Maschinelles Lernen (ML) kann komplex erscheinen, aber was wäre, wenn Sie ein Modell trainieren könnten, ohne Code schreiben zu müssen? Dieser Leitfaden erschließt die Leistungsfähigkeit von ML für alle, indem er zeigt, wie man ein ML-Modell ohne Code trainiert.
Inhaltsverzeichnis
Verwendeter Datensatz
Der Iris-Datensatz ist ein Klassiker auf dem Gebiet des maschinellen Lernens und bietet Anfängern einen einfachen Weg, den Prozess des Trainierens eines Modells für maschinelles Lernen zu erkunden. Es besteht aus 150 Proben von drei Irisarten (Iris setosa, Iris virginica und Iris versicolor) mit jeweils vier Merkmalen: Kelchblattlänge, Kelchblattbreite, Blütenblattlänge und Blütenblattbreite.
Dieses Projekt stellt vor Julius AI, ein leistungsstarkes No-Code-KI-Tool, das maschinelles Lernen vereinfacht. Mithilfe von Befehlen in natürlicher Sprache generiert Julius den erforderlichen Python-Code für jeden Schritt und führt ihn aus. Wir werden Julius nutzen, um Irispflanzen anhand von Merkmalen wie Kelchblatt- und Blütenblattabmessungen in ihre jeweiligen Arten zu klassifizieren. Dies zeigt, wie Sie ein Modell für maschinelles Lernen trainieren können, ohne Code schreiben zu müssen!
Schritte zum Trainieren eines ML-Modells ohne Code
Traditionell erforderte das Training von Modellen für maschinelles Lernen Programmierkenntnisse. Aber mit No-Code-Tools wie Julius kann jeder teilnehmen! Dieser Leitfaden bietet einen schrittweisen Ansatz zum Trainieren eines Modells auf dem Iris-Datensatz, wobei durchgehend Julius- und natürliche Sprachbefehle verwendet werden. Es sind keine Programmierkenntnisse erforderlich – lassen Sie uns den Prozess erkunden!
- Importieren des Datensatzes
- Erste Datenauswertung
- Datenreinigung
- Merkmalsauswahl
- Datenaufteilung
- Auswahl des Modelltyps
- Konfigurieren des Modells
- Das Modell trainieren
- Bewertung der Modellleistung
- Anpassungen und Verbesserungen
Lesen Sie auch: Leitfaden zur akademischen Datenanalyse mit Julius AI
Erste Schritte
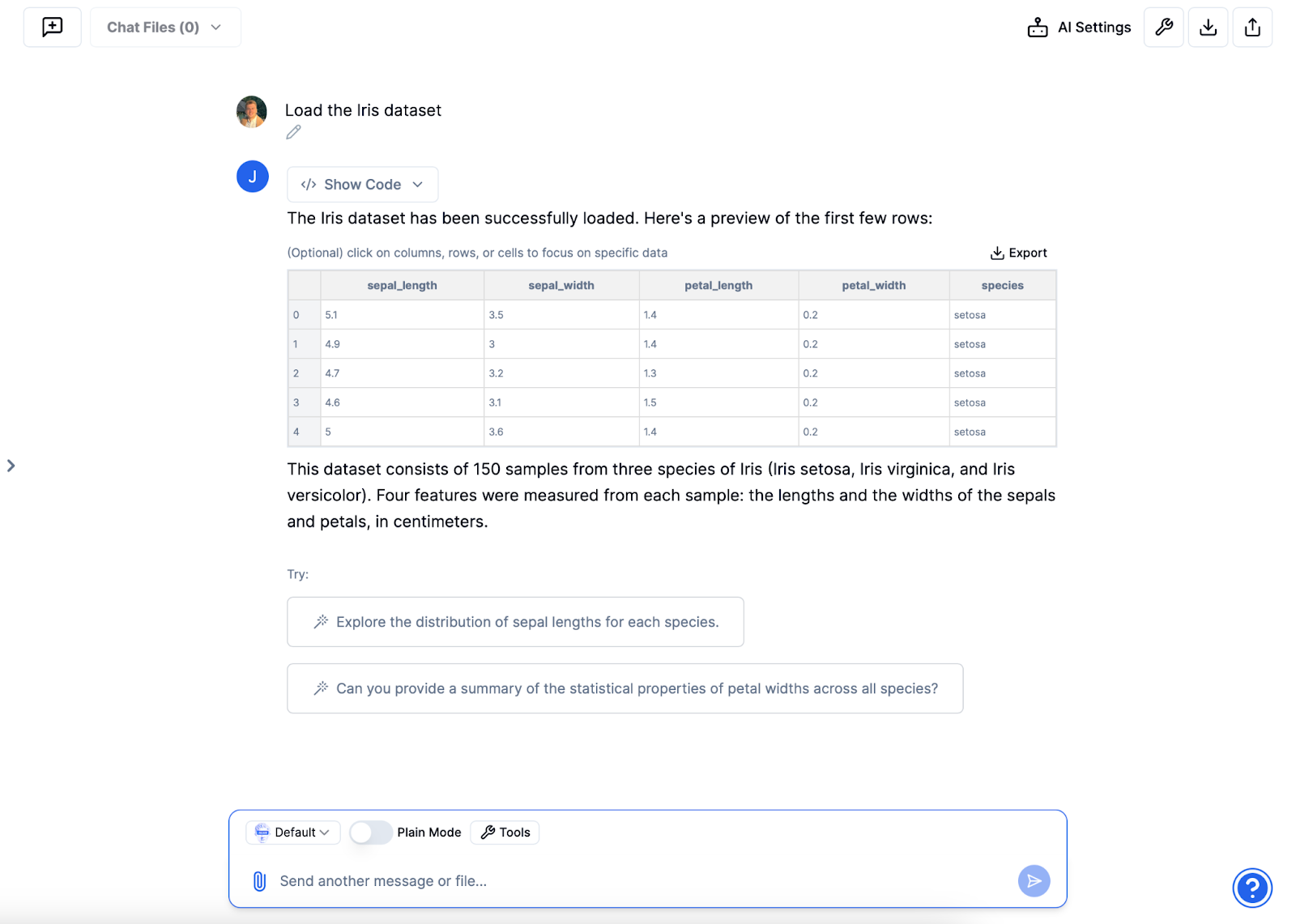
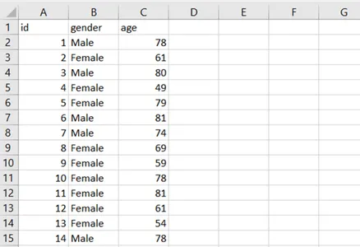
Importieren Sie den Iris-Datensatz in Julius
Navigieren Sie zunächst zu Julius.ai und importieren Sie den Iris-Datensatz. Normalerweise laden Sie eine kompatible Datei hoch, die Ihren Datensatz enthält (CSV, Excel oder Google Sheets). Da es sich bei Iris jedoch um einen so bekannten Datensatz handelt, können Sie einfach nachfragen Julius auf „Iris-Datensatz laden“ und kann Python-Code schreiben, um den Datensatz abzurufen.
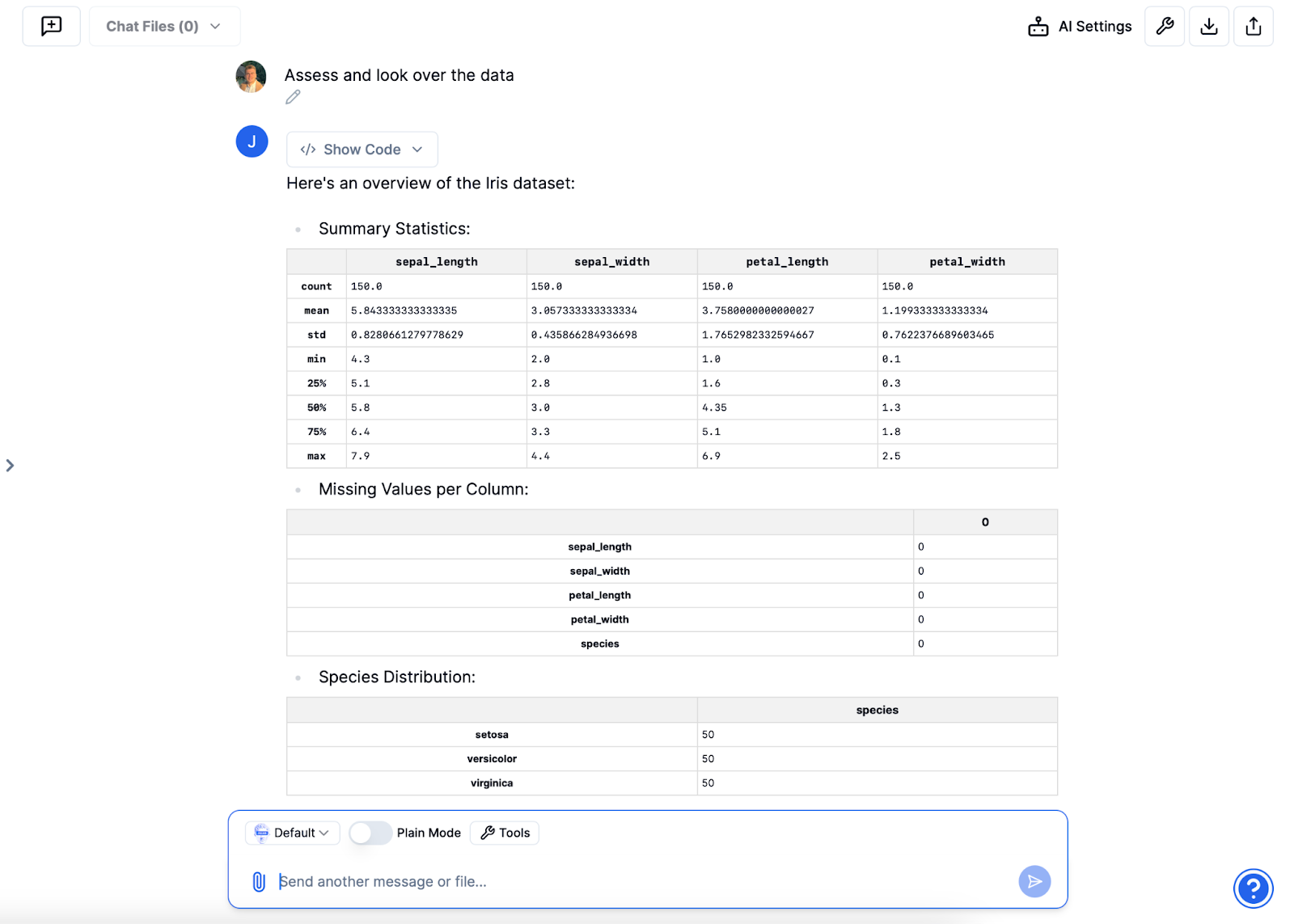
Erste Datenauswertung
Sobald der Datensatz importiert ist, können Sie eine erste Bewertung veranlassen, um Julius dabei zu helfen, seine Struktur und Inhalte zu verstehen. Dazu gehört das Erstellen zusammenfassender Statistiken, das Identifizieren der Anzahl von Features, das Erkennen von Datentypen und das Erkennen fehlender Werte, falls vorhanden.
Vorbereiten Ihrer Daten für das Training

Datenreinigung
Der Iris-Datensatz erfordert normalerweise nur eine minimale Reinigung. Aber keine Sorge, Julius ist hier, um zu helfen! Es sucht automatisch nach fehlenden oder inkonsistenten Daten und schlägt Lösungen vor. In diesem Fall stellt Julius sicher, dass alle numerischen Werte korrekt formatiert sind und keine Einträge fehlen – und das alles, ohne dass Sie eine einzige Codezeile schreiben müssen.
Merkmalsauswahl
Da alle vier Merkmale im Iris-Datensatz zur Klassifizierung der Art beitragen, werden wir sie alle verwenden. Mit Julius können Sie jedoch die Bedeutung von Merkmalen für komplexere Datensätze untersuchen und erhalten so wertvolle Einblicke in Ihre Daten.“

Datenaufteilung
Teilen Sie Ihre Daten vor dem Training in Trainings- und Testsätze auf. Ein übliches Aufteilungsverhältnis beträgt 80 % für Training und 20 % für Tests. Julius automatisiert diesen Prozess und stellt sicher, dass Ihr Modell an einem Teil des Datensatzes trainiert und an einem unsichtbaren Teil getestet wird, um eine unvoreingenommene Bewertung zu ermöglichen.
Trainieren Sie Ihr Modell für maschinelles Lernen
Wählen Sie Ihren Modelltyp
Für den Iris-Datensatz ist ein Klassifizierungsmodell geeignet. Julius bietet verschiedene Algorithmen zur Klassifizierung, wie etwa logistische Regression, Entscheidungsbäume und k-Nearest Neighbors (KNN). Für Anfänger ist KNN aufgrund seiner Einfachheit und Wirksamkeit ein guter Einstieg.
Konfigurieren Sie das Modell
Bei Julius umfasst die Konfiguration Ihres Modells die Auswahl des Algorithmus (z. B. KNN) und die Einstellung aller relevanten Parameter. Für KNN können Sie mit der Standardanzahl von Nachbarn beginnen (z. B. 5) und diese je nach Leistung anpassen.

Trainiere das Modell
Beginnen Sie den Trainingsprozess, indem Sie Julius anweisen, den ausgewählten Algorithmus auf Ihre Trainingsdaten anzuwenden. Julius verwaltet die Rechenaufgaben und hält Sie über den Fortschritt und Abschluss der Schulung auf dem Laufenden.
Bewertung der Modellleistung
Leistungsmetriken
Nach dem Training präsentiert Julius die Leistungsmetriken des Modells, wie Genauigkeit, Präzision, Erinnerung und F1-Score. Anhand dieser Messwerte lässt sich beurteilen, wie gut Ihr Modell gelernt hat, die Irisarten zu klassifizieren. Da es sich um ein relativ einfaches Modell handelt, war die Genauigkeit perfekt und jede Art wurde korrekt identifiziert.
Anpassungen und Verbesserungen
Wenn die ersten Ergebnisse nicht zufriedenstellend sind, können Sie die Parameter des Modells anpassen (z. B. die Anzahl der Nachbarn in KNN ändern) oder einen anderen Algorithmus ausprobieren. Julius erleichtert dieses Experimentieren und führt Sie zur Verbesserung der Modellleistung.
Erkundung jenseits von Julius: Alternative No-Code-ML-Lösungen
Während Julius Anfängern eine benutzerfreundliche Plattform zum Einstieg in maschinelles Lernen bietet, ist dies nur die Spitze des Eisbergs. Die Palette der No-Code-Tools für maschinelles Lernen ist riesig und bietet sowohl Enthusiasten als auch Profis zahlreiche Möglichkeiten, Modelle zu erstellen, zu trainieren und bereitzustellen, ohne sich mit Code zu befassen.
Plattformen wie die von Google AutoML und Microsoft Azure Machine Learning Studio haben den Zugang zu leistungsstarken maschinellen Lernfunktionen demokratisiert. Diese Plattformen vereinfachen nicht nur den Prozess des Modelltrainings, sondern bieten auch erweiterte Funktionen für komplexere Projekte. Ganz gleich, ob Sie benutzerdefinierte Bilderkennungsmodelle erstellen, Geschäftsmetriken prognostizieren oder Stimmungen aus Texten analysieren möchten, es gibt eine Lösung ohne Code für Sie.
Ideen für Ihre nächsten No-Code-Projekte
Tauchen Sie tiefer in die Welt des maschinellen Lernens ohne Code ein und finden Sie hier drei spannende Projektideen, mit denen Anfänger ihre ML-Fähigkeiten und ihr Verständnis erweitern können:
- Börsenprognose: Nutzen Sie historische Aktienkursdaten, um zukünftige Trends vorherzusagen. Indem Sie Ihre No-Code-Plattform mit Zeitreihendaten versorgen, können Sie verschiedene Algorithmen zur Prognose von Aktienkursen erkunden. Dieses Projekt bietet praktische Erfahrungen mit Finanzdatensätzen und führt Sie in die Konzepte der Regressionsanalyse und Zeitreihenprognose ein.
- Analyse der Kundenstimmung: Analysieren Sie Kundenrezensionen oder Social-Media-Beiträge, um die Stimmung gegenüber Produkten oder Marken einzuschätzen. Bei diesem Projekt geht es darum, Textdaten in Kategorien wie positiv, negativ oder neutral zu klassifizieren. Es ist eine großartige Möglichkeit, etwas über die Verarbeitung natürlicher Sprache (NLP) zu lernen und zu verstehen, wie maschinelles Lernen Erkenntnisse aus Texten gewinnen kann.
- Bildklassifizierung für den Einzelhandel: Erstellen Sie ein Modell, das Bilder von Produkten anhand von Fotos in Kategorien wie Kleidungstypen oder Möbel klassifizieren kann. Dieses Projekt ermöglicht es Ihnen, sich mit Computer Vision zu befassen und zu erfahren, wie Modelle des maschinellen Lernens visuelle Daten interpretieren und kategorisieren können. Ein solches Projekt kann besonders nützlich für E-Commerce-Plattformen sein, die die Kategorisierung ihrer Produktlisten automatisieren möchten.
Jedes dieser Projekte bietet nicht nur eine besondere Herausforderung, sondern führt Sie auch in verschiedene Datentypen und Algorithmen für maschinelles Lernen ein, erweitert Ihre Erfahrungen und demonstriert die Vielseitigkeit von No-Code-Plattformen für maschinelles Lernen.
Zusammenfassung
Trainieren eines maschinellen Lernmodells anhand des Iris-Datensatzes mit Julius führt Sie in die wesentlichen Schritte des maschinellen Lernens ein: Daten importieren, für das Training vorbereiten, ein Modell auswählen und konfigurieren sowie die Leistung bewerten. Durch diese praktische Erfahrung erhalten Sie Einblicke in die praktischen Aspekte des maschinellen Lernens und ebnen so den Weg für die Bewältigung komplexerer Projekte.
Dieser Leitfaden vereinfacht den Prozess in überschaubare Schritte und stellt sicher, dass auch Neulinge im Bereich maschinelles Lernen ein Modell mit Julius erfolgreich trainieren können. Wenn Sie mit diesen Schritten vertrauter werden, werden Sie feststellen, dass Julius ein unschätzbar wertvolles Werkzeug für Ihre maschinellen Lernbemühungen ist und in der Lage ist, immer anspruchsvollere Aufgaben problemlos zu bewältigen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/step-by-step-guide-to-training-ml-model-with-no-code/
- :hast
- :Ist
- :nicht
- 150
- 5
- a
- Fähig
- Über uns
- akademisch
- Zugang
- Genauigkeit
- einstellen
- advanced
- AI
- Algorithmus
- Algorithmen
- gleich
- Alle
- erlaubt
- ebenfalls
- Alternative
- an
- Analyse
- analysieren
- und
- jedem
- jemand
- Jetzt bewerben
- Ansatz
- angemessen
- SIND
- AS
- Aspekte
- beurteilen
- Bewertung
- automatisieren
- Automatisches Erfassen:
- Im Prinzip so, wie Sie es von Google Maps kennen.
- basierend
- BE
- Anfänger
- Beyond
- Marken
- erweitern
- bauen
- Geschäft
- aber
- by
- CAN
- Fähigkeiten
- fähig
- Häuser
- Kategorien
- kategorisieren
- challenges
- Ändern
- Auswahl
- klassisch
- Einstufung
- klassifizieren
- Reinigung
- Bekleidung
- Code
- Programmierung
- komfortabel
- gemeinsam
- kompatibel
- Abschluss
- Komplex
- rechnerisch
- Computer
- Computer Vision
- Konzepte
- konfigurieren
- besteht
- mit
- Inhalt
- beitragen
- korrekt
- könnte
- erstellen
- Original
- Kunde
- technische Daten
- Datenanalyse
- Datensätze
- Entscheidung
- tiefer
- Standard
- vertiefen
- tauchen
- demokratisiert
- zeigt
- demonstrieren
- einsetzen
- Erkennung
- anders
- Größe
- Regie bei
- deutlich
- tauchen
- zwei
- e
- e-commerce
- E-Commerce-Plattformen
- jeder
- erleichtern
- Wirksamkeit
- bemüht sich
- gewährleisten
- Gewährleistung
- Enthusiasten
- vollständig
- essential
- Äther (ETH)
- Auswerten
- Auswertung
- Sogar
- jedermann
- Excel
- unterhaltsame Programmpunkte
- spannendes Projekt
- Führt aus
- ERFAHRUNGEN
- Expertise
- ERKUNDEN
- Extrakt
- f1
- erleichtert
- Merkmal
- Eigenschaften
- Fütterung
- Feld
- Reichen Sie das
- Revolution
- Finden Sie
- Aussichten für
- Prognose
- vier
- für
- Zukunft
- Gewinnen
- Spur
- erzeugt
- bekommen
- Unterstützung
- gut
- groß
- Wachsen Sie über sich hinaus
- Guide
- führen
- Handling
- praktische
- Haben
- Hilfe
- hier
- High
- historisch
- Ultraschall
- Hilfe
- aber
- HTTPS
- Ideen
- identifiziert
- Identifizierung
- if
- Image
- Bilderkennung
- Bilder
- importieren
- Bedeutung
- Einfuhr
- Verbesserung
- in
- Dazu gehören
- inkonsistent
- zunehmend
- informiert
- Anfangs-
- Einblicke
- in
- Stellt vor
- unschätzbar
- beteiligt
- beinhaltet
- Iris
- IT
- SEINE
- Julius
- nur
- Aufbewahrung
- Landschaft
- Sprache
- LERNEN
- gelernt
- lernen
- Länge
- Hebelwirkung
- Gefällt mir
- Line
- Liste
- suchen
- Maschine
- Maschinelles Lernen
- handhabbar
- Managed
- Markt
- max-width
- Medien
- Metrik
- Microsoft
- könnte
- minimal
- Kommt demnächst...
- ML
- Modell
- für
- mehr
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- navigieren
- notwendig,
- Negativ
- Nachbarschaft
- Neutral
- Neu
- weiter
- Nlp
- nicht
- Anzahl
- of
- bieten
- bieten
- Angebote
- on
- EINEM
- einzige
- Entwicklungsmöglichkeiten
- or
- Parameter
- Teil
- besonders
- Weg
- Pflasterung
- perfekt
- Leistung
- Fotografien
- Pflanzen
- Plattform
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Teil
- positiv
- BLOG-POSTS
- Werkzeuge
- größte treibende
- Praktisch
- Präzision
- vorhersagen
- Prognose
- Vorbereitung
- Geschenke
- Preis
- Preise
- Prozessdefinierung
- Verarbeitung
- Herstellung
- Produkt
- Produkte
- Profis
- Fortschritt
- Projekt
- Projekte
- bietet
- Bereitstellung
- Python
- Verhältnis
- Lesen Sie mehr
- Anerkennung
- erkennen
- Regression
- verhältnismäßig
- relevant
- falls angefordert
- erfordert
- diejenigen
- Die Ergebnisse
- Einzelhandel
- Bewertungen
- Scan
- Ergebnis
- scheinen
- ausgewählt
- Auswahl
- Auswahl
- Gefühl
- Gefühle
- Sets
- Einstellung
- Blätter
- präsentiert
- Einfacher
- Einfachheit
- Vereinfacht
- vereinfachen
- einfach
- da
- Single
- Fähigkeiten
- Social Media
- Social Media
- Social Media Beiträge
- Lösung
- Lösungen
- anspruchsvoll
- gespalten
- Anfang
- begonnen
- Statistiken
- Schritt
- Shritte
- -bestands-
- einfach
- Struktur
- Erfolgreich
- so
- vorschlagen
- ZUSAMMENFASSUNG
- angehen
- anpacken
- und Aufgaben
- getestet
- Testen
- Text
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Landschaft
- die Welt
- ihr
- Sie
- Dort.
- Diese
- fehlen uns die Worte.
- diejenigen
- nach drei
- Durch
- während
- Tip
- zu
- Werkzeug
- Werkzeuge
- gegenüber
- Training
- trainiert
- Ausbildung
- Bäume
- Trends
- versuchen
- tippe
- Typen
- typisch
- unvoreingenommen
- verstehen
- Verständnis
- entsperrt
- Updates
- -
- nützlich
- benutzerfreundlich
- Verwendung von
- gewöhnlich
- wertvoll
- Werte
- verschiedene
- riesig
- Vielseitigkeit
- Seh-
- visuell
- wurde
- Weg..
- GUT
- bekannt
- Was
- ob
- werden wir
- mit
- ohne
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- Sorgen
- schreiben
- Schreiben
- U
- Ihr
- Zephyrnet