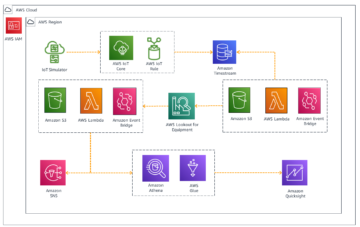
Organisationen verwenden agile Projektmanagement-Plattformen wie Atlassian Jira um es Teams zu ermöglichen, zusammenzuarbeiten, um Ergebnisse zu planen, zu verfolgen und zu versenden. Jira erfasst organisatorisches Wissen über die Funktionsweise der Ergebnisse in den Problemen und Kommentaren, die während der Projektimplementierung protokolliert werden. Dieses Wissen den Benutzern einfach und sicher zur Verfügung zu stellen, ist jedoch eine Herausforderung, da es über Probleme verteilt ist, die zu verschiedenen Projekten und Sprints gehören. Da außerdem verschiedene Beteiligte wie Entwickler, Testingenieure und Projektmanager zum selben Problem beitragen, indem sie es protokollieren und dann Anhänge und Kommentare hinzufügen, wird die herkömmliche schlüsselwortbasierte Suche bei der Suche nach Informationen in Jira-Projekten unwirksam.
Sie können jetzt die Amazon Kendra Jira Cloud Connector zum Indizieren von Problemen, Kommentaren und Anhängen in Ihren Jira-Projekten und zum Durchsuchen dieser Inhalte mit der intelligenten Amazon Kendra-Suche, die auf maschinellem Lernen (ML) basiert.
Dieser Beitrag zeigt, wie Sie den Amazon Kendra Jira Cloud Connector verwenden, um eine Jira Cloud-Instanz als Datenquelle für einen Amazon Kendra-Index zu konfigurieren und die Inhalte der darin enthaltenen Projekte intelligent zu durchsuchen. Wir verwenden ein Beispiel für Jira-Projekte, bei denen Teammitglieder zusammenarbeiten, indem sie Issues erstellen und ihnen während des gesamten Issue-Lebenszyklus Informationen in Form von Beschreibungen, Kommentaren und Anhängen hinzufügen.
Lösungsüberblick
Eine Jira-Instanz hat ein oder mehrere Projekte, wobei jedes Projekt Teammitglieder hat, die an Vorgängen in diesem Projekt arbeiten. Jedes Teammitglied verfügt über eine Reihe von Berechtigungen für die Vorgänge, die es in Bezug auf verschiedene Probleme in dem Projekt, zu dem es gehört, ausführen kann. Teammitglieder können neue Issues erstellen oder den Issues weitere Informationen in Form von Anhängen und Kommentaren hinzufügen sowie den Status eines Issues von seiner Eröffnung bis zum Abschluss während des für dieses Projekt definierten Issue-Lebenszyklus ändern. Ein Projektmanager erstellt Sprints, ordnet Vorgänge bestimmten Sprints zu und weist Vorgängen Verantwortliche zu. Im Laufe des Projekts entwickelt sich das in diesen Fragestellungen erfasste Wissen weiter.
In unserer Lösung konfigurieren wir eine Jira-Cloud-Instance als Datenquelle für einen Amazon Kendra-Suchindex unter Verwendung des Amazon Kendra Jira-Konnektors. Basierend auf der Konfiguration durchsucht und indiziert der Konnektor bei der Synchronisierung der Datenquelle die Inhalte aus den Projekten in der Jira-Instanz. Optional können Sie es so konfigurieren, dass der Inhalt basierend auf dem Änderungsprotokoll indiziert wird. Der Konnektor sammelt und nimmt auch Informationen der Zugriffssteuerungsliste (ACL) für jedes Problem, jeden Kommentar und jeden Anhang auf. Die ACL-Informationen werden für die Benutzerkontextfilterung verwendet, bei der Suchergebnisse für eine Abfrage danach gefiltert werden, worauf ein Benutzer autorisierten Zugriff hat.
Voraussetzungen:
Um den Amazon Kendra-Konnektor für Jira anhand dieses Beitrags als Referenz auszuprobieren, benötigen Sie Folgendes:
- An AWS-Konto mit Berechtigungen zum Erstellen AWS Identity and Access Management and (IAM) Rollen und Richtlinien. Weitere Informationen finden Sie unter Überblick über die Zugriffsverwaltung: Berechtigungen und Richtlinien und Richtlinien für Jira-Datenquellen.
- Grundkenntnisse von AWS und praktische Kenntnisse der Jira-Administration.
- Administratorzugriff auf eine Jira-Cloud-Instanz.
Jira-Instanzkonfiguration
Dieser Abschnitt beschreibt die Jira-Konfiguration, die verwendet wird, um zu demonstrieren, wie man eine Amazon Kendra-Datenquelle mit dem Jira-Konnektor konfiguriert, die Daten aus den Jira-Projekten in den Amazon Kendra-Index aufnimmt und Suchanfragen durchführt. Sie können Ihre eigene Jira-Instanz verwenden, für die Sie Administratorzugriff haben, oder ein neues Projekt erstellen und die Schritte zum Testen des Amazon Kendra-Konnektors für Jira ausführen.
In unserer Jira-Beispielinstanz haben wir zwei Projekte erstellt, um zu demonstrieren, dass die Suchanfragen von Benutzern nur Ergebnisse aus den Projekten zurückgeben, auf die sie Zugriff haben. Wir haben Daten aus den folgenden Public-Domain-Projekten verwendet, um den Anwendungsfall realer Softwareentwicklungsprojekte zu simulieren:
- AWS CLI-Communitybeiträge GitHub-Projekt
- Ein Projekt aus der beliebten Deep Learning Library PyTorch
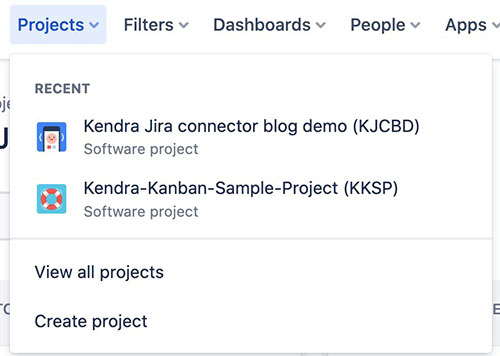
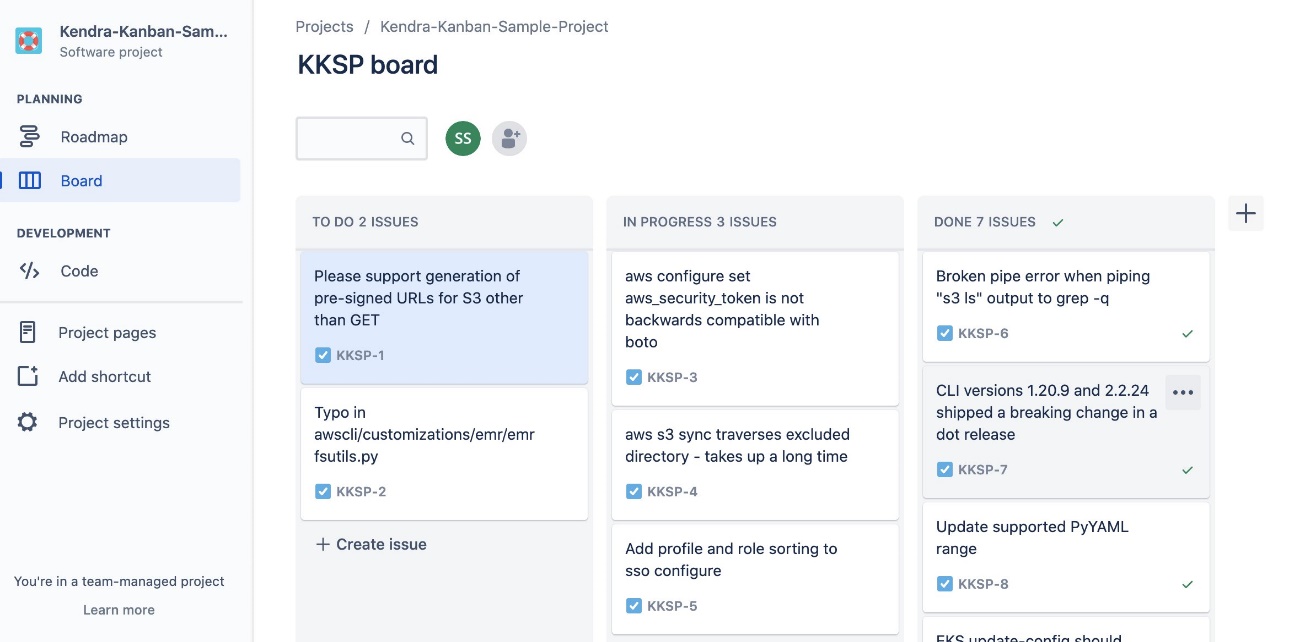
Das Folgende ist ein Screenshot unseres Boards im Kanban-Stil für Projekt 1.
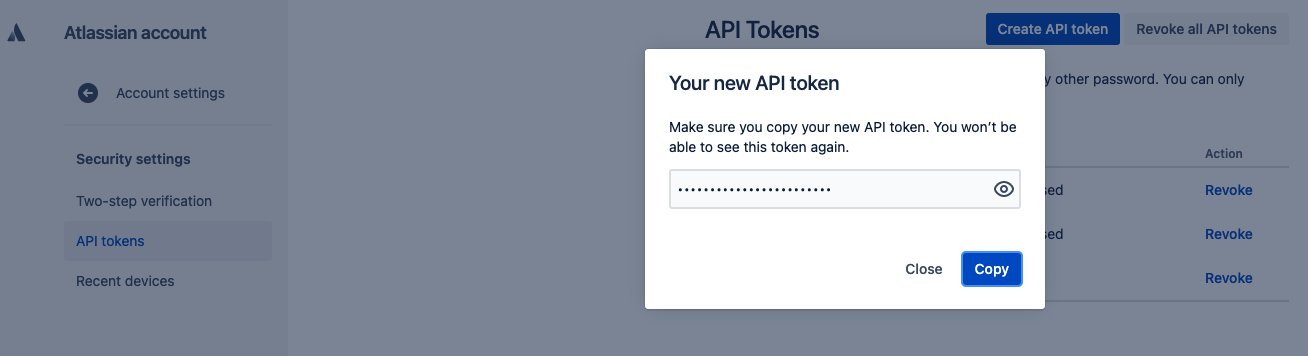
Erstellen Sie ein API-Token für die Jira-Instanz
Führen Sie die folgenden Schritte aus, um das API-Token abzurufen, das zum Konfigurieren des Amazon Kendra Jira-Konnektors erforderlich ist:
- Einloggen in https://id.atlassian.com/manage/api-tokens.
- Auswählen API-Token erstellen.
- Geben Sie im angezeigten Dialogfeld eine Bezeichnung für Ihr Token ein und wählen Sie aus Erstellen.
- Auswählen Kopieren und geben Sie den Token auf einem temporären Notizblock ein.
Sie können dieses Token nicht erneut kopieren und benötigen es, um den Amazon Kendra Jira-Connector zu konfigurieren.
Konfigurieren Sie die Datenquelle mit dem Amazon Kendra-Konnektor für Jira
Um Ihrem Amazon Kendra-Index mithilfe des Jira-Konnektors eine Datenquelle hinzuzufügen, können Sie einen vorhandenen Index verwenden oder Erstellen Sie einen neuen Index. Führen Sie dann die folgenden Schritte aus. Weitere Informationen zu diesem Thema finden Sie unter Amazon Kendra-Entwicklerhandbuch.
- Öffnen Sie in der Amazon Kendra-Konsole Ihren Index und wählen Sie aus Datenquellen im Navigationsbereich.
- Auswählen Datenquelle hinzufügen.
- Der Jira, wählen Stecker hinzufügen.

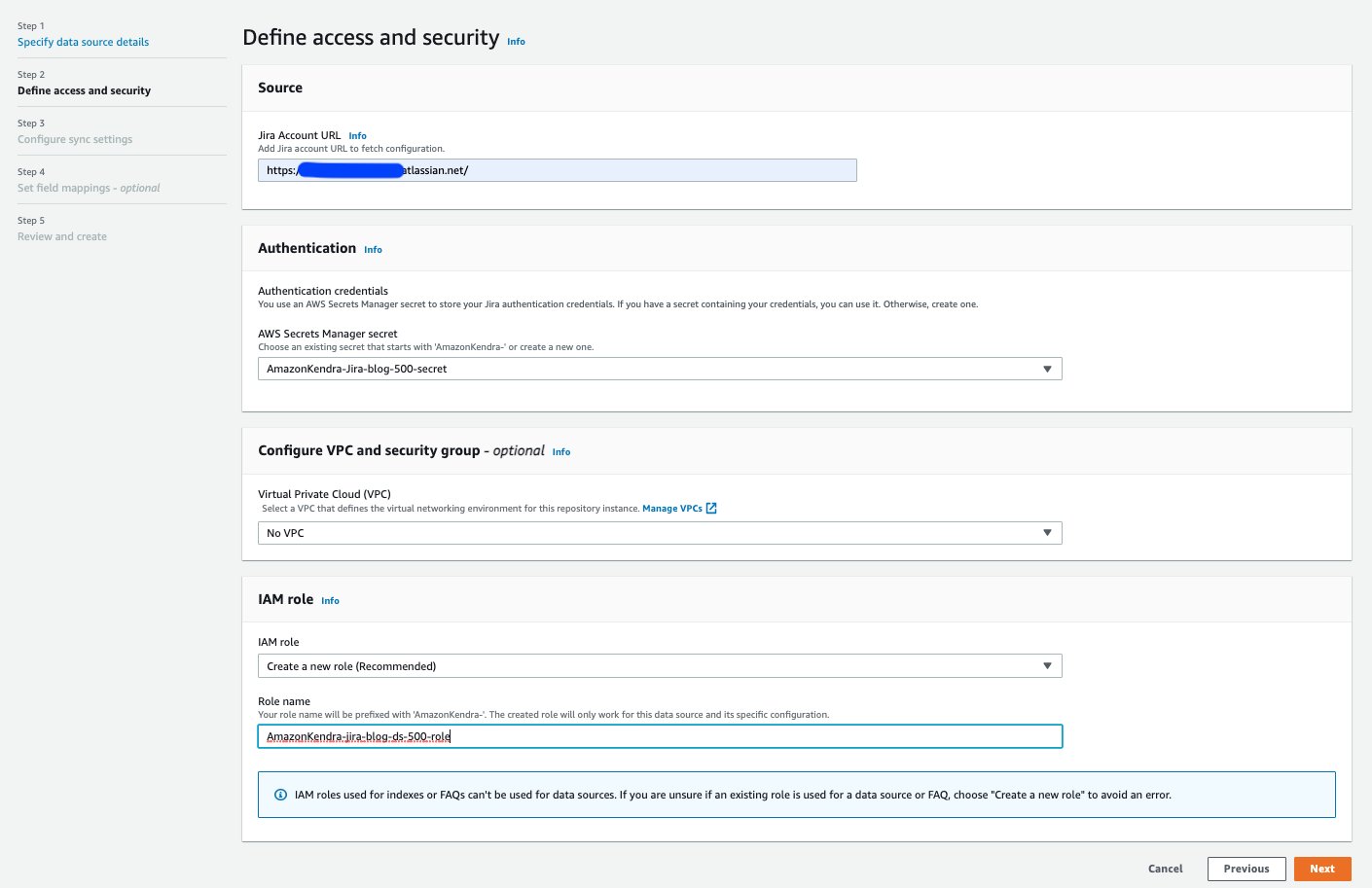
- Im Geben Sie Datenquellendetails an geben Sie die Details Ihrer Datenquelle ein und wählen Sie aus Weiter.
- Im Definieren Sie Zugriff und Sicherheit Abschnitt, für Jira-Konto-URL, geben Sie die URL Ihrer Jira-Cloud-Instanz ein.
- Der AuthentifizierungSie haben zwei Möglichkeiten:
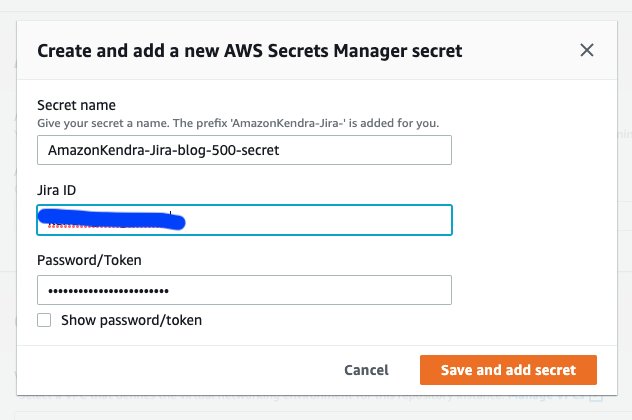
- Auswählen Erstellen , um ein neues Geheimnis mit dem Jira-API-Token hinzuzufügen, das Sie aus Ihrer Jira-Instanz kopiert haben, und verwenden Sie die E-Mail-Adresse, mit der Sie sich bei Jira anmelden, als Jira-ID. (Dies ist die Option, die wir für diesen Beitrag wählen.)
- Verwenden Sie eine vorhandene AWS Secrets Manager Secret, das das API-Token für die Jira-Instanz enthält, auf die der Connector zugreifen soll.
- Aussichten für IAM-Rolle, wählen Erstellen Sie eine neue Rolle oder wählen Sie eine vorhandene IAM-Rolle aus, die mit geeigneten IAM-Richtlinien konfiguriert ist, um auf das Secrets Manager-Secret, den Amazon Kendra-Index und die Datenquelle zuzugreifen.
- Auswählen
Weiter.
- Im Konfigurieren Sie die Synchronisierungseinstellungen Geben Sie im Abschnitt Informationen zu Ihrem Synchronisierungsbereich und Ausführungszeitplan an.
- Auswählen
Weiter.
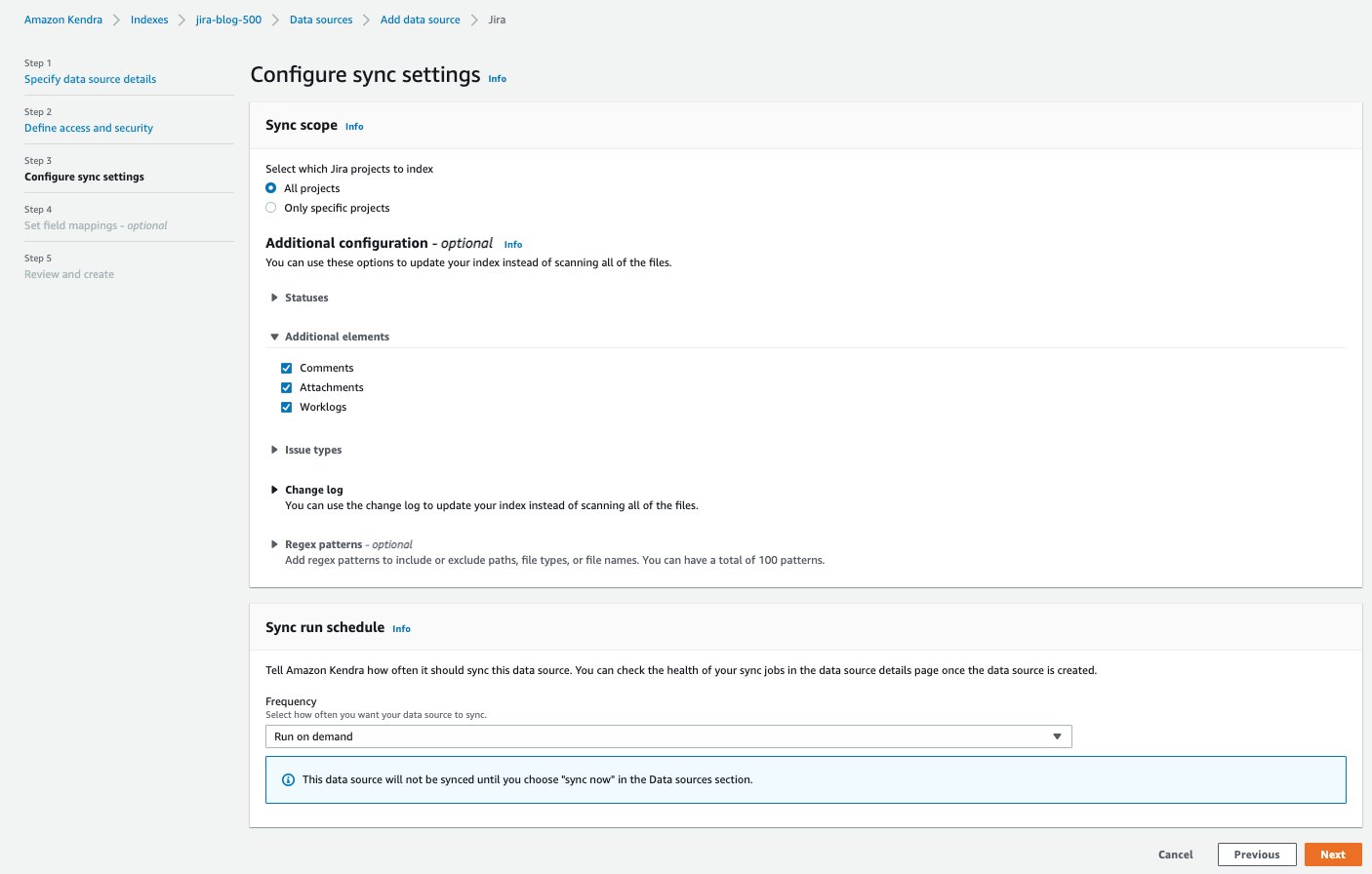
- Im Legen Sie Feldzuordnungen fest Abschnitt können Sie optional die Feldzuordnungen konfigurieren oder wie die Jira-Feldnamen Amazon Kendra-Attributen oder -Facetten zugeordnet werden.
- Auswählen Weiter.
- Überprüfen Sie Ihre Einstellungen und bestätigen Sie das Hinzufügen der Datenquelle.
- Nachdem die Datenquelle hinzugefügt wurde, wählen Sie aus Datenquellen Wählen Sie im Navigationsbereich die neu hinzugefügte Datenquelle aus, und wählen Sie aus Jetzt synchronisieren um die Datenquellensynchronisierung mit dem Amazon Kendra-Index zu starten.
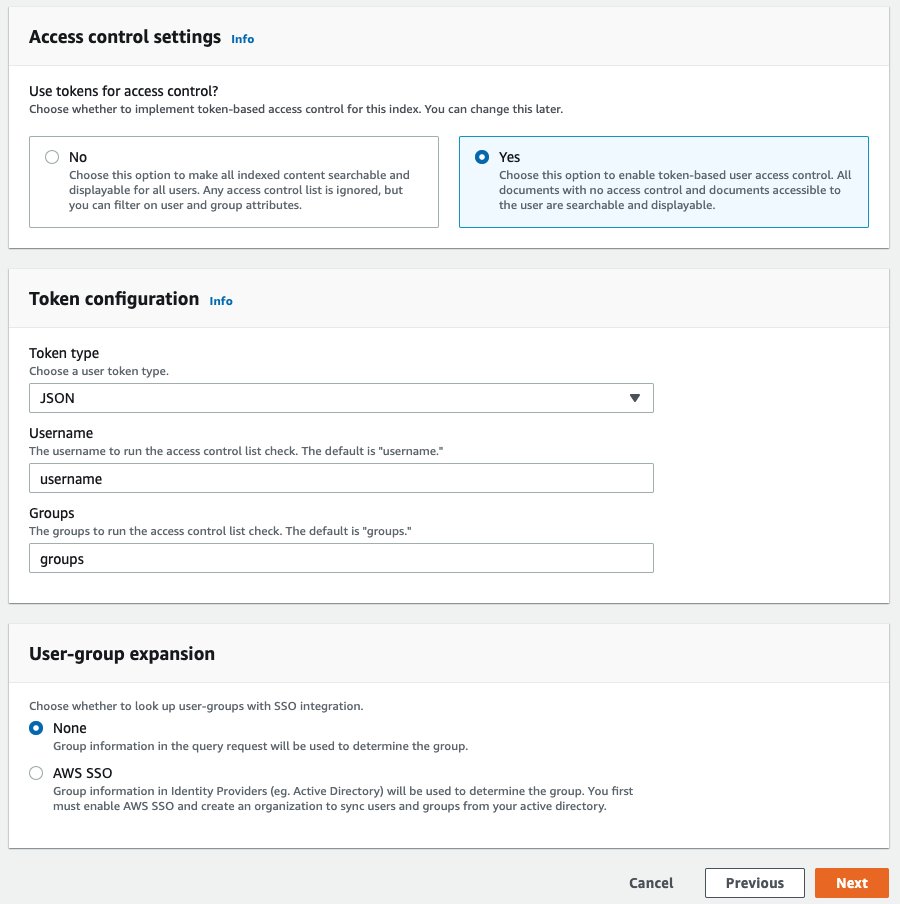
Der Synchronisierungsvorgang kann etwa 10 bis 15 Minuten dauern. Lassen Sie uns nun die Zugriffskontrolle für den Amazon Kendra-Index aktivieren. - Wählen Sie im Navigationsbereich Ihren Index aus.
- Wählen Sie im mittleren Bereich die aus Benutzerzugriffssteuerung Tab.
- Auswählen Einstellungen bearbeiten und ändern Sie die Einstellungen so, dass sie wie im folgenden Screenshot aussehen.
- Auswählen
Weiter und dann wählen Aktualisierung.
Führen Sie eine intelligente Suche mit Amazon Kendra durch
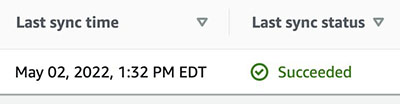
Bevor Sie versuchen, in der Amazon Kendra-Konsole zu suchen oder die API zu verwenden, stellen Sie sicher, dass die Datenquellensynchronisierung abgeschlossen ist. Sehen Sie sich zur Überprüfung die Datenquellen an und überprüfen Sie, ob die letzte Synchronisierung erfolgreich war.
- Um Ihre Suche zu starten, wählen Sie in der Amazon Kendra-Konsole aus Suche nach indizierten Inhalten im Navigationsbereich.
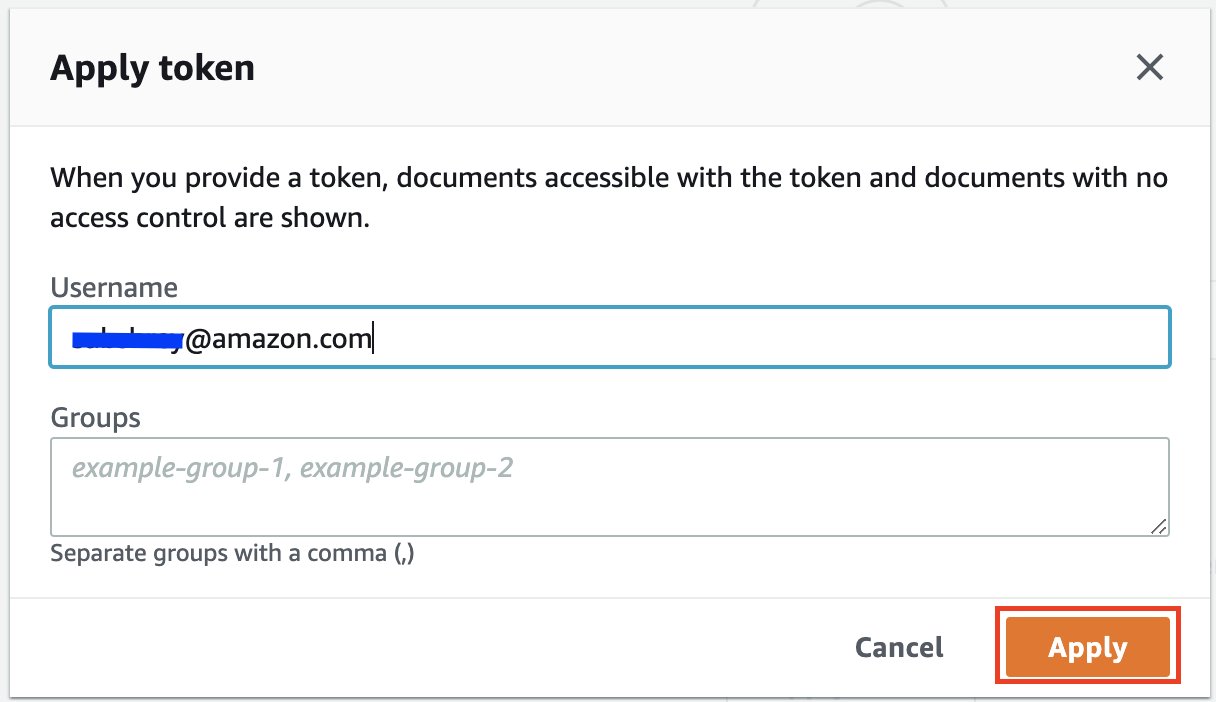
Sie werden zur Amazon Kendra-Suchkonsole weitergeleitet. - Erweitern Sie die Funktionalität der Testabfrage mit einem Zugriffstoken und wählen Sie Token anwenden.
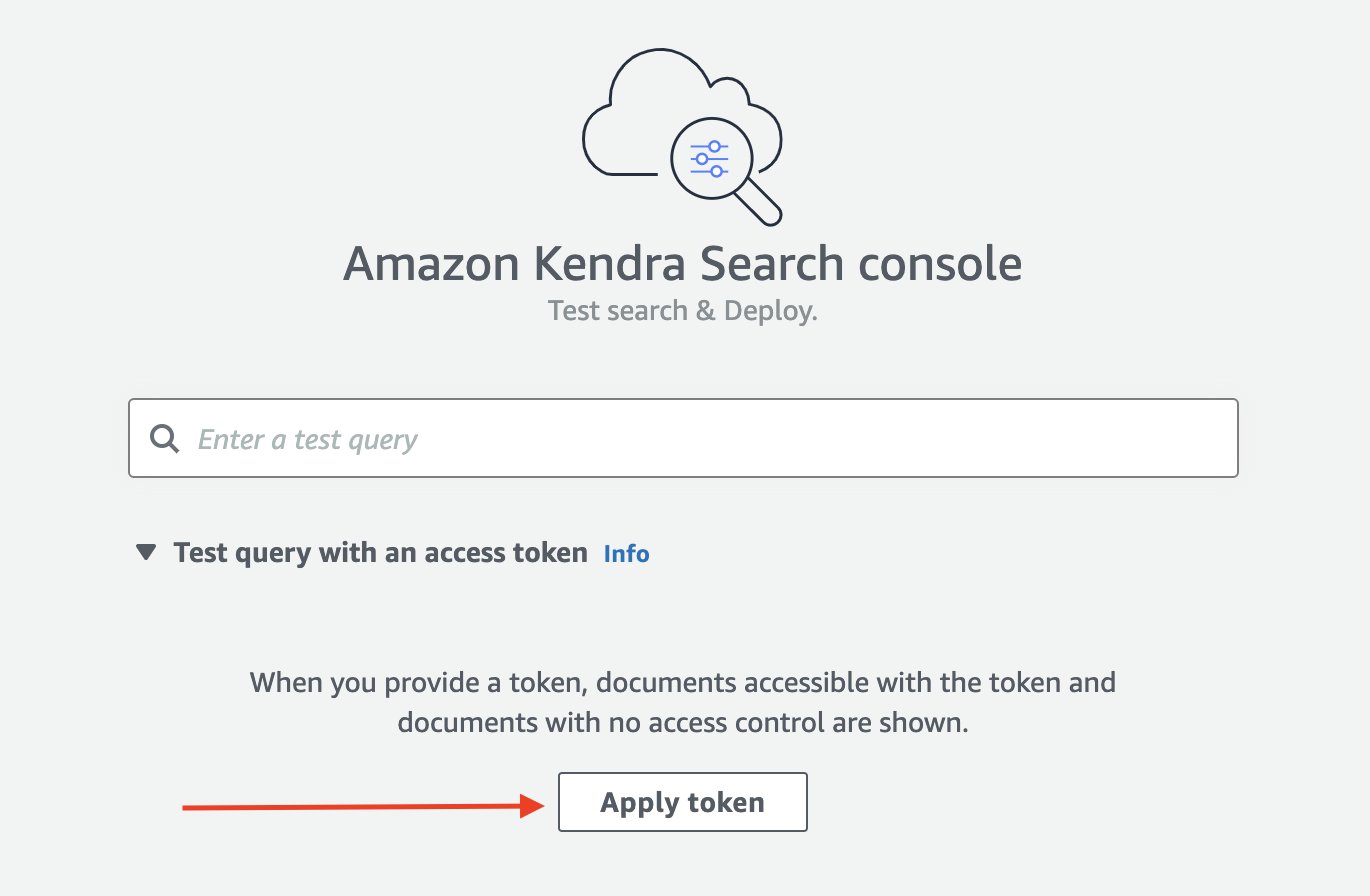
- Aussichten für Benutzername, geben Sie die mit Ihrem Jira-Konto verknüpfte E-Mail-Adresse ein.
- Auswählen
Jetzt bewerben.
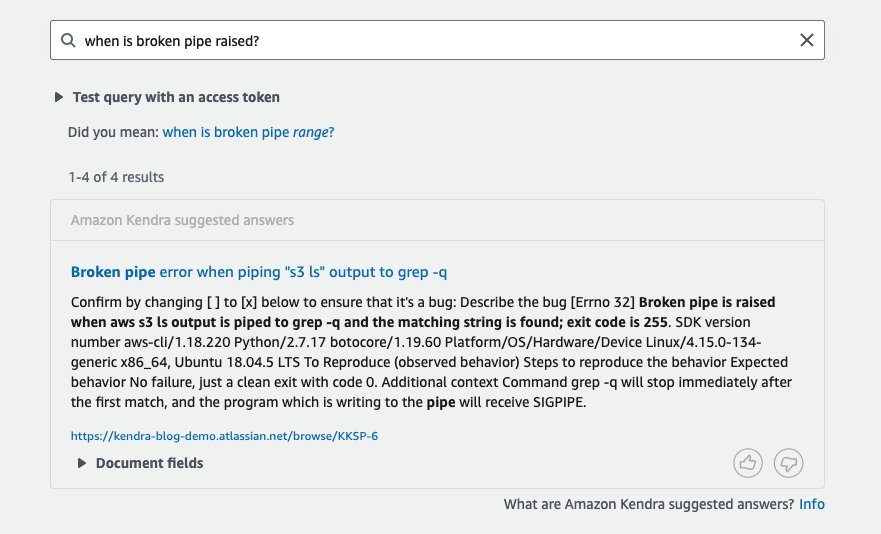
Jetzt können wir unseren Index durchsuchen. Lassen Sie uns die Abfrage „Wo speichert boto3 Sicherheitstoken speichern?“ verwenden.

In diesem Fall liefert Kendra einen Antwortvorschlag von einer der Karten in unserem Kanban-Projekt auf Jira.
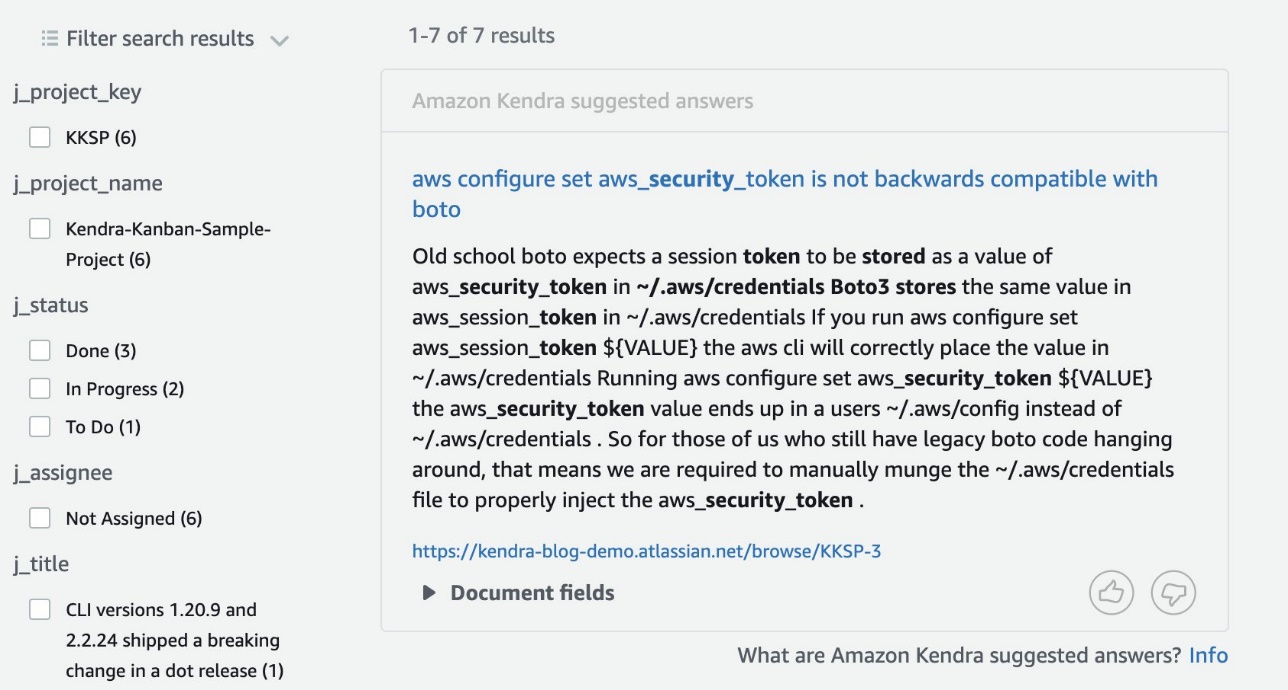
Beachten Sie, dass dies auch eine vorgeschlagene Antwort ist, die auf ein Problem hinweist, bei dem es um AWS-Sicherheitstoken und Boto3 geht. Sie können mit Amazon Kendra auch Sucherfahrungen mit mehreren Datenquellen aufbauen, einschließlich SDK-Dokumentation und Wikis, und Ergebnisse und zugehörige Links entsprechend präsentieren. Der folgende Screenshot zeigt eine andere Suchanfrage für denselben Index.
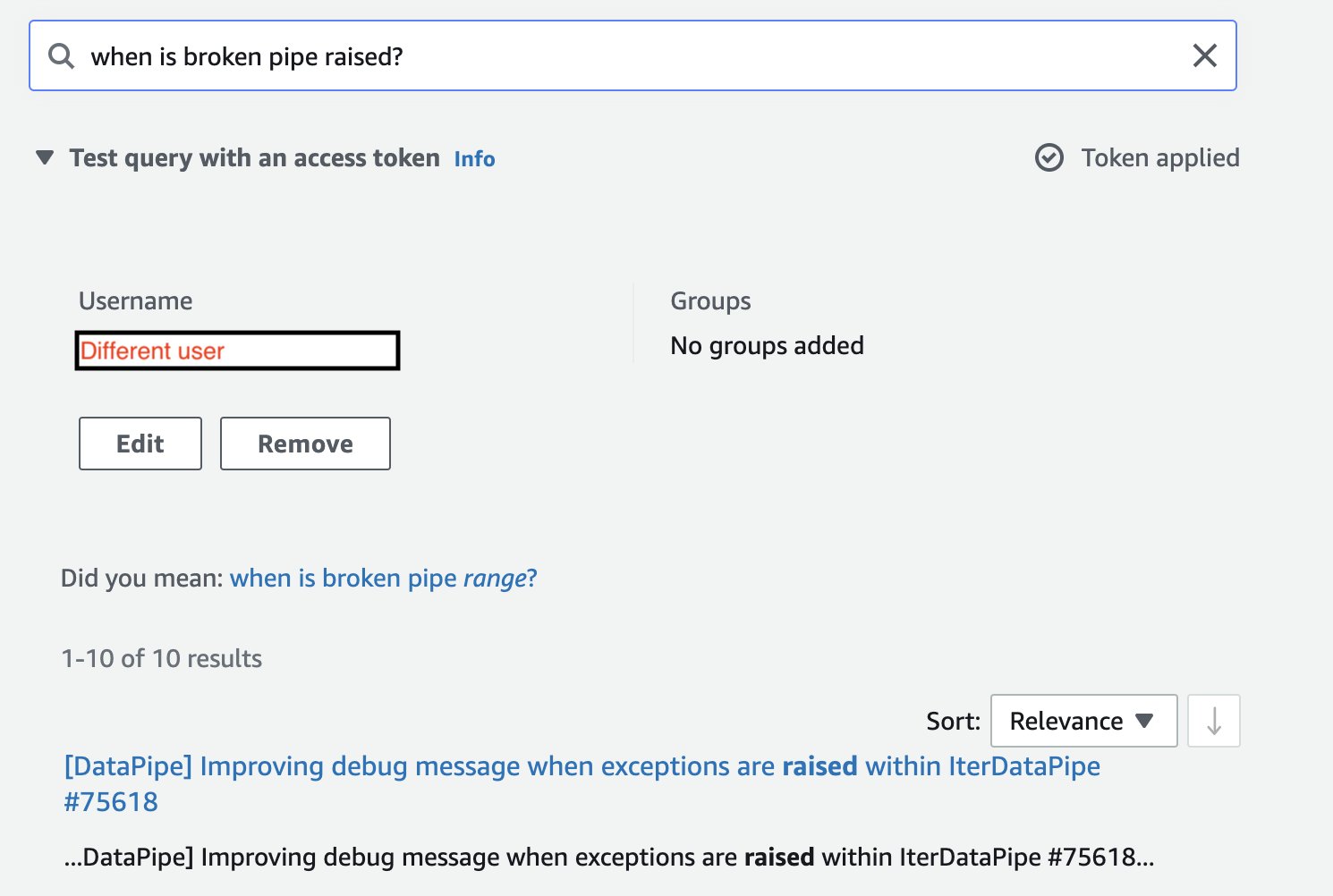
Beachten Sie, dass die Suchergebnisse auf Projekte beschränkt sind, auf die dieser Benutzer Zugriff hat, wenn wir ein anderes Zugriffstoken anwenden (die Suche einem anderen Benutzer zuordnen).
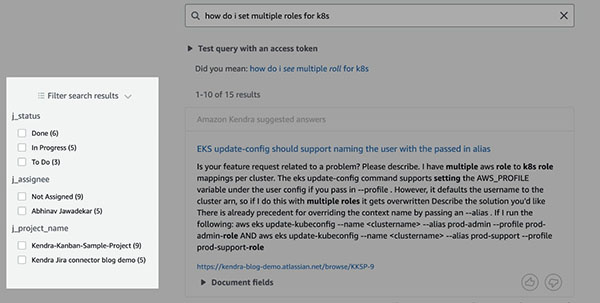
Schließlich können wir bei unserer Suche auch für Jira relevante Filter verwenden. Zuerst navigieren wir zu unserem Index Facettendefinition Seite und überprüfen Facettierbar für j_status, j_assignee und j_project_name. Bei jeder Suche können wir dann nach diesen Feldern filtern, wie im folgenden Screenshot gezeigt.
Aufräumen
Um zukünftige Kosten zu vermeiden, bereinigen Sie die Ressourcen, die Sie als Teil dieser Lösung erstellt haben. Wenn Sie beim Testen dieser Lösung einen neuen Amazon Kendra-Index erstellt haben, löschen Sie ihn. Wenn Sie nur eine neue Datenquelle mit dem Amazon Kendra-Konnektor für Jira hinzugefügt haben, löschen Sie diese Datenquelle.
Zusammenfassung
Mit dem Amazon Kendra Jira-Konnektor kann Ihr Unternehmen Ihren Benutzern mithilfe der intelligenten Suche von Amazon Kendra wertvolles Wissen in Ihren Jira-Projekten sicher zur Verfügung stellen.
Weitere Informationen zum Amazon Kendra Jira-Connector finden Sie unter Amazon Kendra Jira-Konnektor Abschnitt des Amazon Kendra-Entwicklerhandbuchs.
Weitere Informationen zu anderen integrierten Konnektoren von Amazon Kendra zu beliebten Datenquellen finden Sie unter Enträtseln Sie das Wissen in Slack-Workspaces mit intelligenter Suche mit dem Amazon Kendra Slack-Konnektor und Suchen Sie mithilfe der intelligenten Suche mit dem Quip-Konnektor für Amazon Kendra nach Wissen in Quip-Dokumenten.
Über die Autoren
 Shreyas Subramanian ist ein auf KI/ML spezialisierter Lösungsarchitekt und hilft Kunden durch den Einsatz von maschinellem Lernen bei der Lösung ihrer geschäftlichen Herausforderungen in der AWS Cloud.
Shreyas Subramanian ist ein auf KI/ML spezialisierter Lösungsarchitekt und hilft Kunden durch den Einsatz von maschinellem Lernen bei der Lösung ihrer geschäftlichen Herausforderungen in der AWS Cloud.
 Abhinav Jawadekar ist Principal Solutions Architect mit Fokus auf Amazon Kendra im AI/ML-Sprachdienstteam bei AWS. Abhinav arbeitet mit AWS-Kunden und -Partnern zusammen, um ihnen beim Aufbau intelligenter Suchlösungen auf AWS zu helfen.
Abhinav Jawadekar ist Principal Solutions Architect mit Fokus auf Amazon Kendra im AI/ML-Sprachdienstteam bei AWS. Abhinav arbeitet mit AWS-Kunden und -Partnern zusammen, um ihnen beim Aufbau intelligenter Suchlösungen auf AWS zu helfen.
- Coinsmart. Europas beste Bitcoin- und Krypto-Börse.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. DEN FREIEN ZUGANG.
- CryptoHawk. Altcoin-Radar. Kostenlose Testphase.
- Quelle: https://aws.amazon.com/blogs/machine-learning/intelligently-search-your-jira-projects-with-amazon-kendra-jira-cloud-connector/
- "
- 100
- 420
- Über uns
- Zugang
- entsprechend
- Konto
- über
- Adresse
- Administrator
- Verwaltung
- agil
- Amazon
- Ein anderer
- beantworten
- Bienen
- angemessen
- Partnerschaftsräte
- Attribute
- verfügbar
- AWS
- Sein
- Tafel
- Grenze
- Box
- bauen
- eingebaut
- Geschäft
- Captures
- Karten
- tragen
- Herausforderungen
- herausfordernd
- Übernehmen
- Auswählen
- Schließung
- Cloud
- zusammenarbeiten
- Bemerkungen
- community
- Konfiguration
- Konsul (Console)
- Inhalt
- Inhalt
- beitragen
- Smartgeräte App
- Kosten
- erstellen
- erstellt
- schafft
- Erstellen
- Kunden
- technische Daten
- zeigen
- Details
- Entwickler:in / Unternehmen
- Entwickler
- Entwicklung
- anders
- Unterlagen
- Domain
- im
- leicht
- ermöglichen
- Ingenieure
- Enter
- sich entwickelnden
- Beispiel
- vorhandenen
- ERFAHRUNGEN
- Felder
- Filterung
- Filter
- Vorname
- konzentriert
- Folgende
- unten stehende Formular
- Zukunft
- GitHub
- Hilfe
- hilft
- Ultraschall
- Hilfe
- aber
- HTTPS
- Identitätsschutz
- Implementierung
- Einschließlich
- Index
- Information
- Intelligent
- Problem
- Probleme
- IT
- Wissen
- Sprache
- LERNEN
- lernen
- Bibliothek
- Links
- Liste
- Maschine
- Maschinelles Lernen
- gemacht
- Making
- Management
- Manager
- Manager
- Mitglied
- Mitglieder
- ML
- mehr
- mehrere
- Namen
- Navigation
- XNUMXh geöffnet
- Eröffnung
- Einkauf & Prozesse
- Option
- Optionen
- Organisation
- organisatorisch
- Andere
- besitzen
- Besitzer
- Teil
- Plattformen
- Politik durchzulesen
- Beliebt
- Gegenwart
- Principal
- Prozessdefinierung
- Projekt
- Projektmanagement
- Projekte
- die
- bietet
- Öffentlichkeit
- relevant
- Downloads
- Die Ergebnisse
- Rückkehr
- Führen Sie
- Sdk
- Suche
- sicher
- Sicherheitdienst
- Sicherheitstoken
- Leistungen
- kompensieren
- gezeigt
- locker
- Software
- Software-Entwicklung
- solide
- Lösung
- Lösungen
- LÖSEN
- Spezialist
- Anfang
- Status
- speichern
- erfolgreich
- Team
- vorübergehend
- Test
- Testen
- während
- Zeichen
- Tokens
- verfolgen sind
- traditionell
- -
- Nutzer
- überprüfen
- Anzeigen
- Was
- während
- arbeiten,
- Werk