परिचय
बड़े भाषा मॉडल के आगमन के साथ (एलएलएम), उन्होंने कई अनुप्रयोगों में प्रवेश किया है, जैसे छोटे ट्रांसफार्मर मॉडल की जगह ले ली है बर्ट या कई में नियम आधारित मॉडल प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कार्य. एलएलएम बहुमुखी हैं, अपने व्यापक पूर्व-प्रशिक्षण के कारण, पाठ वर्गीकरण, सारांशीकरण, भावना विश्लेषण और विषय मॉडलिंग जैसे कार्यों को संभालने में सक्षम हैं। हालाँकि, अपनी व्यापक क्षमताओं के बावजूद, एलएलएम अक्सर अपने छोटे समकक्षों की तुलना में सटीकता में पिछड़ जाते हैं।
इस सीमा को संबोधित करने के लिए, एक प्रभावी रणनीति विशिष्ट कार्यों में उत्कृष्टता प्राप्त करने के लिए पूर्व-प्रशिक्षित एलएलएम को ठीक करना है। बड़े मॉडलों को फाइन-ट्यूनिंग करने से अक्सर इष्टतम परिणाम मिलते हैं। विशेष रूप से, अन्य बड़े मॉडलों के बीच, Google का जेमिनी अब उपयोगकर्ताओं को अपने स्वयं के प्रशिक्षण डेटा के साथ इन मॉडलों को बेहतर बनाने की क्षमता प्रदान करता है। इस गाइड में, हम विशिष्ट समस्याओं के लिए जेमिनी मॉडल को फाइन-ट्यून करने की प्रक्रिया के साथ-साथ हगिंगफेस के संसाधनों का उपयोग करके डेटासेट को कैसे क्यूरेट करें, इसके बारे में जानेंगे।
सीखने के मकसद
- Google के जेमिनी मॉडल के प्रदर्शन को समझें।
- जेमिनी मॉडल फ़ाइनट्यूनिंग के लिए डेटासेट तैयारी सीखें।
- जेमिनी मॉडल फ़ाइनट्यूनिंग के लिए पैरामीटर कॉन्फ़िगर करें।
- फ़ाइनट्यूनिंग प्रगति और मेट्रिक्स की निगरानी करें।
- नए डेटा पर जेमिनी मॉडल के प्रदर्शन का परीक्षण करें।
- पीआईआई मास्किंग के लिए जेमिनी मॉडल अनुप्रयोगों का अन्वेषण करें।

इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
विषय - सूची
Google ने जेमिनी को ट्यून करने की घोषणा की
जेमिनी दो संस्करणों में आता है: प्रो और अल्ट्रा। प्रो संस्करण में, जेमिनी 1.0 प्रो और नया जेमिनी 1.5 प्रो हैं। Google के ये मॉडल चैटजीपीटी और क्लाउड जैसे अन्य उन्नत मॉडलों के साथ प्रतिस्पर्धा करते हैं। एआई स्टूडियो यूआई और एक मुफ्त एपीआई के माध्यम से जेमिनी मॉडल तक सभी के लिए पहुंच आसान है।
हाल ही में, Google ने जेमिनी मॉडल के लिए एक नई सुविधा की घोषणा की: फ़ाइन-ट्यूनिंग। इसका मतलब यह है कि कोई भी व्यक्ति अपनी आवश्यकताओं के अनुरूप जेमिनी मॉडल को समायोजित कर सकता है। आप एआई स्टूडियो यूआई या उनके एपीआई का उपयोग करके जेमिनी को फाइन-ट्यून कर सकते हैं। फाइन-ट्यूनिंग तब होती है जब हम अपना डेटा जेमिनी को देते हैं ताकि वह हमारी इच्छानुसार व्यवहार कर सके। Google जेमिनी मॉडल के कुछ महत्वपूर्ण हिस्सों को तुरंत समायोजित करने के लिए पैरामीटर कुशल ट्यूनिंग (पीईटी) का उपयोग करता है, जिससे यह विभिन्न कार्यों के लिए उपयोगी हो जाता है।
डेटासेट तैयार करना
इससे पहले कि हम मॉडल को बेहतर बनाना शुरू करें, हम आवश्यक लाइब्रेरी स्थापित करना शुरू करेंगे। वैसे, हम इस गाइड के लिए कोलाब के साथ काम करेंगे।
आवश्यक पुस्तकालय स्थापित करना
आरंभ करने के लिए आवश्यक पायथन मॉड्यूल निम्नलिखित हैं:
!pip install -q google-generativeai datasets- गूगल-जनरेटिवएआई: यह Google टीम की एक लाइब्रेरी है जो हमें Google जेमिनी मॉडल तक पहुंचने की सुविधा देती है। जेमिनी मॉडल को बेहतर बनाने के लिए उसी लाइब्रेरी के साथ काम किया जा सकता है।
- डेटासेट: यह HuggingFace की एक लाइब्रेरी है जिसके साथ हम HuggingFace हब से विभिन्न प्रकार के डेटासेट डाउनलोड करने के लिए काम कर सकते हैं। हम इस डेटासेट लाइब्रेरी के साथ पीआईआई (व्यक्तिगत पहचान योग्य जानकारी) डेटासेट डाउनलोड करने और इसे फाइन-ट्यूनिंग के लिए जेमिनी मॉडल को देने के लिए काम करेंगे।
निम्नलिखित कोड को चलाने से हमारे पायथन पर्यावरण में Google जेनरेटिव एआई और डेटासेट लाइब्रेरी डाउनलोड और इंस्टॉल हो जाएगी।
OAuth की स्थापना
अगले चरण में, हमें इस ट्यूटोरियल के लिए एक OAuth सेट करना होगा। OAuth आवश्यक है ताकि जो डेटा हम Google को फाइन-ट्यूनिंग जेमिनी के लिए भेज रहे हैं वह सुरक्षित रहे। OAuth प्राप्त करने के लिए इसका अनुसरण करें संपर्क. फिर OAuth बनाने के बाद client_secret.json डाउनलोड करें। CLIENT_SECRET नाम के तहत Colab Secrets में client_secret.json की सामग्री सहेजें और नीचे दिया गया कोड चलाएँ:
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'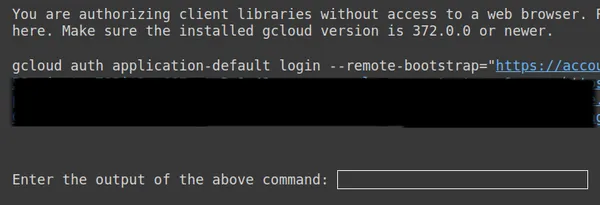
ऊपर, दूसरे लिंक को कॉपी करें और इसे अपने सीएमडी स्थानीय सिस्टम में पेस्ट करें और चलाएं।
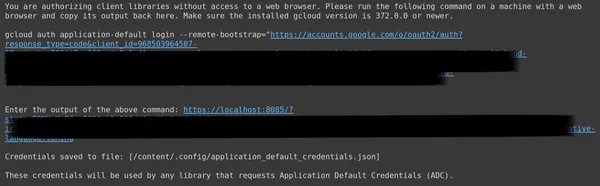
फिर आपको उस ईमेल से लॉग इन करने के लिए वेब ब्राउज़र पर पुनः निर्देशित किया जाएगा जिसके साथ आपने OAuth सेट किया है। लॉग इन करने के बाद सीएमडी में हमें एक यूआरएल मिलता है, अब उस यूआरएल को तीसरी लाइन में पेस्ट करें और एंटर दबाएं। अब हमने Google के साथ OAuth निष्पादित करना समाप्त कर लिया है।
डेटासेट डाउनलोड करना और तैयार करना
सबसे पहले, हम उस डेटासेट को डाउनलोड करके शुरुआत करेंगे जिसके साथ हम इसे जेमिनी मॉडल पर परिष्कृत करने के लिए काम करेंगे। इसके लिए हम डेटासेट लाइब्रेरी के साथ काम करते हैं। इसके लिए कोड होगा:
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- यहां हम डेटासेट लाइब्रेरी से लोड_डेटासेट फ़ंक्शन को आयात करके शुरू करते हैं।
- इस लोड_डेटासेट() फ़ंक्शन में, हम उस डेटासेट को पास करते हैं जिसे हम डाउनलोड करना चाहते हैं। यहां हमारे उदाहरण में यह "ai4privacy/pii-masking-200k" है, जिसमें नकाबपोश और नकाबपोश PII डेटा की 200k पंक्तियाँ हैं।
- फिर हम डेटासेट प्रिंट करते हैं।

हम देखते हैं कि डेटासेट में प्रशिक्षण डेटा की 209261 पंक्तियाँ हैं और कोई परीक्षण डेटा नहीं है। और प्रत्येक पंक्ति में अलग-अलग कॉलम होते हैं जैसे मास्क्ड_टेक्स्ट, अनमास्क्ड_टेक्स्ट, प्राइवेसी_मास्क, स्पैन_लेबल्स, बायो_लेबल्स और टोकनाइज्ड_टेक्स्ट। नमूना डेटा नीचे उल्लिखित है:
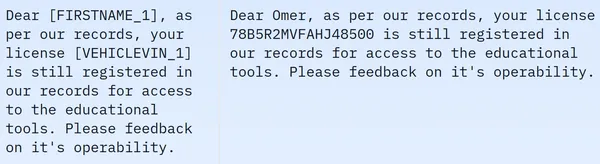
प्रदर्शित छवि में, हम नकाबपोश और नकाबपोश दोनों वाक्यों को देखते हैं। विशेष रूप से, नकाबपोश वाक्य में, व्यक्ति का नाम और वाहन नंबर जैसे कुछ तत्व विशिष्ट टैग द्वारा अस्पष्ट होते हैं। आगे की प्रक्रिया के लिए डेटा तैयार करने के लिए, अब हमें कुछ डेटा प्रीप्रोसेसिंग करने की आवश्यकता है। इस प्रीप्रोसेसिंग चरण के लिए कोड नीचे दिया गया है:
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- सबसे पहले, हम डेटासेट से डेटा का प्रशिक्षण भाग लेते हैं (हमने जो डेटासेट डाउनलोड किया है उसमें केवल प्रशिक्षण भाग होता है)। फिर हम इसे पांडास डेटाफ़्रेम में परिवर्तित करते हैं।
- यहां जेमिनी को ठीक करने के लिए, हमें केवल अनमास्कड_टेक्स्ट और मास्क्ड_टेक्स्ट कॉलम की आवश्यकता है, इसलिए हम केवल इन दोनों को लेते हैं।
- फिर हमें डेटा की पहली 2000 पंक्तियाँ मिलती हैं। हम जेमिनी को बेहतर बनाने के लिए पहली 2000 पंक्तियों के साथ काम करेंगे।
- फिर हम कॉलम नामों को अनमास्क्ड_टेक्स्ट और मास्क्ड_टेक्स्ट से इनपुट और आउटपुट कॉलम में संपादित करते हैं, क्योंकि, जब हम जेमिनी मॉडल को पीआईआई (व्यक्तिगत पहचान योग्य जानकारी) युक्त इनपुट टेक्स्ट डेटा देते हैं, तो हम उम्मीद करते हैं कि यह आउटपुट टेक्स्ट डेटा उत्पन्न करेगा जहां पीआईआई नकाबपोश है.
जेमिनी को फ़ाइन-ट्यूनिंग के लिए डेटा फ़ॉर्मेट करना
अगला कदम हमारे डेटा को प्रारूपित करना है। ऐसा करने के लिए, हम एक फ़ॉर्मेटर फ़ंक्शन बनाएंगे:
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- यहां हम एक फ़ंक्शन फ़ॉर्मेटर को परिभाषित करते हैं, जो हमारे डेटा की एक पंक्ति x लेता है।
- फिर यह एफ-स्ट्रिंग्स के साथ एक वेरिएबल टेक्स्ट को परिभाषित करता है, जहां हम संदर्भ प्रदान करते हैं, उसके बाद डेटाफ्रेम से इनपुट डेटा प्रदान करते हैं।
- अंत में, हम स्वरूपित पाठ वापस कर देते हैं।
- अंतिम पंक्ति फ़ॉर्मेटर फ़ंक्शन को डेटाफ़्रेम की प्रत्येक पंक्ति पर लागू करती है जिसे हमने लागू() फ़ंक्शन के माध्यम से बनाया है।
- axis=1 बताता है कि फ़ंक्शन डेटाफ़्रेम की प्रत्येक पंक्ति पर लागू किया जाएगा।
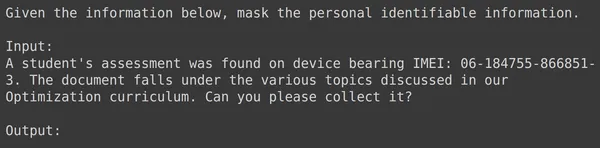
कोड चलाने के परिणामस्वरूप "ट्रेन" नामक एक नया कॉलम बनेगा जिसमें इनपुट फ़ील्ड सहित प्रत्येक पंक्ति के लिए स्वरूपित टेक्स्ट शामिल होगा। आइए डेटाफ़्रेम के तत्वों में से एक को देखने का प्रयास करें:
डेटा को ट्रेन और टेस्ट सेट में विभाजित करना
हम देख सकते हैं कि text_input में डेटा शामिल है जहां प्रत्येक पंक्ति में PII को मास्क करने के लिए डेटा की शुरुआत में संदर्भ होता है और उसके बाद इनपुट डेटा होता है और उसके बाद आउटपुट शब्द होता है, जहां मॉडल को आउटपुट उत्पन्न करने की आवश्यकता होती है। अब हमें डेटाफ़्रेम को ट्रेन और परीक्षण में विभाजित करने की आवश्यकता है:
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- हम डेटा को फ़िल्टर करके प्रारंभ करते हैं ताकि इसमें text_input और आउटपुट कॉलम शामिल हों। मिथुन राशि वालों को प्रशिक्षित करने के लिए Google फाइन-ट्यून लाइब्रेरी द्वारा अपेक्षित ये कॉलम हैं
- मिथुन को text_input मिलेगा और आउटपुट लिखना सीखेंगे
- हम डेटा को df_train में विभाजित करते हैं जिसमें हमारे मूल डेटा की 1900 पंक्तियाँ होती हैं
- और एक df_test जिसमें मूल डेटा की लगभग 100 पंक्तियाँ हैं
- हम जेमिनी को df_train पर प्रशिक्षित करते हैं और फिर इसके द्वारा उत्पन्न आउटपुट को देखने के लिए df_test से 3-4 उदाहरण लेकर इसका परीक्षण करते हैं।
इसलिए कोड चलाने से हमारा डेटा फ़िल्टर हो जाएगा और इसे ट्रेन और टेस्ट में विभाजित कर दिया जाएगा। अंत में, हमने डेटा प्री-प्रोसेसिंग भाग पूरा कर लिया है।
फाइन-ट्यूनिंग जेमिनी मॉडल
अपने जेमिनी मॉडल को बेहतर बनाने के लिए नीचे दिए गए चरणों का पालन करें:
ट्यूनिंग पैरामीटर सेट करना
इस अनुभाग में, हम जेमिनी मॉडल को ट्यून करने की प्रक्रिया से गुजरेंगे। इसके लिए हम निम्नलिखित कोड के साथ काम करेंगे:
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- Google.generativeai लाइब्रेरी आयात करें: यह लाइब्रेरी Google की जेनरेटिव AI सेवाओं के साथ इंटरैक्ट करने के लिए API प्रदान करती है।
- बेस मॉडल नाम प्रदान करें: यह पूर्व-प्रशिक्षित मॉडल का नाम है जिसके साथ हम अपने परिष्कृत मॉडल के शुरुआती बिंदु के लिए काम करना चाहते हैं। अभी, एकमात्र ट्यून करने योग्य मॉडल मॉडल/जेमिनी-1.0-प्रो-001 है, हम इसे वेरिएबल bm_name में संग्रहीत करते हैं।
- फाइनट्यून्ड मॉडल का नाम प्रदान करें: यह वह नाम है जो हम अपने फाइनट्यून्ड मॉडल को देना चाहते हैं। यहां हम इसे "पीआईआई-मॉडल" नाम देते हैं।
- एक ट्यून्ड मॉडल ऑपरेशन ऑब्जेक्ट बनाएं: यह ऑब्जेक्ट एक फाइनट्यून्ड मॉडल बनाने के ऑपरेशन का प्रतिनिधित्व करता है। इसमें निम्नलिखित तर्क लगते हैं:
- source_model: बेस मॉडल का नाम
- ट्रेनिंग_डेटा: हमारे द्वारा अभी बनाए गए परिष्कृत मॉडल के लिए प्रशिक्षण डेटा जो कि df_train है
- आईडी: परिष्कृत मॉडल की आईडी/नाम
- epoch_count: प्रशिक्षण युगों की संख्या। इस उदाहरण के लिए, हम 2 युगों के साथ होंगे
- बैच_आकार: प्रशिक्षण के लिए बैच का आकार। इस उदाहरण के लिए, हम 4 के मान के साथ चलेंगे
- learn_rate: प्रशिक्षण के लिए सीखने की दर। यहां हम इसे 0.001 के मान के साथ प्रदान कर रहे हैं
- हमने पैरामीटर प्रदान करना पूरा कर लिया है। इस कोड को चलाने से एक सुव्यवस्थित मॉडल ऑब्जेक्ट तैयार हो जाएगा। अब हमें जेमिनी एलएलएम के प्रशिक्षण की प्रक्रिया शुरू करने की जरूरत है। इसके लिए हम निम्नलिखित कोड के साथ काम करते हैं।
हमने पैरामीटर सेट करना पूरा कर लिया है। इस कोड को चलाने से एक ट्यून्ड मॉडल ऑब्जेक्ट बन जाएगा। अब हमें जेमिनी एलएलएम के प्रशिक्षण की प्रक्रिया शुरू करने की जरूरत है। इसके लिए, हम निम्नलिखित कोड के साथ काम करते हैं:
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)एक ट्यून्ड मॉडल बनाना
यहां, हम जेनई लाइब्रेरी से .get_tuned_model() फ़ंक्शन का उपयोग करते हैं, अपने परिभाषित मॉडल का नाम पास करते हुए, प्रशिक्षण प्रक्रिया शुरू करते हैं। फिर, हम मॉडल को प्रिंट करते हैं, जैसा कि नीचे दी गई छवि में दिखाया गया है:
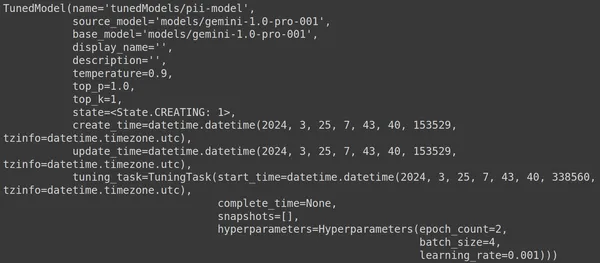
मॉडल TunedModel प्रकार का है। यहां हम उस मॉडल के लिए विभिन्न पैरामीटर देख सकते हैं जिसे हमने परिभाषित किया है। वे हैं:
- नाम: इस वेरिएबल में वह नाम शामिल है जो हमने अपने ट्यून किए गए मॉडल के लिए प्रदान किया है
- source_model: यह स्रोत मॉडल है जिसे हम ठीक कर रहे हैं, जो हमारे उदाहरण में मॉडल/जेमिनी-1.0-प्रो है
- बेस_मॉडल: यह फिर से बेस मॉडल है जिसे हम ठीक कर रहे हैं, जो हमारे उदाहरण में मॉडल/जेमिनी-1.0-प्रो है। बेस मॉडल पहले से ठीक किया गया मॉडल भी हो सकता है। यहां हम दोनों के लिए समान हैं
- डिस्प्ले_नाम: ट्यून किए गए मॉडल का डिस्प्ले नाम
- विवरण: इसमें हमारे मॉडल का कोई भी विवरण और मॉडल किस बारे में है, शामिल है
- तापमान: मान जितना अधिक होगा, बड़े भाषा मॉडल से उत्तर उतने ही अधिक रचनात्मक होंगे। यहां यह डिफ़ॉल्ट रूप से 0.9 पर सेट है
- टॉप_पी: टेक्स्ट बनाते समय टोकन चयन के लिए शीर्ष संभावना को परिभाषित करता है। जितना अधिक शीर्ष_पी उतना अधिक टोकन चयनित होते हैं, यानी डेटा के एक बड़े नमूने से टोकन चुने जाते हैं
- टॉप_k: यह प्रत्येक चरण पर k के सबसे संभावित अगले टोकन से नमूना लेने के लिए कहता है। यहां टॉप_k 1 है, जिसका अर्थ है कि सबसे संभावित अगला टोकन वह है जिसे चुना जाएगा, यानी सबसे अधिक संभावना वाला टोकन हमेशा चुना जाएगा
- राज्य: राज्य बना रहा है, इसका तात्पर्य है कि मॉडल को वर्तमान में ठीक किया जा रहा है
- create_time: वह समय जब मॉडल बनाया गया था
- अपडेट_टाइम: यह वह समय है जब मॉडल को आखिरी बार ट्यून किया गया था
- ट्यूनिंग_टास्क: इसमें वे पैरामीटर शामिल हैं जिन्हें हमने ट्यूनिंग के लिए परिभाषित किया है, जिसमें तापमान, युग और बैच आकार शामिल हैं
प्रशिक्षण प्रक्रिया आरंभ करना
हम निम्नलिखित कोड के माध्यम से ट्यून किए गए मॉडल की स्थिति और मेटाडेटा भी प्राप्त कर सकते हैं:
print(operation.metadata)
यहां यह कुल चरणों को प्रदर्शित करता है, जो कि 950 है, जिसका अनुमान लगाया जा सकता है। क्योंकि हमारे उदाहरण में हमारे पास प्रशिक्षण डेटा की 1900 पंक्तियाँ हैं। प्रत्येक चरण में, हम 4 का एक बैच लेते हैं, यानी 4 पंक्तियाँ, इसलिए एक पूर्ण युग के लिए हमारे पास 1900/4 यानी 475 चरण होते हैं। हमने प्रशिक्षण के लिए 2 युग निर्धारित किए हैं, जिसका अर्थ है कि 2*475 = 950 कदम।
प्रशिक्षण प्रगति की निगरानी करना
नीचे दिया गया कोड एक स्टेटस बार बनाता है जो बताता है कि प्रशिक्षण का कितना प्रतिशत समाप्त हो गया है और संपूर्ण प्रशिक्षण प्रक्रिया को पूरा करने में कितना समय लगेगा:
import time
for status in operation.wait_bar():
time.sleep(30)
उपरोक्त कोड एक प्रगति पट्टी बनाता है, जब पूरा हो जाता है तो इसका मतलब है कि हमारी ट्यूनिंग प्रक्रिया समाप्त हो गई है।
प्रशिक्षण प्रदर्शन को विज़ुअलाइज़ करना
ऑपरेशन ऑब्जेक्ट में प्रशिक्षण के स्नैपशॉट भी शामिल हैं। इसमें प्रति युग माध्य_लॉस जैसे मूल्यांकन मेट्रिक्स शामिल होंगे। हम इसे निम्नलिखित कोड से देख सकते हैं:
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- यहां हमें ऑपरेशन.रिजल्ट() से अंतिम ट्यून किया गया मॉडल मिलता है
- जब हम मॉडल को प्रशिक्षित करते हैं, तो मॉडल लगातार अंतराल पर स्नैपशॉट लेता है। इन स्नैपशॉट में माध्य_लॉस जैसा डेटा होता है। इसलिए हम model.tuning_task.snapshots को कॉल करके ट्यून किए गए मॉडल के स्नैपशॉट निकालते हैं
- हम स्नैपशॉट को pd.DataFrame में पास करके और उन्हें स्नैपशॉट वेरिएबल में संग्रहीत करके इन स्नैपशॉट से एक डेटाफ़्रेम बनाते हैं
- अंत में, हम निकाले गए स्नैपशॉट डेटा से एक लाइन प्लॉट बनाते हैं
कोड चलाने पर निम्नलिखित ग्राफ़ बनेगा:
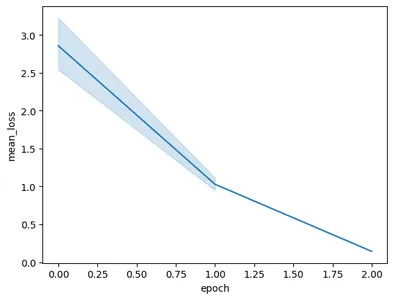
इस छवि में, हम देख सकते हैं कि हमने प्रशिक्षण के केवल 3 युगों में नुकसान को 0.5 से घटाकर 2 से भी कम कर दिया है। अंततः, हमने जेमिनी मॉडल का प्रशिक्षण पूरा कर लिया है
फाइन-ट्यून्ड जेमिनी मॉडल का परीक्षण
इस अनुभाग में, हम परीक्षण डेटा पर अपने मॉडल का परीक्षण करेंगे। अब ट्यून किए गए मॉडल के साथ काम करने के लिए, हम निम्नलिखित कोड के साथ काम करते हैं:
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')उपरोक्त कोड ट्यून किए गए मॉडल को लोड करेगा जिसे हमने व्यक्तिगत पहचान योग्य सूचना डेटा के साथ प्रशिक्षित किया है। अब हम इस मॉडल का परीक्षण उन परीक्षण डेटा से कुछ उदाहरणों के साथ करेंगे जिन्हें हमने अलग रखा है। इसके लिए आइए परीक्षण सेट से यादृच्छिक text_input और उसके संबंधित आउटपुट को प्रिंट करें:
print(df_test['text_input'][1900])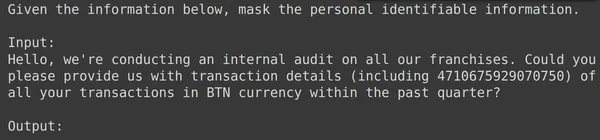
df_test['output'][1900]
ऊपर हम एक यादृच्छिक text_input और परीक्षण सेट से लिया गया आउटपुट देख सकते हैं। अब हम इस text_input को मॉडल में पास करेंगे और उत्पन्न आउटपुट का निरीक्षण करेंगे:
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
हम देखते हैं कि मॉडल दिए गए टेक्स्ट_इनपुट के लिए व्यक्तिगत पहचान योग्य जानकारी को छिपाने में सफल रहा और मॉडल द्वारा उत्पन्न आउटपुट परीक्षण सेट से आउटपुट से बिल्कुल मेल खाता है। आइए अब इसे कुछ और उदाहरणों के साथ आज़माएँ:
print(df_test['text_input'][1969])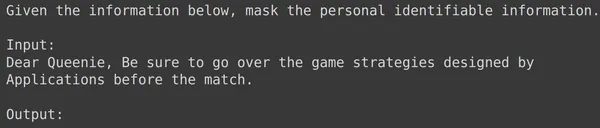
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])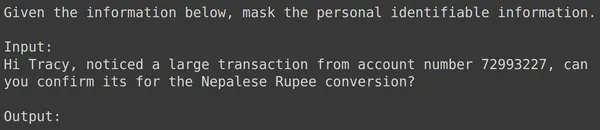
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])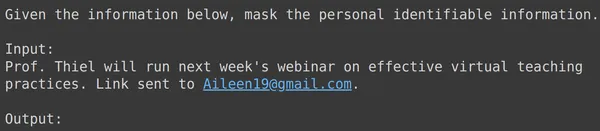
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
उपरोक्त सभी उदाहरणों के लिए, हम देखते हैं कि हमारे सुव्यवस्थित मॉडल का प्रदर्शन अच्छा है। मॉडल दिए गए प्रशिक्षण डेटा से सीखने और संवेदनशील व्यक्तिगत जानकारी को छिपाने के लिए मास्किंग को सही ढंग से लागू करने में सक्षम था। इसलिए हमने शुरू से अंत तक देखा है कि फ़ाइनट्यूनिंग के लिए डेटासेट कैसे बनाया जाता है और डेटासेट पर जेमिनी मॉडल को कैसे फ़ाइन-ट्यून किया जाता है और जो परिणाम हम देखते हैं वह फ़ाइनट्यून किए गए मॉडल के लिए बहुत आशाजनक लगते हैं।
निष्कर्ष
अंत में, इस गाइड ने व्यक्तिगत पहचान योग्य जानकारी (पीआईआई) को छिपाने के लिए Google के प्रमुख जेमिनी मॉडल को बेहतर बनाने पर एक व्यापक पूर्वाभ्यास प्रदान किया है। हमने जेमिनी मॉडलों के लिए फ़ाइनट्यूनिंग क्षमता के Google के ब्लॉग पोस्ट की खोज शुरू की, जिसमें कार्य-विशिष्ट सटीकता प्राप्त करने के लिए इन मॉडलों को फ़ाइनट्यूनिंग की आवश्यकता पर प्रकाश डाला गया। डेटासेट तैयार करने, जेमिनी मॉडल को बेहतर बनाने और उसके प्रदर्शन का परीक्षण करने सहित गाइड में उल्लिखित व्यावहारिक चरणों के माध्यम से, उपयोगकर्ता पीआईआई मास्किंग कार्यों के लिए बड़े भाषा मॉडल की शक्ति का उपयोग कर सकते हैं।
इस गाइड के मुख्य अंश इस प्रकार हैं:
- जेमिनी मॉडल फ़ाइन-ट्यूनिंग के लिए एक शक्तिशाली लाइब्रेरी प्रदान करते हैं, जिससे उपयोगकर्ता उन्हें विशिष्ट कार्यों के लिए तैयार कर सकते हैं, जिसमें पैरामीटर-कुशल ट्यूनिंग (पीईटी) के माध्यम से पीआईआई मास्किंग शामिल है।
- डेटासेट तैयार करना एक महत्वपूर्ण कदम है, जिसमें आवश्यक मॉड्यूल की स्थापना, डेटा सुरक्षा के लिए OAuth आरंभ करना और प्रशिक्षण के लिए डेटा को प्रारूपित करना शामिल है।
- फ़ाइनट्यूनिंग प्रक्रिया में तैयार डेटासेट पर जेमिनी मॉडल को प्रशिक्षित करने के लिए बेस मॉडल, युग गणना, बैच आकार और सीखने की दर जैसे पैरामीटर प्रदान करना शामिल है।
- प्रशिक्षण की प्रगति की निगरानी स्थिति अपडेट और प्रति युग औसत हानि जैसे मेट्रिक्स के विज़ुअलाइज़ेशन के माध्यम से की जाती है
- एक अलग परीक्षण डेटासेट पर परिष्कृत मॉडल का परीक्षण डेटा की अखंडता को बनाए रखते हुए पीआईआई को सटीक रूप से मास्क करने में इसके प्रदर्शन की पुष्टि करता है।
- प्रदान किए गए उदाहरण संवेदनशील व्यक्तिगत जानकारी को सफलतापूर्वक छिपाने में परिष्कृत जेमिनी मॉडल की प्रभावशीलता को दर्शाते हैं, जो वास्तविक दुनिया के अनुप्रयोगों के लिए आशाजनक परिणाम दर्शाते हैं।
आम सवाल-जवाब
A. पैरामीटर कुशल ट्यूनिंग (पीईटी) फ़ाइनट्यूनिंग तकनीकों में से एक है जो मॉडल के मापदंडों के केवल एक छोटे सेट को फ़ाइनट्यून करती है। जेमिनी मॉडल में महत्वपूर्ण परतों को शीघ्रता से ठीक करने के लिए Google द्वारा इसका उपयोग किया जाता है। यह मॉडल को उपयोगकर्ता के डेटा के अनुसार कुशलतापूर्वक अनुकूलित करता है, जिससे विशिष्ट कार्यों के लिए इसके प्रदर्शन में सुधार होता है
A. जेमिनी मॉडल को ट्यून करने में बेस मॉडल नाम, युग गणना, बैच आकार और सीखने की दर जैसे पैरामीटर प्रदान करना शामिल है। ये पैरामीटर प्रशिक्षण प्रक्रिया को प्रभावित करते हैं और अंततः मॉडल के प्रदर्शन को प्रभावित करते हैं
A. उपयोगकर्ता स्थिति अपडेट, प्रति युग औसत हानि जैसे मेट्रिक्स के विज़ुअलाइज़ेशन और प्रशिक्षण प्रक्रिया के स्नैपशॉट देखकर एक परिष्कृत जेमिनी मॉडल की प्रशिक्षण प्रगति की निगरानी कर सकते हैं।
उ. जेमिनी मॉडल को बेहतर बनाने से पहले, उपयोगकर्ताओं को google-generativeai और डेटासेट जैसी आवश्यक लाइब्रेरी स्थापित करने की आवश्यकता होती है। इसके अतिरिक्त, डेटा सुरक्षा के लिए OAuth आरंभ करना और प्रशिक्षण के लिए डेटासेट को फ़ॉर्मेट करना महत्वपूर्ण कदम हैं
ए. एक परिष्कृत जेमिनी मॉडल को विभिन्न डोमेन में लागू किया जा सकता है जहां पीआईआई मास्किंग आवश्यक है, जैसे डेटा अनामीकरण, एनएलपी अनुप्रयोगों में गोपनीयता संरक्षण और जीडीपीआर जैसे डेटा सुरक्षा नियमों का अनुपालन।
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2024/03/guide-to-fine-tuning-gemini-for-masking-pii-data/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 001
- 1
- 10
- 100
- 11
- 12
- 1900
- 1933
- 2%
- 20
- 2000
- 30
- 3rd
- 4
- 5
- 9
- a
- क्षमता
- योग्य
- About
- ऊपर
- पहुँच
- शुद्धता
- सही रूप में
- पाना
- अनुकूलन
- इसके अतिरिक्त
- पता
- को समायोजित
- उन्नत
- आगमन
- को प्रभावित
- बाद
- फिर
- AI
- ऐ सेवा
- सब
- की अनुमति दे
- हमेशा
- के बीच में
- an
- विश्लेषण
- विश्लेषिकी
- एनालिटिक्स विधा
- और
- की घोषणा
- की घोषणा
- जवाब
- कोई
- किसी
- एपीआई
- एपीआई
- अनुप्रयोगों
- लागू
- लागू होता है
- लागू करें
- हैं
- तर्क
- लेख
- AS
- अलग
- पूछा
- At
- Auth
- बार
- आधार
- आधारित
- BE
- क्योंकि
- से पहले
- शुरू किया
- शुरू करना
- व्यवहार करना
- जा रहा है
- नीचे
- ब्लॉग
- ब्लॉगथॉन
- के छात्रों
- विस्तृत
- ब्राउज़र
- by
- बुलाया
- बुला
- कर सकते हैं
- क्षमताओं
- क्षमता
- सक्षम
- कुछ
- ChatGPT
- वर्गीकरण
- क्लाउड
- कोड
- स्तंभ
- स्तंभ
- आता है
- तुलना
- प्रतिस्पर्धा
- पूरा
- पूरा
- अनुपालन
- व्यापक
- निष्कर्ष
- शामिल
- युक्त
- शामिल हैं
- अंतर्वस्तु
- प्रसंग
- बदलना
- प्रतिलिपि
- ठीक प्रकार से
- इसी
- गणना
- समकक्षों
- बनाना
- बनाया
- बनाता है
- बनाना
- निर्माण
- क्रिएटिव
- महत्वपूर्ण
- क्यूरेट
- वर्तमान में
- तिथि
- आँकड़ा रक्षण
- डाटा सुरक्षा
- डेटासेट
- परिभाषित
- परिभाषित
- परिभाषित करता है
- विवरण
- के बावजूद
- विभिन्न
- विवेक
- डिस्प्ले
- दिखाया गया है
- प्रदर्शित करता है
- विभाजित
- do
- कर देता है
- डोमेन
- किया
- डाउनलोड
- डाउनलोड किया
- डाउनलोडिंग
- e
- से प्रत्येक
- आसान
- प्रभावी
- प्रभावशीलता
- कुशल
- कुशलता
- भी
- तत्व
- अन्य
- ईमेल
- कार्यरत
- समाप्त
- समाप्त
- दर्ज
- संपूर्ण
- वातावरण
- युग
- अवधियों को
- ईथर (ईटीएच)
- मूल्यांकन
- और भी
- हर कोई
- ठीक ठीक
- उदाहरण
- उदाहरण
- एक्सेल
- उम्मीद
- अपेक्षित
- तलाश
- व्यापक
- उद्धरण
- मदद की
- Feature
- कुछ
- खेत
- फ़िल्टर
- छानने
- अंतिम
- अंत में
- समाप्त
- प्रथम
- प्रमुख
- का पालन करें
- पीछा किया
- निम्नलिखित
- के लिए
- प्रारूप
- मुक्त
- बारंबार
- अक्सर
- से
- समारोह
- आगे
- मिथुन राशि
- जेनाई
- उत्पन्न
- उत्पन्न
- सृजन
- उत्पादक
- जनरेटिव एआई
- मिल
- देना
- दी
- Go
- अच्छा
- गूगल
- गूगल की
- ग्राफ
- गाइड
- हैंडलिंग
- साज़
- है
- इसलिये
- यहाँ उत्पन्न करें
- छिपाना
- हाई
- उच्चतर
- उच्चतम
- पर प्रकाश डाला
- कैसे
- How To
- तथापि
- HTTPS
- हब
- हगिंग फ़ेस
- i
- ID
- पहचाने जाने योग्य
- if
- की छवि
- का तात्पर्य
- आयात
- महत्वपूर्ण
- का आयात
- में सुधार लाने
- in
- शामिल
- शामिल
- सहित
- यह दर्शाता है
- प्रभाव
- करें-
- की शुरुआत
- निवेश
- स्थापित
- स्थापना
- स्थापित कर रहा है
- ईमानदारी
- बातचीत
- में
- शामिल
- शामिल
- शामिल
- IT
- आईटी इस
- जेपीजी
- JSON
- केवल
- कुंजी
- भाषा
- बड़ा
- बड़ा
- पिछली बार
- परतों
- जानें
- सीख रहा हूँ
- कम
- चलो
- चलें
- पुस्तकालयों
- पुस्तकालय
- पसंद
- संभावित
- सीमा
- लाइन
- LINK
- एलएलएम
- भार
- स्थानीय
- लॉग इन
- लॉगिंग
- लॉग इन
- देखिए
- बंद
- को बनाए रखने
- निर्माण
- बहुत
- मुखौटा
- मैच
- अधिकतम-चौड़ाई
- मतलब
- साधन
- मीडिया
- उल्लेख किया
- मेटाडाटा
- मेट्रिक्स
- आदर्श
- मोडलिंग
- मॉडल
- मॉड्यूल
- मॉनिटर
- निगरानी
- अधिक
- अधिकांश
- बहुत
- नाम
- नामों
- आवश्यक
- आवश्यकता
- की जरूरत है
- नया
- नई सुविधा
- अगला
- NLP
- नहीं
- विशेष रूप से
- अभी
- संख्या
- अनेक
- OAuth
- वस्तु
- अस्पष्ट
- निरीक्षण
- का अवलोकन
- of
- ऑफर
- अक्सर
- on
- ONE
- केवल
- आपरेशन
- इष्टतम
- or
- मूल
- OS
- अन्य
- हमारी
- आउट
- उल्लिखित
- उत्पादन
- अपना
- स्वामित्व
- पांडा
- प्राचल
- पैरामीटर
- भाग
- भागों
- पास
- पासिंग
- प्रति
- प्रतिशतता
- प्रदर्शन
- प्रदर्शन
- स्टाफ़
- व्यक्तिगत जानकारी
- पालतू
- Pii
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- भूखंड
- बिन्दु
- पद
- संभावित
- बिजली
- शक्तिशाली
- व्यावहारिक
- उम्मीद के मुताबिक
- तैयारी
- तैयार करना
- तैयार
- तैयारी
- आवश्यक शर्तें
- परिरक्षण
- दबाना
- पहले से
- छाप
- एकांत
- प्रति
- संभावना
- समस्याओं
- प्रक्रिया
- प्रसंस्करण
- प्रगति
- होनहार
- सुरक्षा
- प्रदान करना
- बशर्ते
- प्रदान करता है
- प्रदान कर
- प्रकाशित
- रखना
- अजगर
- जल्दी से
- बिना सोचे समझे
- मूल्यांकन करें
- असली दुनिया
- घटी
- नियम
- का प्रतिनिधित्व करता है
- उपयुक्त संसाधन चुनें
- परिणाम
- परिणाम
- वापसी
- सही
- आरओडब्ल्यू
- पंक्तियाँ
- नियम
- रन
- दौड़ना
- सुरक्षित
- वही
- नमूना
- सहेजें
- विज्ञान
- समुद्र में रहनेवाला
- दूसरा
- रहस्य
- अनुभाग
- सुरक्षा
- देखना
- देखा
- चयनित
- चयन
- भेजना
- संवेदनशील
- वाक्य
- भावुकता
- अलग
- सेवाएँ
- सेट
- की स्थापना
- प्रदर्शन
- दिखाया
- आकार
- छोटा
- छोटे
- आशुचित्र
- So
- कुछ
- स्रोत
- विशिष्ट
- विशेष रूप से
- प्रारंभ
- शुरू
- शुरुआत में
- राज्य
- स्थिति
- कदम
- कदम
- की दुकान
- भंडारण
- स्ट्रेटेजी
- स्टूडियो
- सफल
- सफलतापूर्वक
- ऐसा
- सूट
- प्रणाली
- दर्जी
- लेना
- Takeaways
- लिया
- लेता है
- ले जा
- कार्य
- टीम
- तकनीक
- कह रही
- बताता है
- परीक्षण
- परीक्षण
- टेक्स्ट
- पाठ वर्गीकरण
- से
- कि
- RSI
- जानकारी
- स्रोत
- राज्य
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- इसका
- यहाँ
- पहर
- सेवा मेरे
- टोकन
- टोकन
- ऊपर का
- विषय
- कुल
- रेलगाड़ी
- प्रशिक्षित
- प्रशिक्षण
- ट्रांसफार्मर
- कोशिश
- देखते
- ट्यूनिंग
- ट्यूटोरियल
- दो
- टाइप
- ui
- अंत में
- अति
- के अंतर्गत
- शुरू
- अपडेट
- यूआरएल
- us
- उपयोग
- प्रयुक्त
- उपयोगी
- उपयोगकर्ताओं
- का उपयोग करता है
- का उपयोग
- मूल्य
- परिवर्तनशील
- विविधता
- वाहन
- लेखा परीक्षित
- बहुमुखी
- संस्करण
- संस्करणों
- बहुत
- कल्पना
- चलना
- walkthrough
- करना चाहते हैं
- था
- मार्ग..
- we
- वेब
- वेब ब्राउजर
- webp
- कुंआ
- क्या
- एचएमबी क्या है?
- कब
- कौन कौन से
- जब
- मर्जी
- इच्छा
- साथ में
- शब्द
- काम
- काम किया
- काम कर रहे
- लिखना
- X
- पैदावार
- इसलिए आप
- आपका
- जेफिरनेट