Structured Query Language (SQL) ist eine komplexe Sprache, die ein Verständnis von Datenbanken und Metadaten erfordert. Heute, generative KI kann Menschen ohne SQL-Kenntnisse ermöglichen. Diese generative KI-Aufgabe heißt Text-to-SQL, die SQL-Anfragen aus der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) generiert und Texte in semantisch korrektes SQL umwandelt. Die Lösung in diesem Beitrag zielt darauf ab, Unternehmensanalysevorgänge auf die nächste Ebene zu bringen, indem der Weg zu Ihren Daten mithilfe natürlicher Sprache verkürzt wird.
Mit dem Aufkommen großer Sprachmodelle (LLMs) hat die NLP-basierte SQL-Generierung einen erheblichen Wandel erfahren. LLMs weisen eine außergewöhnliche Leistung auf und sind nun in der Lage, genaue SQL-Abfragen aus Beschreibungen in natürlicher Sprache zu generieren. Es bleiben jedoch weiterhin Herausforderungen bestehen. Erstens ist die menschliche Sprache von Natur aus mehrdeutig und kontextabhängig, während SQL präzise, mathematisch und strukturiert ist. Diese Lücke kann zu einer ungenauen Konvertierung der Benutzeranforderungen in die generierte SQL führen. Zweitens müssen Sie möglicherweise Text-zu-SQL-Funktionen für jede Datenbank erstellen, da Daten häufig nicht in einem einzigen Ziel gespeichert werden. Möglicherweise müssen Sie die Funktion für jede Datenbank neu erstellen, um Benutzern die NLP-basierte SQL-Generierung zu ermöglichen. Drittens steigt trotz der zunehmenden Verbreitung zentralisierter Analyselösungen wie Data Lakes und Warehouses die Komplexität mit unterschiedlichen Tabellennamen und anderen Metadaten, die zum Erstellen des SQL für die gewünschten Quellen erforderlich sind. Daher bleibt auch die Erhebung umfassender und qualitativ hochwertiger Metadaten eine Herausforderung. Weitere Informationen zu Best Practices und Entwurfsmustern für Text-to-SQL finden Sie unter Mehrwert aus Unternehmensdaten generieren: Best Practices für Text2SQL und generative KI.
Unsere Lösung zielt darauf ab, diese Herausforderungen zu bewältigen Amazonas Grundgestein und AWS Analytics Services. Wir gebrauchen Anthropischer Claude v2.1 auf Amazon Bedrock als unser LLM. Um den Herausforderungen zu begegnen, integriert unsere Lösung zunächst die Metadaten der Datenquellen innerhalb der AWS Glue-Datenkatalog um die Genauigkeit der generierten SQL-Abfrage zu erhöhen. Der Workflow umfasst auch eine abschließende Bewertungs- und Korrekturschleife für den Fall, dass SQL-Probleme festgestellt werden Amazonas Athena, die nachgelagert als SQL-Engine verwendet wird. Athena ermöglicht uns auch die Verwendung einer Vielzahl von Unterstützte Endpunkte und Konnektoren um eine große Menge an Datenquellen abzudecken.
Nachdem wir die Schritte zum Erstellen der Lösung durchgegangen sind, präsentieren wir die Ergebnisse einiger Testszenarien mit unterschiedlichen SQL-Komplexitätsstufen. Abschließend besprechen wir, wie einfach es ist, verschiedene Datenquellen in Ihre SQL-Abfragen einzubinden.
Lösungsüberblick
Unsere Architektur besteht aus drei entscheidenden Komponenten: Retrieval Augmented Generation (RAG) mit Datenbankmetadaten, einer mehrstufigen Selbstkorrekturschleife und Athena als unsere SQL-Engine.
Wir verwenden die RAG-Methode, um die Tabellenbeschreibungen und Schemabeschreibungen (Spalten) aus dem AWS Glue-Metastore abzurufen, um sicherzustellen, dass die Anfrage mit der richtigen Tabelle und den richtigen Datensätzen verknüpft ist. In unserer Lösung haben wir die einzelnen Schritte zum Ausführen eines RAG-Frameworks mit dem AWS Glue Data Catalog zu Demonstrationszwecken erstellt. Sie können jedoch auch verwenden Wissensbasen in Amazon Bedrock, um schnell RAG-Lösungen zu erstellen.
Die mehrstufige Komponente ermöglicht es dem LLM, die generierte SQL-Abfrage auf Genauigkeit zu korrigieren. Hier wird das generierte SQL bei Syntaxfehlern gesendet. Wir verwenden Athena-Fehlermeldungen, um unsere Eingabeaufforderung für das LLM zu bereichern und genauere und effektivere Korrekturen im generierten SQL zu ermöglichen.
Sie können die Fehlermeldungen, die gelegentlich von Athena kommen, als Feedback betrachten. Die Kostenauswirkungen eines Fehlerkorrekturschritts sind im Vergleich zum gelieferten Wert vernachlässigbar. Sie können diese Korrekturschritte sogar als Beispiele für überwachtes, verstärktes Lernen einbinden, um Ihre LLMs zu verfeinern. Der Einfachheit halber haben wir diesen Ablauf in unserem Beitrag jedoch nicht behandelt.
Beachten Sie, dass bei generativen KI-Lösungen immer das Risiko von Ungenauigkeiten besteht. Auch wenn Athena-Fehlermeldungen dieses Risiko sehr effektiv mindern, können Sie weitere Steuerelemente und Ansichten hinzufügen, z. B. menschliches Feedback oder Beispielabfragen zur Feinabstimmung, um diese Risiken weiter zu minimieren.
Athena ermöglicht uns nicht nur die Korrektur der SQL-Abfragen, sondern vereinfacht auch das Gesamtproblem für uns, da es als Hub dient, an dem die Spokes mehrere Datenquellen sind. Zugriffsverwaltung, SQL-Syntax und mehr werden alle über Athena abgewickelt.
Das folgende Diagramm zeigt die Lösungsarchitektur.
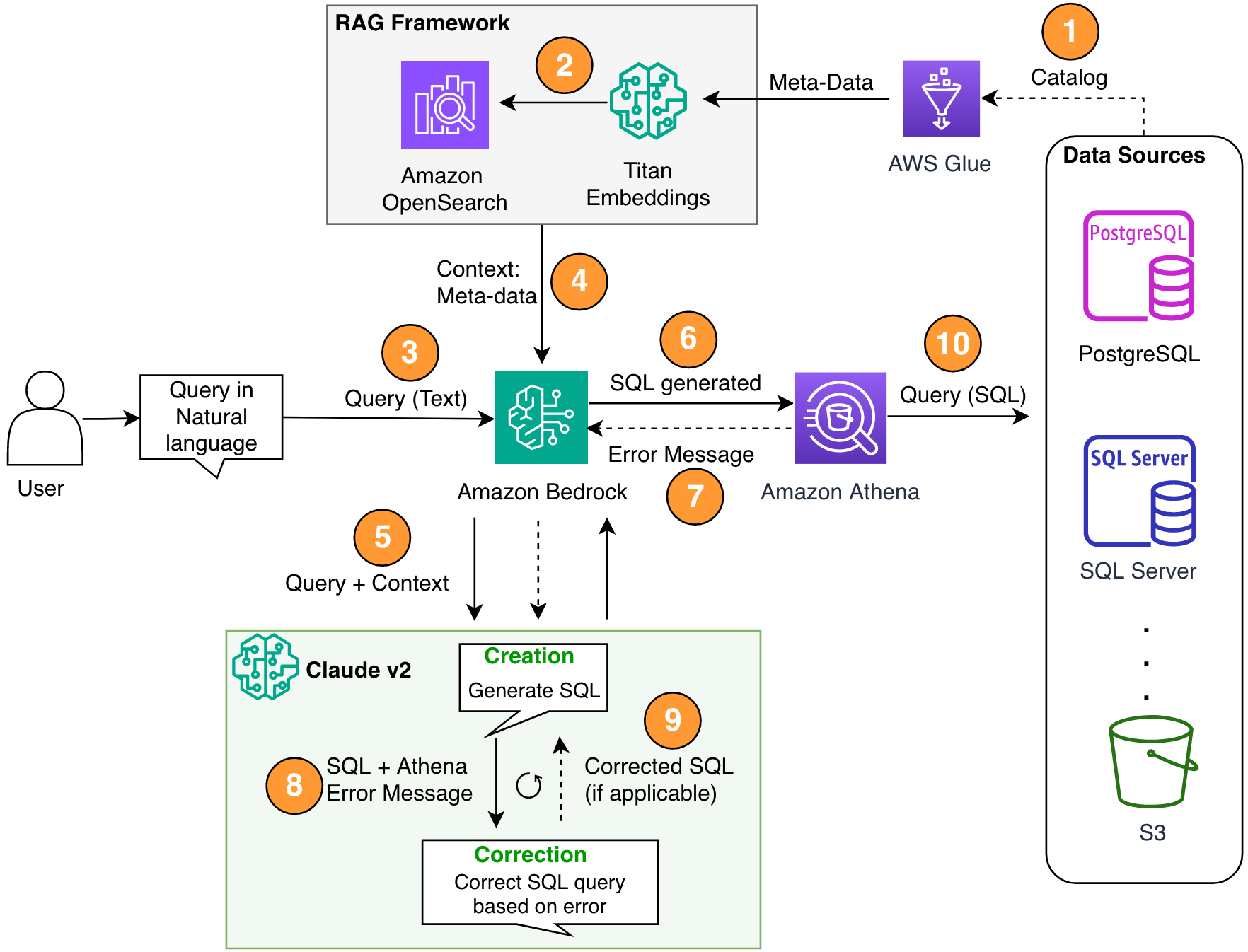
Abbildung 1. Die Lösungsarchitektur und der Prozessablauf.
Der Prozessablauf umfasst die folgenden Schritte:
- Erstellen Sie den AWS Glue-Datenkatalog Verwendung eines AWS Glue-Crawlers (oder eine andere Methode).
- Verwendung der Titan-Text-Embeddings-Modell auf Amazon Bedrock, konvertieren Sie die Metadaten in Einbettungen und speichern Sie sie in einer Amazon OpenSearch ohne Server Vektorspeicher, das als unsere Wissensbasis in unserem RAG-Framework dient.
In dieser Phase ist der Prozess bereit, die Anfrage in natürlicher Sprache zu empfangen. Die Schritte 7–9 stellen ggf. eine Korrekturschleife dar.
- Der Benutzer gibt seine Anfrage in natürlicher Sprache ein. Sie können jede Webanwendung verwenden, um die Chat-Benutzeroberfläche bereitzustellen. Daher haben wir in unserem Beitrag nicht auf die Details der Benutzeroberfläche eingegangen.
- Die Lösung wendet ein RAG-Framework an Ähnlichkeitssuche, wodurch der zusätzliche Kontext aus den Metadaten aus der Vektordatenbank hinzugefügt wird. Diese Tabelle wird verwendet, um die richtige Tabelle, Datenbank und Attribute zu finden.
- Die Abfrage wird mit dem Kontext zusammengeführt und an gesendet Anthropischer Claude v2.1 auf Amazon Bedrock.
- Das Modell ruft die generierte SQL-Abfrage ab und stellt eine Verbindung zu Athena her, um die Syntax zu validieren.
- Wenn Athena eine Fehlermeldung bereitstellt, die besagt, dass die Syntax falsch ist, verwendet das Modell den Fehlertext aus Athenas Antwort.
- Die neue Eingabeaufforderung fügt Athenas Antwort hinzu.
- Das Modell erstellt die korrigierte SQL und setzt den Prozess fort. Diese Iteration kann mehrmals durchgeführt werden.
- Schließlich führen wir SQL mit Athena aus und generieren eine Ausgabe. Hier wird die Ausgabe dem Benutzer präsentiert. Der Einfachheit halber haben wir diesen Schritt nicht dargestellt.
Voraussetzungen:
Für diesen Posten sollten Sie die folgenden Voraussetzungen erfüllen:
- Einen haben AWS-Konto.
- Installieren AWS-Befehlszeilenschnittstelle (AWS-CLI).
- Richten Sie die SDK für Python (Boto3).
- Erstellen Sie den AWS Glue-Datenkatalog Verwendung eines AWS Glue-Crawlers (oder eine andere Methode).
- Verwendung der Titan-Text-Embeddings-Modell auf Amazon Bedrock, konvertieren Sie die Metadaten in Einbettungen und speichern Sie sie in einem OpenSearch Serverless Vektorspeicher.
Implementieren Sie die Lösung
Sie können Folgendes verwenden Jupyter Notizbuch, das alle in diesem Abschnitt bereitgestellten Codeausschnitte enthält, um die Lösung zu erstellen. Wir empfehlen die Verwendung Amazon SageMaker-Studio um dieses Notebook mit einer ml.t3.medium-Instanz mit dem Python 3 (Data Science)-Kernel zu öffnen. Anweisungen finden Sie unter Trainieren Sie ein Modell für maschinelles Lernen. Führen Sie die folgenden Schritte aus, um die Lösung einzurichten:
- Erstellen Sie die Wissensdatenbank im OpenSearch Service für das RAG-Framework:
- Erstellen Sie die Eingabeaufforderung (
final_question) durch Kombinieren der Benutzereingaben in natürlicher Sprache (user_query), die relevanten Metadaten aus dem Vektorspeicher (vector_search_match) und unsere Anweisungen (details): - Rufen Sie Amazon Bedrock für das LLM (Claude v2) auf und fordern Sie es auf, die SQL-Abfrage zu generieren. Im folgenden Code werden mehrere Versuche unternommen, um den Selbstkorrekturschritt zu veranschaulichen:x
- Wenn Probleme mit der generierten SQL-Abfrage auftreten (
{sqlgenerated}) aus der Athena-Antwort ({syntaxcheckmsg}), die neue Eingabeaufforderung (prompt) wird basierend auf der Antwort generiert und das Modell versucht erneut, das neue SQL zu generieren: - Nachdem die SQL generiert wurde, wird der Athena-Client aufgerufen, um die Ausgabe auszuführen und zu generieren:
Testen Sie die Lösung
In diesem Abschnitt führen wir unsere Lösung mit verschiedenen Beispielszenarien aus, um unterschiedliche Komplexitätsstufen von SQL-Abfragen zu testen.
Um unser Text-to-SQL zu testen, verwenden wir zwei Datensätze verfügbar in der IMDB. Teilmengen der IMDb-Daten stehen für den persönlichen und nicht kommerziellen Gebrauch zur Verfügung. Sie können die Datensätze herunterladen und speichern Amazon Simple Storage-Service (Amazon S3). Sie können das folgende Spark SQL-Snippet verwenden, um Tabellen in AWS Glue zu erstellen. Für dieses Beispiel verwenden wir title_ratings und title:
Speichern Sie Daten in Amazon S3 und Metadaten in AWS Glue
In diesem Szenario wird unser Datensatz in einem S3-Bucket gespeichert. Athena verfügt über einen S3-Connector, der es Ihnen ermöglicht, Amazon S3 als abfragbare Datenquelle zu verwenden.
Für unsere erste Abfrage stellen wir die Eingabe „Ich bin neu in diesem Bereich“ bereit. Können Sie mir helfen, alle Tabellen und Spalten im IMDB-Schema anzuzeigen?“
Das Folgende ist die generierte Abfrage:
Der folgende Screenshot und Code zeigen unsere Ausgabe.
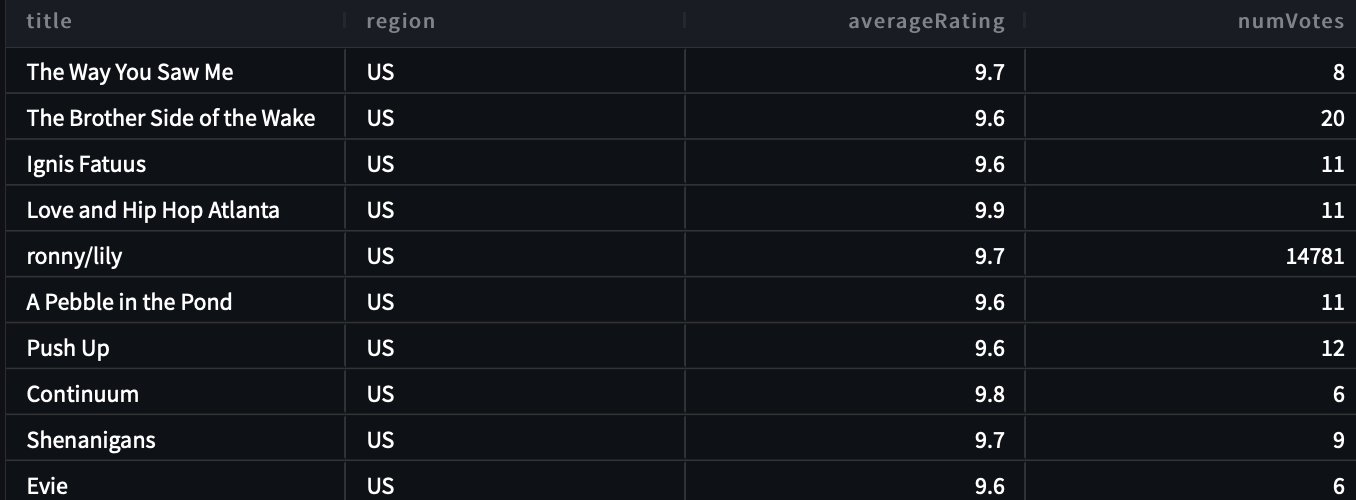
Bei unserer zweiten Abfrage fragen wir: „Zeigen Sie mir alle Titel und Details in der US-Region, deren Bewertung mehr als 9.5 beträgt.“
Das Folgende ist unsere generierte Abfrage:
Die Antwort lautet wie folgt.
Für unsere dritte Abfrage geben wir „Tolle Resonanz!“ ein. Zeigen Sie mir jetzt alle Originaltitel mit Bewertungen über 7.5 und nicht in der US-Region.“
Die folgende Abfrage wird generiert:
Wir erhalten folgende Ergebnisse.

Generieren Sie selbstkorrigiertes SQL
Dieses Szenario simuliert eine SQL-Abfrage mit Syntaxproblemen. Hier wird die generierte SQL basierend auf der Antwort von Athena selbstkorrigiert. In der folgenden Antwort gab Athene eine COLUMN_NOT_FOUND Fehler und erwähnte das table_description kann nicht gelöst werden:
Verwendung der Lösung mit anderen Datenquellen
Wenn Sie die Lösung mit anderen Datenquellen nutzen möchten, übernimmt Athena die Arbeit für Sie. Dazu verwendet Athena Datenquellen-Konnektoren das kann mit verwendet werden föderierte Abfragen. Sie können einen Connector als Erweiterung der Athena-Abfrage-Engine betrachten. Es gibt vorgefertigte Athena-Datenquellenkonnektoren für Datenquellen wie Amazon CloudWatch-Protokolle, Amazon DynamoDB, Amazon DocumentDB (mit MongoDB-Kompatibilität) und Relationaler Amazon-Datenbankdienst (Amazon RDS) und JDBC-kompatible relationale Datenquellen wie MySQL und PostgreSQL unter der Apache 2.0-Lizenz. Nachdem Sie eine Verbindung zu einer beliebigen Datenquelle eingerichtet haben, können Sie die obige Codebasis verwenden, um die Lösung zu erweitern. Weitere Informationen finden Sie unter Fragen Sie jede Datenquelle mit der neuen Verbundabfrage von Amazon Athena ab.
Aufräumen
Um die Ressourcen zu bereinigen, können Sie damit beginnen Aufräumen Ihres S3-Buckets wo sich die Daten befinden. Sofern Ihre Anwendung nicht auf Amazon Bedrock zurückgreift, fallen keine Kosten an. Aus Gründen der Best Practices für das Infrastrukturmanagement empfehlen wir, die in dieser Demonstration erstellten Ressourcen zu löschen.
Zusammenfassung
In diesem Beitrag haben wir eine Lösung vorgestellt, die es Ihnen ermöglicht, mithilfe von NLP komplexe SQL-Abfragen mit einer Vielzahl von Ressourcen zu generieren, die von Athena aktiviert werden. Darüber hinaus haben wir die Genauigkeit der generierten SQL-Abfragen durch eine mehrstufige Auswertungsschleife basierend auf Fehlermeldungen nachgelagerter Prozesse erhöht. Darüber hinaus haben wir die Metadaten im AWS Glue Data Catalog verwendet, um die in der Abfrage über das RAG-Framework abgefragten Tabellennamen zu berücksichtigen. Anschließend haben wir die Lösung in verschiedenen realistischen Szenarien mit unterschiedlichen Abfragekomplexitätsstufen getestet. Abschließend haben wir besprochen, wie diese Lösung auf verschiedene von Athena unterstützte Datenquellen angewendet werden kann.
Amazon Bedrock steht im Mittelpunkt dieser Lösung. Amazon Bedrock kann Ihnen beim Erstellen vieler generativer KI-Anwendungen helfen. Um mit Amazon Bedrock zu beginnen, empfehlen wir, den folgenden Schnellstart zu befolgen GitHub Repo und machen Sie sich mit der Entwicklung generativer KI-Anwendungen vertraut. Sie können es auch versuchen Wissensbasen in Amazon Bedrock, um solche RAG-Lösungen schnell zu erstellen.
Über die Autoren
 Sanjeeb Panda ist Daten- und ML-Ingenieur bei Amazon. Mit seinem Hintergrund in den Bereichen KI/ML, Datenwissenschaft und Big Data entwirft und entwickelt Sanjeeb innovative Daten- und ML-Lösungen, die komplexe technische Herausforderungen lösen und strategische Ziele für globale 3P-Verkäufer erreichen, die ihre Geschäfte auf Amazon verwalten. Neben seiner Arbeit als Daten- und ML-Ingenieur bei Amazon ist Sanjeeb Panda ein begeisterter Feinschmecker und Musikliebhaber.
Sanjeeb Panda ist Daten- und ML-Ingenieur bei Amazon. Mit seinem Hintergrund in den Bereichen KI/ML, Datenwissenschaft und Big Data entwirft und entwickelt Sanjeeb innovative Daten- und ML-Lösungen, die komplexe technische Herausforderungen lösen und strategische Ziele für globale 3P-Verkäufer erreichen, die ihre Geschäfte auf Amazon verwalten. Neben seiner Arbeit als Daten- und ML-Ingenieur bei Amazon ist Sanjeeb Panda ein begeisterter Feinschmecker und Musikliebhaber.
 Burak Gozluklu ist ein leitender KI/ML-Spezialist für Lösungsarchitekten mit Sitz in Boston, MA. Er unterstützt strategische Kunden bei der Einführung von AWS-Technologien und insbesondere generativen KI-Lösungen, um ihre Geschäftsziele zu erreichen. Burak hat einen Doktortitel in Luft- und Raumfahrttechnik von der METU, einen MS in Systemtechnik und einen Postdoc in Systemdynamik vom MIT in Cambridge, MA. Burak ist immer noch ein Forschungspartner am MIT. Burak hat eine Leidenschaft für Yoga und Meditation.
Burak Gozluklu ist ein leitender KI/ML-Spezialist für Lösungsarchitekten mit Sitz in Boston, MA. Er unterstützt strategische Kunden bei der Einführung von AWS-Technologien und insbesondere generativen KI-Lösungen, um ihre Geschäftsziele zu erreichen. Burak hat einen Doktortitel in Luft- und Raumfahrttechnik von der METU, einen MS in Systemtechnik und einen Postdoc in Systemdynamik vom MIT in Cambridge, MA. Burak ist immer noch ein Forschungspartner am MIT. Burak hat eine Leidenschaft für Yoga und Meditation.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/build-a-robust-text-to-sql-solution-generating-complex-queries-self-correcting-and-querying-diverse-data-sources/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 02
- 1
- 10
- 100
- 11
- 12
- 13
- 14
- 16
- 2%
- 20
- 2024
- 21
- 22
- 23
- 29
- 30
- 32
- 39
- 4
- 5
- 50
- 500
- 521
- 6
- 7
- 8
- 9
- a
- LiveBuzz
- oben
- Zugang
- Genauigkeit
- genau
- Erreichen
- hinzufügen
- zusätzlich
- Adresse
- Fügt
- adoptieren
- Adoption
- Luft- und Raumfahrt
- Raumfahrttechnik
- Affiliate
- Nach der
- aufs Neue
- AI
- AI / ML
- Ziel
- Richtet sich aus
- Alle
- erlaubt
- ebenfalls
- Alternative
- immer
- am
- Amazon
- Amazon RDS
- Amazon Web Services
- an
- Analytik
- und
- beantworten
- Anthropisch
- jedem
- Apache
- anwendbar
- Anwendung
- Anwendungen
- gilt
- Bewerben
- architektonisch
- Architektur
- SIND
- AS
- fragen
- gefragt
- At
- Atlanta
- Versuch
- Versuche
- Attribute
- Augmented
- zugelassen
- verfügbar
- AWS
- AWS-Kleber
- Hintergrund
- Base
- basierend
- BE
- weil
- unten
- BESTE
- Best Practices
- Big
- Big Data
- Blockieren
- Boston
- bringen
- Bruder
- bauen
- Building
- erbaut
- Geschäft
- Unternehmen
- aber
- by
- namens
- Cambridge
- CAN
- kann keine
- capability
- fähig
- österreichische Unternehmen
- Häuser
- Katalog
- Center
- zentralisierte
- challenges
- Herausforderungen
- Chat
- geprüft
- Überprüfung
- claude
- reinigen
- cli
- Auftraggeber
- Code
- Codebasis
- Das Sammeln
- Kolonne
- Spalten
- Vereinigung
- kommt
- Kommen
- verglichen
- Vergleich
- Kompatibilität
- abschließen
- Komplex
- Komplexität
- entspricht
- Komponente
- Komponenten
- umfassend
- Verbindung
- Connects
- Geht davon
- Kontext
- weiter
- Steuerung
- Umwandlung (Conversion)
- verkaufen
- Konvertiten
- und beseitigen Muskelschwäche
- korrigiert
- Korrekturen
- Kosten
- zählen
- Abdeckung
- erstellen
- erstellt
- schafft
- kritischem
- Kunden
- technische Daten
- Datenwissenschaft
- Datenbase
- Datenbanken
- Datensätze
- Datum
- datetime
- geliefert
- demonstrieren
- Design
- Designmuster
- erwünscht
- Trotz
- Details
- entwickeln
- Diagramm
- DID
- anders
- diskutieren
- diskutiert
- verschieden
- do
- docs
- Unterlagen
- herunterladen
- im
- Dynamik
- Effektiv
- sonst
- Entstehung
- ermöglichen
- freigegeben
- Endpunkte
- Motor
- Ingenieur
- Entwicklung
- bereichern
- gewährleisten
- Enter
- Unternehmen
- Tritt ein
- Enthusiast
- Fehler
- Fehler
- Äther (ETH)
- Auswertung
- Sogar
- Jedes
- Beispiel
- Beispiele
- außergewöhnlich
- Ausführung
- existieren
- vorhandenen
- Erklären
- erweitern
- Erweiterung
- extra
- Gescheitert
- falsch
- Eigenschaften
- Feedback
- Finale
- Endlich
- Suche nach
- Vorname
- Fluss
- folgen
- Folgende
- folgt
- Aussichten für
- Unser Ansatz
- für
- weiter
- Lücke
- gab
- erzeugen
- erzeugt
- erzeugt
- Erzeugung
- Generation
- generativ
- Generative KI
- bekommen
- bekommt
- Global
- Ziele
- habe
- behandelt
- Griffe
- Haben
- mit
- he
- Hilfe
- hilft
- hier
- hochwertige
- hoch
- Hip-Hop
- seine
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- Nabe
- human
- i
- identifiziert
- if
- veranschaulichen
- zeigt
- Auswirkungen
- wichtig
- in
- ungenau
- das
- Dazu gehören
- integrieren
- beinhaltet
- unrichtig
- Erhöhung
- hat
- Index
- Krankengymnastik
- Info
- Information
- Infrastruktur
- inhärent
- von Natur aus
- Anfangs-
- innere
- innovativ
- Varianten des Eingangssignals:
- Instanz
- Anleitung
- ganze Zahl
- in
- aufgerufen
- ruft auf
- Problem
- Probleme
- IT
- Iteration
- Job
- join
- jpg
- Wissen
- Seen
- Sprache
- grosse
- größer
- LERNEN
- lernen
- Niveau
- Cholesterinspiegel
- Lizenz
- Gefällt mir
- LIMIT
- Line
- llm
- located
- ich liebe
- Maschine
- Maschinelles Lernen
- um
- MACHT
- Management
- flächendeckende Gesundheitsprogramme
- viele
- mathematisch
- Kann..
- me
- Meditation
- mittlere
- erwähnt
- Erwähnungen
- Nachricht
- Nachrichten
- Metadaten
- Methode
- könnte
- minimieren
- MIT
- Mildern
- ML
- Modell
- für
- MongoDB
- mehr
- MS
- mehrere
- Vielzahl
- Musik
- MySQL
- Name
- Namen
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- natürlich
- Need
- Bedürfnisse
- Neu
- weiter
- Nlp
- nichtkommerziell
- Notizbuch
- jetzt an
- Anzahl
- gelegentlich
- of
- vorgenommen,
- on
- einzige
- XNUMXh geöffnet
- Einkauf & Prozesse
- or
- Auftrag
- Bestellung
- Original
- Andere
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- aussen
- Gesamt-
- Bestanden
- leidenschaftlich
- Weg
- Muster
- Personen
- Leistung
- durchgeführt
- persönliche
- phd
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- Post
- Postgresql
- Praktiken
- präzise
- Voraussetzungen
- Gegenwart
- vorgeführt
- Principal
- Aufgabenstellung:
- Prozessdefinierung
- anpassen
- Verarbeitung
- Eingabeaufforderungen
- die
- vorausgesetzt
- bietet
- Zwecke
- Python
- Abfragen
- query
- Frage
- Direkt
- schnell
- Zitate
- Lappen
- Wertung
- Bewertungen
- Lesen Sie mehr
- bereit
- realistisch
- erhalten
- Received
- empfehlen
- siehe
- Region
- verstärkt
- bezogene
- relevant
- bleiben
- bleibt bestehen
- vertreten
- Anforderung
- angefordert
- falls angefordert
- Voraussetzungen:
- erfordert
- Forschungsprojekte
- wohnt
- lösen
- entschlossen
- Downloads
- Umwelt und Kunden
- Antwort
- Folge
- Die Ergebnisse
- Abruf
- Rückkehr
- Recht
- Steigt
- Risiko
- Risiken
- robust
- REIHE
- Führen Sie
- sagemaker
- Sake
- gleich
- sah
- Szenario
- Szenarien
- Wissenschaft
- Suche
- Zweite
- Abschnitt
- sehen
- wählen
- SELF
- Sellers
- geschickt
- Serverlos
- dient
- Lösungen
- kompensieren
- sollte
- erklären
- zeigt
- gezeigt
- Seite
- signifikant
- Einfacher
- Einfachheit
- Vereinfacht
- Simuliert
- Single
- Schnipsel
- Lösung
- Lösungen
- LÖSEN
- einige
- Quelle
- Quellen
- Spark
- Spezialist
- speziell
- SQL
- Stufe
- Anfang
- begonnen
- Bundesstaat
- Erklärung
- Status
- Schritt
- Shritte
- Immer noch
- Lagerung
- speichern
- gelagert
- einfach
- Strategisch
- Schnur
- strukturierte
- so
- Aufsicht
- Unterstützte
- sicher
- Syntax
- System
- Systeme und Techniken
- T
- Tabelle
- Nehmen
- Target
- Aufgabe
- Technische
- Technologies
- Test
- getestet
- Text
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- der Hub
- ihr
- Sie
- dann
- Dort.
- deswegen
- Diese
- Dritte
- fehlen uns die Worte.
- diejenigen
- nach drei
- Durch
- mal
- Titel
- Titel
- zu
- heute
- Transformation
- versucht
- versuchen
- XNUMX
- tippe
- Typen
- ui
- für
- unterzogen
- Verständnis
- es sei denn
- Aktualisierung
- aktualisiert
- us
- -
- benutzt
- Mitglied
- Nutzer
- verwendet
- Verwendung von
- BESTÄTIGEN
- Wert
- Vielfalt
- verschiedene
- Variieren
- Vektor
- Ansichten
- Wake
- Spaziergang
- Weg..
- we
- Netz
- Internetanwendung
- Web-Services
- während
- welche
- während
- deren
- werden wir
- mit
- .
- ohne
- Arbeiten
- Arbeitsablauf.
- schreiben
- Schreiben
- X
- Yoga
- U
- Ihr
- sich selbst
- Zephyrnet