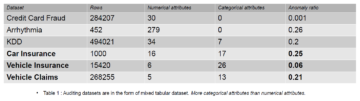
Introduction
Avec l'avènement du RAG (Retrieval Augmented Generation) et grands modèles linguistiques (LLM), des tâches à forte intensité de connaissances telles que la réponse aux questions sur les documents, sont devenues beaucoup plus efficaces et robustes sans qu'il soit nécessaire d'affiner immédiatement un LLM coûteux pour résoudre les tâches en aval. Dans cet article, nous allons plonger dans le monde du QnA de documents basé sur RAG en utilisant Gemini AI et Langchain de Google. Parallèlement à cela, de nombreuses discussions ont eu lieu sur la préservation de la mémoire conversationnelle tout en tirant parti des LLM pour QnA. Dans cet esprit, nous apprendrons également comment créer une mémoire sémantique personnalisée et l'intégrer à notre RAG pour créer une interface conversationnelle où l'utilisateur peut poser des questions de suivi et poursuivre la discussion. Sur ce, creusons !
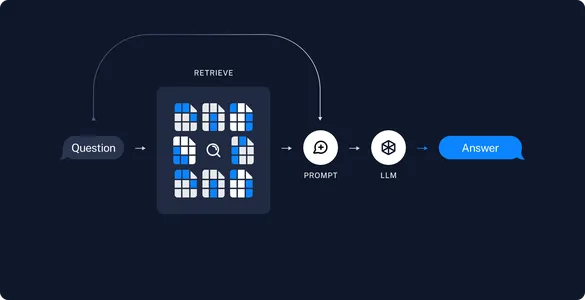
Objectifs d'apprentissage
- Lisez et stockez des documents PDF dans un magasin de vecteurs à l'aide de Gemini Embeddings.
- Créez un lecteur PDF personnalisé pour insérer des informations de métadonnées en fonction de notre choix et de notre cas d'utilisation.
- Générez des réponses aux requêtes des utilisateurs à l'aide du modèle Gemini Pro.
- Implémentez la mise en cache sémantique pour stocker les réponses LLM aux requêtes et utilisez-les comme réponses à des requêtes similaires.
Table des matières
Converser avec des documents
Création d'une application de réponse aux questions sur un document est beaucoup plus facile maintenant qu’il y a un an. L'API OpenAI est le choix principal pour la plupart des applications RAG depuis son lancement, mais pour les petites applications avec moins ou pas de financement, OpenAI devient un choix coûteux. C'est ici que Google API Gémeaux attire l'attention. La version gratuite de l'API prend en charge jusqu'à 60 QPM, ce qui peut sembler moins mais est utile pour les applications non centrées sur le client ou pour les amateurs qui ne veulent pas dépenser d'argent pour leurs projets.
De plus, dans cet article, nous implémenterons également la mise en cache sémantique, ce qui sera utile pour les applications qui utilisent la version payante de API OpenAI. Maintenant, avant de passer aux actions pratiques, comprenons ce qu'est la mise en cache sémantique.
Qu’est-ce que la mise en cache sémantique ?
La mise en cache sémantique est une sorte de mise en cache qui peut être utilisée pour mettre en cache les réponses LLM. Il stocke la réponse LLM pour la requête et renvoie la même réponse lorsque la même requête ou une requête similaire est demandée. Cela permet de réduire les appels LLM inutiles et, par conséquent, de réduire les coûts des API.
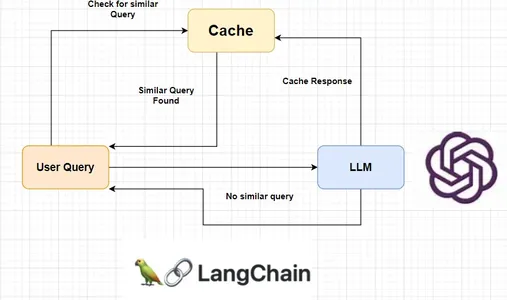
Langchain fournit une large gamme d'outils de cache LLM comme Cache sémantique Redis, GPTCache, AstraDB, etc. Cependant, ils ne sont pas précis en termes de reconnaissance précise de requêtes similaires. Cela se produit en raison des scores de similarité élevés pour les requêtes qui diffèrent par un nombre ou un mot. Eh bien, nous allons également résoudre le problème en créant notre propre système de cache sémantique en utilisant le même concept.
Document pratique QnA avec Langchain + Gemini Pro avec mise en cache sémantique
La première étape de la création de ce système RAG consiste à créer le pipeline d'ingestion. Le pipeline d'ingestion permet simplement à l'utilisateur de télécharger le(s) document(s) pour répondre aux questions. Nous initialisons un magasin de vecteurs, puis y stockons le contenu du document. Nous stockerons le contenu des documents, leurs intégrations et les informations sur les métadonnées du document dans le magasin vectoriel.
Pour les intégrations, nous utiliserons le modèle d'intégration fourni par Gemini. Nous créerons également notre lecteur PDF pour ajouter des informations supplémentaires telles que les numéros de page, les noms de fichiers, etc., dans les métadonnées. Nous utiliserons le Lac profond magasin de vecteurs pour stocker les documents pour RAG ainsi que pour la mise en cache sémantique plus tard dans la chaîne d'assurance qualité.
Guide étape par étape pour documenter QnA avec Langchain + Gemini Pro
Commençons le processus de création d'un système QnA de documents à l'aide de Google Gemini Pro et Langchain, avec ce guide détaillé en 4 étapes.
Étape 1 : Création de la clé API Gemini
La première étape consistera à créer une clé API pour Gemini AI. Vous pouvez ignorer cette étape si vous disposez déjà d’une clé prête. Sinon, suivez les étapes ci-dessous pour créer une nouvelle clé API :
- Cliquez sur https://aistudio.google.com/app
- Cliquez sur Obtenir la clé API -> Créer une clé API.
- Cliquez sur « Créer une clé API sur un nouveau projet » ou « Rechercher des projets Google Cloud » et sélectionnez un projet. Attendez ensuite que la clé soit générée.
- Copiez la clé API générée.
Mettez maintenant cette clé dans le fichier config.py dans la variable GOOGLE_API_KEY. Nous sommes maintenant prêts à partir. Créez un environnement virtuel à l'aide de l'outil de votre choix et utilisez le fichier exigences.txt fourni pour installer les packages requis. Veuillez éviter de modifier la version fournie des packages car cela pourrait interrompre votre application finale.
Voici le contenu du fichier exigences.txt :
deeplake==3.8.19
langchain==0.1.3
langchain-community==0.0.20
langchain-core==0.1.23
langchain-google-genai==0.0.11
langsmith==0.0.87
lxml==4.9.4
nltk==3.8.1
numpy==1.26.2
openai==0.28.0
pydantic==2.5.3
pydantic_core==2.14.6
PyMuPDF==1.23.21
pypdf==3.17.4
pypdfium2==4.25.0
scipy==1.12.0
sentence-transformers==2.3.1
tiktoken==0.5.2
transformers==4.36.2Exécutez le code suivant pour installer tous les packages nécessaires :
# For linux and macOS systems:
pip install -r requirements.txt
# For Windows systems:
python -m pip install -r requirements.txtVous trouverez ci-dessous la base de code complète du pipeline d'ingestion :
import config as cfg
from langchain.vectorstores.deeplake import DeepLake
from src.pdf_reader import PDFReader
from langchain_google_genai import (
GoogleGenerativeAIEmbeddings,
)
class Ingestion:
"""Ingestion class for ingesting documents to vectorstore."""
def __init__(self):
self.text_vectorstore = None
self.image_vectorstore = None
self.text_retriever = None
self.embeddings = GoogleGenerativeAIEmbeddings(
model="models/embedding-001",
google_api_key=cfg.GOOGLE_API_KEY,
)
def ingest_documents(
self,
file: str,
):
# Initialize the PDFReader and load the PDF as chunks
loader = PDFReader()
chunks = loader.load_pdf(file_path=file)
# Initialize the vector store
vstore = DeepLake(
dataset_path="database/text_vectorstore",
embedding=self.embeddings,
overwrite=True,
num_workers=4,
verbose=False,
)
# Ingest the chunks
_ = vstore.add_documents(chunks)Décomposons le code et comprenons chaque ligne rapidement. Nous avons une classe Ingestion qui peut être initialisée. Dans son constructeur, nous avons initialisé les Gemini Embeddings en utilisant le nom du modèle et la clé API, que nous importons depuis le fichier de configuration. Il est à noter que nous pouvons utiliser n'importe quel modèle d'intégration ici et sans nous limiter à l'utilisation de Gemini Embeddings.
Nous créons ensuite une méthode ingest_documents, qui lit les documents et transfère le contenu dans le magasin de vecteurs. Pour ce faire, nous initialisons notre lecteur PDF personnalisé, puis divisons le document en morceaux. Ceci est géré en interne par notre lecteur PDF, qui sera abordé dans la section suivante.
Maintenant que nous disposons de fragments de documents, nous pouvons les ingérer dans la base de données vectorielles. Nous initialisons le magasin de vecteurs Deeplake en utilisant le chemin et les intégrations que nous avons initialisées plus tôt dans le constructeur. De plus, nous définissons le paramètre overwrite sur True afin que le contenu précédent du magasin de vecteurs soit écrasé. Nous ajoutons ensuite les morceaux extraits du document au magasin de vecteurs.
Étape 2 : Lecture, chargement et traitement du PDF
Le lecteur PDF que nous avons initialisé précédemment est un lecteur PDF personnalisé que nous allons créer pour notre cas d'utilisation. Nous utiliserons le PyPDFLoader de Langchain pour charger le document PDF et CharacterTextSplitter pour diviser le document en morceaux de plus petite taille. Ensuite, nous mettons à jour les métadonnées des morceaux en utilisant nos informations préférées telles que le numéro de page et le nom de fichier. Vous trouverez ci-dessous la base de code complète de l'outil PDF Reader :
import os
import config as cfg
from langchain.document_loaders.pdf import PyPDFLoader
from langchain.text_splitter import (
CharacterTextSplitter,
)
from langchain.schema import Document
class PDFReader:
"""Custom PDF Loader to embed metadata with the pdfs."""
def __init__(self) -> None:
self.file_name = ""
self.total_pages = 0
def load_pdf(self, file_path):
# Get the filename from file path
self.file_name = os.path.basename(file_path)
# Initialize Langchain's PyPDFLoader to load the PDF pages
loader = PyPDFLoader(file_path)
# Initialize the text splitter
text_splitter = CharacterTextSplitter(
separator="n",
chunk_size=cfg.PDF_CHARSPLITTER_CHUNKSIZE,
chunk_overlap=cfg.PDF_CHARSPLITTER_CHUNK_OVERLAP,
)
# Load the pages from the document
pages = loader.load()
self.total_pages = len(pages)
chunks = []
# Loop through the pages
for idx, page in enumerate(pages):
# Append each page as Document object with modified metadata
chunks.append(
Document(
page_content=page.page_content,
metadata=dict(
{
"file_name": self.file_name,
"page_no": str(idx + 1),
"total_pages": str(self.total_pages),
}
),
)
)
# Split the documents using splitter
final_chunks = text_splitter.split_documents(chunks)
return final_chunksDécomposons le code et comprenons chaque ligne rapidement. Le constructeur de classe a deux variables locales file_name et total_pages qui sont initialisées respectivement sous forme de chaîne vide et 0. La classe possède une méthode principale appelée load_pdf qui charge le contenu du document et le divise en morceaux plus petits. Nous initialisons d’abord le PyPDFLoader de Langchain en utilisant le chemin du fichier. Initialisez ensuite l'objet Character splitter qui sera utilisé plus tard pour diviser les morceaux. Le séparateur de caractères prend en compte 3 arguments : séparateur, taille de bloc et chevauchement de blocs.
Le séparateur par défaut est « nn », ce qui n'est pas utile lors de l'utilisation du chevauchement de morceaux, nous l'avons donc défini sur « n ». Nous pouvons avoir la taille et le chevauchement des morceaux de notre choix. Pour cet exemple, nous pouvons les définir respectivement sur 1000 et 200. Ensuite, nous chargeons le document à l'aide de l'instance de chargement et obtenons le nombre total de pages.
Nous parcourons ensuite les pages chargées à partir du PDF et créons une nouvelle liste d'objets de document en utilisant le page_content et nos informations de métadonnées. À ce stade, nous disposons d’une liste de morceaux du document avec des métadonnées supplémentaires. Ensuite, nous procédons à la division des morceaux à l'aide du séparateur de texte et les renvoyons.
Étape 3 : Construire le cache sémantique
Ensuite, construisons notre service de cache sémantique pour stocker les réponses LLM et les utiliser comme réponses pour des requêtes similaires. Vous trouverez ci-dessous le code de l'outil CustomGPTCache :
from typing import List
import config as cfg
from langchain.schema import Document
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
class CustomGPTCache:
def __init__(self) -> None:
# Initialize the embeddings model and cache vector store
self.embeddings = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L12-v2"
)
self.response_cache_store = DeepLake(
dataset_path="database/cache_vectorstore",
embedding=self.embeddings,
read_only=False,
num_workers=4,
verbose=False,
)
def cache_query_response(self, query: str, response: str):
# Create a Document object using query as the content and it's
# response as metadata
doc = Document(
page_content=query,
metadata={"response": response},
)
# Insert the Document object into cache vectorstore
_ = self.response_cache_store.add_documents(documents=[doc])
def find_similar_query_response(self, query: str, threshold: int):
try:
# Find similar query based on the input query
sim_response = self.response_cache_store.similarity_search_with_score(
query=query, k=1
)
# Return the response from the fetched entry if it's score is more
# than threshold
return [
{
"response": res[0].metadata["response"],
}
for res in sim_response
if res[1] > threshold
]
except Exception as e:
raise Exception(e)Voyons comment nous construisons le système de cache. Nous utilisons le modèle all-MiniLM-L12-v2 de Sentence Transformers pour créer des intégrations pour le cache. La motivation de cette approche était la suivante : pour les intégrations de dimension supérieure, nous obtenons une plage plus élevée de scores de similarité entre des requêtes différentes, ce qui entraîne un mauvais déclenchement du cache.
Grâce à des recherches approfondies, j'ai observé qu'en utilisant des plongements de dimensions inférieures, disons 256, nous obtenons une plage plus large de scores de similarité entre 0.3 et 1.0. Pour en revenir au code, nous initialisons les intégrations à l'aide de SentenceTransformerEmbeddings de Langchain en spécifiant le nom du modèle. Ensuite, nous initialisons le magasin de vecteurs Deeplake où la requête et les réponses seront stockées.
Notez que lors de l'initialisation du magasin de vecteurs de cache, nous ne définissons pas le paramètre d'écrasement sur True car cela serait contre-intuitif. Nous ajouterons deux méthodes à la classe CustomGPTCache : cache_query_response et find_similar_query_response. Discutons-en.
1. cache_query_response : Cette méthode est appelée dans QAChain lorsqu'une réponse LLM est générée. Un objet Document est créé avec la requête dans page_content et la réponse dans le champ de métadonnées. Ensuite, cet objet Document est ajouté au magasin de vecteurs.
2. find_similar_query_response : Cette méthode est appelée dans QAChain à chaque exécution. Il renvoie une liste de dictionnaires contenant des réponses. La requête de l'utilisateur est transmise à cette méthode à chaque exécution. Il utilise la requête pour effectuer une recherche de similarité sur le magasin de vecteurs de cache afin de trouver la requête la plus similaire mise en cache. Nous ne récupérons qu’une seule entrée similaire dans le magasin de vecteurs. Ensuite, nous créons une liste de ces réponses et imposons un seuil au score de similarité pour éviter de renvoyer des réponses non pertinentes.
Étape 4 : Documenter les questions et les réponses à l'aide de QAChain
Enfin, nous verrons comment QAChain utilise le magasin de vecteurs de cache et le docstore pour générer des réponses aux requêtes des utilisateurs. Nous initialisons les intégrations Gemini et le modèle Gemini dans le constructeur de classe en utilisant les paramètres nécessaires comme le nom du modèle, la clé API, etc. Nous initialisons également ici le cache qui sera utilisé dans les autres méthodes. Ensuite, nous ajouterons deux méthodes à la classe QAChain pour gérer les requêtes des utilisateurs : generate_response et Ask_question.
1. générer_réponse : Cette méthode gère la partie réponse LLM de QAChain. Il prend simplement une requête utilisateur et génère une réponse pour la requête à l'aide de la chaîne RetrievalQA de Langchain. Une fois la réponse générée, elle est mise en cache à l'aide de la méthode cache_query_response de CustomGPTCache et la réponse est renvoyée.
2. question_question : Cette méthode est appelée pour chaque réponse de l'utilisateur. Tout d’abord, la méthode find_similar_query_response de CustomGPTCache est appelée à l’aide de la requête utilisateur. S'il renvoie une liste de réponses, la réponse est renvoyée, sinon la méthode generate_response est appelée à l'aide de la requête utilisateur. De plus, la méthode generate_response est appelée si une exception est levée du côté du cache. Vous trouverez ci-dessous la base de code du pipeline QAChain pour référence.
import config as cfg
from src.cache import CustomGPTCache
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.vectorstores.deeplake import DeepLake
from langchain_google_genai import (
GoogleGenerativeAIEmbeddings,
ChatGoogleGenerativeAI
)
class QAChain:
def __init__(self) -> None:
# Initialize Gemini Embeddings
self.embeddings = GoogleGenerativeAIEmbeddings(
model="models/embedding-001",
google_api_key=cfg.GOOGLE_API_KEY,
task_type="retrieval_query",
)
# Initialize Gemini Chat model
self.model = ChatGoogleGenerativeAI(
model="gemini-pro",
temperature=0.3,
google_api_key=cfg.GOOGLE_API_KEY,
convert_system_message_to_human=True,
)
# Initialize GPT Cache
self.cache = CustomGPTCache()
self.text_vectorstore = None
self.text_retriever = None
def ask_question(self, query):
try:
# Search for similar query response in cache
cached_response = self.cache.find_similar_query_response(
query=query, threshold=cfg.CACHE_THRESHOLD
)
# If similar query response is present,vreturn it
if len(cached_response) > 0:
print("Using cache")
result = cached_response[0]["response"]
# Else generate response for the query
else:
print("Generating response")
result = self.generate_response(query=query)
except Exception as _:
print("Exception raised. Generating response.")
result = self.generate_response(query=query)
return result
def generate_response(self, query: str):
# Initialize the vectorstore and retriever object
vstore = DeepLake(
dataset_path="database/text_vectorstore",
embedding=self.embeddings,
read_only=True,
num_workers=4,
verbose=False,
)
retriever = vstore.as_retriever(search_type="similarity")
retriever.search_kwargs["distance_metric"] = "cos"
retriever.search_kwargs["fetch_k"] = 20
retriever.search_kwargs["k"] = 15
# Write prompt to guide the LLM to generate response
prompt_template = """
<YOUR PROMPT HERE>
Context: {context}
Question: {question}
Answer:
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
# Create Retrieval QA chain
qa = RetrievalQA.from_chain_type(
llm=self.model,
retriever=retriever,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
)
# Run the QA chain and store the response in cache
result = qa({"query": query})["result"]
self.cache.cache_query_response(query=query, response=result)
return resultMaintenant que l’ensemble du pipeline est prêt, utilisons-le pour tester notre application. La première étape consiste à ingérer le document. Nous initialisons l'objet Ingestion et appelons la méthode ingest_document en utilisant le chemin du fichier du document à stocker.
from src.ingestion import Ingestion
ingestion = Ingestion()
file = "Apple 10k.pdf"
ingestion.ingest_documents(
file=file
)Une fois le document ingéré, nous initialiserons l'objet QAChain. Ensuite, nous appelons la méthode Ask_question en utilisant la requête utilisateur pour générer une réponse.
from src.qachain import QAChain
qna = QAChain()
%%time
query = "What were the highlights for 2nd quarter of FY2023?"
results = qna.ask_question(
query=query
)
print(results)
# OUTPUT:
# Generating response
# The highlights for the second quarter of FY2023 were:
# • MacBook Pro 14”, MacBook Pro 16” and Mac mini; and
# • Second-generation HomePod.
# CPU times: total: 2.94 s
# Wall time: 11.4 s
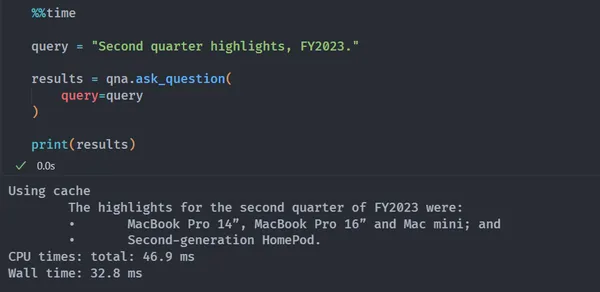
%%time
query = "Second quarter highlights, FY2023."
results = qna.ask_question(
query=query
)
print(results)
# OUTPUT:
# Using cache
# The highlights for the second quarter of FY2023 were:
# • MacBook Pro 14”, MacBook Pro 16” and Mac mini; and
# • Second-generation HomePod.
# CPU times: total: 46.9 ms
# Wall time: 32.8 ms
Performances et limites des applications
Il existe plusieurs bibliothèques d'évaluation RAG qui peuvent être utilisées pour évaluer les performances de l'application. Les deux plus populaires sont RAGAS et Tonic Validate Metrics. Les deux offrent des mesures similaires telles que le score de similarité de réponse, la précision de récupération, la précision d'augmentation, la précision/pertinence d'augmentation et le k-recall de récupération, qui aident à évaluer les performances de l'application. Bien que peu d'exceptions soient gérées dans les bases de code ci-dessus, il existe quelques cas où l'application peut planter. Le PDFReader n'a actuellement aucune vérification sur le type de fichier d'entrée qui doit être traité.
Cette application est largement réutilisable dans un large éventail de cas d'utilisation professionnels tels que le médical, la finance, l'industrie, le commerce électronique, etc. Dans les industries médicales, les pipelines RAG peuvent aider à dépanner rapidement les pannes d'instruments, à décider du médicament approprié pour une condition médicale, etc. Les pipelines RAG peuvent aider à répondre aux requêtes provenant d'un vaste corpus de documents financiers en un clin d'œil. Leurs capacités de récupération et de réponse rapides les rendent idéales pour répondre à des questions sur de grands ensembles de données. Les pipelines RAG peuvent également permettre un examen rapide des avancées de recherche antérieures sur un sujet et suggérer une portée de recherche plus approfondie.
Bien que notre pipeline actuel soit prêt à être utilisé pour n’importe quel cas d’utilisation, il existe certaines limites. Le modèle professionnel Gemini a actuellement une longueur de contexte de 32 Ko, ce qui pourrait ne pas convenir aux grandes bases de connaissances. Une autre suggestion serait d'utiliser le Modèle Gémeaux Pro 1.5 qui prend en charge une longueur de contexte allant jusqu'à 1 million. Le pipeline actuel n'a pas de mémoire de discussion, le modèle n'aura donc pas le contexte des conversations précédentes. Langchain propose plusieurs options de mémoire (Memory Docs) qui peuvent être intégrées au pipeline sans effort.
Réutilisabilité du code
- Le code du pipeline d'ingestion peut être réutilisé pour créer des systèmes d'ingestion pour d'autres applications nécessitant le stockage et la récupération de documents.
- L'outil PDF Reader peut être réutilisé pour d'autres applications nécessitant un traitement et une extraction de métadonnées à partir de documents PDF.
- Le code CustomGPTCache peut être utilisé dans d'autres projets pour mettre en œuvre une mise en cache et une récupération efficaces des réponses LLM ou des cas d'utilisation similaires.
- La classe QAChain peut être adaptée à d'autres systèmes de questions-réponses qui utilisent des magasins de documents et des mécanismes de mise en cache.
Conclusion
Alors, mes amis, c'est ainsi que vous pouvez communiquer avec vos documents grâce aux réponses aux questions basées sur RAG et à la mise en cache sémantique à l'aide de Gemini Pro et Langchain !
Dans cet article, nous avons développé un pipeline qui présente une approche globale de la gestion des documents pour une QnA intelligente. En intégrant les intégrations Gemini de Google, un lecteur PDF personnalisé et la mise en cache sémantique, ce système RAG maintient l'efficacité et la précision en fournissant des réponses aux requêtes des utilisateurs. De plus, la base de code est hautement adaptable, évolutive et fiable pour une variété de cas d'utilisation QnA avec un minimum de modifications de code !
Faits marquants
- Le système RAG implique la création d'un pipeline d'ingestion pour télécharger et stocker des documents pour répondre aux questions.
- Le pipeline d'ingestion utilise les intégrations Gemini pour l'intégration de documents et un lecteur PDF personnalisé pour l'extraction de métadonnées.
- Un service de cache sémantique personnalisé est implémenté pour stocker et récupérer efficacement les réponses LLM pour des requêtes similaires.
- La classe QAChain est chargée de générer des réponses aux requêtes des utilisateurs et d'utiliser le cache et le magasin de vecteurs.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/03/rag-powered-document-qna-semantic-caching-with-gemini-pro/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 1.3
- 10K
- 11
- 12
- 14
- 15%
- 17
- 19
- 2%
- 20
- 200
- 21
- 23
- 25
- 26
- 28
- 2nd
- 32
- 36
- 4
- 4-étape
- 46
- 5
- 6
- 60
- 8
- 87
- 9
- a
- Qui sommes-nous
- au dessus de
- précision
- Avec cette connaissance vient le pouvoir de prendre
- avec précision
- actes
- adapté
- ajouter
- ajoutée
- Supplémentaire
- En outre
- progrès
- avènement
- Après
- depuis
- AI
- Aide
- Tous
- permet
- aux côtés de
- déjà
- aussi
- Bien que
- an
- ainsi que le
- répondre
- répondre
- réponses
- tous
- api
- Apple
- Application
- applications
- une approche
- SONT
- arguments
- autour
- article
- AS
- demander
- demandé
- At
- précaution
- augmentée
- éviter
- RETOUR
- basé
- BE
- devenez
- devient
- était
- before
- commencer
- ci-dessous
- jusqu'à XNUMX fois
- Cligner des yeux
- tous les deux
- Pause
- construire
- Développement
- la performance des entreprises
- mais
- by
- cachette
- la mise en cache
- Appelez-nous
- appelé
- Appels
- CAN
- capacités
- maisons
- cas
- certaines
- chaîne
- Chaînes
- en changeant
- caractère
- le chat
- vérifier
- le choix
- classe
- le cloud
- code
- Base de code
- Venir
- communiquer
- complet
- concept
- condition
- par conséquent
- comprenant
- contenu
- contenu
- contexte
- de la conversation
- conversations
- Core
- correct
- cos
- Costs
- Processeur
- Crash
- engendrent
- créée
- La création
- Courant
- Lecture
- Customiser
- Base de données
- ensembles de données
- Décider
- def
- Réglage par défaut
- détaillé
- développé
- différer
- DIG
- Dimension
- dimensions
- discuter
- discuté
- spirituelle
- plongeon
- do
- docs
- document
- INSTITUTIONNELS
- dollars
- Ne pas
- down
- deux
- e
- e-commerce
- chacun
- Plus tôt
- plus facilement
- efficace
- efficace
- efficacement
- d'effort
- d'autre
- enchâsser
- vide
- permettre
- Tout
- entrée
- Environment
- etc
- Ether (ETH)
- évaluer
- évaluation
- Chaque
- exemple
- Sauf
- exception
- cher
- les
- précieux
- supplémentaire
- extraction
- œil
- échecs
- Récupéré
- few
- champ
- Déposez votre dernière attestation
- finale
- la traduction de documents financiers
- Trouvez
- Prénom
- suivre
- Abonnement
- Pour
- Gratuit
- De
- financement
- plus
- GEMINI
- générer
- généré
- génère
- générateur
- génération
- obtenez
- Go
- aller
- Bien
- Google Cloud
- guide
- manipuler
- manipulés
- Poignées
- Maniabilité
- hands-on
- arrive
- Vous avez
- vous aider
- utile
- aide
- ici
- Haute
- augmentation
- Faits saillants
- très
- amateurs
- Comment
- How To
- Cependant
- HTTPS
- i
- idéal
- IDX
- if
- Immédiat
- Mettre en oeuvre
- mis en œuvre
- la mise en œuvre
- importer
- in
- Dans d'autres
- industriel
- secteurs
- d'information
- contribution
- installer
- instance
- instrument
- intégrer
- des services
- Intégration
- Intelligent
- Interfaces
- intérieurement
- développement
- implique
- aide
- IT
- SES
- saut
- XNUMX éléments à
- ACTIVITES
- Genre
- spécialisées
- langue
- gros
- plus tard
- lancer
- APPRENTISSAGE
- Longueur
- moins
- en tirant parti
- bibliothèques
- comme
- limites
- limité
- Gamme
- linux
- Liste
- llm
- charge
- chargeur
- chargement
- charges
- locales
- Style
- Lot
- baisser
- mac
- macbook
- macos
- Entrée
- maintient
- a prendre une
- mécanismes
- médical
- médecine
- Mémoire
- Métadonnées
- méthode
- méthodes
- Métrique
- pourrait
- million
- l'esprit
- minimal
- modèle
- modifié
- PLUS
- plus efficace
- Par ailleurs
- (en fait, presque toutes)
- Le Plus Populaire
- motivation
- MS
- beaucoup
- prénom
- noms
- nécessaire
- Besoin
- Besoins
- Nouveauté
- next
- aucune
- Aucun
- remarquable
- maintenant
- nombre
- numéros
- objet
- objets
- observée
- of
- code
- on
- ONE
- et, finalement,
- uniquement
- OpenAI
- Options
- or
- OS
- Autre
- autrement
- nos
- sortie
- plus de
- chevauchement
- propre
- Forfaits
- page
- pages
- payé
- paramètre
- paramètres
- partie
- passé
- chemin
- performant
- pipeline
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- Populaire
- alimenté
- La précision
- préféré
- représentent
- conservation
- empêcher
- précédent
- Pro
- procéder
- processus
- traitement
- Projet
- projets
- instructions
- à condition de
- fournit
- aportando
- mettre
- Python
- Questions et réponses
- Trimestre
- requêtes
- question
- question
- fréquemment posées
- Rapide
- vite.
- chiffon
- augmenter
- collectés
- gamme
- Reader
- en cours
- solutions
- reconnaissant
- réduire
- réduit
- référence
- fiable
- exigent
- conditions
- Exigences
- un article
- réponse
- réponses
- responsables
- résultat
- Résultats
- récupération
- retourner
- retour
- Retours
- réutilisable
- réutilisés
- Avis
- robuste
- Courir
- s
- même
- dire
- évolutive
- portée
- But
- scores
- Rechercher
- Deuxièmement
- deuxième quartier
- Section
- sembler
- Sélectionner
- AUTO
- sémantique
- phrase
- service
- set
- plusieurs
- vitrines
- côté
- similaires
- simplement
- depuis
- Taille
- petit
- faibles
- So
- RÉSOUDRE
- en précisant
- passer
- scission
- splits
- Étape
- étapes
- Étapes
- storage
- Boutique
- stockée
- STORES
- stockage
- Chaîne
- suggérer
- convient
- Les soutiens
- combustion propre
- Système
- prend
- tâches
- conditions
- tester
- texte
- que
- qui
- Les
- le monde
- leur
- Les
- puis
- Là.
- l'ont
- this
- ceux
- порог
- Avec
- fiable
- fois
- à
- outil
- les outils
- sujet
- Total
- transformateurs
- oui
- Essai
- deux
- type
- comprendre
- inutile
- Mises à jour
- Utilisation
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- Usages
- en utilisant
- utilise
- Utilisant
- VALIDER
- variable
- les variables
- variété
- vecteur
- version
- Salle de conférence virtuelle
- attendez
- marcher
- Wall
- souhaitez
- était
- we
- webp
- WELL
- ont été
- Quoi
- quand
- qui
- tout en
- WHO
- large
- Large gamme
- plus large
- sera
- fenêtres
- comprenant
- dans les
- sans
- Word
- world
- pourra
- écrire
- an
- you
- Votre
- Youtube
- zéphyrnet