معرفی
سیستمهای هوش مصنوعی به شدت به استنتاج سریع متکی هستند. APIهای استنتاج از رهبران صنعت مانند OpenAI، Google و Azure تصمیم گیری سریع را امکان پذیر می کنند. فناوری واحد پردازش زبان (LPU) Groq یک راه حل برجسته است که کارایی پردازش هوش مصنوعی را افزایش می دهد. این مقاله به فناوری نوآورانه Groq، تأثیر آن بر سرعت استنتاج هوش مصنوعی و نحوه استفاده از آن با استفاده از Groq API می پردازد.
اهداف یادگیری
- با فناوری واحد پردازش زبان (LPU) Groq و تاثیر آن بر سرعت استنتاج هوش مصنوعی آشنا شوید
- بیاموزید که چگونه از نقاط پایانی API Groq برای کارهای پردازش هوش مصنوعی در زمان واقعی و با تاخیر کم استفاده کنید.
- قابلیتهای مدلهای پشتیبانیشده Groq، مانند Mixtral-8x7b-Instruct-v0.1 و Llama-70b را برای درک و تولید زبان طبیعی بررسی کنید.
- مقایسه و مقایسه سیستم LPU Groq با سایر APIهای استنتاج، بررسی عواملی مانند سرعت، کارایی و مقیاس پذیری
این مقاله به عنوان بخشی از بلاگاتون علم داده.
جدول محتوا
گروک چیست؟
در 2016 تاسیس شد، گروک یک استارتاپ راه حل های هوش مصنوعی مستقر در کالیفرنیا است که دفتر مرکزی آن در Mountain View واقع شده است. Groq که در استنتاج هوش مصنوعی با تأخیر بسیار کم تخصص دارد، عملکرد محاسباتی هوش مصنوعی را به طور قابل توجهی ارتقا داده است. Groq یک شرکت کننده برجسته در فضای فناوری هوش مصنوعی است که نام خود را به عنوان یک علامت تجاری به ثبت رسانده و یک تیم جهانی متعهد به دموکراتیک کردن دسترسی به هوش مصنوعی تشکیل داده است.
واحدهای پردازش زبان
واحد پردازش زبان Groq (LPU)، یک فناوری نوآورانه، با هدف افزایش عملکرد محاسباتی هوش مصنوعی، بهویژه برای مدلهای زبان بزرگ (LLM) است. سیستم Groq LPU در تلاش است تا تجربیاتی را در زمان واقعی و با تأخیر کم با عملکرد استنتاج استثنایی ارائه دهد. Groq در مدل Llama-300 2B متا AI به بیش از 70 توکن در ثانیه در هر کاربر دست یافت و معیار جدیدی در صنعت ایجاد کرد.
سیستم Groq LPU دارای قابلیتهای تأخیر بسیار کم است که برای فناوریهای پشتیبانی هوش مصنوعی ضروری است. به طور خاص برای پردازش زبان GenAI متوالی و فشرده طراحی شده است، از راه حل های GPU معمولی بهتر عمل می کند و از پردازش کارآمد برای کارهایی مانند ایجاد و درک زبان طبیعی اطمینان می دهد.
نسل اول GroqChip، بخشی از سیستم LPU، دارای معماری جریان تانسور است که برای سرعت، کارایی، دقت و مقرون به صرفه بودن بهینه شده است. این تراشه از راه حل های فعلی پیشی می گیرد و رکوردهای جدیدی را در سرعت پایه LLM که بر حسب توکن در ثانیه برای هر کاربر اندازه گیری می شود، ثبت می کند. Groq با برنامه ریزی برای استقرار یک میلیون تراشه استنتاج هوش مصنوعی طی دو سال، تعهد خود را به پیشرفت فناوری های شتاب هوش مصنوعی نشان می دهد.
به طور خلاصه، سیستم واحد پردازش زبان Groq نشاندهنده پیشرفت قابل توجهی در فناوری محاسبات هوش مصنوعی است که عملکرد و کارایی فوقالعادهای را برای مدلهای زبان بزرگ ارائه میکند و در عین حال نوآوری در هوش مصنوعی را ایجاد میکند.
همچنین خواندن: ساخت مدل ML در AWS SageMaker
شروع کار با Groq
در حال حاضر، Groq در حال ارائه نقاط پایانی API با استفاده رایگان برای مدل های زبان بزرگ در حال اجرا در Groq LPU – واحد پردازش زبان است. برای شروع به این سایت مراجعه کنید با ما و روی login کلیک کنید. صفحه شبیه به صفحه زیر است:
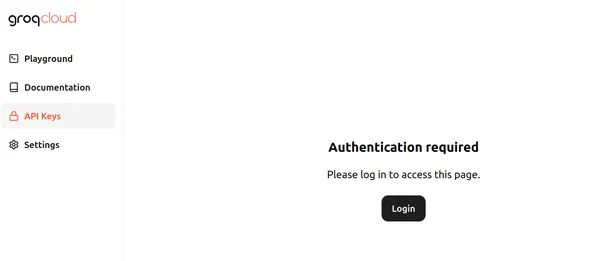
روی ورود کلیک کنید و یکی از روش های مناسب را برای ورود به Groq انتخاب کنید. سپس می توانیم با کلیک بر روی دکمه Create API Key یک API جدید مانند شکل زیر ایجاد کنیم
در مرحله بعد، یک نام به کلید API اختصاص دهید و برای ایجاد یک کلید API جدید، روی "submit" کلیک کنید. اکنون، به هر ویرایشگر کد/Colab بروید و کتابخانه های مورد نیاز را برای شروع استفاده از Groq نصب کنید.
!pip install groqاین دستور کتابخانه Groq را نصب میکند و به ما امکان میدهد مدلهای زبان بزرگ را که روی LPUهای Groq اجرا میشوند، استنباط کنیم.
حالا بیایید با کد ادامه دهیم.
پیاده سازی کد
# Importing Necessary Libraries
import os
from groq import Groq
# Instantiation of Groq Client
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)این قطعه کد یک شی مشتری Groq را برای تعامل با Groq API ایجاد می کند. با بازیابی کلید API از یک متغیر محیطی به نام GROQ_API_KEY شروع می شود و آن را به آرگومان api_key ارسال می کند. متعاقباً، کلید API شی مشتری Groq را مقداردهی اولیه می کند و فراخوانی های API به مدل های زبان بزرگ در سرورهای Groq را فعال می کند.
تعریف LLM ما
llm = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful AI Assistant. You explain ever
topic the user asks as if you are explaining it to a 5 year old"
},
{
"role": "user",
"content": "What are Black Holes?",
}
],
model="mixtral-8x7b-32768",
)
print(llm.choices[0].message.content)- خط اول یک شی llm را مقداردهی اولیه می کند، و تعامل با مدل زبان بزرگ، مشابه OpenAI Chat Completion API را امکان پذیر می کند.
- کد بعدی فهرستی از پیامهای ارسالی به LLM را میسازد که در متغیر پیامها ذخیره میشود.
- اولین پیام نقش را به عنوان "سیستم" اختصاص می دهد و رفتار مطلوب LLM را برای توضیح موضوعات مانند یک کودک 5 ساله تعریف می کند.
- پیام دوم نقش "کاربر" را اختصاص می دهد و شامل سوال در مورد سیاهچاله ها می شود.
- خط زیر LLM مورد استفاده برای تولید پاسخ را مشخص میکند که روی «mixtral-8x7b-32768» تنظیم شده است.
- خروجی این کد پاسخی از LLM خواهد بود که سیاهچاله ها را به شیوه ای مناسب برای درک یک کودک 5 ساله توضیح می دهد.
- دسترسی به خروجی از رویکردی مشابه کار با نقطه پایانی OpenAI پیروی می کند.
تولید
در زیر خروجی تولید شده توسط مدل زبان بزرگ Mixtral-8x7b-Instruct-v0.1 نشان داده شده است:

La completions.create() شی حتی می تواند پارامترهای اضافی مانند درجه حرارت, top_pو max_tokens.
ایجاد یک پاسخ
بیایید سعی کنیم پاسخی با این پارامترها ایجاد کنیم:
llm = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful AI Assistant. You explain ever
topic the user asks as if you are explaining it to a 5 year old"
},
{
"role": "user",
"content": "What is Global Warming?",
}
],
model="mixtral-8x7b-32768",
temperature = 1,
top_p = 1,
max_tokens = 256,
)- درجه حرارت: تصادفی بودن پاسخ ها را کنترل می کند. دمای پایینتر منجر به خروجیهای قابل پیشبینیتر میشود، در حالی که دمای بالاتر منجر به خروجیهای متنوعتر و گاهی خلاقتر میشود.
- max_tokens: حداکثر تعداد نشانه هایی که مدل می تواند در یک پاسخ پردازش کند. این محدودیت کارایی محاسباتی و مدیریت منابع را تضمین می کند
- top_p: روشی برای تولید متن که توکن بعدی را از توزیع احتمال p به احتمال زیاد توکن انتخاب می کند. این اکتشاف و بهره برداری را در طول تولید متعادل می کند
تولید

حتی گزینه ای برای پخش پاسخ های تولید شده از نقطه پایانی Groq وجود دارد. فقط باید مشخص کنیم جریان = درست است گزینه در completions.create() شیء برای مدل برای شروع جریان پاسخ ها.
Groq در Langchain
Groq حتی با LangChain سازگار است. برای شروع استفاده از Groq در LangChain، کتابخانه را دانلود کنید:
!pip install langchain-groqموارد فوق کتابخانه Groq را برای سازگاری با LangChain نصب می کند. حالا بیایید آن را در کد امتحان کنیم:
# Import the necessary libraries.
from langchain_core.prompts import ChatPromptTemplate
from langchain_groq import ChatGroq
# Initialize a ChatGroq object with a temperature of 0 and the "mixtral-8x7b-32768" model.
llm = ChatGroq(temperature=0, model_name="mixtral-8x7b-32768")کد بالا کارهای زیر را انجام می دهد:
- یک شی ChatGroq جدید به نام llm ایجاد می کند
- تنظیم می کند درجه حرارت پارامتر به 0، نشان می دهد که پاسخ ها باید قابل پیش بینی تر باشند
- تنظیم می کند نام مدل پارامتر به "mixtral-8x7b-32768"، مشخص کردن مدل زبان مورد استفاده
# پیام سیستمی که قابلیت های دستیار هوش مصنوعی را معرفی می کند را تعریف کنید.
# Define the system message introducing the AI assistant's capabilities.
system = "You are an expert Coding Assistant."
# Define a placeholder for the user's input.
human = "{text}"
# Create a chat prompt consisting of the system and human messages.
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", human)])
# Invoke the chat chain with the user's input.
chain = prompt | llm
response = chain.invoke({"text": "Write a simple code to generate Fibonacci numbers in Rust?"})
# Print the Response.
print(response.content)- کد با استفاده از کلاس ChatPromptTemplate یک Chat Prompt ایجاد می کند.
- این درخواست شامل دو پیام است: یکی از "سیستم" (دستیار هوش مصنوعی) و دیگری از "انسان" (کاربر).
- پیام سیستم، دستیار هوش مصنوعی را به عنوان یک دستیار کدنویسی خبره معرفی می کند.
- پیام انسانی به عنوان یک مکان نگهدار برای ورودی کاربر عمل می کند.
- متد llm زنجیره llm را فراخوانی می کند تا بر اساس Prompt ارائه شده و ورودی کاربر، پاسخی تولید کند.
تولید
در اینجا خروجی تولید شده توسط مدل زبان بزرگ Mixtral است:

Mixtral LLM به طور مداوم پاسخ های مرتبط را ایجاد می کند. تست کد در Rust Playground کارایی آن را تایید می کند. پاسخ سریع به واحد پردازش زبان (LPU) نسبت داده می شود.
Groq در مقابل سایر APIهای استنتاج
سیستم واحد پردازش زبان (LPU) Groq با هدف ارائه سرعت استنتاج بسیار سریع برای مدلهای زبان بزرگ (LLM) از دیگر APIهای استنتاج مانند آنچه توسط OpenAI و Azure ارائه میشود، پیشی میگیرد. سیستم LPU Groq که برای LLM ها بهینه شده است، قابلیت های تأخیر بسیار کم را فراهم می کند که برای فناوری های کمکی هوش مصنوعی بسیار مهم است. این گلوگاه های اصلی LLM ها، از جمله چگالی محاسباتی و پهنای باند حافظه را برطرف می کند و امکان تولید سریعتر دنباله های متنی را فراهم می کند.
در مقایسه با سایر APIهای استنتاج، سیستم LPU Groq سریعتر است، با توانایی تولید تا 18 برابر عملکرد استنتاج سریعتر در تابلوی برتر LLMPerf Anyscale در مقایسه با سایر ارائه دهندگان برتر مبتنی بر ابر. سیستم LPU Groq نیز کارآمدتر است، با معماری تک هستهای و شبکههای همزمان حفظ شده در مقیاسهای بزرگ که امکان کامپایل خودکار LLMها و دسترسی فوری به حافظه را فراهم میکند.
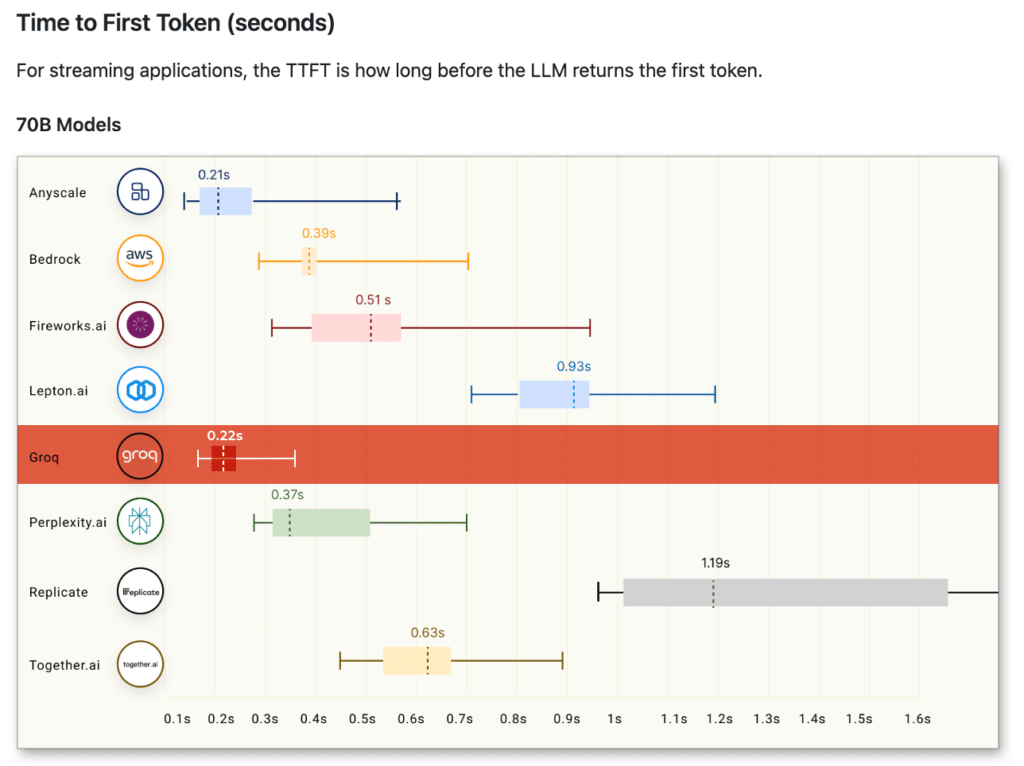
تصویر بالا معیارهایی را برای مدل های 70B نمایش می دهد. محاسبه توان عملیاتی توکن های خروجی شامل میانگین تعداد توکن های خروجی برگردانده شده در هر ثانیه است. هر ارائهدهنده استنتاج LLM 150 درخواست را برای جمعآوری نتایج پردازش میکند و میانگین توان خروجی توکنهای خروجی با استفاده از این درخواستها محاسبه میشود. عملکرد بهبود یافته ارائهدهنده استنتاج LLM با توان عملیاتی بالاتر توکنهای خروجی نشان داده میشود. واضح است که توکن های خروجی Groq در هر ثانیه از بسیاری از ارائه دهندگان ابری نمایش داده شده بهتر عمل می کنند.
نتیجه
در پایان، سیستم واحد پردازش زبان (LPU) Groq به عنوان یک فناوری انقلابی در حوزه محاسبات هوش مصنوعی برجسته است که سرعت و کارایی بیسابقهای را برای مدیریت مدلهای زبان بزرگ (LLM) و ایجاد نوآوری در زمینه هوش مصنوعی ارائه میدهد. Groq با استفاده از قابلیتهای تأخیر بسیار کم و معماری بهینهشده، معیارهای جدیدی را برای سرعت استنتاج تعیین میکند و از راهحلهای GPU معمولی و دیگر APIهای استنتاج پیشرو در صنعت بهتر عمل میکند. Groq با تعهد خود به دموکراتیک کردن دسترسی به هوش مصنوعی و تمرکز بر تجربیات زمان واقعی و کم تاخیر، آماده است تا چشم انداز فناوری های شتاب هوش مصنوعی را تغییر دهد.
گیرنده های کلیدی
- سیستم واحد پردازش زبان (LPU) Groq سرعت و کارایی بینظیری را برای استنتاج هوش مصنوعی، بهویژه برای مدلهای زبان بزرگ (LLM) ارائه میکند و تجربههای بیدرنگ و با تأخیر کم را امکانپذیر میکند.
- سیستم LPU Groq، که دارای GroqChip است، دارای قابلیت تاخیر بسیار کم است که برای فناوریهای پشتیبانی هوش مصنوعی ضروری است و از راهحلهای GPU معمولی بهتر عمل میکند.
- Groq با برنامه ریزی برای استقرار 1 میلیون تراشه استنتاج هوش مصنوعی طی دو سال، تعهد خود را به پیشرفت فناوری های شتاب هوش مصنوعی و دموکراتیک کردن دسترسی به هوش مصنوعی نشان می دهد.
- Groq نقاط پایانی API با استفاده رایگان را برای مدلهای زبان بزرگی که روی Groq LPU اجرا میشوند، فراهم میکند و توسعهدهندگان را برای ادغام با پروژههای خود در دسترس قرار میدهد.
- سازگاری Groq با LangChain و LlamaIndex قابلیت استفاده آن را بیشتر گسترش می دهد و یکپارچه سازی یکپارچه را برای توسعه دهندگانی که به دنبال استفاده از فناوری Groq در وظایف پردازش زبان خود هستند ارائه می دهد.
پرسش و پاسخهای متداول
A. Groq در استنتاج هوش مصنوعی با تأخیر بسیار کم، به ویژه برای مدل های زبان بزرگ (LLM) متخصص است و هدف آن انقلابی کردن عملکرد محاسباتی هوش مصنوعی است.
سیستم LPU A. Groq که دارای GroqChip است، به طور خاص برای ماهیت محاسباتی پردازش زبان GenAI طراحی شده است و سرعت، کارایی و دقت بالاتری را در مقایسه با راه حل های GPU سنتی ارائه می دهد.
A. Groq طیف وسیعی از مدلها را برای استنتاج هوش مصنوعی پشتیبانی میکند، از جمله Mixtral-8x7b-Instruct-v0.1 و Llama-70b.
پاسخ. بله، Groq با LangChain و LlamaIndex سازگار است، قابلیت استفاده آن را گسترش داده و یکپارچه سازی یکپارچه را برای توسعه دهندگانی که به دنبال استفاده از فناوری Groq در وظایف پردازش زبان خود هستند، ارائه می دهد.
سیستم LPU A. Groq از نظر سرعت و کارایی از سایر APIهای استنتاج پیشی می گیرد و سرعت استنتاج تا 18 برابر سریعتر و عملکرد عالی را ارائه می دهد، همانطور که توسط معیارهای موجود در تابلوی برتر LLMPerf Anyscale نشان داده شده است.
رسانه نشان داده شده در این مقاله متعلق به Analytics Vidhya نیست و به صلاحدید نویسنده استفاده می شود.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.analyticsvidhya.com/blog/2024/03/getting-started-with-groq-api/
- : دارد
- :است
- :نه
- ][پ
- $UP
- 1
- 10
- 11
- 14
- 150
- 20
- 2016
- 300
- 5
- 9
- a
- توانایی
- درباره ما
- بالاتر
- شتاب
- دسترسی
- در دسترس
- دقت
- دست
- اضافی
- آدرس
- پیشرفته
- پیشرفت
- پیشبرد
- AI
- دستیار هوش مصنوعی
- سیستم های هوش مصنوعی
- هدف
- اهداف
- اجازه دادن
- همچنین
- an
- علم تجزیه و تحلیل
- تجزیه و تحلیل Vidhya
- و
- هر
- API
- رابط های برنامه کاربردی
- روش
- مناسب
- معماری
- هستند
- استدلال
- مقاله
- AS
- خواسته
- مونتاژ
- اختصاص دادن
- کمک
- دستیار
- At
- در دسترس
- میانگین
- AWS
- لاجوردی
- تعادل
- پهنای باند
- مستقر
- BE
- شروع
- آغاز می شود
- رفتار
- در زیر
- محک
- معیار
- سیاه پوست
- سیاه چاله ها
- بلاگاتون
- می افتد
- تنگناها
- by
- محاسبه
- محاسبه
- تماس ها
- CAN
- قابلیت های
- زنجیر
- گپ
- تراشه
- چیپس
- را انتخاب کنید
- کلاس
- واضح
- کلیک
- کلیک کردن
- مشتری
- ابر
- رمز
- برنامه نویسی
- تعهد
- مرتکب شده
- مقايسه كردن
- مقایسه
- مقایسه
- سازگاری
- سازگار
- اتمام
- شامل
- محاسباتی
- محاسبه
- محاسبه
- نتیجه
- همواره
- شامل
- می سازد
- محتوا
- زمینه
- کنتراست
- گروه شاهد
- معمولی
- هسته
- ایجاد
- ایجاد
- خالق
- بسیار سخت
- تصمیم گیری
- فداکاری
- تعريف كردن
- تعریف می کند
- ارائه
- تحویل
- غوطه ور شدن
- دموکراتیک کردن
- نشان
- نشان می دهد
- چگالی
- گسترش
- اعزام ها
- طراحی
- مطلوب
- توسعه دهندگان
- متفاوت است
- اختیار
- نمایش داده
- صفحه نمایش
- توزیع
- do
- میکند
- دانلود
- رانندگی
- در طی
- هر
- بهره وری
- موثر
- قادر ساختن
- را قادر می سازد
- نقطه پایانی
- نقاط پایان
- بالا بردن
- افزایش
- تضمین می کند
- حصول اطمینان از
- محیط
- ضروری است
- ایجاد می کند
- اتر (ETH)
- حتی
- تا کنون
- در حال بررسی
- استثنایی
- گسترش
- گسترش می یابد
- تجارب
- کارشناس
- توضیح دهید
- توضیح دادن
- بهره برداری
- اکتشاف
- عوامل
- FAST
- سریعتر
- سریعترین
- امکانات
- ویژگی های
- فیبوناچی
- رشته
- نام خانوادگی
- تمرکز
- پیروی
- به دنبال آن است
- برای
- بنیادین
- از جانب
- قابلیت
- بیشتر
- جمع آوری
- جنایی
- تولید می کنند
- تولید
- تولید می کند
- مولد
- نسل
- دریافت کنید
- گرفتن
- جهانی
- گرم شدن کره زمین
- گوگل
- GPU
- اداره
- داشتن
- مرکز فرماندهی
- به شدت
- مفید
- زیاد
- بالاتر
- سوراخ
- چگونه
- چگونه
- HTTPS
- انسان
- if
- تصویر
- تأثیر
- واردات
- واردات
- بهبود یافته
- in
- شامل
- از جمله
- مسوول
- نشان داد
- نشان دادن
- صنعت
- پیشرو در صنعت
- ابداع
- ابتکاری
- فن آوری نوآورانه
- ورودی
- نصب
- فوری
- نمونه سازی
- ادغام
- ادغام
- تعامل
- اثر متقابل
- به
- معرفی
- فراخوانی میکند
- شامل
- IT
- ITS
- تنها
- کلید
- چشم انداز
- زبان
- بزرگ
- در مقیاس بزرگ
- تاخیر
- رهبران
- منجر می شود
- قدرت نفوذ
- بهره برداری
- کتابخانه ها
- کتابخانه
- رعد و برق سریع
- پسندیدن
- احتمالا
- محدود
- لاین
- فهرست
- llm
- واقع شده
- ورود
- مطالب
- کاهش
- حفظ
- ساخت
- روش
- بسیاری
- حداکثر عرض
- بیشترین
- متوسط
- اندازه گیری
- رسانه ها
- حافظه
- پیام
- پیام
- متا
- روش
- روش
- میلیون
- ML
- مدل
- مدل
- بیش
- کارآمدتر
- اکثر
- کوه
- نام
- تحت عنوان
- طبیعی
- زبان طبیعی
- درک زبان طبیعی
- طبیعت
- لازم
- نیاز
- شبکه
- جدید
- بعد
- اکنون
- عدد
- تعداد
- هدف
- of
- ارائه
- پیشنهادات
- قدیمی
- on
- ONE
- OpenAI
- بهینه
- گزینه
- or
- OS
- دیگر
- ما
- خارج
- بهتر از
- بهتر از
- عملکرد بهتر
- تولید
- خروجی
- برجسته
- روی
- متعلق به
- با ما
- پارامتر
- پارامترهای
- بخش
- شرکت کننده
- ویژه
- عبور می کند
- برای
- کارایی
- حفره یا سوراخ
- برنامه
- سیستم عامل
- افلاطون
- هوش داده افلاطون
- PlatoData
- زمین بازی
- آمادگی
- قابل پیش بینی
- هدیه
- اصلی
- چاپ
- احتمال
- ادامه
- روند
- فرآیندهای
- در حال پردازش
- تولید کردن
- برجسته
- پرسیدن
- ارائه
- ارائه دهنده
- ارائه دهندگان
- فراهم می کند
- ارائه
- منتشر شده
- سوال
- سریع
- تصادفی بودن
- محدوده
- سریع
- خواندن
- زمان واقعی
- قلمرو
- سوابق
- ثبت نام
- مربوط
- تکیه
- نشان دهنده
- درخواست
- ضروری
- تغییر شکل
- منابع
- پاسخ
- پاسخ
- نتایج
- انقلابی
- انقلابی کردن
- نقش
- در حال اجرا
- زنگ
- s
- علم
- بدون درز
- دوم
- به دنبال
- فرستاده
- سرور
- خدمت
- تنظیم
- محیط
- باید
- نشان داده شده
- نشان می دهد
- امضاء
- قابل توجه
- به طور قابل توجهی
- مشابه
- ساده
- تنها
- قطعه
- راه حل
- مزایا
- گاهی
- فضا
- تخصص دارد
- به طور خاص
- مشخص کردن
- سرعت
- سرعت
- standout
- می ایستد
- شروع
- آغاز شده
- شروع
- ذخیره شده
- جریان
- جریان
- تلاش می کند
- متعاقب
- متعاقبا
- چنین
- مناسب
- خلاصه
- برتر
- پشتیبانی
- پشتیبانی
- پشتیبانی از
- فراتر می رود
- فراتر
- سیستم
- سیستم های
- طراحی شده
- گرفتن
- وظایف
- تیم
- فن آوری
- پیشرفته
- قوانین و مقررات
- تست
- متن
- تولید متن
- که
- La
- منظره
- شان
- سپس
- اینها
- آنها
- این
- کسانی که
- از طریق
- توان
- به
- رمز
- نشانه
- بالا
- موضوع
- تاپیک
- علامت تجارتی
- سنتی
- امتحان
- دو
- اساسی
- درک
- واحد
- بی نظیر
- بی سابقه
- us
- قابلیت استفاده
- استفاده
- کاربر
- با استفاده از
- استفاده کنید
- متغیر
- از طريق
- چشم انداز
- بازدید
- vs
- بود
- we
- وب سایت
- چی
- چه شده است
- که
- در حین
- اراده
- با
- در داخل
- کارگر
- خواهد بود
- نوشتن
- سال
- سال
- بله
- شما
- زفیرنت