Amazon SageMaker-Autopilot ist eine Lösung für automatisiertes maschinelles Lernen (AutoML), die alle Aufgaben ausführt, die Sie für einen durchgängigen Workflow für maschinelles Lernen (ML) benötigen. Es untersucht und bereitet Ihre Daten auf, wendet verschiedene Algorithmen an, um ein Modell zu generieren, und stellt transparent Modelleinblicke und Erklärbarkeitsberichte bereit, um Ihnen bei der Interpretation der Ergebnisse zu helfen. Autopilot kann auch einen Echtzeit-Endpunkt für Online-Inferenz erstellen. Sie können auf die Ein-Klick-Funktionen von Autopilot in zugreifen Amazon SageMaker-Studio oder mit dem AWS SDK für Python (Boto3) oder das SageMaker Python SDK.
In diesem Beitrag zeigen wir, wie Sie mithilfe eines von Autopilot trainierten Modells Batchvorhersagen für ein unbeschriftetes Dataset erstellen. Wir verwenden einen synthetisch generierten Datensatz, der auf die Arten von Merkmalen hinweist, die Sie normalerweise bei der Vorhersage der Kundenabwanderung sehen.
Lösungsüberblick
Stapel Schlussfolgerung bzw Offline-Bereich. Inferenz ist der Prozess der Erstellung von Vorhersagen für eine Reihe von Beobachtungen. Bei der Batch-Inferenz wird davon ausgegangen, dass Sie keine sofortige Antwort auf eine Modellvorhersageanforderung benötigen, wie dies bei der Verwendung eines Online-Echtzeit-Modellendpunkts der Fall wäre. Offlinevorhersagen eignen sich für größere Datasets und in Fällen, in denen Sie es sich leisten können, mehrere Minuten oder Stunden auf eine Antwort zu warten. Im Gegensatz, Online Inferenz generiert ML-Vorhersagen in Echtzeit und wird treffend als bezeichnet Echtzeit Schlussfolgerung bzw dynamisch Inferenz. Typischerweise werden diese Vorhersagen anhand einer einzelnen Beobachtung von Daten zur Laufzeit generiert.
Der Verlust von Kunden ist für jedes Unternehmen kostspielig. Wenn Sie unzufriedene Kunden frühzeitig erkennen, haben Sie die Möglichkeit, ihnen Anreize zum Bleiben zu bieten. Mobilfunkbetreiber verfügen über historische Kundendaten, die diejenigen zeigen, die abgewandert sind und diejenigen, die den Service aufrechterhalten haben. Wir können diese historischen Informationen verwenden, um ein Modell zu erstellen, um vorherzusagen, ob ein Kunde mit ML abwandern wird.
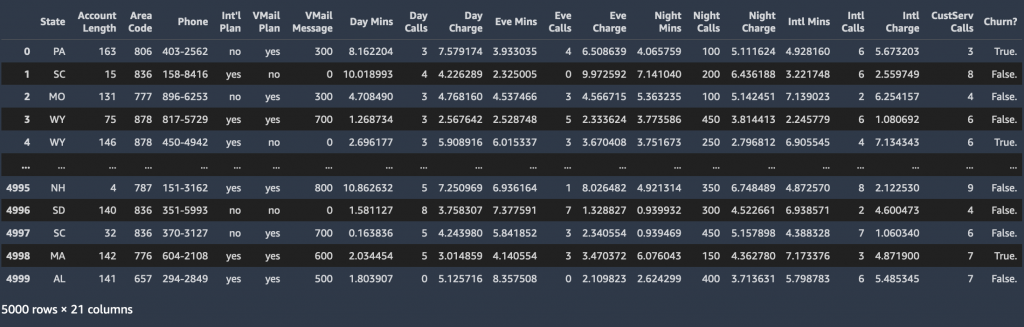
Nachdem wir ein ML-Modell trainiert haben, können wir die Profilinformationen eines beliebigen Kunden (die gleichen Profilinformationen, die wir für das Training verwendet haben) an das Modell übergeben und das Modell vorhersagen lassen, ob der Kunde abwandern wird oder nicht. Der für diesen Beitrag verwendete Datensatz wird im Ordner sagemaker-sample-files in einem gehostet Amazon Simple Storage-Service (Amazon S3) öffentlicher Bucket, den Sie herunterladen können. Es besteht aus 5,000 Datensätzen, wobei jeder Datensatz 21 Attribute verwendet, um das Profil eines Kunden eines unbekannten US-Mobilfunkanbieters zu beschreiben. Die Attribute lauten wie folgt:
- Bundesstaat – US-Bundesstaat, in dem der Kunde ansässig ist, gekennzeichnet durch eine aus zwei Buchstaben bestehende Abkürzung; B. TX oder CA
- Kontolänge – Anzahl der Tage, die dieses Konto aktiv war
- Vorwahl – Dreistellige Vorwahl der entsprechenden Kundenrufnummer
- Telefon – Verbleibende siebenstellige Telefonnummer
- Internationaler Plan – Hat einen internationalen Anrufplan: Ja/Nein
- VMail-Plan – Hat eine Voicemail-Funktion: Ja/Nein
- VMail-Nachricht – Durchschnittliche Anzahl von Voicemail-Nachrichten pro Monat
- Tag Min – Gesamtzahl der während des Tages genutzten Gesprächsminuten
- Tagesanrufe – Gesamtzahl der während des Tages getätigten Anrufe
- Tagesgebühr – In Rechnung gestellte Kosten für Tagesanrufe
- Eve Mins, Eve Calls, Eve Charge – In Rechnung gestellte Kosten für Anrufe, die am Abend getätigt werden
- Nachtmin., Nachtanrufe, Nachtgebühr – In Rechnung gestellte Kosten für Anrufe, die während der Nacht getätigt werden
- Intl. Min., Intl. Anrufe, Intl. Gebühren – In Rechnung gestellte Kosten für Auslandsgespräche
- CustServ-Anrufe – Anzahl der beim Kundendienst getätigten Anrufe
- Abwanderung? – Kunde hat den Service verlassen: True/False
Das letzte Attribut, Churn?, ist das Zielattribut, das das ML-Modell vorhersagen soll. Da das Zielattribut binär ist, führt unser Modell eine binäre Vorhersage durch, auch bekannt als binäre Klassifikation.
Voraussetzungen:
Laden Sie das Dataset in Ihre lokale Entwicklungsumgebung herunter und erkunden Sie es, indem Sie den folgenden S3-Kopierbefehl mit dem ausführen AWS-Befehlszeilenschnittstelle (AWS-CLI):
Anschließend können Sie den Datensatz in einen S3-Bucket innerhalb Ihres eigenen AWS-Kontos kopieren. Dies ist der Eingabeort für Autopilot. Sie können das Dataset in Amazon S3 kopieren, indem Sie es entweder manuell in Ihren Bucket hochladen oder den folgenden Befehl über die AWS CLI ausführen:
Erstellen Sie ein Autopilot-Experiment
Wenn das Dataset fertig ist, können Sie ein Autopilot-Experiment in SageMaker Studio initialisieren. Vollständige Anweisungen finden Sie unter Erstellen Sie ein Amazon SageMaker Autopilot-Experiment.
Der Grundeinstellungen, können Sie ganz einfach ein Autopilot-Experiment erstellen, indem Sie einen Experimentnamen, die Dateneingabe- und -ausgabeorte und die vorherzusagenden Zieldaten angeben. Optional können Sie den Typ des ML-Problems angeben, das Sie lösen möchten. Verwenden Sie andernfalls die Auto Einstellung und Autopilot bestimmt automatisch das Modell basierend auf den von Ihnen bereitgestellten Daten.

Sie können auch ein Autopilot-Experiment mit Code ausführen, indem Sie entweder das AWS SDK for Python (Boto3) oder das SageMaker Python SDK verwenden. Das folgende Code-Snippet zeigt, wie ein Autopilot-Experiment mit dem SageMaker Python SDK initialisiert wird. Wir nehmen das AutoML-Klasse aus dem SageMaker Python SDK.
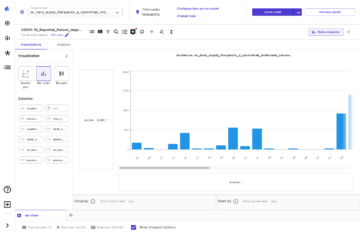
Nachdem Autopilot ein Experiment gestartet hat, überprüft der Dienst automatisch die rohen Eingabedaten, wendet Feature-Prozessoren an und wählt den besten Satz von Algorithmen aus. Nachdem ein Algorithmus ausgewählt wurde, optimiert Autopilot seine Leistung mithilfe eines Hyperparameter-Optimierungs-Suchprozesses. Dies wird oft als Training und Tuning des Modells bezeichnet. Dies trägt letztendlich dazu bei, ein Modell zu erstellen, das genaue Vorhersagen für Daten treffen kann, die es noch nie gesehen hat. Autopilot verfolgt automatisch die Modellleistung und ordnet dann die endgültigen Modelle basierend auf Metriken, die die Genauigkeit und Präzision eines Modells beschreiben.

Sie haben auch die Möglichkeit, jedes der Ranglistenmodelle einzusetzen, indem Sie entweder das Modell auswählen (Rechtsklick) und auswählen Modell bereitstellen, oder indem Sie das Modell in der Rangliste auswählen und auswählen Modell bereitstellen.
Erstellen Sie Stapelvorhersagen mithilfe eines Modells von Autopilot
Wenn Ihr Autopilot-Experiment abgeschlossen ist, können Sie das trainierte Modell verwenden, um Batchvorhersagen für Ihr Test- oder Holdout-Dataset zur Auswertung auszuführen. Sie können dann die vorhergesagten Beschriftungen mit den erwarteten Beschriftungen vergleichen, wenn Ihr Test- oder Holdout-Dataset vorbeschriftet ist. Dies ist im Wesentlichen eine Möglichkeit, die Vorhersagen eines Modells mit der Wahrheit zu vergleichen. Wenn mehr Vorhersagen des Modells mit den wahren Bezeichnungen übereinstimmen, können wir das Modell im Allgemeinen als gut leistungsfähig kategorisieren. Sie können auch Batchvorhersagen ausführen, um Daten ohne Label zu kennzeichnen. Sie können dasselbe mit dem High-Level-SageMaker-Python-SDK mit ein paar Zeilen Code erreichen.
Beschreiben Sie ein zuvor ausgeführtes Autopilot-Experiment
Wir müssen zuerst die Informationen aus einem zuvor abgeschlossenen Autopilot-Experiment extrahieren. Wir können die AutoML-Klasse aus dem SageMaker Python SDK verwenden, um ein automl-Objekt zu erstellen, das die Informationen eines vorherigen Autopilot-Experiments kapselt. Sie können den Experimentnamen verwenden, den Sie beim Initialisieren des Autopilot-Experiments definiert haben. Siehe folgenden Code:
Mit dem automl-Objekt können wir das am besten trainierte Modell einfach beschreiben und neu erstellen, wie in den folgenden Ausschnitten gezeigt:
In einigen Fällen möchten Sie vielleicht ein anderes Modell als das beste Modell laut Autopilot verwenden. Um ein solches Kandidatenmodell zu finden, können Sie das automl-Objekt verwenden und die Liste aller oder der Top-N-Modellkandidaten durchlaufen und das Modell auswählen, das Sie neu erstellen möchten. Für diesen Beitrag verwenden wir eine einfache Python-For-Schleife, um eine Liste von Modellkandidaten zu durchlaufen:
Passen Sie die Inferenzantwort an
Wenn wir entweder das beste oder ein anderes von Autopilot trainiertes Modell neu erstellen, können wir die Inferenzantwort für das Modell anpassen, indem wir den zusätzlichen Parameter hinzufügen inference_response_keys, wie im vorherigen Beispiel gezeigt. Sie können diesen Parameter sowohl für binäre als auch für mehrklassige Klassifizierungsproblemtypen verwenden:
- vorhergesagtes_label – Die vorhergesagte Klasse.
- Wahrscheinlichkeit – Bei der binären Klassifizierung die Wahrscheinlichkeit, dass das Ergebnis als zweite oder wahre Klasse in der Zielspalte vorhergesagt wird. Bei der Mehrklassenklassifizierung die Wahrscheinlichkeit der Gewinnerklasse.
- Etiketten – Eine Liste aller möglichen Klassen.
- Wahrscheinlichkeiten – Eine Liste aller Wahrscheinlichkeiten für alle Klassen (Reihenfolge entspricht Labels).
Da das Problem, das wir in diesem Beitrag angehen, die binäre Klassifizierung ist, setzen wir diesen Parameter wie folgt in den vorangegangenen Snippets, während wir die Modelle erstellen:
Transformer erstellen und Batchvorhersagen ausführen
Nachdem wir die Kandidatenmodelle neu erstellt haben, können wir schließlich einen Transformer erstellen, um den Stapelvorhersagejob zu starten, wie in den folgenden beiden Codeausschnitten gezeigt. Beim Erstellen des Transformators definieren wir die Spezifikationen des Clusters zum Ausführen des Batch-Jobs, z. B. Anzahl und Typ der Instanzen. Die Batch-Eingabe und -Ausgabe sind die Amazon S3-Speicherorte, an denen unsere Dateneingaben und -ausgaben gespeichert werden. Der Stapelvorhersagejob wird bereitgestellt von SageMaker-Batch-Transformation.
Wenn der Auftrag abgeschlossen ist, können wir die Stapelausgabe lesen und Auswertungen und andere nachgelagerte Aktionen durchführen.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie Sie mithilfe von Autopilot-trainierten Modellen schnell und einfach Batchvorhersagen für Ihre Auswertungen nach dem Training treffen können. Wir haben SageMaker Studio verwendet, um ein Autopilot-Experiment zu initialisieren, um ein Modell zur Vorhersage der Kundenabwanderung zu erstellen. Dann haben wir auf das beste Modell von Autopilot verwiesen, um Batchvorhersagen mithilfe der automl-Klasse mit dem SageMaker-Python-SDK auszuführen. Wir haben das SDK auch verwendet, um Batchvorhersagen mit anderen Modellkandidaten durchzuführen. Mit Autopilot haben wir unsere Daten automatisch untersucht und vorverarbeitet, dann mit einem Klick mehrere ML-Modelle erstellt und SageMaker die Verwaltung der Infrastruktur überlassen, die zum Trainieren und Optimieren unserer Modelle erforderlich ist. Schließlich haben wir die Stapeltransformation verwendet, um Vorhersagen mit unserem Modell mit minimalem Code zu treffen.
Weitere Informationen zum Autopiloten und seinen erweiterten Funktionen finden Sie unter Automatisieren Sie die Modellentwicklung mit Amazon SageMaker Autopilot. Für eine detaillierte exemplarische Vorgehensweise des Beispiels im Beitrag werfen Sie einen Blick auf das Folgende Beispiel Notizbuch.
Über die Autoren
 Arunprasath Shankar ist ein auf AWS spezialisierter Lösungsarchitekt für künstliche Intelligenz und maschinelles Lernen (AI / ML), der globalen Kunden hilft, ihre KI-Lösungen effektiv und effizient in der Cloud zu skalieren. In seiner Freizeit sieht Arun gerne Science-Fiction-Filme und hört klassische Musik.
Arunprasath Shankar ist ein auf AWS spezialisierter Lösungsarchitekt für künstliche Intelligenz und maschinelles Lernen (AI / ML), der globalen Kunden hilft, ihre KI-Lösungen effektiv und effizient in der Cloud zu skalieren. In seiner Freizeit sieht Arun gerne Science-Fiction-Filme und hört klassische Musik.
 Peter Chung ist Solutions Architect für AWS und hilft Kunden mit Leidenschaft dabei, Erkenntnisse aus ihren Daten zu gewinnen. Er hat Lösungen entwickelt, die Unternehmen dabei helfen, datengesteuerte Entscheidungen sowohl im öffentlichen als auch im privaten Sektor zu treffen. Er besitzt alle AWS-Zertifizierungen sowie zwei GCP-Zertifizierungen. Er genießt Kaffee, kocht, bleibt aktiv und verbringt Zeit mit seiner Familie.
Peter Chung ist Solutions Architect für AWS und hilft Kunden mit Leidenschaft dabei, Erkenntnisse aus ihren Daten zu gewinnen. Er hat Lösungen entwickelt, die Unternehmen dabei helfen, datengesteuerte Entscheidungen sowohl im öffentlichen als auch im privaten Sektor zu treffen. Er besitzt alle AWS-Zertifizierungen sowie zwei GCP-Zertifizierungen. Er genießt Kaffee, kocht, bleibt aktiv und verbringt Zeit mit seiner Familie.
- "
- 000
- 100
- Über uns
- Zugang
- Konto
- Aktionen
- aktiv
- advanced
- AI
- Algorithmus
- Algorithmen
- Alle
- Amazon
- Bereich
- künstlich
- künstliche Intelligenz
- Künstliche Intelligenz und maschinelles Lernen
- Automatisiert
- durchschnittlich
- AWS
- BESTE
- Grenze
- Building
- Geschäft
- österreichische Unternehmen
- Fälle
- Einstufung
- Cloud
- Code
- Kaffee
- Kolonne
- Erstellen
- Kunden
- technische Daten
- einsetzen
- Entwicklung
- anders
- Früh
- leicht
- Endpunkt
- Arbeitsumfeld
- Beispiel
- Ausführung
- erwartet
- Experiment
- Familie
- Merkmal
- Eigenschaften
- Vorname
- Folgende
- voller
- erzeugen
- Global
- Hilfe
- hilft
- historisch
- hält
- Ultraschall
- Hilfe
- HTTPS
- unmittelbar
- Information
- Infrastruktur
- Einblicke
- Intelligenz
- International
- IT
- Job
- Jobs
- bekannt
- Etiketten
- größer
- lernen
- Line
- Liste
- Hören
- aus einer regionalen
- Standorte
- Standorte
- Maschine
- Maschinelles Lernen
- flächendeckende Gesundheitsprogramme
- manuell
- Spiel
- Metrik
- ML
- Mobil
- Modell
- für
- Filme
- Musik
- Anzahl
- bieten
- Online
- Optimierung
- Option
- Auftrag
- Organisationen
- Andere
- Andernfalls
- Leistung
- möglich
- Prognose
- Prognosen
- privat
- Aufgabenstellung:
- Prozessdefinierung
- produziert
- Profil
- die
- bietet
- Öffentlichkeit
- schnell
- Roh
- Echtzeit
- Rekord
- Aufzeichnungen
- Meldungen
- Antwort
- Die Ergebnisse
- Führen Sie
- Laufen
- Skalieren
- Sdk
- Suche
- Sektoren
- kompensieren
- Einstellung
- Einfacher
- Lösungen
- LÖSEN
- Ausgabe
- Anfang
- Bundesstaat
- bleiben
- Lagerung
- Studio Adressen
- Target
- und Aufgaben
- Test
- Durch
- Zeit
- Top
- Ausbildung
- Transformieren
- TX
- aufdecken
- us
- -
- Stimme
- warten
- ob
- WHO
- .