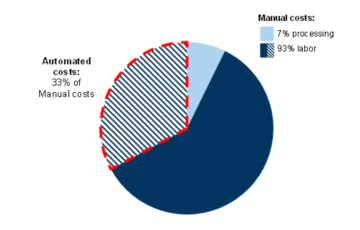
Sellest artiklist leiate erinevaid meetodeid PDF-i teisendamiseks Google'i arvutustabeliteks.
Samuti saate teada, kuidas Nanonets saab automatiseerida kogu PDF-i teisendamise töövoogu Google'i arvutustabeliteks online.
Enne kui uurime, kuidas PDF-faili Google'i arvutustabeliteks teisendada, vaatame, miks see on oluline.
Miks teisendada PDF-failid Google'i arvutustabeliteks?
Vastavalt sellele Google'i ajaveeb postitus Google'i ametlikult ajaveebi lehelt, kasutab enam kui 5 miljonit ettevõtet nende G Suite'i lahendust. Samal ajal on suur osa ettevõtteid hakanud kasutama ka Google Sheetsi integratsioone ülesannete automatiseerimiseks.
Vaatleme tüüpilist kasutusjuhtumit. Teie võlgnevuste meeskond saab arve standardses PDF-vormingus. Keegi vaatab arve käsitsi läbi ja sisestab vajaliku teabe Google'i arvutustabelite dokumenti, enne kui suunab selle edasi jaotisesse Finants. Finantsjaotis maksab teie tarnijale ja teeb kande ettevõtte pearaamatusse.
Peale selle, et protsess on pikk, on see vigadetundlik ja palju mõttekam oleks see lihtsalt automatiseerida.
Nüüd, kui vajadus PDF-failide teisendamiseks Google'i lehevormiks on selge, vaatame, kuidas PDF-dokumendid on üles ehitatud ja millised on nende sõelumise väljakutsed.
Tahad teisendada pDF failid Google'i arvutustabelid ? Vaadake välja Nanonetsid tasuta PDF-i CSV-muundur. Või uurige, kuidas automatiseerige kogu oma PDF-i töövoog Google'i arvutustabeliteks Nanonetsi abil.
Väljakutsed PDF-dokumendi sõelumisel
Kaasaskantav dokumendivorming oli algselt Adobe välja töötatud failivorming, mis hiljem avaldati avatud standardina. Sellest ajast alates on see laialdaselt kasutusele võetud, kuna see on aluseks oleva operatsioonisüsteemi suhtes agnostiline.
Niisiis, miks on PDF-i sõelumine ja selle sisu teise vormingusse teisendamine nii keeruline? Järgmised pildid räägivad rohkem kui tuhat sõna ja viivad asja koju.
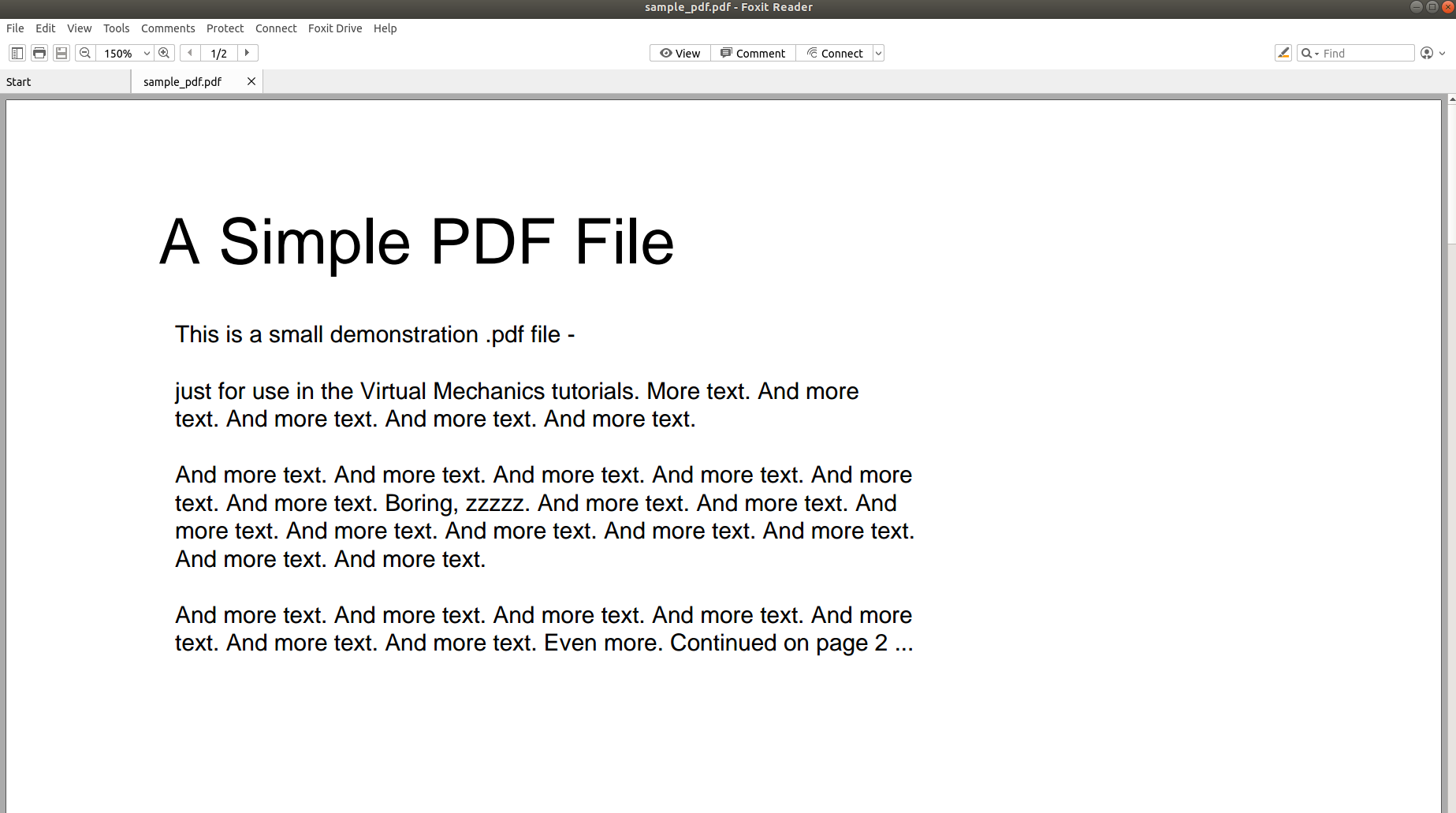
Ülaltoodud pilt näitab PDF-dokumendi ekraanipilti, mis on avatud PDF-lugeja abil. Proovime sama PDF-dokumendi avada tekstiredaktoriga.
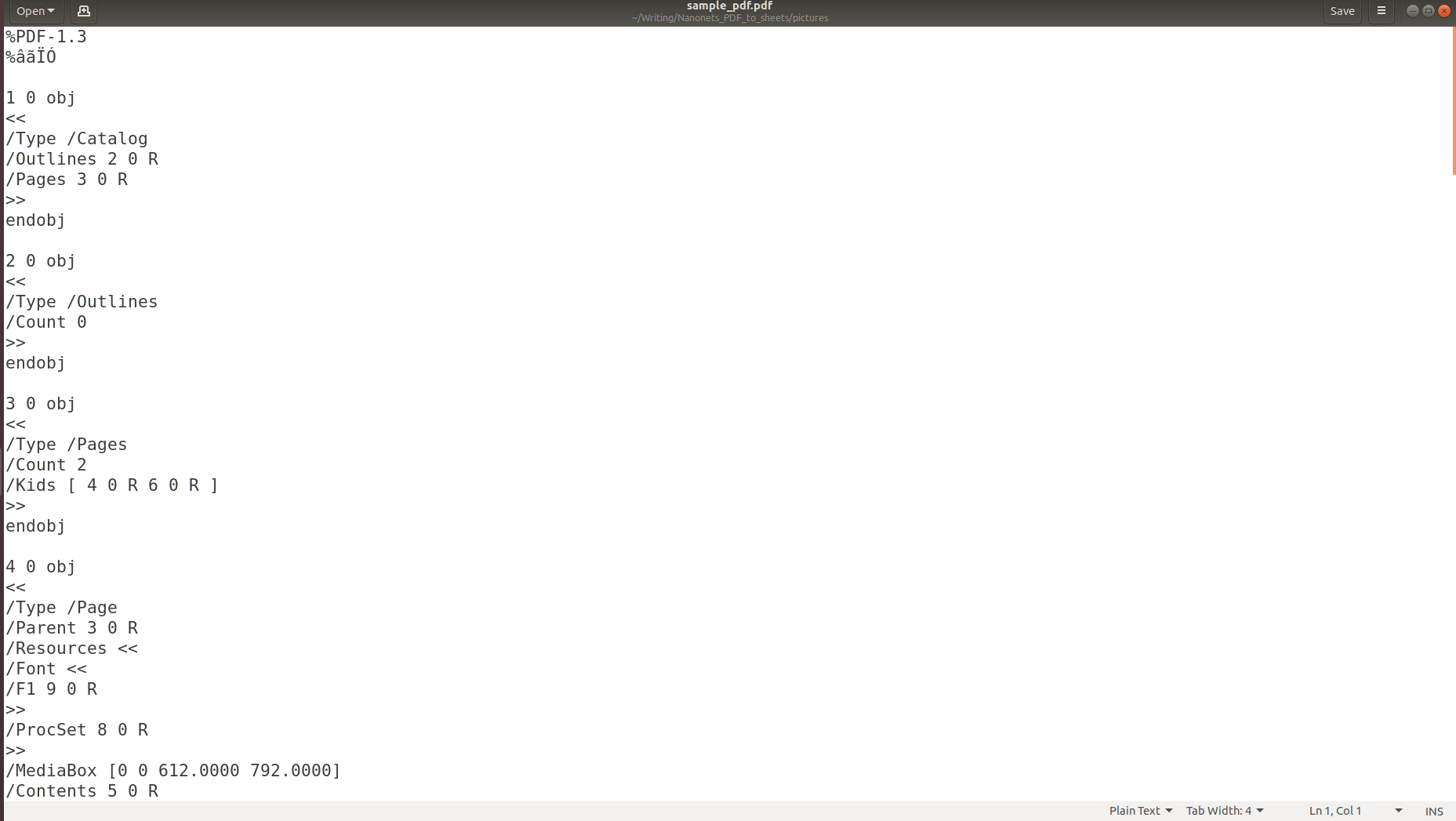
Ülaltoodud piltidelt on selge, et kui teave salvestatakse PDF-i, kaob selle algne struktuur täielikult. Seda seetõttu, et PDF-vorming koosneb lihtsalt juhistest, kuidas lehele märgijada printida/joonistada.
Kui arvate, et teksti ekstraheerimine on keeruline, on tabelites olevate andmete eraldamine veelgi keerulisem, kuna kasutatavad tabelivormingud on väga erinevad.
Loodetavasti olete veendunud, et PDF-dokumendi teisendamine Google'i arvutustabelite vormiks pole lihtsalt jalutuskäik. Järgmises jaotises räägitakse lähenemisviisist, mida enamik kaasaegseid PDF-i parsereid kasutavad PDF-dokumendi teabe tuvastamiseks/parsimiseks.
Kaasaegne lähenemine PDF-dokumentide sõelumisele
Enamik kaasaegseid PDF-i parsereid kasutab PDF-dokumentidest struktureerimata andmete sõelumiseks allpool kirjeldatud voogu.
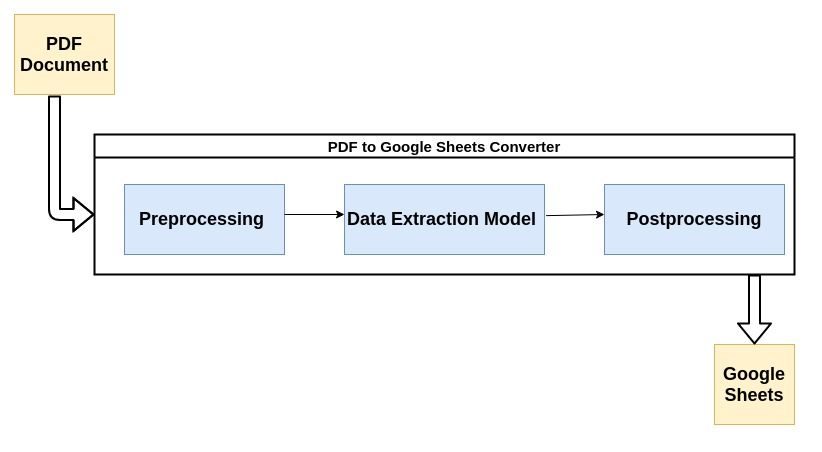
Vaatame lühidalt iga protsessi etappi:
1. Eeltöötlus või andmete puhastamine:
Mida parem teie PDF välja näeb, seda lihtsam on teie masinõppe mudelil välja võtta või andmeid koguma sellest. Näiteks kui PDF-dokument on skannitud, sisaldab see kindlasti mõningaid skannimise artefakte, mis võivad mõjutada muunduri jõudlust.
Müra eemaldamine sobivate filtrite abil, binariseerimine, kalde korrigeerimine jne on mõned kõige levinumad eeltöötlusetapid. Järgmine Nanonetsi postitus Nanonets Tesseract Post sisaldab mõningaid suurepäraseid näiteid selle kohta, kuidas dokumente saab eelnevalt töödelda OCR(OCR) käivitatakse nende peal.
See on koht, kus suurem osa maagiast juhtub. Andmete ekstraheerimine toimub tavaliselt masinõppe (ML) mudeli abil. Enamik PDF-idest andmete eraldamiseks kasutatavaid ML-mudeleid sisaldavad optiliste märgituvastustööriistade, teksti- ja mustrituvastustööriistade jne kombinatsiooni.
Selle postituse jaoks saame mudelit käsitleda musta kastina, mis võtab teie PDF-dokumendi sisendiks ja sülitab välja sõelutud teabe. Lisaks, kuna selle keskmes on ML, saab seda kohandatud andmetega ümber õpetada, et see sobiks teie ettevõtte kasutusjuhtumiga.
3. Järeltöötlus:
Selles etapis teisendatakse ekstraheeritud andmed nõutavasse vormingusse, näiteks CSV, XML, JSON jne. Lisaks AI ennustustele lisatakse kasutaja määratud täiendavad reeglid. See võib hõlmata väljundi vormindamise reegleid, ekstraheeritava teabe täiendavaid piiranguid jne.
Järgmises jaotises vaadeldakse mõningaid mõõdikuid, mida saaksime kasutada PDF-parseri jõudluse mõõtmiseks.
Tahad teisendada pDF failid Google'i arvutustabelid ? Vaadake välja Nanonetsid tasuta PDF-i CSV-muundur. Siit saate teada, kuidas automatiseerida kogu oma PDF-i töövoog Google'i arvutustabeliteks Nanonetsi abil.

Mõõdikud PDF-muunduri jõudluse mõõtmiseks
Kuna enamikku PDF-muundureid kasutatakse arvete töötlemiseks või sellega seotud ülesanneteks, on PDF-dokumendist tabeli ekstraheerimise täpsus ja kiirus kriitilise tähtsusega PDF-muunduri jõudluse hindamisel.
2. Mitmekeelsus:
Enamik suuri ettevõtteid on kohustatud saama arveid mitmes erinevas keeles. PDF-i parser peaks kas toetama mitmekeelset sõelumist või pakkuma valikut, mille abil kasutajad saavad kohandatud andmete abil mudelit koolitada.
3. Integreerimine raamatupidamistarkvaraga:
Ideaalne PDF-muundur peaks olema plug and play moodul, mille saab hõlpsasti olemasolevale lisada dokumendi töövoog. See peaks toetama integreerimist populaarsete raamatupidamistarkvaradega, nagu QuickBooks, Xero, Wave jne.
4. Lihtne ja intuitiivne:
Tööriista kasutavad tõenäoliselt mittetehnilised kasutajad. Oleks kasulik, kui seda saaks kasutada minimaalsete tehniliste teadmistega.
Erinevad meetodid PDF-ide teisendamiseks Google'i arvutustabeliteks
1. Google'i dokumentide kasutamine PDF-i teisendamiseks Google'i arvutustabeliteks
Google Drive'il on sisseehitatud võimalus tuvastada lihtsates PDF-dokumentides tabeleid ja teksti. Peate lihtsalt:
-
Laadige oma PDF-fail üles Google Drive'i
-
Klõpsake "Ava Google Docsiga"
-
Kopeerige soovitud andmed ja kleepige need Google'i arvutustabelitesse
Kuigi tundub, et see töötab hästi, proovime midagi praktilisemat. Mõelge sellele lihtsale arvele.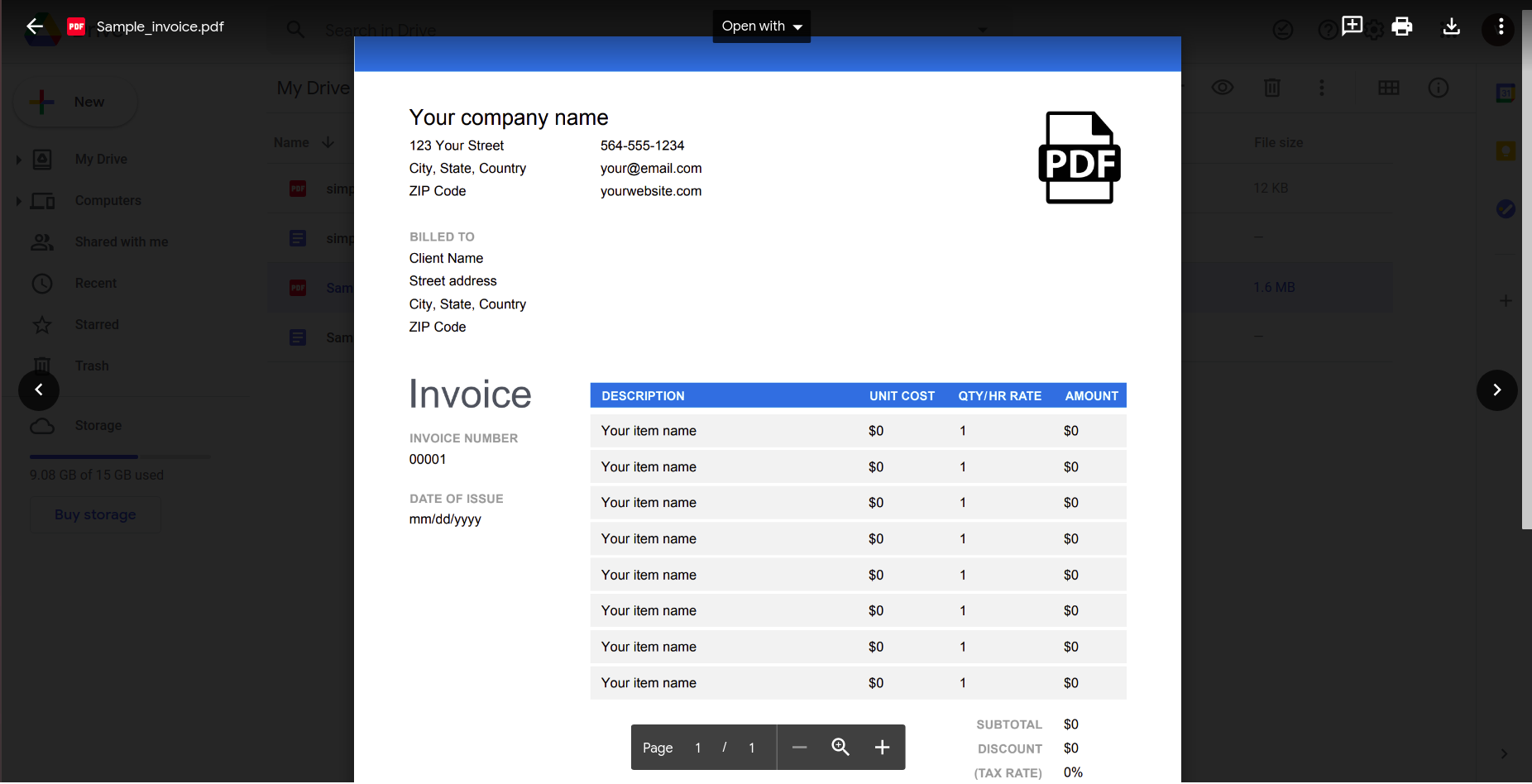
Selle avamine Google docsi rakendusega annab järgmise tulemuse.
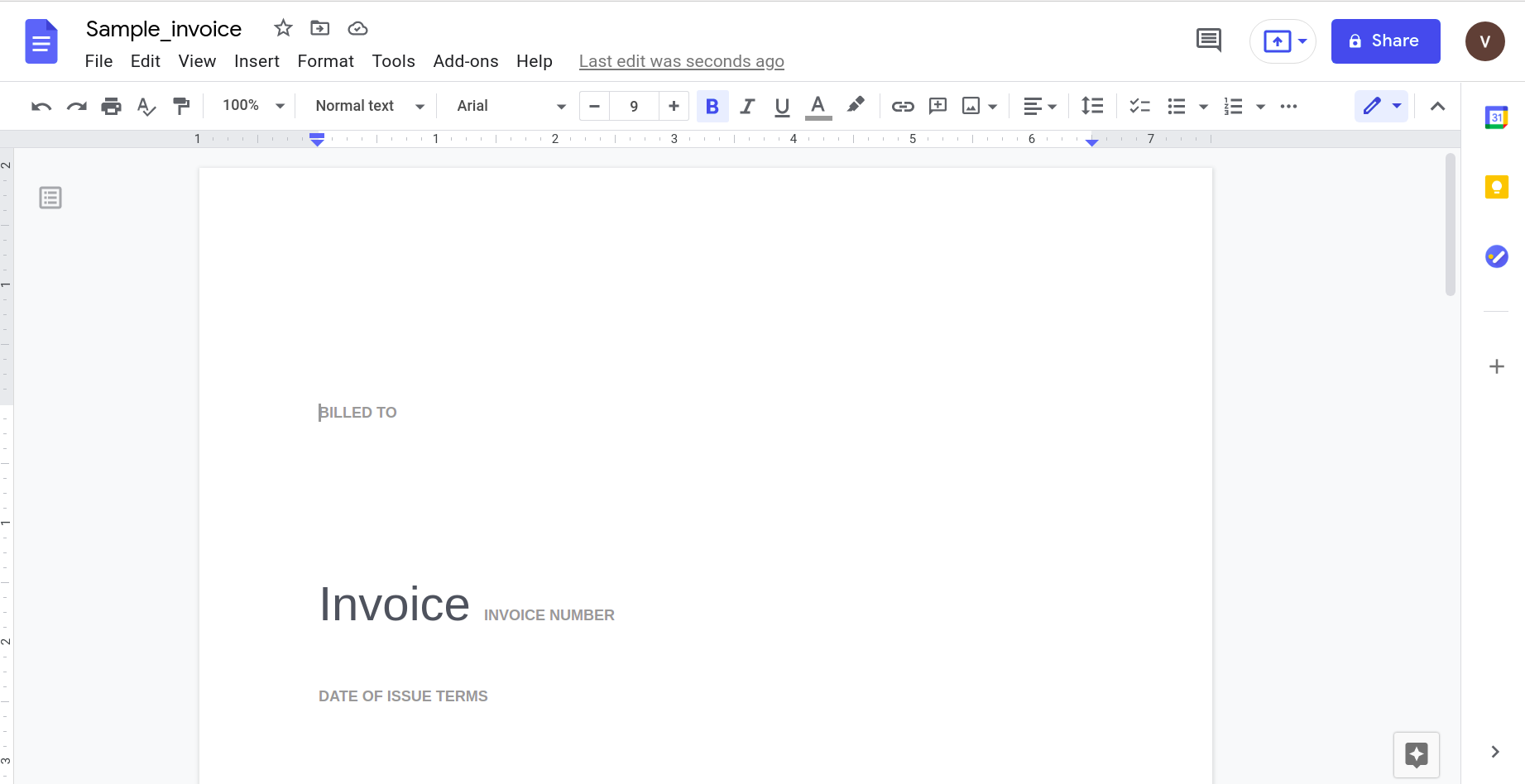
On selge, et dokumendi keerukuse kasvades peame andmete tuvastamiseks toetuma keerukamatele tööriistadele.
2. Võrgutööriistade kasutamine.
Mitmed võrgutööriistad, nagu PDF-tabelite ekstraktor, Online2PDF jne, integreeruvad otse Google Drive'iga ja pakuvad kohe võimalust PDF-dokumentide teisendamiseks Google'i arvutustabeliteks.
Kuid kui neid tööriistu testiti ülaltoodud arve PDF-i näidisfaili abil, siis enamikul juhtudel tabeleid ei tuvastatud.
Tahad teisendada pDF failid Google'i arvutustabelid ? Vaadake välja Nanonetsid tasuta PDF-i CSV-muundur. Siit saate teada, kuidas automatiseerida kogu oma PDF-i töövoogu Google'i arvutustabeliteks Nanonetsi abil, nagu allpool näidatud.
PDF-faili Google'i arvutustabeliteks teisendusprotsessi automatiseerimine
Saame täielikult automatiseerida PDF-i sõelumise ja andmete Google'i arvutustabelite vormi ekstraktimise protsessi, kasutades järgmisi tööriistu.
1. Veebihaagide kasutamine.
Veebihaagid on kohandatud HTTP-päringud. Need käivituvad tavaliselt sündmusel, st sündmuse toimumisel saadab rakendus teabe eelmääratletud URL-ile.
Kuidas saate seda oma töövoo automatiseerimiseks kasutada? Vaatleme arvete töötlemise tüüpilist kasutusjuhtu. Saate oma tarnijatelt mitmeid arveid ja sisestate need oma PDF-i Google'i arvutustabelite teisendajasse, mis asub pilves. Kuidas teada saada, kui mudel on dokumentide töötlemise lõpetanud?
Selle asemel, et käsitsi kontrollida, kas teisendamine on lõpule viidud, võite lihtsalt kasutada veebihaagi, mis teavitab teid, kui PDF-is olevad andmed on Google'i arvutustabelite dokumenti ekstraktitud.
2. API-de kasutamine
API tähistab rakenduste programmeerimisliidest. Sobivate API-kutsete abil võib PDF-dokumentide teisendamine Google'i arvutustabeliteks osutuda sama lihtsaks kui järgmiste koodiridade kirjutamine.
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Kui teie ettevõte on Webhooksiga integreerimise juba seadistanud, saate teate, kui teie PDF-dokumendid on edukalt teisendatud. Seejärel saate allpool näidatud API abil alla laadida Google'i arvutustabelite vormi.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF nanovõrkudega Google'i arvutustabelitesse
Nanonetsi PDF-parser muudab sõelumise ja teisendamise lihtsaks ja täpseks. Näidisarve sõelumiseks kasutati PDF-parserit. See jaotis näitab tööriista kasutusmugavust ja täpsust. Selle asemel, et rääkida sellest, kui suurepärane see on, illustreerivad järgmised pildid asja tabavalt.
Allolev pilt on ekraanipilt näidisarvest, mis edastati Nanonetsi PDF-i parserisse.
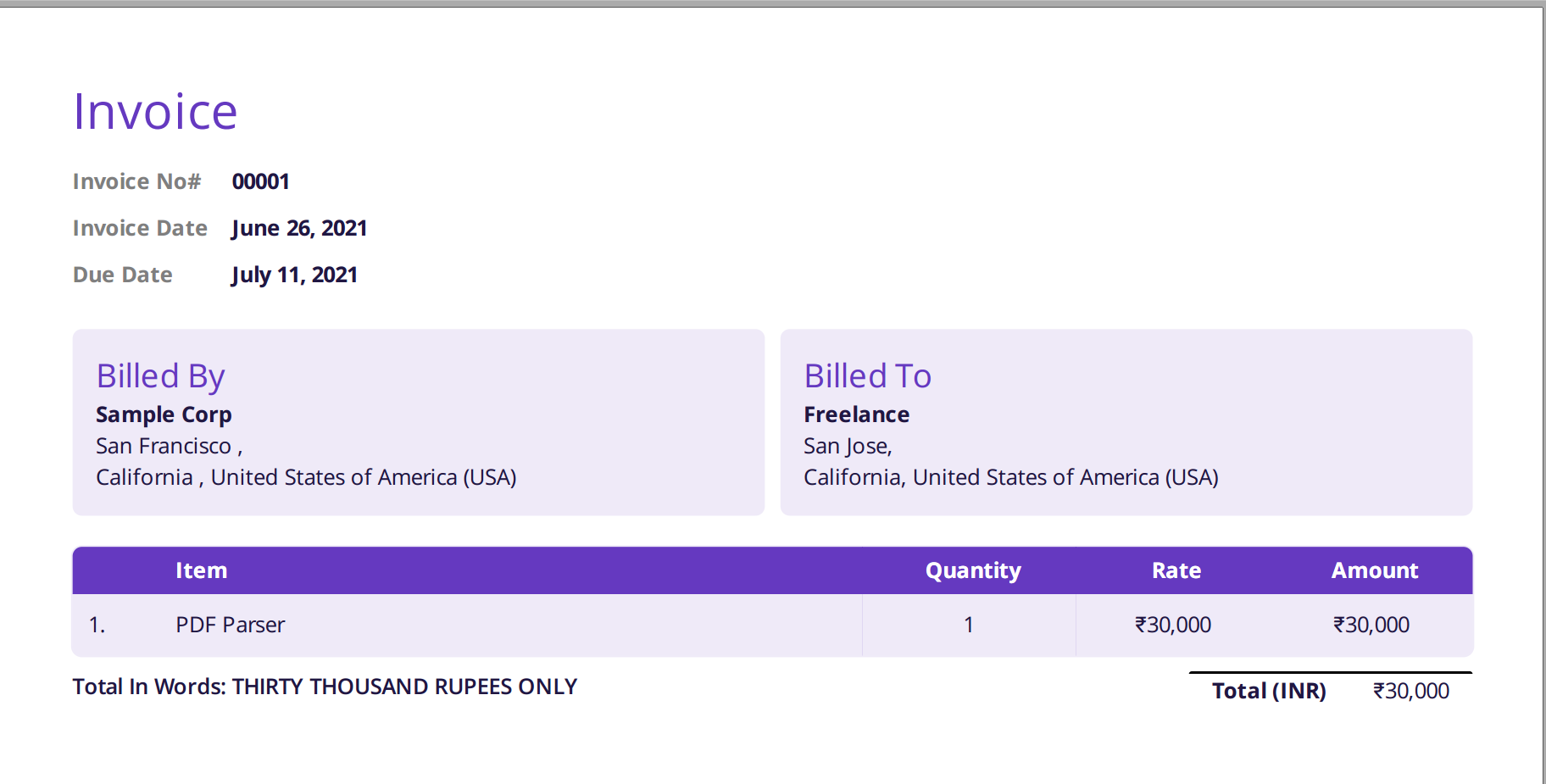
Lihtsalt navigeerige Nanonetsi veebisaidile ja laadige arve üles. Teisendamine võtab vaid mõne sekundi, pärast mida saab sõelutud andmed alla laadida erinevates vormingutes, näiteks CSV, XLSX jne (vaadake Nanonets'i PDF-i CSV-muundur)
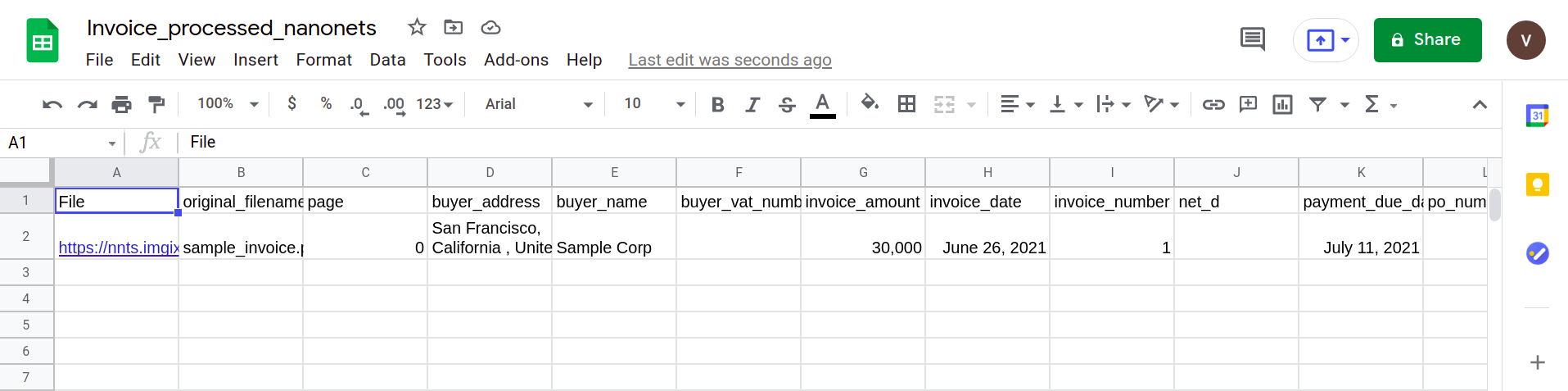
Järgmisel pildil on kuvatõmmis CSV-failist, mis sisaldab PDF-dokumendi sõelutud andmeid.

Lõpuks tuleb CSV-faili teisendamiseks Google'i lehtede vormiks lihtsalt XLSX/CSV-fail oma Google'i draivi üles laadida. Seda sammu saab automatiseerida, kasutades Google Drive'i API-sid.
Järgmises jaotises näidatakse, kuidas Nanonetsi PDF-parserit kasutades saab luua lihtsa torujuhtme.
Kas soovite PDF-dokumentidest teavet eraldada ja need Google'i arvutustabelite dokumendiks teisendada/lisada? Vaadake Nanonetsit™ mis tahes teabe automatiseerimiseks mis tahes PDF-dokumendist Google'i arvutustabelitesse!
Lihtsa torujuhtme loomine
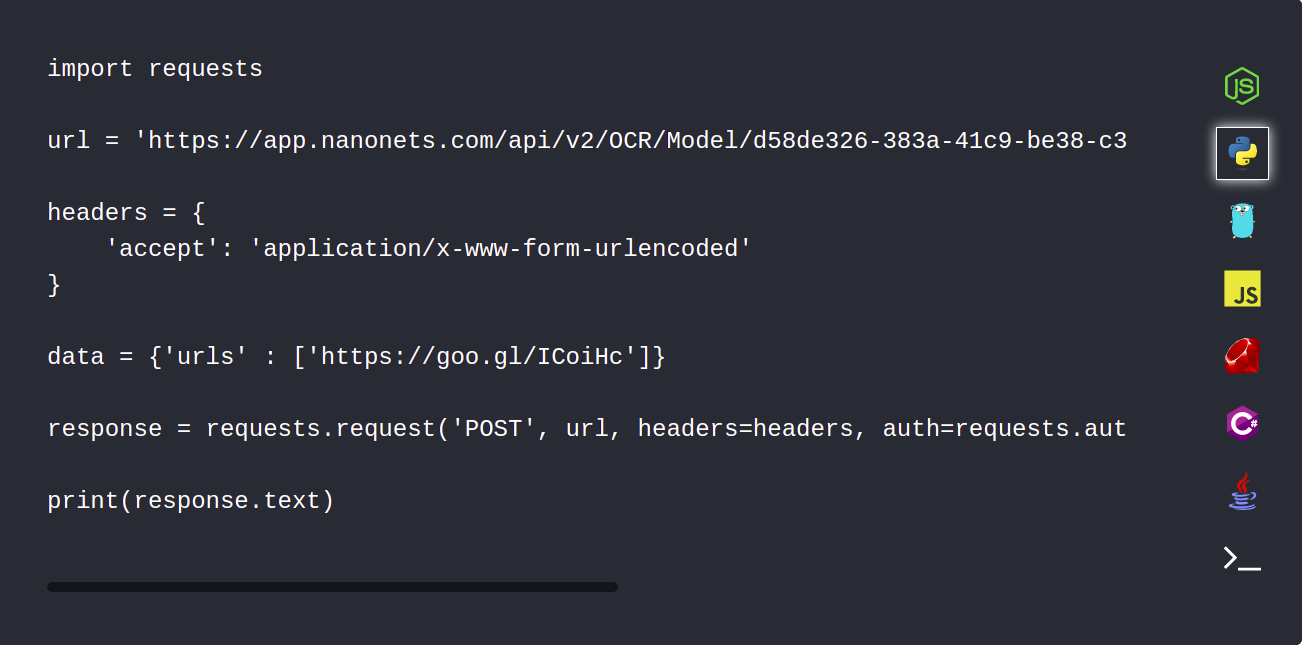
1. Laadige oma PDF-dokumendid Nanonets API abil automaatselt üles
Nanonets API võimaldab teil oma dokumente, mis tuleb sõeluda, automaatselt üles laadida. Järgmine koodilõik näitab, kuidas seda pythoni abil teha.
2. Kasutage parsimise lõpetamise kohta teatise saamiseks veebihaagide integreerimist
Veebihaake saab konfigureerida nii, et need teavitaksid teid automaatselt, kui dokumendid on sõelutud.
3. Vaadake üle ja laadige Google'i arvutustabelitesse üles
Laadige alla ja vaadake üle CSV-failid, veendumaks, et kõik on korras, ning laadige andmed Google Drive'i API abil Google'i arvutustabelitesse üles.
Nanonets Edge
Siin on mõned Nanonets PDF Parseri funktsioonid, mis muudavad selle teie ettevõtte jaoks ideaalseks tööriistaks.
1. Välised integratsioonid:
Nanovõrkude mudelit saab hõlpsasti integreerida MySql-i, Quickbookide, Salesforce'i jne. See tähendab, et teie praegune töövoog jääb häirimatuks ja nanovõrkude muunduri saab lihtsalt lisamoodulina ühendada.
2. Suur täpsus ja madal töötlemisaeg:
Nanonetsi PDF-parseri tööriista täpsus on üle 95%+, mis on konkurentidega võrreldes palju suurem.
3. Lahedad järeltöötlusfunktsioonid:
Oletame, et teie andmebaas on integreeritud nanovõrkude mudeliga. Mudel täidab automaatselt mõned väljad (teie andmebaasi andmetega) dokumendist eraldatud andmete põhjal. Näiteks:
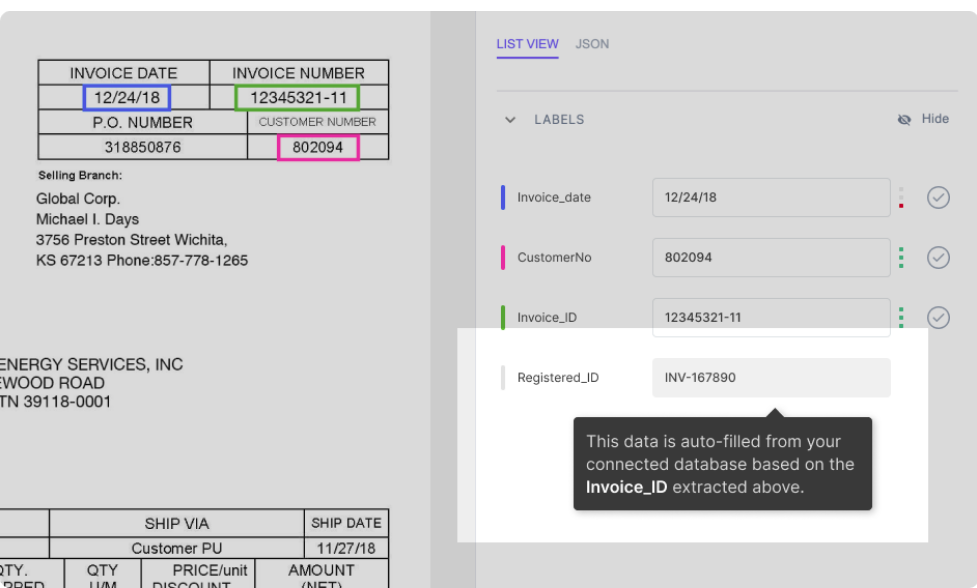
Nagu on näidatud joonisel, täidetakse väli Registreeritud_ID automaatselt (andmebaasiotsinguga) PDF-failist ekstraheeritud arve_ID alusel.
4. Lihtne ja intuitiivne liides
Kuigi see funktsioon on alahinnatud, leidsin, et kasutajaliides ja UX on õiged. Kogu registreerumise, dokumendi üleslaadimise ja andmete sõelumise protsess võttis aega vähem kui 5 minutit. See on peaaegu võrdne ajaga, mis minu sülearvuti käivitamiseks kulub!
5. Tohutu kliendibaas
Kui teil on töövoo automatiseerimiseks Nanonetsi kasutamise suhtes endiselt kahtlusi, vaadake lihtsalt mõnda ettevõtet, kes nende teenuseid kasutavad.
- Deloitte
- sherwin Williams
- DoorDash
- P&G
Kas soovite PDF-dokumentidest teavet eraldada ja need Google'i arvutustabelite dokumendiks teisendada/lisada? Vaadake Nanonetsit™ mis tahes teabe automatiseerimiseks mis tahes PDF-dokumendist Google'i arvutustabelitesse!
Järeldus
Selles postituses vaatlesime, kuidas saate oma töövoogu automatiseerida, kasutades PDF-i teisendajat Google'i arvutustabeliteks. Algselt saime teada vajadusest teisendada PDF-dokumendid Google'i arvutustabeliteks, millele järgnesid selle protsessi käigus tekkinud väljakutsed. Seejärel sukeldusime lähenemisviisidesse, mida kaasaegsed parserid PDF-dokumentide sõelumisel kasutavad, ja rakendasime ka mõningaid levinud lähenemisviise. Samuti õppisime, kuidas me saame konversiooni täielikult automatiseerida, kasutades väliseid integratsioone, nagu veebihaagid ja API-d. Lõpuks kasutasime Nanonetsi tööriista näidisarve sõelumiseks, andmete eraldamiseks Google'i arvutustabelite vormi ja uurisime ka selle lahedaid järeltöötlusfunktsioone.
Kas olete Nanonetsi mudelit proovinud? Kui jah, siis jätke allpool kommentaar selle tööriista kasutamise kohta. Kui ei, siis proovige seda. See võib lihtsalt muuta teie päeva paremaks!
- AI
- Tehisintellekt ja masinõpe
- ai kunst
- ai kunsti generaator
- on robot
- tehisintellekti
- tehisintellekti sertifikaat
- tehisintellekt panganduses
- tehisintellekti robot
- tehisintellekti robotid
- tehisintellekti tarkvara
- blockchain
- plokiahela konverents ai
- coingenius
- vestluslik tehisintellekt
- krüptokonverents ai
- dall's
- sügav õpe
- google ai
- masinõpe
- pdf Google'i lehtedesse
- Platon
- plato ai
- Platoni andmete intelligentsus
- Platoni mäng
- PlatoData
- platogaming
- skaala ai
- süntaks
- sephyrnet