Diese dreiteilige Serie demonstriert die Verwendung von Graph Neural Networks (GNNs) und Amazon Neptun um Filmempfehlungen mit dem zu generieren IMDb und Box Office Mojo Movies/TV/OTT lizenzierbares Datenpaket, das eine breite Palette von Unterhaltungsmetadaten bereitstellt, darunter über 1 Milliarde Benutzerbewertungen; Credits für mehr als 11 Millionen Besetzungs- und Crewmitglieder; 9 Millionen Film-, Fernseh- und Unterhaltungstitel; und globale Kassenberichtsdaten aus mehr als 60 Ländern. Viele AWS-Kunden aus den Bereichen Medien und Unterhaltung lizenzieren IMDb-Daten durch AWS-Datenaustausch um das Auffinden von Inhalten zu verbessern und die Kundenbindung und -bindung zu erhöhen.
In Teil 1, diskutierten wir die Anwendungen von GNNs und wie wir unsere IMDb-Daten für Abfragen transformieren und vorbereiten. In diesem Beitrag diskutieren wir den Prozess der Verwendung von Neptune zum Generieren von Einbettungen, die für die Durchführung unserer Suche außerhalb des Katalogs in Teil 3 verwendet werden. Wir gehen auch vorbei Amazon Neptun ML, die Funktion für maschinelles Lernen (ML) von Neptune und der Code, den wir in unserem Entwicklungsprozess verwenden. In Teil 3 gehen wir durch die Anwendung unserer Knowledge Graph-Einbettungen auf einen Anwendungsfall für die Suche außerhalb des Katalogs.
Lösungsüberblick
Große verbundene Datensätze enthalten oft wertvolle Informationen, die mit Abfragen, die allein auf menschlicher Intuition basieren, nur schwer zu extrahieren sind. ML-Techniken können helfen, versteckte Korrelationen in Diagrammen mit Milliarden von Beziehungen zu finden. Diese Korrelationen können hilfreich sein, um Produkte zu empfehlen, die Kreditwürdigkeit vorherzusagen, Betrug zu erkennen und viele andere Anwendungsfälle.
Neptune ML ermöglicht das Erstellen und Trainieren nützlicher ML-Modelle auf großen Graphen in Stunden statt Wochen. Um dies zu erreichen, verwendet Neptune ML die GNN-Technologie powered by Amazon Sage Maker und für Deep-Graph-Bibliothek (DGL) (welches ist Open-Source). GNNs sind ein aufstrebendes Feld der künstlichen Intelligenz (siehe z Eine umfassende Umfrage zu Graph Neural Networks). Ein praktisches Tutorial zur Verwendung von GNNs mit der DGL finden Sie unter Neurale Netze von Graphen lernen mit der Deep Graph Library.
In diesem Beitrag zeigen wir, wie Sie Neptune in unserer Pipeline verwenden, um Einbettungen zu generieren.
Das folgende Diagramm zeigt den Gesamtfluss der IMDb-Daten vom Download bis zur Generierung der Einbettung.
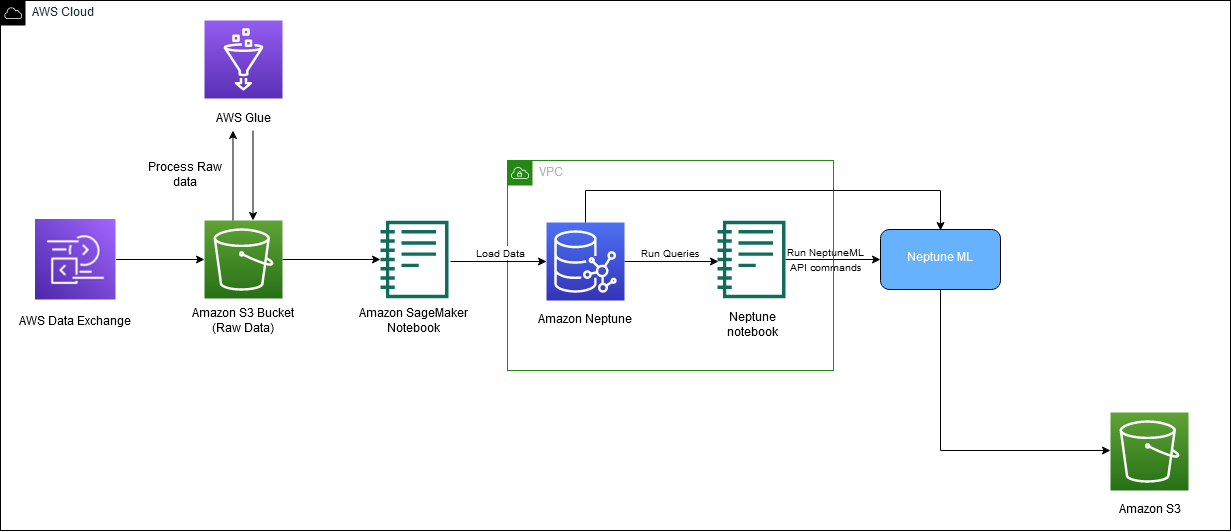
Wir verwenden die folgenden AWS-Dienste, um die Lösung zu implementieren:
In diesem Beitrag führen wir Sie durch die folgenden allgemeinen Schritte:
- Umgebungsvariablen einrichten
- Erstellen Sie einen Exportauftrag.
- Erstellen Sie einen Datenverarbeitungsauftrag.
- Ausbildungsauftrag abgeben.
- Einbettungen herunterladen.
Code für Neptune ML-Befehle
Wir verwenden die folgenden Befehle im Rahmen der Implementierung dieser Lösung:
Wir verwenden neptune_ml export um den Status zu überprüfen oder einen Neptune ML-Exportprozess zu starten, und neptune_ml training zum Starten und Überprüfen des Status eines Neptune ML-Modelltrainingsjobs.
Weitere Informationen zu diesen und anderen Befehlen finden Sie unter Verwenden Sie die Neptun-Workbench-Magie in Ihren Notizbüchern.
Voraussetzungen:
Um diesem Beitrag zu folgen, sollten Sie Folgendes haben:
- An AWS-Konto
- Vertrautheit mit SageMaker, Amazon S3 und AWS CloudFormation
- In den Neptun-Cluster geladene Diagrammdaten (siehe Teil 1 für mehr Informationen)
Umgebungsvariablen einrichten
Bevor wir beginnen, müssen Sie Ihre Umgebung einrichten, indem Sie die folgenden Variablen festlegen: s3_bucket_uri und processed_folder. s3_bucket_uri ist der Name des in Teil 1 verwendeten Buckets und processed_folder ist der Amazon S3-Speicherort für die Ausgabe des Exportauftrags.
Erstellen Sie einen Exportauftrag
In Teil 1 haben wir ein SageMaker-Notebook und einen Exportdienst erstellt, um unsere Daten aus dem Neptune DB-Cluster im erforderlichen Format nach Amazon S3 zu exportieren.
Nachdem unsere Daten geladen und der Exportdienst erstellt wurde, müssen wir einen Exportjob erstellen und ihn starten. Dazu verwenden wir NeptuneExportApiUri und Parameter für den Exportauftrag anlegen. Im folgenden Code verwenden wir die Variablen expo und export_params. einstellen expo auf Ihre NeptuneExportApiUri Wert, den Sie auf der finden Ausgänge Registerkarte Ihres CloudFormation-Stacks. Für export_paramsverwenden wir den Endpunkt Ihres Neptune-Clusters und stellen den Wert für bereit outputS3path, das ist der Amazon S3-Speicherort für die Ausgabe des Exportauftrags.
Verwenden Sie den folgenden Befehl, um den Exportauftrag zu senden:
Verwenden Sie den folgenden Befehl, um den Status des Exportauftrags zu überprüfen:
Nachdem Ihr Auftrag abgeschlossen ist, stellen Sie die processed_folder Variable, um den Amazon S3-Speicherort der verarbeiteten Ergebnisse bereitzustellen:
Erstellen Sie einen Datenverarbeitungsauftrag
Nachdem der Export nun abgeschlossen ist, erstellen wir einen Datenverarbeitungsjob, um die Daten für den Neptune ML-Trainingsprozess vorzubereiten. Dies kann auf verschiedene Arten erfolgen. Für diesen Schritt können Sie die ändern job_name und modelType Variablen, aber alle anderen Parameter müssen gleich bleiben. Der Hauptteil dieses Codes ist die modelType Parameter, die entweder heterogene Graphenmodelle sein können (heterogeneous) oder Wissensgraphen (kge).
Der Exportauftrag beinhaltet auch training-data-configuration.json. Verwenden Sie diese Datei, um Knoten oder Kanten hinzuzufügen oder zu entfernen, die Sie nicht für das Training bereitstellen möchten (wenn Sie beispielsweise die Verknüpfung zwischen zwei Knoten vorhersagen möchten, können Sie diese Verknüpfung in dieser Konfigurationsdatei entfernen). Für diesen Blogbeitrag verwenden wir die ursprüngliche Konfigurationsdatei. Weitere Informationen finden Sie unter Bearbeiten einer Trainingskonfigurationsdatei.
Erstellen Sie Ihren Datenverarbeitungsauftrag mit folgendem Code:
Verwenden Sie den folgenden Befehl, um den Status des Exportauftrags zu überprüfen:
Ausbildungsauftrag abgeben
Nachdem der Verarbeitungsjob abgeschlossen ist, können wir mit unserem Trainingsjob beginnen, in dem wir unsere Einbettungen erstellen. Wir empfehlen einen Instance-Typ von ml.m5.24xlarge, aber Sie können diesen an Ihre Rechenanforderungen anpassen. Siehe folgenden Code:
Wir geben die Variable training_results aus, um die ID für den Trainingsjob zu erhalten. Verwenden Sie den folgenden Befehl, um den Status Ihres Jobs zu überprüfen:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Einbettungen herunterladen
Nachdem Ihr Trainingsjob abgeschlossen ist, besteht der letzte Schritt darin, Ihre Roheinbettungen herunterzuladen. Die folgenden Schritte zeigen Ihnen, wie Sie Einbettungen herunterladen, die mit KGE erstellt wurden (Sie können den gleichen Prozess für RGCN verwenden).
Im folgenden Code verwenden wir neptune_ml.get_mapping() und get_embeddings() um die Zuordnungsdatei herunterzuladen (mapping.info) und die rohe Einbettungsdatei (entity.npy). Dann müssen wir die entsprechenden Einbettungen den entsprechenden IDs zuordnen.
Um RGCNs herunterzuladen, folgen Sie dem gleichen Prozess mit einem neuen Trainingsauftragsnamen, indem Sie die Daten verarbeiten, wobei der modelType-Parameter auf eingestellt ist heterogeneous, und trainieren Sie dann Ihr Modell mit dem auf modelName gesetzten Parameter rgcn sehen hier für mehr Details. Wenn das erledigt ist, rufen Sie die an get_mapping und get_embeddings Funktionen zum Herunterladen Ihrer neuen Mapping.info und Entity.npy Dateien. Nachdem Sie die Entitäts- und Zuordnungsdateien haben, ist der Prozess zum Erstellen der CSV-Datei identisch.
Laden Sie schließlich Ihre Einbettungen an den gewünschten Amazon S3-Speicherort hoch:
Denken Sie daran, sich diesen S3-Speicherort zu merken, Sie müssen ihn in Teil 3 verwenden.
Aufräumen
Wenn Sie mit der Verwendung der Lösung fertig sind, stellen Sie sicher, dass Sie alle Ressourcen bereinigen, um laufende Gebühren zu vermeiden.
Zusammenfassung
In diesem Beitrag haben wir besprochen, wie man Neptune ML verwendet, um GNN-Einbettungen aus IMDb-Daten zu trainieren.
Einige verwandte Anwendungen der Einbettung von Wissensgraphen sind Konzepte wie Suche außerhalb des Katalogs, Inhaltsempfehlungen, gezielte Werbung, Vorhersage fehlender Links, allgemeine Suche und Kohortenanalyse. Die Suche außerhalb des Katalogs ist der Prozess der Suche nach Inhalten, die Sie nicht besitzen, und das Finden oder Empfehlen von Inhalten in Ihrem Katalog, die dem, was der Benutzer gesucht hat, so ähnlich wie möglich sind. In Teil 3 tauchen wir tiefer in die Suche außerhalb des Katalogs ein.
Über die Autoren
 Matthäus Rhodos ist Data Scientist und arbeite im Amazon ML Solutions Lab. Er ist spezialisiert auf den Aufbau von Pipelines für maschinelles Lernen, die Konzepte wie Natural Language Processing und Computer Vision beinhalten.
Matthäus Rhodos ist Data Scientist und arbeite im Amazon ML Solutions Lab. Er ist spezialisiert auf den Aufbau von Pipelines für maschinelles Lernen, die Konzepte wie Natural Language Processing und Computer Vision beinhalten.
 Divya Bhargavi ist Data Scientist und Media and Entertainment Vertical Lead im Amazon ML Solutions Lab, wo sie hochwertige Geschäftsprobleme für AWS-Kunden mithilfe von maschinellem Lernen löst. Sie arbeitet an Bild-/Videoverständnis, Empfehlungssystemen für Wissensgraphen und prädiktiven Werbeanwendungsfällen.
Divya Bhargavi ist Data Scientist und Media and Entertainment Vertical Lead im Amazon ML Solutions Lab, wo sie hochwertige Geschäftsprobleme für AWS-Kunden mithilfe von maschinellem Lernen löst. Sie arbeitet an Bild-/Videoverständnis, Empfehlungssystemen für Wissensgraphen und prädiktiven Werbeanwendungsfällen.
 Gaurav Rele ist Data Scientist am Amazon ML Solution Lab, wo er mit AWS-Kunden in verschiedenen Branchen zusammenarbeitet, um die Nutzung von maschinellem Lernen und AWS Cloud-Diensten zur Lösung ihrer geschäftlichen Herausforderungen zu beschleunigen.
Gaurav Rele ist Data Scientist am Amazon ML Solution Lab, wo er mit AWS-Kunden in verschiedenen Branchen zusammenarbeitet, um die Nutzung von maschinellem Lernen und AWS Cloud-Diensten zur Lösung ihrer geschäftlichen Herausforderungen zu beschleunigen.
 Karan Sindwani ist Data Scientist im Amazon ML Solutions Lab, wo er Deep-Learning-Modelle erstellt und bereitstellt. Er hat sich auf den Bereich Computer Vision spezialisiert. In seiner Freizeit wandert er gerne.
Karan Sindwani ist Data Scientist im Amazon ML Solutions Lab, wo er Deep-Learning-Modelle erstellt und bereitstellt. Er hat sich auf den Bereich Computer Vision spezialisiert. In seiner Freizeit wandert er gerne.
 Soji Adeshina ist ein angewandter Wissenschaftler bei AWS, wo er auf Graphen basierende Modelle für neuronale Netzwerke für maschinelles Lernen bei Graphenaufgaben mit Anwendungen für Betrug und Missbrauch, Wissensgraphen, Empfehlungssysteme und Biowissenschaften entwickelt. In seiner Freizeit liest und kocht er gerne.
Soji Adeshina ist ein angewandter Wissenschaftler bei AWS, wo er auf Graphen basierende Modelle für neuronale Netzwerke für maschinelles Lernen bei Graphenaufgaben mit Anwendungen für Betrug und Missbrauch, Wissensgraphen, Empfehlungssysteme und Biowissenschaften entwickelt. In seiner Freizeit liest und kocht er gerne.
 Vidya Sagar Ravipati ist Manager im Amazon ML Solutions Lab, wo er seine umfangreiche Erfahrung mit großen verteilten Systemen und seine Leidenschaft für maschinelles Lernen einsetzt, um AWS-Kunden in verschiedenen Branchen dabei zu helfen, ihre KI- und Cloud-Einführung zu beschleunigen.
Vidya Sagar Ravipati ist Manager im Amazon ML Solutions Lab, wo er seine umfangreiche Erfahrung mit großen verteilten Systemen und seine Leidenschaft für maschinelles Lernen einsetzt, um AWS-Kunden in verschiedenen Branchen dabei zu helfen, ihre KI- und Cloud-Einführung zu beschleunigen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Über uns
- Missbrauch
- beschleunigen
- über
- Zusätzliche
- Zusätzliche Angaben
- Adoption
- Marketings
- Nach der
- AI
- Alle
- allein
- Amazon
- Amazon ML-Lösungslabor
- Analyse
- und
- Anwendungen
- angewandt
- Jetzt bewerben
- angemessen
- Bereich
- künstlich
- künstliche Intelligenz
- AWS
- basierend
- zwischen
- Milliarde
- Milliarden
- Blog
- Box
- Abendkasse
- bauen
- Building
- baut
- Geschäft
- rufen Sie uns an!
- Häuser
- Fälle
- Katalog
- Herausforderungen
- Übernehmen
- Gebühren
- aus der Ferne überprüfen
- Menu
- Cloud
- Cloud-Einführung
- Cloud-Services
- Cluster
- Code
- Kohorte
- abschließen
- umfassend
- Computer
- Computer Vision
- Computing
- Konzepte
- Leiten
- Konfiguration
- Sie
- Inhalt
- Dazugehörigen
- Länder
- erstellen
- erstellt
- Kredit
- Credits
- Kunde
- Kundenbindung
- Kunden
- technische Daten
- Datenverarbeitung
- Datenwissenschaftler
- Datensätze
- tief
- tiefe Lernen
- tiefer
- setzt ein
- Details
- Entwicklung
- entwickelt
- DGL
- anders
- Entdeckung
- diskutieren
- diskutiert
- verteilt
- verteilte Systeme
- Nicht
- herunterladen
- entweder
- aufstrebenden
- Endpunkt
- Engagement
- Unterhaltung
- Einheit
- Arbeitsumfeld
- Äther (ETH)
- Beispiel
- ERFAHRUNGEN
- exportieren
- Extrakt
- Merkmal
- wenige
- Feld
- Reichen Sie das
- Mappen
- Finden Sie
- Suche nach
- Fluss
- folgen
- Folgende
- Format
- Betrug
- für
- voller
- Funktionen
- Allgemeines
- erzeugen
- Generation
- bekommen
- Global
- Go
- Graph
- Graphen
- praktische
- hart
- Hilfe
- hilfreich
- versteckt
- High-Level
- STUNDEN
- Ultraschall
- Hilfe
- HTML
- HTTPS
- human
- identisch
- Identifizierung
- implementieren
- Umsetzung
- zu unterstützen,
- in
- Dazu gehören
- Einschließlich
- Erhöhung
- Index
- Energiegewinnung
- Info
- Information
- Instanz
- beantragen müssen
- Intelligenz
- beteiligen
- IT
- Job
- JSON
- Wesentliche
- Wissen
- Labor
- Sprache
- grosse
- großflächig
- Nachname
- führen
- lernen
- Hebelwirkungen
- Bibliothek
- Lizenz
- Lebensdauer
- Biowissenschaften
- LINK
- Links
- Standorte
- Maschine
- Maschinelles Lernen
- Main
- MACHT
- Manager
- viele
- Karte
- Mapping
- Medien
- mittlere
- Mitglieder
- Metadaten
- Million
- Kommt demnächst...
- ML
- Modell
- für
- mehr
- Film
- Name
- Natürliche
- Verarbeitung natürlicher Sprache
- Need
- Bedürfnisse
- Neptun
- netzwerkbasiert
- Netzwerke
- Neuronale Netze
- Neu
- Fiber Node
- Notizbuch
- Office
- laufend
- Original
- Andere
- Gesamt-
- besitzen
- Paket
- Parameter
- Parameter
- Teil
- Leidenschaft & KREATIVITÄT
- Pipeline
- Plato
- Datenintelligenz von Plato
- PlatoData
- möglich
- Post
- Werkzeuge
- angetriebene
- vorhersagen
- Vorhersage
- Danach
- Probleme
- Prozessdefinierung
- Verarbeitung
- Produkte
- Profil
- die
- bietet
- Angebot
- Bewertungen
- Roh
- Lesebrillen
- empfehlen
- Software Empfehlungen
- Empfehlungen
- empfehlen
- bezogene
- Beziehungen
- bleiben
- merken
- entfernen
- Reporting
- falls angefordert
- Downloads
- Die Ergebnisse
- Beibehaltung
- sagemaker
- gleich
- WISSENSCHAFTEN
- Wissenschaftler
- Suche
- Suche
- Modellreihe
- Leistungen
- kompensieren
- Einstellung
- sollte
- erklären
- Lösung
- Lösungen
- LÖSEN
- Löst
- spezialisiert
- Stapel
- Anfang
- Status
- Schritt
- Shritte
- speichern
- abschicken
- so
- Anzug
- Umfrage
- Systeme und Techniken
- gezielt
- und Aufgaben
- Techniken
- Technologie
- Das
- Die Gegend
- ihr
- Durch
- Zeit
- Titel
- zu
- Training
- Ausbildung
- Transformieren
- was immer dies auch sein sollte.
- Lernprogramm
- tv
- Verständnis
- -
- Anwendungsfall
- Mitglied
- wertvoll
- Wert
- riesig
- Version
- Vertikalen
- Seh-
- Wege
- Wochen
- Was
- welche
- breit
- Große Auswahl
- werden wir
- arbeiten,
- Werk
- Ihr
- Zephyrnet