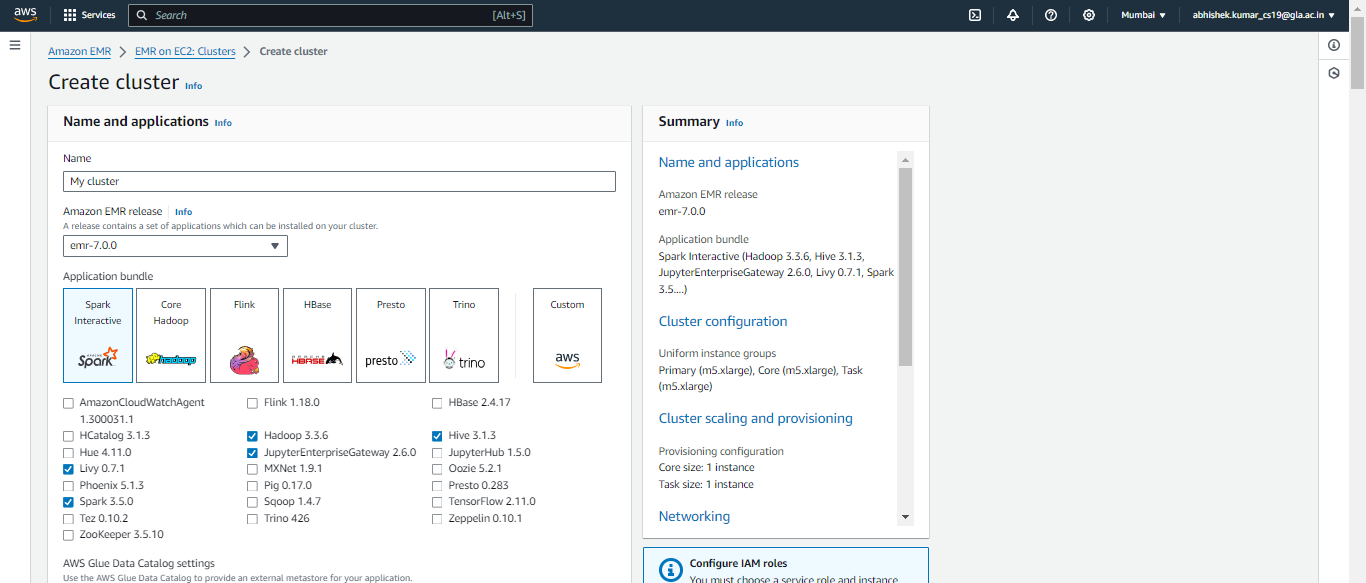
بعد ذلك، سننتقل إلى تكوين المجموعة ولكن بالنسبة لهذه المقالة، لن نغير أي شيء، وسنحتفظ بالتكوين الافتراضي ولكن يمكنك إزالة عقدة المهمة عن طريق تحديد إزالة مجموعة المثيلات خيار لحالة الاستخدام هذه لأنك لن تحتاج إليه كثيرًا لهذا الغرض.
الآن في الشبكات، عليك اختيار VPC الذي أنشأناه سابقًا:
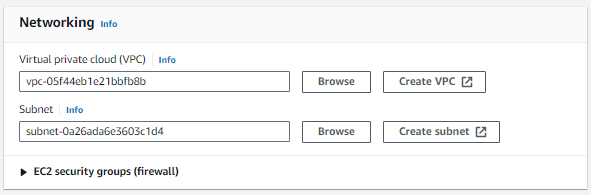
سنحتفظ الآن بالأشياء الافتراضية وننتقل إلى Cluster Logs ونتصفح إلى S3 الذي أنشأناه سابقًا للسجلات.
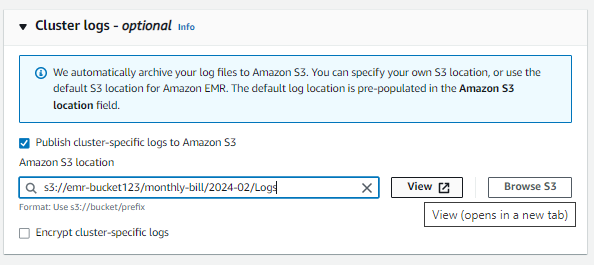
بعد تكوين السجلات، يتعين عليك الآن تعيين تكوين الأمان وزوج مفاتيح EC2 لسجل السجلات الطبية الإلكترونية الخاص بك، ويمكنك استخدام المفاتيح الموجودة أو إنشاء زوج جديد من المفاتيح.
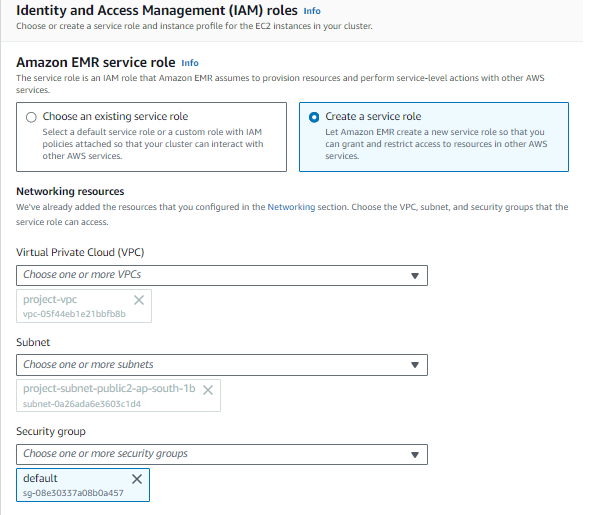
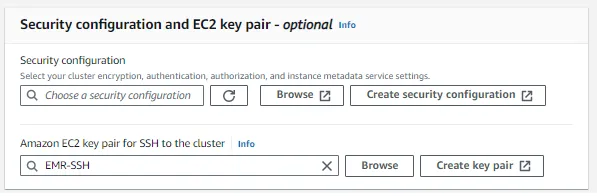
أدوار IAM حدد إنشاء دور الخدمة الخيار وتوفير VPC الذي قمت بإنشائه ووضع مجموعة الأمان الافتراضية.
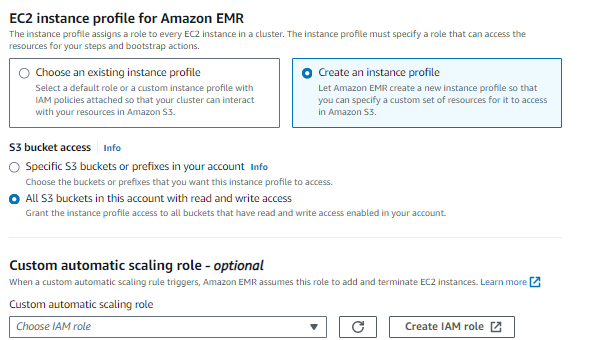
الآن في ملف تعريف مثيل EC2 لـ EMR، حدد إنشاء ملف تعريف المثيل الخيار ومنح الوصول إلى المجموعة لجميع S3.

لقد انتهيت الآن من كل الأشياء اللازمة لإعداد مجموعة EMR الأولى الخاصة بك، حيث تقوم بتشغيل مجموعتك من خلال النقر على خيار إنشاء مجموعة.
معالجة البيانات في مجموعة EMR
لمعالجة البيانات بشكل فعال داخل مجموعة السجلات الطبية الإلكترونية، نحتاج إلى برنامج نصي Spark مصمم لاسترداد مجموعة بيانات محددة ومعالجتها. في هذه المقالة سوف نستخدم مواد غذائية بيانات المنشأة. يوجد أدناه برنامج Python النصي المسؤول عن الاستعلام عن مجموعة البيانات ومعالجتها (LINK):
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
import argparse
def transform_data(data_source: str,output_uri: str)->None:
with SparkSession.builder.appName("My EMR Application").getOrCreate() as spark:
# Load CSV file
df = spark.read.option("header","true").csv(data_source)
#Rename Columns
df = df.select(
col("Name").alias("name"),
col("Violation Type").alias("violation_type")
)
#create an in-memory dataframe
df.createOrReplaceTempView("restaurant_violations")
#Construct SQL Query
GROUP_BY_QUERY='''
SELECT name,count(*) AS total_violations
FROM restaurant_violations
WHERE violation_type="RED"
GROUP BY name
'''
#Transform Data
transformed_df = spark.sql(GROUP_BY_QUERY)
#Log into EMR stdout
print(f"Number of rows in SQL query:{transformed_df.count()}")
#Write out results as parquet files
transformed_df.write.mode("overwrite").parquet(output_uri)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--data_source")
parser.add_argument("--output_uri")
args = parser.parse_args()
transform_data(args.data_source, args.output_uri)تم تصميم هذا البرنامج النصي لمعالجة بيانات المنشأة الغذائية بكفاءة ضمن مجموعة السجلات الطبية الإلكترونية، مما يوفر خطوات واضحة ومنظمة لتحويل البيانات وتخزين المخرجات.
الآن قم بتحميل ملف Python في مجموعة S3 وقم بتشفير الملف بعد تحميله.
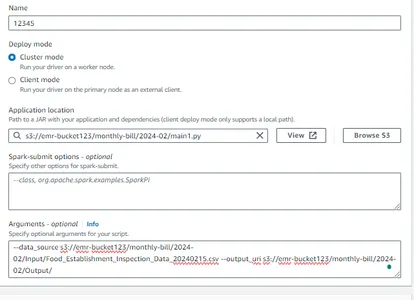
لتشغيل مجموعة السجلات الطبية الإلكترونية (EMR)، عليك إنشاء خطوات. انتقل إلى مجموعة EMR الخاصة بك، وانتقل إلى خيار "الخطوة"، ثم انقر على "إضافة خطوة".

بعد ذلك، قم بتوفير المسار إلى برنامج Python النصي الخاص بك (يمكن الوصول إليه من خلال خيار COPY S3 URI) بمجرد فتح المجموعة في متصفح الويب الخاص بك. ما عليك سوى النقر عليه ثم لصق المسار في مسار التطبيق وتكرار نفس العملية لمجموعة بيانات الإدخال عن طريق إدخال عنوان URI الخاص بالحاوية التي توجد بها مجموعة البيانات (على سبيل المثال، مجلد الإدخال في هذه الحالة)، وتعيين مصدر الإخراج إلى URI لمجموعة الإخراج.

الحجج
الآن يمكننا أن نرى أن الخطوة قد اكتملت أم لا.

اكتملت الآن معالجة البيانات في EMR، ويمكن ملاحظة الإخراج الناتج في مجلد الإخراج المخصص داخل حاوية S3.
تعظيم كفاءة التكلفة والأداء مع Amazon EMR
- الاستفادة من مثيلات Spot: توفر Amazon EMR خيار استخدام مثيلات Spot، وهي موارد EC2 غير مستخدمة متاحة بتكلفة مخفضة. ومن خلال الدمج الاستراتيجي لمثيلات Spot في المجموعات، يمكن للمؤسسات تحقيق وفورات كبيرة في التكاليف دون التضحية بالأداء.
- تقديم أساطيل المثيلات: يقدم Amazon EMR فكرة أساطيل المثيلات، مما يمكّن المستخدمين من تخصيص مجموعة من المثيلات عند الطلب والمثيلات الفورية ضمن مجموعة موحدة. تسمح هذه القدرة على التكيف للمؤسسات بإيجاد التوازن الأمثل بين فعالية التكلفة والتوافر.
مراقبة مجموعة السجلات الطبية الإلكترونية
تعد مراقبة مجموعة Amazon EMR (Elastic MapReduce) أمرًا ضروريًا لضمان صحتها وأدائها واستخدام الموارد بكفاءة. توفر السجلات الطبية الإلكترونية (EMR) العديد من الأدوات والآليات لمراقبة المجموعات. فيما يلي بعض الجوانب الرئيسية التي يمكنك وضعها في الاعتبار:
- مقاييس Amazon CloudWatch
- وحدة تحكم AWS EMR
- تسجيل
- Ganglia وSpark Web UI
- استخدام الموارد
تذكر أن تقوم بتكييف استراتيجية المراقبة الخاصة بك بناءً على المتطلبات والخصائص المحددة لعبء العمل وحالة الاستخدام لديك. قم بمراجعة وتحديث إعداد المراقبة الخاص بك بانتظام لتلبية الاحتياجات المتغيرة وتحسين أداء المجموعة.
اقرأ أيضا: AWS مقابل Azure: Ultimate Cloud Face-Off
وفي الختام
تقدم Amazon EMR حلاً فعالاً لمعالجة البيانات الضخمة، مع نظام أساسي مرن وفعال لإدارة مجموعات البيانات الشاملة. تضمن بنيتها القائمة على المجموعة، إلى جانب المكونات متعددة الطبقات، تعدد الاستخدامات والتحسين لتلبية احتياجات التطبيقات المتنوعة. يتضمن إنشاء مجموعة السجلات الطبية الإلكترونية خطوات بسيطة، كما أن تكاملها مع أطر العمل مفتوحة المصدر الشائعة يعزز جاذبيتها.
يوضح عرض معالجة البيانات ضمن مجموعة السجلات الطبية الإلكترونية (EMR) باستخدام برنامج Spark النصي قدرات النظام الأساسي. تعمل إستراتيجيات مثل الاستفادة من مثيلات Spot وأساطيل المثيلات على زيادة كفاءة التكلفة إلى الحد الأقصى، مما يسلط الضوء على التزام EMR بتوفير حلول فعالة من حيث التكلفة.
تعد المراقبة الفعالة لمجموعات السجلات الطبية الإلكترونية أمرًا ضروريًا للحفاظ على الأداء واستخدام الموارد. أدوات مثل Amazon CloudWatch وميزات التسجيل تسهل عملية المراقبة هذه. تعد Amazon EMR أداة حيوية وسهلة الاستخدام، وتوفر وصولاً سلسًا إلى معالجة البيانات المتقدمة.
الأسئلة المتكررة
ج. Amazon EMR، أو Elastic MapReduce، هي خدمة قائمة على السحابة من AWS مصممة لمعالجة البيانات الضخمة بكفاءة باستخدام أدوات مفتوحة المصدر مثل Apache Spark وHive.
A. تعمل EMR على تحسين معالجة البيانات من خلال بنية عنقودية تحتوي على العقد الأساسية والأساسية وعقد المهام، مما يوفر المرونة والكفاءة لمتطلبات التطبيقات المتنوعة.
ج. يتضمن إعداد مجموعة EMR إنشاء حاوية S3 وتكوين VPC وتهيئة المجموعة من خلال وحدة تحكم AWS EMR.
ج. تتضمن إستراتيجيات كفاءة التكلفة الاستفادة من مثيلات Spot واستخدام أساطيل المثيلات لتحقيق التوازن الأمثل بين فعالية التكلفة والتوافر.
ج: تعد مراقبة مجموعات السجلات الطبية الإلكترونية أمرًا ضروريًا لضمان الصحة والأداء والاستخدام الفعال للموارد. تساعد أدوات مثل Amazon CloudWatch وميزات التسجيل في المراقبة الفعالة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/03/what-is-aws-emr-heres-everything-you-need-to-know/
- :لديها
- :يكون
- :ليس
- :أين
- $ UP
- 10
- 11
- 17
- 2%
- 515
- 610
- 8
- a
- الوصول
- الوصول إلى البيانات
- يمكن الوصول
- يستوعب
- في
- اسيكليك
- تكيف
- تكيف
- إضافي
- وبالإضافة إلى ذلك
- العنوان
- متقدم
- بعد
- ضد
- جدول أعمال
- خوارزميات
- الكل
- تخصيص
- توزيع
- السماح
- يسمح
- على طول
- أمازون
- Amazon EC2
- أمازون EMR
- من بين
- المبالغ
- an
- تحليل
- تحليل
- و
- آخر
- أي وقت
- اى شى
- أباتشي
- أباتشي سبارك
- استئناف
- تطبيق
- التطبيقات
- نهج
- بجدارة
- هندسة معمارية
- هي
- حول
- البند
- AS
- طلب
- الجوانب
- مساعدة
- At
- تعلق
- توفر
- متاح
- AWS
- Azure
- العمود الفقري
- الرصيد
- على أساس
- BE
- كان
- بدأ
- أقل من
- الفوائد
- ما بين
- كبير
- البيانات الكبيرة
- حظر
- تفتخر
- المتصفح
- باني
- الأعمال
- لكن
- by
- CAN
- قدرات
- حقيبة
- التموين
- تسبب
- مركزية
- تحدى
- تغيير
- متغير
- الخصائص
- اختار
- واضح
- انقر
- النقر
- سحابة
- الحوسبة السحابية
- كتلة
- الأعمدة
- مجموعة
- التزام
- عادة
- إكمال
- الطلب مكتمل
- التعقيدات
- عنصر
- مكونات
- شامل
- إحصاء
- الحوسبة
- مفهوم
- الاعداد
- تكوين
- متصل
- الإتصال
- نظر
- كنسولات
- المساهمة
- رابطة
- نسخة
- جوهر
- التكلفة
- وفورات في التكاليف
- فعاله من حيث التكلفه
- حرفة
- خلق
- خلق
- خلق
- خلق
- حاسم
- البيانات
- معالجة المعلومات
- تخزين البيانات
- قواعد البيانات
- صفر
- الترتيب
- الافتراضات
- مطالب
- محدد
- تصميم
- التطوير التجاري
- بجد
- مباشرة
- الوصول المباشر
- توجه
- خامد
- وزعت
- توزيع
- توزيع
- عدة
- do
- هل
- فعل
- قيادة
- مدة الأقامة
- أثناء
- ديناميكي
- e
- كل
- في وقت سابق
- الطُرق الفعّالة
- على نحو فعال
- كفاءة
- فعال
- بكفاءة
- إما
- الشروع
- يعمل
- تمكين
- تمكين
- تمكن
- يشمل
- يشمل
- تشفير
- التشفير
- محرك
- تعزيز
- تعزيز
- يعزز
- ضمان
- يضمن
- ضمان
- أدخل
- الدخول
- كامل
- توازن
- أساسي
- تأسيس
- الأثير (ETH)
- حتى
- كل
- كل شىء
- على وجه الحصر
- تنفيذ
- تنفيذ
- القائمة
- اكتشف
- استكشاف
- واسع
- تسهيل
- الفشل
- قابليه
- المميزات
- ويتميز
- شعور
- قم بتقديم
- ملفات
- مالي
- الاسم الأول
- مرونة
- مرن
- ركز
- اتباع
- متابعيك
- طعام
- في حالة
- القوة
- التأسيسية
- الإطار
- الأطر
- مجانًا
- تبدأ من
- بالإضافة إلى
- وظيفة
- وظائف
- وظائف
- أساسي
- إضافي
- توليد
- جيل
- منح
- يحكم
- الرسوم البيانية
- أكبر
- تجمع
- توجيه
- Hadoop
- معالجة
- يملك
- صحة الإنسان
- هنا
- مرتفع
- تسليط الضوء
- خلية النحل
- منـزل
- كيفية
- لكن
- HTTPS
- i
- IAM
- if
- يوضح
- صورة
- صيغة الامر
- تنفيذ
- استيراد
- أهمية
- in
- تتضمن
- يشمل
- بما فيه
- فرد
- متأصل
- بدء
- الابتكار
- إدخال
- مثل
- حالات
- تعليمات
- متكامل
- يدمج
- دمج
- التكامل
- التفاعل
- التفاعلية
- متوسط
- Internet
- الدخول إلى الإنترنت
- إلى
- أدخلت
- يدخل
- ينطوي
- IT
- انها
- جافا
- المشــاريــع
- رحلة
- احتفظ
- القفل
- مفاتيح
- علم
- معروف
- المشهد
- لغة
- اللغات
- إطلاق
- طبقة
- تعلم
- تعلم
- الأقل
- الاستفادة من
- المكتبات
- المكتبة
- يكمن
- دورة حياة
- مثل
- تحميل
- محلي
- محليا
- تقع
- سجل
- تسجيل
- منطق
- بحث
- آلة
- آلة التعلم
- المحافظة
- إدارة
- إدارة
- تلاعب
- كثير
- رسم خريطة
- ماكس العرض
- تعظيم
- الإجراءات
- آليات
- بدقة
- نموذج
- تصميم
- مراقبة
- شاشات
- خطوة
- كثيرا
- متعدد الطبقات،
- my
- الاسم
- التنقل
- حاجة
- إحتياجات
- الشبكات
- أبدا
- جديد
- العقدة
- العقد
- بدون اضاءة
- جدير بالذكر
- لاحظ
- Notion
- الآن
- عدد
- ملاحظ
- of
- الوهب
- عروض
- غالبا
- on
- على الطلب
- مرة
- ONE
- فقط
- جاكيت
- المصدر المفتوح
- تعمل
- عملية
- الأمثل
- التحسين
- الأمثل
- المثلى
- خيار
- مزيد من الخيارات
- or
- منظمة
- المنظمات
- منظم
- أخرى
- لنا
- خارج
- الناتج
- النتائج
- الكلي
- فوق
- نظرة عامة
- زوج
- موازية
- خاص
- مسار
- أداء
- لا يزال قائما
- ابتليت
- المنصة
- منصات التداول
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- بلايستشن
- وفرة أو فرط
- الرائج
- قوي
- محتمل
- قوة
- منع
- ابتدائي
- خاص
- والمضي قدما
- عملية المعالجة
- معالجة
- ملفي الشخصي
- برمجة وتطوير
- مشروع ناجح
- بارز
- دافع
- تزود
- المقدمة
- ويوفر
- توفير
- جمهور
- أغراض
- وضع
- بايثون
- سؤال
- سؤال
- عشوائية
- عرض
- أدرك
- يستلم
- أحمر
- تخفيض
- عقار مخفض
- يشار
- بانتظام
- ذات الصلة
- إزالة
- كرر
- تطلب
- المتطلبات الأساسية
- يقيم
- مرونة
- مورد
- الموارد
- هؤلاء
- المسؤوليات
- مسؤول
- مما أدى
- النتائج
- مراجعة
- ثور
- يدور
- النوع
- الأدوار
- الصفوف
- يجري
- تشغيل
- s
- التضحية
- نفسه
- مدخرات
- التدرجية
- تحجيم
- جدولة
- سيناريو
- سلس
- بسلاسة
- أمن
- تدابير أمنية
- انظر تعريف
- حدد
- اختيار
- يخدم
- الخدمة
- طقم
- ضبط
- إعدادات
- الإعداد
- عدة
- هام
- الاشارات
- يبسط
- ببساطة
- So
- تطبيقات الكمبيوتر
- مكونات البرامج
- حل
- الحلول
- بعض
- مصدر
- شرارة
- متخصص
- محدد
- بقعة
- SQL
- الحالة
- خطوة
- خطوات
- تخزين
- متجر
- تخزين
- تخزين
- إستراتيجيا
- استراتيجيات
- الإستراتيجيات
- مجرى
- متدفق
- بناء
- الشبكات الفرعية
- بعد ذلك
- جوهري
- هذه
- الدعم
- الدعم
- نظام
- أنظمة
- معالجة
- خياط
- مهمة
- المهام
- أن
- •
- من مشاركة
- then
- هناك.
- تشبه
- هم
- الأشياء
- ثلاثة
- عبر
- إلى
- أداة
- أدوات
- المسارات
- تحول
- صحيح
- اثنان
- نوع
- أنواع
- نهائي
- كشف
- فهم
- يتعهد
- موحد
- فتح
- غير المستخدمة
- تحديث
- تحميل
- URI
- تستخدم
- حالة الاستخدام
- مستعمل
- سهل الاستعمال
- المستخدمين
- استخدام
- استخدام
- الاستفادة من
- استخدام
- مختلف
- كبير
- طلاقة الحركة
- بواسطة
- عنيف
- افتراضي
- حيوي
- مجلدات
- vs
- وحدات التخزين
- we
- الويب
- متصفح الويب
- ويب بي
- ابحث عن
- ما هي تفاصيل
- التي
- في حين
- لماذا
- سوف
- مع
- في غضون
- بدون
- سير العمل
- اكتب
- حتى الآن
- لصحتك!
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت