Dieser Beitrag wurde gemeinsam mit Mahima Agarwal, Machine Learning Engineer, und Deepak Mettem, Senior Engineering Manager, bei VMware Carbon Black verfasst
VMware Carbon Black ist eine renommierte Sicherheitslösung, die Schutz vor dem gesamten Spektrum moderner Cyberangriffe bietet. Mit Terabytes an Daten, die vom Produkt generiert werden, konzentriert sich das Sicherheitsanalyseteam auf die Entwicklung von Lösungen für maschinelles Lernen (ML), um kritische Angriffe aufzudecken und aufkommende Bedrohungen durch Rauschen aufzuzeigen.
Für das VMware Carbon Black-Team ist es von entscheidender Bedeutung, eine benutzerdefinierte End-to-End-MLOps-Pipeline zu entwerfen und zu erstellen, die Workflows im ML-Lebenszyklus orchestriert und automatisiert und Modelltraining, Evaluierungen und Bereitstellungen ermöglicht.
Es gibt zwei Hauptzwecke für den Aufbau dieser Pipeline: Unterstützung der Data Scientists bei der Modellentwicklung in der Spätphase und Oberflächenmodellvorhersagen im Produkt, indem Modelle in großem Umfang und im Echtzeit-Produktionsverkehr bereitgestellt werden. Daher entschieden sich VMware Carbon Black und AWS für den Aufbau einer benutzerdefinierten MLOps-Pipeline mit Amazon Sage Maker für seine Benutzerfreundlichkeit, Vielseitigkeit und vollständig verwaltete Infrastruktur. Wir orchestrieren unsere ML-Trainings- und Bereitstellungspipelines mit Von Amazon verwaltete Workflows für Apache Airflow (Amazon MWAA), wodurch wir uns mehr auf die programmgesteuerte Erstellung von Workflows und Pipelines konzentrieren können, ohne uns Gedanken über die automatische Skalierung oder die Wartung der Infrastruktur machen zu müssen.
Mit dieser Pipeline ist das, was einst Jupyter-Notebook-gesteuerte ML-Forschung war, jetzt ein automatisierter Prozess, der Modelle mit wenig manuellem Eingriff von Data Scientists für die Produktion bereitstellt. Früher konnte der Prozess des Trainierens, Evaluierens und Bereitstellens eines Modells über einen Tag dauern; Mit dieser Implementierung ist alles nur einen Auslöser entfernt und hat die Gesamtzeit auf wenige Minuten reduziert.
In diesem Beitrag erörtern VMware Carbon Black- und AWS-Architekten, wie wir benutzerdefinierte ML-Workflows erstellt und verwaltet haben Gitlab, Amazon MWAA und SageMaker. Wir besprechen, was wir bisher erreicht haben, weitere Verbesserungen der Pipeline und die auf diesem Weg gelernten Lektionen.
Lösungsüberblick
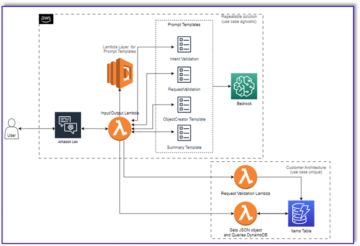
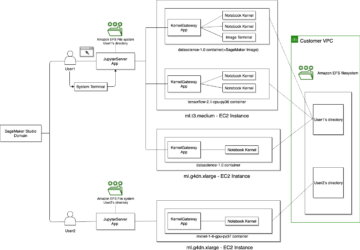
Das folgende Diagramm veranschaulicht die ML-Plattformarchitektur.

Lösungsdesign auf hohem Niveau
Diese ML-Plattform wurde so konzipiert und entwickelt, dass sie von verschiedenen Modellen in verschiedenen Code-Repositories genutzt werden kann. Unser Team verwendet GitLab als Quellcode-Verwaltungstool, um alle Code-Repositories zu verwalten. Alle Änderungen im Quellcode des Modellrepositorys werden kontinuierlich mithilfe von integriert Gitlab-CI, die die nachfolgenden Workflows in der Pipeline aufruft (Modelltraining, Evaluierung und Bereitstellung).
Das folgende Architekturdiagramm veranschaulicht den End-to-End-Workflow und die an unserer MLOps-Pipeline beteiligten Komponenten.

End-to-End-Workflow
Die Trainings-, Evaluierungs- und Bereitstellungspipelines des ML-Modells werden mithilfe von Amazon MWAA orchestriert, das als a bezeichnet wird Gerichteter azyklischer Graph (DAG). Eine DAG ist eine Sammlung von Aufgaben, die mit Abhängigkeiten und Beziehungen organisiert sind, um anzugeben, wie sie ausgeführt werden sollen.
Auf hoher Ebene umfasst die Lösungsarchitektur drei Hauptkomponenten:
- ML-Pipeline-Code-Repository
- Trainings- und Evaluierungspipeline für ML-Modelle
- Bereitstellungspipeline für ML-Modelle
Lassen Sie uns besprechen, wie diese verschiedenen Komponenten verwaltet werden und wie sie miteinander interagieren.
ML-Pipeline-Code-Repository
Nachdem das Modellrepo das MLOps-Repo als nachgelagerte Pipeline integriert hat und ein Data Scientist Code in sein Modellrepo schreibt, führt ein GitLab-Runner die standardmäßige Codevalidierung und -tests durch, die in diesem Repo definiert sind, und löst die MLOps-Pipeline basierend auf den Codeänderungen aus. Wir verwenden die Multi-Projekt-Pipeline von Gitlab, um diesen Trigger über verschiedene Repos hinweg zu aktivieren.
Die MLOps-GitLab-Pipeline führt eine bestimmte Reihe von Phasen aus. Es führt eine grundlegende Codevalidierung mit pylint durch, packt den Trainings- und Inferenzcode des Modells in das Docker-Image und veröffentlicht das Container-Image in Amazon Elastic Container-Registrierung (Amazon ECR). Amazon ECR ist eine vollständig verwaltete Containerregistrierung, die hochleistungsfähiges Hosting bietet, sodass Sie Anwendungs-Images und Artefakte überall zuverlässig bereitstellen können.
Trainings- und Evaluierungspipeline für ML-Modelle
Nachdem das Bild veröffentlicht wurde, löst es das Training und die Bewertung aus Apache-Luftstrom Rohrleitung durch die AWS Lambda Funktion. Lambda ist ein serverloser, ereignisgesteuerter Rechendienst, mit dem Sie Code für praktisch jede Art von Anwendung oder Backend-Dienst ausführen können, ohne Server bereitstellen oder verwalten zu müssen.
Nachdem die Pipeline erfolgreich ausgelöst wurde, führt sie den Trainings- und Evaluierungs-DAG aus, der wiederum das Modelltraining in SageMaker startet. Am Ende dieser Trainingspipeline erhält die identifizierte Benutzergruppe eine Benachrichtigung mit den Trainings- und Modellbewertungsergebnissen per E-Mail Amazon Simple Notification Service (Amazon SNS) und Slack. Amazon SNS ist ein vollständig verwalteter Pub/Sub-Service für A2A- und A2P-Messaging.
Nach sorgfältiger Analyse der Bewertungsergebnisse kann der Datenwissenschaftler oder ML-Ingenieur das neue Modell einsetzen, wenn die Leistung des neu trainierten Modells im Vergleich zur vorherigen Version besser ist. Die Leistung der Modelle wird basierend auf den modellspezifischen Metriken (wie F1-Score, MSE oder Konfusionsmatrix) bewertet.
Bereitstellungspipeline für ML-Modelle
Um die Bereitstellung zu starten, startet der Benutzer den GitLab-Job, der den Bereitstellungs-DAG über dieselbe Lambda-Funktion auslöst. Nachdem die Pipeline erfolgreich ausgeführt wurde, erstellt oder aktualisiert sie den SageMaker-Endpunkt mit dem neuen Modell. Dadurch wird auch eine Benachrichtigung mit den Endpunktdetails per E-Mail mit Amazon SNS und Slack gesendet.
Im Falle eines Ausfalls in einer der Pipelines werden die Benutzer über dieselben Kommunikationskanäle benachrichtigt.
SageMaker bietet Echtzeit-Inferenz, die sich ideal für Inferenz-Workloads mit geringer Latenz und hohen Durchsatzanforderungen eignet. Diese Endpunkte sind vollständig verwaltet, mit Lastenausgleich und automatisch skaliert und können für Hochverfügbarkeit in mehreren Availability Zones bereitgestellt werden. Unsere Pipeline erstellt einen solchen Endpunkt für ein Modell, nachdem es erfolgreich ausgeführt wurde.
In den folgenden Abschnitten gehen wir auf die verschiedenen Komponenten ein und tauchen in die Details ein.
GitLab: Package-Modelle und Trigger-Pipelines
Wir verwenden GitLab als unser Code-Repository und für die Pipeline, um den Modellcode zu verpacken und nachgelagerte Airflow-DAGs auszulösen.
Multi-Projekt-Pipeline
Die GitLab-Pipelinefunktion für mehrere Projekte wird verwendet, wenn die übergeordnete Pipeline (Upstream) ein Modell-Repository und die untergeordnete Pipeline (Downstream) das MLOps-Repository ist. Jedes Repo verwaltet eine .gitlab-ci.yml, und der folgende Codeblock, der in der Upstream-Pipeline aktiviert ist, löst die Downstream-MLOps-Pipeline aus.
Die Upstream-Pipeline sendet den Modellcode an die Downstream-Pipeline, wo die Pack- und Veröffentlichungs-CI-Jobs ausgelöst werden. Code zum Containerisieren des Modellcodes und Veröffentlichen in Amazon ECR wird von der MLOps-Pipeline verwaltet und verwaltet. Es sendet die Variablen wie ACCESS_TOKEN (kann unter erstellt werden Einstellungen , Access), JOB_ID (um auf vorgelagerte Artefakte zuzugreifen) und $CI_PROJECT_ID (die Projekt-ID des Modellrepos) Variablen, sodass die MLOps-Pipeline auf die Modellcodedateien zugreifen kann. Mit dem Job-Artefakte Feature von Gitlab greift das Downstream-Repository mit dem folgenden Befehl auf die Remote-Artefakte zu:
Das Modell-Repository kann nachgelagerte Pipelines für mehrere Modelle aus demselben Repository verwenden, indem es die Stufe erweitert, die es mit der auslöst erweitert Schlüsselwort von GitLab, mit dem Sie dieselbe Konfiguration in verschiedenen Phasen wiederverwenden können.
Nach der Veröffentlichung des Modell-Images in Amazon ECR löst die MLOps-Pipeline die Amazon MWAA-Trainingspipeline mit Lambda aus. Nach der Genehmigung durch den Benutzer löst es auch die Amazon MWAA-Pipeline für die Modellbereitstellung mit derselben Lambda-Funktion aus.
Semantische Versionierung und Weitergabe von Versionen nach unten
Wir haben benutzerdefinierten Code entwickelt, um ECR-Images und SageMaker-Modelle zu versionieren. Die MLOps-Pipeline verwaltet die semantische Versionierungslogik für Bilder und Modelle als Teil der Phase, in der der Modellcode containerisiert wird, und übergibt die Versionen als Artefakte an spätere Phasen.
Umschulung
Da die Umschulung ein entscheidender Aspekt eines ML-Lebenszyklus ist, haben wir Umschulungsfunktionen als Teil unserer Pipeline implementiert. Wir verwenden die List-Models-API von SageMaker, um anhand der Versionsnummer und des Zeitstempels der Modellneuschulung zu ermitteln, ob es sich um eine Neuschulung handelt.
Wir verwalten den Tagesablauf der Umschulungspipeline mit Die Zeitplan-Pipelines von GitLab.
Terraform: Einrichtung der Infrastruktur
Neben einem Amazon MWAA-Cluster, ECR-Repositories, Lambda-Funktionen und SNS-Thema verwendet diese Lösung auch AWS Identity and Access Management and (IAM) Rollen, Benutzer und Richtlinien; Amazon Simple Storage-Service (Amazon S3) Eimer und ein Amazon CloudWatch Log-Weiterleitung.
Um die Einrichtung und Wartung der Infrastruktur für die in unserer gesamten Pipeline involvierten Dienste zu rationalisieren, verwenden wir Terraform die Infrastruktur als Code zu implementieren. Wann immer Infra-Updates erforderlich sind, lösen die Codeänderungen eine von uns eingerichtete GitLab-CI-Pipeline aus, die die Änderungen validiert und in verschiedenen Umgebungen bereitstellt (z. B. Hinzufügen einer Berechtigung zu einer IAM-Richtlinie in Dev-, Stage- und Prod-Konten).
Amazon ECR, Amazon S3 und Lambda: Pipeline-Erleichterung
Wir verwenden die folgenden Schlüsseldienste, um unsere Pipeline zu vereinfachen:
- Amazon ECR – Um die Modell-Container-Images zu verwalten und bequem abrufen zu können, markieren wir sie mit semantischen Versionen und laden sie in ECR-Repositories hoch, die pro eingerichtet wurden
${project_name}/${model_name}durch Terraform. Dies ermöglicht eine gute Isolationsebene zwischen verschiedenen Modellen und ermöglicht es uns, benutzerdefinierte Algorithmen zu verwenden und Inferenzanforderungen und -antworten so zu formatieren, dass sie gewünschte Modellmanifestinformationen (Modellname, Version, Trainingsdatenpfad usw.) enthalten. - Amazon S3 – Wir verwenden S3-Buckets, um Modelltrainingsdaten, trainierte Modellartefakte pro Modell, Airflow-DAGs und andere zusätzliche Informationen, die von den Pipelines benötigt werden, beizubehalten.
- Lambda – Da unser Airflow-Cluster aus Sicherheitsgründen in einer separaten VPC bereitgestellt wird, kann nicht direkt auf die DAGs zugegriffen werden. Daher verwenden wir eine Lambda-Funktion, die ebenfalls mit Terraform verwaltet wird, um alle durch den DAG-Namen angegebenen DAGs auszulösen. Bei ordnungsgemäßer IAM-Einrichtung löst der GitLab-CI-Job die Lambda-Funktion aus, die die Konfigurationen bis zu den angeforderten Trainings- oder Bereitstellungs-DAGs durchläuft.
Amazon MWAA: Trainings- und Bereitstellungspipelines
Wie bereits erwähnt, verwenden wir Amazon MWAA, um die Trainings- und Bereitstellungspipelines zu orchestrieren. Wir verwenden SageMaker-Operatoren, die in verfügbar sind Amazon-Anbieterpaket für Airflow zur Integration mit SageMaker (um Jinja-Templating zu vermeiden).
Wir verwenden die folgenden Operatoren in dieser Trainingspipeline (gezeigt im folgenden Workflow-Diagramm):

MWAA-Schulungspipeline
Wir verwenden die folgenden Operatoren in der Deployment-Pipeline (gezeigt im folgenden Workflow-Diagramm):

Modellbereitstellungspipeline
Wir verwenden Slack und Amazon SNS, um die Fehler-/Erfolgsmeldungen und Bewertungsergebnisse in beiden Pipelines zu veröffentlichen. Slack bietet eine Vielzahl von Optionen zum Anpassen von Nachrichten, einschließlich der folgenden:
- SnsPublishOperator - Wir gebrauchen SnsPublishOperator um Erfolgs-/Fehlerbenachrichtigungen an Benutzer-E-Mails zu senden
- Slack-API – Wir haben die erstellt eingehende Webhook-URL um die Pipeline-Benachrichtigungen an den gewünschten Kanal zu senden
CloudWatch und VMware Wavefront: Überwachung und Protokollierung
Wir verwenden ein CloudWatch-Dashboard, um die Überwachung und Protokollierung von Endpunkten zu konfigurieren. Es hilft bei der Visualisierung und Verfolgung verschiedener Betriebs- und Modellleistungsmetriken, die für jedes Projekt spezifisch sind. Zusätzlich zu den Auto Scaling-Richtlinien, die eingerichtet wurden, um einige von ihnen zu verfolgen, überwachen wir kontinuierlich die Änderungen der CPU- und Speicherauslastung, Anfragen pro Sekunde, Antwortlatenzen und Modellmetriken.
CloudWatch ist sogar in ein VMware Tanzu Wavefront-Dashboard integriert, sodass es die Metriken für Modellendpunkte sowie andere Dienste auf Projektebene visualisieren kann.
Geschäftsvorteile und was als nächstes kommt
ML-Pipelines sind für ML-Dienste und -Funktionen sehr wichtig. In diesem Beitrag haben wir einen End-to-End-ML-Anwendungsfall mit Funktionen von AWS besprochen. Wir haben mit SageMaker und Amazon MWAA eine benutzerdefinierte Pipeline erstellt, die wir projekt- und modellübergreifend wiederverwenden können, und den ML-Lebenszyklus automatisiert, wodurch die Zeit vom Modelltraining bis zur Produktionsbereitstellung auf nur 10 Minuten reduziert wurde.
Mit der Verlagerung der ML-Lebenszykluslast auf SageMaker wurde eine optimierte und skalierbare Infrastruktur für das Modelltraining und die Bereitstellung bereitgestellt. Die Modellbereitstellung mit SageMaker hat uns geholfen, Echtzeitvorhersagen mit Millisekunden-Latenzen und Überwachungsfunktionen zu treffen. Wir haben Terraform verwendet, um die Einrichtung zu vereinfachen und die Infrastruktur zu verwalten.
Die nächsten Schritte für diese Pipeline wären die Verbesserung der Modelltrainingspipeline mit Umschulungsfunktionen, unabhängig davon, ob es geplant ist oder auf der Erkennung von Modellabweichungen basiert, Unterstützung von Schattenbereitstellung oder A/B-Tests für eine schnellere und qualifizierte Modellbereitstellung und ML-Herkunftsverfolgung. Wir planen auch zu evaluieren Amazon SageMaker-Pipelines weil die GitLab-Integration jetzt unterstützt wird.
Lessons learned
Als Teil der Erstellung dieser Lösung haben wir gelernt, dass Sie früh verallgemeinern sollten, aber nicht zu sehr verallgemeinern. Als wir das Architekturdesign zum ersten Mal abgeschlossen hatten, versuchten wir, als Best Practice Codevorlagen für den Modellcode zu erstellen und durchzusetzen. Allerdings war es so früh im Entwicklungsprozess, dass die Vorlagen entweder zu allgemein oder zu detailliert waren, um für zukünftige Modelle wiederverwendet werden zu können.
Nachdem das erste Modell durch die Pipeline geliefert wurde, kamen die Vorlagen auf natürliche Weise heraus, basierend auf den Erkenntnissen aus unserer vorherigen Arbeit. Eine Pipeline kann nicht alles vom ersten Tag an.
Modellexperimente und Produktion haben oft sehr unterschiedliche (oder manchmal sogar widersprüchliche) Anforderungen. Entscheidend ist, diese Anforderungen von Anfang an im Team auszubalancieren und entsprechend zu priorisieren.
Darüber hinaus benötigen Sie möglicherweise nicht alle Funktionen eines Dienstes. Die Nutzung wesentlicher Funktionen eines Dienstes und ein modularisiertes Design sind der Schlüssel zu einer effizienteren Entwicklung und einer flexiblen Pipeline.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie wir mit SageMaker und Amazon MWAA eine MLOps-Lösung erstellt haben, die den Prozess der Bereitstellung von Modellen für die Produktion mit wenig manuellem Eingriff von Data Scientists automatisiert. Wir empfehlen Ihnen, verschiedene AWS-Services wie SageMaker, Amazon MWAA, Amazon S3 und Amazon ECR zu evaluieren, um eine vollständige MLOps-Lösung zu erstellen.
*Apache, Apache Airflow und Airflow sind entweder eingetragene Warenzeichen oder Warenzeichen der Apache Software Foundation in den USA und/oder anderen Ländern.
Über die Autoren
 Deepak Mettem ist Senior Engineering Manager bei VMware, Carbon Black Unit. Er und sein Team arbeiten daran, Streaming-basierte Anwendungen und Dienste zu entwickeln, die hochverfügbar, skalierbar und belastbar sind, um Kunden auf maschinellem Lernen basierende Lösungen in Echtzeit bereitzustellen. Er und sein Team sind auch für die Erstellung von Tools verantwortlich, die Data Scientists zum Erstellen, Trainieren, Bereitstellen und Validieren ihrer ML-Modelle in der Produktion benötigen.
Deepak Mettem ist Senior Engineering Manager bei VMware, Carbon Black Unit. Er und sein Team arbeiten daran, Streaming-basierte Anwendungen und Dienste zu entwickeln, die hochverfügbar, skalierbar und belastbar sind, um Kunden auf maschinellem Lernen basierende Lösungen in Echtzeit bereitzustellen. Er und sein Team sind auch für die Erstellung von Tools verantwortlich, die Data Scientists zum Erstellen, Trainieren, Bereitstellen und Validieren ihrer ML-Modelle in der Produktion benötigen.
 Mahima Agarwal ist Machine Learning Engineer bei VMware, Carbon Black Unit.
Mahima Agarwal ist Machine Learning Engineer bei VMware, Carbon Black Unit.
Sie arbeitet an Design, Aufbau und Entwicklung der Kernkomponenten und der Architektur der Plattform für maschinelles Lernen für die VMware CB SBU.
 Vamshi Krishna Enabothala ist Senior Applied AI Specialist Architect bei AWS. Er arbeitet mit Kunden aus verschiedenen Branchen zusammen, um wirkungsvolle Daten-, Analyse- und maschinelle Lerninitiativen zu beschleunigen. Er interessiert sich leidenschaftlich für Empfehlungssysteme, NLP und Computer Vision-Bereiche in KI und ML. Außerhalb der Arbeit ist Vamshi ein RC-Enthusiast, der RC-Ausrüstung (Flugzeuge, Autos und Drohnen) baut und auch gerne im Garten arbeitet.
Vamshi Krishna Enabothala ist Senior Applied AI Specialist Architect bei AWS. Er arbeitet mit Kunden aus verschiedenen Branchen zusammen, um wirkungsvolle Daten-, Analyse- und maschinelle Lerninitiativen zu beschleunigen. Er interessiert sich leidenschaftlich für Empfehlungssysteme, NLP und Computer Vision-Bereiche in KI und ML. Außerhalb der Arbeit ist Vamshi ein RC-Enthusiast, der RC-Ausrüstung (Flugzeuge, Autos und Drohnen) baut und auch gerne im Garten arbeitet.
 Sahil Thapar ist Enterprise Solutions Architect. Er arbeitet mit Kunden zusammen, um ihnen beim Aufbau hochverfügbarer, skalierbarer und stabiler Anwendungen in der AWS Cloud zu helfen. Derzeit konzentriert er sich auf Container und Lösungen für maschinelles Lernen.
Sahil Thapar ist Enterprise Solutions Architect. Er arbeitet mit Kunden zusammen, um ihnen beim Aufbau hochverfügbarer, skalierbarer und stabiler Anwendungen in der AWS Cloud zu helfen. Derzeit konzentriert er sich auf Container und Lösungen für maschinelles Lernen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :Ist
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- Über uns
- beschleunigen
- Zugang
- Zugriff
- entsprechend
- Trading Konten
- erreicht
- über
- azyklisch
- Zusatz
- Zusätzliche
- Zusätzliche Angaben
- Nach der
- gegen
- AI
- Algorithmen
- Alle
- erlaubt
- Amazon
- Amazon Sage Maker
- Analyse
- Analytik
- und
- von jedem Standort
- Apache
- Bienen
- Anwendung
- Anwendungen
- angewandt
- Angewandte KI
- Genehmigung
- Architektur
- SIND
- Bereiche
- AS
- Aussehen
- At
- Anschläge
- Authoring
- Auto
- Automatisiert
- Automatisches Erfassen:
- Verfügbarkeit
- verfügbar
- vermeiden
- AWS
- Backend
- Balance
- basierend
- basic
- BE
- weil
- Anfang
- Vorteile
- BESTE
- Besser
- zwischen
- Schwarz
- Blockieren
- Filiale
- bringen
- bauen
- Building
- erbaut
- Last
- by
- CAN
- kann keine
- Fähigkeiten
- Kohlenstoff
- Autos
- Häuser
- CB
- sicher
- Änderungen
- Kanäle
- der
- wählten
- Cloud
- Cluster
- Code
- Sammlung
- Kommunikation
- verglichen
- abschließen
- Komponenten
- Berechnen
- Computer
- Computer Vision
- dirigiert
- Konfiguration
- Konfigurationen
- Widersprüchlich
- Verwirrung
- Überlegungen
- verbrauchen
- verbraucht
- Container
- Behälter
- ständig
- Praktische
- Kernbereich
- könnte
- Länder
- CPU
- erstellen
- erstellt
- schafft
- Erstellen
- kritischem
- wichtig
- Zur Zeit
- Original
- Kunden
- anpassen
- Cyber-Angriffe
- TAG
- Unterricht
- Armaturenbrett
- technische Daten
- Datenwissenschaftler
- Tag
- definiert
- liefern
- einsetzen
- Einsatz
- Bereitstellen
- Einsatz
- Implementierungen
- setzt ein
- Design
- entworfen
- Entwerfen
- detailliert
- Details
- Entdeckung
- Entwickler
- entwickelt
- Entwicklung
- Entwicklung
- anders
- Direkt
- diskutieren
- diskutiert
- Docker
- Nicht
- nach unten
- Drohnen
- jeder
- Früher
- Früh
- Benutzerfreundlichkeit
- effizient
- entweder
- aufstrebenden
- ermöglichen
- freigegeben
- ermöglicht
- ermutigen
- End-to-End
- Endpunkt
- Ingenieur
- Entwicklung
- Unternehmen
- Enterprise-Lösungen
- Enthusiast
- Umgebungen
- Ausrüstung
- essential
- Äther (ETH)
- bewerten
- Bewerten
- Auswerten
- Auswertung
- Auswertungen
- Sogar
- Event
- Jedes
- alles
- Beispiel
- Erweitern Sie die Funktionalität der
- Verlängerung
- f1
- erleichtern
- Scheitern
- weit
- beschleunigt
- Merkmal
- Eigenschaften
- wenige
- Mappen
- Vorname
- flexibel
- Setzen Sie mit Achtsamkeit
- konzentriert
- konzentriert
- Folgende
- Aussichten für
- Format
- für
- voller
- full spectrum
- voll
- Funktion
- Funktionen
- weiter
- Zukunft
- erzeugt
- bekommen
- gut
- Gruppe an
- Haben
- mit
- Hilfe
- dazu beigetragen,
- hilft
- High
- Hohe Leistungsfähigkeit
- hoch
- Hosting
- Ultraschall
- aber
- HTML
- http
- HTTPS
- IAM
- ID
- ideal
- identifiziert
- identifizieren
- Identitätsschutz
- Image
- Bilder
- implementieren
- Implementierung
- umgesetzt
- in
- das
- Dazu gehören
- Einschließlich
- Information
- Infrastruktur
- Initiativen
- Einblicke
- integrieren
- integriert
- Integriert
- Integration
- interagieren
- Intervention
- ruft auf
- beteiligt
- Isolierung
- IT
- SEINE
- Job
- Jobs
- jpg
- Behalten
- Wesentliche
- Tasten
- Latency
- Schicht
- gelernt
- lernen
- Programm
- Lessons Learned
- Lasst uns
- Niveau
- Lebenszyklus
- Gefällt mir
- wenig
- Belastung
- Sneaker
- Maschine
- Maschinelles Lernen
- Main
- halten
- unterhält
- Wartung
- um
- verwalten
- verwaltet
- Management
- Manager
- Managed
- flächendeckende Gesundheitsprogramme
- manuell
- Matrix
- Memory
- erwähnt
- Nachrichten
- Messaging
- Metrik
- könnte
- Millisekunde
- Minuten
- ML
- MLOps
- Modell
- für
- modern
- Überwachen
- Überwachung
- mehr
- effizienter
- mehrere
- Name
- natürlich
- notwendig,
- Need
- Neu
- weiter
- Nlp
- Lärm
- Benachrichtigung
- Benachrichtigungen
- Anzahl
- of
- bieten
- Angebote
- on
- EINEM
- Betriebs-
- Betreiber
- optimiert
- Optionen
- orchestriert
- Organisiert
- Andere
- aussen
- Gesamt-
- Paket
- Pakete
- Verpackung
- Teil
- leitet
- Bestehen
- leidenschaftlich
- Weg
- Leistung
- Erlaubnis
- Pipeline
- Plan
- Flugzeuge
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Politik durchzulesen
- Datenschutzrichtlinien
- Post
- Praxis
- Prognosen
- früher
- Priorität einräumen
- Prozessdefinierung
- Produkt
- Produktion
- Projekt
- Projekte
- ordnungsgemäße
- Sicherheit
- vorausgesetzt
- Versorger
- bietet
- veröffentlichen
- veröffentlicht
- Veröffentlicht
- Publishing
- Zwecke
- qualifiziert
- Angebot
- Echtzeit
- Software Empfehlungen
- Reduziert
- bezeichnet
- eingetragen
- Registratur
- Beziehungen
- entfernt
- Berühmt
- Quelle
- angefordert
- Zugriffe
- falls angefordert
- Voraussetzungen:
- Forschungsprojekte
- federnde
- Antwort
- für ihren Verlust verantwortlich.
- Die Ergebnisse
- Umschulung
- wiederverwendbar
- Rollen
- Führen Sie
- Läufer
- sagemaker
- gleich
- skalierbaren
- Skalierung
- Zeitplan
- vorgesehen
- Wissenschaftler
- Wissenschaftler
- Zweite
- Abschnitte
- Sektoren
- Sicherheitdienst
- Senior
- getrennte
- Serverlos
- Fertige Server
- Leistungen
- Dienst
- kompensieren
- Setup
- Shadow
- VERSCHIEBUNG
- sollte
- gezeigt
- Einfacher
- locker
- So
- bis jetzt
- Software
- Lösung
- Lösungen
- einige
- Quelle
- Quellcode
- Spezialist
- spezifisch
- angegeben
- Spektrum
- Scheinwerfer
- Stufe
- Stufen
- Standard
- Anfang
- beginnt
- Staaten
- Shritte
- Lagerung
- Strategie
- Streaming
- rationalisieren
- Folge
- Erfolgreich
- so
- Support
- Unterstützte
- Oberfläche
- Systeme und Techniken
- TAG
- Nehmen
- und Aufgaben
- Team
- Vorlagen
- Terraform
- Testen
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- deswegen
- Diese
- Bedrohungen
- nach drei
- Durch
- während
- Durchsatz
- Zeit
- Zeitstempel
- zu
- gemeinsam
- auch
- Werkzeug
- Werkzeuge
- Top
- Thema
- verfolgen sind
- Tracking
- Warenzeichen
- der Verkehr
- Training
- trainiert
- Ausbildung
- auslösen
- ausgelöst
- WENDE
- für
- Einheit
- Vereinigt
- USA
- Updates
- us
- Anwendungsbereich
- -
- Anwendungsfall
- Mitglied
- Nutzer
- BESTÄTIGEN
- Bestätigung
- Variablen
- verschiedene
- Version
- praktisch
- Seh-
- visualisieren
- VMware
- Volumen
- Weg..
- GUT
- Was
- ob
- welche
- breit
- Große Auswahl
- mit
- .
- ohne
- Arbeiten
- Arbeitsablauf.
- Workflows
- Werk
- würde
- Zephyrnet
- PLZ
- Zonen