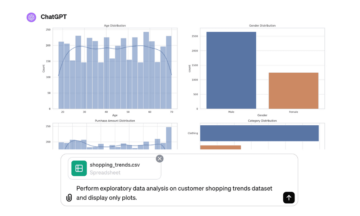
लेखक द्वारा छवि
किसी पुस्तक में किसी विशेष विषय की खोज करते समय, हम सबसे पहले अनुक्रमणिका पृष्ठ (जो उस पुस्तक की शुरुआत में मौजूद है) पर जाएंगे और पता लगाएंगे कि किस पृष्ठ संख्या में हमारी रुचि का विषय है। अब, कल्पना कीजिए कि किसी पुस्तक में बिना अनुक्रमणिका पृष्ठ के किसी विशेष विषय को ढूंढना कितना असुविधाजनक है। इसके लिए हमें किताब के हर पन्ने को खोजना होगा, जो बहुत समय लेने वाला और निराशाजनक है।
इसी तरह की समस्या SQL सर्वर में भी होती है जब वह डेटाबेस से डेटा पुनर्प्राप्त करता है। इसे दूर करने के लिए, SQL सर्वर इंडेक्सिंग का भी उपयोग करता है जो डेटा पुनर्प्राप्ति प्रक्रिया को गति देता है, और इस लेख में, हम उस भाग को कवर करेंगे। हम कवर करेंगे कि इंडेक्सिंग की आवश्यकता क्यों है और हम कैसे प्रभावी ढंग से इंडेक्स बना और हटा सकते हैं। इस ट्यूटोरियल की शर्त SQL कमांड का बुनियादी ज्ञान है।
इंडेक्सिंग एक स्कीमा ऑब्जेक्ट है जो पंक्तियों से डेटा पुनर्प्राप्त करने के लिए पॉइंटर का उपयोग करता है, जो डेटा का पता लगाने के लिए I/O (इनपुट/आउटपुट) समय को कम करता है। अनुक्रमण को एक या अधिक कॉलम पर लागू किया जा सकता है जिन्हें हम खोजना चाहते हैं। वे कॉलम को एक अलग डेटा संरचना में संग्रहीत करते हैं जिसे कहा जाता है बी-ट्री. बी-ट्री का एक मुख्य लाभ यह है कि यह डेटा को क्रमबद्ध क्रम में संग्रहीत करता है।
यदि आप सोच रहे हैं कि सॉर्ट किए जाने पर डेटा को तेज़ी से पुनर्प्राप्त क्यों किया जा सकता है, तो आपको इसके बारे में अवश्य पढ़ना चाहिए रैखिक खोज बनाम बाइनरी खोज.
SQL क्वेरीज़ के प्रदर्शन को बेहतर बनाने के लिए इंडेक्सिंग सबसे प्रसिद्ध तरीकों में से एक है। वे संबंधपरक तालिकाओं के लिए छोटे, तेज़ और उल्लेखनीय रूप से अनुकूलित हैं। जब हम अनुक्रमण के बिना एक पंक्ति खोजना चाहते हैं, तो SQL रैखिक रूप से एक पूर्ण-तालिका स्कैन करता है। दूसरे शब्दों में, SQL को मिलान स्थितियों को खोजने के लिए प्रत्येक पंक्ति को स्कैन करना पड़ता है, जिसमें बहुत समय लगता है। दूसरी ओर, अनुक्रमणिका डेटा को क्रमबद्ध रखती है, जैसा कि ऊपर चर्चा की गई है।
लेकिन हमें सावधान भी रहना चाहिए, अनुक्रमण एक अलग डेटा संरचना बनाता है जिसके लिए अतिरिक्त स्थान की आवश्यकता होती है, और डेटाबेस बड़ा होने पर यह समस्याग्रस्त हो सकता है। अच्छे अभ्यास के लिए, अनुक्रमण केवल अक्सर उपयोग किए जाने वाले कॉलम पर प्रभावी होता है और शायद ही कभी उपयोग किए जाने वाले कॉलम पर इससे बचा जा सकता है। नीचे कुछ परिदृश्य दिए गए हैं जिनमें अनुक्रमण सहायक हो सकता है,
- पंक्तियों की संख्या (>10000) होनी चाहिए।
- आवश्यक कॉलम में बड़ी संख्या में मान हैं।
- आवश्यक कॉलम में बड़ी संख्या में NULL मान नहीं होने चाहिए।
- यदि हम विशेष कॉलम के आधार पर डेटा को बार-बार क्रमबद्ध या समूहित करते हैं तो यह सहायक होता है। अनुक्रमण पूर्ण स्कैन करने के बजाय क्रमबद्ध डेटा को शीघ्रता से पुनः प्राप्त करता है।
और अनुक्रमण से बचा जा सकता है जब,
- टेबल छोटी है.
- या जब कॉलम के मानों का उपयोग शायद ही कभी किया जाता है।
- या जब कॉलम के मान बार-बार बदल रहे हों।
ऐसा भी मौका हो सकता है जब ऑप्टिमाइज़र यह पता लगाता है कि पूर्ण-तालिका स्कैन में अनुक्रमित तालिका की तुलना में कम समय लगता है, तो अनुक्रमण का उपयोग नहीं किया जा सकता है, भले ही वह मौजूद हो। ऐसा तब हो सकता है जब तालिका छोटी हो, या कॉलम अक्सर अद्यतन किया जाता हो।
शुरू करने से पहले, आपको ट्यूटोरियल का आसानी से पालन करने के लिए अपने पीसी पर MySQL वर्कबेंच सेट करना होगा। आप उल्लेख कर सकते हैं इसका अपना कार्यक्षेत्र स्थापित करने के लिए यूट्यूब वीडियो।
आपका कार्यक्षेत्र स्थापित करने के बाद, हम कुछ यादृच्छिक डेटा बनाएंगे जिससे हम अपने प्रश्नों को निष्पादित कर सकते हैं।
तालिका बनाना:
-- Create a table to hold the random data CREATE TABLE employee_info (id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(100), age INT, email VARCHAR(100));
डेटा सम्मिलित करना:
-- Insert random data into the table INSERT INTO employee_info (name, age, email)
SELECT CONCAT('User', LPAD(ROW_NUMBER() OVER (), 5, '0')), FLOOR(RAND() * 50) + 20, CONCAT('user', LPAD(ROW_NUMBER() OVER (), 5, '0'), '@xyz.com')
FROM information_schema.tables
LIMIT 100;
यह नाम की एक तालिका बनाएगा employee_info नाम, उम्र और ईमेल जैसी विशेषताएं होना।
डेटा दिखाएँ:
SELECT *
FROM employee_info;
आउटपुट:
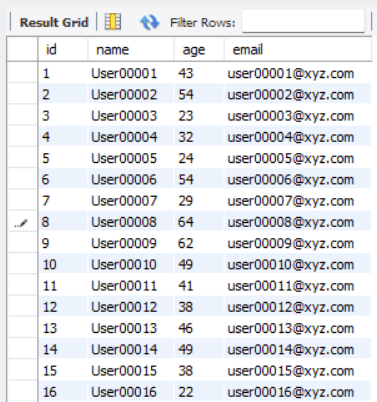
चित्र 1 नमूना डेटाबेस | लेखक द्वारा छवि
एक इंडेक्स बनाने के लिए, हम CREATE कमांड का उपयोग इस प्रकार कर सकते हैं,
सिंटेक्स:
CREATE INDEX index_name ON TABLE_NAME (COLUMN_NAME);
उपरोक्त प्रश्न में, index_name सूचकांक का नाम है, table_name तालिका का नाम है और column_name उस कॉलम का नाम है जिस पर हम अनुक्रमण लागू करना चाहते हैं।
भूतपूर्व
CREATE INDEX age_index ON employee_info (age);
हम एक ही तालिका में एकाधिक स्तंभों के लिए अनुक्रमणिका भी बना सकते हैं,
CREATE INDEX index_name ON TABLE_NAME (col1, col2, col3, ....);
अद्वितीय सूचकांक: हम किसी विशेष कॉलम के लिए एक अद्वितीय इंडेक्स भी बना सकते हैं जो उस कॉलम में डुप्लिकेट मानों को संग्रहीत करने की अनुमति नहीं देता है। इससे डेटा की अखंडता बनी रहती है और प्रदर्शन में भी सुधार होता है।
CREATE UNIQUE INDEX index_name ON TABLE_NAME (COLUMN_NAME);
नोट: PRIMARY_KEY और UNIQUE कॉलम के लिए इंडेक्स स्वचालित रूप से बनाए जा सकते हैं। हमें उन्हें मैन्युअल रूप से बनाने की ज़रूरत नहीं है.
एक सूचकांक हटाना:
हम टेबल से किसी विशेष इंडेक्स को हटाने के लिए DROP कमांड का उपयोग कर सकते हैं।
DROP INDEX index_name ON TABLE_NAME;
इंडेक्स को हटाने के लिए हमें इंडेक्स और टेबल नाम निर्दिष्ट करने की आवश्यकता है।
अनुक्रमणिका दिखाएँ:
आप अपनी तालिका में मौजूद सभी अनुक्रमणिकाएँ भी देख सकते हैं।
सिंटेक्स:
SHOW INDEX
FROM TABLE_NAME;
भूतपूर्व
SHOW INDEX
FROM employee_info;
आउटपुट:

नीचे दिया गया आदेश मौजूदा तालिका में एक नया सूचकांक बनाता है।
सिंटेक्स:
ALTER TABLE TABLE_NAME ADD INDEX index_name (col1, col2, col3, ...);
नोट: ALTER ANSI SQL का मानक कमांड नहीं है। इसलिए यह अन्य डेटाबेस के बीच भिन्न हो सकता है।
पूर्व के लिए-
ALTER TABLE employee_info ADD INDEX name_index (name); SHOW INDEX
FROM employee_info;
आउटपुट:

उपरोक्त उदाहरण में, हमने मौजूदा तालिका में एक नया सूचकांक बनाया है। लेकिन हम किसी मौजूदा सूचकांक को संशोधित नहीं कर सकते। इसके लिए, हमें पहले पुराने इंडेक्स को हटाना होगा और फिर एक नया संशोधित इंडेक्स बनाना होगा।
पूर्व के लिए-
DROP INDEX name_index ON employee_info; CREATE INDEX name_index ON employee_info (name, email); SHOW INDEX
FROM employee_info ;
आउटपुट:

इस लेख में, हमने SQL इंडेक्सिंग की बुनियादी समझ को कवर किया है। यह भी सलाह दी जाती है कि अनुक्रमण को संकीर्ण रखें, अर्थात, कुछ स्तंभों तक सीमित रखें, क्योंकि अधिक अनुक्रमण प्रदर्शन पर नकारात्मक प्रभाव डाल सकता है। अनुक्रमण हमें SELECT क्वेरीज़ और WHERE क्लॉज़ को गति देता है लेकिन इंसर्ट और अपडेट स्टेटमेंट को धीमा कर देता है। इसलिए, केवल अक्सर उपयोग किए जाने वाले कॉलम पर इंडेक्सिंग लागू करना एक अच्छा अभ्यास है।
तब तक पढ़ते रहिए और सीखते रहिए।
आर्यन गर्ग बीटेक है। इलेक्ट्रिकल इंजीनियरिंग का छात्र, वर्तमान में अपने स्नातक के अंतिम वर्ष में है। उनकी रुचि वेब डेवलपमेंट और मशीन लर्निंग के क्षेत्र में है। उन्होंने इस रुचि का पीछा किया है और इन दिशाओं में और अधिक काम करने के लिए उत्सुक हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. ऑटोमोटिव/ईवीएस, कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- BlockOffsets. पर्यावरणीय ऑफसेट स्वामित्व का आधुनिकीकरण। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/07/database-optimization-exploring-indexes-sql.html?utm_source=rss&utm_medium=rss&utm_campaign=database-optimization-exploring-indexes-in-sql
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 10
- 100
- 11
- 20
- 50
- 7
- 9
- a
- About
- ऊपर
- जोड़ना
- फायदे
- उम्र
- सब
- अनुमति देना
- भी
- am
- के बीच में
- an
- और
- लागू
- लागू करें
- लागू
- हैं
- लेख
- AS
- At
- विशेषताओं
- स्वतः
- बचा
- आधारित
- बुनियादी
- BE
- क्योंकि
- बन
- नीचे
- किताब
- लेकिन
- by
- बुलाया
- कर सकते हैं
- नही सकता
- सावधान
- संयोग
- बदलना
- स्तंभ
- स्तंभ
- COM
- स्थितियां
- शामिल हैं
- आवरण
- कवर
- बनाना
- बनाया
- बनाता है
- बनाना
- वर्तमान में
- तिथि
- डाटाबेस
- डेटाबेस
- विकास
- चर्चा की
- नहीं करता है
- डॉन
- नीचे
- बूंद
- e
- उत्सुक
- आसानी
- प्रभावी
- प्रभावी रूप से
- इलेक्ट्रिकल इंजीनियरिंग
- ईमेल
- अभियांत्रिकी
- ईथर (ईटीएच)
- और भी
- प्रत्येक
- उदाहरण
- निष्पादित
- मौजूदा
- मौजूद
- तलाश
- अतिरिक्त
- प्रसिद्ध
- फास्ट
- और तेज
- कुछ
- खेत
- अंतिम
- खोज
- प्रथम
- का पालन करें
- के लिए
- अक्सर
- से
- निराशा होती
- पूर्ण
- आगे
- अच्छा
- समूह
- हाथ
- होना
- है
- होने
- he
- सहायक
- उसके
- पकड़
- कैसे
- HTTPS
- i
- ID
- if
- की छवि
- कल्पना करना
- प्रभाव
- में सुधार
- सुधार
- in
- अन्य में
- अनुक्रमणिका
- अनुक्रमित
- अनुक्रमणिका
- ईमानदारी
- ब्याज
- में
- मुद्दा
- IT
- केडनगेट्स
- रखना
- कुंजी
- ज्ञान
- बड़ा
- सीख रहा हूँ
- कम
- झूठ
- पसंद
- सीमा
- सीमित
- लिंक्डइन
- मशीन
- यंत्र अधिगम
- मुख्य
- का कहना है
- मैन्युअल
- मिलान
- मई..
- तरीकों
- हो सकता है
- संशोधित
- संशोधित
- अधिक
- अधिकांश
- विभिन्न
- चाहिए
- जरूर पढ़े
- MySQL
- नाम
- नामांकित
- नामों
- संकीर्ण
- आवश्यकता
- जरूरत
- नकारात्मक
- नया
- अभी
- संख्या
- वस्तु
- of
- पुराना
- on
- ONE
- केवल
- इष्टतमीकरण
- अनुकूलित
- or
- आदेश
- अन्य
- हमारी
- के ऊपर
- काबू
- पृष्ठ
- भाग
- विशेष
- PC
- प्रदर्शन
- प्रदर्शन
- प्रदर्शन
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- अभ्यास
- वर्तमान
- प्राथमिक
- प्रक्रिया
- प्रश्नों
- जल्दी से
- बिना सोचे समझे
- शायद ही कभी
- बल्कि
- पढ़ना
- पढ़ना
- कम कर देता है
- अपेक्षित
- की आवश्यकता होती है
- आरओडब्ल्यू
- वही
- स्कैन
- परिदृश्यों
- Search
- खोज
- देखना
- अलग
- सेट
- की स्थापना
- चाहिए
- दिखाना
- समान
- धीमा कर देती है
- छोटा
- So
- कुछ
- अंतरिक्ष
- गति
- एसक्यूएल
- मानक
- प्रारंभ
- शुरुआत में
- बयान
- की दुकान
- संग्रहित
- भंडार
- संरचना
- छात्र
- तालिका
- लेता है
- तकनीक
- से
- कि
- RSI
- उन
- फिर
- इसलिये
- इन
- वे
- इसका
- पहर
- बहुत समय लगेगा
- सेवा मेरे
- विषय
- ट्यूटोरियल
- समझ
- अद्वितीय
- अपडेट
- अद्यतन
- us
- उपयोग
- प्रयुक्त
- उपयोगकर्ता
- का उपयोग करता है
- मान
- बहुत
- वीडियो
- भेंट
- vs
- करना चाहते हैं
- we
- वेब
- वेब विकास
- कब
- कौन कौन से
- क्यों
- विकिपीडिया
- मर्जी
- बिना
- सोच
- शब्द
- काम
- वर्ष
- इसलिए आप
- आपका
- यूट्यूब
- जेफिरनेट