परिचय
जेनरेटिव लार्ज लैंग्वेज मॉडल जैसे GPT, PaLM इत्यादि को बड़ी मात्रा में डेटा पर प्रशिक्षित किया जाता है। ये मॉडल डेटासेट से टेक्स्ट को वैसे नहीं लेते हैं, क्योंकि कंप्यूटर टेक्स्ट को नहीं समझते हैं, वे केवल संख्याओं को समझते हैं। एंबेडिंग पाठ का प्रतिनिधित्व है लेकिन संख्यात्मक प्रारूप में। बड़े भाषा मॉडलों से आने और जाने वाली सारी जानकारी इन एम्बेडिंग के माध्यम से होती है। इन एम्बेडिंग तक सीधे पहुँचना समय लेने वाला है। इसलिए, जिसे वेक्टर डेटाबेस कहा जाता है, वह इन एम्बेडिंग को संग्रहीत करता है जो विशेष रूप से वेक्टर एम्बेडिंग के कुशल भंडारण और पुनर्प्राप्ति के लिए डिज़ाइन किया गया है। इस गाइड में, हम एक ऐसे वेक्टर स्टोर/डेटाबेस, क्रोमा डीबी पर ध्यान केंद्रित करेंगे, जो व्यापक रूप से उपयोग किया जाता है और ओपन-सोर्स है।
सीखने के मकसद
- ChromaDB के साथ एम्बेडिंग उत्पन्न करना और एंबेडिंग मॉडल
- क्रोमा वेक्टर स्टोर के भीतर संग्रह बनाना
- संग्रह के भीतर दस्तावेज़, चित्र और एम्बेडिंग संग्रहीत करना
- डेटा को हटाना और अपडेट करना, संग्रह का नाम बदलना जैसे संग्रह संचालन करना
- अंत में, प्रासंगिक जानकारी निकालने के लिए संग्रहों से पूछताछ करना
इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
विषय - सूची
एंबेडिंग का संक्षिप्त परिचय
एंबेडिंग या वेक्टर एंबेडिंग संख्यात्मक प्रारूप में डेटा (चाहे वह पाठ, चित्र, ऑडियो, वीडियो आदि हो) का प्रतिनिधित्व करने का एक तरीका है, सटीक होने के लिए यह एन-आयामी स्थान (ए) में संख्याओं के रूप में डेटा का प्रतिनिधित्व करने का एक तरीका है संख्यात्मक वेक्टर). इस तरह, एम्बेडिंग हमें समान डेटा को एक साथ क्लस्टर करने की अनुमति देती है। ऐसे मॉडल हैं, जो इन इनपुटों को लेते हैं और उन्हें वैक्टर में परिवर्तित करते हैं। ऐसा ही एक उदाहरण है वर्ड2पुराना, जो Google द्वारा विकसित एक लोकप्रिय एम्बेडिंग मॉडल है, जो शब्दों को वेक्टर में परिवर्तित करता है (वेक्टर एन-आयाम वाले बिंदु हैं)। सभी बड़े भाषा मॉडलों के अपने संबंधित एम्बेडिंग मॉडल होते हैं, जो उनके एलएलएम के लिए एम्बेडिंग बनाते हैं।
इन एम्बेडिंग का उपयोग किस लिए किया जाता है?
शब्दों को वेक्टर में बदलने की अच्छी बात यह है कि हम उनकी तुलना कर सकते हैं। एक कंप्यूटर दो शब्दों की वैसे ही तुलना नहीं कर सकता जैसे वे हैं, लेकिन अगर हम उन्हें संख्यात्मक इनपुट, यानी वेक्टर एम्बेडिंग के रूप में देते हैं तो यह उनकी तुलना कर सकता है। हम समान एम्बेडिंग वाले शब्दों का एक समूह बना सकते हैं। राजा, रानी, राजकुमार और राजकुमारी शब्द एक समूह में दिखाई देंगे क्योंकि वे दूसरे से संबंधित हैं।
इस तरह से एंबेडिंग हमें किसी दिए गए शब्द के समान शब्द ढूंढने की अनुमति देती है। हम इसे वाक्यों में शामिल कर सकते हैं, जहां हम एक वाक्य इनपुट करते हैं और दिए गए डेटा से संबंधित वाक्य प्राप्त करते हैं। यह सिमेंटिक खोज, वाक्य समानता, विसंगति का पता लगाना, चैटबॉट और कई अन्य उपयोग के मामलों का आधार है। किसी दिए गए पीडीएफ, डॉक से प्रश्न उत्तर देने के लिए हम जो चैटबॉट बनाते हैं, वे एम्बेडिंग की इसी अवधारणा का लाभ उठाते हैं। सभी जनरेटिव लार्ज लैंग्वेज मॉडल उन्हें प्रदान किए गए प्रश्नों से संबंधित सामग्री प्राप्त करने के लिए इस दृष्टिकोण का उपयोग करते हैं।
वेक्टर स्टोर और उनकी आवश्यकता
जैसा कि चर्चा की गई है, एम्बेडिंग आमतौर पर किसी भी प्रकार के डेटा का प्रतिनिधित्व करते हैं, एन-आयामी स्थान में संख्यात्मक प्रारूप में असंरचित। अब हम उन्हें कहां संग्रहित करें? इन वेक्टर एम्बेडिंग को संग्रहीत करने के लिए पारंपरिक आरडीएमएस (रिलेशनल डेटाबेस मैनेजमेंट सिस्टम) का उपयोग नहीं किया जा सकता है। यहीं पर वेक्टर स्टोर/वेक्टर डेटाबेस चलन में आते हैं। वेक्टर डेटाबेस को कुशल तरीके से वेक्टर एम्बेडिंग को संग्रहीत और पुनः प्राप्त करने के लिए डिज़ाइन किया गया है। वहाँ कई वेक्टर स्टोर हैं, जो उनके द्वारा समर्थित एम्बेडिंग मॉडल और समान वैक्टर प्राप्त करने के लिए उपयोग किए जाने वाले खोज एल्गोरिदम के प्रकार से भिन्न होते हैं।
हमें आपकी प्रतिक्रिया का बेसब्री से इंतेज़ार हैं। हमें उनकी आवश्यकता है क्योंकि वे हमें आवश्यक डेटा तक त्वरित पहुंच प्रदान करते हैं। आइए पीडीएफ पर आधारित एक चैटबॉट पर विचार करें। अब जब कोई उपयोगकर्ता कोई क्वेरी दर्ज करता है, तो सबसे पहले उस क्वेरी से संबंधित सामग्री को पीडीएफ से प्राप्त करना होगा और इस जानकारी को चैटबॉट को फीड करना होगा। ताकि चैटबॉट क्वेरी से संबंधित यह जानकारी ले सके और उपयोगकर्ता को प्रासंगिक उत्तर साबित कर सके। अब हम उपयोगकर्ता क्वेरी से संबंधित पीडीएफ से प्रासंगिक सामग्री कैसे प्राप्त करेंगे? उत्तर एक सरल समानता खोज है
जब डेटा को वेक्टर एम्बेडिंग में दर्शाया जाता है, तो हम डेटा के विभिन्न हिस्सों के बीच समानताएं पा सकते हैं और किसी विशेष एम्बेडिंग के समान डेटा निकाल सकते हैं। क्वेरी को पहले एक एम्बेडिंग मॉडल द्वारा एम्बेडिंग में परिवर्तित किया जाता है और फिर वेक्टर स्टोर इस वेक्टर एम्बेडिंग को लेता है और फिर अपने डेटाबेस में संग्रहीत अन्य एम्बेडिंग के बीच एक समानता खोज (खोज एल्गोरिदम के माध्यम से) करता है और सभी प्रासंगिक डेटा लाता है। इन प्रासंगिक वेक्टर एम्बेडिंग को फिर बड़े भाषा मॉडल में भेज दिया जाता है जो चैटबॉट है जो उपयोगकर्ता को अंतिम उत्तर उत्पन्न करने के लिए इस जानकारी का उपयोग करता है।
क्रोमा डीबी क्या है?
Chroma, Chroma कंपनी का एक वेक्टर स्टोर/वेक्टर DB है। क्रोमा डीबी, कई अन्य वेक्टर स्टोर्स की तरह, वेक्टर एम्बेडिंग को संग्रहीत करने और पुनर्प्राप्त करने के लिए है। अच्छी बात यह है कि क्रोमा एक फ्री और ओपन सोर्स प्रोजेक्ट है। इससे दुनिया के अन्य कुशल डेवलपर्स को सुझाव देने और डेटाबेस में जबरदस्त सुधार करने का मौका मिलता है और यहां तक कि कोई भी ओपन सोर्स सॉफ्टवेयर के साथ काम करते समय किसी मुद्दे पर त्वरित उत्तर की उम्मीद कर सकता है, क्योंकि पूरा ओपन सोर्स समुदाय वहां देखने के लिए मौजूद है। और उस मुद्दे को हल करें.
वर्तमान में Chroma कोई होस्टिंग सेवाएँ प्रदान नहीं करता है। क्रोमा के आसपास एप्लिकेशन बनाते समय डेटा को स्थानीय फ़ाइल सिस्टम में स्थानीय रूप से संग्रहीत करें। हालाँकि Chroma निकट भविष्य में एक होस्टिंग सेवा बनाने की योजना बना रही है। क्रोमा डीबी वेक्टर एम्बेडिंग को स्टोर करने के विभिन्न तरीके प्रदान करता है। आप उन्हें इन-मेमोरी में संग्रहीत कर सकते हैं, आप उन्हें इन-मेमोरी में सहेज और लोड कर सकते हैं, आप बैकएंड सर्वर से बात करने के लिए क्रोमा क्लाइंट चला सकते हैं। कुल मिलाकर क्रोमा डीबी में एपीआई में केवल 4 फ़ंक्शन हैं, इस प्रकार यह छोटा, सरल और आरंभ करने में आसान है।
आइए क्रोमा डीबी से शुरुआत करें
इस अनुभाग में, हम Chroma इंस्टॉल करेंगे और इसके द्वारा प्रदान की जाने वाली सभी कार्यक्षमताएँ देखेंगे। सबसे पहले, हम लाइब्रेरी को पिप कमांड के माध्यम से स्थापित करेंगे
$ pip install chromadbक्रोमा वेक्टर स्टोर एपीआई
यह पायथन के लिए क्रोमा वेक्टर स्टोर एपीआई डाउनलोड करेगा। इस पैकेज के साथ, हम वेक्टर एम्बेडिंग को संग्रहीत करने, उन्हें पुनर्प्राप्त करने और किसी दिए गए वेक्टर एम्बेडिंग के लिए सिमेंटिक खोज करने जैसे सभी कार्य कर सकते हैं।
import chromadb
from chromadb.config import Settings client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet", persist_directory="/content/" ))
मेमोरी डेटाबेस
हम एक स्थायी इन-मेमोरी डेटाबेस बनाने के साथ शुरुआत करेंगे। उपरोक्त कोड हमारे लिए एक कोड तैयार करेगा। ग्राहक बनाने के लिए हम लेते हैं ग्राहक() क्रोमा डीबी से ऑब्जेक्ट। अब इन-मेमोरी डेटाबेस बनाने के लिए, हम अपने क्लाइंट को निम्नलिखित मापदंडों के साथ कॉन्फ़िगर करते हैं
- chroma_db_impl = "डकडीबी+पैरक्वेट"
- बनी_निर्देशिका = “/सामग्री/”
यह पैराक्वेट फ़ाइल प्रारूप के साथ एक इन-मेमोरी डकडीबी डेटाबेस बनाएगा। और हम वह निर्देशिका प्रदान करते हैं जहां यह डेटा संग्रहीत किया जाना है। यहां हम डेटाबेस को /content/ फ़ोल्डर में सहेज रहे हैं। इसलिए जब भी हम इस कॉन्फ़िगरेशन के साथ क्रोमा डीबी क्लाइंट से जुड़ते हैं, तो क्रोमा डीबी प्रदान की गई निर्देशिका में मौजूदा डेटाबेस की तलाश करेगा और उसे लोड करेगा। यदि यह मौजूद नहीं है तो यह इसे बनायेगा। और जब हम कनेक्शन बंद करते हैं, तो डेटा इस निर्देशिका में सहेजा जाएगा।
अब, हम एक संग्रह बनाएंगे. वेक्टर स्टोर में संग्रह वह जगह है जहां हम वेक्टर एम्बेडिंग, दस्तावेज़ और यदि कोई मेटाडेटा मौजूद है तो उसके सेट को सहेजते हैं। वेक्टर डेटाबेस में संग्रह को रिलेशनल डेटाबेस में एक तालिका के रूप में माना जा सकता है।
संग्रह बनाएँ और दस्तावेज़ जोड़ें
अब हम एक संग्रह बनाएंगे और उसमें दस्तावेज़ जोड़ेंगे।
collection = client.create_collection("my_information") collection.add( documents=["This is a document containing car information", "This is a document containing information about dogs", "This document contains four wheeler catalogue"], metadatas=[{"source": "Car Book"},{"source": "Dog Book"},{'source':'Vechile Info'}], ids=["id1", "id2", "id3"]
)
- यहां हम पहले एक संग्रह बनाकर शुरुआत करते हैं। यहां हम संग्रह को नाम देते हैं "मेरी जानकारी".
- इस संग्रह में, हम दस्तावेज़ जोड़ेंगे। यहां हम 3 दस्तावेज़ जोड़ रहे हैं, हमारे मामले में, हम केवल तीन दस्तावेज़ों के रूप में तीन वाक्य जोड़ रहे हैं। पहला दस्तावेज़ कारों के बारे में है, दूसरा कुत्तों के बारे में है और अंतिम चार पहिया वाहनों के बारे में है।
- हम मेटाडेटा भी जोड़ रहे हैं। तीनों दस्तावेज़ों के लिए मेटाडेटा प्रदान किया गया है।
- प्रत्येक दस्तावेज़ के लिए एक विशिष्ट आईडी की आवश्यकता होती है, इसलिए हम उन्हें id1, id2 और id3 दे रहे हैं
- ये सभी वेरिएबल्स की तरह हैं (जोड़ें) संग्रह से कार्य करें
- कोड चलाने के बाद, इन दस्तावेज़ों को हमारे संग्रह में जोड़ें ”मेरी जानकारी"
वेक्टर डेटाबेस
हमने सीखा कि वेक्टर डेटाबेस में संग्रहीत जानकारी वेक्टर एंबेडिंग के रूप में होती है। लेकिन यहां, हमने टेक्स्ट/टेक्स्ट फ़ाइलें यानी दस्तावेज़ उपलब्ध कराए हैं। तो यह उन्हें कैसे संग्रहीत करता है? क्रोमा डीबी डिफ़ॉल्ट रूप से, एक का उपयोग करता है ऑल-मिनीएलएम-एल6-वी2 हमारे लिए एम्बेडिंग बनाने के लिए वेक्टर एम्बेडिंग मॉडल। यह मॉडल हमारे दस्तावेज़ लेगा और उन्हें वेक्टर एम्बेडिंग में बदल देगा। यदि हम हगिंगफेस या ओपनएआई एम्बेडिंग मॉडल के अन्य वाक्य-ट्रांसफॉर्मर मॉडल की तरह एक विशिष्ट एम्बेडिंग फ़ंक्शन के साथ काम करना चाहते हैं, तो हम इसे इसके अंतर्गत निर्दिष्ट कर सकते हैं एम्बेडिंग_फंक्शन = एम्बेडिंग_फंक्शन_नाम में परिवर्तनीय नाम create_collection() विधि.
हम दस्तावेज़ों को वेक्टर स्टोर तक पहुंचाने के बजाय सीधे उसे एम्बेडिंग भी प्रदान कर सकते हैं। बिल्कुल दस्तावेज़ पैरामीटर की तरह create_collection, हमारे पास एक है embedding पैरामीटर, जिसमें हम उन एम्बेडिंग को पास करते हैं जिन्हें हम वेक्टर डेटाबेस में संग्रहीत करना चाहते हैं।
तो अब मॉडल ने वेक्टर स्टोर में वेक्टर एम्बेडिंग के रूप में हमारे तीन दस्तावेज़ों को सफलतापूर्वक संग्रहीत कर लिया है। अब, हम उनसे प्रासंगिक दस्तावेज़ प्राप्त करने पर विचार करेंगे। हम एक प्रश्न पारित करेंगे और उससे संबंधित दस्तावेज़ लाएंगे। इसके लिए संगत कोड होगा
results = collection.query( query_texts=["Car"], n_results=2
) print(results)
किसी वेक्टर स्टोर से पूछताछ करें
- एक वेक्टर स्टोर को क्वेरी करने के लिए, हमारे पास एक है क्वेरी () संग्रह द्वारा प्रदान किया गया फ़ंक्शन जो हमें प्रासंगिक दस्तावेज़ों के लिए वेक्टर डेटाबेस से क्वेरी करने देता है। इस फ़ंक्शन में, हम दो पैरामीटर प्रदान करते हैं
- query_texts - इस पैरामीटर में, हम उन प्रश्नों की एक सूची देते हैं जिनके लिए हमें संबंधित दस्तावेज़ निकालने की आवश्यकता होती है।
- n_परिणाम - यह पैरामीटर निर्दिष्ट करता है कि डेटाबेस को कितने शीर्ष परिणाम लौटाने चाहिए। हमारे मामले में हम चाहते हैं कि हमारा संग्रह क्वेरी से संबंधित 2 शीर्ष प्रासंगिक दस्तावेज़ लौटाए
- जब हम परिणाम चलाते हैं और प्रिंट करते हैं, तो हमें निम्नलिखित आउटपुट मिलता है

हम देखते हैं कि वेक्टर स्टोर इससे जुड़े दो दस्तावेज़ लौटाता है id1 और id3। id1 कारों और के बारे में दस्तावेज़ है id3 चार पहिया वाहनों की दस्तावेज़ राशि है, जो फिर से एक कार से संबंधित है। तो जब हमने एक दिया सवाल, क्रोम डीबी क्वेरी को हमारे द्वारा शुरुआत में प्रदान किए गए एम्बेडिंग मॉडल के साथ वेक्टर एम्बेडिंग में परिवर्तित करता है। फिर यह वेक्टर एम्बेडिंग सभी उपलब्ध दस्तावेज़ों पर एक अर्थ संबंधी खोज (समान निकटतम पड़ोसियों) करता है। यहाँ प्रश्न "कार"आईडी1 और आईडी3 दस्तावेजों के लिए सबसे अधिक प्रासंगिक है, इसलिए हमें क्वेरी के लिए निम्नलिखित परिणाम मिलते हैं।
यह तब बहुत मददगार होता है जब हम एक चैट एप्लिकेशन बनाने का प्रयास कर रहे होते हैं जिसमें कई दस्तावेज़ शामिल होते हैं। एक वेक्टर स्टोर के माध्यम से, हम सिमेंटिक खोज करके और केवल इन दस्तावेजों को अंतिम जेनरेटिव एआई मॉडल में फीड करके संबंधित दस्तावेजों को प्रदान की गई क्वेरी में ला सकते हैं, जो फिर इन प्रासंगिक दस्तावेजों को लेगा और प्रदान की गई क्वेरी का जवाब उत्पन्न करेगा।
डेटा अपडेट करना और हटाना
हम हमेशा वेक्टर स्टोर में सारी जानकारी एक साथ नहीं जोड़ते हैं। ज्यादातर मामलों में, शुरुआत में हमारे पास केवल सीमित डेटा/दस्तावेज़ होते हैं, जिन्हें हम वेक्टर स्टोर में वैसे ही जोड़ते हैं। बाद में, जब हमें अधिक डेटा मिलता है, तो वेक्टर स्टोर में मौजूद मौजूदा डेटा/वेक्टर एम्बेडिंग को अपडेट करना आवश्यक हो जाता है। Chroma DB में डेटा अपडेट करने के लिए, हम निम्नलिखित कार्य करते हैं
collection.update( ids=["id2"], documents=["This is a document containing information about Cats"], metadatas=[{"source": "Cat Book"}],
)
पहले, दस्तावेज़ में जानकारी संबद्ध थी id2 कुत्तों के बारे में था. अब हम इसे कैट्स में बदल रहे हैं। इस जानकारी को वेक्टर स्टोर के भीतर अद्यतन करने के लिए, हम दस्तावेज़ की आईडी, अद्यतन दस्तावेज़ और दस्तावेज़ के अद्यतन मेटाडेटा को पास करते हैं। अपडेट करें () संग्रह का कार्य. यह अब अपडेट हो जाएगा id2 बिल्लियों के लिए जो पहले कुत्तों के बारे में था।
डेटाबेस में क्वेरी
results = collection.query( query_texts=["Felines"], n_results=1
) print(results)

हम फ़ील्ड्स को वेक्टर स्टोर में क्वेरी के रूप में पास करते हैं। बिल्लियाँ फेलिन्स नामक स्तनधारियों के परिवार से संबंधित हैं। इसलिए संग्रह को कैट दस्तावेज़ को प्रासंगिक दस्तावेज़ के रूप में हमें वापस करना होगा। आउटपुट में हमें बिल्कुल वैसा ही देखने को मिलता है। वेक्टर स्टोर क्वेरी और दस्तावेजों की सामग्री के बीच एक अर्थपूर्ण खोज करने में सक्षम था और प्रदान की गई क्वेरी के लिए सही दस्तावेज़ वापस करने में सक्षम था।
अपसेट फ़ंक्शन
अद्यतन फ़ंक्शन के समान एक फ़ंक्शन है जिसे कहा जाता है अपसर्ट() समारोह। दोनों में बस यही अंतर है अपडेट करें () और अपसर्ट() फ़ंक्शन है, यदि दस्तावेज़ आईडी में निर्दिष्ट है अपडेट करें () फ़ंक्शन मौजूद नहीं है, अपडेट करें () फ़ंक्शन एक त्रुटि उत्पन्न करेगा. लेकिन के मामले में अपसर्ट() फ़ंक्शन, यदि दस्तावेज़ आईडी संग्रह में मौजूद नहीं है, तो इसे संग्रह के समान जोड़ा जाएगा (जोड़ें) समारोह.
कभी-कभी, स्थान को कम करने या अनावश्यक/अवांछित जानकारी को हटाने के लिए, हम वेक्टर स्टोर में संग्रह से कुछ दस्तावेज़ हटाना चाहेंगे।
collection.delete(ids = ['id1']) results = collection.query( query_texts=["Car"], n_results=2
) print(results)

हटाएँ फ़ंक्शन
किसी संग्रह से किसी आइटम को हटाने के लिए, हमारे पास है हटाना () समारोह। उपरोक्त में, हम इससे जुड़े पहले दस्तावेज़ को हटा रहे हैं id1 जो कारों के बारे में था. अब जांचने के लिए, हम संग्रह को "" के साथ क्वेरी करते हैंकार"क्वेरी के रूप में और फिर परिणाम देखें। हम देखते हैं कि केवल 2 दस्तावेज़ हैं id2 और id3 प्रकट हों, जहां id2 चार पहिया वाहनों के बारे में दस्तावेज़ है जो कारों के सबसे करीब हैं और id3 बिल्लियों के बारे में दस्तावेज़ है जो कारों के सबसे करीब है, लेकिन जैसा कि हमने निर्दिष्ट किया है n_परिणाम = 2 हमें मिलता है id3 भी। यदि हम इसमें कोई चर निर्दिष्ट नहीं करते हैं हटाना () फ़ंक्शन, तो उस संग्रह से सभी आइटम हटा दिए जाएंगे
संग्रहण कार्य
हमने देखा है कि एक नया संग्रह कैसे बनाया जाता है और फिर उसमें दस्तावेज़ और एम्बेडिंग कैसे जोड़े जाते हैं। हमने यह भी देखा है कि संग्रह से यानी वेक्टर स्टोर में संग्रहीत दस्तावेज़ों से किसी क्वेरी के लिए प्रासंगिक जानकारी कैसे निकाली जाती है। क्रोमा डीबी से संग्रह ऑब्जेक्ट कई अन्य उपयोगी कार्यों से भी जुड़ा हुआ है।
आइए क्रोमा डीबी द्वारा प्रदान की गई कुछ अन्य कार्यक्षमताओं पर नजर डालें
new_collections = client.create_collection("new_collection") new_collections.add( documents=["This is Python Documentation", "This is a Javascript Documentation", "This document contains Flast API Cheatsheet"], metadatas=[{"source": "Python For Everyone"}, {"source": "JS Docs"}, {'source':'Everything Flask'}], ids=["id1", "id2", "id3"]
) print(new_collections.count())
print(new_collections.get())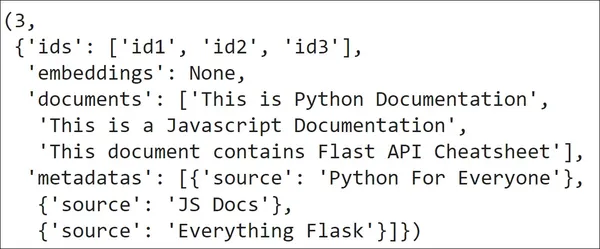
गिनती समारोह
RSI गिनती () संग्रह से फ़ंक्शन संग्रह में मौजूद वस्तुओं की संख्या लौटाता है। हमारे मामले में, हमारे संग्रह में 3 दस्तावेज़ संग्रहीत हैं, इसलिए आउटपुट 3 होगा प्राप्त() फ़ंक्शन, यह हमारे संग्रह में मौजूद सभी वस्तुओं को वापस कर देगा मेटाडेटा, आईडी, तथा घात लगाना यदि कोई। आउटपुट में, हम देखते हैं कि हमारे संग्रह में मौजूद सभी वस्तुओं को प्राप्त करना है प्राप्त() आज्ञा। आइए अब संग्रह नाम को संशोधित करने पर नजर डालें
collection.modify(name="new_collection_name")संशोधित फ़ंक्शन
उपयोग संशोधित() संग्रह से फ़ंक्शन संग्रह का नाम बदलने के लिए जो संग्रह निर्माण की शुरुआत में दिया गया था। चलाते समय, संग्रह नाम को पुराने नाम से बदलें जिसे प्रारंभ में परिभाषित किया गया था, इसमें दिए गए नए नाम में बदलें संशोधित() नाम वेरिएबल के अंतर्गत कार्य करें। अब मान लीजिए, हमारे वेक्टर स्टोर में कई संग्रह हैं। किसी विशिष्ट संग्रह पर कैसे काम करें, अर्थात वेक्टर स्टोर से एक विशिष्ट संग्रह कैसे प्राप्त करें और एक विशिष्ट संग्रह को कैसे हटाएं? आइए इसे देखें
my_collection = client.get_collection(name="my_information_2") client.delete_collection(name="my_information_2")संग्रह प्राप्त करें फ़ंक्शन
RSI get_collection() फ़ंक्शन मौजूदा संग्रह लाएगा बशर्ते कि नाम, वेक्टर स्टोर से। यदि प्रदान किया गया संग्रह मौजूद नहीं है, तो फ़ंक्शन उसी के लिए एक त्रुटि उत्पन्न करेगा। यहां ही get_collection() पाने का प्रयास करेंगे मेरी_जानकारी_2 संग्रह करें और इसे वेरिएबल को असाइन करें मेरा संग्रह. किसी मौजूदा संग्रह को हटाने के लिए, हमारे पास है हटाएँ_संग्रह() फ़ंक्शन, जो संग्रह नाम को पैरामीटर के रूप में लेता है (मेरी जानकारी इस मामले में) और यदि यह मौजूद है तो इसे हटा देता है।
निष्कर्ष
इस गाइड में, हमने देखा है कि ओपन सोर्स वेक्टर डेटाबेस में से एक, क्रोमा के साथ कैसे शुरुआत करें। हमने शुरुआत में यह सीखना शुरू किया कि वेक्टर एम्बेडिंग क्या हैं, वे जेनरेटिव एआई मॉडल के लिए क्यों आवश्यक हैं, और वेक्टर स्टोर इन जेनरेटिव लार्ज लैंग्वेज मॉडल्स की कैसे मदद करते हैं। फिर हमने क्रोमा में गहराई से प्रवेश किया, और हमने देखा कि क्रोमा में संग्रह कैसे बनाया जाता है। फिर हमने देखा कि क्रोमा में दस्तावेजों जैसे डेटा को कैसे जोड़ा जाए और क्रोमा डीबी उनमें से वेक्टर एम्बेडिंग कैसे बनाता है। अंत में, हमने देखा कि वेक्टर स्टोर में मौजूद किसी विशेष संग्रह से दी गई क्वेरी से संबंधित प्रासंगिक जानकारी कैसे प्राप्त की जाए।
इस गाइड की कुछ मुख्य बातें इस प्रकार हैं:
- वेक्टर एंबेडिंग पाठ, चित्र, ऑडियो आदि जैसे गैर-संख्यात्मक डेटा का संख्यात्मक प्रतिनिधित्व (संख्यात्मक वेक्टर) हैं।
- वेक्टर स्टोर वे डेटाबेस हैं जिनका उपयोग वेक्टर एम्बेडिंग को संग्रह के रूप में संग्रहीत करने के लिए किया जाता है
- वे एम्बेडिंग डेटा से जानकारी का कुशल भंडारण और पुनर्प्राप्ति प्रदान करते हैं
- क्रोमा डीबी इन-मेमोरी डेटाबेस और बैकएंड दोनों के रूप में काम कर सकता है
- क्रोमा डीबी में कनेक्शन शुरू करने पर डेटा को स्टोर करने और कनेक्शन शुरू करने पर डेटा को मेमोरी में लोड करने की कार्यक्षमता है, इस प्रकार डेटा बना रहता है
- वेक्टर स्टोर्स के साथ, दस्तावेजों से जानकारी निकालना, सिफारिशें तैयार करना और चैटबॉट एप्लिकेशन बनाना बहुत आसान हो जाएगा
आम सवाल-जवाब
A. वेक्टर डेटाबेस वह स्थान है जहां वेक्टर एम्बेडिंग संग्रहीत की जाती हैं। ये मौजूद हैं क्योंकि वे वेक्टर एम्बेडिंग की कुशल पुनर्प्राप्ति प्रदान करते हैं। इनका उपयोग सिमेंटिक खोज के माध्यम से अपने डेटाबेस से क्वेरी के लिए प्रासंगिक जानकारी निकालने के लिए किया जाता है।
A. वेक्टर एंबेडिंग एन-डायमेंशनल स्पेस में संख्यात्मक प्रारूप में टेक्स्ट/छवि/ऑडियो/वीडियो का प्रतिनिधित्व है, आमतौर पर एक संख्यात्मक वेक्टर के रूप में। ऐसा इसलिए किया जाता है क्योंकि कंप्यूटर पाठ या छवियों या किसी अन्य गैर-संख्यात्मक डेटा को मूल रूप से नहीं समझते हैं। इसलिए ये एम्बेडिंग उन्हें डेटा को अच्छी तरह से समझने की अनुमति देती है क्योंकि यह एक संख्यात्मक प्रारूप में प्रस्तुत किया जाता है।
A. एंबेडिंग मॉडल वे होते हैं जो टेक्स्ट/छवियों जैसे गैर-संख्यात्मक डेटा को एक संख्यात्मक प्रारूप में बदल देते हैं जो कि वेक्टर एंबेडिंग है। क्रोमा डीबी डिफ़ॉल्ट रूप से एम्बेडिंग बनाने के लिए ऑल-मिनीएलएम-एल6-वी2 मॉडल का उपयोग करता है। इन मॉडलों के अलावा, कई अन्य मॉडल भी हैं जैसे Googles का Word2Vec, OpenAI Embedding मॉडल, HuggingFace के अन्य सेंटेंस ट्रांसफॉर्मर और भी बहुत कुछ।
उ. ये वेक्टर स्टोर लगभग हर उस चीज़ में अपना एप्लिकेशन ढूंढते हैं जिसमें जेनरेटिव एआई मॉडल शामिल हैं। जैसे दस्तावेज़ों से जानकारी निकालना, दिए गए संकेतों से छवियां बनाना, एक अनुशंसा प्रणाली बनाना, प्रासंगिक डेटा को एक साथ क्लस्टर करना और भी बहुत कुछ।
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. ऑटोमोटिव/ईवीएस, कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- BlockOffsets. पर्यावरणीय ऑफसेट स्वामित्व का आधुनिकीकरण। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2023/07/guide-to-chroma-db-a-vector-store-for-your-generative-ai-llms/
- :हैस
- :है
- :नहीं
- :कहाँ
- 11
- 13
- 14
- 9
- a
- योग्य
- About
- ऊपर
- पहुँच
- तक पहुँचने
- जोड़ना
- जोड़ा
- जोड़ने
- फिर
- AI
- कलन विधि
- एल्गोरिदम
- सब
- अनुमति देना
- साथ में
- भी
- हमेशा
- राशि
- राशियाँ
- an
- विश्लेषिकी
- एनालिटिक्स विधा
- और
- असंगति का पता लगाये
- जवाब
- कोई
- अलग
- एपीआई
- दिखाई देते हैं
- आवेदन
- अनुप्रयोगों
- दृष्टिकोण
- हैं
- चारों ओर
- लेख
- AS
- पूछा
- जुड़े
- At
- ऑडियो
- उपलब्ध
- बैकएण्ड
- आधार
- आधारित
- BE
- क्योंकि
- बन
- हो जाता है
- के बीच
- ब्लॉगथॉन
- किताब
- के छात्रों
- निर्माण
- इमारत
- लेकिन
- by
- बुलाया
- कर सकते हैं
- नही सकता
- कार
- कारों
- मामला
- मामलों
- कैट
- बिल्ली की
- परिवर्तन
- बदलना
- chatbot
- chatbots
- चेक
- ग्राहक
- समापन
- समूह
- गुच्छन
- कोड
- संग्रह
- संग्रह
- कैसे
- अ रहे है
- समुदाय
- कंपनी
- तुलना
- कंप्यूटर
- कंप्यूटर्स
- संकल्पना
- विन्यास
- जुडिये
- संबंध
- विचार करना
- शामिल हैं
- सामग्री
- अंतर्वस्तु
- बदलना
- परिवर्तित
- परिवर्तित
- इसी
- बनाना
- बनाता है
- बनाना
- निर्माण
- तिथि
- डाटाबेस
- डेटाबेस
- व्यवहार
- चूक
- परिभाषित
- बनाया गया
- खोज
- विकसित
- डेवलपर्स
- अलग
- अंतर
- विभिन्न
- सीधे
- विवेक
- चर्चा की
- do
- दस्तावेज़
- दस्तावेज़ीकरण
- दस्तावेजों
- कर देता है
- नहीं करता है
- कुत्ता
- कुत्ते की
- किया
- डाउनलोड
- e
- आसान
- कुशल
- embedding
- में प्रवेश करती है
- त्रुटि
- आदि
- और भी
- हर कोई
- सब कुछ
- ठीक ठीक
- उदाहरण
- मौजूद
- मौजूदा
- मौजूद
- उम्मीद
- उद्धरण
- डेटा निकालें
- परिवार
- फास्ट
- भोजन
- पट्टिका
- फ़ाइलें
- अंतिम
- अंत में
- खोज
- प्रथम
- पहले तो
- फोकस
- निम्नलिखित
- के लिए
- प्रपत्र
- प्रारूप
- चार
- मुक्त
- से
- समारोह
- कार्यक्षमताओं
- कार्यक्षमता
- कार्यों
- भविष्य
- दे दिया
- उत्पन्न
- सृजन
- उत्पादक
- जनरेटिव एआई
- मिल
- देना
- दी
- देता है
- देते
- अच्छा
- गूगल
- गाइड
- है
- होने
- मदद
- सहायक
- इसलिये
- यहाँ उत्पन्न करें
- होस्टिंग
- कैसे
- How To
- HTTPS
- हगिंग फ़ेस
- i
- ID
- आईडी
- if
- छवियों
- आयात
- सुधार
- in
- शामिल
- शामिल
- सम्मिलित
- पता
- करें-
- शुरू में
- की शुरुआत
- निवेश
- निविष्टियां
- स्थापित
- बजाय
- में
- परिचय
- शामिल
- मुद्दा
- IT
- आइटम
- आईटी इस
- जावास्क्रिप्ट
- केवल
- कुंजी
- बच्चा
- राजा
- भाषा
- बड़ा
- बाद में
- सीखा
- सीख रहा हूँ
- कम से कम
- चलें
- लीवरेज
- पुस्तकालय
- पसंद
- सीमित
- सूची
- भार
- स्थानीय
- स्थानीय स्तर पर
- देखिए
- देखा
- बनाना
- निर्माण
- प्रबंध
- ढंग
- बहुत
- मीडिया
- याद
- मेटाडाटा
- तरीका
- हो सकता है
- आदर्श
- मॉडल
- संशोधित
- अधिक
- अधिकांश
- बहुत
- विभिन्न
- चाहिए
- नाम
- निकट
- आवश्यक
- आवश्यकता
- की जरूरत है
- पड़ोसियों
- नया
- अभी
- संख्या
- संख्या
- वस्तु
- प्राप्त
- of
- बंद
- ऑफर
- पुराना
- on
- एक बार
- ONE
- लोगों
- केवल
- खुला
- खुला स्रोत
- OpenAI
- संचालन
- or
- अन्य
- हमारी
- आउट
- उत्पादन
- कुल
- स्वामित्व
- पैकेज
- ताड़
- प्राचल
- भाग
- विशेष
- भागों
- पास
- पारित कर दिया
- पासिंग
- पीडीएफ
- उत्तम
- निष्पादन
- प्रदर्शन
- प्रदर्शन
- जगह
- की योजना बना
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- प्ले
- बिन्दु
- अंक
- लोकप्रिय
- ठीक
- वर्तमान
- प्रस्तुत
- पहले से
- प्रिंस
- छाप
- परियोजना
- साबित
- प्रदान करना
- बशर्ते
- प्रदान करता है
- प्रकाशित
- अजगर
- प्रश्नों
- प्रश्न
- त्वरित
- उठाना
- सिफारिश
- सिफारिशें
- को कम करने
- सम्बंधित
- प्रासंगिक
- हटाना
- जवाब दें
- प्रतिनिधित्व
- प्रतिनिधित्व
- का प्रतिनिधित्व
- कि
- प्रतिक्रिया
- परिणाम
- परिणाम
- वापसी
- रिटर्न
- रन
- दौड़ना
- वही
- सहेजें
- बचत
- विज्ञान
- Search
- दूसरा
- अनुभाग
- देखना
- देखा
- वाक्य
- सेवा
- सेवाएँ
- सेट
- सेटिंग्स
- कम
- चाहिए
- दिखाया
- समान
- समानता
- उसी प्रकार
- सरल
- कुशल
- So
- सॉफ्टवेयर
- कुछ
- स्रोत
- अंतरिक्ष
- विशिष्ट
- विशेष रूप से
- विनिर्दिष्ट
- प्रारंभ
- शुरू
- भंडारण
- की दुकान
- डेटा स्टोर करें
- संग्रहित
- भंडार
- सफलतापूर्वक
- ऐसा
- समर्थन
- प्रणाली
- सिस्टम
- तालिका
- लेना
- Takeaways
- लेता है
- बातचीत
- कार्य
- कि
- RSI
- जानकारी
- दुनिया
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- बात
- इसका
- हालांकि?
- विचार
- तीन
- यहाँ
- इस प्रकार
- पहर
- बहुत समय लगेगा
- सेवा मेरे
- एक साथ
- ऊपर का
- परंपरागत
- प्रशिक्षित
- ट्रान्सफ़ॉर्मर
- भयानक
- कोशिश
- मोड़
- दो
- आम तौर पर
- के अंतर्गत
- समझना
- अद्वितीय
- अवांछित
- अपडेट
- अद्यतन
- अद्यतन
- के ऊपर
- us
- उपयोग
- प्रयुक्त
- उपयोगकर्ता
- का उपयोग करता है
- आमतौर पर
- चर
- बहुत
- वीडियो
- करना चाहते हैं
- था
- मार्ग..
- तरीके
- we
- webp
- कुंआ
- क्या
- एचएमबी क्या है?
- कब
- जब कभी
- कौन कौन से
- पूरा का पूरा
- क्यों
- व्यापक रूप से
- मर्जी
- साथ में
- अंदर
- शब्द
- शब्द
- काम
- विश्व
- इसलिए आप
- आपका
- जेफिरनेट