Perluas portofolio NLP Anda menggunakan BERT dan Haystack untuk menjawab semua pertanyaan Anda!
Jika Anda mencoba mempelajari Pemrosesan Bahasa Alami (NLP), membuat Bot Perselisihan, atau hanya tertarik untuk bermain-main dengan Transformers sebentar, ini adalah proyek untuk Anda!

Dalam contoh ini, kami akan membuat Chatbot yang mengetahui segalanya tentang Dragon Ball, tetapi Anda dapat melakukan apa pun yang Anda inginkan! Ini bisa berupa chatbot yang menjawab pertanyaan tentang seri lain, kursus universitas, hukum suatu negara, dll. Pertama, mari kita lihat bagaimana hal itu mungkin terjadi dengan BERT.
Bagaimana BERT bekerja sebagai Chatbot
BERT adalah teknik Machine Learning untuk NLP yang dibuat dan diterbitkan oleh Google pada tahun 2018. Pada fase pertama, model dilatih sebelumnya pada kumpulan data bahasa besar dengan cara semi-diawasi.
Pada fase ini, model belum dapat menjawab pertanyaan, tetapi mempelajari penyisipan kontekstual untuk kata-kata.

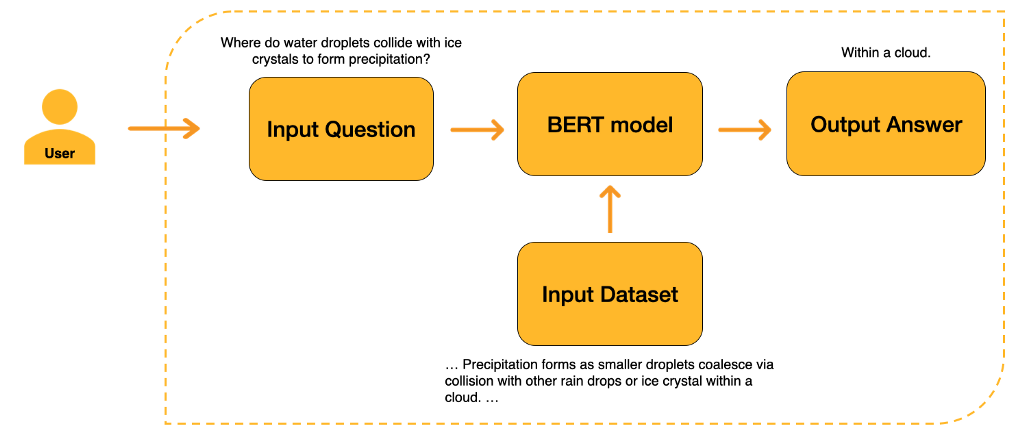
Pada fase kedua, BERT kemudian disesuaikan untuk tugas tertentu. Karena kami mencoba membangun Chatbot, kami membutuhkan model yang disesuaikan dengan tugas Menjawab Pertanyaan.

Setelah model difinishing untuk Question Answering, kita harus menyediakan Input Dataset agar model mengetahui dari mana harus mengekstrak jawabannya. Akhirnya, pengguna kemudian dapat memasukkan pertanyaan. Model akan mengekstrak jawaban dari dataset input.
Dengan demikian, pertama-tama, kita perlu mendapatkan Input Dataset dari mana model akan mengekstrak jawabannya.
Mengambil Data
Dalam contoh ini, chatbot kami akan menjadi Master Bola Naga, jadi kami akan mengambil data dari Wiki Bola Naga dengan BeautifulSoup. Scraping bukanlah fokus dari posting ini, jadi kami hanya akan memaksanya sedikit untuk mendapatkan semua data yang kami butuhkan.

Kami mengambil data dari bab dan juga dari seri yang berbeda (Dragon Ball Z, Dragon Ball GT, dll). Informasi terpenting yang akan kami ambil adalah apa yang sebenarnya terjadi di setiap bab dan, melalui halaman-halaman seri yang berbeda, kami juga memiliki jenis informasi lain (pencipta, perusahaan produksi, tanggal penayangan, dll).

Setelah mendapatkan semua ringkasan setiap episode, Haystack membutuhkan data untuk diformat sebagai daftar kamus, yang memiliki dua kunci utama. Salah satu kuncinya disebut "konten", di mana model akan mengekstrak semua informasi yang diperlukan untuk menjawab semua pertanyaan. Kunci lainnya disebut "meta" dan memiliki kamus bersarang dengan semua metadata yang Anda butuhkan. Dalam contoh ini, saya memberikan kamus dengan judul dan nomor dari episode yang ringkasannya diambil.

Sekarang setelah kita memiliki semua informasi tentang apa yang terjadi dalam rangkaian, kita perlu menginisialisasi model kita!
Memulai BERT
Untuk bagian ini, saya akan menggunakan Google Collab karena dua alasan:
- jauh lebih mudah untuk mengatur Haystack: Haystack adalah perpustakaan untuk NLP yang memiliki banyak ketergantungan dan terkadang membuatnya bekerja di komputer pribadi Anda tidak terlalu mulus, terutama untuk pemula yang tidak terbiasa mengatur lingkungan;
- kita akan menggunakan model BERT, yang merupakan model besar yang bekerja lebih cepat dengan GPU — yang disediakan Google Colab secara gratis!

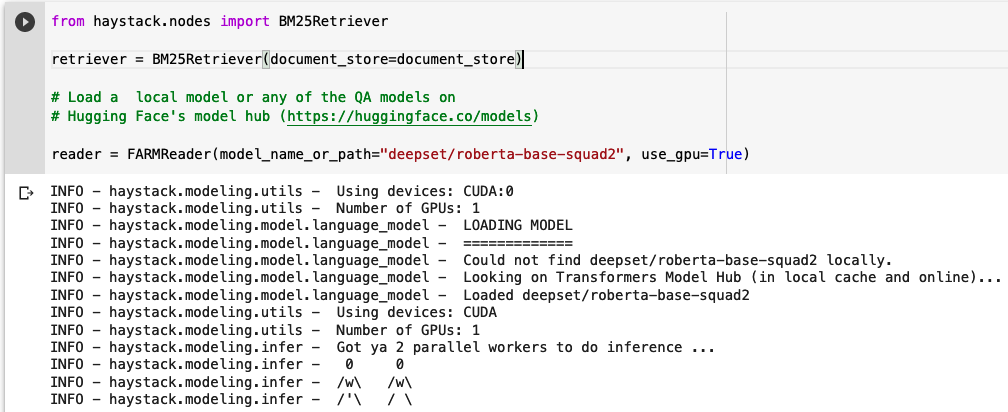
Kita perlu memilih Retriever dan Reader untuk digunakan. Retriever adalah filter ringan yang menelusuri seluruh database dokumen kami dan memilih sejumlah X dokumen yang mungkin menjawab pertanyaan yang diajukan pengguna. Dalam hal ini, kami akan meminta Retriever untuk mengembalikan 10 dokumen.

Retriever meneruskan 10 dokumen ini ke Reader. Dalam hal ini, kami akan menggunakan BERT sebagai Pembaca kami. Lebih khusus lagi, kami akan menggunakan model BERT bahasa Inggris yang sudah disesuaikan untuk Jawaban Pertanyaan Ekstraktif. Intinya, itu berarti model tersebut telah dilatih sebelumnya dalam bahasa Inggris dan kemudian dilatih untuk QA Ekstraktif di lapisan pelatihan terakhir. Karena data Dragon Ball sudah dalam bahasa Inggris, modelnya sudah siap untuk menjawab pertanyaan kami!
PS: Jika Anda memiliki data dalam bahasa lain, Anda dapat mencari model yang dilatih dalam bahasa tersebut di MemelukWajah.
Kami akan meminta model untuk mengembalikan 5 jawaban benar yang paling mungkin dari 10 dokumen yang paling mungkin untuk mendapatkan jawabannya! Ingat: Retriever menemukan dokumen yang tepat dan Pembaca menemukan jawaban yang tepat (dalam hal ini, pembaca kami adalah robert-base-squad2)! Ini adalah output dari model setelah memasukkan pertanyaan sederhana tentang Dragon Ball:
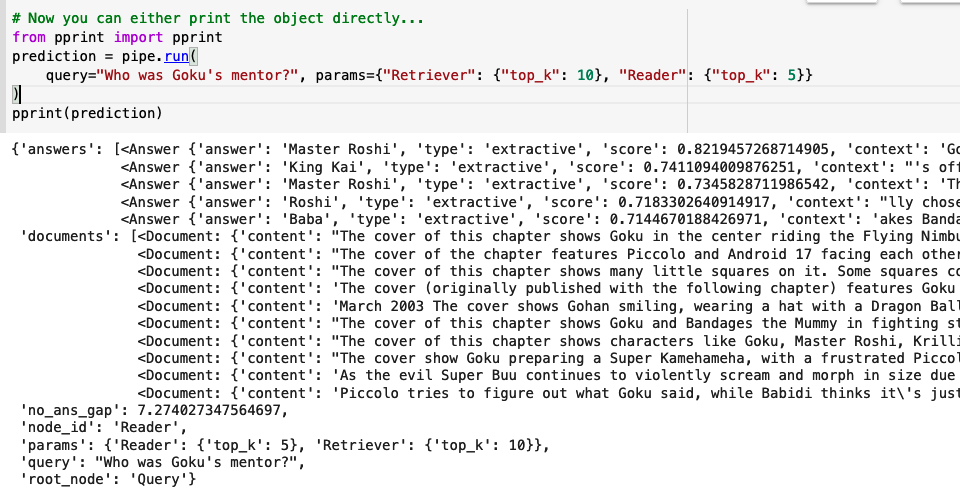
Model mendapat jawaban yang benar! Mentor dari Goku adalah Master Roshi dan Raja Kai!

Sekali lagi, ini benar, kami tidak perlu melatih model apa pun pada data kami!
Menguji Chatbot kami
Setelah membuat fungsi yang membuat output kita lebih cantik, mari kita lihat hasilnya!
Mari kita tanyakan dengan siapa Vegeta menikah:

Itu benar! Jawaban pertamanya adalah Bulma! Mari kita coba pertanyaan lain dan lihat hasilnya:



Model menjawab cukup baik untuk banyak pertanyaan!

Tetapi jika kita menambahkan beberapa variasi dalam cara kita mengajukan beberapa pertanyaan, itu mulai menjadi kurang tepat…


Ini hanya beberapa contoh bagaimana modelnya masih belum sempurna.

Jangan khawatir, karena kami dapat melatihnya lebih lanjut pada data kami jika kami mau! Haystack memiliki tutorial sederhana tentang cara melakukan ini juga. Namun, itu bisa menjadi seluruh posting barunya. Jika Anda merasa ini berguna, Anda dapat mengirimi saya pesan atau komentar dan saya akan mencoba membuat posting yang menjelaskannya selangkah demi selangkah.
Pekerjaan selanjutnya
Perpustakaan Haystack memiliki dokumentasi yang sangat bagus dan posting ini sebenarnya didasarkan pada salah satu buku catatan tutorial mereka. Kami dapat mencoba menambahkan lebih banyak data tentang seri lain dan mencoba melihat apakah model mempertahankan kinerjanya. Ini dia tautan ke Repositori Github proyek jika Anda ingin mengakses buku catatan yang digunakan.
Saya harap Anda menikmati membuat chatbot pertama Anda dengan BERT

![]()
Bangun Chatbot tentang serial favorit Anda dalam 30 menit awalnya diterbitkan di Kehidupan Chatbots on Medium, di mana orang-orang melanjutkan pembicaraan dengan menyoroti dan merespons cerita ini.
- Coinsmart. Pertukaran Bitcoin dan Crypto Terbaik Eropa.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. AKSES GRATIS.
- CryptoHawk. Radar Altcoin. Uji Coba Gratis.
- Source: https://chatbotslife.com/build-a-chatbot-about-your-favorite-series-in-30-minutes-3337e1a107b0?source=rss—-a49517e4c30b—4
- "
- 10
- a
- Tentang Kami
- mengakses
- Akun
- Semua
- sudah
- Lain
- menjawab
- sekitar
- karena
- makhluk
- Bit
- Bot
- Kotak
- membangun
- Bab
- Pilih
- perusahaan
- komputer
- Konten
- Percakapan
- bisa
- negara
- membuat
- dibuat
- menciptakan
- membuat
- pencipta
- data
- Basis Data
- Tanggal
- rinci
- berbeda
- perselisihan
- dokumen
- Naga
- Inggris
- terutama
- esensi
- dll
- segala sesuatu
- contoh
- contoh
- Ekstrak
- FAST
- lebih cepat
- Fed
- Akhirnya
- menemukan
- Pertama
- Fokus
- dari
- fungsi
- lebih lanjut
- mendapatkan
- GitHub
- Pemberian
- akan
- GPU
- di sini
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTTPS
- penting
- impresif
- informasi
- memasukkan
- tertarik
- IT
- kunci
- kunci-kunci
- King
- Tahu
- bahasa
- besar
- Hukum
- lapisan
- BELAJAR
- belajar
- pengetahuan
- Tingkat
- Perpustakaan
- petir
- ringan
- Daftar
- sedikit
- mesin
- Mesin belajar
- utama
- membuat
- Membuat
- cara
- medium
- meta
- mungkin
- model
- lebih
- paling
- Alam
- kebutuhan
- jumlah
- Lainnya
- bagian
- Konsultan Ahli
- sempurna
- prestasi
- pribadi
- tahap
- Bermain
- portofolio
- mungkin
- kekuasaan
- cukup
- pengolahan
- Produksi
- proyek
- memberikan
- menyediakan
- pertanyaan
- segera
- Pembaca
- alasan
- Hasil
- kembali
- Tersebut
- Pencarian
- Seri
- set
- penyiapan
- Sederhana
- kecil
- So
- beberapa
- tertentu
- Secara khusus
- dimulai
- Masih
- Grafik
- Melalui
- Judul
- Pelatihan
- transfer
- ditransfer
- jenis
- universitas
- menggunakan
- Apa
- SIAPA
- kata
- Kerja
- bekerja
- akan
- X
- Anda