Tämä viesti on kirjoitettu yhdessä koneoppimisinsinööri Mahima Agarwalin ja VMware Carbon Blackin vanhempi suunnittelupäällikkö Deepak Mettem kanssa
VMware hiilimusta on tunnettu tietoturvaratkaisu, joka tarjoaa suojan kaikkia moderneja kyberhyökkäyksiä vastaan. Tuotteen tuottaman teratavun datan ansiosta tietoturva-analytiikkatiimi keskittyy koneoppimisratkaisujen (ML) rakentamiseen kriittisten hyökkäysten hallintaan ja melun aiheuttamien uusien uhkien huomioimiseen.
VMware Carbon Black -tiimille on tärkeää suunnitella ja rakentaa mukautettu päästä päähän MLOps-putkilinja, joka ohjaa ja automatisoi työnkulkuja ML-elinkaaren aikana ja mahdollistaa mallin koulutuksen, arvioinnit ja käyttöönotot.
Tämän putkilinjan rakentamisella on kaksi päätarkoitusta: datatieteilijöiden tukeminen loppuvaiheen mallikehityksessä ja pintamallien ennusteet tuotteessa palvelemalla malleja suurella volyymilla ja reaaliaikaisessa tuotantoliikenteessä. Siksi VMware Carbon Black ja AWS päättivät rakentaa mukautetun MLOps-putkilinjan käyttämällä Amazon Sage Maker sen helppokäyttöisyyden, monipuolisuuden ja täysin hallitun infrastruktuurin vuoksi. Järjestämme ML-koulutus- ja käyttöönottoputkistomme käyttämällä Amazonin hallinnoidut työnkulut Apache Airflowlle (Amazon MWAA), jonka avulla voimme keskittyä enemmän työnkulkujen ja putkien ohjelmalliseen luomiseen ilman, että meidän tarvitsee huolehtia automaattisesta skaalauksesta tai infrastruktuurin ylläpidosta.
Tämän putkilinjan myötä entinen Jupyter-kannettavien ML-tutkimus on nyt automatisoitu prosessi, joka ottaa malleja tuotantoon ilman, että datatieteilijät puuttuvat käsin. Aikaisemmin mallin koulutus-, arviointi- ja käyttöönottoprosessi saattoi kestää yli päivän; Tämän toteutuksen ansiosta kaikki on vain laukaisin päässä ja kokonaisaika on lyhentynyt muutamaan minuuttiin.
Tässä viestissä VMware Carbon Black- ja AWS-arkkitehdit keskustelevat siitä, kuinka rakensimme ja hallinnoimme mukautettuja ML-työnkulkuja käyttämällä Gitlab, Amazon MWAA ja SageMaker. Keskustelemme tähänastisista saavutuksistamme, prosessin lisäparannuksista ja matkan varrella opituista kokemuksista.
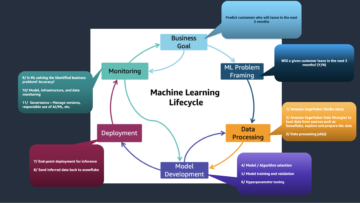
Ratkaisun yleiskatsaus
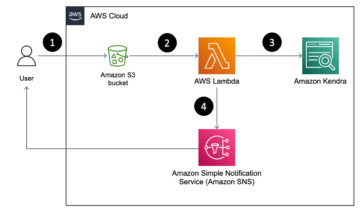
Seuraava kaavio havainnollistaa ML-alustan arkkitehtuuria.

Korkeatasoinen ratkaisusuunnittelu
Tämä ML-alusta on suunniteltu ja suunniteltu käytettäväksi eri malleissa eri koodivarastoissa. Tiimimme käyttää GitLabia lähdekoodin hallintatyökaluna kaikkien koodivarastojen ylläpitämiseen. Kaikki mallivaraston lähdekoodin muutokset integroidaan jatkuvasti käyttämällä Gitlab CI, joka käynnistää seuraavat työnkulkuprosessit (mallin koulutus, arviointi ja käyttöönotto).
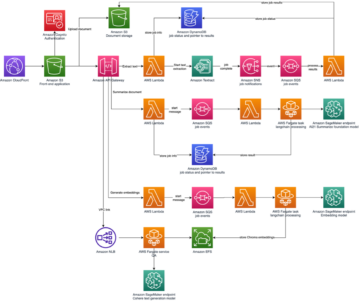
Seuraava arkkitehtuurikaavio havainnollistaa päästä päähän -työnkulkua ja MLOps-putkistossamme mukana olevia komponentteja.

Päästä päähän -työnkulku
ML-mallin koulutus-, arviointi- ja käyttöönottoputkistot on järjestetty käyttämällä Amazon MWAA:ta, jota kutsutaan nimellä Ohjattu asyklinen kuvaaja (DAG). DAG on kokoelma tehtäviä yhdessä, ja ne on järjestetty riippuvuuksilla ja suhteilla kertomaan, kuinka niiden pitäisi toimia.
Korkealla tasolla ratkaisuarkkitehtuuri sisältää kolme pääkomponenttia:
- ML-putkilinjan koodivarasto
- ML-mallin koulutus- ja arviointiputki
- ML-mallin käyttöönottoputki
Keskustellaan siitä, kuinka näitä eri komponentteja hallitaan ja miten ne ovat vuorovaikutuksessa toistensa kanssa.
ML-putkilinjan koodivarasto
Sen jälkeen, kun mallirepo integroi MLOps-repon alavirran liukuhihnakseen ja datatieteilijä sitoo koodin mallivarastossaan, GitLab-apuohjelma suorittaa kyseisessä repossa määritellyn standardin koodin validoinnin ja testauksen ja laukaisee MLOps-putken koodimuutosten perusteella. Käytämme Gitlabin usean projektin putkilinjaa salliaksemme tämän triggerin eri repoissa.
MLOps GitLab -liukuhihna suorittaa tietyt vaiheet. Se suorittaa peruskoodin validoinnin pylintin avulla, pakkaa mallin koulutus- ja päättelykoodin Docker-kuvaan ja julkaisee säilön kuvan Amazonin elastisten säiliörekisteri (Amazon ECR). Amazon ECR on täysin hallittu konttirekisteri, joka tarjoaa tehokkaan isännöinnin, joten voit ottaa sovelluskuvia ja esineitä luotettavasti käyttöön missä tahansa.
ML-mallin koulutus- ja arviointiputki
Kun kuva on julkaistu, se käynnistää koulutuksen ja arvioinnin apache-ilmavirta putki läpi AWS Lambda toiminto. Lambda on palvelimeton, tapahtumapohjainen laskentapalvelu, jonka avulla voit suorittaa koodia käytännöllisesti katsoen minkä tahansa tyyppisille sovelluksille tai taustapalveluille ilman palvelimien hallintaa tai hallintaa.
Kun putki on käynnistetty onnistuneesti, se suorittaa Training and Evaluation DAG:n, joka puolestaan aloittaa mallikoulutuksen SageMakerissa. Tämän koulutusputken lopussa tunnistettu käyttäjäryhmä saa sähköpostitse ilmoituksen koulutuksen ja mallin arvioinnin tuloksista Amazonin yksinkertainen ilmoituspalvelu (Amazon SNS) ja Slack. Amazon SNS on täysin hallittu pubi-/alapalvelu A2A- ja A2P-viestintään.
Arviointitulosten huolellisen analyysin jälkeen datatieteilijä tai ML-insinööri voi ottaa uuden mallin käyttöön, jos juuri koulutetun mallin suorituskyky on parempi kuin edellisessä versiossa. Mallien suorituskykyä arvioidaan mallikohtaisten mittareiden perusteella (kuten F1-pisteet, MSE tai sekavuusmatriisi).
ML-mallin käyttöönottoputki
Käyttöönoton aloittamiseksi käyttäjä käynnistää GitLab-työn, joka käynnistää Deployment DAG:n saman Lambda-toiminnon kautta. Kun liukuhihna on suoritettu onnistuneesti, se luo tai päivittää SageMaker-päätepisteen uudella mallilla. Tämä lähettää myös päätepisteen tiedot sisältävän ilmoituksen sähköpostitse Amazon SNS:n ja Slackin kautta.
Jos jompikumpi putkisto epäonnistuu, käyttäjille ilmoitetaan samojen viestintäkanavien kautta.
SageMaker tarjoaa reaaliaikaisen johtopäätöksen, joka on ihanteellinen päättelytyökuormille, joissa on alhainen latenssi ja korkeat suorituskyvyn vaatimukset. Nämä päätepisteet ovat täysin hallittuja, kuormitettuja ja automaattisesti skaalattuja, ja ne voidaan ottaa käyttöön useilla käytettävyysvyöhykkeillä korkean käytettävyyden saavuttamiseksi. Liukulinjamme luo tällaisen päätepisteen mallille sen jälkeen, kun se on suoritettu onnistuneesti.
Seuraavissa osioissa laajennamme eri komponentteja ja sukeltamme yksityiskohtiin.
GitLab: Pakettimallit ja laukaisuputket
Käytämme GitLabia koodivarastona ja putkistossa mallikoodin pakkaamiseen ja myöhempien Airflow DAG:ien käynnistämiseen.
Usean hankkeen putki
Usean projektin GitLab-liukuhihnaominaisuutta käytetään, kun pääliukuhihna (ylävirtaan) on mallivarasto ja aliputki (alavirtaan) on MLOps-repo. Jokainen repo ylläpitää .gitlab-ci.yml-tiedostoa, ja seuraava ylävirran liukuhihnassa käytössä oleva koodilohko laukaisee alavirran MLOps-liukuhihnan.
Ylävirran liukuhihna lähettää mallikoodin loppupään liukuhihnalle, jossa CI-pakkaus- ja julkaisutyöt käynnistyvät. Koodia, jolla mallikoodi säilytetään ja julkaistaan Amazon ECR:lle, ylläpidetään ja hallitaan MLOps-putkistossa. Se lähettää muuttujat, kuten ACCESS_TOKEN (voidaan luoda alla Asetukset, Pääsy), JOB_ID (pääsy ylävirran artefakteihin) ja $CI_PROJECT_ID (mallivaraston projektitunnus) -muuttujat, jotta MLOps-liukuhihna voi käyttää mallikooditiedostoja. Kanssa työartefakteja Gitlabin ominaisuuden myötä loppupään repo käyttää etäartefakteja seuraavalla komennolla:
Mallirepo voi kuluttaa alavirran putkilinjoja useille malleille samasta reposta laajentamalla vaihetta, joka käynnistää sen käyttämällä ulottuu GitLabin avainsana, jonka avulla voit käyttää samaa kokoonpanoa uudelleen eri vaiheissa.
Kun mallikuva on julkaistu Amazon ECR:lle, MLOps-putki käynnistää Amazon MWAA -koulutusputken Lambdan avulla. Käyttäjän hyväksynnän jälkeen se käynnistää myös Amazon MWAA -mallin käyttöönottoprosessin käyttämällä samaa Lambda-toimintoa.
Semanttinen versiointi ja välitysversiot alavirtaan
Kehitimme mukautetun koodin ECR-kuvien ja SageMaker-mallien versioihin. MLOps-liukuhihna hallitsee kuvien ja mallien semanttista versiointilogiikkaa osana vaihetta, jossa mallikoodi säilötään ja siirtää versiot myöhemmille vaiheille artefakteina.
Uudelleenkoulutus
Koska uudelleenkoulutus on olennainen osa ML-elinkaaria, olemme ottaneet käyttöön uudelleenkoulutusominaisuudet osana prosessiamme. Käytämme SageMaker list-models API:ta tunnistamaan, onko kyseessä uudelleenkoulutus mallin uudelleenkoulutuksen versionumeron ja aikaleiman perusteella.
Hallitsemme uudelleenkoulutusputken päivittäisen aikataulun käyttämällä GitLabin aikatauluputket.
Terraform: Infrastruktuurin asennus
Amazon MWAA -klusterin, ECR-tietovarastojen, Lambda-toimintojen ja SNS-aiheen lisäksi tämä ratkaisu käyttää myös AWS-henkilöllisyyden ja käyttöoikeuksien hallinta (IAM) roolit, käyttäjät ja käytännöt; Amazonin yksinkertainen tallennuspalvelu (Amazon S3) kauhat ja an amazonin pilvikello lokin huolitsija.
Käytämme virtaviivaistaaksemme infrastruktuurin asennusta ja ylläpitoa putkistossamme mukana olevien palveluiden osalta terraform toteuttaa infrastruktuuri koodina. Aina kun infrapäivityksiä tarvitaan, koodimuutokset laukaisevat perustamamme GitLab CI -putken, joka vahvistaa ja ottaa muutokset käyttöön eri ympäristöissä (esimerkiksi lisäämällä luvan IAM-käytäntöön kehittäjä-, vaihe- ja tuotetileillä).
Amazon ECR, Amazon S3 ja Lambda: Pipeline Facilitation
Käytämme seuraavia keskeisiä palveluita putkistomme helpottamiseksi:
- Amazon ECR – Mallin säilön kuvien ylläpitämiseksi ja helpon hakemisen mahdollistamiseksi merkitsemme ne semanttisilla versioilla ja lataamme ne ECR-tietovarastoihin, jotka on määritetty
${project_name}/${model_name}Terraformin kautta. Tämä mahdollistaa hyvän eristyskerroksen eri mallien välillä ja antaa meille mahdollisuuden käyttää mukautettuja algoritmeja ja muotoilla johtopäätöspyyntöjä ja vastauksia sisältämään halutut malliluettelotiedot (mallin nimi, versio, koulutusdatan polku jne.). - Amazon S3 – Käytämme S3-ämpäriä mallin koulutustietojen, mallikohtaisten koulutettujen malliartefaktien, Airflow DAG:ien ja muiden putkilinjojen edellyttämien lisätietojen säilyttämiseen.
- Lambda – Koska Airflow-klusterimme on otettu käyttöön erillisessä VPC:ssä turvallisuussyistä, DAG:ita ei voida käyttää suoraan. Siksi käytämme Lambda-toimintoa, jota myös ylläpidetään Terraformin kanssa, käynnistämään DAG-nimen määrittämät DAG:t. Oikealla IAM-asetuksella GitLab CI -työ laukaisee Lambda-toiminnon, joka kulkee kokoonpanojen läpi vaadittuihin koulutus- tai käyttöönotto-DAG:ihin.
Amazon MWAA: Koulutus- ja käyttöönottoputkistot
Kuten aiemmin mainittiin, käytämme Amazon MWAA:ta koulutus- ja käyttöönottoputkien järjestämiseen. Käytämme SageMaker-operaattoreita, jotka ovat saatavilla osoitteessa Amazon-palveluntarjoajapaketti Airflowlle integroidaksesi SageMakeriin (jinja-mallien välttämiseksi).
Käytämme tässä koulutusputkessa seuraavia operaattoreita (näkyy seuraavassa työnkulkukaaviossa):

MWAA Training Pipeline
Käytämme seuraavia operaattoreita käyttöönottoprosessissa (näkyy seuraavassa työnkulkukaaviossa):

Mallin käyttöönottoputki
Käytämme Slackia ja Amazon SNS:ää virhe-/onnistumisviestien ja arviointitulosten julkaisemiseen molemmissa putkissa. Slack tarjoaa laajan valikoiman vaihtoehtoja viestien mukauttamiseen, mukaan lukien seuraavat:
- SnsPublishOperator - Käytämme SnsPublishOperator lähettääksesi onnistumis-/epäonnistumisilmoituksia käyttäjien sähköposteihin
- Slack API – Loimme saapuvan webhookin URL-osoite saadaksesi putken ilmoitukset halutulle kanavalle
CloudWatch ja VMware Wavefront: Valvonta ja kirjaaminen
Käytämme CloudWatch-hallintapaneelia päätepisteiden valvonnan ja kirjaamisen määrittämiseen. Se auttaa visualisoimaan ja pitämään kirjaa kunkin projektin eri toiminnallisista ja mallien suorituskykymittareista. Joitakin niistä seuraavien automaattisten skaalauskäytäntöjen lisäksi seuraamme jatkuvasti muutoksia suorittimen ja muistin käytössä, sekuntikohtaisissa pyynnöissä, vastausviiveissä ja mallimittareissa.
CloudWatch on jopa integroitu VMware Tanzu Wavefront -kojelautaan, jotta se voi visualisoida mallien päätepisteiden ja muiden palveluiden mittareita projektitasolla.
Liiketoiminnan edut ja mitä seuraavaksi
ML-putkistot ovat erittäin tärkeitä ML-palveluille ja -ominaisuuksille. Tässä viestissä keskustelimme päästä päähän ML-käyttötapauksesta, jossa käytettiin AWS:n ominaisuuksia. Rakensimme mukautetun putkilinjan SageMakerilla ja Amazon MWAA:lla, jota voimme käyttää uudelleen eri projekteissa ja malleissa, ja automatisoimme ML-elinkaarin, mikä lyhensi mallin koulutuksesta tuotannon käyttöönottoon kuluvan ajan vain 10 minuuttiin.
Kun ML-elinkaaritaakka siirrettiin SageMakerille, se tarjosi optimoidun ja skaalautuvan infrastruktuurin mallin koulutusta ja käyttöönottoa varten. Mallin tarjoaminen SageMakerin kanssa auttoi meitä tekemään reaaliaikaisia ennusteita millisekuntien viiveillä ja valvontaominaisuuksilla. Käytimme Terraformia asennuksen helpottamiseksi ja infrastruktuurin hallintaan.
Seuraavat vaiheet tälle putkilinjalle olisivat mallin koulutusputkilinjan tehostaminen uudelleenkoulutusominaisuuksilla riippumatta siitä, onko se ajoitettu tai perustuu mallin ajautuman havaitsemiseen, tuen varjokäyttöön tai A/B-testaukseen mallin nopeampaa ja pätevää käyttöönottoa varten sekä ML-linjan seurantaa. Suunnittelemme myös arvioinnin Amazon SageMaker -putkistot koska GitLab-integraatiota tuetaan nyt.
Saadut kokemukset
Osana tämän ratkaisun rakentamista opimme, että sinun tulee yleistää aikaisin, mutta älä yleistä liikaa. Kun saimme ensimmäisen arkkitehtuurin suunnittelun valmiiksi, yritimme luoda ja pakottaa mallikoodin koodipohjaa parhaana käytäntönä. Kehitysprosessi oli kuitenkin niin varhaisessa vaiheessa, että mallit olivat joko liian yleisiä tai liian yksityiskohtaisia, jotta niitä voitaisiin käyttää uudelleen tuleviin malleihin.
Ensimmäisen mallin toimituksen jälkeen mallit tulivat luonnollisesti esiin aikaisemman työmme oivallusten pohjalta. Putki ei voi tehdä kaikkea alusta alkaen.
Mallikokeilulla ja tuotannolla on usein hyvin erilaisia (tai joskus jopa ristiriitaisia) vaatimuksia. On ratkaisevan tärkeää tasapainottaa nämä vaatimukset alusta alkaen joukkueena ja priorisoida sen mukaisesti.
Lisäksi et välttämättä tarvitse kaikkia palvelun ominaisuuksia. Palvelun olennaisten ominaisuuksien hyödyntäminen ja modulaarinen suunnittelu ovat avaimia tehokkaampaan kehitykseen ja joustavaan putkilinjaan.
Yhteenveto
Tässä viestissä näytimme, kuinka rakensimme MLOps-ratkaisun käyttämällä SageMakeria ja Amazon MWAA:ta, joka automatisoi mallien käyttöönottoprosessin tuotantoon ilman, että datatieteilijät puuttuvat käsin. Suosittelemme sinua arvioimaan erilaisia AWS-palveluita, kuten SageMaker, Amazon MWAA, Amazon S3 ja Amazon ECR, jotta voit rakentaa täydellisen MLOps-ratkaisun.
*Apache, Apache Airflow ja Airflow ovat joko rekisteröityjä tavaramerkkejä tai tavaramerkkejä Apache-ohjelmistosäätiö Yhdysvalloissa ja / tai muissa maissa.
Tietoja Tekijät
 Deepak Mettem on Senior Engineering Manager VMware, Carbon Black Unit. Hän ja hänen tiiminsä työskentelevät rakentaakseen suoratoistoon perustuvia sovelluksia ja palveluita, jotka ovat erittäin saatavilla, skaalautuvia ja joustavia tuomaan asiakkaille koneoppimiseen perustuvia ratkaisuja reaaliajassa. Hän ja hänen tiiminsä ovat myös vastuussa työkalujen luomisesta, joita datatieteilijät tarvitsevat ML-malliensa rakentamiseen, kouluttamiseen, käyttöönottamiseksi ja validoimiseksi tuotannossa.
Deepak Mettem on Senior Engineering Manager VMware, Carbon Black Unit. Hän ja hänen tiiminsä työskentelevät rakentaakseen suoratoistoon perustuvia sovelluksia ja palveluita, jotka ovat erittäin saatavilla, skaalautuvia ja joustavia tuomaan asiakkaille koneoppimiseen perustuvia ratkaisuja reaaliajassa. Hän ja hänen tiiminsä ovat myös vastuussa työkalujen luomisesta, joita datatieteilijät tarvitsevat ML-malliensa rakentamiseen, kouluttamiseen, käyttöönottamiseksi ja validoimiseksi tuotannossa.
 Mahima Agarwal on koneoppimisinsinööri VMwaressa, hiilimustan yksikössä.
Mahima Agarwal on koneoppimisinsinööri VMwaressa, hiilimustan yksikössä.
Hän suunnittelee, rakentaa ja kehittää VMware CB SBU:n koneoppimisalustan ydinkomponentteja ja arkkitehtuuria.
 Vamshi Krishna Enabothala on Sr. Applied AI Specialist Architect AWS:ssä. Hän työskentelee eri alojen asiakkaiden kanssa nopeuttaakseen vaikuttavia data-, analytiikka- ja koneoppimisaloitteita. Hän on intohimoinen suositusjärjestelmistä, NLP:stä ja tietokonenäköalueista tekoälyssä ja ML:ssä. Työn ulkopuolella Vamshi on RC-ihminen, rakentaa RC-laitteita (lentokoneita, autoja ja droneja) ja nauttii myös puutarhanhoidosta.
Vamshi Krishna Enabothala on Sr. Applied AI Specialist Architect AWS:ssä. Hän työskentelee eri alojen asiakkaiden kanssa nopeuttaakseen vaikuttavia data-, analytiikka- ja koneoppimisaloitteita. Hän on intohimoinen suositusjärjestelmistä, NLP:stä ja tietokonenäköalueista tekoälyssä ja ML:ssä. Työn ulkopuolella Vamshi on RC-ihminen, rakentaa RC-laitteita (lentokoneita, autoja ja droneja) ja nauttii myös puutarhanhoidosta.
 Sahil Thapar on Enterprise Solutions -arkkitehti. Hän työskentelee asiakkaiden kanssa auttaakseen heitä rakentamaan erittäin saatavilla olevia, skaalautuvia ja joustavia sovelluksia AWS-pilveen. Tällä hetkellä hän keskittyy konteihin ja koneoppimisratkaisuihin.
Sahil Thapar on Enterprise Solutions -arkkitehti. Hän työskentelee asiakkaiden kanssa auttaakseen heitä rakentamaan erittäin saatavilla olevia, skaalautuvia ja joustavia sovelluksia AWS-pilveen. Tällä hetkellä hän keskittyy konteihin ja koneoppimisratkaisuihin.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :On
- $ YLÖS
- 1
- 10
- 100
- 7
- 8
- a
- Meistä
- kiihdyttää
- pääsy
- Accessed
- sen mukaisesti
- Tilit
- saavutettu
- poikki
- asykliset
- Lisäksi
- lisä-
- lisäinformaatio
- Jälkeen
- vastaan
- AI
- algoritmit
- Kaikki
- mahdollistaa
- Amazon
- Amazon Sage Maker
- analyysi
- Analytics
- ja
- kaikkialla
- Apache
- api
- Hakemus
- sovellukset
- sovellettu
- Sovellettu tekoäly
- hyväksyminen
- arkkitehtuuri
- OVAT
- alueet
- AS
- ulkomuoto
- At
- Hyökkäykset
- kirjoittaminen
- auto
- Automatisoitu
- automaatti
- saatavuus
- saatavissa
- välttää
- AWS
- taustaosa
- Balance
- perustua
- perustiedot
- BE
- koska
- Alku
- Hyödyt
- PARAS
- Paremmin
- välillä
- Musta
- Tukkia
- Sivuliike
- tuoda
- rakentaa
- Rakentaminen
- rakennettu
- taakka
- by
- CAN
- ei voi
- kyvyt
- hiili
- autot
- tapaus
- CB
- tietty
- Muutokset
- kanavat
- lapsi
- valitsi
- pilvi
- Cluster
- koodi
- kokoelma
- Viestintä
- verrattuna
- täydellinen
- osat
- Laskea
- tietokone
- Tietokoneen visio
- toimintatapoja,
- Konfigurointi
- kokoonpanot
- ristiriitaiset
- sekaannus
- näkökohdat
- kuluttaa
- kulutetaan
- Kontti
- Kontit
- jatkuvasti
- Mukava
- Ydin
- voisi
- maahan
- prosessori
- luoda
- luotu
- luo
- Luominen
- kriittinen
- ratkaiseva
- Tällä hetkellä
- asiakassuhde
- Asiakkaat
- räätälöidä
- cyberattacks
- PÄIVÄ
- päivittäin
- kojelauta
- tiedot
- tietojen tutkija
- päivä
- määritelty
- tuottaa
- sijoittaa
- käyttöön
- levityspinnalta
- käyttöönotto
- käyttöönotot
- lauennut
- Malli
- suunniteltu
- suunnittelu
- yksityiskohtainen
- yksityiskohdat
- Detection
- dev
- kehitetty
- kehittämällä
- Kehitys
- eri
- suoraan
- pohtia
- keskusteltiin
- Satamatyöläinen
- Dont
- alas
- Drones
- kukin
- Aikaisemmin
- Varhainen
- helppokäyttöisyys
- tehokas
- myöskään
- syntymässä
- mahdollistaa
- käytössä
- mahdollistaa
- kannustaa
- päittäin
- päätepiste
- insinööri
- Tekniikka
- yritys
- Enterprise-ratkaisut
- intoilija
- ympäristöissä
- laitteet
- olennainen
- Eetteri (ETH)
- arvioida
- arvioitu
- arviointiin
- arviointi
- arvioinnit
- Jopa
- tapahtuma
- Joka
- kaikki
- esimerkki
- Laajentaa
- ulottuu
- f1
- helpottamaan
- Epäonnistuminen
- paljon
- nopeampi
- Ominaisuus
- Ominaisuudet
- harvat
- Asiakirjat
- Etunimi
- joustava
- Keskittää
- keskityttiin
- keskittyy
- jälkeen
- varten
- muoto
- alkaen
- koko
- koko kirjon
- täysin
- toiminto
- tehtävät
- edelleen
- tulevaisuutta
- syntyy
- saada
- hyvä
- Ryhmä
- Olla
- ottaa
- auttaa
- auttanut
- auttaa
- Korkea
- korkea suorituskyky
- erittäin
- hotellit
- Miten
- Kuitenkin
- HTML
- http
- HTTPS
- IAM
- ID
- ihanteellinen
- tunnistettu
- tunnistaa
- Identiteetti
- kuva
- kuvien
- toteuttaa
- täytäntöönpano
- täytäntöön
- in
- sisältää
- sisältää
- Mukaan lukien
- tiedot
- Infrastruktuuri
- aloitteita
- oivalluksia
- yhdistää
- integroitu
- integroi
- integraatio
- olla vuorovaikutuksessa
- interventio
- vedotaan
- osallistuva
- eristäminen
- IT
- SEN
- Job
- Työpaikat
- jpg
- Pitää
- avain
- avaimet
- Viive
- kerros
- oppinut
- oppiminen
- Lessons
- Lessons Learned
- Lets
- Taso
- elinkaari
- pitää
- vähän
- kuormitus
- Matala
- kone
- koneoppiminen
- tärkein
- ylläpitää
- ylläpitää
- huolto
- tehdä
- hoitaa
- onnistui
- johto
- johtaja
- hallinnoi
- toimitusjohtaja
- manuaalinen
- Matriisi
- Muisti
- mainitsi
- viestien
- Viestit
- Metrics
- ehkä
- millisekunnin
- pöytäkirja
- ML
- MLOps
- malli
- mallit
- Moderni
- monitori
- seuranta
- lisää
- tehokkaampi
- moninkertainen
- nimi
- luonnollisesti
- välttämätön
- Tarve
- Uusi
- seuraava
- NLP
- Melu
- ilmoituksen
- ilmoitukset
- numero
- of
- tarjoamalla
- Tarjoukset
- on
- ONE
- toiminta-
- operaattorit
- optimoitu
- Vaihtoehdot
- orkestroinut
- Järjestetty
- Muut
- ulkopuolella
- yleinen
- paketti
- paketit
- pakkaus
- osa
- kulkee
- Ohimenevä
- intohimoinen
- polku
- suorituskyky
- lupa
- putki
- suunnitelma
- Planes
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- politiikkaa
- politiikka
- Kirje
- harjoitusta.
- Ennusteet
- edellinen
- Asettaa etusijalle
- prosessi
- Tuotteet
- tuotanto
- projekti
- hankkeet
- asianmukainen
- suojaus
- mikäli
- toimittaja
- tarjoaa
- julkaista
- julkaistu
- Julkaisee
- Julkaiseminen
- tarkoituksiin
- pätevän
- alue
- reaaliaikainen
- Suositus
- Vähentynyt
- tarkoitettuja
- kirjattu
- rekisterin
- Ihmissuhteet
- kaukosäädin
- kuuluisa
- säilytyspaikka
- pyysi
- pyynnöt
- tarvitaan
- vaatimukset
- tutkimus
- kimmoisa
- vastaus
- vastuullinen
- tulokset
- uudelleenkoulutus
- uudelleen käytettävä
- roolit
- ajaa
- juoksija
- sagemaker
- sama
- skaalautuva
- skaalaus
- aikataulu
- suunniteltu
- Tiedemies
- tutkijat
- Toinen
- osiot
- sektorit
- turvallisuus
- vanhempi
- erillinen
- serverless
- servers
- palvelu
- Palvelut
- palvelevat
- setti
- setup
- varjo
- VAIHTO
- shouldnt
- esitetty
- Yksinkertainen
- löysä
- So
- niin kaukana
- Tuotteemme
- ratkaisu
- Ratkaisumme
- jonkin verran
- lähde
- lähdekoodi
- asiantuntija
- erityinen
- määritelty
- spektri
- Valokeila
- Vaihe
- vaiheissa
- standardi
- Alkaa
- alkaa
- Valtiot
- Askeleet
- Levytila
- Strategia
- streaming
- tehostaa
- myöhempi
- Onnistuneesti
- niin
- tuki
- Tuetut
- pinta
- järjestelmät
- TAG
- ottaa
- tehtävät
- joukkue-
- malleja
- terraform
- Testaus
- että
- -
- heidän
- Niitä
- siksi
- Nämä
- uhat
- kolmella
- Kautta
- kauttaaltaan
- suoritusteho
- aika
- aikaleima
- että
- yhdessä
- liian
- työkalu
- työkalut
- ylin
- aihe
- raita
- Seuranta
- tavaramerkkejä
- liikenne
- Juna
- koulutettu
- koulutus
- laukaista
- laukeaa
- VUORO
- varten
- yksikkö
- Yhtenäinen
- Yhdysvallat
- Päivitykset
- us
- Käyttö
- käyttää
- käyttölaukku
- käyttäjä
- Käyttäjät
- VAHVISTA
- validointi
- muuttujat
- eri
- versio
- käytännössä
- visio
- havainnollistaa
- vMware
- tilavuus
- Tapa..
- HYVIN
- Mitä
- onko
- joka
- leveä
- Laaja valikoima
- with
- sisällä
- ilman
- Referenssit
- työnkulku
- työnkulkuja
- toimii
- olisi
- zephyrnet
- Postinumero
- alueet