A Meta bemutatta legújabb, Llama 3 névre keresztelt nagy nyelvi modelljét (LLM), és azt állítja, hogy sokkal nagyobb modelleket fog kihívni, mint például a Google, a Mistral és az Anthropic.
Hosszasban kiderült közlemény csütörtökön a Llama 3 nyolcmilliárdtól több mint 400 milliárd paraméterig terjedő verziókban érhető el. Referenciaként megjegyezzük, hogy az OpenAI és a Google legnagyobb modelljei megközelítik a két billió paramétert.
Egyelőre csak a Llama 3 nyolcmilliárd és 70 milliárd paraméteres szövegváltozatához férünk hozzá. A Meta még nem fejezte be a legnagyobb és legösszetettebb modellek betanítását, de arra utal, hogy többnyelvűek és multimodálisak lesznek – vagyis több kisebb, tartományra optimalizált modellből állnak össze.
A Meta azt állítja, hogy a Llama 70 még mindössze 3 milliárd paraméterrel is több mint képes arra, hogy jóval nagyobb modellekkel haladjon.

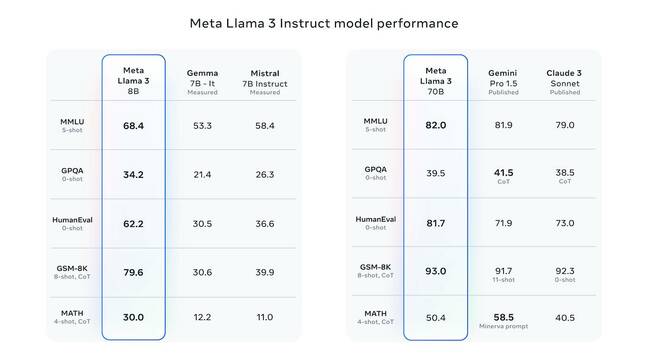
A Meta azt állítja, hogy a Llama3-8B és 70B sokkal nagyobb teljesítményt nyújt, mint a Gemini Pro és az Antrhopic's Claude 3 – Kattintson a nagyításhoz
Jobb adat, jobb modell
A Meta szerint az egyik legnagyobb nyereség egy 128,000 XNUMX jelzőt tartalmazó tokenizátor használatából származik. Az LLM-ek kontextusában a tokenek lehetnek néhány karakter, egész szó vagy akár kifejezés is. Az AI-k az emberi bemenetet tokenekre bontják, majd a tokenek szókincsével állítják elő a kimenetet.
A Meta elmagyarázta, hogy tokenizátora segít a nyelv hatékonyabb kódolásában, jelentősen növelve a teljesítményt. További eredményeket értek el a jobb minőségű adatkészletek és a képzés utáni további finomhangolási lépések használatával a modell teljesítményének és általános pontosságának javítása érdekében.
Konkrétan, a Meta felfedte, hogy a Llama 3 több mint 15 billió nyilvános forrásokból gyűjtött tokenre volt előképzett.
A Llama 3 képzési adatkészlete több mint hétszer nagyobb, és négyszer több kódot tartalmaz, mint a Llama 2, amely indított mindössze kilenc hónapja. De ahogy a mondás tartja, „szemetet be, szemetet ki” – ezért a Meta azt állítja, hogy kifejlesztett egy sor adatszűrő csővezetéket annak biztosítására, hogy a Llama 3 a lehető legkevesebb rossz információra legyen kiképezve.
Ezek a minőségellenőrzések egyaránt tartalmaztak heurisztikus és NSFW szűrőket, valamint az adatok deduplikációját és a szöveges osztályozókat, amelyek az információ minőségének előrejelzésére szolgáltak a képzés előtt. A Meta még a régebbi Llama 2 modelljét is felhasználta – amelyről azt mondta, hogy „meglepően jó a jó minőségű adatok azonosításában” –, hogy segítse a búzát a pelyvától elkülöníteni.
A képzési adatok 30 százaléka több mint XNUMX nyelvről származott, ami a Meta előrejelzése szerint a jövőben jelentősebb többnyelvűségi képességeket hoz a modellbe. A Social Network™️ egyelőre azt mondja, hogy a felhasználóknak nem szabad elvárniuk ugyanilyen fokú teljesítményt az angoltól eltérő nyelveken.
A kis modellek ilyen nagy adathalmazokon való betanítását általában számítási időpazarlásnak tekintik, sőt a pontosság csökkenő megtérülése miatt is. A képzési adatok ideális keverékét az erőforrások kiszámításához a „Csincsilla optimális” [PDF] összeg. A Meta szerint egy nyolcmilliárd paraméteres modellnél, mint a Llama3-8B, ez körülbelül 200 milliárd token lenne.
A tesztelés során azonban a Meta azt találta, hogy a Llama 3 teljesítménye tovább javult, még akkor is, ha nagyobb adathalmazokon tanítják. „Mind a nyolcmilliárd, mind a 70 milliárd paraméteres modellünk log-lineárisan fejlődött, miután akár 15 billió tokenre is betanítottuk őket” – írta a biznisz.
Az eredmény, úgy tűnik, egy viszonylag kompakt modell, amely sokkal nagyobb modellekkel összehasonlítható eredményeket képes produkálni. Valószínűleg érdemesnek tartották a számítással kapcsolatos kompromisszumot, mivel a kisebb modellek általában könnyebben következtethetők, és így könnyebben telepíthetőek.
8 bites pontossággal egy nyolcmilliárd paraméterű modell mindössze 8 GB memóriát igényel. A 4 bites pontosság csökkentése – akár ezt támogató hardver használatával, akár kvantálás használatával a modell tömörítésére – körülbelül felére csökkentené a memóriaigényt.
A Meta egy pár számítási klaszterre tanította a modellt, amelyek mindegyike 24,000 XNUMX Nvidia GPU-t tartalmaz. Elképzelhető, hogy egy ilyen nagy klaszteren való edzés, bár gyorsabb, bizonyos kihívásokat is jelent – megnő annak a valószínűsége, hogy valami meghibásodik egy edzés közben.
Ennek enyhítésére a Meta kifejtette, hogy kifejlesztett egy képzési veremet, amely automatizálja a hibaészlelést, -kezelést és -karbantartást. A hiperskálázó hibafigyelő és -tároló rendszereket is hozzáadott, hogy csökkentse az ellenőrzési pont és a visszaállítás többletköltségét abban az esetben, ha egy edzési futás megszakad. És miután elkészült, a Meta egy sor edzés utáni tesztelésnek és finomhangolási lépésnek vetette alá a modelleket.
A Llama3-8B és 70B mellett a Meta új és frissített megbízhatósági és biztonsági eszközöket is bevezetett – köztük a Llama Guard 2-t és a Cybersec Eval 2-t –, amelyek segítségével a felhasználók megvédhetik a modellt a visszaélésektől és/vagy az azonnali injekciós támadásoktól. A Code Shield egy másik kiegészítő, amely védőkorlátokat kínál, amelyek célja a Llama 3 által generált nem biztonságos kód kiszűrése.
Amint arról korábban beszámoltunk, az LLM által támogatott kódgenerálás érdekességekhez vezetett támadási vektorok hogy Meta kerülni akarja.
Elérhetőség
A következő néhány hónapban a Meta további modellek bevezetését tervezi – köztük egy olyant, amely meghaladja a 400 milliárd paramétert, és további funkciókat, nyelveket és nagyobb kontextusablakokat támogat. Ez utóbbi lehetővé teszi a felhasználók számára, hogy nagyobb, összetettebb lekérdezéseket tegyenek fel – például egy nagy szövegtömb összefoglalását.
A Llama3-8B és 70B jelenleg letölthető a Meta's-tól . Az Amazon Web Services, a Microsoft Azure, a Google Cloud, a Hugging Face és mások is azt tervezik, hogy platformjaikon telepítik a modellt.
Ha szeretné kipróbálni a Llama3-at a gépén, tekintse meg a helyi LLM-ek futtatásáról szóló útmutatónkat itt. Miután telepítette, elindíthatja a következő futtatásával:
ollama fut láma3
Jó szórakozást, és tudassa velünk, hogyan sikerült. ®
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://go.theregister.com/feed/www.theregister.com/2024/04/19/meta_debuts_llama3_llm/
- :van
- :is
- $ UP
- 000
- 15%
- 2%
- 200
- 200 milliárd
- 24
- 30
- 400
- 70
- a
- Rólunk
- visszaélés
- hozzáférés
- Szerint
- pontosság
- elért
- hozzáadott
- mellett
- További
- további nyereség
- Után
- Augusztus
- ais
- lehetővé
- Is
- amazon
- Az Amazon Web Services
- összeg
- an
- és a
- Másik
- Antropikus
- VANNAK
- AS
- kérdez
- összeszerelt
- At
- Támadások
- automaták
- elérhető
- elkerülése érdekében
- Égszínkék
- Rossz
- BE
- Jobb
- Legnagyobb
- Billió
- Milliárd token
- biz
- Blokk
- fellendítése
- határ
- mindkét
- szünet
- hoz
- de
- by
- jött
- TUD
- képességek
- képes
- eset
- kihívás
- kihívások
- karakter
- ellenőrizze
- követelések
- claude
- kettyenés
- felhő
- Fürt
- CO
- kód
- összegyűjtött
- jön
- kompakt
- hasonló
- Befejezett
- bonyolult
- borogatás
- Kiszámít
- számítástechnika
- figyelembe vett
- tartalmazó
- tartalmaz
- kontextus
- tovább
- ellenőrzések
- Jelenleg
- dátum
- adatkészletek
- Kezdet
- Fok
- telepíteni
- bevetés
- tervezett
- Érzékelés
- fejlett
- csökkenő
- csinált
- le-
- letöltés
- Csepp
- Csepegés
- minden
- könnyebb
- eredményesen
- nyolc
- bármelyik
- Angol
- biztosítására
- hiba
- Eter (ETH)
- Még
- meghaladó
- vár
- magyarázható
- Arc
- hiányában
- Kudarc
- messze
- gyorsabb
- kevés
- szűrő
- Szűrők
- A
- talált
- négy
- ból ből
- móka
- funkcionalitás
- jövő
- Nyereség
- Gemini
- általában
- generál
- generált
- generáló
- generáció
- szerzés
- Goes
- megy
- jó
- A Google Cloud
- kapott
- GPU
- Őr
- útmutató
- fél
- Kezelés
- hardver
- segít
- segít
- jó minőségű
- tanácsok
- Hogyan
- HTTPS
- emberi
- ideális
- azonosító
- kép
- javul
- in
- beleértve
- Beleértve
- Növeli
- információ
- bemenet
- bizonytalan
- telepítve
- érdekes
- megszakított
- bele
- Bemutatja
- Hát
- IT
- ITS
- jpg
- éppen
- Ismer
- nyelv
- Nyelvek
- nagy
- nagyobb
- legnagyobb
- legutolsó
- utóbbi
- indít
- Led
- hadd
- mint
- valószínűség
- Valószínű
- Kedvencek
- kis
- Láma
- llm
- helyi
- keres
- gép
- karbantartás
- jelenti
- Memory design
- mers
- meta
- microsoft
- Microsoft Azure
- Középső
- esetleg
- Enyhít
- keverje
- modell
- modellek
- ellenőrzés
- hónap
- több
- a legtöbb
- sok
- többszörös
- Nevezett
- közeledik
- Új
- következő
- kilenc
- Most
- NSFW
- Nvidia
- of
- ajánlat
- idősebb
- on
- egyszer
- ONE
- csak
- OpenAI
- or
- Más
- Egyéb
- mi
- ki
- teljesítményben felülmúl
- teljesítmény
- felett
- átfogó
- felső
- pár
- paraméter
- paraméterek
- százalék
- teljesítmény
- kifejezés
- terv
- tervek
- Platformok
- Plató
- Platón adatintelligencia
- PlatoData
- lehetséges
- Pontosság
- előre
- jósolt
- korábban
- Előzetes
- per
- gyárt
- biztosít
- nyilvánosan
- világítás
- lekérdezések
- kezdve
- RE
- csökkenteni
- referencia
- említett
- viszonylag
- Számolt
- követelmények
- megköveteli,
- Tudástár
- eredményez
- Eredmények
- Visszatér
- Revealed
- Tekercs
- tekercselt
- futás
- futás
- s
- biztosíték
- Biztonság
- Mondott
- azonos
- mondás
- azt mondja,
- Skála
- Úgy tűnik,
- különálló
- Series of
- Szolgáltatások
- hét
- Shield
- jelentősen
- kicsi
- kisebb
- So
- Közösség
- néhány
- valami
- Források
- verem
- Lépései
- tárolás
- lényeges
- ilyen
- Támogató
- Támogatja
- meglepően
- Systems
- T
- teszt
- Tesztelés
- szöveg
- mint
- hogy
- A
- az információ
- azok
- Őket
- akkor
- ők
- ezt
- csütörtök
- Így
- idő
- alkalommal
- nak nek
- tokenek
- szerszámok
- elad
- kiképzett
- Képzések
- Trillió
- Bízzon
- kettő
- elszabadult
- frissítve
- us
- használ
- használt
- Felhasználók
- segítségével
- változatok
- Ve
- verzió
- akar
- volt
- Hulladék
- we
- háló
- webes szolgáltatások
- JÓL
- ment
- voltak
- amikor
- ami
- míg
- egész
- lesz
- ablakok
- val vel
- szavak
- érdemes
- lenne
- írt
- még
- te
- A te
- zephyrnet