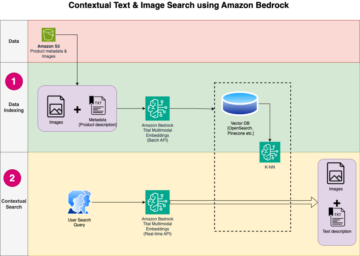
Korrekt estimering af prædiktiv usikkerhed er grundlæggende i applikationer, der involverer kritiske beslutninger. Usikkerhed kan bruges til at vurdere pålideligheden af modelforudsigelser, udløse menneskelig indgriben eller afgøre, om en model sikkert kan placeres i naturen.
Vi introducerer Fortuna, et open source-bibliotek til kvantificering af usikkerhed. Fortuna leverer kalibreringsmetoder, såsom konform forudsigelse, der kan anvendes på ethvert trænet neuralt netværk for at opnå kalibrerede usikkerhedsestimater. Biblioteket understøtter yderligere en række Bayesianske inferensmetoder, der kan anvendes på dybe neurale netværk skrevet i Hør. Biblioteket gør det nemt at køre benchmarks og vil gøre det muligt for praktikere at bygge robuste og pålidelige AI-løsninger ved at drage fordel af avancerede usikkerhedskvantificeringsteknikker.
Problemet med overmod til dyb læring
Hvis du nogensinde har set på klassesandsynligheder returneret af en trænet dyb neural netværksklassifikator, har du måske observeret, at sandsynligheden for en klasse var meget større end de andre. Noget som dette, for eksempel:
p = [0.0001, 0.0002, …, 0.9991, 0.0003, …, 0.0001]
Hvis dette er tilfældet for størstedelen af forudsigelserne, kan din model være overmodig. For at evaluere gyldigheden af de sandsynligheder, der returneres af klassifikatoren, kan vi sammenligne dem med den faktiske nøjagtighed opnået over et holdout-datasæt. Det er faktisk naturligt at antage, at andelen af korrekt klassificerede datapunkter tilnærmelsesvis bør matche den estimerede sandsynlighed for den forudsagte klasse. Dette koncept er kendt som kalibrering [Guo C. et al., 2017].
Desværre er mange trænede dybe neurale netværk fejlkalibrerede, hvilket betyder, at den estimerede sandsynlighed for den forudsagte klasse er meget højere end andelen af korrekt klassificerede inputdatapunkter. Med andre ord, klassificereren er overmodig.
At være overmodig kan være problematisk i praksis. En læge bestiller muligvis ikke relevante yderligere tests, som følge af en overmodig sund diagnose produceret af en AI. En selvkørende bil kan beslutte ikke at bremse, fordi den med sikkerhed vurderede, at genstanden foran ikke var en person. En guvernør kan beslutte at evakuere en by, fordi sandsynligheden for en eminent naturkatastrofe estimeret af en AI er for høj. I disse og mange andre applikationer er kalibrerede usikkerhedsestimater afgørende for at vurdere pålideligheden af modelforudsigelser, falde tilbage til en menneskelig beslutningstager eller beslutte, om en model kan implementeres sikkert.
Fortuna: Et bibliotek til kvantificering af usikkerhed
Der er mange offentliggjorte teknikker til enten at estimere eller kalibrere forudsigelsernes usikkerhed, f.eks. Bayesiansk inferens [Wilson AG, 2020], temperaturskalering [Guo C. et al., 2017], og konform forudsigelse [Angelopoulos AN et al., 2022] metoder. Eksisterende værktøjer og biblioteker til kvantificering af usikkerhed har dog et snævert omfang og tilbyder ikke en bredde af teknikker ét enkelt sted. Dette resulterer i en betydelig overhead, der forhindrer overtagelsen af usikkerhed i produktionssystemer.
For at udfylde dette hul lancerer vi Fortuna, et bibliotek til kvantificering af usikkerhed, der samler fremtrædende metoder på tværs af litteraturen og gør dem tilgængelige for brugere med en standardiseret og intuitiv grænseflade.
Antag som et eksempel, at du har trænings-, kalibrerings- og testdataindlæsere i tensorflow.Tensor format, nemlig train_data_loader, calib_data_loader , test_data_loader. Ydermere har du en deep learning-model skrevet ind Hør, nemlig model. Så kan du bruge Fortuna til at:
- passe en posterior fordeling;
- kalibrer modeludgangene;
- lave kalibrerede forudsigelser;
- skøn over usikkerhed;
- beregne evalueringsmetrikker.
Den følgende kode gør alt dette for dig.
Ovenstående kode gør brug af flere standardvalg, herunder SWAG [Maddox WJ et al., 2019] som en posterior inferensmetode, temperaturskalering [Guo C. et al., 2017] til at kalibrere modeloutput, og en standard Gaussisk forudgående fordeling, samt konfigurationen af den posteriore tilpasning og kalibreringsprocesser. Du kan nemt konfigurere alle disse komponenter, og du opfordres stærkt til at gøre det, hvis du leder efter en specifik konfiguration, eller hvis du vil sammenligne flere.
Brugstilstande
Fortuna tilbyder tre brugstilstande: 1/ Starter fra Hør-modeller, 2 / Starter fra modeludgange, og 3/ Ud fra usikkerhedsestimater. Deres rørledninger er afbildet i den følgende figur, hver startende fra et af de grønne paneler. Kodestykket ovenfor er et eksempel på brug af Fortuna med udgangspunkt i Flax-modeller, som gør det muligt at træne en model ved hjælp af Bayesianske inferensprocedurer. Alternativt kan du starte enten ved modeloutput eller direkte fra dine egne usikkerhedsestimater. Begge disse sidstnævnte tilstande er rammeuafhængig og hjælpe dig med at opnå kalibrerede usikkerhedsestimater fra en trænet model.

1/ Ud fra usikkerhedsestimater
At starte fra usikkerhedsestimater har minimale kompatibilitetskrav, og det er det hurtigste niveau af interaktion med biblioteket. Denne brugstilstand tilbyder konforme forudsigelsesmetoder til både klassificering og regression. Disse tager usikkerhedsestimater ind numpy.ndarray formatere og returnere strenge sæt forudsigelser, der bevarer et brugergivet sandsynlighedsniveau. I endimensionelle regressionsopgaver kan konforme sæt opfattes som kalibrerede versioner af konfidens eller troværdige intervaller.
Vær opmærksom på, at hvis usikkerhedsestimaterne, som du angiver i input, er unøjagtige, kan konforme sæt være store og ubrugelige. Af denne grund, hvis din ansøgning tillader det, bedes du overveje Starter fra modeludgange , Starter fra Hør-modeller brugstilstande beskrevet nedenfor.
2/ Starter fra modeludgange
Denne tilstand antager, at du allerede har trænet en model i nogle rammer og ankommer til Fortuna med modeludgange i numpy.ndarray format for hvert inputdatapunkt. Denne brugstilstand giver dig mulighed for at kalibrere dine modeloutput, estimere usikkerhed, beregne metrikker og opnå konforme sæt.
Sammenlignet med Ud fra usikkerhedsestimater brugstilstand, Starter fra modeludgange giver bedre kontrol, da det kan sikre, at usikkerhedsestimater er blevet korrekt kalibreret. Men hvis modellen var blevet trænet med klassiske metoder, kan den resulterende kvantificering af model (alias epistemisk) usikkerhed være dårlig. For at afhjælpe dette problem skal du overveje Starter fra Hør-modeller brugstilstand.
3/ Starter fra Hør-modeller
Startende fra Flax-modeller har højere kompatibilitetskrav end Ud fra usikkerhedsestimater , Starter fra modeludgange brugstilstande, da det kræver deep learning-modeller skrevet ind Hør. Det giver dig dog mulighed for at erstatte standardmodeltræning med skalerbare Bayesianske inferensprocedurer, hvilket kan forbedre kvantificeringen af forudsigelig usikkerhed markant.
Bayesianske metoder fungerer ved at repræsentere usikkerhed om, hvilken løsning der er korrekt, givet begrænset information, gennem usikkerhed over modelparametre. Denne type usikkerhed kaldes "epistemisk" usikkerhed. Fordi neurale netværk kan repræsentere mange forskellige løsninger, svarende til forskellige indstillinger af deres parametre, kan Bayesianske metoder være særligt effektive i dyb læring. Vi leverer mange skalerbare Bayesianske inferensprocedurer, som ofte kan bruges til at give usikkerhedsestimater, samt forbedret nøjagtighed og kalibrering, i det væsentlige uden overhead til træningstid.
Konklusion
Vi annoncerede den generelle tilgængelighed af Fortuna, et bibliotek til kvantificering af usikkerhed i deep learning. Fortuna samler fremtrædende metoder på tværs af litteraturen, f.eks. konforme metoder, temperaturskalering og Bayesiansk inferens, og gør dem tilgængelige for brugere med en standardiseret og intuitiv grænseflade. For at komme i gang med Fortuna kan du konsultere følgende ressourcer:
Prøv Fortuna, og lad os vide, hvad du synes! Du opfordres til at bidrage til biblioteket eller efterlade dine forslag og bidrag - bare opret en spørgsmål eller åbn en Træk anmodning. På vores side vil vi fortsætte med at forbedre Fortuna, øge dets dækning af usikkerhedskvantificeringsmetoder og tilføje yderligere eksempler, der viser dets anvendelighed i flere scenarier.
Om forfatterne

Gianluca Detommaso er en anvendt videnskabsmand ved AWS. Han arbejder i øjeblikket med kvantificering af usikkerhed i deep learning. I sin fritid kan Gianluca godt lide at dyrke sport, spise god mad og lære nye færdigheder.
 Alberto Gasparin er en Applied Scientist i Amazon Community Shopping siden juli 2021. Hans interesser omfatter naturlig sprogbehandling, informationssøgning og usikkerhedskvantificering. Han er mad- og vinentusiast.
Alberto Gasparin er en Applied Scientist i Amazon Community Shopping siden juli 2021. Hans interesser omfatter naturlig sprogbehandling, informationssøgning og usikkerhedskvantificering. Han er mad- og vinentusiast.
 Michele Donini er Sr Applied Scientist ved AWS. Han leder et team af forskere, der arbejder med ansvarlig kunstig intelligens, og hans forskningsinteresser er Algorithmic Fairness og Explainable Machine Learning.
Michele Donini er Sr Applied Scientist ved AWS. Han leder et team af forskere, der arbejder med ansvarlig kunstig intelligens, og hans forskningsinteresser er Algorithmic Fairness og Explainable Machine Learning.
 Matthias Seeger er Principal Applied Scientist hos AWS.
Matthias Seeger er Principal Applied Scientist hos AWS.
 Cedric Archambeau er Principal Applied Scientist ved AWS og Fellow of European Lab for Learning and Intelligent Systems.
Cedric Archambeau er Principal Applied Scientist ved AWS og Fellow of European Lab for Learning and Intelligent Systems.
 Andrew Gordon Wilson er lektor ved Courant Institute of Mathematical Sciences og Center for Data Science ved New York University og Amazon Visiting Academic ved AWS. Han er især engageret i at bygge metoder til Bayesiansk og probabilistisk dyb læring, skalerbare Gaussiske processer, Bayesiansk optimering og fysik-inspireret maskinlæring.
Andrew Gordon Wilson er lektor ved Courant Institute of Mathematical Sciences og Center for Data Science ved New York University og Amazon Visiting Academic ved AWS. Han er især engageret i at bygge metoder til Bayesiansk og probabilistisk dyb læring, skalerbare Gaussiske processer, Bayesiansk optimering og fysik-inspireret maskinlæring.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/introducing-fortuna-a-library-for-uncertainty-quantification/
- 100
- 2017
- 2019
- 2020
- 2021
- 2022
- a
- over
- akademisk
- nøjagtighed
- opnået
- ACM
- tværs
- Yderligere
- Vedtagelse
- fremskreden
- Fordel
- AI
- algoritmisk
- Alle
- tillader
- allerede
- Amazon
- ,
- annoncerede
- Anvendelse
- applikationer
- anvendt
- passende
- cirka
- vurderes
- Associate
- tilgængelighed
- til rådighed
- AWS
- tilbage
- Bayesiansk
- fordi
- jf. nedenstående
- Benchmarks
- Bedre
- pin
- bredde
- Bringer
- bygge
- Bygning
- kaldet
- bil
- tilfælde
- center
- valg
- klasse
- klassificering
- klassificeret
- kode
- samfund
- sammenligne
- kompatibilitet
- komponenter
- Compute
- Konceptet
- tillid
- trygt
- Konfiguration
- Overvej
- bidrage
- kontrol
- konvertere
- Tilsvarende
- dækning
- skabe
- troværdig
- kritisk
- For øjeblikket
- data
- datapunkter
- datalogi
- datasæt
- beslutningstager
- afgørelser
- dyb
- dyb læring
- Standard
- indsat
- detaljeret
- forskellige
- direkte
- katastrofe
- fordeling
- Doctor
- hver
- nemt
- enten
- muliggøre
- muliggør
- tilskyndes
- beskæftiget
- entusiast
- fejl
- især
- væsentlige
- skøn
- anslået
- skøn
- Ether (ETH)
- europæisk
- evaluere
- evaluering
- NOGENSINDE
- eksempel
- eksempler
- eksisterende
- forventet
- fairness
- Fall
- fyr
- Figur
- udfylde
- montering
- efter
- mad
- format
- Framework
- fra
- forsiden
- fundamental
- yderligere
- Endvidere
- kløft
- Generelt
- få
- given
- Guvernør
- stor
- Grøn
- sund
- hjælpe
- Høj
- højere
- stærkt
- Men
- HTML
- HTTPS
- menneskelig
- effektfuld
- importere
- Forbedre
- forbedret
- forbedring
- in
- I andre
- forkert
- omfatter
- Herunder
- Forøg
- oplysninger
- indgang
- Institut
- Intelligent
- interaktion
- interesser
- grænseflade
- indgriben
- indføre
- indføre
- intuitiv
- involvere
- IT
- juli
- Holde
- Kend
- kendt
- lab
- Sprog
- stor
- større
- lancere
- Leads
- læring
- Forlade
- Niveau
- biblioteker
- Bibliotek
- Limited
- litteratur
- kiggede
- leder
- maskine
- machine learning
- Flertal
- lave
- maerker
- mange
- Match
- matematiske
- betyder
- metode
- metoder
- metrisk
- Metrics
- måske
- mindste
- afbøde
- tilstand
- model
- modeller
- nemlig
- Natural
- Natural Language Processing
- netværk
- net
- neurale netværk
- neurale netværk
- Ny
- New York
- nummer
- objekt
- tilbyde
- Tilbud
- ONE
- åbent
- open source
- optimering
- ordrer
- Andet
- Andre
- overmod
- egen
- paneler
- parametre
- især
- person,
- Place
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- Punkt
- punkter
- fattige
- praksis
- forudsagde
- forudsigelse
- Forudsigelser
- Main
- Forud
- Problem
- procedurer
- Processer
- forarbejdning
- produceret
- produktion
- Professor
- fremtrædende
- give
- giver
- offentliggjort
- hurtigste
- grund
- relevant
- pålidelighed
- pålidelig
- erstatte
- repræsentere
- repræsenterer
- Krav
- Kræver
- forskning
- Ressourcer
- ansvarlige
- resultere
- resulterer
- Resultater
- afkast
- stringent
- robust
- Kør
- sikkert
- skalerbar
- skalering
- scenarier
- Videnskab
- VIDENSKABER
- Videnskabsmand
- forskere
- rækkevidde
- selvkørende
- sæt
- sæt
- indstillinger
- flere
- Shopping
- bør
- udstillingsvindue
- signifikant
- betydeligt
- siden
- enkelt
- færdigheder
- So
- løsninger
- Løsninger
- nogle
- noget
- specifikke
- Sport
- standard
- starte
- påbegyndt
- Starter
- sådan
- Understøtter
- Swag
- Systemer
- Tag
- tager
- opgaver
- hold
- teknikker
- prøve
- tests
- deres
- tænkte
- tre
- Gennem
- tid
- til
- sammen
- også
- værktøjer
- Tog
- uddannet
- Kurser
- udløse
- Usikkerhed
- universitet
- us
- Brug
- brug
- brugere
- W
- Hvad
- hvorvidt
- som
- Wild
- vilje
- Wilson
- VIN
- inden for
- ord
- Arbejde
- arbejder
- virker
- skriftlig
- Din
- zephyrnet