परिचय
आज की स्थानीय खाद्य वितरण की तेज़ गति वाली दुनिया में, ग्राहकों की संतुष्टि सुनिश्चित करना कंपनियों के लिए महत्वपूर्ण है। ज़ोमैटो और स्विगी जैसे प्रमुख खिलाड़ी इस उद्योग पर हावी हैं। ग्राहक ताज़ा भोजन की अपेक्षा करते हैं; यदि उन्हें खराब वस्तुएँ मिलती हैं, तो वे धनवापसी या छूट वाउचर की सराहना करते हैं। हालाँकि, भोजन की ताजगी का मैन्युअल रूप से निर्धारण करना ग्राहकों और कंपनी के कर्मचारियों के लिए बोझिल है। एक समाधान डीप लर्निंग मॉडल का उपयोग करके इस प्रक्रिया को स्वचालित करना है। ये मॉडल भोजन की ताजगी का अनुमान लगा सकते हैं, जिससे अंतिम सत्यापन के लिए कर्मचारियों द्वारा केवल चिह्नित शिकायतों की समीक्षा की जा सकती है। यदि मॉडल भोजन के ताज़ा होने की पुष्टि करता है, तो वह स्वचालित रूप से शिकायत को ख़ारिज कर सकता है। इस लेख में हम डीप लर्निंग का उपयोग करके एक खाद्य गुणवत्ता डिटेक्टर का निर्माण करेंगे।
डीप लर्निंग, कृत्रिम बुद्धिमत्ता का एक उपसमूह, इस संदर्भ में महत्वपूर्ण उपयोगिता प्रदान करता है। विशेष रूप से, सीएनएन (कन्वेल्यूशनल न्यूरल नेटवर्क) को खाद्य छवियों का उपयोग करके उनकी ताजगी को समझने के लिए मॉडल को प्रशिक्षित करने के लिए नियोजित किया जा सकता है। हमारे मॉडल की सटीकता पूरी तरह से डेटासेट की गुणवत्ता पर निर्भर करती है। आदर्श रूप से, हाइपरलोकल फूड डिलीवरी ऐप्स में उपयोगकर्ताओं की चैटबॉट शिकायतों से वास्तविक भोजन छवियों को शामिल करने से सटीकता में काफी वृद्धि होगी। हालाँकि, ऐसे डेटा तक पहुंच की कमी के कारण, हम व्यापक रूप से उपयोग किए जाने वाले डेटासेट पर भरोसा करते हैं, जिसे "फ्रेश एंड रॉटेन क्लासिफिकेशन डेटासेट" के रूप में जाना जाता है, जिसे कागल पर एक्सेस किया जा सकता है। संपूर्ण डीप-लर्निंग कोड का पता लगाने के लिए, बस दिए गए "कॉपी और संपादित करें" बटन पर क्लिक करें यहाँ उत्पन्न करें.
सीखने के मकसद
- ग्राहक संतुष्टि और व्यवसाय वृद्धि में भोजन की गुणवत्ता के महत्व को जानें।
- पता लगाएं कि खाद्य गुणवत्ता डिटेक्टर के निर्माण में गहन शिक्षण कैसे सहायक होता है।
- इस मॉडल के चरण-दर-चरण कार्यान्वयन के माध्यम से व्यावहारिक अनुभव प्राप्त करें।
- इसके कार्यान्वयन में आने वाली चुनौतियों और समाधानों को समझें।
इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
विषय - सूची
खाद्य गुणवत्ता डिटेक्टर में गहन शिक्षण के उपयोग को समझना
गहरी सीख, का एक उपसमुच्चय Artificial Intelligence, मॉडल बनाने के लिए मुख्य रूप से स्थानिक डेटासेट का उपयोग करता है। डीप लर्निंग के भीतर तंत्रिका नेटवर्क का उपयोग मानव मस्तिष्क की कार्यक्षमता की नकल करते हुए, इन मॉडलों को प्रशिक्षित करने के लिए किया जाता है।
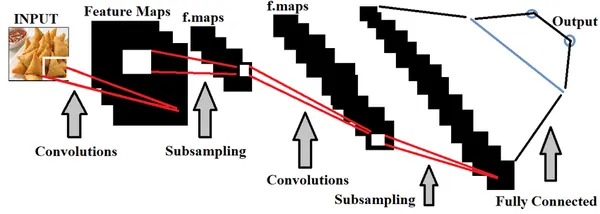
खाद्य गुणवत्ता का पता लगाने के संदर्भ में, अच्छी और बुरी गुणवत्ता वाले खाद्य पदार्थों के बीच सटीक अंतर करने के लिए खाद्य छवियों के व्यापक सेट के साथ गहन शिक्षण मॉडल का प्रशिक्षण आवश्यक है। हम क्या कर सकते हैं हाइपरपरमीटर ट्यूनिंग मॉडल को अधिक सटीक बनाने के लिए, फीड किए जा रहे डेटा के आधार पर।
हाइपरलोकल डिलीवरी में खाद्य गुणवत्ता का महत्व
इस सुविधा को हाइपरलोकल फूड डिलीवरी में एकीकृत करने से कई लाभ मिलते हैं। मॉडल विशिष्ट ग्राहकों के प्रति पूर्वाग्रह से बचाता है और सटीक भविष्यवाणी करता है, जिससे शिकायत समाधान का समय कम हो जाता है। इसके अतिरिक्त, हम डिलीवरी से पहले भोजन की गुणवत्ता का निरीक्षण करने के लिए ऑर्डर पैकिंग प्रक्रिया के दौरान इस सुविधा का उपयोग कर सकते हैं, जिससे यह सुनिश्चित हो सके कि ग्राहकों को लगातार ताजा भोजन मिले।

खाद्य गुणवत्ता डिटेक्टर का विकास करना
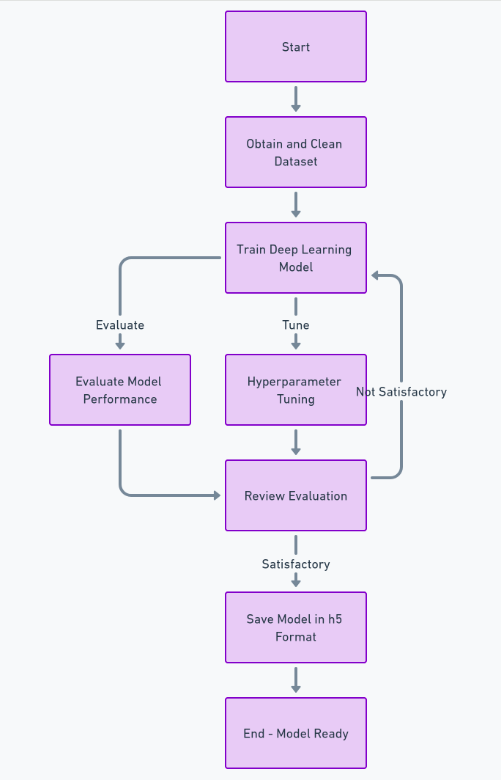
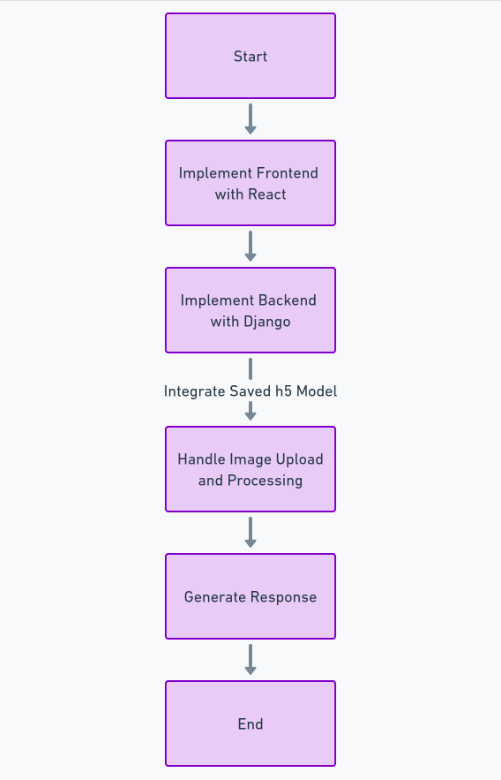
इस सुविधा को पूरी तरह से बनाने के लिए, हमें डेटासेट प्राप्त करने और साफ़ करने, गहन शिक्षण मॉडल को प्रशिक्षित करने, प्रदर्शन का मूल्यांकन करने और हाइपरपैरामीटर ट्यूनिंग करने और अंत में मॉडल को सहेजने जैसे कई चरणों का पालन करने की आवश्यकता है। h5 प्रारूप। इसके बाद, हम फ्रंटएंड का उपयोग करके कार्यान्वित कर सकते हैं प्रतिक्रिया, और पायथन के ढांचे का उपयोग करके बैकएंड जैंगो। हम छवि अपलोड को संभालने और इसे संसाधित करने के लिए Django का उपयोग करेंगे।
डेटासेट के बारे में
डेटा प्रीप्रोसेसिंग और मॉडल बिल्डिंग में गहराई से जाने से पहले, डेटासेट को समझना महत्वपूर्ण है। जैसा कि पहले चर्चा की गई है, हम कागल नामक डेटासेट का उपयोग करेंगे ताजा और सड़ा हुआ भोजन वर्गीकरण. इस डेटासेट को दो मुख्य श्रेणियों में विभाजित किया गया है रेलगाड़ी और टेस्ट कौन कौन से क्रमशः प्रशिक्षण और परीक्षण उद्देश्यों के लिए उपयोग किया जाता है। ट्रेन फ़ोल्डर के अंतर्गत, हमारे पास ताजे फल और ताजी सब्जियों के 9 उप-फ़ोल्डर और सड़े हुए फल और सड़ी हुई सब्जियों के 9 उप-फ़ोल्डर हैं।
डेटासेट की मुख्य विशेषताएं
- छवि विविधता: इस डेटासेट में कोण, पृष्ठभूमि और प्रकाश की स्थिति के संदर्भ में बहुत अधिक भिन्नता के साथ बहुत सारी खाद्य छवियां शामिल हैं। इससे मॉडल को पक्षपाती न होने और अधिक सटीक होने में मदद मिलती है।
- उच्च गुणवत्ता के चित्र: इस डेटासेट में विभिन्न पेशेवर कैमरों द्वारा कैप्चर की गई बहुत अच्छी गुणवत्ता वाली छवियां हैं।
डेटा लोडिंग और तैयारी
इस अनुभाग में, हम सबसे पहले 'का उपयोग करके छवियों को लोड करेंगे।Tensorflow.keras.preprocessing.image.लोड_आईएमजी' matplotlib लाइब्रेरी का उपयोग करके छवियों को कार्यान्वित करें और विज़ुअलाइज़ करें। मॉडल प्रशिक्षण के लिए इन छवियों को प्रीप्रोसेस करना वास्तव में महत्वपूर्ण है। इसमें छवियों को मॉडल के लिए उपयुक्त बनाने के लिए उन्हें साफ करना और व्यवस्थित करना शामिल है।
import os
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img
def visualize_sample_images(dataset_dir, categories):
n = len(categories)
fig, axs = plt.subplots(1, n, figsize=(20, 5))
for i, category in enumerate(categories):
folder = os.path.join(dataset_dir, category)
image_file = os.listdir(folder)[0]
img_path = os.path.join(folder, image_file)
img = load_img(img_path)
axs[i].imshow(img)
axs[i].set_title(category)
plt.tight_layout()
plt.show()
dataset_base_dir = '/kaggle/input/fresh-and-stale-classification/dataset'
train_dir = os.path.join(dataset_base_dir, 'Train')
categories = ['freshapples', 'rottenapples', 'freshbanana', 'rottenbanana']
visualize_sample_images(train_dir, categories)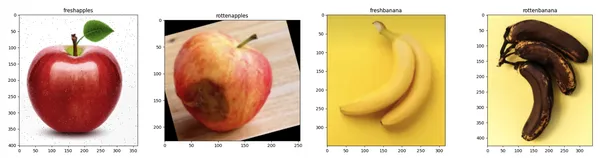
अब प्रशिक्षण और परीक्षण छवियों को वेरिएबल्स में लोड करते हैं। हम सभी छवियों का आकार 180 की समान ऊंचाई और चौड़ाई में बदल देंगे।
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
img_height = 180
img_width = 180
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='training')
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='validation')
प्रतिरूप निर्माण
आइए अब 'tensorflow.keras' से अनुक्रमिक एल्गोरिदम का उपयोग करके डीप-लर्निंग मॉडल बनाएं। हम 3 कनवल्शन परतें और एक एडम ऑप्टिमाइज़र जोड़ेंगे। व्यावहारिक भाग पर ध्यान देने से पहले आइए समझें कि 'शब्द' क्या हैंअनुक्रमिक मॉडल''एडम ऑप्टिमाइज़र', तथा 'कनवल्शन लेयर' अर्थ।
अनुक्रमिक मॉडल
अनुक्रमिक मॉडल में परतों का ढेर शामिल है, जो केरस में एक मौलिक संरचना की पेशकश करता है। यह उन परिदृश्यों के लिए आदर्श है जहां आपके तंत्रिका नेटवर्क में एक एकल इनपुट टेंसर और एक एकल आउटपुट टेंसर होता है। आप निष्पादन के अनुक्रमिक क्रम में परतें जोड़ते हैं, जिससे यह स्टैक्ड परतों के साथ सीधे मॉडल बनाने के लिए उपयुक्त हो जाता है। यह सरलता अनुक्रमिक मॉडल को अत्यधिक उपयोगी और लागू करने में आसान बनाती है।
एडम ऑप्टिमाइज़र
एडम का संक्षिप्त नाम 'एडेप्टिव मोमेंट एस्टीमेशन' है। यह स्टोकेस्टिक ग्रेडिएंट डिसेंट के लिए एक अनुकूलन एल्गोरिदम विकल्प के रूप में कार्य करता है, जो नेटवर्क भार को पुनरावृत्त रूप से अद्यतन करता है। एडम ऑप्टिमाइज़र फायदेमंद है क्योंकि यह प्रत्येक नेटवर्क भार के लिए सीखने की दर (एलआर) बनाए रखता है, जो डेटा में शोर से निपटने में फायदेमंद है।
संवादात्मक परत (Conv2D)
यह कन्वेन्शनल न्यूरल नेटवर्क्स (सीएनएन) का मुख्य घटक है। इसका उपयोग मुख्य रूप से छवियों जैसे स्थानिक डेटासेट को संसाधित करने के लिए किया जाता है। यह परत इनपुट पर कनवल्शन फ़ंक्शन या ऑपरेशन लागू करती है और फिर परिणाम को अगली परत पर भेजती है।
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size)
खाद्य गुणवत्ता डिटेक्टर का परीक्षण
आइए अब मॉडल को एक नई खाद्य छवि देकर उसका परीक्षण करें और देखें कि यह ताजे और सड़े हुए भोजन को कितनी सटीकता से वर्गीकृत कर सकता है।
from tensorflow.keras.preprocessing import image
import numpy as np
def classify_image(image_path, model):
img = image.load_img(image_path, target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
predictions = model.predict(img_array)
if predictions[0] > 0.5:
print("Rotten")
else:
print("Fresh")
image_path = '/kaggle/input/fresh-and-stale-classification/dataset/Train/
rottenoranges/Screen Shot 2018-06-12 at 11.18.28 PM.png'
classify_image(image_path, model)
जैसा कि हम देख सकते हैं कि मॉडल ने सही भविष्यवाणी की है। जैसा कि हमने दिया है रोटेनोरेंज इनपुट के रूप में छवि, मॉडल ने इसकी सही भविष्यवाणी की है सड़ा हुआ.
फ्रंटएंड (रिएक्ट) और बैकएंड (Django) कोड के लिए, आप GitHub पर मेरा पूरा कोड यहां देख सकते हैं: संपर्क
निष्कर्ष
निष्कर्ष में, हाइपरलोकल डिलीवरी ऐप्स में भोजन की गुणवत्ता की शिकायतों को स्वचालित करने के लिए, हम एक वेब ऐप के साथ एकीकृत एक गहन शिक्षण मॉडल बनाने का प्रस्ताव करते हैं। हालाँकि, सीमित प्रशिक्षण डेटा के कारण, मॉडल प्रत्येक खाद्य छवि का सटीक पता नहीं लगा सकता है। यह कार्यान्वयन एक बड़े समाधान की दिशा में एक मूलभूत कदम के रूप में कार्य करता है। इन ऐप्स के भीतर वास्तविक समय में उपयोगकर्ता द्वारा अपलोड की गई छवियों तक पहुंच से हमारे मॉडल की सटीकता में काफी वृद्धि होगी।
चाबी छीन लेना
- हाइपरलोकल खाद्य वितरण बाजार में ग्राहकों की संतुष्टि प्राप्त करने में खाद्य गुणवत्ता महत्वपूर्ण भूमिका निभाती है।
- आप एक सटीक खाद्य गुणवत्ता भविष्यवक्ता को प्रशिक्षित करने के लिए डीप लर्निंग तकनीक का उपयोग कर सकते हैं।
- वेब ऐप बनाने के लिए इस चरण-दर-चरण मार्गदर्शिका से आपको व्यावहारिक अनुभव प्राप्त हुआ।
- आप एक सटीक मॉडल बनाने के लिए डेटासेट की गुणवत्ता के महत्व को समझ गए हैं।
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2024/03/food-quality-detector/
- :हैस
- :है
- :नहीं
- :कहाँ
- 1
- 10
- 11
- 127
- 180
- 2%
- 20
- 28
- 300
- 32
- 48
- 5
- 501
- 55
- 58
- 9
- a
- संक्षिप्त नाम
- About
- पहुँच
- सुलभ
- शुद्धता
- सही
- सही रूप में
- प्राप्त करने
- ऐडम
- जोड़ना
- इसके अतिरिक्त
- लाभदायक
- बाद
- एड्स
- कलन विधि
- सब
- की अनुमति दे
- वैकल्पिक
- an
- विश्लेषिकी
- एनालिटिक्स विधा
- और
- कोण
- अनुप्रयोग
- लागू होता है
- सराहना
- क्षुधा
- हैं
- लेख
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- AS
- At
- को स्वचालित रूप से
- स्वतः
- से बचा जाता है
- AXS
- बैकएण्ड
- पृष्ठभूमि
- बुरा
- आधारित
- BE
- से पहले
- जा रहा है
- लाभदायक
- लाभ
- के बीच
- पूर्वाग्रह
- झुका हुआ
- बाइनरी
- ब्लॉगथॉन
- दिमाग
- निर्माण
- इमारत
- व्यापार
- बटन
- by
- कैमरों
- कर सकते हैं
- पर कब्जा कर लिया
- श्रेणियाँ
- वर्ग
- चुनौतियों
- chatbot
- वर्गीकरण
- वर्गीकृत
- सफाई
- क्लिक करें
- कोड
- कंपनियों
- कंपनी
- शिकायत
- शिकायतों
- पूरा
- पूरी तरह से
- अंग
- शामिल
- निष्कर्ष
- स्थितियां
- लगातार
- निर्माण
- निर्माण
- शामिल हैं
- प्रसंग
- ठीक प्रकार से
- महत्वपूर्ण
- महत्वपूर्ण
- बोझिल
- ग्राहक
- ग्राहक संतुष्टि
- ग्राहक
- तिथि
- डेटासेट
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- डीईएफ़
- प्रसव
- घना
- पता लगाना
- खोज
- निर्धारित करने
- विकासशील
- देख लेना
- छूट
- विवेक
- चर्चा की
- खारिज
- Django
- do
- कर
- हावी
- दो
- दौरान
- से प्रत्येक
- पूर्व
- आसान
- अन्य
- कार्यरत
- कर्मचारियों
- रोजगार
- बढ़ाना
- सुनिश्चित
- पूरी तरह से
- अवधियों को
- आवश्यक
- ईथर (ईटीएच)
- का मूल्यांकन
- प्रत्येक
- निष्पादन
- उम्मीद
- अनुभव
- का पता लगाने
- व्यापक
- तेजी से रफ़्तार
- Feature
- विशेषताएं
- फेड
- अंजीर
- अंतिम
- अंत में
- प्रथम
- फ्लैग किए गए
- का पालन करें
- भोजन
- भोजन पहुचना
- के लिए
- मूलभूत
- ढांचा
- ताजा
- से
- दृश्यपटल
- फल
- समारोह
- कार्यक्षमता
- मौलिक
- प्राप्त की
- GitHub
- दी
- देते
- जा
- अच्छा
- बहुत
- विकास
- गाइड
- संभालना
- हैंडलिंग
- हाथों पर
- है
- ऊंचाई
- मदद करता है
- यहाँ उत्पन्न करें
- हाई
- अत्यधिक
- टिका
- इतिहास
- कैसे
- तथापि
- http
- HTTPS
- मानव
- हाइपरपरमेटर ट्यूनिंग
- i
- आदर्श
- आदर्श
- if
- की छवि
- छवियों
- लागू करने के
- कार्यान्वयन
- आयात
- महत्व
- महत्वपूर्ण
- in
- शामिल
- उद्योग
- निवेश
- एकीकृत
- बुद्धि
- में
- शामिल
- शामिल
- IT
- आइटम
- आईटी इस
- keras
- कुंजी
- जानने वाला
- कमी
- बड़ा
- परत
- परतों
- सीख रहा हूँ
- पुस्तकालय
- प्रकाश
- पसंद
- सीमित
- भार
- लोड हो रहा है
- स्थानीय
- लॉट
- मुख्य
- मुख्यतः
- का कहना है
- प्रमुख
- बनाना
- बनाता है
- निर्माण
- मैन्युअल
- बाजार
- matplotlib
- अधिकतम-चौड़ाई
- मई..
- मतलब
- मीडिया
- आदर्श
- मॉडल
- पल
- अधिक
- my
- नामांकित
- आवश्यकता
- नेटवर्क
- नेटवर्क
- तंत्रिका
- तंत्रिका नेटवर्क
- तंत्रिका जाल
- नया
- अगला
- शोर
- numpy
- प्राप्त करने के
- of
- की पेशकश
- ऑफर
- on
- ONE
- केवल
- आपरेशन
- इष्टतमीकरण
- or
- आदेश
- आयोजन
- OS
- हमारी
- उत्पादन
- स्वामित्व
- भाग
- गुजरता
- पथ
- प्रदर्शन
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- खिलाड़ियों
- निभाता
- pm
- व्यावहारिक
- भविष्यवाणी करना
- भविष्यवाणी
- भविष्यवाणियों
- Predictor
- भविष्यवाणी
- तैयारी
- मुख्यत
- प्रक्रिया
- प्रसंस्करण
- पेशेवर
- प्रस्ताव
- बशर्ते
- प्रकाशित
- प्रयोजनों
- गुणवत्ता
- मूल्यांकन करें
- प्रतिक्रिया
- वास्तविक
- वास्तविक समय
- वास्तव में
- प्राप्त करना
- को कम करने
- वापसी
- पुनरारंभ
- भरोसा करना
- संकल्प
- परिणाम
- समीक्षा
- भूमिका
- वही
- संतोष
- बचत
- परिदृश्यों
- विज्ञान
- अनुभाग
- देखना
- कार्य करता है
- सेट
- कई
- शॉट
- दिखाया
- महत्वपूर्ण
- काफी
- सादगी
- केवल
- एक
- समाधान
- समाधान ढूंढे
- स्थानिक
- विशिष्ट
- विशेष रूप से
- विभाजित
- धुआँरा
- खड़ी
- कर्मचारी
- कदम
- कदम
- सरल
- संरचना
- ऐसा
- उपयुक्त
- Swiggy
- टेक्नोलॉजी
- tensorflow
- शर्तों
- परीक्षण
- परीक्षण
- कि
- RSI
- लेकिन हाल ही
- फिर
- जिसके चलते
- इन
- वे
- इसका
- यहाँ
- पहर
- सेवा मेरे
- आज का दि
- की ओर
- रेलगाड़ी
- प्रशिक्षण
- ट्यूनिंग
- दो
- के अंतर्गत
- समझना
- समझ
- समझ लिया
- अद्यतन
- उपयोग
- प्रयुक्त
- उपयोगी
- का उपयोग
- उपयोगिता
- उपयोग
- उपयोग किया
- सत्यापन
- चर
- विभिन्न
- सब्जियों
- बहुत
- कल्पना
- था
- we
- वेब
- webp
- भार
- क्या
- कौन कौन से
- मर्जी
- साथ में
- अंदर
- विश्व
- होगा
- इसलिए आप
- आपका
- जेफिरनेट
- Zomato