Última actualización: enero de 2021.
Este blog es una descripción general completa del uso de OCR con cualquier herramienta RPA para automatizar los flujos de trabajo de sus documentos. Exploramos cómo las últimas tecnologías de OCR basadas en aprendizaje automático no requieren reglas o configuración de plantillas.

Las RPA o automatización de procesos robóticos son herramientas de software destinadas a eliminar las tareas comerciales repetitivas. Más CIO están recurriendo a ellos para reducir costos y ayudar a los empleados a concentrarse en un trabajo comercial de mayor valor. Los ejemplos incluyen responder a comentarios en sitios web o procesar pedidos de clientes. Las tareas un poco más complejas incluyen el manejo de documentos como formularios escritos a mano y facturas - por lo general, estos deben moverse de un sistema heredado a otro - por ejemplo, su cliente de correo electrónico a su sistema SAP ERP donde necesita extraer datos. Ésta es la parte problemática.
La mayoría de las herramientas de OCR que capturan datos de estos documentos se basan en plantillas (digamos Abbyy Flexicapture) y no escalan bien en documentos semiestructurados. Existen soluciones basadas en aprendizaje automático de última generación que normalmente proporcionan API
integraciones que pueden capturar pares clave-valor de documentos: los sistemas empresariales generalmente son heredados y no están abiertos para integrarse con API externas. Por otro lado, las RPA están diseñadas para manejar estos flujos de trabajo de sistemas heredados, como ingerir documentos de carpetas e ingresar resultados en ERP o CRM.
A medida que la automatización robótica de procesos (RPA) y el aprendizaje automático evolucionan hacia la hiperautomatización, podemos hacer uso de bots de software junto con el aprendizaje automático para manejar tareas complejas como la clasificación, extracción y reconocimiento óptico de caracteres de documentos. En un estudio reciente, se dijo que al automatizar solo el 29% de las funciones para una tarea usando RPA, los departamentos de finanzas por sí solos ahorran más de 25,000 horas de retrabajo causado por errores humanos a un costo de $ 878,000 por año para una organización con 40 personal de contabilidad de tiempos [1]. En este blog, aprenderemos sobre el uso de OCR con RPA y profundizaremos en los flujos de trabajo de comprensión de documentos. A continuación se muestra la tabla de contenido.
Definiciones y descripción general
RPA, en general, es una tecnología que ayuda a automatizar las tareas administrativas a través de bots de software y hardware. Estos bots aprovechan las interfaces de usuario; para capturar los datos y manipular aplicaciones como lo hacen los humanos. Por ejemplo, una RPA puede ver una serie de tareas realizadas en una GUI, digamos, cursores en movimiento, conectarse a API, copiar y pegar los datos y formular la misma secuencia de acciones en una estructura alámbrica de RPA que se traduce en código. Además, estas tareas se pueden realizar sin intervención humana en el futuro. El reconocimiento óptico de caracteres (OCR) es una característica crucial de cualquier solución funcional de automatización de procesos robóticos (RPA). Esta tecnología se utiliza para leer y extraer texto de diferentes fuentes como imágenes o pdfs en un formato digital sin capturarlo manualmente.
Por otro lado, la comprensión de documentos es el término que se utiliza para describir automáticamente la lectura, la interpretación y la actuación sobre los datos del documento. Lo más importante en este proceso es que los propios robots de software realizan todas las tareas. Estos bots aprovechan el poder de la inteligencia artificial y el aprendizaje automático para comprender los documentos como asistentes digitales. De esta manera, podemos decir que la comprensión de los documentos surge en la intersección del procesamiento de documentos, la IA y la RPA.

Cómo los robots pueden aprender a comprender los documentos con OCR y ML
Antes de profundizar en la comprensión de documentos, hablemos sobre el papel de los robots para la comprensión de documentos. Estos ayudantes totalmente invisibles hacen que nuestra vida sea mucho más cómoda. A diferencia de las películas y series, estos robots no son dispositivos físicos o programas de inteligencia artificial que se sientan en un escritorio y pulsan botones para realizar tareas. Podemos pensar en ellos como asistentes digitales capacitados para procesar documentos leyendo y usando aplicaciones como lo hacemos nosotros. En el aspecto funcional, los robots son buenos para mejorar el rendimiento y la eficiencia de un proceso. Aún así, al ser un software independiente, no pueden evaluar el proceso y tomar decisiones cognitivas. Sin embargo, si el aprendizaje automático se integra con éxito, la robótica se volverá más dinámica y adaptable. Por ejemplo, los robots utilizados para el procesamiento de documentos, la gestión de datos y otras funciones en la oficina central y frontal realizarán acciones más inteligentes, como eliminar entradas duplicadas o resolver excepciones desconocidas del sistema en el proceso. Además, los robots están entrenados para leer, extraer, interpretar y actuar sobre los datos de los documentos utilizando inteligencia artificial (IA).
¿Cómo pueden las empresas integrar OCR inteligente con RPA para mejorar los flujos de trabajo?
La extracción de datos de documentos es un componente crucial para la comprensión de documentos. En esta sección, discutiremos cómo podemos integrar OCR con RPA o viceversa. En primer lugar, todos sabíamos que existen diferentes tipos de documentos en términos de plantillas, estilo, formato y, a veces, idioma. Por lo tanto, no podemos confiar en una técnica simple de OCR para extraer los datos de estos documentos. Para abordar este problema, utilizaremos enfoques basados en reglas y enfoques basados en modelos dentro de OCR para manejar datos de diferentes estructuras de documentos. Ahora veremos cómo las empresas que realizan OCR pueden integrar RPA en su sistema existente según el tipo de documentos.
Documentos estructurados: En este tipo de documentos, los diseños y plantillas suelen ser fijos y casi consistentes. Por ejemplo, considere una organización que realiza KYC con identificaciones emitidas por el gobierno, como un pasaporte o una licencia de conducir. Todos estos documentos serán idénticos y tendrán los mismos campos como Número de identificación, Nombre de la persona, Edad y algunos otros en las mismas posiciones. Pero solo varían los detalles. Puede haber pocas restricciones, como el desbordamiento de la tabla o los datos no archivados.
Por lo general, el enfoque recomendado utiliza una plantilla o un motor basado en reglas para extraer la información de los documentos estructurados. Estos pueden incluir expresiones regulares o mapeo de posición simple y OCR. Por lo tanto, para integrar robots de software para automatizar la extracción de información, podemos usar plantillas preexistentes o crear reglas para nuestros datos estructurados. Hay una desventaja al usar el enfoque basado en reglas, ya que se basa en partes fijas, incluso cambios menores en la estructura del formulario pueden hacer que las reglas se rompan.
Documentos semiestructurados: Estos documentos tienen la misma información pero están dispuestos en diferentes posiciones. Por ejemplo, considere facturas que contiene 8-12 campos idénticos. En algunas facturas , la dirección del comerciante se puede ubicar en la parte superior y, en otros, se puede encontrar en la parte inferior. Por lo general, estos enfoques basados en reglas no proporcionan una gran precisión; por lo tanto, incorporamos modelos de aprendizaje automático y aprendizaje profundo para la extracción de información mediante OCR. Alternativamente, en algunos casos, podemos usar modelos híbridos que involucren tanto reglas como modelos ML. Algunos modelos populares previamente entrenados son FastRCNN, Attention OCR, Graph Convolutions para la extracción de información en documentos. Sin embargo, nuevamente estos modelos tienen pocos inconvenientes; por lo tanto, medimos el rendimiento del algoritmo utilizando métricas como la precisión o la puntuación de confianza. Debido a que el modelo está aprendiendo patrones, en lugar de operar con reglas concretas, puede cometer errores inicialmente justo después de las correcciones. Sin embargo, la solución a estos inconvenientes es que cuantas más muestras procesa el modelo de ML, más patrones aprende para garantizar la precisión.
Documentos no estructurados: RPA, hoy en día, no puede administrar datos no estructurados directamente, por lo que requiere que los robots primero extraigan y creen datos estructurados utilizando OCR. A diferencia de los documentos estructurados y semiestructurados, los datos no estructurados no tienen algunos pares clave-valor. Por ejemplo, en unos pocos facturas , vemos la dirección de un comerciante en algún lugar sin ningún nombre clave; de manera similar, observamos lo mismo para otros campos como fecha, ID de factura. Para que los modelos de aprendizaje automático los procesen con precisión, los robots deben aprender a traducir el texto escrito en datos procesables, como un correo electrónico, un número de teléfono, una dirección, etc. El modelo entonces aprenderá que se deben extraer patrones numéricos de 7 o 10 dígitos. como números de teléfono y texto enorme que contiene códigos de cinco dígitos y diferentes sustantivos como texto. Para hacer que estos modelos sean más precisos, también podemos utilizar técnicas del procesamiento del lenguaje natural (NLP) como el reconocimiento de entidades nombradas y la incrustación de palabras.
En general, para comprender los documentos, primero es esencial comprender los datos y luego implementar OCR con RPA. A continuación, en lugar de trazar un proceso paso a paso, podemos enseñarle a un robot a "hacer lo que yo hago" registrando el proceso tal como sucede con las potentes capacidades de OCR, como se mencionó anteriormente, integrando reglas y algoritmos de aprendizaje automático. El robot de software sigue sus clics y acciones en la pantalla y luego los convierte en un flujo de trabajo editable. Si está trabajando completamente en programas locales, eso es todo lo que necesita saber.
Desafíos de OCR que enfrentan los desarrolladores de RPA
Hemos visto cómo podemos integrar OCRR con RPA para diferentes documentos, pero hay algunos casos de desafíos en los que los robots deben manejarse bien. ¡Discutamos ahora!
- Datos débiles o inconsistentes: Los datos juegan un papel crucial en la comprensión de documentos. En la mayoría de los casos, los documentos se escanean usando cámaras donde existe la posibilidad de perder el formato del documento durante el escaneo de texto (es decir, no siempre se reconocen negrita, cursiva y subrayado). A veces, el OCR puede extraer texto de forma incorrecta, lo que genera errores de ortografía, saltos de párrafo irregulares, lo que reduce el rendimiento general de los robots. Por lo tanto, manejar todos los valores faltantes y capturar los datos con mayor precisión es vital para lograr una mayor precisión para OCR.
- Orientación de página incorrecta en documentos: La orientación y la asimetría de la página también es uno de los problemas comunes que provocan la corrección incorrecta del texto del OCR. Esto suele ocurrir cuando los documentos se escanean incorrectamente durante la fase de recopilación de datos. Para superar esto, tendremos que declarar algunas funciones a los robots como auto-ajuste a la página, auto-filtro para que puedan permitir el aumento de la calidad del documento escaneado y recibir datos correctos en la salida.
- Problemas de integración: No todas las herramientas de RPA funcionan bien en entornos de escritorio remoto: provocan bloqueos y problemas críticos en la automatización. Además, el desarrollador de RPA necesita saber qué solución de OCR será la mejor para un caso específico. Además, para trabajar con herramientas de automatización específicas, el desarrollador de RPA debe elegir solo tecnología OCR limitada creada por Microsoft, Google. Por lo tanto, integrar nuestros algoritmos y modelos personalizados a veces es un desafío.
- Todo el texto es texto codificado: Para casos de uso de la vida real, el texto capturado por un OCR genérico está codificado y no tiene información significativa que los bots puedan usar para realizar operaciones importantes. Los desarrolladores de RPA necesitan un sólido soporte de ML para poder crear aplicaciones útiles.
Canalización para el flujo de trabajo de comprensión de documentos
En las secciones anteriores, hemos visto cómo los bots ayudan a realizar el OCR para diferentes tipos de documentos. Pero OCR es solo una técnica que convierte imágenes u otros archivos en texto. Ahora, en esta sección, veremos el flujo de trabajo de comprensión de documentos desde el comienzo de la recopilación de documentos para finalmente guardarlos información significativa en el formato deseado.

- Ingiera el documento de una carpeta usando su Bot: Este es el primer paso para lograr la comprensión de documentos a través de bots. Aquí, obtendremos el documento ubicado en una plataforma en la nube (usando una API) o desde una máquina local. En algunos casos, si nuestros documentos están en páginas web, podemos automatizar la extracción de scripts a través de bots donde pueden obtener documentos de manera oportuna.
- Tipo de documento: Una vez que obtenemos los datos, es fundamental comprender el tipo de documento y el formato con el que se guardan en nuestros sistemas, ya que a veces recibimos datos de diferentes fuentes en varios formatos de archivo como (PDF), PNG y JPG. No solo los tipos de archivos, a veces, cuando los documentos se escanean con las cámaras de los teléfonos, también deben resolverse algunos problemas desafiantes como la inclinación de la imagen, la rotación, el brillo o la baja resolución. Por lo tanto, tendremos que asegurarnos de que los bots clasifiquen estos documentos en la categoría estructurada, semiestructurada o no estructurada, guardándolos así en un formato genérico. La tarea de clasificación se logra comparando los documentos con plantillas y analizando características como fuentes, idioma, presencia de pares clave-valor, tablas, etc.
- Extrayendo los datos con OCR: Muy bien, ahora que los bots organizaron nuestros documentos en un formato genérico y los clasificaron, es hora de que los digitalicemos utilizando la técnica OCR. Con esto tendremos el texto, su ubicación en co-coordenadas de las imágenes. Esto ayuda a estandarizar los documentos y datos para los pasos siguientes. También encontramos algunos en los que el software OCR no pudo distinguir correctamente entre caracteres, como 't' frente a 'i' o '0' frente a 'O'. Los mismos errores que desea evitar con el software OCR pueden convertirse en nuevos dolores de cabeza cuando la tecnología OCR es incapaz de analizar los matices de un documento en función de su calidad o forma original. Aquí es donde entra en juego el aprendizaje automático, que discutiremos en el siguiente paso.
- Aprovechamiento de ML / DL para OCR inteligente usando Bots: Una vez digitalizados los datos, el software de OCR debe comprender el tipo de documento con el que está trabajando y lo que es relevante. Pero el software OCR tradicional puede tener dificultades para escalar los esfuerzos de clasificación de documentos. Por lo tanto, los robots de software deben capacitarse con habilidades cognitivas aprovechando el aprendizaje automático y las técnicas de aprendizaje profundo para hacer que los OCR sean más inteligentes. Las soluciones de OCR basadas en ML pueden identificar un tipo de documento y compararlo con un tipo de documento conocido utilizado por su empresa. También pueden analizar y comprender bloques de texto en documentos no estructurados. Una vez que la solución sepa más sobre el documento en sí, puede comenzar a extraer información relevante según la intención y el significado.
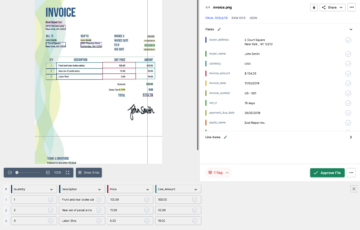
- Mejor extracción y clasificación de datos: La extracción de datos es el núcleo de la comprensión de documentos. Como se discutió en la sección anterior sobre Integración de RPA con OCR en este paso, opte por la técnica de extracción de datos según el tipo de documento. A través de las RPA, podemos configurar fácilmente qué extractor utilizar, ya sea una técnica de OCR basada en reglas, ML o modelo híbrido. Según las métricas de confianza y rendimiento que se devuelven después de la extracción de información, los robots de software las guardarán en nuestro formato deseado para un análisis más detallado. A continuación se muestra una imagen de cómo podemos configurar extractores y establecer el nivel de confianza en una herramienta RPA de UIPath.

6. Validación y empoderamiento de conocimientos: Los modelos de OCR y Machine Learning no son cien por ciento precisos en términos de extracción de información, por lo que agregar una capa de intervención humana con la ayuda de robots puede resolver el problema. La forma en que funciona esta validación es que cada vez que los robots tratan con poca precisión y excepciones, inmediatamente genera una notificación al centro de acción donde un empleado puede recibir una solicitud para validar datos o manejar excepciones y puede resolver cualquier incertidumbre en cuestión de clics. Además, podemos desbloquear el potencial de la inteligencia artificial para documentar datos a lo largo del tiempo para hacer predicciones e identificar anomalías potenciales que pueden indicar fraude, duplicación y otros errores.
Beneficios de integrar robots con Document Understanding
- Automatizar el proceso: La razón clave para integrar bots para la comprensión de documentos es automatizar todo el proceso de principio a fin. Todo lo que tenemos que hacer es crear un flujo de trabajo para que los bots aprendan, se sienten y se relajen. Durante el proceso de validación, es posible que debamos abordar los problemas notificados por los bots cuando se identifican errores o fraudes.
- Bots con aprendizaje automático: Durante el proceso de automatización, podemos hacer que los bots sean resistentes al aprendizaje automático. Lo que significa que los robots también pueden aprender cómo funcionan los modelos de aprendizaje automático y, por lo tanto, mejorar los modelos para lograr una mayor precisión y rendimiento para la extracción de texto e información de documentos.
- Procese una amplia gama de procesamiento de documentos: Para tareas generales como extracción de tablas e información, tendremos que crear diferentes canales de aprendizaje profundo para diferentes tipos de documentos. Esto lleva a construir múltiples aplicaciones e implementar varios modelos en diferentes servidores, lo que requiere mucho esfuerzo y tiempo. Cuando los bots están en la imagen para una amplia gama de documentos, solo podríamos tener una única canalización en la que los bots puedan clasificarlos y luego usar el modelo apropiado para diferentes tareas. También podemos integrar varios servicios a través de API y comunicarnos con otras organizaciones en términos de obtención de datos.
- Fácil de implementar: Para comprender los documentos después de que se crean las canalizaciones, el proceso de implementación es de solo un minuto. Podemos hacer que los bots exporten las API después del entrenamiento, o bien podemos crear una solución RPA personalizada que se pueda usar en nuestros sistemas locales. Este tipo de implementación también puede optimizar las empresas y puede reducir el gasto con riesgos mínimos.
Introduzca nanonetas
NanoNets es una plataforma de aprendizaje automático que permite a los usuarios capturar datos de facturas , recibos y otros documentos sin ninguna configuración de plantilla. Tenemos algoritmos de visión por computadora y aprendizaje profundo de última generación que se ejecutan en la parte posterior que pueden manejar cualquier tipo de tareas de comprensión de documentos como OCR, extracción de tablas, extracción de pares clave-valor. Por lo general, se exportan como API o se pueden implementar localmente en función de diferentes casos de uso. Aquí están algunos ejemplos,
- Modelo de factura: identifique los campos clave de Facturas como el nombre de los compradores, la identificación de la factura, la fecha, la cantidad, etc.
- Modelo de recibos: identifique los campos clave de los recibos, como el nombre del vendedor, el número, la fecha, la cantidad, etc.
- Licencia de conducir (EE. UU.): Identifique campos clave como número de licencia, fecha de nacimiento, fecha de vencimiento, fecha de emisión, etc.
- Currículums: Extraiga experiencia, educación, conjuntos de habilidades, información del candidato, etc.
Para hacer que estos flujos de trabajo sean más rápidos y sólidos, utilizamos UiPath, una herramienta RPA para la automatización perfecta de sus documentos sin ninguna plantilla. En la siguiente sección, veremos cómo puede usar UiPath Connect con Nanonets para comprender los documentos. Los 3 jugadores más importantes en el mercado de RPA son UiPath, Automation Anywhere y Prisma azul. Este blog se centra en Uipath.
NanoNets con UiPath
Hemos aprendido a crear una canalización de comprensión de documentos en nuestras secciones anteriores. Requiere conocimientos básicos de OCR, RPA y aprendizaje automático, ya que existen diferentes enfoques y algoritmos para diferentes tareas en varios puntos. Además, debemos dedicar mucho esfuerzo a la creación de redes neuronales que comprendan nuestras plantillas, las capaciten y las implementen. Por lo tanto, para estar cómodos y automatizar todo, desde cargar documentos, clasificarlos, crear OCR, integrar modelos de ML, en Nanonets estamos trabajando en Ui Path para crear una canalización perfecta para la comprensión de documentos. A continuación se muestra una imagen de cómo funciona esto.

Ahora revisemos cada uno de estos y aprendamos cómo podemos integrar Nanorred con UiPath.
Paso 1: Regístrese en UiPath y descargue UiPath Studio
Para crear un flujo de trabajo, primero tendremos que crear una cuenta en UiPath. Si es un usuario existente, puede iniciar sesión directamente en su cuenta, redirigiendo su panel de control de UiPath. A continuación, deberá descargar e instalar UiPath Studio (Community Edition), que es gratis.
Paso 2: Descarga el componente Nanonets
A continuación, para configurar su canalización de procesamiento de facturas, tendrá que descargar el conector Nanonets desde el enlace a continuación.
-> NanoNets OCR - Componente RPA
A continuación se muestra una captura de pantalla de UiPath Marketplace y el componente Nanonets. Además, para descargar esto, asegúrese de haber iniciado sesión en UiPath desde un sistema operativo Windows.

Sus archivos descargados deben contener los archivos que se enumeran a continuación,
UiPath OCR Predict ├── Main.xaml
└── project.json
Paso 3: Abra el componente Nanonets del archivo Main.xaml
Para verificar si Nanonets UiPath está funcionando o no, puede abrir su archivo Main.xml desde el componente Nanonets descargado usando Ui Path Studio. Luego, puede ver su canalización ya creada para usted para el procesamiento de documentos.

Paso 4: Reúna su ID de modelo, clave API y punto final API de la aplicación Nanonets
A continuación, puede utilizar cualquiera de los modelos de OCR entrenados de la aplicación Nanonets y recopilar el ID del modelo, la clave API y el punto final. A continuación hay más detalles para que los encuentre rápidamente.
ID del modelo: Inicie sesión en su cuenta de Nanonets y vaya a "Mis modelos". Puede entrenar un nuevo modelo o copiar el ID de aplicación de un modelo existente.

Punto final de API: Puede elegir cualquier modelo existente y hacer clic en Integrar para encontrar su punto final de API. A continuación, se muestra un ejemplo de cómo se ven sus puntos finales.
https://app.nanonets.com/api/v2/OCR/Model/XXXXXXX-4840-4c27-8940-d3add200779e/LabelUrls/

3. API Key: navegue hasta la pestaña API Key y podrá copiar cualquier API Key existente o crear una nueva.

Paso 5: agregue una solicitud HTTP para obtener su método y variables en la ruta de la interfaz de usuario
Ahora, para integrar su modelo de Nanonets a la ruta de la interfaz de usuario, tendrá que hacer clic primero en Solicitud HTTP y agregar el EndPoint, que se puede encontrar en la navegación izquierda en la sección Entrada. A continuación se muestra una captura de pantalla.

Luego, agregue todas sus variables para establecer una conexión desde su estudio UiPath a la API de Nanonets. Puede encontrar esta sección en el panel inferior en la "pestaña Variables". A continuación se muestra la captura de pantalla, deberá actualizar / copiar su clave API, punto final y el modelo-ID de su modelo aquí.

Paso 6: agregue la ubicación del archivo para las predicciones
Por último, puede agregar la ubicación de su archivo en la pestaña de atributos, como se muestra en la captura de pantalla a continuación, y presionar el botón de reproducción en su navegación superior para predecir sus resultados.

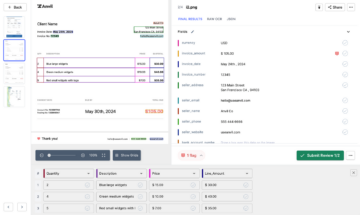
¡Voila! Aquí están nuestros resultados para el documento que solicitamos en la siguiente captura de pantalla. Para procesar más, simplemente puede agregar las ubicaciones de sus archivos y presionar el botón Ejecutar.

Paso 7: enviar la salida a CSV / ERP
Por último, para personalizar nuestra salida en el formato que desee, podemos agregar nuevos bloques a su canalización en el archivo Main.XML. También podemos introducir esto en cualquier sistema ERP existente a través de archivos fuera de línea o llamadas API.

Para cualquier ayuda contáctenos en support@nanonets.com
Seminarios Web

Únase a nosotros para un seminario web el próximo martes sobre OCR con RPA, registrar aquí.
Referencias
[ 2 ] Comprensión de documentos: procesamiento de documentos con IA
[ 3 ] RPA OCR: automatización de procesos de elevación | BONITO
[ 4 ] Cómo utilizar la IA para optimizar la comprensión de los documentos
[ 5 ] https://www.uipath.com/product/document-understanding
[ 6 ] Uso de NanoNets en el flujo de trabajo de UiPath para OCR de facturas
OTRAS LECTURAS
Es posible que le interesen nuestras últimas publicaciones sobre:
Actualizar:
Se agregó más material de lectura sobre el uso y el impacto de OCR, RPA en la comprensión de documentos.
Fuente: https://nanonets.com/blog/ocr-with-rpa-and-document-understanding-uipath/
- '
- &
- 000
- 2021
- 7
- Mi Cuenta
- Contabilidad
- la columna Acción
- Ventaja
- AI
- algoritmo
- algoritmos
- Todos
- análisis
- abejas
- API
- applicación
- Aplicación
- aplicaciones
- Arte
- inteligencia artificial
- Inteligencia Artificial (AI)
- Inteligencia Artificial y Aprendizaje Automático
- Automatización
- automatización en cualquier lugar
- MEJOR
- Mayor
- Blog
- Bot
- los robots
- build
- Construir la
- cámaras
- cases
- Causar
- causado
- reconocimiento de caracteres
- clasificación
- Soluciones
- Plataforma en la nube
- código
- cognitivo
- El cobro
- comentarios
- Algunos
- vibrante e inclusiva
- Empresas
- componente
- Visión por computador
- confianza
- contenido
- correcciones
- Precio
- página de información de sus operaciones
- datos
- datos de gestión
- acuerdo
- deep learning
- Developer
- desarrolladores
- Dispositivos
- digital
- documentos
- Esquivar
- conducción
- Educación
- eficiencia
- personas
- Punto final
- Empresa
- etc.
- extraer los datos
- Extracción
- Feature
- Caracteristicas
- Terrenos
- Finalmente
- financiar
- Nombre
- Focus
- formulario
- formato
- fraude
- Gratuito
- futuras
- Gartner
- General
- gif
- candidato
- guía
- Manejo
- dolores de cabeza
- esta página
- Alta
- Cómo
- Como Hacer
- HTTPS
- enorme
- Humanos
- Híbrido
- Identifique
- imagen
- Impacto
- aumente
- info
- información
- extracción de información
- Intelligence
- intención
- cuestiones
- IT
- Clave
- especialistas
- KYC
- idioma
- más reciente
- Lead
- líder
- APRENDE:
- aprendido
- aprendizaje
- Nivel
- Apalancamiento
- Licencia
- Limitada
- LINK
- local
- Ubicación
- máquina de aprendizaje
- Management
- Mercado
- mercado
- Match
- medir
- Comerciante
- Métrica
- Microsoft
- ML
- modelo
- Películas
- Lenguaje natural
- Procesamiento natural del lenguaje
- Navegación
- telecomunicaciones
- Neural
- redes neuronales
- nlp
- .
- números
- OCR
- habiertos
- funcionamiento
- sistema operativo
- Operaciones
- reconocimiento óptico de caracteres
- solicite
- Otro
- Otros
- pasaporte
- actuación
- imagen
- plataforma
- Popular
- Artículos
- industria
- Precisión
- Predicciones
- Automatización de procesos
- Programas
- proyecto
- calidad
- plantea
- distancia
- RE
- Reading
- reducir
- Resultados
- una estrategia SEO para aparecer en las búsquedas de Google.
- robot
- Automatización de procesos robóticos
- robótica
- los robots
- RPA
- reglas
- Ejecutar
- correr
- savia
- ahorro
- Escala
- exploración
- raspado
- Pantalla
- sin costura
- Vendedores
- Serie
- Servicios
- set
- sencillos
- So
- Software
- Bots de software
- Soluciones
- RESOLVER
- pasar
- comienzo
- Estado
- ESTUDIO
- SOPORTE
- te
- Todas las funciones a su disposición
- extracción de mesa
- Tecnologías
- Tecnología
- El futuro de las
- equipo
- parte superior
- Formación
- ui
- UiPath
- Actualizar
- us
- Estados Unidos de America
- casos de uso
- usuarios
- propuesta de
- Versus
- visión
- web
- Webinar
- sitios web
- QUIENES
- ventanas
- dentro de
- Actividades:
- flujo de trabajo
- funciona
- XML
- año
- Youtube