Bevezetés
Hogyan kezeli a hatalmas mennyiségű adat hatékony feldolgozásának és elemzésének kihívását? Ez a kérdés sok vállalkozást és szervezetet foglalkoztatott, miközben eligazodnak a big data összetettségei között. A naplóelemzéstől a pénzügyi modellezésig a méretezhető és rugalmas megoldások iránti igény soha nem volt ekkora. Írja be az AWS EMR-t vagy az Amazon Elastic MapReduce-t.
Ebben a cikkben megvizsgáljuk annak jellemzőit és előnyeit AWS Az EMR feltárja, hogyan tudja forradalmasítani az adatfeldolgozási és -elemzési megközelítést. Az Apache Sparkkal és az Apache Hive-vel való integrációtól kezdve az Amazon EC2 és S3 zökkenőmentes méretezhetőségéig feltárjuk az EMR erejét és az innovációt a szervezetében rejlő potenciált. Tehát induljunk el egy utazásra, hogy kiaknázzuk az adatokban rejlő teljes potenciált az AWS EMR segítségével.
Tartalomjegyzék
Mik azok a klaszterek és csomópontok?
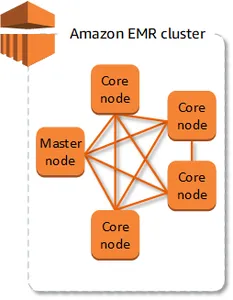
Az Amazon EMR magja a „Cluster” alapkoncepciója – az Amazon Elastic Compute Cloud (Amazon EC2) példányok dinamikus együttese, minden példányt találóan „csomópontnak” neveznek. Ezen a fürtön belül minden csomópont külön szerepet tölt be, amelyet „csomóponttípusként” ismerünk, és leírja sajátos funkcióját az elosztott alkalmazási környezetben, beleértve az olyan kiemelkedő eszközöket, mint az Apache Hadoop. Az Amazon EMR aprólékosan megszervezi a különféle szoftverösszetevők konfigurációját az egyes csomóponttípusokon, hatékonyan hozzárendelve a szerepeket a csomópontokhoz az elosztott alkalmazási keretrendszeren belül.
Csomópontok típusai az Amazon EMR-ben
- Elsődleges csomópont: Ez a tekintélyes erő irányítja a teljes fürtöt, és kulcsfontosságú szoftverkomponenseket hajt végre az adatok elosztásának és a feladatok más csomópontok közötti elosztásának koordinálásához. Az elsődleges csomópont szorgalmasan követi a feladat állapotát, és figyeli a fürt általános állapotát. Minden fürt eleve tartalmaz egy elsődleges csomópontot, és még egy olyan egycsomópontos fürt létrehozása is megvalósítható, amely kizárólag az elsődleges csomópontot tartalmazza.
- Alapcsomópont: A fürt gerincét képező központi csomópontok speciális szoftverkomponenseket tartalmaznak, amelyek a Hadoop elosztott fájlrendszerben (HDFS) feladatok végrehajtására és adatok tárolására szolgálnak. A több csomópontból álló fürtökben legalább egy központi csomópont az architektúra szerves részét képezi, biztosítva a zökkenőmentes feladatvégrehajtást és adattárolást.
- Feladat csomópont: A feladatcsomópontok kiemelt szerepet töltenek be, kizárólag a feladatokat futtatják anélkül, hogy hozzájárulnának a HDFS-ben való adattároláshoz. A feladatcsomópontok, bár opcionálisak, fokozzák a fürt sokoldalúságát azáltal, hogy hatékonyan hajtják végre a feladatokat az adattárolási kötelezettségek túlterhelése nélkül.
Az Amazon EMR fürtstruktúrája optimalizálja az adatfeldolgozást és -tárolást különálló csomóponttípusokkal, rugalmasságot kínálva a fürtök egyedi alkalmazási igényekhez való testreszabásához.
Az Amazon EMR architektúrájának áttekintése
Az Amazon EMR szolgáltatás alapstruktúrája egy többrétegű architektúra körül forog, minden réteg különböző képességekkel és funkciókkal járul hozzá a klaszter általános működéséhez.
Tárolás
A tárolóréteg különféle fájlrendszereket foglal magában, amelyek a fürt szerves részét képezik. A figyelemre méltó lehetőségek a következők:
Hadoop elosztott fájlrendszer (HDFS)
A Hadoop számára tervezett elosztott, méretezhető fájlrendszer, amely az adatokat a fürtpéldányok között osztja el az egyedi példányok hibáival szembeni ellenálló képesség biztosítása érdekében. A HDFS olyan célokat szolgál, mint a közbenső eredmények gyorsítótárazása a MapReduce feldolgozása során és a munkaterhelések kezelése jelentős véletlenszerű I/O-val.
EMR fájlrendszer (EMRFS)
A Hadoop képességeit kiterjesztve az EMRFS közvetlen hozzáférést tesz lehetővé az Amazon S3-ban tárolt adatokhoz, és zökkenőmentesen integrálja azokat a HDFS-hez hasonló fájlrendszerként. Ez a rugalmasság lehetővé teszi a felhasználók számára, hogy a HDFS vagy az Amazon S3 fájlrendszert válasszák, az Amazon S3-at általában a bemeneti/kimeneti adatok, a HDFS-t pedig a közbenső eredmények tárolására használják.
Helyi fájlrendszer
A helyileg csatlakoztatott lemezekre hivatkozva a helyi fájlrendszer az Amazon EC2-példányokhoz csatolt előre konfigurált blokktárolókon működik a Hadoop-fürt létrehozása során. Az ilyen példánytároló kötetek adatai csak a megfelelő Amazon EC2 példány életciklusának időtartama alatt maradnak meg.
Klaszter erőforrás-kezelés
Ez a réteg szabályozza a fürt erőforrások hatékony kiosztását és ütemezését az adatfeldolgozási feladatokhoz. Az Amazon EMR alapértelmezés szerint kihasználja a YARN-t (Yet Another Resource Negotiator), az Apache Hadoop 2.0-ban bevezetett összetevőt a központosított erőforrás-kezeléshez. Míg a helyszíni példányok gyakran futtatnak feladatcsomópontokat, az Amazon EMR ügyesen ütemezi a YARN-feladatokat, hogy megelőzze a spotpéldány-alapú feladatcsomópontok megszűnése által okozott hibákat.
Adatfeldolgozási keretrendszerek
Az adatfeldolgozást és -elemzést elősegítő motor ebben a rétegben található, különféle keretekkel, amelyek különféle feldolgozási igényeket szolgálnak ki, például kötegelt, interaktív, memórián belüli és streaming. Az Amazon EMR kulcsfontosságú keretrendszerek támogatásával büszkélkedhet, beleértve:
Hadoop MapReduce
A nyílt forráskódú programozási modell a logika kezelésével leegyszerűsíti a párhuzamosan elosztott alkalmazások fejlesztését, míg a felhasználók Map és Reduce funkciókat biztosítanak. Támogatja a további keretrendszereket, mint például a Hive.
Apache Spark
Fürtkeretrendszer és programozási modell nagy adatterhelések feldolgozásához, irányított aciklikus grafikonok és memórián belüli gyorsítótár használatával a fokozott hatékonyság érdekében. Az Amazon EMR zökkenőmentesen integrálja a Sparkot, lehetővé téve az Amazon S3 adataihoz való közvetlen hozzáférést az EMRFS-en keresztül.
Alkalmazások és programok
Az Amazon EMR számos alkalmazást támogat, például a Hive, Pig és Spark Streaming könyvtárat, és olyan képességeket kínál, mint a magasabb szintű nyelvi feldolgozás, a gépi tanulási algoritmusok, az adatfolyam-feldolgozás és az adattárház. Ezenkívül a nyílt forráskódú projekteket is befogadja fürtkezelési funkcióival. Ezekkel az alkalmazásokkal való interakció magában foglalja a különböző könyvtárak és nyelvek használatát, beleértve a Java, a Hive, a Pig, a Spark Streaming, a Spark SQL, az MLlib és a GraphX with Spark használatát.
Is Read: Szeretné megtanulni a felhőalapú számítástechnikát? Kezdje utazását az AWS-sel!
Az első EMR-fürt beállítása
Az első EMR-klaszter beállításához a következő lépéseket követjük:
Fájlrendszer létrehozása S3-ban
Az EMR fájlrendszer létrehozásának megkezdéséhez első lépésünk egy S3 vödör létrehozása. Ezt követően ezen a tárolón belül létrehozunk egy kijelölt mappát, és megvalósítjuk a szerveroldali titkosítást. A mappán belüli további szervezés magában foglalja három almappa létrehozását: egy bemeneti mappa a bemeneti adatok fogadására, egy kimeneti mappa az EMR-folyamat kimeneteinek tárolására és egy naplómappa a releváns naplók karbantartására.
Feltétlenül meg kell jegyezni, hogy ezen mappák mindegyikének létrehozása során a kiszolgálóoldali titkosítás engedélyezve lesz a biztonsági intézkedések fokozása érdekében. Az eredményül kapott mappastruktúra a következőhöz fog hasonlítani:
└── emr-bucket123/
└── monthly-bill/
└── 2024-02/
├── Input
├── Output
└── Logs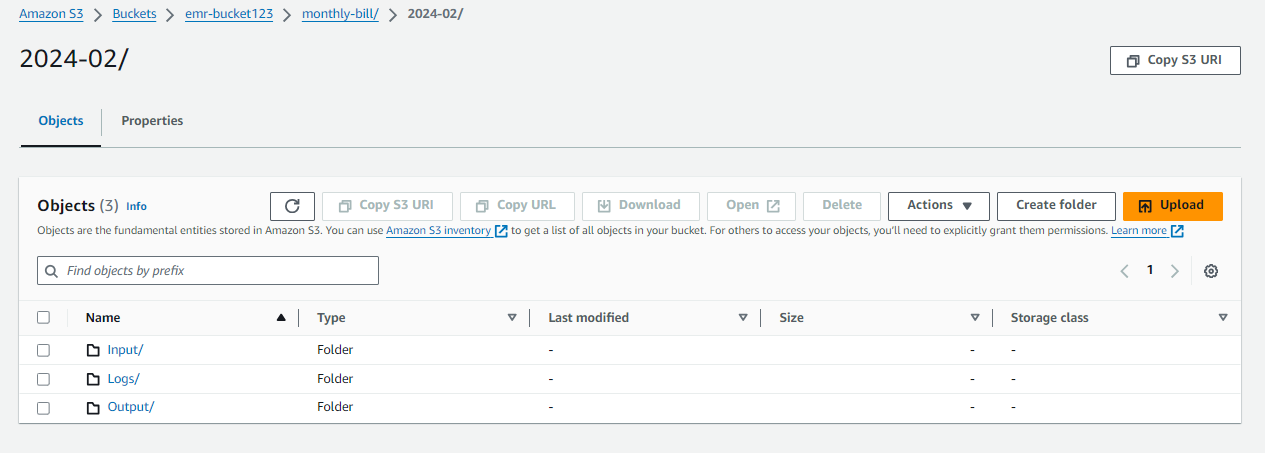
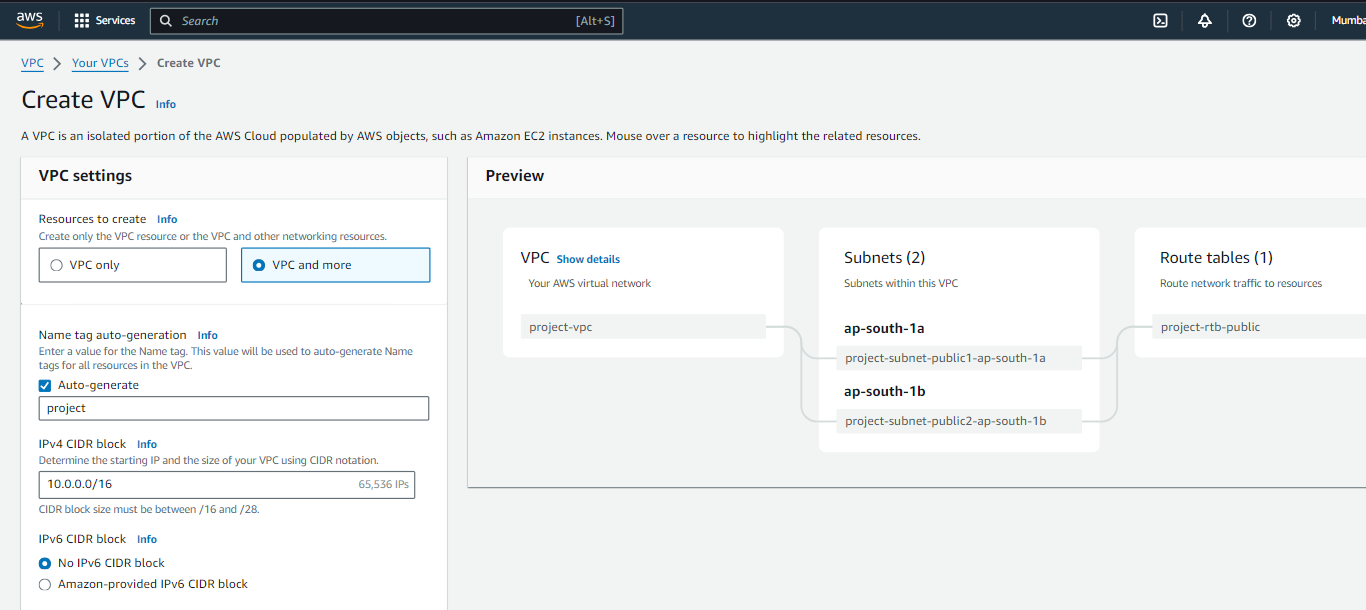
Hozzon létre egy VPC-t
A következő napirendünk egy virtuális magánfelhő (VPC) létrehozása. Ebben a beállításban két nyilvános alhálózatot konfigurálunk internet-hozzáféréssel, így biztosítva a zökkenőmentes kapcsolatot. Ebben a konfigurációban azonban nem lesznek privát alhálózatok.
A VPC elkészítésével kapcsolatos átfogó megértéshez és lépésről lépésre útmutatásért tekintse át az alábbi áttekintést és utasításokat:
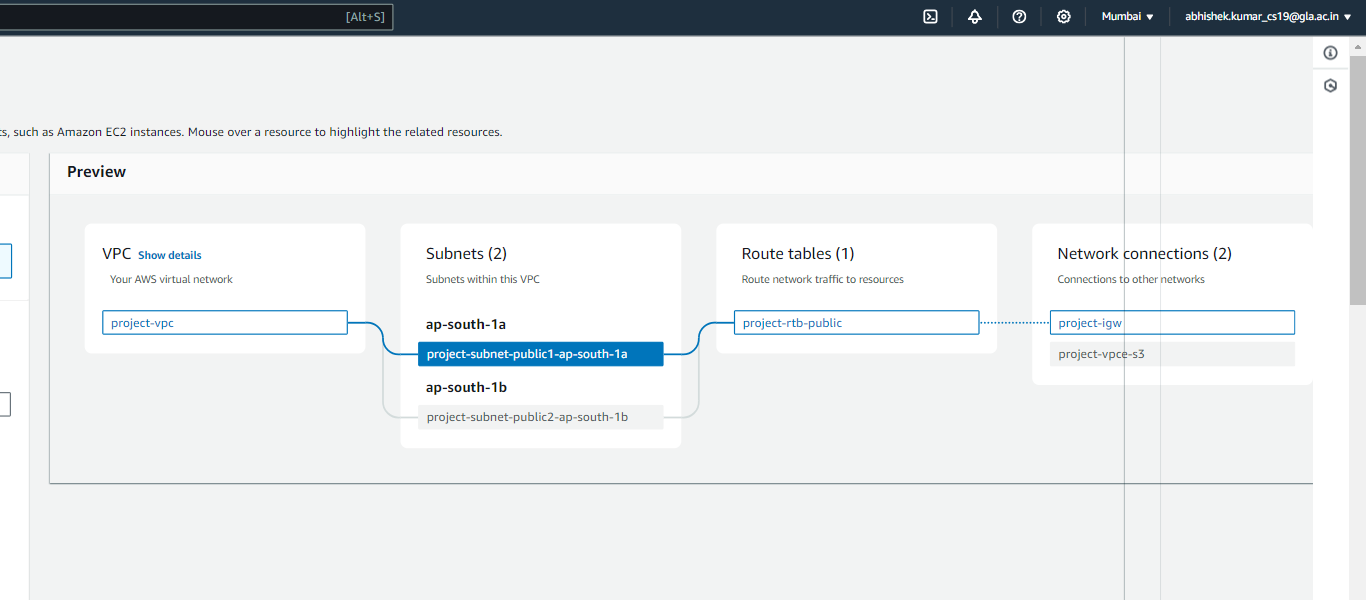
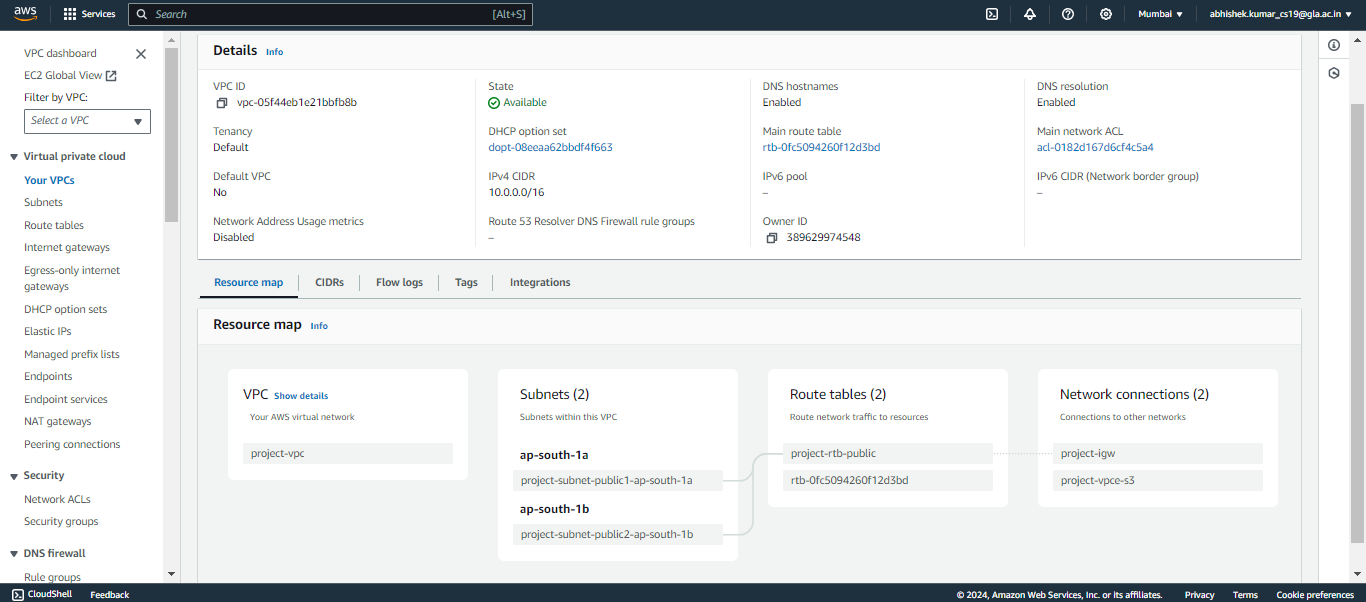
EMR-fürt konfigurálása
A beállítás után továbblépünk az EMR-fürt létrehozására. Ha rákattint a „Cluster létrehozása” lehetőségre, az alapértelmezett beállítások lesznek elérhetők:
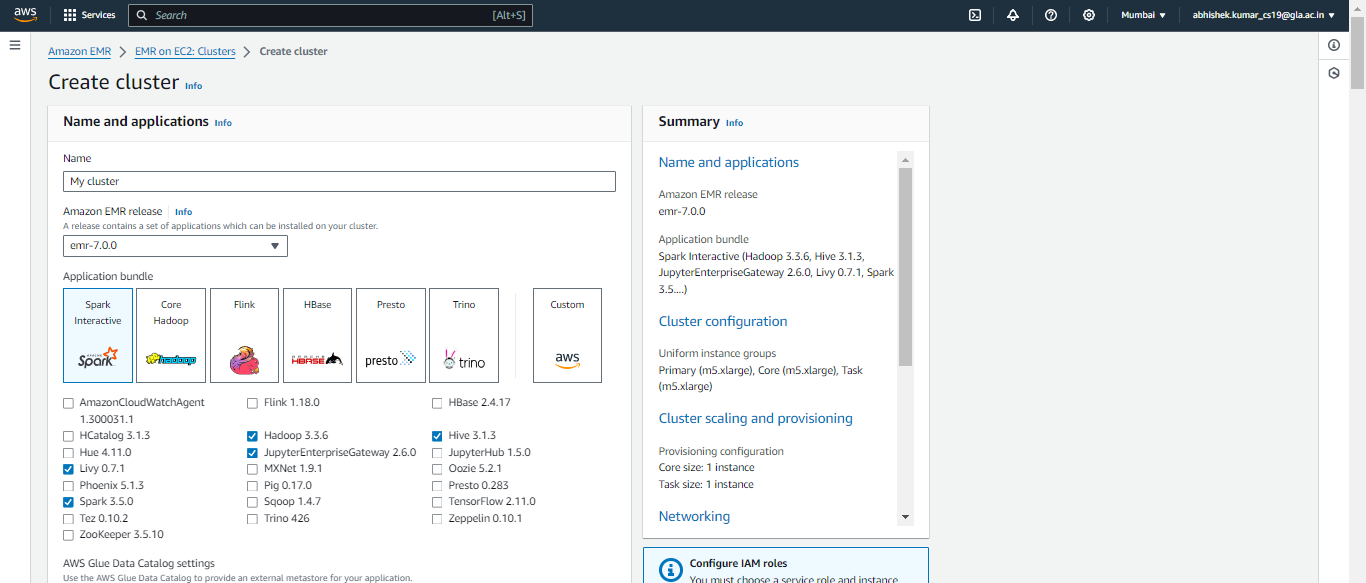
Ezután áttérünk a fürtkonfigurációra, de ebben a cikkben nem változtatunk semmit, megtartjuk az alapértelmezett konfigurációt, de eltávolíthatja a Feladat csomópontot a példánycsoport eltávolítása opció ehhez a használati esethez, mivel ehhez nem lesz annyira szüksége.
Most a Networkingben ki kell választania a korábban létrehozott VPC-t:
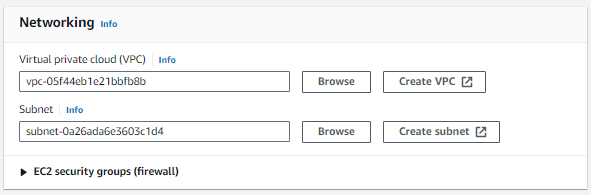
Most megőrizzük az alapértelmezett dolgokat, és továbblépünk a fürtnaplókhoz, és tallózunk az S3-hoz, amelyet korábban készítettünk a naplókhoz.
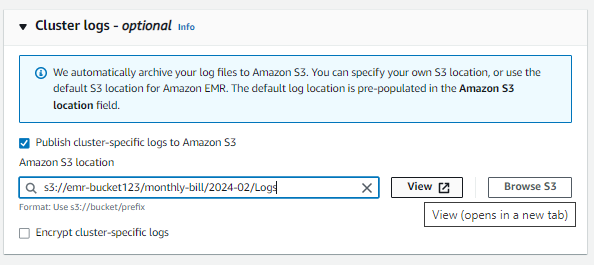
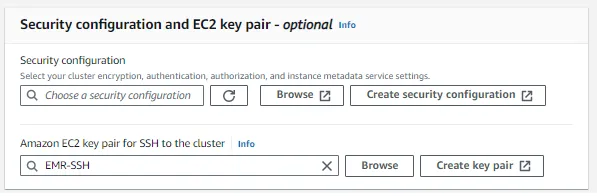
A naplók konfigurálása után most be kell állítania a biztonsági konfigurációt és az EC2 kulcspárt az EMR-hez, használhatja a meglévő kulcsokat, vagy létrehozhat új kulcspárt.
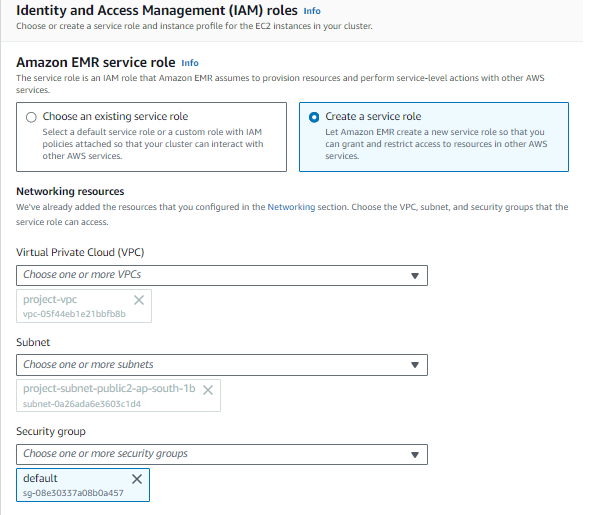
IAM szerepkörök válassza ki a Hozzon létre egy szolgáltatási szerepet opciót, adja meg a létrehozott VPC-t, és helyezze el az alapértelmezett biztonsági csoportot.
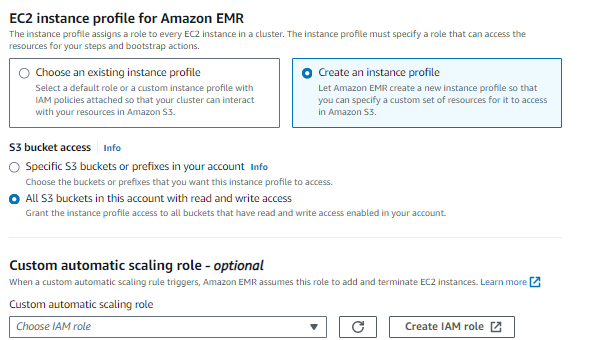
Most az EMR EC2 példányprofiljában válassza ki a Hozzon létre egy példányprofilt opciót és a vödör hozzáférést biztosít minden S3-hoz.

Most elkészült az első EMR-fürt beállításával kapcsolatos összes dologgal, és elindítja a fürtöt a Klaszter létrehozása lehetőségre kattintva.
Adatok feldolgozása EMR-fürtben
Az EMR-fürtön belüli adatok hatékony feldolgozásához szükségünk van egy Spark-szkriptre, amelyet egy adott adatkészlet lekérésére és manipulálására terveztek. Ehhez a cikkhez felhasználjuk Élelmiszer Letelepedési adatok. Az alábbiakban látható a Python szkript, amely az adatkészlet lekérdezéséért és kezeléséért felelős (LINK):
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
import argparse
def transform_data(data_source: str,output_uri: str)->None:
with SparkSession.builder.appName("My EMR Application").getOrCreate() as spark:
# Load CSV file
df = spark.read.option("header","true").csv(data_source)
#Rename Columns
df = df.select(
col("Name").alias("name"),
col("Violation Type").alias("violation_type")
)
#create an in-memory dataframe
df.createOrReplaceTempView("restaurant_violations")
#Construct SQL Query
GROUP_BY_QUERY='''
SELECT name,count(*) AS total_violations
FROM restaurant_violations
WHERE violation_type="RED"
GROUP BY name
'''
#Transform Data
transformed_df = spark.sql(GROUP_BY_QUERY)
#Log into EMR stdout
print(f"Number of rows in SQL query:{transformed_df.count()}")
#Write out results as parquet files
transformed_df.write.mode("overwrite").parquet(output_uri)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--data_source")
parser.add_argument("--output_uri")
args = parser.parse_args()
transform_data(args.data_source, args.output_uri)Ezt a szkriptet arra tervezték, hogy hatékonyan dolgozza fel az élelmiszeripari létesítmények adatait egy EMR-fürtön belül, világos és szervezett lépéseket biztosítva az adatátalakításhoz és a kimeneti tároláshoz.
Most töltse fel a Python fájlt az S3 tárolóba, és titkosítsa a fájlt a feltöltés után.
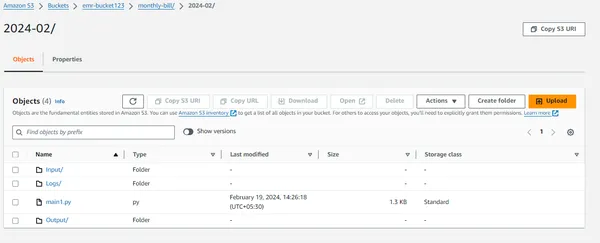
Az EMR-fürt futtatásához lépéseket kell létrehozni. Keresse meg az EMR-fürtöt, folytassa a „Step” opcióval, majd kattintson a „Lépés hozzáadása” gombra.

Ezt követően adja meg a Python-szkript elérési útját (a COPY S3 URI opción keresztül érhető el), miután megnyitotta a tárolót a webböngészőben. Egyszerűen kattintson rá, majd illessze be az elérési utat az alkalmazás elérési útjába, és ismételje meg ugyanezt a folyamatot a bemeneti adatkészlettel úgy, hogy megadja annak a vödörnek az URI-címét, ahol az adatkészlet található (ebben az esetben a bemeneti mappa), és állítsa be a kimeneti forrást. a kimeneti vödör URI-jére.

érvek
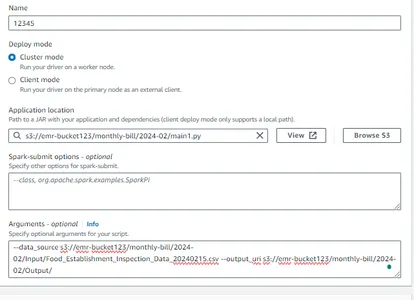
Most láthatjuk, hogy a lépés befejeződött-e vagy sem.

Az adatfeldolgozás az EMR-ben ezzel befejeződött, és az eredményül kapott kimenet megtekinthető a kijelölt kimeneti mappában az S3 vödörben.
A költséghatékonyság és a teljesítmény maximalizálása az Amazon EMR segítségével
- Az azonnali példányok kihasználása: Az Amazon EMR lehetőséget kínál a helyszíni példányok használatára, amelyek nem használt EC2 erőforrások, amelyek csökkentett áron érhetők el. A helyszíni példányok fürtökbe történő stratégiai integrálásával a szervezetek jelentős költségmegtakarítást érhetnek el a teljesítmény feláldozása nélkül.
- A példányflották bemutatása: Az Amazon EMR bevezeti a példányflották fogalmát, lehetővé téve a felhasználók számára, hogy az On-Demand és a Helyszíni példányok kombinációját egy egységes fürtön belül lefoglalják. Ez az alkalmazkodóképesség lehetővé teszi a szervezetek számára, hogy megtalálják az optimális egyensúlyt a költséghatékonyság és a rendelkezésre állás között.
Monitoring EMR Cluster
Az Amazon EMR (Elastic MapReduce) fürt monitorozása elengedhetetlen az egészség, a teljesítmény és az erőforrások hatékony kihasználása érdekében. Az EMR számos eszközt és mechanizmust biztosít a fürtök figyelésére. Íme néhány kulcsfontosságú szempont, amelyet figyelembe vehet:
- Amazon CloudWatch Metrics
- AWS EMR konzol
- Fakitermelés
- Ganglia és Spark webes felhasználói felület
- Erőforrás-felhasználás
Ne felejtse el módosítani a megfigyelési stratégiát a munkaterhelés és a használati eset speciális követelményei és jellemzői alapján. Rendszeresen ellenőrizze és frissítse megfigyelési beállításait a változó igények kielégítése és a fürt teljesítményének optimalizálása érdekében.
Is Read: AWS vs Azure: The Ultimate Cloud Face-Off
Következtetés
Az Amazon EMR hatékony megoldást kínál a nagy adatfeldolgozáshoz, rugalmas és hatékony platformmal kiterjedt adatkészletek kezelésére. Fürt alapú architektúrája, valamint többrétegű komponensei sokoldalúságot és optimalizálást biztosítanak a különféle alkalmazási igényekhez. Az EMR-fürt létrehozása egyszerű lépésekből áll, és a népszerű nyílt forráskódú keretrendszerekkel való integrációja fokozza vonzerejét.
Az EMR-fürtön belüli adatfeldolgozás Spark-szkripttel történő bemutatása szemlélteti a platform képességeit. Az olyan stratégiák, mint a helyszíni példányok és példányflották kihasználása, maximalizálják a költséghatékonyságot, kiemelve az EMR elkötelezettségét a költséghatékony megoldások biztosítása iránt.
Az EMR-fürtök hatékony monitorozása elengedhetetlen a teljesítmény és az erőforrás-kihasználás fenntartásához. Az olyan eszközök, mint az Amazon CloudWatch és a naplózási funkciók megkönnyítik ezt a megfigyelési folyamatot. Az Amazon EMR egy létfontosságú, felhasználóbarát eszköz, amely zökkenőmentes hozzáférést biztosít a fejlett adatfeldolgozáshoz.
Gyakran ismételt kérdések
V. Az Amazon EMR vagy az Elastic MapReduce az AWS felhőalapú szolgáltatása, amelyet hatékony nagy adatfeldolgozásra terveztek olyan nyílt forráskódú eszközökkel, mint az Apache Spark és a Hive.
V. Az EMR optimalizálja az adatfeldolgozást egy elsődleges, mag- és feladatcsomópontokkal rendelkező fürtstruktúra révén, rugalmasságot és hatékonyságot biztosítva a különféle alkalmazási igényekhez.
V. Az EMR-fürt beállítása magában foglalja egy S3-csoport létrehozását, egy VPC konfigurálását és a fürt inicializálását az AWS EMR-konzolon keresztül.
V. A költséghatékonysági stratégiák közé tartozik az azonnali példányok kihasználása és a példányflották használata a költséghatékonyság és a rendelkezésre állás közötti optimális egyensúly érdekében.
V. Az EMR-fürtök monitorozása elengedhetetlen az egészség, a teljesítmény és a hatékony erőforrás-felhasználás biztosításához. Az olyan eszközök, mint az Amazon CloudWatch és a naplózási funkciók segítik a hatékony megfigyelést.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://www.analyticsvidhya.com/blog/2024/03/what-is-aws-emr-heres-everything-you-need-to-know/
- :van
- :is
- :nem
- :ahol
- $ UP
- 10
- 11
- 17
- 2%
- 515
- 610
- 8
- a
- hozzáférés
- Az adatokhoz való hozzáférés
- hozzáférhető
- Férőhely
- át
- aciklikus
- alkalmazkodni
- rugalmasság
- További
- Ezen kívül
- cím
- fejlett
- Után
- ellen
- napirend
- algoritmusok
- Minden termék
- kioszt
- kiosztás
- lehetővé téve
- lehetővé teszi, hogy
- mentén
- amazon
- Amazon EC2
- Amazon EMR
- között
- Összegek
- an
- elemzés
- elemzése
- és a
- Másik
- bármilyen
- bármi
- Apache
- Apache Spark
- fellebbezés
- Alkalmazás
- alkalmazások
- megközelítés
- találóan
- építészet
- VANNAK
- körül
- cikkben
- AS
- kérdezte
- szempontok
- segít
- At
- csatolt
- elérhetőség
- elérhető
- AWS
- Égszínkék
- Hátgerinc
- Egyenleg
- alapján
- BE
- óta
- kezdődik
- lent
- Előnyök
- között
- Nagy
- Big adatok
- Blokk
- dicsekszik
- böngésző
- építész
- vállalkozások
- de
- by
- TUD
- képességek
- eset
- ellátás
- okozott
- központosított
- kihívás
- változik
- változó
- jellemzők
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- világos
- kettyenés
- kattintással
- felhő
- cloud computing
- Fürt
- Oszlopok
- kombináció
- elkötelezettség
- általában
- teljes
- Befejezett
- bonyodalmak
- összetevő
- alkatrészek
- átfogó
- Kiszámít
- számítástechnika
- koncepció
- Configuration
- konfigurálása
- összefüggő
- Connectivity
- Fontolja
- Konzol
- hozzájáruló
- koordináta
- másolat
- Mag
- Költség
- költségmegtakarítás
- költséghatékony
- kézműves
- teremt
- készítette
- létrehozása
- teremtés
- kritikus
- dátum
- adatfeldolgozás
- adattárolás
- adatkészletek
- def
- alapértelmezett
- alapértelmezett
- igények
- kijelölt
- tervezett
- Fejlesztés
- szorgalmasan
- közvetlen
- Közvetlen hozzáférés
- irányított
- különböző
- megosztott
- elosztó
- terjesztés
- számos
- do
- nem
- csinált
- hajtás
- időtartama
- alatt
- dinamikus
- e
- minden
- Korábban
- Hatékony
- hatékonyan
- hatékonyság
- hatékony
- eredményesen
- bármelyik
- induljon
- munkavállaló
- képessé
- engedélyezve
- lehetővé teszi
- felöleli
- átfogó
- titkosítani
- titkosítás
- Motor
- növelése
- fokozott
- Javítja
- biztosítására
- biztosítja
- biztosítása
- belép
- belépés
- Egész
- Egyensúlyi
- alapvető
- intézmény
- Eter (ETH)
- Még
- Minden
- minden
- kizárólagosan
- kivégez
- végrehajtó
- végrehajtás
- létező
- feltárása
- Feltárása
- kiterjedt
- megkönnyítése
- hibák
- megvalósítható
- Jellemzők
- Featuring
- érez
- filé
- Fájlok
- pénzügyi
- Találjon
- vezetéknév
- Rugalmasság
- rugalmas
- összpontosított
- következik
- következő
- élelmiszer
- A
- Kényszer
- alapítványi
- Keretrendszer
- keretek
- Ingyenes
- ból ből
- Tele
- funkció
- funkciós
- funkciók
- alapvető
- további
- generál
- generáció
- Ad
- irányelv szabályozza
- grafikonok
- nagyobb
- Csoport
- útmutatást
- Hadoop
- Kezelés
- Legyen
- Egészség
- itt
- Magas
- kiemelve
- Kaptár
- Ház
- Hogyan
- azonban
- HTTPS
- i
- IAM
- if
- illusztrálja
- kép
- parancsoló
- végre
- importál
- fontos
- in
- tartalmaz
- magában foglalja a
- Beleértve
- egyéni
- eredendően
- kezdeményez
- Innováció
- bemenet
- példa
- példányok
- utasítás
- szerves
- integrál
- integrálása
- integráció
- kölcsönható
- interaktív
- Közbülső
- Internet
- internet-hozzáférés
- bele
- Bevezetett
- Bemutatja
- jár
- IT
- ITS
- Jáva
- Állások
- utazás
- Tart
- Kulcs
- kulcsok
- Ismer
- ismert
- táj
- nyelv
- Nyelvek
- indít
- réteg
- TANUL
- tanulás
- legkevésbé
- erőfölény
- könyvtárak
- könyvtár
- fekszik
- életciklus
- mint
- kiszámításának
- helyi
- helyileg
- található
- log
- fakitermelés
- logika
- néz
- gép
- gépi tanulás
- fenntartása
- vezetés
- kezelése
- manipulál
- sok
- térkép
- max-width
- Maximize
- intézkedések
- mechanizmusok
- aprólékosan
- modell
- modellezés
- ellenőrzés
- monitorok
- mozog
- sok
- többrétegű
- my
- név
- Keresse
- Szükség
- igények
- hálózatba
- soha
- Új
- csomópont
- csomópontok
- Egyik sem
- figyelemre méltó
- megjegyezni
- fogalom
- Most
- szám
- megfigyelt
- of
- felajánlás
- Ajánlatok
- gyakran
- on
- Igény szerint
- egyszer
- ONE
- csak
- nyitva
- nyílt forráskódú
- működik
- működés
- optimálisan
- optimalizálás
- Optimalizálja
- Optimalizálja
- opció
- Opciók
- or
- szervezet
- szervezetek
- Szervezett
- Más
- mi
- ki
- teljesítmény
- kimenetek
- átfogó
- felső
- áttekintés
- pár
- Párhuzamos
- különös
- ösvény
- teljesítmény
- fennáll
- sújtja
- emelvény
- Platformok
- Plató
- Platón adatintelligencia
- PlatoData
- játszani
- rengeteg
- Népszerű
- erős
- potenciális
- hatalom
- megakadályozása
- elsődleges
- magán
- folytassa
- folyamat
- feldolgozás
- profil
- Programozás
- projektek
- kiemelkedő
- hajtó
- ad
- feltéve,
- biztosít
- amely
- nyilvános
- célokra
- tesz
- Piton
- kérdés
- kérdés
- véletlen
- Olvass
- észre
- fogadó
- Piros
- csökkenteni
- Csökkent
- említett
- rendszeresen
- eltávolítása
- ismétlés
- szükség
- követelmények
- lakik
- rugalmasság
- forrás
- Tudástár
- azok
- felelősség
- felelős
- kapott
- Eredmények
- Kritika
- forradalmasítani
- forog
- Szerep
- szerepek
- sorok
- futás
- futás
- s
- feláldozása
- azonos
- Megtakarítás
- skálázhatóság
- skálázható
- ütemezés
- forgatókönyv
- zökkenőmentes
- zökkenőmentesen
- biztonság
- biztonsági intézkedések
- lát
- válasszuk
- kiválasztása
- szolgálja
- szolgáltatás
- készlet
- beállítás
- beállítások
- felépítés
- számos
- jelentős
- Egyszerű
- egyszerűsíti
- egyszerűen
- So
- szoftver
- szoftver komponensek
- megoldások
- Megoldások
- néhány
- forrás
- Szikra
- specializált
- különleges
- Spot
- SQL
- Állapot
- Lépés
- Lépései
- tárolás
- tárolni
- memorizált
- tárolása
- Stratégiailag
- stratégiák
- Stratégia
- folyam
- folyó
- struktúra
- alhálózatok
- Később
- lényeges
- ilyen
- támogatás
- Támogatja
- rendszer
- Systems
- felszerelés
- Szabó
- Feladat
- feladatok
- hogy
- A
- azok
- akkor
- Ott.
- Ezek
- ők
- dolgok
- ezt
- három
- Keresztül
- nak nek
- szerszám
- szerszámok
- pályák
- Átalakítás
- igaz
- kettő
- típus
- típusok
- végső
- feltárni
- megértés
- vállalja
- egységes
- kinyit
- felhasználatlan
- Frissítések
- Feltöltés
- URI
- használ
- használati eset
- használt
- barátságos felhasználói
- Felhasználók
- segítségével
- hasznosítás
- hasznosít
- kihasználva
- különféle
- Hatalmas
- sokoldalúság
- keresztül
- Sértés
- Tényleges
- fontos
- kötetek
- vs
- Raktározás
- we
- háló
- webböngésző
- webp
- Mit
- Mi
- ami
- míg
- miért
- lesz
- val vel
- belül
- nélkül
- munkafolyamat
- ír
- még
- te
- A te
- zephyrnet