El reconocimiento óptico de caracteres (OCR), el método para convertir textos escritos a mano / impresos en texto codificado por máquina, siempre ha sido un área importante de investigación en visión por computadora debido a sus numerosas aplicaciones en varios dominios: los bancos usan OCR para comparar declaraciones; Los gobiernos utilizan OCR para recopilar comentarios de encuestas.

Debido a la diversidad de estilos de escritura a mano y texto impreso, los enfoques recientes de OCR incorporan aprendizajes profundos para obtener una mayor precisión. Dado que el aprendizaje profundo requiere grandes cantidades de datos para el entrenamiento de modelos, empresas como Google se adelantan a la hora de producir resultados prometedores con sus servicios de OCR.
Este artículo profundiza en los detalles de Google Vision OCR, incluido un tutorial simple en python, la gama de aplicaciones, los precios y otras alternativas.
- ¿Qué es Google Cloud Vision OCR?
- Un tutorial sencillo
- ¿Por qué OCR?
- Casos de uso de ejemplo
- Precios
- Funciones destacadas de Google Cloud Vision OCR
- Alternativas
- Problemas Comunes
¿Qué es Google Cloud Vision?

Google Cloud Vision OCR es parte de la API de Google Cloud Vision para extraer texto de imágenes. Específicamente, hay dos anotaciones para ayudar con el reconocimiento de caracteres:
- Anotación_de_texto: Extrae y genera textos codificados por máquina de cualquier imagen (por ejemplo, fotos de vistas de la calle o paisajes). Dado que inicialmente fue diseñado para ser utilizado en diferentes situaciones de iluminación, el modelo es en cierto sentido más robusto para leer palabras de diferentes estilos, pero solo en un nivel más escaso. El archivo JSON devuelto incluye las cadenas completas, así como las palabras individuales y sus correspondientes cuadros delimitadores.
- Documento_Texto_Anotación: Está especialmente diseñado para documentos de texto densamente presentados (por ejemplo, libros escaneados). Por lo tanto, si bien admite la lectura de textos más pequeños y concentrados, es menos adaptable a imágenes en estado salvaje. La información como párrafos, bloques y saltos se incluye en el archivo JSON de salida.
Buscando una solución de OCR que supere las deficiencias de Google Cloud Vision o OCR zonal? dar nanoredes™ un giro para una mayor precisión, mayor flexibilidad y tipos de documentos más amplios.
Un tutorial sencillo
La siguiente sección presenta un tutorial simple para comenzar con la API de Google Vision, particularmente sobre cómo usarla para el servicio de OCR de Google Cloud Vision.
Resumen simple
La idea detrás de esto es muy intuitiva y simple.
1) Básicamente, envía una imagen (remota o desde su almacenamiento local) a la API de Google Cloud Vision.
2) La imagen se procesa de forma remota en Google Cloud y produce los formatos JSON correspondientes con respecto a la función que llamó.
3) El archivo JSON se devuelve como resultado después de que se llama a la función.
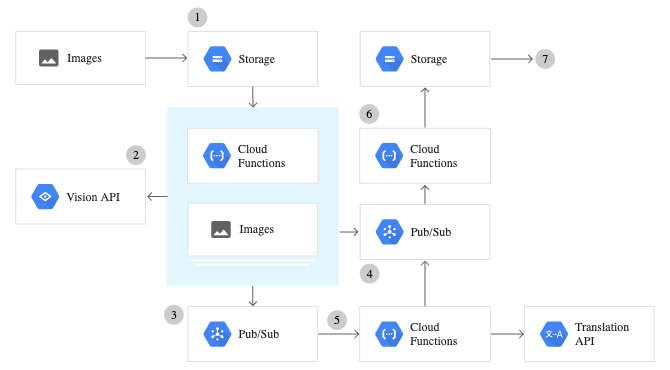
Configuración de la API de Google Cloud Vision
Para utilizar cualquier servicio proporcionado por la API de Google Vision, se debe configurar Google Cloud Console y realizar una serie de pasos para la autenticación. A continuación, se muestra una descripción general paso a paso de cómo configurar todo el servicio de la API de Vision.
- Crear un proyecto en Google Cloud Console: es necesario crear un proyecto para comenzar a usar cualquier servicio de Vision. El proyecto organiza recursos como colaboradores, API e información de precios.
- Habilitar facturación: para habilitar la API de visión, primero debe habilitar la facturación para su proyecto. Los detalles de los precios se abordarán en secciones posteriores.
- Habilitar la API de Vision
- Crear cuenta de servicio: cree una cuenta de servicio y enlace al proyecto creado, luego cree una clave de cuenta de servicio. La clave se generará y se descargará como un archivo JSON en su computadora.
- Configurar variable de entorno GOOGLE_APPLICATION_CREDENTIALS; Para configurar esta variable de entorno, ejecútelo en Mac/Linux o Windows.
- Bloques de código para Mac / Linux
- Bloques de código para Windows
Se puede encontrar un procedimiento más detallado de los pasos antes mencionados en la documentación oficial proporcionada por Google Cloud desde aquí:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Función simple de OCR de Google Vision en Python
La API de Google Cloud Vision funciona con numerosos lenguajes populares, que van desde Java, Node.js, Python hasta el propio lenguaje Go de Google. Para simplificar, presentamos un método de llamada simple en Python.
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) En otras palabras, el método llama consecuentemente a la función anotación_de_texto, luego extraiga las respuestas e imprima la información. documento_texto_anotación también se puede llamar utilizando la misma forma para recuperar textos densos. También se pueden detectar imágenes de forma remota configurando la imagen a través de:
image.source.image_uri = uridonde el uri es el uri de la imagen.
Se pueden obtener más detalles de los códigos aquí:
https://cloud.google.com/vision
¿Busca una solución de OCR que supere las deficiencias de Google Cloud Vision? Dar nanorred™ un giro para una mayor precisión, mayor flexibilidad y tipos de documentos más amplios.
Nivel de salida ofrecido
Para ayudar en un mayor análisis de datos del texto, las dos funciones de Google OCR proporcionan varios niveles de salida para que los usuarios los utilicen: para anotación_de_texto, tanto las cadenas completas (si Google las considera como una oración o frase) como las palabras individuales que contienen; por documento_texto_anotación, dado que el modelo está optimizado para texto denso, la página, el bloque, el párrafo, la palabra y el salto se ofrecen como parte de la salida.
¿Qué tan bien funciona?
¿Qué tan robustos son los modelos?
Como se mencionó anteriormente, Google ofrece dos funciones para OCR en dos situaciones diferentes. A continuación se describe la capacidad de dos funciones para recuperar diferentes tipos de datos.
Datos impresos
El tipo de datos más fácil de interpretar son los datos de texto impresos, es decir, el texto escrito por computadora, impreso y escaneado. Se requiere OCR cuando solo tenemos la copia impresa de estos datos en lugar de los textos originales codificados por máquina. Como la mayoría de estos textos son compactos y están empaquetados en páginas, documento_texto_anotación sería una mejor opción.
Datos escritos a mano
El contenido puede contener texto escrito a mano y los estilos de los datos escritos a mano pueden variar drásticamente. Sin embargo, Google Vision OCR proporciona una precisión decente siempre que las notas escritas a mano no sean demasiado desordenadas. Dependiendo de qué tan empaquetado se presente el medio de los datos escritos a mano, usamos una de las dos funciones caso por caso.
Datos rotados / in-the-wild
Cuando las imágenes o las fotos escaneadas se presentan en ángulos poco ortodoxos o no alineados, las consideramos como datos en estado salvaje. Los textos podrían ser potencialmente más difíciles de detectar en primer lugar y, por lo tanto, usualmente usamos el anotación_de_texto función que fue diseñada para procesar datos en estado salvaje en primer lugar. Basándonos en algunos experimentos de pasar a través de textos verticales y señales de tráfico capturados en diferentes ángulos, mostramos que Google Vision OCR en realidad funciona decentemente con datos de varios entornos.
¿Por qué OCR?
Muchos de los datos que tenemos hoy están en formato no estructurado. Por ejemplo, dada una imagen, un documento escaneado o una fotografía, mientras que los humanos pueden reconocer rápidamente los textos e interpretar más significados, todos los datos del texto son simplemente píxeles con colores, lo que no proporciona un significado real a las máquinas.

Cuando las empresas o grandes corporaciones están lidiando con cantidades masivas de papeleo, el gran volumen de datos haría imposible que cualquier clasificación o procesamiento de datos se hiciera con el esfuerzo exclusivamente humano; aquí es cuando el texto codificado por máquina se vuelve útil.
Después de la conversión de OCR, la información se puede analizar con varios métodos diferentes según la naturaleza de los datos:
- Para datos numéricos, los métodos estadísticos podrían aplicarse directamente para analizar cualquier correlación. También podríamos adoptar métodos tradicionales de aprendizaje automático (por ejemplo, KNN, K-Means, Regresión lineal) o enfoques de aprendizaje profundo para crear modelos predictivos para regresión y / o clasificación.
- Para los datos de texto, es posible que se requieran más etapas de procesamiento. El proceso de analizar e interpretar datos de texto en estadísticas significativas a menudo se conoce como procesamiento del lenguaje natural (NLP). Específicamente, podríamos extraer números o incluso semántica / atmósfera según el contenido dado.
Todos estos análisis podrían permitir a las empresas, especialmente a las que tienen grandes cantidades de datos nuevos todos los días, crear modelos sólidos e incluso automatizar muchos procesos y reemplazar los enfoques tradicionales que requieren mucha mano de obra y muchos errores. La siguiente sección profundiza en algunos ejemplos detallados de cómo se puede utilizar OCR.
¿Busca una solución de OCR que supere las deficiencias de Google Cloud Vision? Dar nanorred™ un giro para una mayor precisión, mayor flexibilidad y tipos de documentos más amplios.
Casos de uso de ejemplo
Lectura de matrículas

Quizás uno de los usos más habituales del OCR en la actualidad es la aplicación en la lectura de matrículas. En los países desarrollados, los estacionamientos suelen ir acompañados de modelos de lectura de matrículas para determinar la hora de entrada, la hora de salida e incluso la ubicación exacta de estacionamiento por automóvil. Algunos estacionamientos incluso están conectados a la red gubernamental para cobrar las tarifas de estacionamiento directamente a las familias, todo lo cual alivia los esfuerzos humanos redundantes.
Los modelos de OCR de matrículas también se pueden adoptar para la detección de infracciones de tránsito, lo que facilita el tiempo para que la policía ingrese manualmente los datos del automóvil infractor.
Escaneo de recibos y facturas

Las proyecciones financieras y el equilibrio de los activos y pasivos de las empresas son actividades importantes para cualquier empresa. Dado que las grandes empresas realizan compras en grandes cantidades de múltiples sectores durante todo el año, se les exige que recopilen y procesen meticulosamente todas las facturas y recibos al crear los estados financieros.
Con la ayuda de OCR, podemos crear canalizaciones automatizadas que reconocer una serie de formatos de factura y convertirlos en números. Los esfuerzos laborales solo son necesarios para verificar, y los datos y números estructurados pueden permitirle a la empresa equilibrar rápidamente las entradas y salidas, crear proyecciones financieras y vigilar cualquier manipulación maliciosa de las finanzas de la empresa.
Registros médicos eléctricos

Los datos de los pacientes a menudo se encuentran dispersos por una región, un país o incluso entre países, según el estilo de vida de las personas. Debido a los diferentes estilos de clínicas y hospitales (los hospitales grandes pueden tener bases de datos organizadas, mientras que los médicos de las clínicas más pequeñas pueden simplemente escribir los registros a mano), la edad de los pacientes (los pacientes mayores pueden insertarse en una base de datos particular antes de la renovación e incorporación de computadoras) y las ubicaciones de las personas (las personas pueden mudarse a una ciudad diferente o incluso al extranjero), mantener un sistema médico universal puede ser realmente muy difícil.
Por lo tanto, un OCR bien capacitado se vuelve útil cuando se transfiere el EMR de un hospital a otro o cuando se transforman datos escritos a mano en texto de máquina, los cuales pueden acelerar el proceso de comprensión del historial médico de los pacientes de una manera rápida y concisa.
Formularios y encuestas

Las organizaciones (ya sean gubernamentales o no gubernamentales) a menudo pueden requerir comentarios de los clientes o ciudadanos para mejorar sus planes y productos promocionales actuales. Dado que los formularios generalmente se escriben a mano, sería potencialmente difícil realizar un análisis estadístico directo. Por lo tanto, el proceso de conversión de datos no estructurados y encuestas escritas a mano en cifras numéricas para facilitar los cálculos podría ser asistido y acelerado por el OCR.
¿Busca una solución de OCR que supere las deficiencias de Google Cloud Vision? Dar nanorred™ un giro para una mayor precisión, mayor flexibilidad y tipos de documentos más amplios.
Precios de Cloud Vision
Según Google página web del NDN Collective , Tanto anotación_de_texto y documento_texto_anotación se ofrecen al mismo nivel de precio que los siguientes:
Por cada mes, las primeras 1000 unidades se dan gratis, y las 1000-5000000 se cobran a $ 1.5 por 1000 unidades. Después de alcanzar la marca 5000000, el precio disminuye a $ 0.6 por 1000 unidades (cada imagen enviada a través de la API de Google Vision se considera como una unidad).
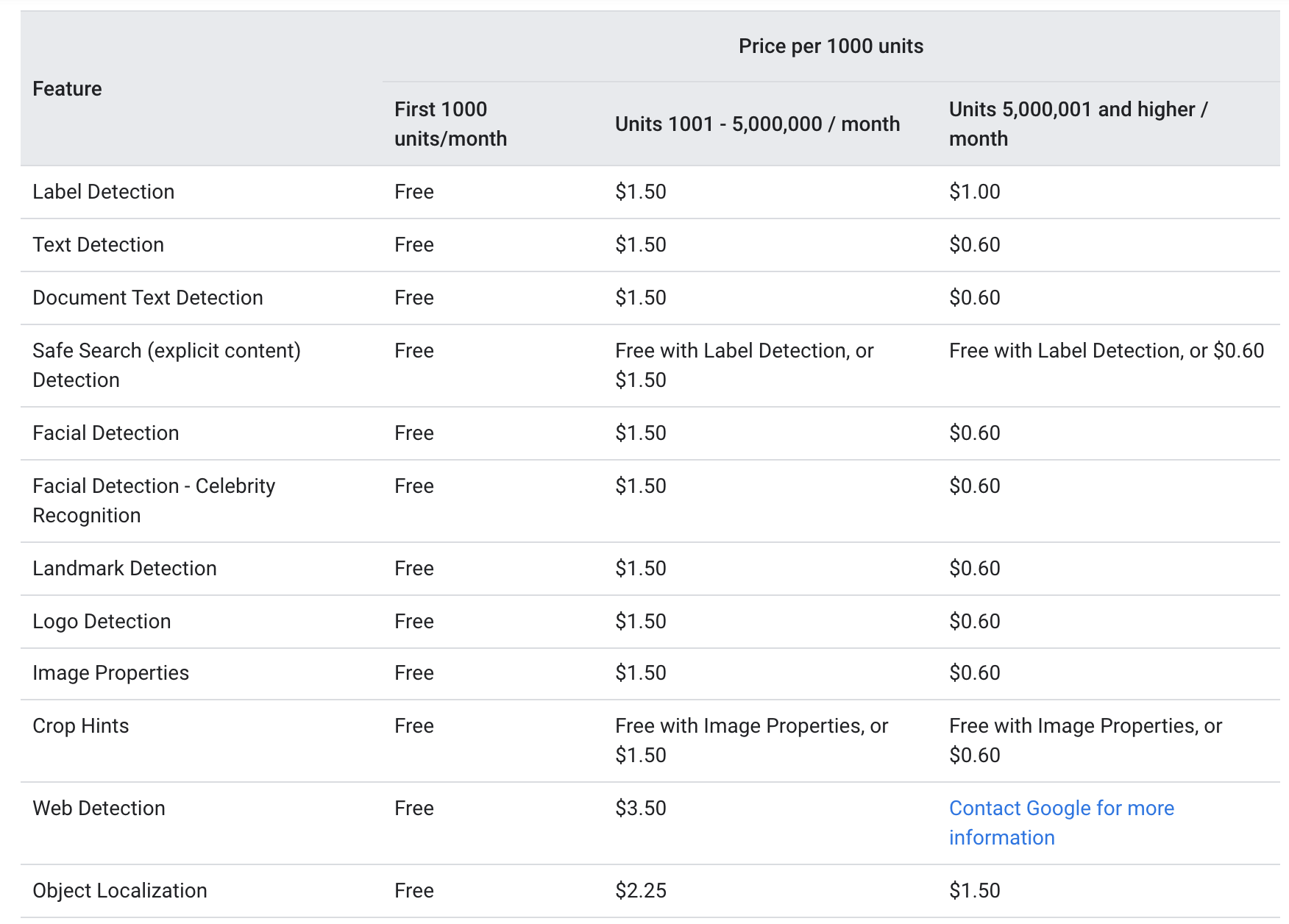
El precio anterior sugiere que el servicio OCR es relativamente asequible tanto para pequeñas empresas con usos menos frecuentes como para grandes corporaciones donde el servicio se requiere mucho más de 5000000 veces al mes.
Funciones destacadas de Google Cloud Vision OCR
Google OCR tiene varios beneficios, aquí describimos algunos de los beneficios más importantes:
- Robusto - Las dos funciones, que sirven a dos tipos de documentos de texto que dependen de la decisión de los usuarios, hacen que Google Vision OCR sea comparativamente más robusto que los motores de OCR de un solo modelo.
- Ayuda de idioma - Con quizás la base de datos de idiomas más grande, Google ha informado que su OCR es aplicable a más de 60 idiomas, experimentando con algunas docenas más y asigna muchos del resto a otro código de idioma o reconocedor de idioma general.
- Facilidad de uso - El modelo en sí es parte de la biblioteca incorporada de Google Vision. Después del proceso un poco más complicado de configurar la clave API (que es requerido por casi todos los motores de OCR), el método de llamada de función se puede usar en numerosos idiomas de una manera muy sencilla.
- Escalabilidad - La estrategia de precios de Google alienta a los usuarios a aumentar el uso de la API, ya que un mayor uso conduce a un precio promedio más barato.
- Velocidad - La plataforma de almacenamiento de Google Cloud acompaña maravillosamente el uso de la API. Al cargar las imágenes en la unidad, el tiempo de respuesta de la API puede ser muy rápido y escalable.

¿Busca una solución de OCR que supere las deficiencias de Google Cloud Vision? Dar nanorred™ un giro para una mayor precisión, mayor flexibilidad y tipos de documentos más amplios.
Alternativas
Los siguientes son algunos servicios de OCR alternativos además de la API de Google Vision, junto con las ventajas y desventajas de cada servicio.
ABBYY
ABBYY FineReader PDF es un OCR desarrollado por ABBYY, que se centra especialmente en la lectura de PDF.
- Pros: ABBYY es mucho más rentable para los usuarios individuales ya que los precios están segmentados en sectores más pequeños (1000, 2000 páginas, etc.). También está dirigido a clientes que no son ingenieros, ya que es una aplicación comercializada.
- Contras: El software se enfoca solo en formato PDF, y el precio se vuelve muy caro cuando se realiza OCR a gran escala.
- Cuándo usar: Para los usuarios individuales que solo desean manejar archivos PDF rápidamente, ABBYY puede ser una opción más viable que la API de Google Vision, que brinda más flexibilidad pero requiere códigos adicionales.
Microsoft
Microsoft Azure también ofrece API de lectura para OCR.
- Pros: Microsoft ofrece un precio más económico para utilizar una cantidad aún mayor de datos. El almacenamiento en la nube de Azure ofrece servicios similares a los de Google Cloud.
- Contras: No hay un nivel gratuito, mientras que otras opciones ofrecen llamadas API gratuitas para un uso reducido.
- Cuándo usar: Las canalizaciones de producción de OCR a muy gran escala podrían beneficiarse de los precios de Microsoft.
cofax
Al igual que ABBYY, Kofax también ofrece lectura OCR de archivos PDF
- Pros: El precio es fijo para uso individual y se ofrecen descuentos para empresas. También se proporciona soporte al cliente 24 horas al día, 7 días a la semana.
- Contras: Se afirma que la calidad no es tan alta como la de ABBYY.
- Cuándo usar: Pequeñas empresas con bajos requisitos de uso.
Texto de AWS
AWS Textract cumple una función muy similar en comparación con la API de Google Vision. Sus servicios y precios son muy similares, por lo que cuál adoptar se basa completamente en las preferencias del cliente.
Nanonetas
A diferencia de los servicios discutidos anteriormente, los OCR de Nanonets se clasifican en categorías específicas, con modelos robustos entrenados en cada tipo de datos (por ejemplo, recibos, facturas, permisos de conducir).
- Pros: OCR de categoría específica, por lo que proporciona resultados aún mejores en términos de precisión cuando las empresas requieren OCR para aplicaciones específicas de destino.
- Contras: El OCR de Nanonets puede ser menos aplicable a entornos en estado salvaje debido a los modelos altamente específicos y personalizados
- Cuándo usar: Si las empresas requieren OCR para un tipo específico de datos, como facturas, las nanorredes pueden ser una opción rentable y muy precisa.
solicite pruebe Nanonets Online OCR aquí.
Problemas comunes con Cloud Vision
En esta sección final, nuestro objetivo es abordar algunas preguntas de Stackoverflow con respecto al escaneo de documentos y OCR
Reconocer documentos mediante redes neuronales
¡Este es el uso exacto de Google OCR! Siga los pasos anteriores para escanear documentos y realizar la recuperación de texto.
Obtener los detalles más importantes después de OCR
La idea de analizar el contenido más significativo dentro de cualquier documento se denomina procesamiento de lenguaje natural. Como cada documento contiene dicha información en diferentes formatos, se recomendaría adoptar algunos enfoques de ML para hacerlo. Por supuesto, si todas las tarjetas tienen el mismo formato, los métodos basados en reglas para recuperar los textos con ciertos caracteres clave (por ejemplo, si contiene @ es un correo electrónico) también deberían funcionar.
¿Se puede ejecutar sin conexión?
Enlace: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
Lamentablemente no. La API llama a Google Cloud OCR de forma remota y no puede trabajar sin conexión ya que la API cuesta dinero.
¿Puede detectar si un texto está en negrita o cursiva?
No. Lo más probable es que Google OCR detecte el contenido del texto incluso cuando esté en negrita o cursiva, pero el modelo OCR no está diseñado para comprender los tipos de fuentes.
Actualizar: Se agregó más información basada en las consultas de los lectores.
- &
- a
- acelerado
- Mi Cuenta
- preciso
- a través de
- actividades
- dirección
- ventajas
- Todos
- alternativa
- alternativas
- hacerlo
- cantidades
- análisis
- analizar
- Otra
- abejas
- API
- applicación
- aplicable
- Aplicación
- aplicaciones
- aplicada
- enfoques
- Reservada
- en torno a
- artículo
- Activos
- Autenticación
- automatizado
- Confirmación de Viaje
- promedio
- Azure
- Nube azul
- fondo
- Bancos
- base
- antes
- es el beneficio
- beneficios
- facturación
- Bloquear
- Libros
- frontera
- rompe
- de
- Tarjetas
- a ciertos
- personajes
- CHARGE
- cargado
- más barato
- comprobación
- Ciudad
- clasificación
- Soluciones
- almacenamiento en la nube
- código
- Algunos
- Empresas
- compañía
- en comparación con
- completamente
- computadora
- computadoras
- conectado
- Considerar
- Consola
- contiene
- contenido
- contenido
- Conversión
- Corporaciones
- Correspondiente
- Precio
- podría
- países
- país
- Para crear
- creado
- Creamos
- Current
- cliente
- Atención al cliente
- Clientes
- datos
- análisis de los datos
- proceso de datos
- Base de datos
- bases de datos
- día
- tratar
- Koops
- profundo
- dependiente
- Dependiente
- describir
- diseñado
- detallado
- detalles
- detectado
- Determinar
- desarrollado
- una experiencia diferente
- difícil
- de reservas
- directamente
- Diversidad
- Doctores
- documentos
- dominios
- DE INSCRIPCIÓN
- el lado de la transmisión
- conducción
- cada una
- aliviando
- Southern Implants
- esfuerzo
- esfuerzos
- surgido
- habilitar
- anima
- empresas
- Entorno
- especialmente
- esencialmente
- etc.
- ejemplos
- Exit
- Extractos
- familias
- RÁPIDO
- Caracteristicas
- realimentación
- Costes
- Finanzas
- financiero
- Firme
- Nombre
- fijas
- Flexibilidad
- se centra
- seguir
- siguiendo
- formato
- Formularios
- encontrado
- Gratuito
- Desde
- función
- funciones
- promover
- General
- conseguir
- gubernamental
- Gobiernos
- mayor
- encargarse de
- ayuda
- esta página
- Alta
- más alto
- altamente
- historia
- hospitales
- Cómo
- Como Hacer
- HTTPS
- humana
- Humanos
- idea
- imagen
- imágenes
- importante
- imposible
- mejorar
- incluido
- incluye
- Incluye
- INSTRUMENTO individual
- individuos
- info
- información
- ejemplo
- intuitivo
- cuestiones
- IT
- sí mismo
- Java
- acuerdo
- Clave
- mano de obra
- idioma
- Idiomas
- large
- mayores
- mayor
- Prospectos
- aprendizaje
- Nivel
- Biblioteca
- Licencia
- licencias
- estilo de vida
- que otros
- LINK
- local
- Ubicación
- Ubicaciones
- Largo
- máquina
- máquina de aprendizaje
- Máquinas
- gran
- para lograr
- manera
- a mano
- Mapas
- marca
- masivo
- sentido
- significativo
- servicios
- mediano
- mencionado
- métodos
- Microsoft
- ML
- modelo
- modelos
- dinero
- Mes
- más,
- MEJOR DE TU
- movimiento
- múltiples
- Natural
- Naturaleza
- del sistema,
- sin embargo
- Notas
- número
- números
- numeroso
- Ofrecido
- Ofertas
- oficial
- digital fuera de línea.
- en línea
- optimizado
- Optión
- Opciones
- solicite
- Organizado
- Otro
- EL DESARROLLADOR
- llena
- estacionamiento
- parte
- particular
- particularmente
- Pasando (Paso)
- (PDF)
- Personas
- quizás
- jubilación
- plataforma
- Policía
- Popular
- poderoso
- precio
- cotización
- en costes
- tratamiento
- Producción
- Productos
- proyecto
- proyecciones
- prometedor
- promocional
- proporcionar
- previsto
- proporciona un
- proporcionando
- compras
- calidad
- con rapidez
- distancia
- que van
- RE
- lectores
- Reading
- reciente
- reconocer
- archivos
- con respecto a
- región
- sanaciones
- exigir
- Requisitos
- Requisitos
- requiere
- la investigación
- Recursos
- respuesta
- RESTO
- Resultados
- carretera
- Función
- Ejecutar
- mismo
- escalable
- Escala
- escanear
- exploración
- Sectores
- sentido
- Serie
- de coches
- Servicios
- servicio
- set
- pólipo
- importante
- Letreros y Pancartas
- similares
- sencillos
- desde
- chica
- So
- Software
- sólido
- a medida
- algo
- soluciones y
- específicamente
- Girar
- etapas
- fundó
- declaraciones
- estadístico
- statistics
- STORAGE
- Estrategia
- calle
- estructurado
- SOPORTE
- soportes
- Peritaje
- términos
- La
- por lo tanto
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- a lo largo de
- equipo
- veces
- hoy
- hacia
- tradicional
- tráfico
- Formación
- Transferencia
- transformadora
- tipos
- bajo
- entender
- comprensión
- unidades que
- Universal
- utilizan el
- usuarios
- generalmente
- diversos
- visión
- volumen
- Ver ahora
- sean
- mientras
- QUIENES
- más ancho
- ventanas
- dentro de
- palabras
- Actividades:
- funciona
- se
- X
- año
- tú