Kuva tekijältä
Yksi datatieteen perustana olevista aloista on koneoppiminen. Joten jos haluat päästä tietotieteeseen, koneoppimisen ymmärtäminen on yksi ensimmäisistä askeleista, jotka sinun on otettava.
Mutta mistä aloitat? Aloitat ymmärtämällä eron kahden koneoppimisalgoritmin päätyypin välillä. Vasta sen jälkeen voimme puhua yksittäisistä algoritmeista, joiden tulisi olla prioriteettiluettelossasi oppiaksesi aloittelijana.
Pääasiallinen ero algoritmien välillä perustuu siihen, miten ne oppivat.

Kuva tekijältä
Valvotut oppimisalgoritmit ovat koulutettuja a merkitty tietojoukko. Tämä tietojoukko toimii ohjaajana (siis nimi) oppimiselle, koska osa sen sisältämistä tiedoista on jo merkitty oikeaksi vastaukseksi. Tämän syötteen perusteella algoritmi voi oppia ja soveltaa oppimista muuhun dataan.
Toisaalta, valvomattomia oppimisalgoritmeja oppia an nimeämätön tietojoukko, mikä tarkoittaa, että he etsivät kuvioita tiedosta ilman, että ihmiset antavat ohjeita.
Voit lukea tarkemmin aiheesta koneoppimisalgoritmit ja oppimisen tyypit.
On myös joitain muita koneoppimistyyppejä, mutta ei aloittelijoille.
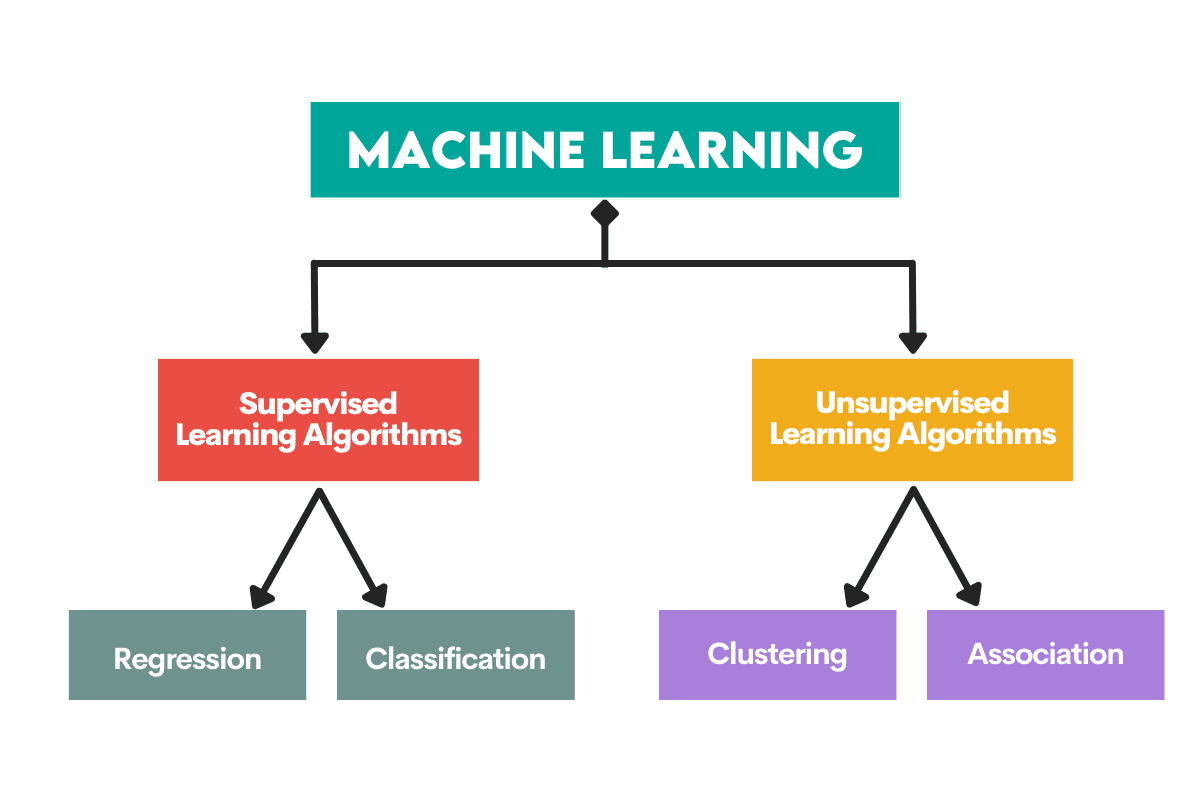
Algoritmeja käytetään ratkaisemaan kaksi erillistä pääongelmaa kussakin koneoppimistyypissä.
Jälleen on joitain muita tehtäviä, mutta ne eivät ole aloittelijoille.
Kuva tekijältä
Ohjatut oppimistehtävät
Regressio on tehtävä ennustaa a numeerinen arvo, Kutsutaan jatkuva tulosmuuttuja tai riippuva muuttuja. Ennuste perustuu ennustajamuuttujiin tai riippumattomiin muuttujiin.
Ajattele öljyn hinnan tai ilman lämpötilan ennustamista.
Luokittelu käytetään ennustamaan luokka (luokka) syöttötiedoista. The tulosmuuttuja täällä on kategorinen tai diskreetti.
Ajattele ennustamista, onko sähköposti roskapostia vai ei, vai sairastuuko potilas tiettyyn sairauteen vai ei.
Ohjaamattomat oppimistehtävät
Clustering välineet tietojen jakaminen osajoukkoihin tai klustereihin. Tavoitteena on ryhmitellä tiedot mahdollisimman luonnollisesti. Tämä tarkoittaa, että saman klusterin tietopisteet ovat samankaltaisempia toistensa kanssa kuin muiden klustereiden datapisteet.
Mitat pieneneminen viittaa syötemuuttujien määrän vähentämiseen tietojoukossa. Se tarkoittaa pohjimmiltaan supistamalla tietojoukon hyvin harvojen muuttujien määrään, mutta silti sen olemuksen vangitseminen.
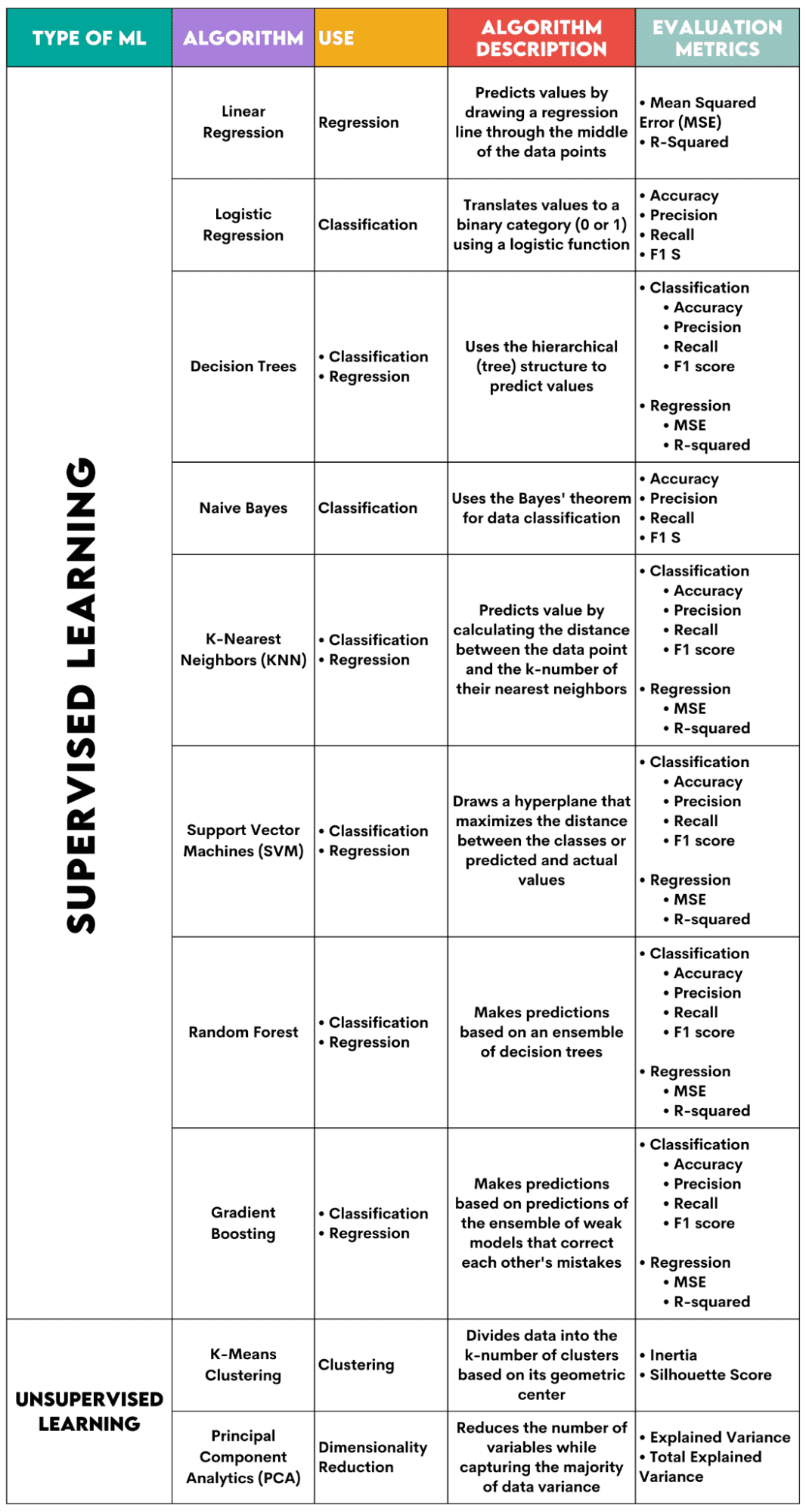
Tässä on yleiskatsaus käsittelemistäni algoritmeista.
Kuva tekijältä
Valvotut oppimisalgoritmit
Kun valitset algoritmia ongelmallesi, on tärkeää tietää, mihin tehtävään algoritmia käytetään.
Datatieteilijänä tulet todennäköisesti käyttämään näitä algoritmeja Pythonissa käyttämällä scikit-learn -kirjasto. Vaikka se tekee (melkein) kaiken puolestasi, on suositeltavaa, että tunnet ainakin kunkin algoritmin sisäisen toiminnan yleiset periaatteet.
Lopuksi, kun algoritmi on koulutettu, sinun tulee arvioida, kuinka hyvin se toimii. Tätä varten jokaisella algoritmilla on joitain vakiomittareita.
1. Lineaarinen regressio
Käytetty: Regressio
Kuvaus: Lineaarinen regressio piirtää suoran viivan kutsutaan regressioviivaksi muuttujien välillä. Tämä viiva kulkee suunnilleen datapisteiden keskeltä, mikä minimoi estimointivirheen. Se näyttää riippuvan muuttujan ennustetun arvon riippumattomien muuttujien arvon perusteella.
Arviointimittarit:
- Keskimääräinen neliövirhe (MSE): Edustaa neliön virheen keskiarvoa, jolloin virhe on todellisen ja ennustetun arvojen välinen ero. Mitä pienempi arvo, sitä parempi algoritmi toimii.
- R-neliö: Edustaa riippumattoman muuttujan varianssiprosenttia, jonka riippumaton muuttuja voi ennustaa. Tätä mittaa varten sinun tulee pyrkiä saavuttamaan 1 mahdollisimman lähelle.
2. Logistinen regressio
Käytetty: Luokittelu
Kuvaus: Se käyttää a logistinen toiminto muuntaa data-arvot binääriluokkaan, eli 0 tai 1. Tämä tehdään käyttämällä kynnysarvoa, joka on yleensä asetettu arvoon 0.5. Binääritulos tekee tästä algoritmista täydellisen ennustamaan binäärituloksia, kuten KYLLÄ/EI, TOSI/EPÄTOSI tai 0/1.
Arviointimittarit:
- Tarkkuus: Oikeiden ja kokonaisennusteiden suhde. Mitä lähempänä 1:tä, sen parempi.
- Tarkkuus: Mallin tarkkuuden mitta positiivisissa ennusteissa; näytetään oikeiden positiivisten ennusteiden ja odotettujen positiivisten tulosten välisenä suhteena. Mitä lähempänä 1:tä, sen parempi.
- Muista: Se mittaa myös mallin tarkkuutta positiivisissa ennusteissa. Se ilmaistaan oikeiden positiivisten ennusteiden ja luokassa tehtyjen kokonaishavaintojen välisenä suhteena. Lue lisää näistä mittareista tätä.
- F1-pisteet: Mallin muistamisen ja tarkkuuden harmoninen keskiarvo. Mitä lähempänä 1:tä, sen parempi.
3. Päätöspuut
Käytetty: Regressio ja luokittelu
Kuvaus: Päättävät puut ovat algoritmeja, jotka käyttävät hierarkkista tai puurakennetta arvon tai luokan ennustamiseen. Juurisolmu edustaa koko tietojoukkoa, joka sitten haarautuu päätössolmuihin, haarautumiin ja lähteisiin muuttujan arvojen perusteella.
Arviointimittarit:
- Tarkkuus, tarkkuus, muistaminen ja F1-pisteet -> luokittelua varten
- MSE, R-neliö -> regressiolle
4. Naivisti Bayes
Käytetty: Luokittelu
Kuvaus: Tämä on joukko luokittelualgoritmeja, joita käytetään Bayesin lause, mikä tarkoittaa, että ne olettavat luokan ominaisuuksien välisen riippumattomuuden.
Arviointimittarit:
- tarkkuus
- Tarkkuus
- Palauttaa mieleen
- F1 pisteet
5. K-Lähimmät naapurit (KNN)
Käytetty: Regressio ja luokittelu
Kuvaus: Se laskee testitietojen ja testitietojen välisen etäisyyden k-luku lähimmistä datapisteistä harjoitustiedoista. Testitiedot kuuluvat luokkaan, jossa on enemmän "naapureita". Mitä tulee regressioon, ennustettu arvo on k valitun harjoituspisteen keskiarvo.
Arviointimittarit:
- Tarkkuus, tarkkuus, muistaminen ja F1-pisteet -> luokittelua varten
- MSE, R-neliö -> regressiolle
6. Tuki vektorikoneille (SVM)
Käytetty: Regressio ja luokittelu
Kuvaus: Tämä algoritmi piirtää a hypertaso eri tietoluokkien erottamiseen. Se on sijoitettu suurimmalle etäisyydelle jokaisen luokan lähimmistä pisteistä. Mitä suurempi datapisteen etäisyys hypertasosta on, sitä enemmän se kuuluu luokkaansa. Regression periaate on samanlainen: hypertaso maksimoi ennustetun ja todellisen arvojen välisen etäisyyden.
Arviointimittarit:
- Tarkkuus, tarkkuus, muistaminen ja F1-pisteet -> luokittelua varten
- MSE, R-neliö -> regressiolle
7. Random Forest
Käytetty: Regressio ja luokittelu
Kuvaus: Satunnainen metsäalgoritmi käyttää päätöspuita, jotka sitten tekevät päätösmetsän. Algoritmin ennuste perustuu useiden päätöspuiden ennustukseen. Tiedot kohdistetaan eniten ääniä saaneelle luokalle. Regressiota varten ennustettu arvo on kaikkien puiden ennustettujen arvojen keskiarvo.
Arviointimittarit:
- Tarkkuus, tarkkuus, muistaminen ja F1-pisteet -> luokittelua varten
- MSE, R-neliö -> regressiolle
8. Gradientin tehostaminen
Käytetty: Regressio ja luokittelu
Kuvaus: Nämä algoritmit käyttää joukkoa heikkoja malleja, jolloin jokainen seuraava malli tunnistaa ja korjaa edellisen mallin virheet. Tätä prosessia toistetaan, kunnes virhe (häviöfunktio) on minimoitu.
Arviointimittarit:
- Tarkkuus, tarkkuus, muistaminen ja F1-pisteet -> luokittelua varten
- MSE, R-neliö -> regressiolle
Valvomattomat oppimisalgoritmit
9. K-Means Clustering
Käytetty: Clustering
Kuvaus: Algoritmi jakaa tietojoukon k-luvun klusteriin, joista jokaista edustaa sen sentroidi tai geometrinen keskusta. Iteratiivisella prosessilla, jossa data jaetaan k-määrään klustereita, tavoitteena on minimoida datapisteiden ja niiden klusterin painopisteen välinen etäisyys. Toisaalta se yrittää myös maksimoida näiden datapisteiden etäisyyden muiden klustereiden sentroidista. Yksinkertaisesti sanottuna samaan klusteriin kuuluvien tietojen tulee olla mahdollisimman samankaltaisia ja erilaisia kuin muiden klustereiden data.
Arviointimittarit:
- Inertia: Kunkin datapisteen etäisyyden neliön summa lähimmästä klusterin painopisteestä. Mitä pienempi inertia-arvo, sitä kompaktimpi klusteri.
- Silhouette Score: Se mittaa klusterien koheesiota (tietojen samankaltaisuus omassa klusterissaan) ja erottelua (tietojen ero muista klustereista). Tämän pistemäärän arvo vaihtelee -1:stä +1:een. Mitä korkeampi arvo, sitä paremmin tiedot sopivat klusteriinsa, ja sitä huonommin se täsmää muihin klustereihin.
10. Pääkomponenttianalyysi (PCA)
Käytetty: Ulottuvuuden pienentäminen
Kuvaus: Algoritmi vähentää käytettävien muuttujien määrää rakentamalla uusia muuttujia (pääkomponentteja) samalla kun yrittää maksimoida datan siepatun varianssin. Toisin sanoen se rajoittaa tiedot yleisimpiin komponentteihinsa menettämättä kuitenkaan tietojen olemusta.
Arviointimittarit:
- Selitetty varianssi: kunkin pääkomponentin kattaman varianssin prosenttiosuus.
- Selitetty kokonaisvarianssi: Kaikkien pääkomponenttien kattaman varianssin prosenttiosuus.
Koneoppiminen on olennainen osa datatieteitä. Näiden kymmenen algoritmin avulla katat koneoppimisen yleisimmät tehtävät. Tietenkin tämä yleiskatsaus antaa sinulle vain yleiskuvan kunkin algoritmin toiminnasta. Tämä on siis vasta alkua.
Nyt sinun on opittava toteuttamaan nämä algoritmit Pythonissa ja ratkaisemaan todellisia ongelmia. Siinä suosittelen scikit-learnin käyttöä. Ei vain siksi, että se on suhteellisen helppokäyttöinen ML-kirjasto, vaan myös sen vuoksi laajat materiaalit ML-algoritmeilla.
Nate Rosidi on datatieteilijä ja tuotestrategiassa. Hän on myös analytiikkaa opettava dosentti ja StrataScratch-alustan perustaja, joka auttaa datatieteilijöitä valmistautumaan haastatteluihin huippuyritysten todellisilla haastattelukysymyksillä. Nate kirjoittaa viimeisimmistä uramarkkinoiden trendeistä, antaa haastatteluneuvoja, jakaa datatieteen projekteja ja kattaa kaiken SQL:n.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms
- :on
- :On
- :ei
- :missä
- 1
- 10
- 5
- a
- Meistä
- tarkkuus
- todellinen
- lisäaine
- neuvot
- suositeltavaa
- Jälkeen
- AIR
- algoritmi
- algoritmit
- Kaikki
- melkein
- jo
- Myös
- Vaikka
- an
- Analytics
- ja
- vastaus
- käyttää
- suunnilleen
- OVAT
- AS
- osoitettu
- olettaa
- At
- yrittää
- keskimäärin
- perustua
- Pohjimmiltaan
- BE
- koska
- Aloittelija
- Aloittelijan
- ovat
- kuuluvat
- kuuluu
- Paremmin
- välillä
- binaarinen
- oksat
- mutta
- by
- laskee
- nimeltään
- CAN
- kiinni
- Kaappaaminen
- Ura
- Kategoria
- tietty
- valita
- valittu
- luokka
- luokat
- luokittelu
- lähellä
- lähempänä
- lähin
- Cluster
- koheesio
- Yhteinen
- kompakti
- Yritykset
- komponentti
- osat
- rakentamalla
- sisältää
- korjata
- kurssi
- kattaa
- katettu
- kannet
- tiedot
- datapisteet
- tietojenkäsittely
- tietojen tutkija
- päätös
- riippuvainen
- yksityiskohta
- ero
- eri
- ohjeet
- Sairaus
- etäisyys
- selvä
- ero
- jakaa
- jakava
- do
- ei
- tehty
- kiinnittää
- e
- kukin
- helppo käyttää
- Työllisiä
- sitoutua
- virhe
- virheet
- ydin
- olennainen
- Eetteri (ETH)
- arvioida
- Joka
- kaikki
- odotettu
- selitti
- ilmaistuna
- f1
- perhe
- Ominaisuudet
- harvat
- Fields
- löytäminen
- Etunimi
- Ensiaskeleet
- varten
- metsä
- perustaja
- alkaen
- toiminto
- general
- saada
- antaa
- Antaminen
- tavoite
- Goes
- Ryhmä
- ohjaavat
- käsi
- he
- auttaa
- siten
- tätä
- korkeampi
- Miten
- Miten
- HTML
- HTTPS
- Ihmiset
- i
- Minä
- ajatus
- if
- toteuttaa
- tärkeä
- in
- Muilla
- itsenäisyys
- itsenäinen
- henkilökohtainen
- inertia
- sisempi
- panos
- Haastatella
- haastattelu kysymykset
- Haastattelut
- tulee
- IT
- SEN
- vain
- KDnuggets
- Tietää
- suurin
- uusin
- OPPIA
- oppiminen
- vähiten
- lehdet
- Kirjasto
- rajat
- linja
- lineaarinen
- Lista
- menettää
- pois
- alentaa
- kone
- koneoppiminen
- Koneet
- tehty
- tärkein
- tehdä
- TEE
- monet
- markkinat
- Hyväksytty
- Maksimoida
- Maksimoi
- tarkoittaa
- merkitys
- välineet
- mitata
- toimenpiteet
- Metrics
- Keskimmäinen
- minimoida
- minimointia
- ML
- ML-algoritmit
- malli
- mallit
- lisää
- eniten
- naiivi
- nimi
- luonnollisesti
- Tarve
- naapurit
- Uusi
- solmu
- solmut
- numero
- havainnot
- of
- Öljy
- on
- ONE
- vain
- or
- Muut
- Tulos
- tuloksiin
- yleiskatsaus
- oma
- osa
- potilas
- kuviot
- osuus
- täydellinen
- suorituskyky
- suorittaa
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- Kohta
- pistettä
- asemoitu
- positiivinen
- mahdollinen
- Tarkkuus
- ennustaa
- ennusti
- ennustamiseen
- ennustus
- Ennusteet
- Predictor
- Valmistella
- edellinen
- Hinnat
- Pääasiallinen
- periaate
- periaatteet
- prioriteetti
- todennäköisesti
- Ongelma
- ongelmia
- prosessi
- Tuotteet
- Opettaja
- hankkeet
- laittaa
- Python
- kysymykset
- satunnainen
- vaihtelee
- suhde
- Lue
- todellinen
- vastaanottaa
- tunnustaa
- suositella
- vähentää
- vähentämällä
- viittaa
- suhteen
- regressio
- suhteellisesti
- toistuva
- edustettuina
- edustaa
- REST
- juuri
- s
- sama
- tiede
- Tiedemies
- tutkijat
- scikit opittava
- pisteet
- erillinen
- palvelee
- setti
- osakkeet
- shouldnt
- esitetty
- Näytä
- samankaltainen
- yksinkertaisesti
- So
- SOLVE
- jonkin verran
- spam
- SQL
- Squared
- standardi
- Alkaa
- Askeleet
- Yhä
- suoraan
- Strategia
- pyrittävä
- rakenne
- myöhempi
- niin
- summa
- valvonta
- tuki
- SVG
- ottaa
- Puhua
- Tehtävä
- tehtävät
- Opetus
- kymmenen
- testi
- kuin
- että
- -
- heidän
- sitten
- Siellä.
- Nämä
- ne
- tätä
- kynnys
- Kautta
- Näin
- että
- liian
- ylin
- Top 10
- Yhteensä
- koulutettu
- koulutus
- Kääntää
- puu
- Puut
- Trendit
- yrittää
- Turing
- kaksi
- tyyppi
- tyypit
- ymmärtäminen
- asti
- käyttää
- käytetty
- käyttötarkoituksiin
- käyttämällä
- yleensä
- arvo
- arvot
- muuttuja
- muuttujat
- vektori
- hyvin
- ääntä
- haluta
- we
- HYVIN
- Mitä
- joka
- vaikka
- koko
- wikipedia
- tulee
- with
- sisällä
- ilman
- sanoja
- louhos
- toimii
- huonompi
- te
- Sinun
- zephyrnet